Linux 内核 | 网络流量限速方案大 PK
网络流量限速是一个经久不衰的话题,Linux 内核中已经实现了若干种流量限速的方式。
最简单的方式是通过定期采集速率,在超过指定的速率后直接丢包,但这种方案效果不佳,不能精准地将流量控制在指定的速率。
更成熟的方案都是把需要延迟发送的数据包缓冲在队列中,在合适的时间再进行发送,因此 Linux 内核中的 Traffic Control(简称 TC)层就成了实现透明的网络流量限速的最佳位置。
由于历史原因,TC 只有在出口方向上实现了有队列的 Qdisc (Queue discipline),所以我们在这里提到的限速方案也都是在出口方向上实现的。入口方向上的限速比较困难,除了 TC 层缺少队列之外,还很难对流量的源头进行限速,因此我们在这里不予讨论。
1 . 传统限速方案
传统的 TC 限速,是通过给网络设备添加单一的具有限速功能的 Qdisc (比如 HTB、TBF 等)来完成的。这些方案有一个共同的缺点,即依赖一把设备全局的 Qdisc spinlock 来进行同步。
这把锁很难进行优化,主要有两个原因:
- 数据包的入队、出队都是写操作,且都不是原子操作,因此需要使用锁来同步;
- 这些 Qdisc 实现的都是设备全局的限速,其中一部分(如 HTB Qdisc)还允许不同流量类型 (class) 之间互相借用带宽,因此更需要一把全局锁来进行统一协调。
上述传统方案在发送流量较大的时候会碰到这个全局锁的性能瓶颈。
2 . mq Qdisc 方案
针对传统方案的弊端,Linux 内核提供了一个「拆散」这把全局 spinlock 的软件方案:mq Qdisc。mq Qdisc 是一个很特殊的 Qdisc,它为网络设备的每一个硬件队列分别创建一个软件 Qdisc,再通过一个 ->attach()操作将它们挂载到各个硬件队列上,如图所示:
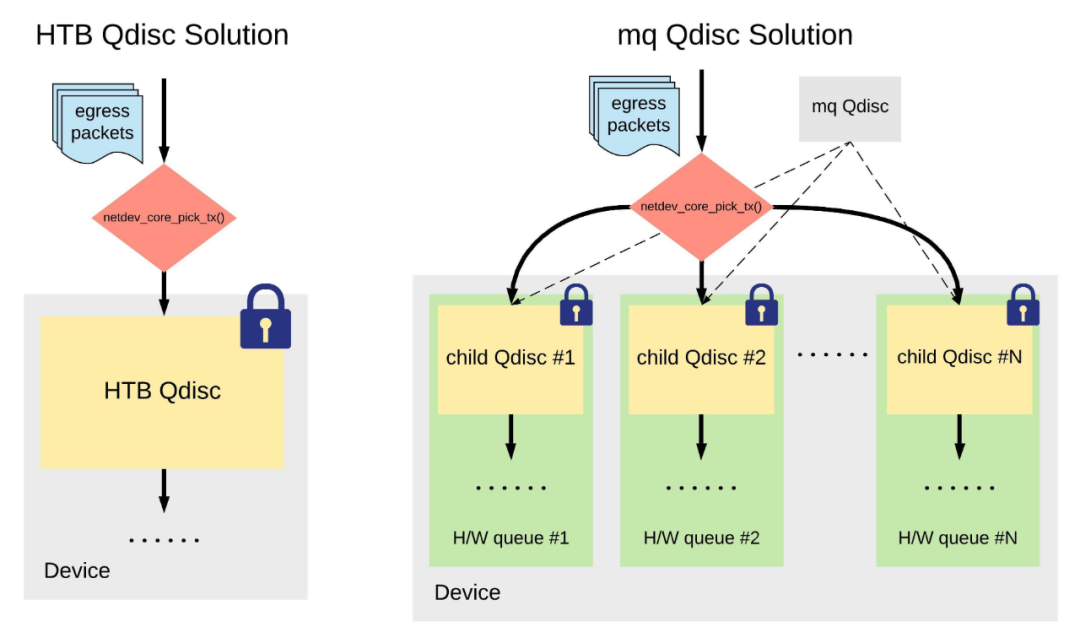
这样一来,每一个硬件队列上的 Qdisc(上图中「child Qdisc」)都有各自的 spinlock,一个锁被「拆」成了多个锁,从而改善了设备全局 spinlock 带来的性能问题。
需注意的是,mq Qdisc 本身并不实现任何限速机制,仅仅提供了一个框架,须和其它具有限速功能的 child Qdisc(HTB、SFQ 等)配合使用。
这样做有一个缺点:现在设备上的一个 Qdisc 被「拆」成了多个 child Qdisc,我们就只能分别对这些 child Qdisc 配置限速规则,从而失去了传统方案里对设备流量的全局控制。
3 . HTB 硬件 offload 方案
针对传统 HTB 方案的缺点,Mellanox 网卡推出了一个通过硬件来实现限速的方案,给 HTB Qdisc 添加了「offload 模式」,模拟 mq Qdisc 的 ->attach() 操作:
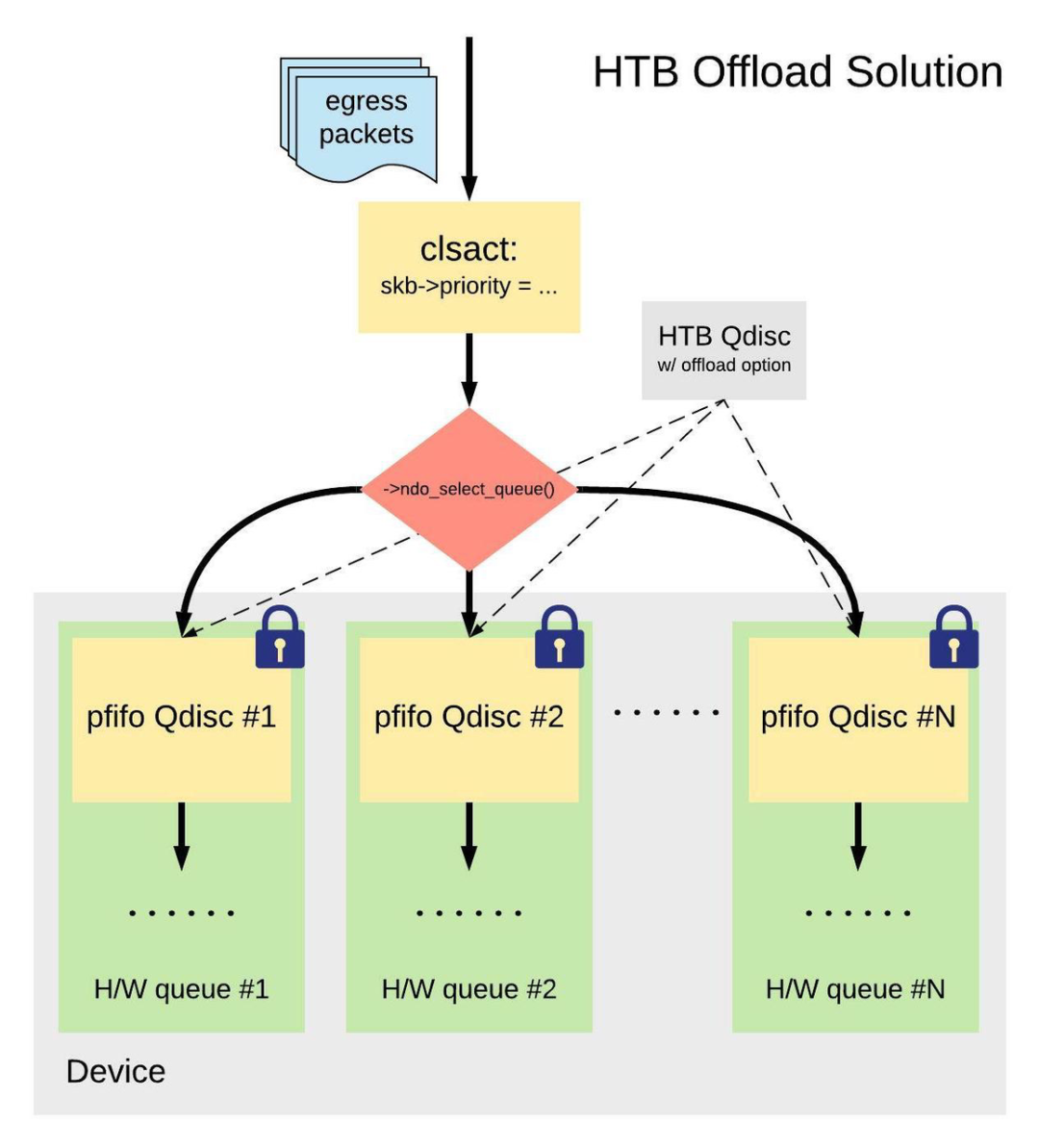
$ tc qdisc add dev $DEV clsact
$ tc filter add dev $DEV egress protocol ip flower dst_port 80 \
action skbedit priority 1:10梳理一下这种方案下的发包流程:
- 安装在 clsact Qdisc 上的 filter 对数据包进行分类,设置
skb->priority; - Mellanox 网卡驱动注册的
->ndo_select_queue()成员函数根据skb->priority将数据包分发到不同的硬件队列(对应不同的 HTB leaf class)里; - 最终由硬件完成限速。
但同样的,无论是基于 mq Qdisc 的软件方案,还是依赖于硬件特性的 offload 方案,它们都有一个最大的弊端:流量的类型、限速规则绑定在各个硬件队列上,没有办法根据业务的需求灵活地分配带宽。
4 . ifb 方案
ifb 方案为每一种流量类型新建一个软件 ifb 设备,在原发送设备的 clsact Qdisc 上对流量进行分类,通过 mirred action 将不同类型的流量转发到对应的 ifb 设备,再由各个 ifb 设备上的 TBF Qdisc 完成限速:
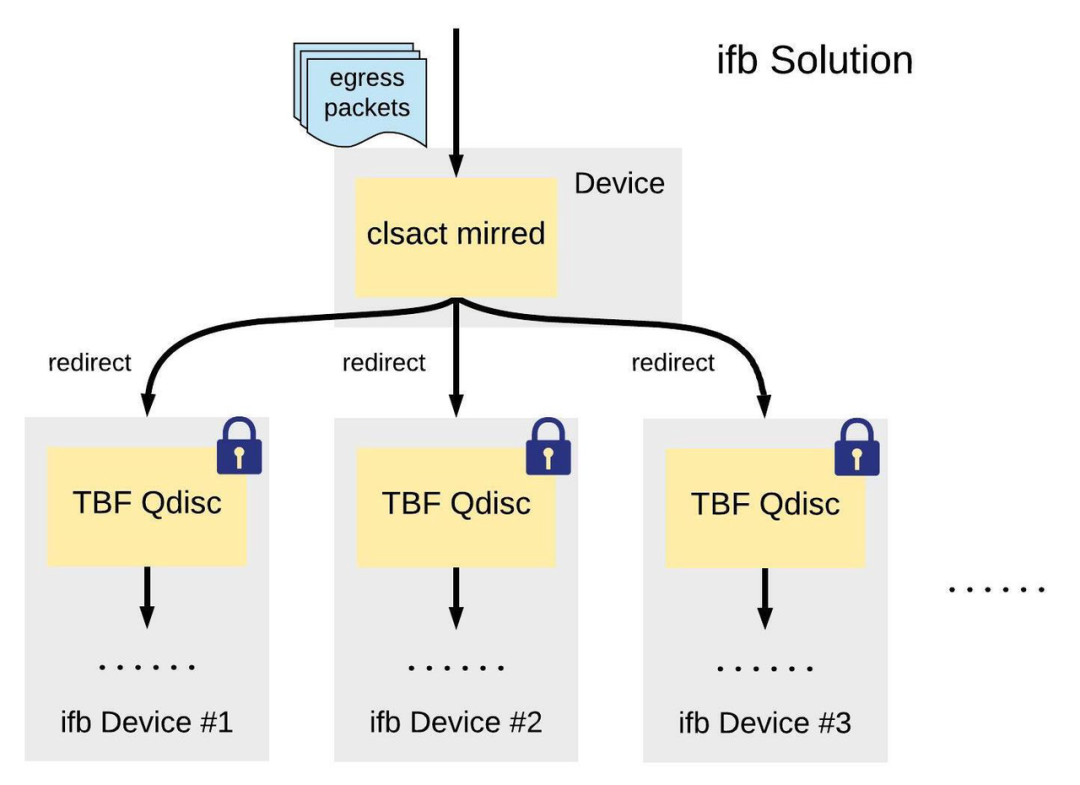
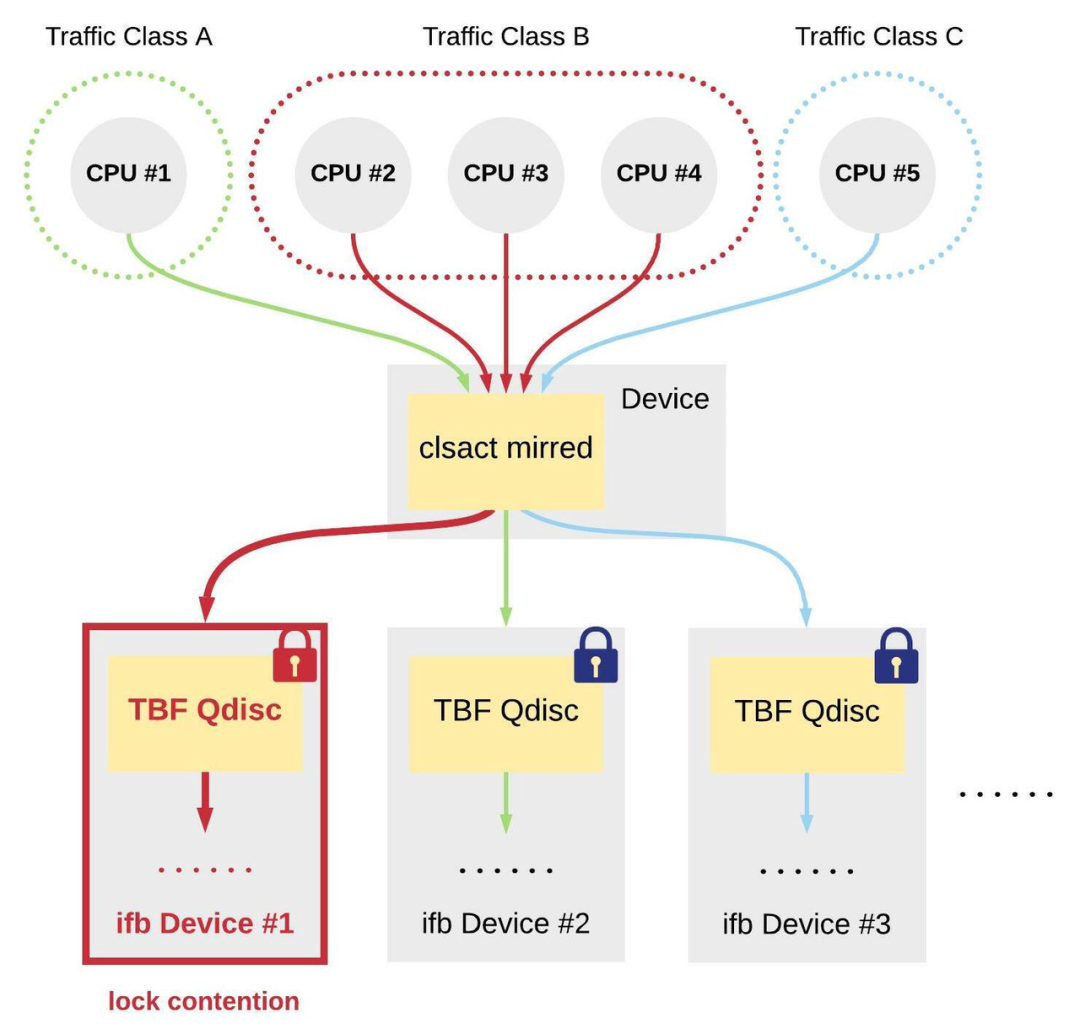
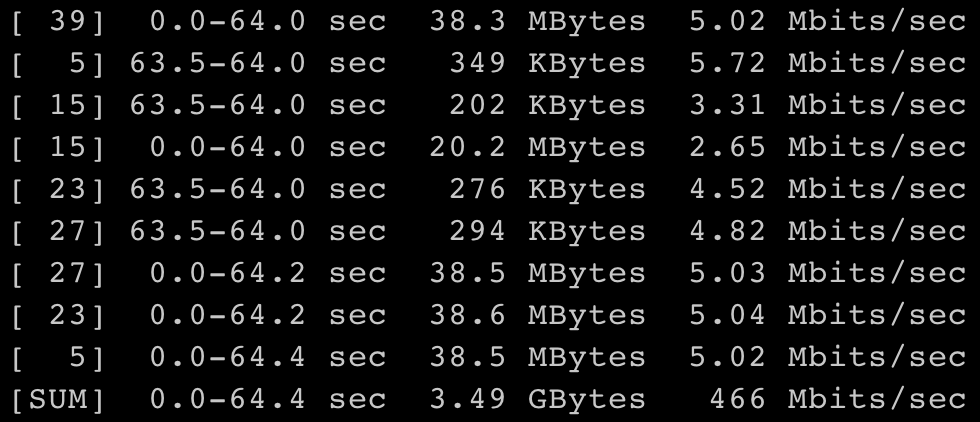
字节跳动系统部 STE 团队进行了以下验证:
- 在 eth0 设备上安装 clsact Qdisc,并设置 mirred 规则,转发出口方向 A 类流量至 ifb0;
- 在 ifb0 设备上安装 TBF Qdisc,并给 A 类流量设置 500 Mbits/sec 的带宽限制;
- 启动 96 个 iperf client 进程全速向 eth0 设备发送 A 类流量,分别绑定到 96 个 CPU 上。
5 . EDT 方案
针对上述各类方案的缺点,Eric Dumazet 等人提出了一种使用 clsact Qdsic + eBPF filter + mq Qdisc + fq Qdisc 的 EDT (Earliest Departure Time) 方案:

- 数据包先统一经过一个安装在 clsact Qdisc 出口方向上的 eBPF filter。这个 eBPF filter 程序包含着主要的限速逻辑;它会根据某一个数据包所属流量类别的带宽来计算这个数据包的预计发送时间,并给它盖一个时间戳 (
skb->tstamp); - 随后,数据包被分发到设备的各个硬件队列,且每个硬件队列都有一个自己的 fq Qdisc;
- 最后,fq Qdisc 按照时间戳对数据包进行排序,并确保每个数据包最终出队的时间都不早于数据包上的时间戳,从而达到限速的目的。
与 mq Qdisc 等方案相比,EDT 方案的一个优点,在于流量类别与硬件队列之间不存在对应关系:
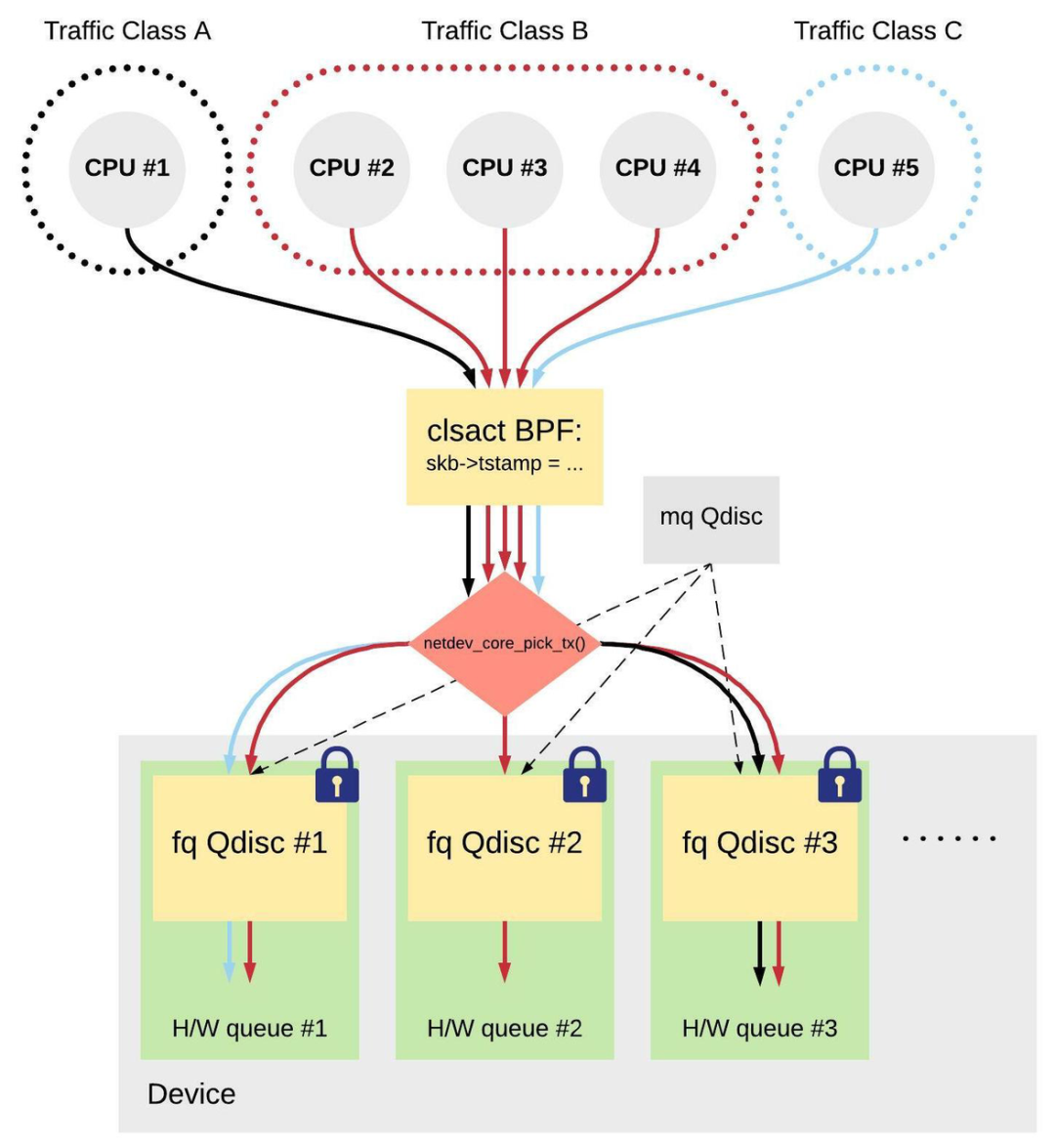
需要注意的是,不管是发送相同还是不同类流量的两个 CPU 仍然有可能竞争同一个 fq Qdisc spinlock。
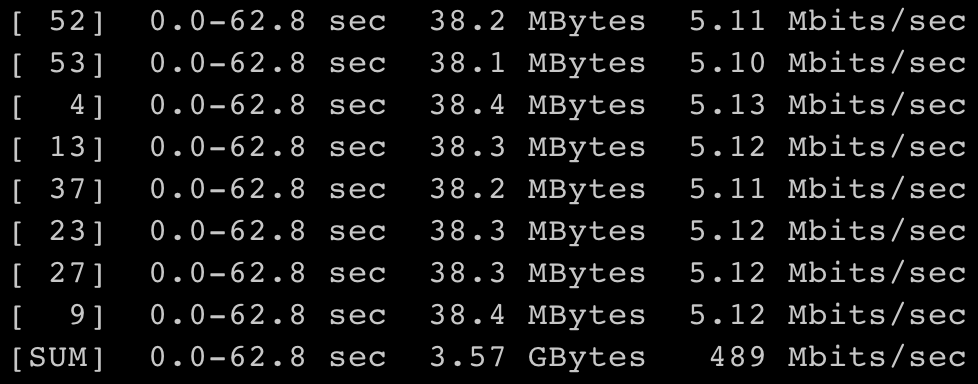
字节跳动系统部 STE 团队对 EDT 方案也做了类似的验证:
- 在 eth0 设备上安装 mq Qdisc;
- 为 eth0 设备的 8 个硬件队列分别安装 fq Qdisc;
- 在 eth0 设备上安装 clsact Qdisc,并挂载 eBPF filter 程序,对 A 类流量设置 500 Mbits/sec 的带宽限制;
- 同样地,启动 96 个 iperf client 进程全速向 eth0 设备发送 A 类流量,并分别绑定到 96 个 CPU 上。
可选操作:将 CPU 与硬件队列绑定
通过在 eBPF filter 程序中修改 skb->queue_mapping,我们可以将 CPU 与发送设备的硬件队列一一绑定(例如 CPU 1 只能发送到硬件队列 1,等等),从而进一步减缓 CPU 之间的锁竞争。事实上,如果机器上 CPU 的数量小于等于发送设备的硬件队列数,这样操作可以完全避免 CPU 之间的锁竞争。
但这也带来一个问题,考虑:假设我们让 CPU 1 只能发到硬件队列 1,CPU 2 只能发到硬件队列 2。发送某类流量的进程甲,上一时刻运行在 CPU 1 上,发了一个数据包 A 到硬件队列 1 上;下一时刻它被调度到 CPU 2 上,发了一个数据包 B 到硬件队列 2 上。由于硬件队列 1 和 2 分别有自己的 fq Qdisc,维护着各自的数据包出队顺序,我们无法保证数据包 A 会先于数据包 B 出队——也就可能会有发包乱序的问题。
EDT 方案小结
总的来说,我们认为 EDT 方案有三个优点:
- 可以减轻(甚至 彻底避免)锁的竞争,尤其是针对某一类流量发送速度很高的情况;
- 可以完全根据业务的需求直接进行限速,而不是为底层的硬件队列分别分配带宽(如 mq Qdisc 等方案)。底层的 fq Qdisc 仅负责执行上层 eBPF 代码中计算好的限速决策;
- 内核代码逻辑简单,可以把更多逻辑放到用户空间,可扩展性强。例如,可以在用户空间运行一个守护进程,实时监控各类流量的实际发送速率,并通过更新 eBPF map 的方式实现带宽借用等需求。
示例 eBPF 代码 (example.c)
按照 IP 目的地址把流量分为不同类型,并为每一类配置 100 Mbits/sec 的带宽:
#include <linux/types.h>
#include <bpf/bpf_helpers.h>
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/pkt_cls.h>
#include <linux/swab.h>
#include <stdint.h>
#include <linux/ip.h>
struct bpf_elf_map {
__u32 type;
__u32 size_key;
__u32 size_value;
__u32 max_elem;
__u32 flags;
__u32 id;
__u32 pinning;
__u32 inner_id;
__u32 inner_idx;
};
#define NS_PER_SEC 1000000000ULL
#define PIN_GLOBAL_NS 2
#ifndef __section
# define __section(NAME) \
__attribute__((section(NAME), used))
#endif
struct bpf_elf_map __section("maps") rate_map = {
.type = BPF_MAP_TYPE_HASH,
.size_key = sizeof(__u32),
.size_value = sizeof(__u64),
.pinning = PIN_GLOBAL_NS,
.max_elem = 16,
};
struct bpf_elf_map __section("maps") tstamp_map = {
.type = BPF_MAP_TYPE_HASH,
.size_key = sizeof(__u32),
.size_value = sizeof(__u64),
.max_elem = 16,
};
int classifier(struct __sk_buff *skb)
{
void *data_end = (void *)(unsigned long long)skb->data_end;
__u64 *rate, *tstamp, delay_ns, now, init_rate = 12500000; /* 100 Mbits/sec */
void *data = (void *)(unsigned long long)skb->data;
struct iphdr *ip = data + sizeof(struct ethhdr);
struct ethhdr *eth = data;
__u64 len = skb->len;
long ret;
now = bpf_ktime_get_ns();
if (data + sizeof(struct ethhdr) > data_end)
return TC_ACT_OK;
if (eth->h_proto != ___constant_swab16(ETH_P_IP))
return TC_ACT_OK;
if (data + sizeof(struct ethhdr) + sizeof(struct iphdr) > data_end)
return TC_ACT_OK;
rate = bpf_map_lookup_elem(&rate_map, &ip->daddr);
if (!rate) {
bpf_map_update_elem(&rate_map, &ip->daddr, &init_rate, BPF_ANY);
bpf_map_update_elem(&tstamp_map, &ip->daddr, &now, BPF_ANY);
return TC_ACT_OK;
}
delay_ns = skb->len * NS_PER_SEC / (*rate);
tstamp = bpf_map_lookup_elem(&tstamp_map, &ip->daddr);
if (!tstamp) /* unlikely */
return TC_ACT_OK;
if (*tstamp < now) {
*tstamp = now + delay_ns;
skb->tstamp = now;
return TC_ACT_OK;
}
skb->tstamp = *tstamp;
__sync_fetch_and_add(tstamp, delay_ns);
return TC_ACT_OK;
}
char _license[] SEC("license") = "GPL";使用
# 1. 编译 example.c
clang -O2 -emit-llvm -c example.c -o - | llc -march=bpf -filetype=obj -o example.o
# 2. 安装 mq/fq Qdisc
tc qdisc add dev $DEV root handle 1: mq
NUM_TX_QUEUES=$(ls -d /sys/class/net/$DEV/queues/tx* | wc -l)
for (( i=1; i<=$NUM_TX_QUEUES; i++ ))
do
tc qdisc add dev $DEV parent 1:$(printf '%x' $i) \
handle $(printf '%x' $((i+1))): fq
done
# 3. 安装 clsact Qdisc, 加载 example.o
tc qdisc add dev $DEV clsact
tc filter add dev $DEV egress bpf direct-action obj example.o sec .text
# 4. (使用后) 卸载 Qdisc,清理 eBPF map
tc qdisc del dev $DEV clsact
rm -f /sys/fs/bpf/tc/globals/rate_map
tc qdisc del dev $DEV root handle 1: mq6 . 总结
我们把所有的方案放到一张表中对比不难看出 EDT 方案的总体优势:
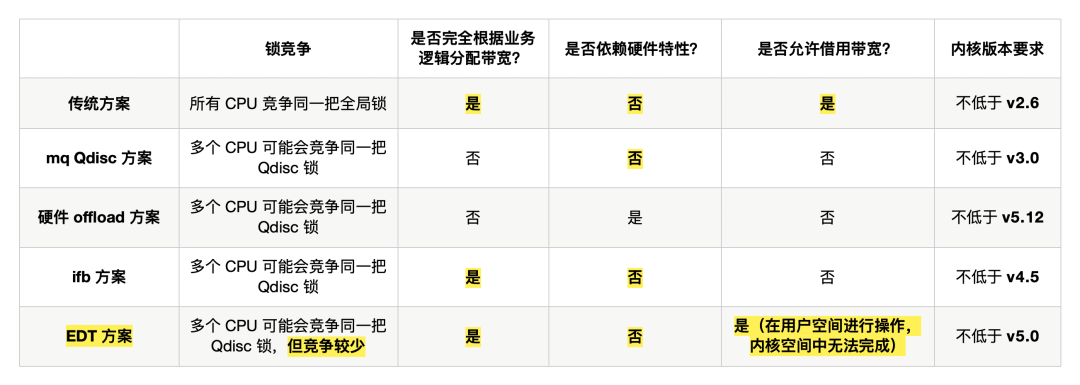
EDT 方案的不足之处是目前还无法和下层的 Qdisc 直接进行交互,从而实现更复杂的公平性逻辑。但是,字节跳动系统部 STE 团队正在开发的基于 eBPF 的 Qdisc 可以通过共享 eBPF map 达到这个目的,从而会让这个方案变得更加完善。
7 . 参考资料
- Yossi Kuperman, Maxim Mikityanskiy, Rony Efraim, 'Hierarchical QoS Hardware Offload (HTB)', Proceedings of Netdev 0x14, THE Technical Conference on Linux Networking, August 2020,https://legacy.netdevconf.info/0x14/pub/papers/44/0x14-paper44-talk-paper.pdf.
- Stanislav Fomichev, Eric Dumazet, Willem de Bruijn, Vlad Dumitrescu, Bill Sommerfeld, Peter Oskolkov, 'Replacing HTB with EDT and BPF', Proceedings of Netdev 0x14, THE Technical Conference on Linux Networking, August 2020,https://legacy.netdevconf.info/0x14/pub/papers/55/0x14-paper55-talk-paper.pdf.