Flutter难点问题之GPU后台Crash
背景介绍
众所周知,在众多跨平台方案中,Flutter的渲染一致性一直是它的一大亮点,可谓是真正的实现了像素级别的控制。这主要归功于Flutter的架构设计,它基于Skia来实现渲染,而后者则以OpenGLES、Metal或Vulkan作为后端,这在最大程度上保证了不同平台的渲染一致性。Flutter的这个架构设计非常先进,当然,同其他项目一样,Flutter也不可避免的存在一些bug。今天我想和大家聊的,就是一个Flutter在iOS后台时访问GPU导致Crash的问题。本文将先对GPU后台Crash发生的原因进行说明,再介绍官方对此问题的修复方案,最后分享闲鱼在此基础上如何在其他三个场景解决该问题。
闲鱼App在使用Flutter开发项目的过程中,发现了一个与Flutter相关的iOS Crash,这个Crash的具体堆栈如下:

根据堆栈中的_gpus_ReturnNotPermittedKillClient可知,App是因为在后台访问了GPU导致了Crash,或许有些同学不太明白,为什么App在后台访问GPU会导致Crash呢?这其实是和iOS系统的策略有关。iOS系统是禁止后台的App访问GPU的,主要是为了保证前台正在运行的App的性能体验。因为GPU在系统看来是非常宝贵且有限的资源,如果App退到后台之后还继续疯狂使用GPU的话,那么前台App的性能可能就无法得到保障了。那么就有同学问了,如果App并没有遵循这个规范,在退到后台之后,继续使用Metal或OpenGLES访问GPU,会发生什么事情呢?答案很简单,会直接Crash。
由于Flutter使用了Skia作为渲染引擎,而后者在iOS则以Metal或OpenGLES作为后端,因此免不了要和GPU打交道,而在LayerTree光栅化上屏或者图片解码上传纹理时,都会使用到GPU,因此如果没有做好相应的保护措施的话,App就有可能Crash。
官方的修复方案
Flutter应用日益增多,开发者们慢慢发现了这个问题,并向官方提了相应的Issue。陆陆续续有开发者向Flutter官方反馈GPU后台Crash的问题,这引起了官方的注意,官方决定跟踪和解决这个问题。那么这个问题该如何解决呢?解决这个问题的关键,就是在收到UIApplicationDidEnterBackgroundNotification这个通知后,不要再执行任何可能会访问到GPU的操作。但是这个通知是在主线程收到的,而真正去访问GPU的则是Raster线程或IO线程,那么该如何通知它们呢?为此,Google软件工程师Aaron Clarke(github名为gaaclarke)设计了一个新的同步机制: SyncSwitch。SyncSwitch简单来说就是可以在一个线程去设置一个类型为bool的value,另一个线程的代码分为两个分支,根据value的值来确定具体走哪个分支。我们先来看看SyncSwitch是如何设计与实现的,以下是SyncSwitch的构造函数和两个API:

当iOS的前后台状态发生改变时,可以通过SetSwitch来设置value来表示GPU是否可用。而逻辑需要根据iOS在前台或者在后台走不同分支时,则调用Execute方法来走对应的逻辑。以下是作为Execute方法参数的结构体Handlers的代码:

以下是上述方法的具体实现,我们可以看到逻辑比较简单,主要就是在 SetSwitch和Execude时加锁,然后根据value值去调用true_handler或者false_handler。

最终官方通过这个方案,成功修复了ImageDecoder::UploadRasterImage导致的GPU后台Crash,具体代码如下:

这是官方关于用于修复这个问题的PR: #13908 Made a way to turn off the OpenGL operations on the IO thread for backgrounded apps[1]
当然,这个过程也不是一帆风顺的,在这个过程中,也遇到了一些问题,但是gaaclarke都顺利解决了。
问题的进一步解决
闲鱼将Flutter引擎升级并将官方最新的修复Patch打上以后,发现依然存在GPU后台Crash,这说明GPU后台Crash的问题并没有完全解决,难道是官方的解决方案还存在什么疏漏吗?我仔细分析了闲鱼发生GPU后台Crash的堆栈后,确认问题一共分布在3个地方,MultipleFrameCodec、EncodeImage以及DrawToSurface,而之前大家反馈的ImageDecoder则并未出现。所以可以确定的是,官方的解决方案并没有问题,只是并没有覆盖全面。而闲鱼由于业务体量大,场景复杂,再加上大规模使用Flutter,所以这些问题都都被一一暴露了出来。既然问题原因已经确认,那么让我们来看下如何修复吧。
MultipleFrameCodec::getNextFrame场景的Crash
在闲鱼遇到的3个GPU后台Crash中,MultipleFrameCodec::getNextFrame引起的占比是最高的,因此我决定先从这个问题下手。我们先来看一下问题的堆栈信息,来分析一下Crash具体是如何发生的。
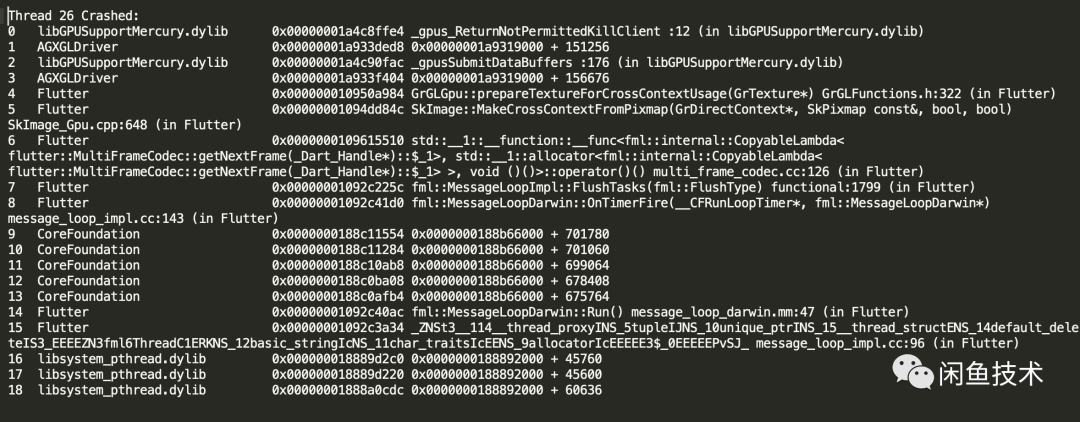
根据堆栈可知,在发生Crash时,Flutter调用了SkImage::MakeCrossContextFromPixmap来生成一个基于texture的SkImage,该方法与问题相关的逻辑如下:

我们看到,在生成SkImage之前,会先调用了GrGpu::prepareTextureForCrossContextUsage来获取一个GrSemaphore,那么这个方法具体是什么用的呢,我们先来看看官方的文档注释:

根据文档注释可以看到,这个方法主要是为了让保障texture能够在多个context下安全使用。根据具体的后端实现,这个方法可能会返回一个GrSemaphore用于同步。接下来看看使用OpenGLES的情况下这个方法是如何实现的吧。

我们注意到,这个方法会创建一个GrGLSync,并且会调用一次flush来确保GrGLSync对象已经创建并且发送到了gpu。这个flush方法会去调用OpenGLES的APIglFlush,如果此时应用正处于后台,那么调用glFlush会导致应用直接崩溃。
上面我们分析了OpenGLES的实现,那么在Metal下是否也存在GPU后台Crash呢?答案是肯定的,Metal也有这方面的限制,我们在flutter issue里找到了一个与上面相似的堆栈。

既然已经找到问题的原因了,那么我们来看看如何修复吧。先来看一下MultipleFrameCodec::getNextFrame方法与之相关的逻辑,逻辑还是比较清晰的,如果有resourceContext,则使用SkImage::MakeCrossContextFromPixmap来生成SkImage,否则则使用SkImage::MakeFromBitmap来生成。

那么该如何修复这个问题呢,相信细心的读者可能已经想到了解决方法,可以使用gpu_disable_sync_switch来确保只有在GPU可用时才会调用SkImage::MakeCrossContextFromPixmap生成SkImage,而如果GPU不可用,则回退到调用SkImage::MakeFromBitmap生成SkImage。
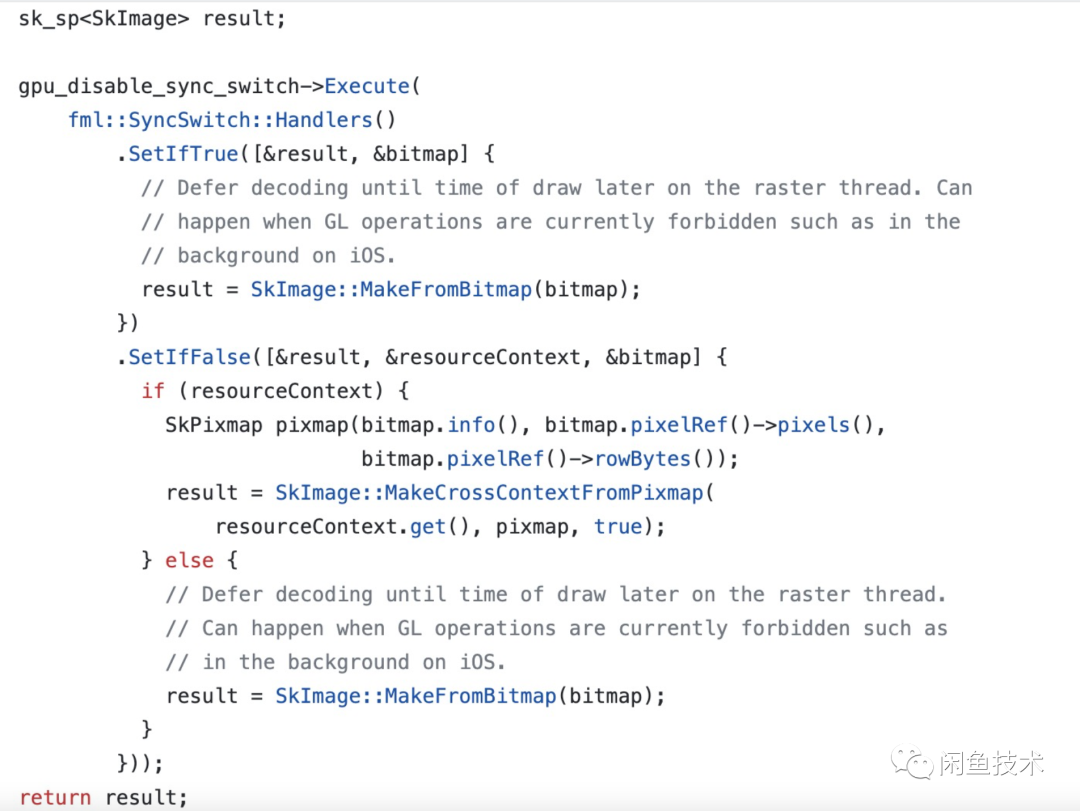
有了这个方案后,那么只需要稍加修改代码,功能也就实现了。当然,为了确保功能正确以及后续不会因为其他改动而导致不可用,我们还需要写一个单元测试。最终的PR如下:
#28159 Prevent app from accessing the GPU in the background in MultiFrameCodec[2]
gaaclarke在review了这个PR之后给予了肯定,目前这个PR已经成功合入到了master。

EncodeImage场景的Crash
第二个发生Crash的场景是在EncodeImage的时候,具体堆栈如下

根据这个堆栈,我很快就定位到了场景,这是在image_encoding.cc中的EncodeImage方法未使用is_gpu_disabled_sync_switch导致的Crash,具体代码如下:

有了上一次的经验,我很快在这个基础上加上is_gpu_disabled_sync_switch的逻辑,这部分代码比较简单,就不贴了。定位问题和修改问题可以说都很顺利,但是如何去写单元测试则让我犯了难。我修改的ConvertToRasterUsingResourceContext是一个内部方法,写单元测试时访问不到,另外即使将这个方法暴露出来,我们也没有办法传入一个flutter::SyncSwitch来用于测试,原因是flutter::SyncSwitch内部并没有属性来判断它自己是否被访问过。由于写不出单元测试,所以我只好向flutter官方的同学求助。
gaaclarke非常热心地给了我一个方案,让我将ConvertToRasterUsingResourceContext放到头文件,并改成模板,这样单元测试里不用传入flutter::SyncSwitch,只需要传入另一个Mock的其它类型的SyncSwitch就行。

我尝试了这个他给的这个方案,觉得改动有点大,在当时的我看来,单元测试的作用是为了保证自己的功能不被意外回滚。而我觉得这个PR被回滚的概率很小,因此我想着是不是可以和官方同学商量一下,不用写测试。
官方同学给我的回复让我对单元测试有了新的认知。gaaclarke觉得一个不完美的测试也比没有测试要好,而zanderso则给出了另一个理由,所有能被cherry-pick到beta或stable分支的功能都需要有单元测试,如果一个功能没有单元测试,那么即使有需要,它也不可能被cherry-pick到beta或stable分支。
他们的回复让我更加明白了单元测试的重要性,但是我当时觉得gaaclarke给的方案改动有点大,所以想了一个新方案,使用FLUTTER_RELEASE这个宏来做条件编译,在非release模式下为SyncSwitch增加逻辑使得其可以知道它是否被调用过,这样可以尽量少改动具体实现来做单元测试。但是这个方案最终没有被gaaclarke采纳,他觉得条件编译使得维护变得复杂,并不是一个好方案。
所以最终我还是按照gaaclarke的建议实现了最终版本的单元测试,同时也向gaaclarke表达了我自己的担忧。这个方案将原本无需暴露的头文件都暴露到了image_encoding.h中,gaaclarke给了我一个建议,可以增加一个image_encoding_impl.h来解决这个问题,这的确是个好主意。
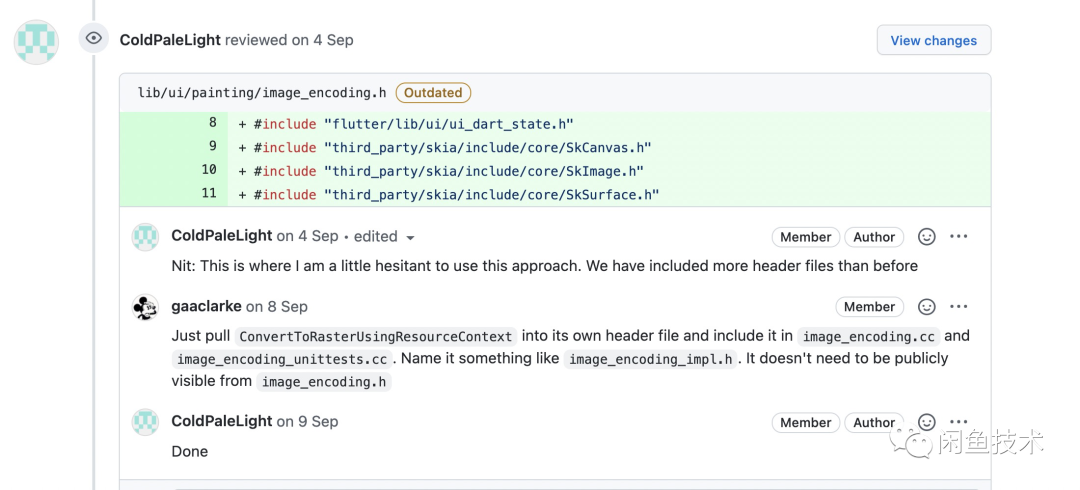
#28369 Prevent app from accessing the GPU in the background in EncodeImage[3]
整个过程和结果得到了gaaclarke的认可,他对此表示赞许以及感谢。

其实我觉得这个过程中,我从gaaclarke那边学到了非常多的东西,包括编码能力以及如何写好单元测试等等。
Rasterizer::DrawToSurface场景的Crash
这是闲鱼GPU后台Crash的最后一个场景,也是三个场景中最为棘手的一个,其堆栈如下:

从堆栈分析,问题非常清晰。我们需要确保Rasterizer::DrawToSurface方法不要在后台访问GPU。但是这个场景和之前场景却有着比较大的区别,之前的场景如果我们无法访问GPU,那么我们可以使用CPU来做兜底逻辑。但是在Rasterizer::DrawToSurface时无法访问GPU,那么应该怎么处理呢。
正在我还在苦恼如何来解决这个问题时,官方突然提了一个Issue:Crash in Metal from MTLReleaseAssertionFailure[4],我仔细看了一下堆栈,发现他们遇到的竟然和我遇到的是同一个问题!这个Issue的优先级是P2,还是非常紧急的,因为我决定尽我所能,和官方一起解决这个问题。
为了说清楚这个问题,我写了一段具体的分析过程[5],阐述了这个问题和之前遇到的GPU后台Crash是一类问题,所以我们需要在Rasterizer::DrawToSurface时,也使用is_gpu_disabled_sync_switch。那么如果当前无法访问GPU,该怎么做呢,我突然想到,DrawToSurface是为了让这一帧上屏,让用户能够看见。那么如果此时应用在后台,用户本来就看不见这一帧,那么我们为什么不直接将这一帧丢弃掉呢?这一帧丢掉会有问题吗,我仔细分析了一下,应该没有问题,因为当用户从后台回到前台时,Animator::Start会被调用,然后会调用RequestFrame去确保最新的一帧上屏。
为了能更快解决这个问题,我还提了一个PR,供官方作为解决问题的一个选择方案。gaaclarke在看了我的分析后,觉得有道理,不过他还是不太确定是不是应该在Rasterizer::DrawToSurface这么顶层的地方使用is_gpu_disabled_sync_switch。他觉得或许这个问题应该从Skia层解决更为合适。

而在经过一阵子调研后,gaaclarke决定采纳我的这个方案,最终经过几轮的讨论和改进,我和gaaclarke一起完成了这个PR,这个PR最终被合入了主干。
#28383 Started providing the GPU sync switch to Rasterizer.DrawToSurface()

总结
Flutter应用在后台访问GPU导致Crash的问题至此得到了圆满解决,相信不久的将来大家就能在Flutter release版本体验到。未来闲鱼团队会一如既往在Flutter上继续深耕,解决Flutter在落地过程中遇到的各种问题,给大家带来更好的用户体验。