分布式基石|最难 paxos 和最易 raft ?
坚持思考,就会很酷
什么是一致性协议?
注意,今天是大白话随便聊聊,目的是直白的了解 raft 是什么,不用太抠理论定义。
什么是一致性协议?
字面理解就是让某些东西保持一致的协议嘛。
什么是一致?
大白话就是内容完全相同呗。以存储场景举例,假设有三个磁盘文件,大小为 1M ,如果三个文件 1M 的数据都完全相同,那么这可以说这文件的数据是一致的。
一致性还分了不同的等级,如线性、因果、最终一致性等等,而且如果站在不同的系统层面来看,承诺的一致性也会有所不同。这些今天都不重要,重要的是我们知道了:一致性协议就是用来达到一致的协议呗。
有两个最出名的一致性协议:paxos 和 raft 。数学上已经严格证明了 paxos 的正确性,只要严格遵守它协议的约束,就能保证在分布式的恶劣环境下多副本数据的一致。我们来看一下吧!
paxos 协议
paxos 是 Leslie Lamport 大神于 1990 年提出的一致性协议。它解决的问题是一个分布式系统如何就某个值(决议)达成一致。
划重点:paxos 协议本质是确定一个值。
论文《The part-time parliarment》提到的 paxos 里面有两个重要角色:
- Proposer:提议发起者
- Acceptor:提议接受者
它们的操作对象就是:提议( Proposal ) = 提议的值 + 提议编号。里面有三大"定律",满足这三大约束条件,那么就能保证一致性:
第一定律:每轮的投票编号唯一;
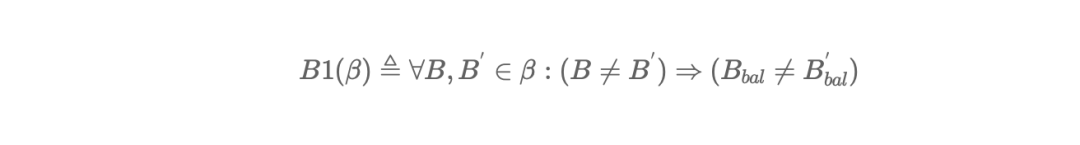
第二定律:投票满足多数才算成功(并且如果任意两次投票都存在多数派,则多数派的交集不为空);
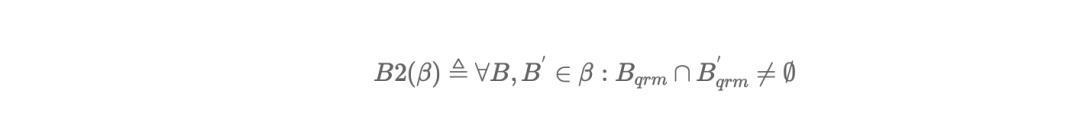
第三定律:如果一轮编号为 Bbal 的投票,多数派中任意一位成员曾投过 Bbal 编号小的票(B'),那么 Bdec == B'dec;
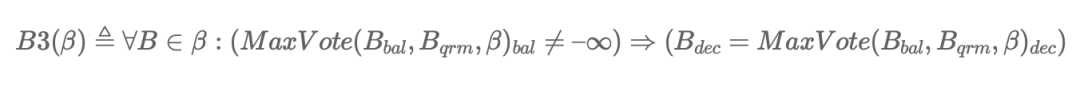
上面就是 paxos 最核心的内容,但是说实话,每一个字都看得懂,但是连起来就不知道啥意思?
paxos 到底能做啥?这个我们存储系统有啥关系?它为啥那么难懂?
paxos 难就难在于它没告诉大家,这个东西能用来做啥,映射不到现实,就无法产生共鸣。
我们先接受一个事实:paxos 的本质是确定一个值,且一旦这个值确定之后,后续无论怎么投票,无论发生什么,这个值保持不变。
那我就比以前更懵逼了!怎么越说越糊涂了了,说好的做一个分布式存储服务吗?存储服务应该允许可以写入任何数据,且可以 Update 的嘛。
确定一个不能变的值有啥用?
paxos 的工程化
我们下面尝试将 paxos 工程化,将它具现化到现实的工程实现。
1 确定一个值,有啥用?
回到最开始的问题,确定一个值对我们有啥用?
我们来简要发散下 paxos 工程化的思路。
paxos 本质:确定一个值,现在把这里面参与的角色打包起来,Proposer,Acceptor,Proposal 等等组成的抽象的集合:paxos instance,称为 paxos 实例:

划重点:每个实例必须是完全独立,投票互不干涉,即可。
一个 instance 确定一个值,多个 instance 确定多个值。
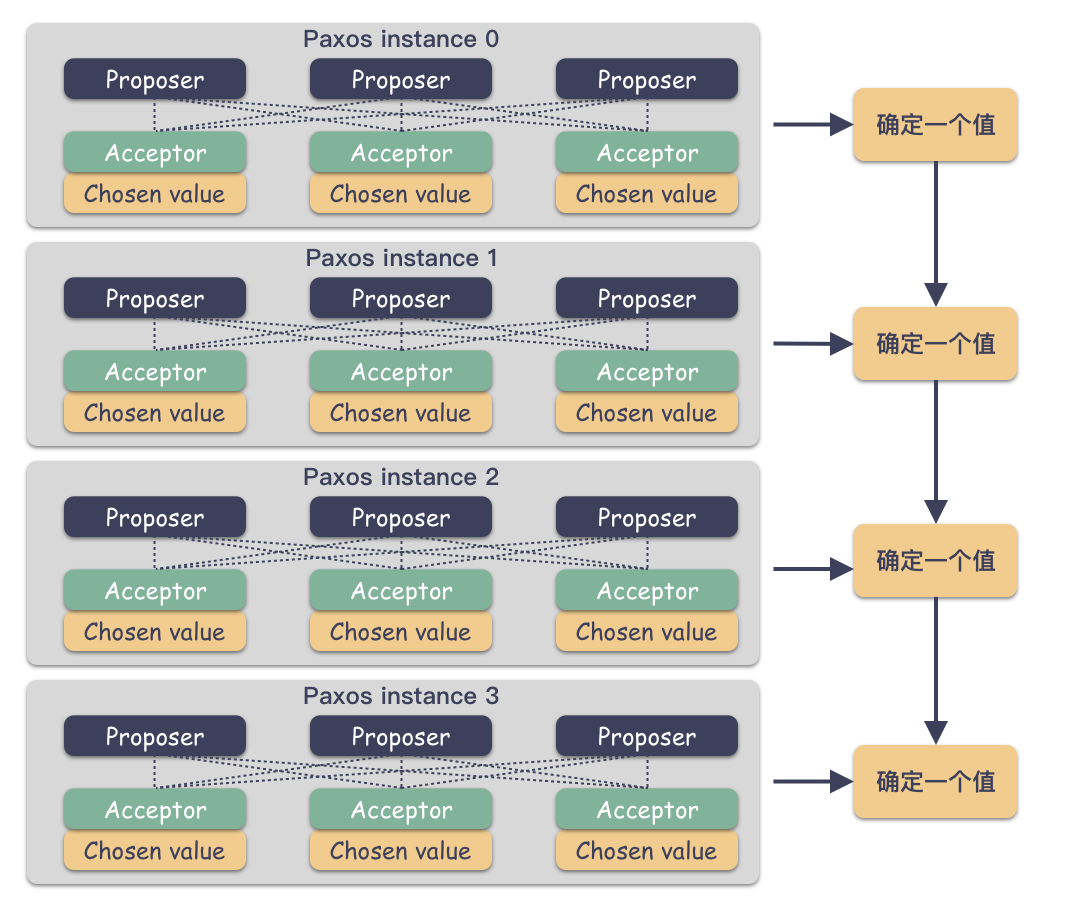
这些值不断的被确定(永不更改),形成了一个值序列,这有啥用?
2 确定多个值有啥用?
接着上面,我们现在有了一系列永远无法被修改了值序列,有啥用?存储服务的基本特点是允许存储任何数据,并且能够增删改。
哪还有啥用?
这一个个值序列像不像一个东西:日志!
这个跟 rocksdbdb,leveldb 的 wal 日志是不是差不多意思了?
我们应用这些日志就能得到一致性的输出。所以我们还缺个啥?
状态机嘛。
3 加个状态机就起飞了
什么是状态机?
状态机全称为有限状态机。它接收条件的触发,由一种状态转变为新的状态。初始状态相同,输入的一系列事件相同,那么它最终的状态一定相同。
这可太常见了,比如 rocksdb,leveldb 等等 lsm 存储,它们数据先写 append log ,通过重放日志到达的系统状态一定是一致的。
这种状态机的应用模式可不仅限于存储服务。
到这,我相信童鞋们已经很豁然开朗了,只要我们通过 paxos 来产生分布式一致的有序的操作日志,加上状态机的配合,实现一个分布式存储服务必然不是问题。
通过不停的确定一个个值,形成一个有序的操作系列,配合状态机的应用,这,就是 paxos 的工程化方向。
4 活锁的问题怎么解决?
对于 paxos 来说,Proposer 和 Acceptor 角色是可以重叠的,每个节点既可以是 Proposer,也可以是 Acceptor ,或者两者都是。
这带来了非常大的灵活,每一个 Proposer 都可以递交协议(写入数据),但由于最终只能确定一个值,那么这会导致非常多的无效功,这期间是使用类似乐观锁来解决那些冲突的提议。
比如说,A 刚递交一个提案,B 就递交一个新提案导致 A 的提案被否定了,然后 A 又迅速递交一个提案,形成了一种类似活锁的状态,这时间就浪费了呀。
怎么解决?
问题根因在于可以提案的点太多,大家都是平等的。那么统一声音才能解决这个问题。于是Leader 就应运而生。通过某种方法指定一个节点为 Leader ,只有一个节点能递交提案,这样就解决了混乱问题,效率提随之提升(这就是 Multi-Paxos )。
5 paxos 工程化小结
小结一下,如果要将一个 paxos 工程化落地,衍生了哪些东西:
- paxos 本质是确定一个值,把参与确定这个值的角色打包称为一组实例( paxos instance );2.不同实例之间决议互不干扰。多组 paxos 实例确定多个值,形成一组操作序列,也是就日志 ;
- 日志 + 状态机 可以成为任何有意义的工程系统;
- 为了解决递交提案混乱可能引发的效率问题(比如活锁),可以通过指定 Leader 角色来解决;
慢着,这个工程化方向咋这么眼熟呢?
这不就是 raft !
raft 协议
终于到了 raft 协议,raft 的论文开篇就是这么一段话:
Raft is a consensus algorithm for managing a replicated log. It produces a result equivalent to (multi-)Paxos, and it is as efficient as Paxos, but its structure is different from Paxos;
raft 证明和 paxos 等价,raft 是一种日志复制的一致性算法。
看懂了吗?raft 的着眼点就是 日志+状态机 的方向。
划重点:raft 天生就是 paxos 协议工程化的一种样子。
如下图:
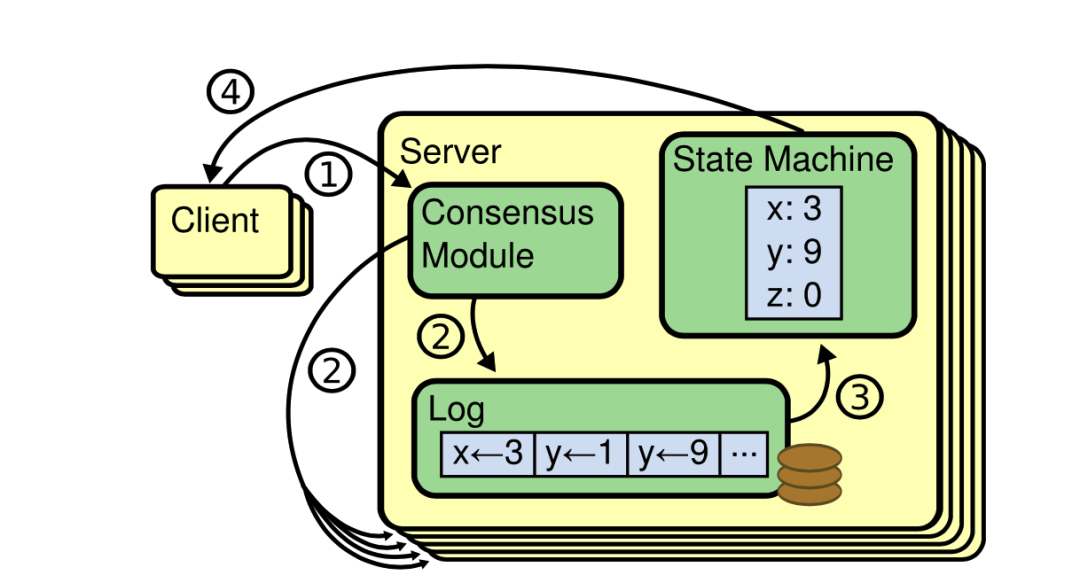
图里交代了关键模块:
- 客户端( Client ):就是用户嘛,写入数据的就是它喽;
- 一致性模块( Consensus Module ):负责写入 log,并且把 log 复制到其他节点;
- 状态机( State Machine ):输入 log ,推进变更系统状态;
raft 确实比 paxos 简单啊,因为它已经把实现程序交互的样子都画出来了。
在 raft 论文里面直接把几个因素交代清楚了:
- raft 就是管理日志复制的算法;
- 日志 + 状态机 就能落地一个一致性的系统应用;
- 集群角色有分类,Leader 作为唯一的写入点,所有日志复制是 Leader 到 Follower 单项传输;
说实话,上面的这些知识点都是我们对 paxos 工程化的长时间推导才想明白的。
没想到 raft 论文上来就给整好了,所以我才说,raft 协议出生就是为了解决工程化的问题的。
raft 把一致性归纳成三个核心问题:
- Leader 的选举;
- 日志的复制;
- 正确性的保证(约束条件);
其实真正要做的就两个,第三个问题贯穿前两个事情:
- 选出一个 Leader ;
- 把 Leader 的日志复制分发到 Follower 节点;
我们下面来看下这两个事情是怎么做的。
而用户则只好奇两个事情:
- 数据怎么读写?
- 节点扩缩容怎么搞?
1 Leader 选举
角色转变:
简单看下 raft 协议中关于 Leader 选举的部分。下面是角色转化图,非常清晰:
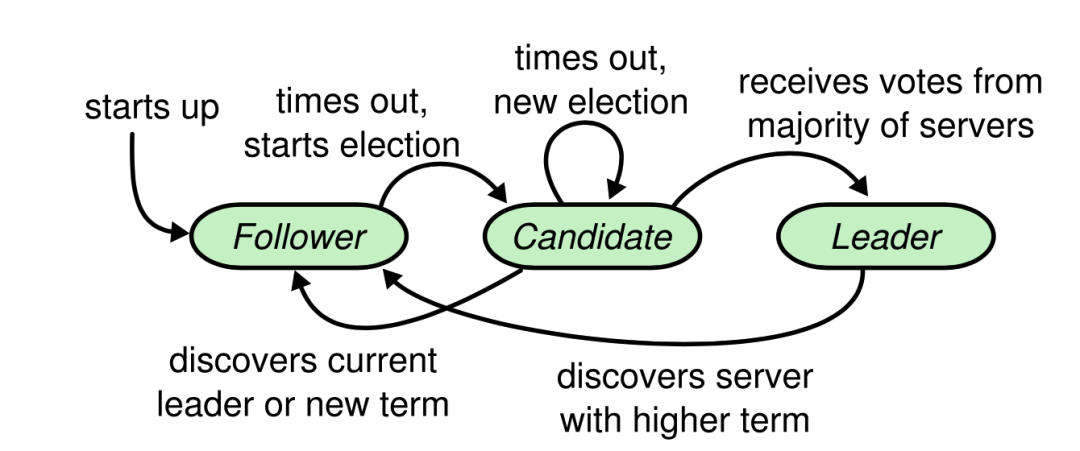
图里至少能得到这么几点知识点:
- 系统开始每个节点都是从 Follower 角色开始;
- 定时器超时之后,角色转变为 Candidate ,开始竞选 Leader;
- Candidate 如果获得多数人的支持,那么选举成功,角色转变为 Leader 。如果选举失败,那么退为 Follower ;
Leader 选举成功之后则可以对外提供服务。
在论文中,为了让选举更高效(避免类似活锁的场景),各个节点的定时器间隔是随机值。
服务时间线:
从时间线来看,可以分为两部分时间(如下图):
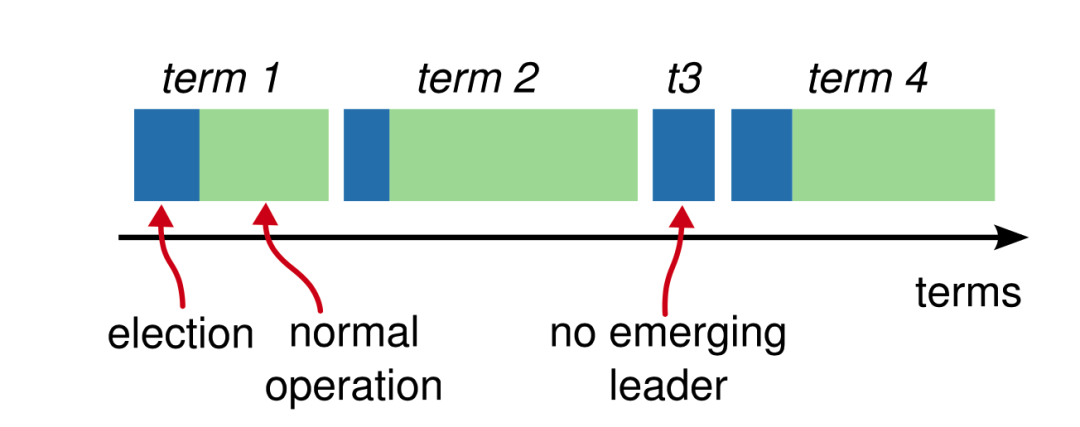
- 无 Leader 状态(选举中);
- 正常状态( Leader );
每个 Leader 都有自己的任期,注意:无 Leader 的状态是停服状态。
Leader 选举的规则?
被多数节点接受并且持久化的的日志叫做 committed log 。
说实话,Leader 选举的规则其实就一条:具备完备的 committed 的 log 数据即可。
那怎么才能选出具有完备数据的节点呢?
这就是 raft 协议里安全性的内容。投票发起者( Candidate )要告诉对方两个东西:
- 任期编号;
- 当前日志的最新位置;
其他节点( Follower )收到这两个信息会决定要投它一票,还是拒绝它?
划重点:做这个决定依赖于它的日志是不是比我新(全)。
那怎么判断谁更新(全)呢?
1 . 先比 term ,谁更大谁就新;
- 举个例子,Follower 节点保存的任期是 4,Candidate 发过来的是 3 ,这种就直接拒绝了;
2 . 如果任期相同,那么就比较 index ,index 谁更大就新;
- 举个例子,对面发过来的 index 是 7,我本地是的 8 ,那么就多说了,拒绝;
我们看一眼下图,我们知道 raft 的操作对象就是日志。在 raft 协议中,每个日志都有唯一的编号:index ,代表了它唯一的槽位。
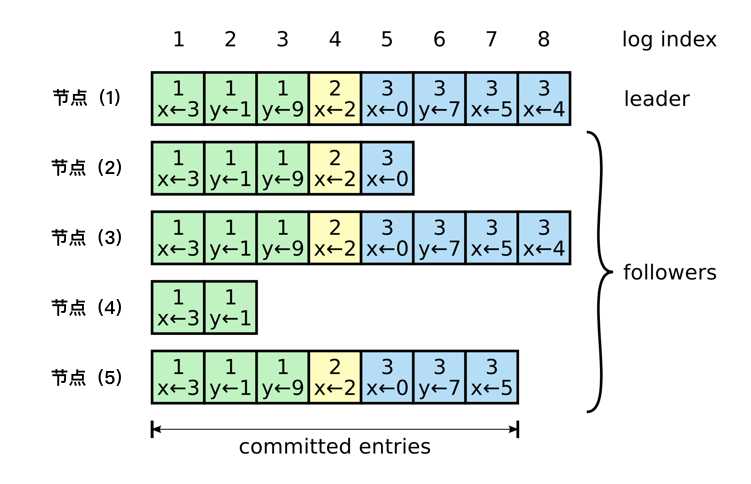
题外话:这里可以类比上面 paxos 章节说的 instance 概念。其实每一个日志槽位和其他模块对象结合其他就是单独的 instance ,这一系列的日志对象就类似于 paxos 多实例 instance 确定的值。
每个 index 槽位代表的值一旦确定将永不更改,它们的确认不相互影响。
从完备的数据来看 committed 的位置在 index:7 这个位置。那么第一个节点、第三个节点、第五个节点都具备完备的数据,但是按照协议跑起来,只有第一个节点和第三个节点才有可能会成为 Leader 。因为它们两个节点有最新的数据(虽然是没有 commited 的),第五个节点找它们投票的时候,会被拒绝(它虽然有完备的数据,但是不够新)。
2 日志复制
日志复制有几个特点:
- 日志传输为单向传输,Leader 到 Follower ;
- Leader 永远不会改写或者删除自己的日志,永远只做 Append ;
- 日志内容一切以 Leader 为主,哪怕是强制覆盖 ;
和 paxos 类似,每个日志槽位的值一旦确定就无法更改,无论怎么投票,怎么运转,这个值不再变更。raft 就这样连续的确定值就能形成一个的日志序列,给到状态机使用。
这里类比 paxos 的 instance ,其实我们只需要保证每个槽位的投票和数据的独立就和 instance 的是一个效果。
以这个图为例,在不切主的情况下,数据从节点(1)向其他节点发送,补齐数据。
经过状态机应用,所有的节点最终系统状态一致:
- x = 4
- y = 7
思考一个问题:如果用户写失败了,系统提供了什么结果语义?
划重点:未定义。有可能写入了,有可能没写入。这种场景只能依赖于用户重试。标准的存储服务写失败语义。
还是以上图举例,就拿 index:8 这个位置的写入来说,用户从节点(1)写入数据 x=4。
场景一:这个时候只把日志成功复制到节点(3)就挂了。用户那边自然是失败的。节点(1)恢复后,还是又成为了 Leader ,由于 leader 永远不会删改日志,所以最终还是会把 index 的日志复制到其他节点,等复制完之后,满足 quroum 系统状态就变了就变成 x=4 了。
场景二:一条日志没写入,那么系统状态就还是 x=5 ;
所以,用户写入失败的场景,一定要依赖重试。不能对结果假定。这种假定在存储系统中通用。
关于 raft 日志复制,有个规则不得不提:Leader 永远不能 commit 非自己任期的日志。哪怕已经满足 quorum 。
为什么会有这个限定 ?
看一个 raft 论文中的简单的例子:
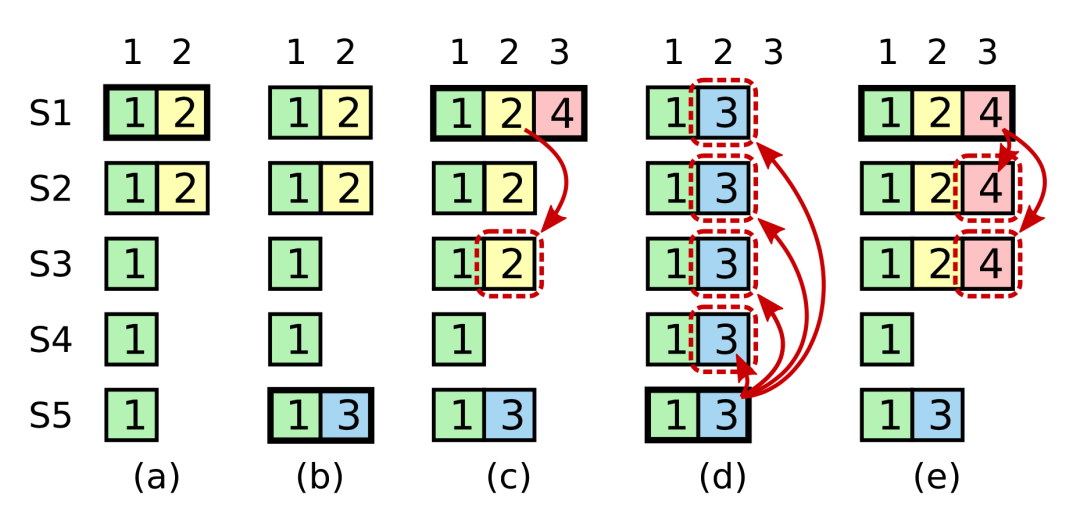
这是一个时间序列,从 a -> b -> c -> d -> e :
- a 时刻:Leader 为 S1( 黑框的为 Leader ),它有着最新的日志 index:2 ,虽然最新的 index:2 并没有 committed(复制到多数),只复制到了 S2 ;
- b 时刻:S1 挂了,S5 被选举为 Leader ,任期为 3 ,并且 Client 还递交了一个写入;
- c 时刻:S5 挂了,S1 被重新选举为 Leader ,任期为 4,这个时候它复制日志,把 index:2 的日志复制给了 S1,S2,S3 ,这是满足了 quorum (但注意了,这个系统千万不能认为 commit 了,且往后看)。并且 Client 还递交了一个写入在 index:3 的位置;
- d 时刻:S1 挂了,S5 被重新选举为 Leader(S2,S3,S4 都会投票),于是把 index:2 的日志强制覆盖到所有节点;
- e 时刻:这个时刻是一种假设,假设说,S1 在 c 时刻的时候在挂掉之前把任期 4,index:3 的日志复制到多数节点,那结果又不一样了。这种场景系统可以认为 index:3 被 commit 了,index:2 则是被间接 commit 了;
看到了吗?
为什么在 c 时刻一直强调,不要认为 index:2 满足了 quorum 就认为是 committed 的日志,然后就去 apply 。因为你一旦这样做了,d 时刻的场景发生之后,index:2 的日志是被修改了。
这就导致 index:2 两次 commit 了不同的 log !这就违背了一个槽位确定一个值,永不更改的承诺。
这绝对不行。
怎么办?
解决很简单,上面已经讲了,在 c 时刻这种场景,就算 index:2 被复制到多数,满足了 quorum 也不能认为是 committed ( 没有 commit 自然就不能 apply ),Leader 只能 commit 自己任期的日志。前面的日志将被间接的递交。
再谈谈 e 时刻为什么把 index:3 的日志复制到多数之后,就可以认为 index:2 被 commit 了?
因为,这样做了之后,将不可能出现 d 时刻的场景。因为 S5 的任期只有 3 !它将不可能成为 Leader 。
题外话:etcd 在每次选举出 Leader 的第一件事就是广播一条空白消息,原因就在这里。目的是为了间接 commit 掉前任的日志。
3 状态机
这部分其实是最简单的,状态机做的事情我们叫做 apply 。apply 的内容则是各个业务自行解释,举个例子,如下的日志,这是一个典型的 kv 系统的样子:
日志 apply 完之后,系统状态为:
x = 4
y = 7划重点:日志里面的内容由业务自行解释,raft 只保证日志复制是完全一致的。
4 Propose 递交
用户的入口就是从递交 Propose 开始,由 Leader 接收用户请求,然后封装成日志的样子,经过了 commit( 确定这个值 )之后就能对外承诺。
思考一个小问题:集群只有一个 Leader ,如果请求发给了 Follower 呢?难不成 Client 还要专门记录谁是 Leader ?
也没关系,Follower 可以透明转发给 Leader 。Leader 处理好之后,回应即可。
划重点:还是那句话,只由 Leader 来发起,就算发给了 Follower ,请求也会转发 Leader。
5 成员变更
成员变更一般分为两种场景:
- 单节点变更
- 多节点变更
场景一:单节点变更
这是绝对安全的,因为它不会直接影响 Leader 的地位。这种的处理也简单。把集群变更的消息作为一条日志广播到集群,被集群 commit 之后,就可以直接 apply 新配置了。
划重点:集群变更也可以作为日志消息。 还是那句话,日志里面的内容可以是任何东西,业务自行解释。raft 只保证它的一致即可。
举个栗子:
原始集群 (S1,S2,S3),现在扩容一台 S4 ,只需要封装一条 < add S4 > 这样的日志消息,广播到集群里就可以,等这条消息 commit 了,就可以变更配置了。
场景二:多节点变更
多节点的配置则不能这样做,为什么?
因为怕一次性来的人太多,直接威胁到原有 Leader 的权威。如下:
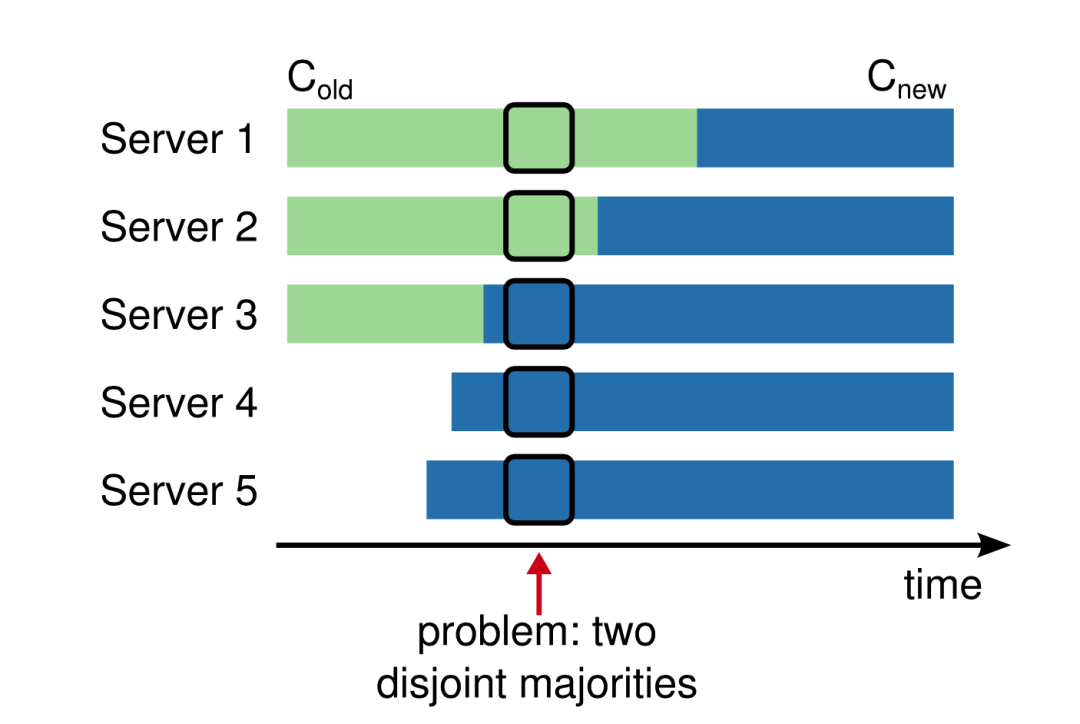
比如说,原有集群 ( S1,S3,S3 ),一次性来了两个 ( S4,S5 ),这就可能导致某个时刻出现两个 Leader 的情况:
- S1,S2 认为 S1 是 Leader,在原有 3 节点的集群中,满足多数,合法 ;
- S3,S4,S5 认为 S3 是 Leader ,在新的 5 节点集群中满足多数,合法;
那这可不行,这不就脑裂了嘛。一个集群只能有一个 Leader ,不然就会出现数据混乱的情况。
那怎么解决这个问题呢?
通用的做法是 joint consensus 算法。其实这个算法很简单,就是加一个中间过程,集群配置搞成两阶段切换,过程中要满足新集群和老集群的同时的 quorum 投票。
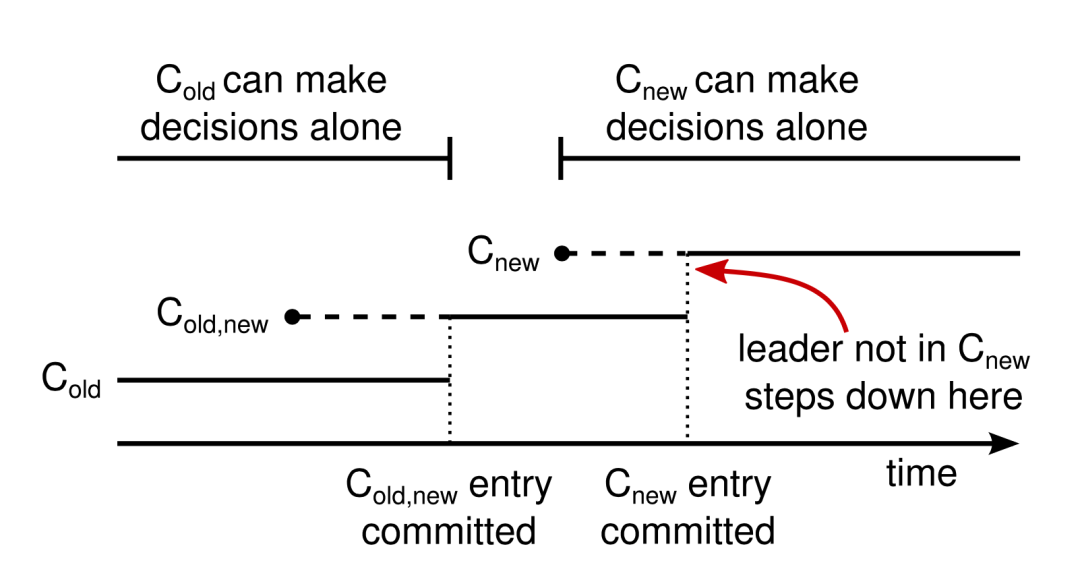
这个图怎么看不懂?我举个栗子:
-
最开始集群配置( S1,S2,S3 ),我们暂且叫做 C_old ;
-
递交两条集群变更的日志,Add S4,Add S5 ,Leader 向所有 S1,S2,S3 广播日志;
-
所有节点( S1,S2,S3 )收到这两条日志,则代表这两条日志被 commit 了,于是 apply 这两条日志,apply 的行为:集群配置变更为( S1,S2,S3,S4,S5 )&( S1,S2,S3 ),俗称 C_old,new ;
-
在 etcd 中,对应 enter joint 的操作;
-
开始递交一个切换配置的日志消息( etcd 里面叫做 ConfChangeV2 ),并且广播这条配置;
-
所有节点( S1,S2,S3,S4,S5 )收到这条日志则代表这条日志被 commit,于是可以 apply 这条日志,apply 的行为:集群配置变更为( S1,S2,S3,S4,S5 ),这个配置就是 C_new,至此,配置变更结束;
重点提一下:在 C_old,C_new 阶段如果收到写请求,需要满足两份配置的 quorum 同意才能 commit 。
这样就解决了双 Leader 的问题。
总结
- paxos 协议的本质是确定一个值,不同的 instance 确定多个值就成了日志序列;
- 日志 + 状态机就能实现任何系统,存储服务只是其一;
- raft 协议和 paxos 等价,它天然就是 paxos 工程化的一种样子;
- Leader 选举,日志复制,Leader 的安全性约束是 raft 的三大核心问题;
- raft 的日志里面可以是任何内容,里面的含义由业务 apply 的时候自行解析;
- raft 单节点变更可以随意搞,多节点变更需要用 joint consensus 算法走两阶段变更,才能防止多 Leader 的脑裂情况;