详解事务、隔离级别、悲观锁和乐观锁
今天,我们来聊数据库事务ACID、隔离级别、悲观锁和乐观锁。无论是在工作中,还是在笔试面试中,数据库相关的问题,总是绕不开,不会的话,很容易歇菜,你懂的。
数据库事务场景
在银行系统中,数据库事务是必须的。在电商系统中,也是如此。
来看下A给B汇款100元的例子,可以看到,A账户扣款100元,此时如果进程崩溃或者机器掉电,那么这100元就没有加到B的账户中,自然会导致用户的强烈投诉:
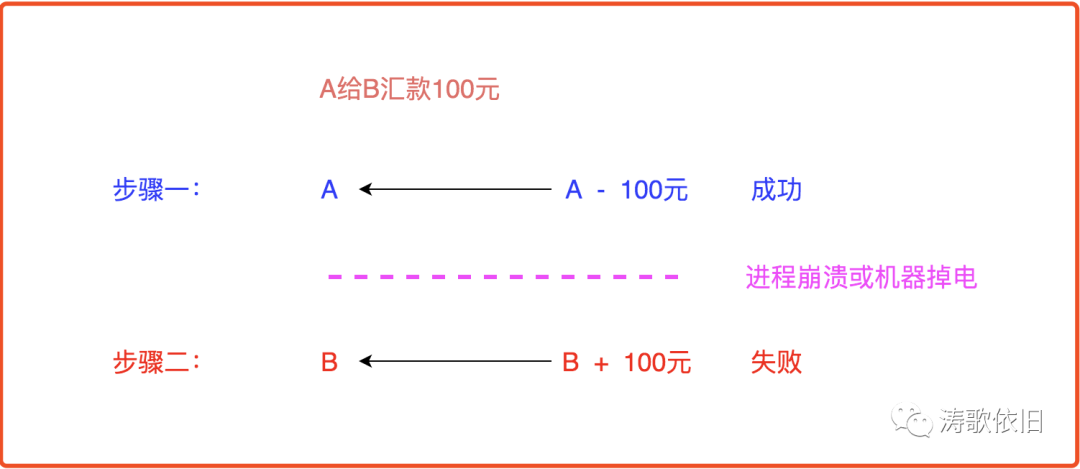
如果先给B账户加钱,然后给A账户扣钱,会怎样呢?可以看到,此时如果进程崩溃或者机器掉电,银行白白给B加了100元,而没有扣减A的100元,只怕银行会亏得没裤子穿:
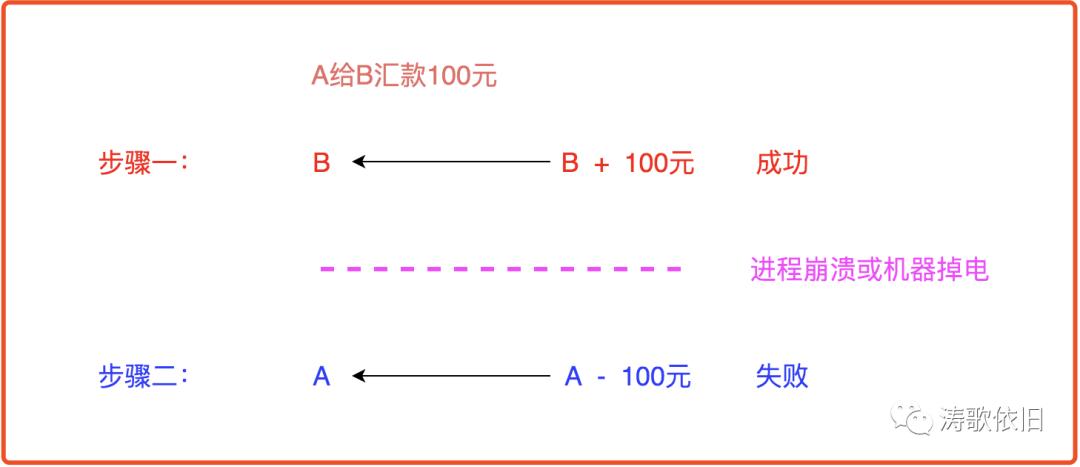
墨菲定律说:凡是会出错的事,一定会出错。 而且,一旦发生,将造成较大危害。所以,在软件设计上,有必要考虑这种异常。进程崩溃,机房掉电,网络抖动,硬件损坏,都应该被视为常态,都应该被考虑到。

如果要在应用层处理这些异常问题,将极为困难,甚至几乎不可能。做过软件开发的朋友应该知道,很多时候,如果异常问题处理得不妥当,将要投入大量时间分析和补救,且不一定能补救回来。
所以,有必要引入数据库事务。所谓事务,就是一组SQL操作,它们不可分割,不能被打断,要么都成功,要么都失败。具体地说,就是要满足ACID性质。
引入事务之后,应用层再也不用担心上述异常了,因为数据库已经为我们处理得很好了。很多书籍把ACID放在一起叙述,我认为有点扯,因为他们并不正交。在我看来,C是AID的最终目的。下面,我们来看下ACID性质。
Atomicity(原子性)
古希腊哲学家德谟克利特认为,原子是构成世界万物的单元,且不可分割:

那么具体怎样去实现原子性呢?有兴趣的朋友可以了解下undo log, 在此不展开叙述。我们不是DBA, 不需要精通数据库的众多具体细节,但是,至少要知道大概的原理和可行性,这可以为我们解决类似问题提供思路和参考。
Consistency(一致性)
一致性是我们最终的目的,笼统地说,一致性就是要确保数据是正确无误的。所谓valid data, 其实就是正确无误的data:
Isolation(隔离性)
隔离性,就是要隔离不同事务,隔离性是本文的重点,我们会针对不同的隔离级别进行介绍,先来看一眼:
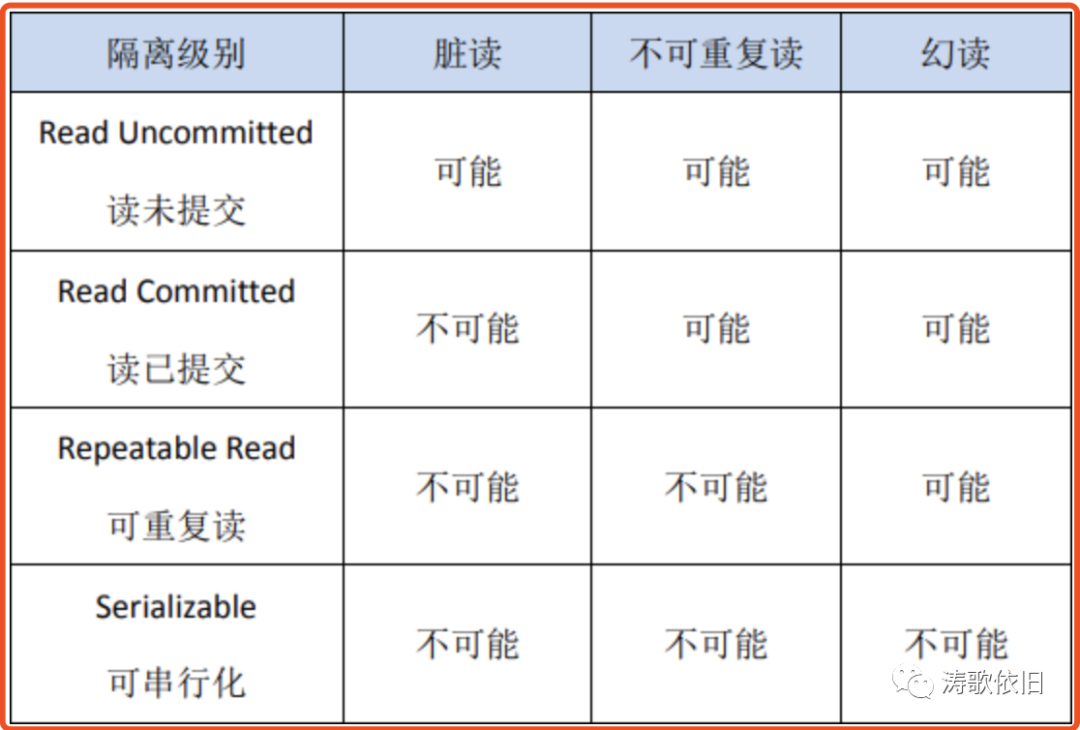
- InnoDB通过MVCC部分地解决了幻读问题:a. 针对select不会有幻读;b. 针对select for update会有幻读。
- 其它很多数据库引擎,还是存在幻读问题。
关于InnoDB是否存在幻读问题,我们将在本文的实验部分进行验证。
Durability(持久性)
持久性的意思是,一旦事务提交,它对数据库的变更是永久性的。实际上,事务提交后,最后不一定会落地到数据库中(比如落地时机器断电了),那怎么保证一定要落地成功呢?
这就涉及到redo log了,我们也不需要具体知道redo log的细节,但是,我们从逻辑上可以缕清:redo log要记录什么?redo log为什么能保证持久性?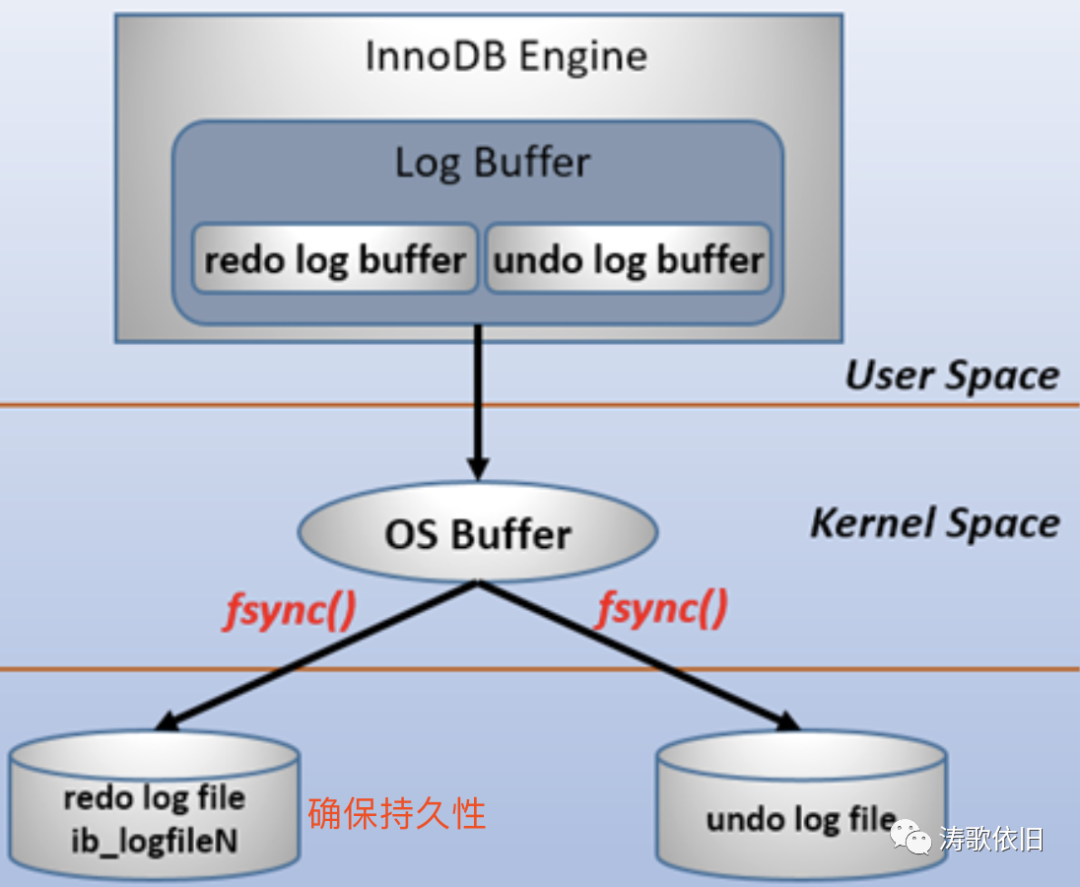
接下来,我们看这个问题:客户端A的事务,是否应该看到客户端B的事务所作的修改?这就涉及到数据库事务的隔离级别。
在本文中,如下图示都是基于我的实际验证。建议有兴趣的朋友一起动手,感受一下。
说明:事务A和事务B位于两个不同的终端窗口,对应两个不同的进程,在改变隔离级别时,仅改A的隔离级别来进行验证。
1.读未提交
我们来看看读未提交的场景:

2.读已提交
我们来看看读已提交的场景: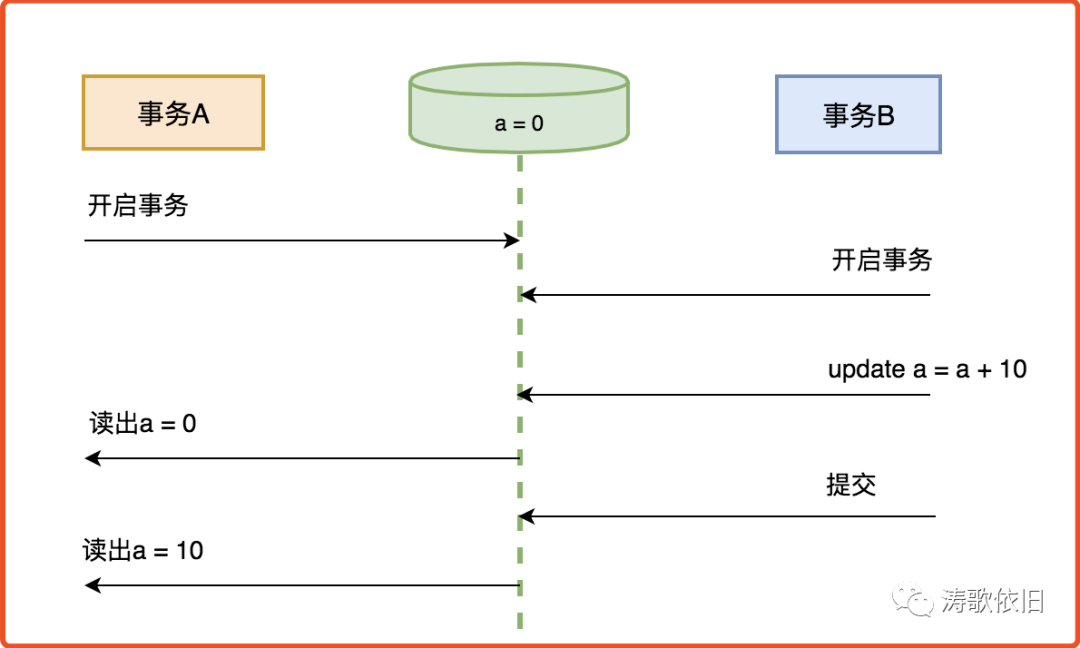
3 . 可重复读
我们来看看可重复读的场景: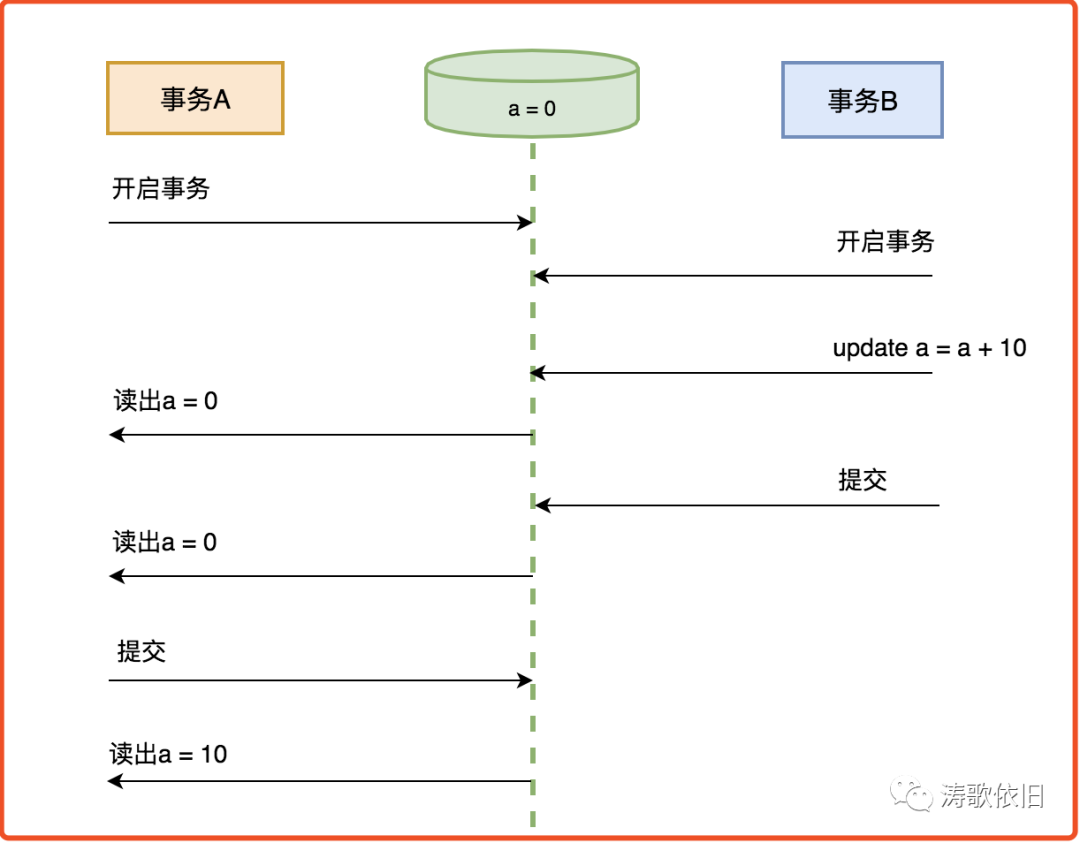
接下来,我们看一个魔幻现象: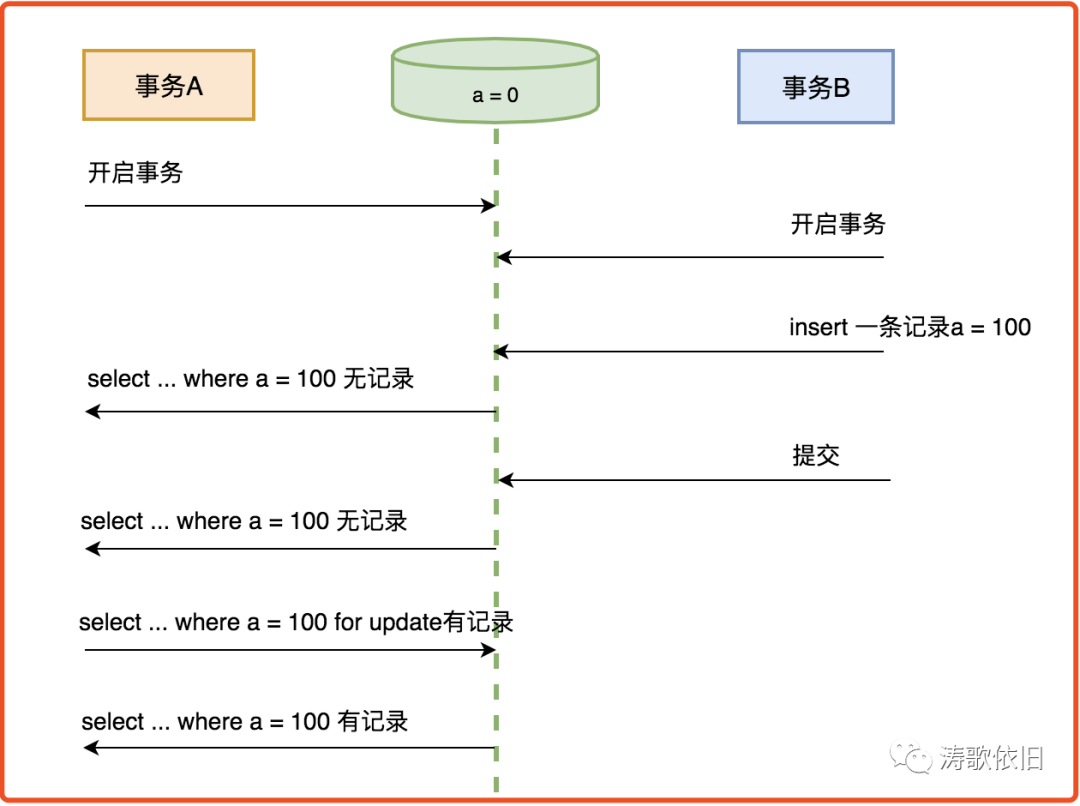
可见,在InnoDB可重复读的隔离级别中,并未完全解决“幻读”问题,而是解决了读数据情况下的“幻读”问题,而对于修改的操作依然存在“幻读”问题。
4.串行化
我们来看看串行化的场景: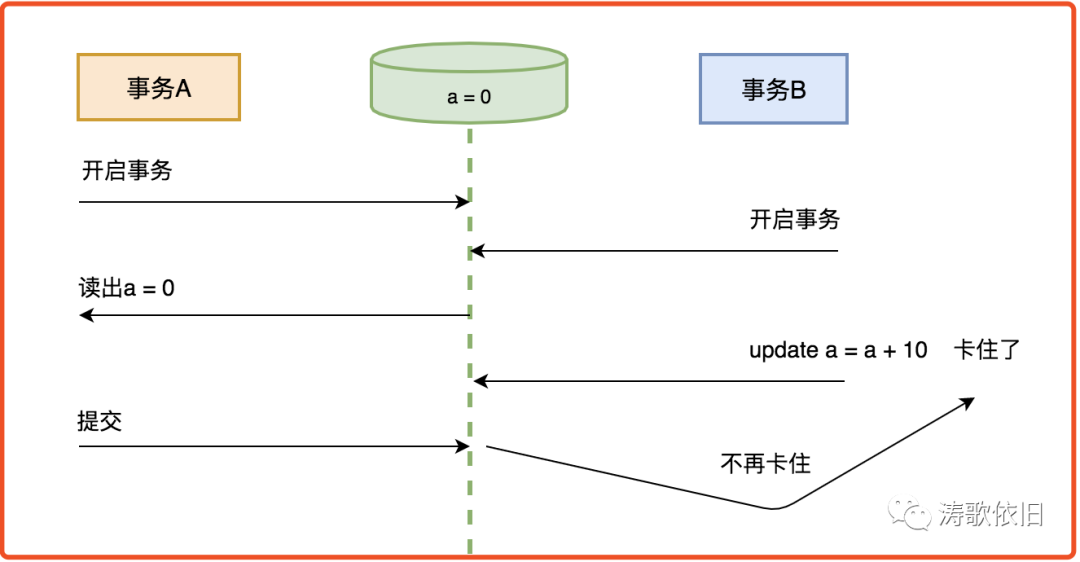
丢失更新问题
有了这些隔离级别,就万事大吉了吗? 当然不是。以MySql为例,在默认隔离级别下,会有丢失更新的问题。
领导A给你加了30元的鸡腿,领导B给你加了40元的鸡腿,最终结果发现,只有40元鸡腿,显然,这是不合理的: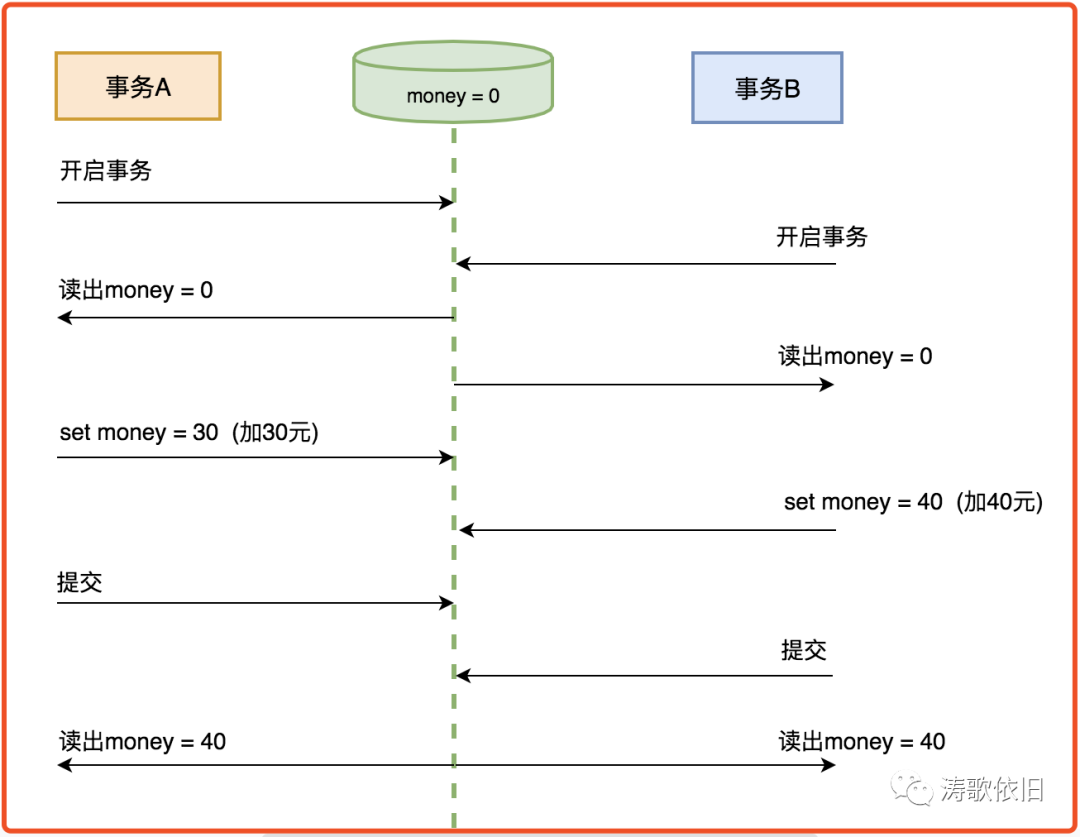
悲观锁
所谓悲观锁,就是持悲观态度,认为一定会有冲突,所以提前加强保护。悲观锁可以用select for update来实现,之前项目中就经常这样玩,但后来重构了代码,统一优化成了分布式锁。
使用分布式锁, 代码示意如下(如下使用方法有问题):
func proc() {
money := queryMoneyFromDb()
begin lock
begin transaction
money += req.Money
setToDb(money)
end transaction
end lock
}上述代码的使用是有问题的,想一下为什么?
当两个进程都读取money=0后,进程A获取锁,并且执行完毕后,money=30,然后进程B获取锁,执行完毕后,显然可知,最后的结果是money=40,仍然存在丢失更新的问题。
曾经在项目中,就出现过这种错误,导致了低概率的金额不匹配,比较难发现问题,最后还是通过对账发现了,然后查出上述错误的用法。
正确使用悲观锁代码示意如下:
func proc() {
begin lock
begin transaction
money := queryMoneyFromDb()
money += req.Money
setToDb(money)
end transaction
end lock
}
乐观锁
所谓乐观锁,就是抱有很乐观的态度,也就是假定不会存在数据冲突(即使有冲突也不怕,乐观得很)。具体实现时,可以在数据上打一个version标记,基于version进行控制,代码示意如下:
func proc() {
begin transaction
select * from T where user_id = 123456 // 假设查到的version为100
update T set money = xxx, version = version + 1 where user_id = 123456 and version = 100;
end transaction
}分析一下:进程A和进程B都读到了version=100的数据,进程A在加完30元后,同时让version变成了101;此时进程B去执行,突然发现不满足where version=100这个条件,所以更新失败,这是合理的,符合预期,宁可执行失败,也不能产生数据错误。
这里有一个极为微妙的问题:在MySql可重复读隔离级别下,当进程A的update执行成功并且提交事务后,version变为了101, 但是在进程B看来,version还是100(可重复读), 为什么B在执行update的时候,在where version=100条件下又无法真正执行update呢?
要注意,可重复读是针对select而言的,而不是select for update或者update之类的操作,当A进程事务提交后,B进程事务看到的情况如下:
mysql> select * from user;
+----+-------+---------+
| id | money | version |
+----+-------+---------+
| 1 | 0 | 100 |
+----+-------+---------+
1 row in set (0.00 sec)
mysql> select * from user for update;
+----+-------+---------+
| id | money | version |
+----+-------+---------+
| 1 | 30 | 101 |
+----+-------+---------+
1 row in set (0.25 sec)
mysql> select * from user;
+----+-------+---------+
| id | money | version |
+----+-------+---------+
| 1 | 0 | 100 |
+----+-------+---------+
1 row in set (0.00 sec)可见,对B事务而言,用select看,看不到B事务的更新,这满足事务的可重复读。但是,当使用select for update时,能看到B事务的更新。
所以,当B事务使用update尝试更新where version=100的记录时,发现更新失败,这是我们期望的结果,宁可执行失败,也不能产生数据错误。针对这种失败,可以采用多次重试。
至于悲观锁和乐观锁的选择,还是要依赖于具体业务。数据的一致性如此重要,可千万别把用户的钱给算错了。
对于频繁写冲突的业务,用乐观锁肯定是不太好的,重试操作会增加各种开销,此时可以考虑使用悲观锁。对于写冲突较少发生的场景,那乐观锁就非常适合了。
·················· END ··················