一文带你看完计算机CPU发家史
1 计算机概述
1.1 发展简史
一阶段(1946~1957)
电子管计算机
-
电子管
-
第一代计算机"ENIAC"
世界上第一台电子计算机"ENIAC"于1946年2月14日在美国宾夕法尼亚大学诞生,美国人莫克利(JohnW.Mauchly)和艾克特(J.PresperEckert)发明,主要是有大量的电子管组成,主用于科学计算。 主要特点:
-
以电子管作为元器件,所以称电子管计算机
-
用了18000个电子管,占地150平方米,足有两间房子大,重达30吨,耗电功率约150千瓦,每秒钟可进行5000次运算
-
电子管空间占用大,耗电量大,易发热,因而工作的时间不能太长
-
使用机器语言,无系统软件
-
采用磁鼓、小磁芯作为储存器,存储空间有限
-
输入/输出设备简单,采用穿孔纸带或卡片,操作复杂,更换程序需要接线
-
主要用于科学计算,当时美国国防部用它来进行弹道计算


二阶段(1957~1964)
晶体管计算机
-
晶体管
第二代计算机采用的主要元件是晶体管,称为晶体管计算机。计算机软件有了较大发展,程序语言也出现了Fortran,Cobol计算机高级语言,采用了监控程序,这是操作系统的雏形。 主要特点: 1、集成度较高,体积小 2、运算速度快,功耗更低 3、操作简单,交互方便(有显示器了)

三阶段(1964~1980)
中小规模集成电路计算机。
德州仪器的工程师发明了集成电路(IC)
集成电路可在几平方毫米的单晶硅片上集成十几个甚至上百个电子元件。计算机开始采用中小规模的集成电路元件,这一代比上一代更小,耗电更少,功能更强,寿命更长,领域扩大,性能比上一代有很大提高。 主要特点: 1、体积更小,寿命更长。 2、运行计算速度更快。 3、外围设备考试出现多样化。 4、有类似操作系统和应用程序,高级语言进一步发展。 5、应用范围扩大到企业管理和辅助设计等领域。
四阶段(1980~至今)
超大规模集成电路计算机。
这时期的计算机的体积、重量、功耗进一步减少,运算速度、存储容量、可靠性都有很大提高。 主要特点: 1、采用了大规模和超大规模集成电路逻辑元件,体积与第三代相比进一步缩小,可靠性更高,寿命更长。 2、运算速度加快,每秒可达集千万次到几十亿次。 3、系统软件和应用软件获得了巨大的发展,软件配置丰富,程序设计部分自动化。 4、计算机网络技术、多媒体技术、分布式处理技术有了很大的发展,微型计算机大量进入家庭,产品更新速度加快。 5、计算机在办公自动化、数据库管理、图像处理、语言设别和专家系统等各个领域得到应用,电子商务已开始进入家庭,出现个人电脑(PC),计算机的发展进入到了一个新的历史时期。
未来的计算机
超导计算机、纳米计算机、光计算机、DNA计算机、量子计算机和神经网络计算机等,体积更小,运算速度更快,更加智能化,耗电量更小。
程序的CPU执行时间 = 指令数×CPI×Clock Cycle Time
所以提升计算机的性能,可以通过指令数/CPI,好像都太难了。 因此工程师们,就在CPU上多放晶体管,不断提升CPU的时钟频率,让CPU更快,程序的执行时间就会缩短。
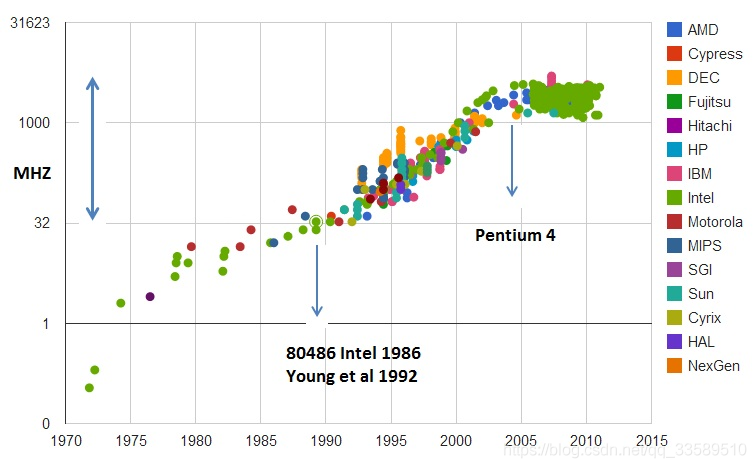
- 从1978年Intel发布的8086 CPU开始,计算机的主频从5MHz开始,不断攀升
- 1980年代中期的80386能够跑到40MHz
- 1989年的486能够跑到100MHz
- 直到2000年的奔腾4处理器,主频已经到达了1.4GHz
1.2 分类
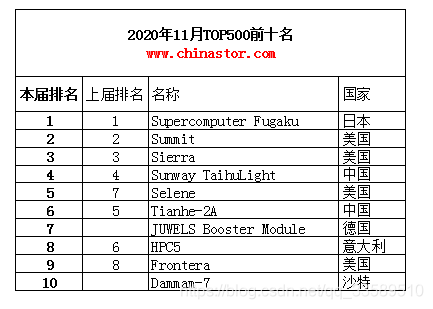
超级计算机
功能最强、运算速度最快、存储容量最大的计算机,多用于国家高科技领域和尖端技术研究。
计算速度单位 TFlop/s。1TFlop/s= 1万亿次浮点计算/s Intel® Core™ 10090K CPU
5.3GHz = 59.45 GFlop/s = 0.05945TFlop/s
大型计算机
又称大型机、大型主机、主机等,具有高性能,可处理大量数据与复杂的运算。该领域下IBM占据大份额。IBM Z9,NASA的最后一台大型机,使用的Red Hat Enterprise Linux。 但是造价太高,阿里巴巴提出去 I(IBM)O(Oracle)E(EMC)这种高代价的存储系统维护,而且伸缩性差。
迷你计算机(服务器)
也称为小型机,普通服务器。不需要特殊的空调场所,具备不错的算力,可以完成较复杂的运算。 普通服务器已替代传统的大型机,成为大规模企业计算的核心。
工作站
高端的通用微型计算机,提供比个人计算机更强大的性能。类似于普通台式电脑, 体积较大,但性能强劲。
微型计算机
即个人计算机,是最普通的一类计算机,如台式机,笔记本和一体机。
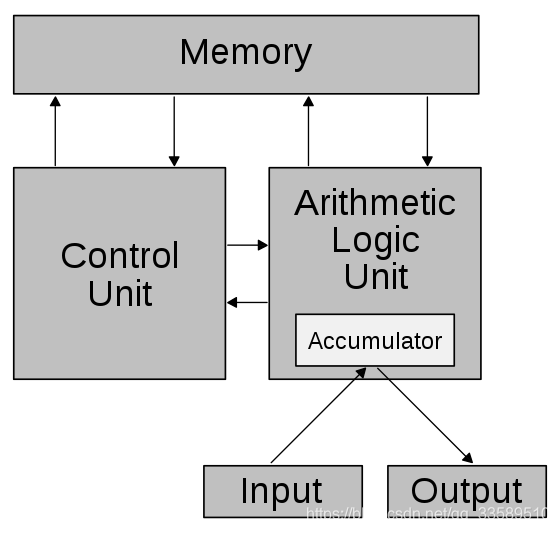
1.3 冯·诺伊曼结构
早期计算机仅含固定用途程序,如果改变程序就得更改结构、重新设计电路。所以需要把程序存储起来,并设计通用电路,即存储程序指令设计通用电路。
- 把需要的程序和数据送至计算机中
- 长期记忆程序、数据、中间结果及最终运算结果的能力
- 具备算术、逻辑运算和数据传送等数据加工处理的能力
- 按照要求将处理结果输出给用户
冯·诺伊曼瓶颈(von Neumann bottleneck)
在CPU与存储器之间的流量(资料传输率)与存储器的容量相比起来相当小,在现代电脑中,流量与CPU的工作效率相比之下非常小,在某些情况下(当CPU需要在巨大的数据上运行一些简单指令时),数据流量就成了整体效率非常严重的限制。CPU将会在数据输入或输出存储器时闲置。由于CPU速度远大于存储器读写速率,因此瓶颈问题越来越严重。
在CPU与存储器间的缓存存储器缓解冯·诺伊曼瓶颈。分支预测(branch prediction)算法的创建也帮助缓和了此问题。
程序翻译与程序解释
2 CPU的极限-功耗
奔腾4的CPU主频从来没有达到过10GHz,最终定格在3.8GHz 奔腾4主频虽高,但实际性能却配不上同样的主频。
于是不仅让AMD获得喘息之机,更代表“主频时代”终结。后面几代Intel CPU主频不但没上升,反而下降。
-
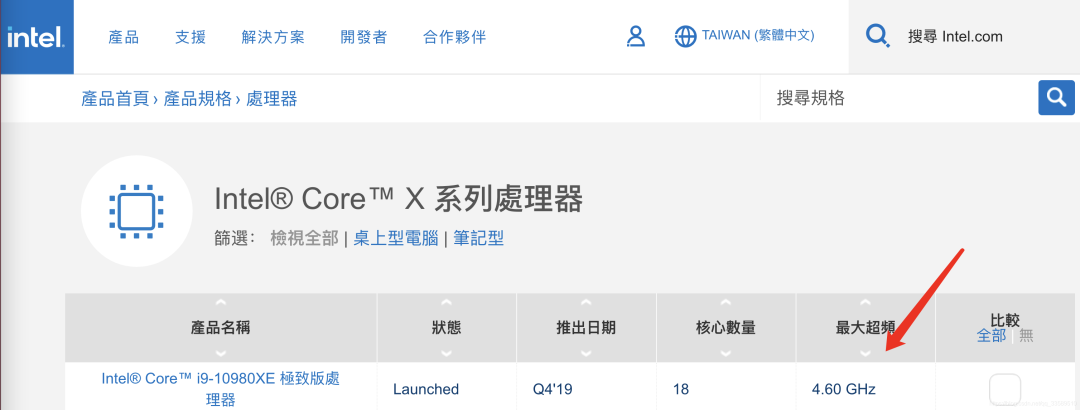
至今的最高配置Intel X 系列 CPU
主频也不过5GHz。 相较于1978年到2000年,这20年里300倍的主频提升,从2000年到现在的20 年,CPU的主频大概提高3倍。
-
奔腾4时CPU主频进入瓶颈期
就是因为功耗。CPU,也称作超大规模集成电路,Very-Large-Scale Integration,VLSI。 CPU就是让晶体管里面的“开关”不断“打开”/“关闭”,组合完成各种运算和功能。
提高CPU计算速度:
- 增加密度 同样的面积,多放晶体管。如果CPU的面积大,晶体管之间的距离变更大,电信号传输的时间就会变长,运算速度自然就慢了。
- 提升主频 让晶体管“打开”/“关闭”更快,但是动作快,就要出汗散热,所以有了CPU上的硅脂、风扇、水冷。但设备散热效果也有极限。
因此,CPU里能够放下的晶体管数量和晶体管的“开关”频率也有限。 一个CPU的功率,可以用这样一个公式来表示:
功耗 ≈ 1/2 ×负载电容 × 电压的平方 × 开关频率 × 晶体管数量
为提升性能,要不断增加晶体管密度,就要把晶体管造得小一点,即提升“制程”。从28nm到5nm,还要提升主频,让开关频率变快。
但功耗过多,CPU散热就跟不上,公式里功耗和电压平方成正比,即可降低电压。 从5MHz主频的8086到5GHz主频的Intel X,CPU电压从5V下降到了1V。
2 并行优化-阿姆达尔定律
从90s到本世纪初,“面向摩尔定律编程”的套路越来越用不下去了。奔腾4开始,Intel意识到通过提升主频“难”以性能提升。开始推出多核CPU,提升“吞吐率”而非“响应时间”。即通过并行提高性能。 但要使用这种思想,需满足以下条件:
- 需要进行的计算,本身即可分解成几个可并行任务 比如向量的点乘运算
- 需要能够分解好问题,并确保几个人的结果能够汇总到一起
- 在“汇总”这个阶段,是没有办法并行进行的,还是得顺序执行,一步一步来
这就引出了阿姆达尔定律(Amdahl’s Law): 对一个程序优化后,处理器并行运算之后效率提升的情况可用如下公式表示:
优化后的执行时间 = 受优化影响的执行时间/加速倍数+不受影响的执行时间
比如向量点乘,同时计算向量的一小段点积,就是并行提高部分计算性能。但最终还是要在一个人那汇总相加,这部分时间无法并行优化,即不受影响的执行时间。
比如向量
- 点积需100ns
- 加法需要20ns
总共需要120ns。这里通过并行4个CPU有了4倍的加速度。那么最终优化后,就有了100/4+20=45ns。 即使增加并行度来提供加速倍数,比如有100个CPU,整个时间也需要100/100+20=21ns,所以并非越多就肯定越快。
3 让性能再次提升
无论是简单提升主频,还是增加CPU核心数,通过并行提升性能,都会遇到瓶颈。 仅靠“堆硬件”,已经不能很好地满足性能。于是,工程师们需要从其他方面开始下功夫。 在“摩尔定律”和“并行计算”之外,在整个计算机组成层面,还有如下:
3.1 大概率事件
深度学习,整个计算过程中基本都是向量矩阵计算。所以用GPU替代CPU,大幅度提升了深度学习的模型训练过程,Google不满足GPU性能,还推出了TPU。
3.2 流水线
现代的工厂里的生产线叫“流水线”。可以把装配iPhone这样的任务拆分成一个个细分的任务,让每个人都只需要处理一道工序,最大化整个工厂的生产效率。 CPU就是一个运算工厂,把CPU指令执行的过程进行拆分,细化运行。
3.3 预测
预测下一步而非苦等上一步结果,即提前运算。就像循环访问数组时,你也会猜到下一步会访问数组下一项。比如“分支和冒险”、“局部性原理”。
参考
- 《深入理解计算机操作系统》
- https://www.eda365.com/portal.php?mod=view&aid=53086