启动理论部分(整理版)
MIX
最近整理前面所有操作系统的文章,想着做成一个集合,首先就是启动部分,要想捋清启动部分,零碎的知识点很多,本文将前面所写的杂糅在一起,修改了一些有误的,添了些新的东西,写成了本文。因知识点的确很多,涉及了各个方面,我就没向其他文章一样前后各节之间的联系较深,而是直接以干货的形式罗列出来,这样或许更清晰些,不多说了来看
内存低 1M 布局
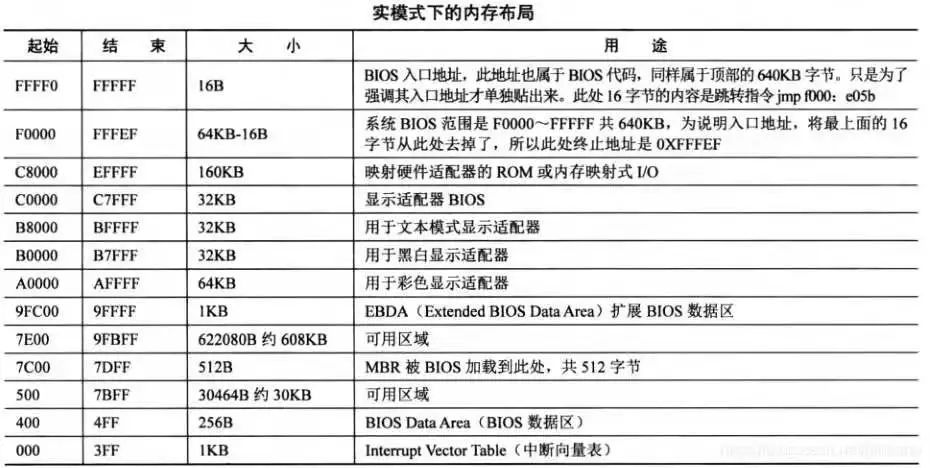
对于这个图要有个简单了解,一般来说 0~640KB 这部分叫做基本内存。其中这几个部分后面会用到需要重点关注下:
- 处的 BIOS 程序入口地址
- 用于文本模式的显示适配器
- 作为 EBDA(扩展 BIOS 数据区),这里可能存在 Floating Pointer Structure,它会指向 MP Configuration Table,这个表里面有我们需要的处理器信息,主要就是处理器的个数,以及 APIC ID
- ,MBR 被加载到此处运行
- 下面一部分可用区域在 xv6 里面被当作临时栈
- 之间的空闲区域 xv6 拿来放置 APs 的启动程序,以及内核 elf 文件,AP 意思是 Application Processor,对应还有个 BSP,Bootstrap Processor,BSP 先启动,APs 后启动,详情见后。
主要就是关注这几部分,看不懂没关系,后面会慢慢展开详细说明,这里只是过过眼。
物理内存与物理地址空间
上述所讨论的内存都是物理内存,所看到的地址都是实际的物理地址。计算机中的内存靠地址总线进行访问,地址总线能够寻址到的空间就叫做物理地址空间。我们平常聊天讨论的物理内存可能指的是内存条的大小,但是实际在计算机里面物理内存并不单单指的是内存条里面的内存,还有外设的一些内存,比如 BIOS 所在的 ROM,显存,还有一些外设的寄存器映射到内存。
这些等等都是使用地址线寻址,都是物理内存的一部分。32 位的地址总线寻址空间为 4G,假设计算机的内存条大于等于 4G,因为地址线分出去了一些去访问其他内存,所以内存条里面的内存不可能物尽其用。这也是电脑中显示的已安装的内存与实际买的内存大小不符的原因,总是会小上一点,不信右击此电脑点属性查看内存。
不过这一般是 32 位机子出现的情况,现在 64 位不会出现因为地址线分给了一些硬件而导致分给内存条不够的情况。那为什么现在 64 位机子也会出现内存条大小与显示的可用大小不同呢?就如这样:

实模式与保护模式
计算机只在刚启动的那一小会儿处于实模式,后面都初始保护模式
实模式
特点
- 地址总线只使用了 20 根,寻址范围为
- 寄存器只使用了 16 位,所以如果只用单一的寄存器来寻址的话只能访问到 的空间
- 分段,访问内存采用 段基址:段内偏移 的方式,实际地址为 段基址段内偏移,如此便用 16 位的寄存器访问到了 20 位的地址空间(乘以 16 相当于左移 4 位)
- 段寄存器里面存放的是段基址
缺点
- 程序引用的地址都是真实的物理地址,不安全,也不灵活
- 程序可随意修改自己的段基址,任意访问改变所有内存
- 访问超过 64KB 的内存便要修改段基址
- 只能使用 20 位地址线,最大可用内存只有 1M,远远不够使用
保护模式(32位)
特点
- 地址总线使用 32 位,寻址范围
- 通用寄存器、标志寄存器、指令指针寄存器扩展到了 32 位,段寄存器没变
- 仍然采用 段基址选择子:段内偏移 地址的访问策略,但引入了全局描述符表,由此间接安全的访问内存
- 段寄存器里面放的不再是段基址,而是选择子(可见部分),要从段描述符中(或者段寄存器的不可见的缓存部分)获取段基址
相对于实模式,基本上弥补了其缺点,便是保护模式的优点,再此便不细说了
全局描述符表 GDT
为了安全地进行内存访问,引入了全局描述符表,使得 段基址段内偏移 的访问策略从实模式下对物理地址的直接映射变为保护模式下对全局描述符表的间接映射。
在 x86 架构下,分段是必须的,访存策略始终都是 段基址选择子段内偏移,只是在实模式下段基址就在段寄存器,可直接获取。但是保护模式下获取段基址没那么容易,段寄存器里面存放的是段选择子(可见部分),需要根据段选择子去索引段描述符,从中获取段基址(段寄存器没缓存的话)。这期间可能还会有特权级检查等等,因为增加了段描述符这一层,所以安全,是为保护模式。
全局描述符表里面存放的是描述符,描述符也分多种,但格式上基本一样
段描述符

- 段基址,被分散到了三个部分,平坦模式下一般就是 0
- 段界限与 G 位,段界限表示一个段的边界扩展最值,也就是表示一个段最大能有多大。G 表示单位,0 表示 1B,1 表示 4KB。段界限这个数值和 G 这个单位两者一起才有意义,段界限共 20 位,故段的最大值要么是 1M 要么是 4G。
- P 位,Present,表示该段是否在内存中,若在 P 为 1,反之为 0
- DPL,Descriptor Privilege Level,描述符特权级,0 最高,3 最低
- S 位,为 0 表示系统段,为 1 表示代码段或者数据段。所谓系统段我理解的是有硬件支持的段或者说硬件运行所需要用到的段,比如说中断机制,中断来临时,硬件自动处理,但是我们需要提供中断服务程序,中断机制才能正常运行,这个中断服务程序所在段就可叫做系统段,也叫做中断门结构,各种门结构都是系统段。但其实这些 xv6 里都没使用,唯一使用了的系统段就是 TSS 段,这在进程一块会详细讲述。
- TYPE,顾名思义,段的类型,不同的段有不同的取值,后面遇到实际的段再说
段选择子

TI 为 0 表示全局描述符表 GDT,TI 为 1 表示局部描述符表 LDT,LDT 一般不用,这在进程那一块还会有所提及。
RPL,Request Privilege Level,请求特权级,同样有 4 个取值,0、1、2、3,主要拿来进行特权级检查,详情见后特权级部分
段级地址转换
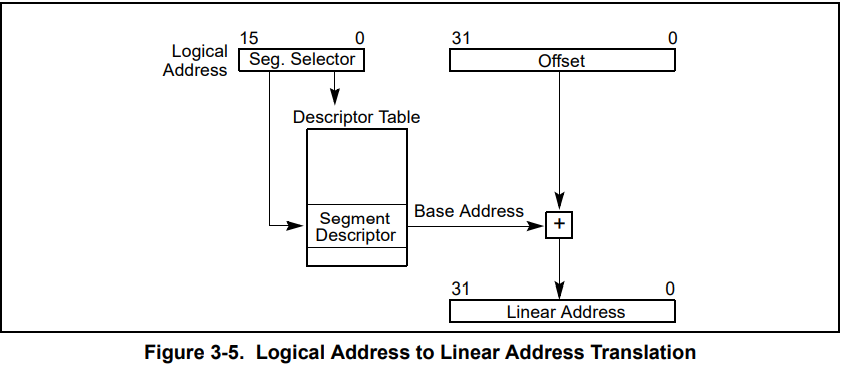
段寄存器
每个处理器有 6 个段寄存器有,CS 代码段,SS 栈段,DS 数据段,ES FS GS 附加数据段,xv6 里只用到了前 4 个段寄存器,FS GS 没有使用
实模式下,段寄存器里面的存放的是段基址,保护模式下,段寄存器里面存放的是段选择子。当然这只是可见部分,段寄存器还有不可见部分作为段描述符的缓存

要访问一个内存段的时候,这个段的段选择子必须加载到某段寄存器,所以一个系统虽然可以定义上千个段,但是当前使用的段最多就只有 6 个。当然这只是单个处理器,每个处理器都有 6 个段寄存器,有各自的 GDT,有各自定义的内存段。
控制寄存器
每个处理器有 5 个控制寄存器,每个寄存器 32 位

-
CR0
-
PE 位,Protection Enable,置 1 表示保护模式,0 表示在实模式下
-
PG 位,Paging,置 1 表示使用分页机制,0 反之
-
CR2,发生缺页异常的时候,CR2 里面就会存放引发缺页的那个地址
-
CR3,存放页目录的地址(物理地址)
-
CR4
-
PSE 位,Page Size Extensions,置 1 表示页面大小扩展为 4M,配合页目录项 PS 位使用
特权级
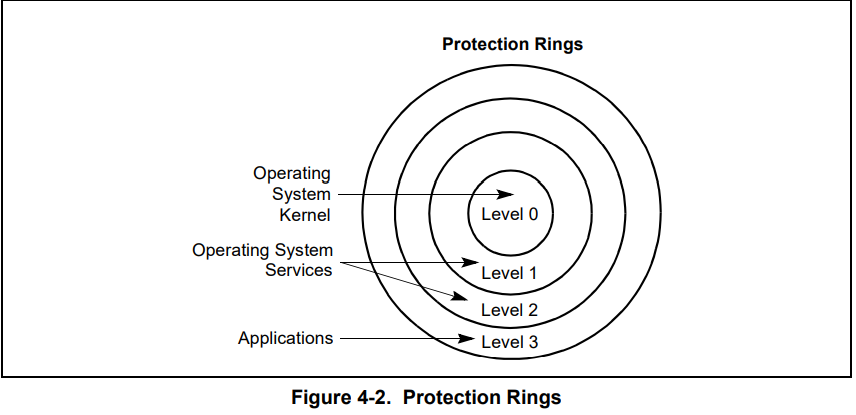
DPL,Descriptor Privilege Level,描述符特权级,为描述符的 DPL 位域
RPL,Request Privilege Level,请求特权级,为选择子的 RPL 位域
CPL,Current Privilege Level,当前特权级,为 CS 段寄存器不可见部分的 bit0 bit1,这里注意不是段寄存器里面选择子部分的 RPL 位域。所以 CPL 的值其实是当前正在执行的代码段描述符的 DPL 位域值。
这是数值上的关系,要清楚实际的特权级大小是与数值相反的。
进入保护模式
进入保护模式分三步:
- 打开 A20
- 构建加载 GDT
- 设置 CR0 的 PE 位
打开A20
地址线的编号从 0 开始,实模式下只用了其中 20 根即 A0~A19,这是因为 A20Gate 的存在,它可以控制 A20 地址线的有效性,而实模式下是将 A20 关闭了的。因此只要打开 A20 便可突破 1M的局限性,访问更大的内存空间。
A20Gate 由键盘控制器(i8042芯片)控制,虽然由键盘控制器控制,但实际上与键盘并没有什么关系,这是早期 IBM 利用键盘控制器上剩余的输出线来对 A20 管理控制,物尽其用嘛
打开 A20 一般有三种方法:
- 利用键盘控制器
- 通过 BIOS 中断
- 通过系统端口 0x92
这里就不细说了,后面 xv6 会讲述利用键盘控制器打开 A20
构建加载GDT
GDT 是硬件支持的一个数据结构,专门有个寄存器 GDTR 指示 GDT 的起始位置和大小,GDT 的位置信息加载到 GDTR 之后,CPU 才知道 GDT 在哪。

加载 GDT 有专门的指令,lgdt m16&32,GDT 构建好之后,使用 lgdt 指令将其位置信息加载到 GDTR 寄存器便完成了加载 GDT 的过程
注:GDTR 里面存放的是线性地址,即经过段级转换后的地址,GDT 里面的描述符作用之一存放段基址,用作段级地址转化。如果它本身的位置是个未转化的逻辑地址,那要寻找 GDT 的时候谁又来转化这个地址呢,岂不“无限递归”了?
将CR0寄存器PE位置1
将 CR0 寄存器 PE 位置 1,表进入保护模式
分页机制
x86 结构下分段是必须的,分页不是必须的,GDTR GDT 段寄存器等等这些硬件设施和数据结构就是拿来段式管理的。很多朋友认为分段有很多弊端,所以没使用分段,这是错误的。x86 的分段是刻在骨子里的,访存始终采用 段基址选择子段内偏移 的策略,只是保护模式下段基址需要通过段选择子来转化,这页也是地址转换的第一个步骤:段级地址转换。
回到分页上来,分页的本质就是将各种大小不同的内存段拆分成大小相同的内存块(通常4KB),以便进行内存管理的一种机制。
在纯分段情况下会出现许多问题,如应用程序过多,或者内存碎片过多而无法容纳新进程;又或者重新加载某内存段(之前交换出去的)时,找不到合适的内存区域。
造成这情况的原因:只分段的情况下,线性地址就是物理地址,两者都是连续的,不够灵活,不可能每次都能找到合适的内存区域。而分页的话,线性地址需要进一步转化为物理地址,线性地址是连续的,但是物理地址可以不连续。
这意味着可以在物理内存上随便(不是真随便,有块大小限制)找块地,只要线性地址和物理地址建立起映射关系就好。这样的话寻找合适的内存区域时就很灵活,解决了上述问题。
一级页表与多级页表
页级地址转换
一级页表与多级页表的优缺点是经常讨论的一个问题,这里多级页表我就拿二级页表来举例。首先来看两者的页级地址翻译过程:
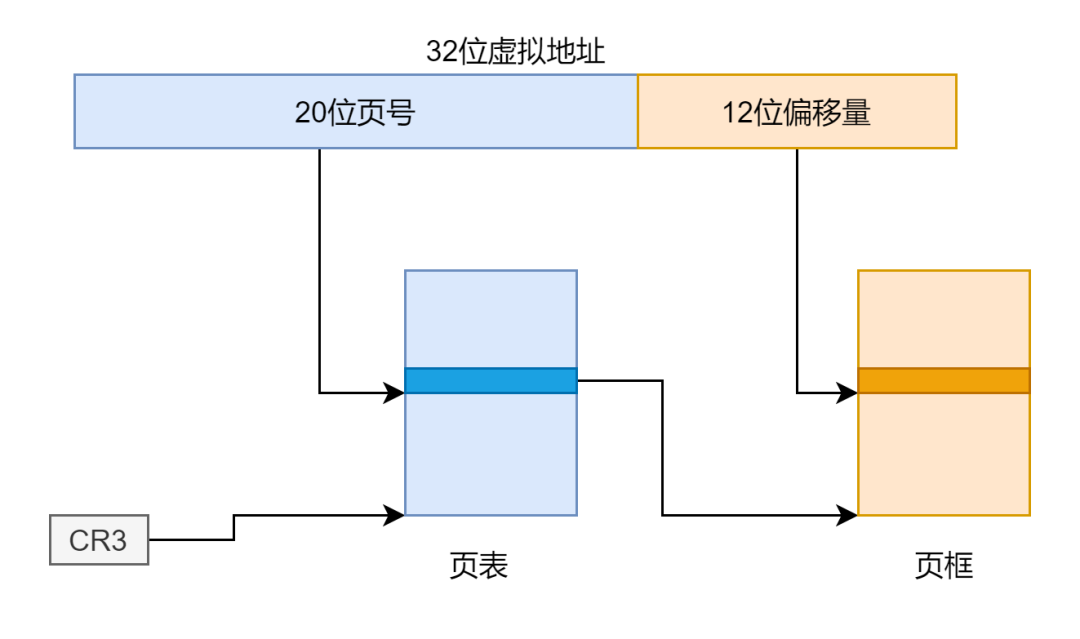
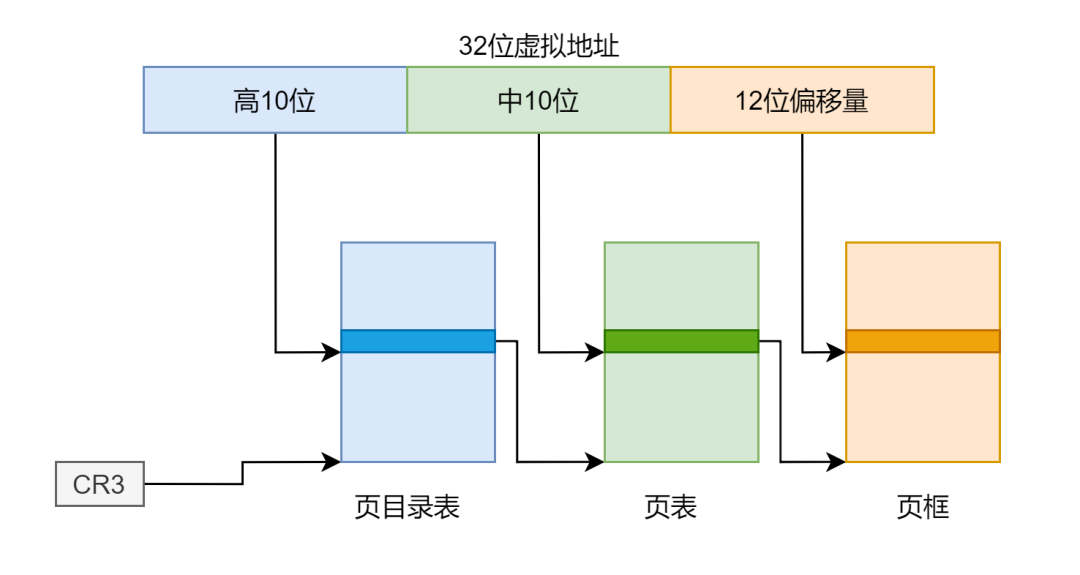
为什么一级页表不适用,为什么多级页表比一级页表省空间
对于这个问题,网上有很多解答,我看着始终觉得有些抽象,在这里说说自己的见解。
首先对于一级页表和多级页表我们对地址的划分情况是不同的,一级页表是 20-12,二级页表是 10-10-12,这些数字可以看作是粒度,12 表示页的大小为 ,20 表示一级页表有 个页表项,所以这个大页表就占用 4M 内存。10 表示二级页表的情况下,页目录页表都有 个表项,占用 4KB 的内存。粒度说明了最小单元的大小,不可分割,为什么不可分割?页表就像个数组,页目录号和页号就是下标,有见过将数组分割开来的吗。
所以只是用一级页表的话就只有一整个 4M 的大页表存于内存。每个进程都需要一张页表,如果使用一级页表的话,每个进程都要有一张 4M 的页表,如果说有很多进程则会花费许多内存来储存页表。再者这还只是 32 位的系统,内存空间只有 ,若是 64 位系统,则需要 个页表项,那简直不可想象。
多级页表则不同,用二级页表来举例,其粒度只有 4KB,必须存在内存中的只有页目录和有映射建立的页表。要知道虚拟地址空间 4G 是很大的,不可能全用了,没有映射建立的页表就不用在内存中,所以省空间。
多级页表的这种结构使得一级页表情况下的那个 4M 大页表变得可分割,拆卸开来,只有用到的页表才存于内存,反之则不需要放在内存中浪费空间。
另外有大佬认为页表一定要覆盖全部的虚拟地址空间,那么一级页表就需要创建 1M 个页表项来映射,二级页表就需要 1024 个页目录项,私以为这是不对的,不管一级页表还是多级页表,分配物理空间建立映射增加页表项都应该是个动态的过程,不应是个静态的过程一下子全部映射。
以二级页表举个例子,一个目录项指向一个页表,一个页表管理 4M 空间。当要映射新的虚拟内存到物理内存时,如果要映射的虚拟页归现有的页表所管,那么就在现有的页表中添加一个页表项。如果现有的页表管不了,那么分配 4K 新建一个页表,在这新的页表里面添加一个页表项,因为新建了一个页表,那么页目录也要添加相应的页目录项。
即使是一级页表只有一整个 4M 的大页表应该也是如此,页表项的创建应该是动态的,而不是说 1M 个页表项全部就创建了。虽然没见过使用 1M 的操作系统,但想来应该不会如此设计,那也太费时了,我们经常看到说一级页表费空间但没听说过费时间吧。
关于页表如果还有些许疑惑,后面看代码实现就了然了,这里就先这样。
页目录 页目录项 页表 页表项
页目录里面是页目录项,一个页目录项指向一个页表,页表里面是页表项,一个页表项指向一个物理页。来看两种表项结构:
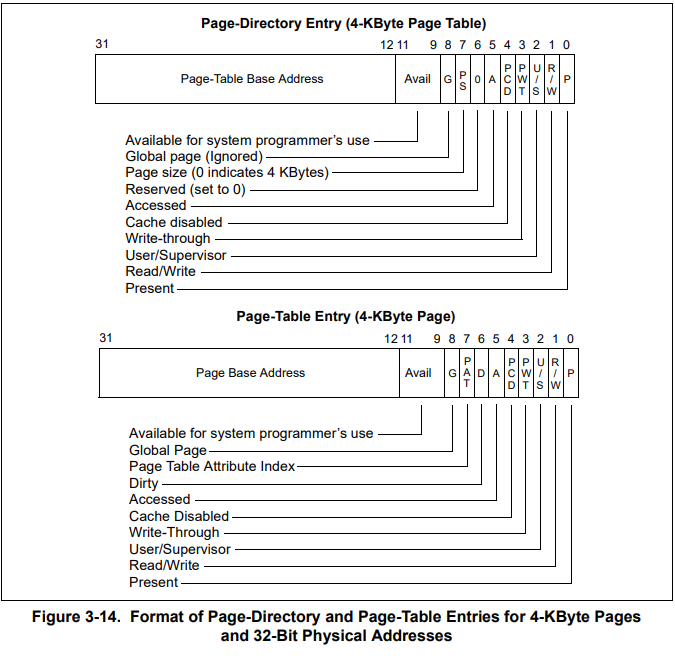
- P,present,该页存在物理内存中,则为 1,反之为 0
- R/W,为 0 表示只可读,为 1 表示可读可写
- U/S,User/Supervisor,为 1 表示处于用户级,任意特权级别都能访问,为 0 表示处于 Supervisor 级别,只有 0、1、2 能够访问,用户级别不能访问。
- A,Accessed,意为访问位,CPU 访问过后该位置 1,可以利用该位记录某一内存页的使用频率(操作系统定期清零,统计一段时间变为 1 的次数),如此可作为页面置换算法的依据。
- D,Dirty,脏位,CPU 对某个页面进行写操作后置 1,只对页表项有效,不会修改页目录的 D 位
- PS,PageSize,页目录项特有,为 0 表示一个页面大小 4KB,为 1 表示一个页面大小 4M
开启分页机制
开启分页机制分为三步:
- 构建页表
- 加载页目录物理地址到 CR3 寄存器
- 设置 CR0 寄存器的 PG 位为 1 表示开启分页机制
注:CR3 里面一定存放的是物理地址,即经过页级转化后的地址,道理同 GDTR 里面一定要存放经过段级转化后的线性地址。CR3 本身就是用来定位页目录好做页级地址转化用的,如果 CR3 里面存放线性地址,寻找页目录还需要转换地址,谁来转换呢?没有,所以 CR3 里面一定要存放页目录的物理地址
各类地址
逻辑地址
访问内存采用 段基址段选择子段内偏移 的策略,逻辑地址就是段选择子和段内偏移量这两部分组合而成,逻辑地址也叫做 far pointer,这个不知怎么翻译(远指针?)。写汇编需要远跳的时候通常就会指定一个逻辑地址。举个例子,xv6 启动的时候有这么一个远跳指令:
ljmp $(SEG_KCODE<<3), $start32
就是个选择子,它会被加载到 CS 寄存器, 就是段内偏移量,它被加载到 EIP 寄存器
线性地址
逻辑地址经过段级转换就变成线性地址,而段级转换就是根据段选择子获取到段基址,段基址加上段内偏移就是所谓的线性地址了
虚拟地址
关于虚拟地址在各类手册里面其实没有明确的定义,有说是逻辑地址的,有说是线性地址的。个人认为,虚拟地址是相对于物理地址来说的,对于实际能被送上地址线的物理地址来说,其他地址都可以叫做虚拟地址。
不必太纠结逻辑地址,线性地址,虚拟地址这三种虚拟出来的地址到底什么概念,在后面平坦模式段基址都为 0 的情况下,段基址选择子段内偏移 这种形式被弱化为 偏移量,所以三者差别不大,都主要是指给出的那个偏移量。
物理地址
物理地址,送上地址总线,内存单元的真正地址。如果没有分页,线性地址就是物理地址。如果分了页,线性地址经过页级转换后的地址为物理地址
地址转换
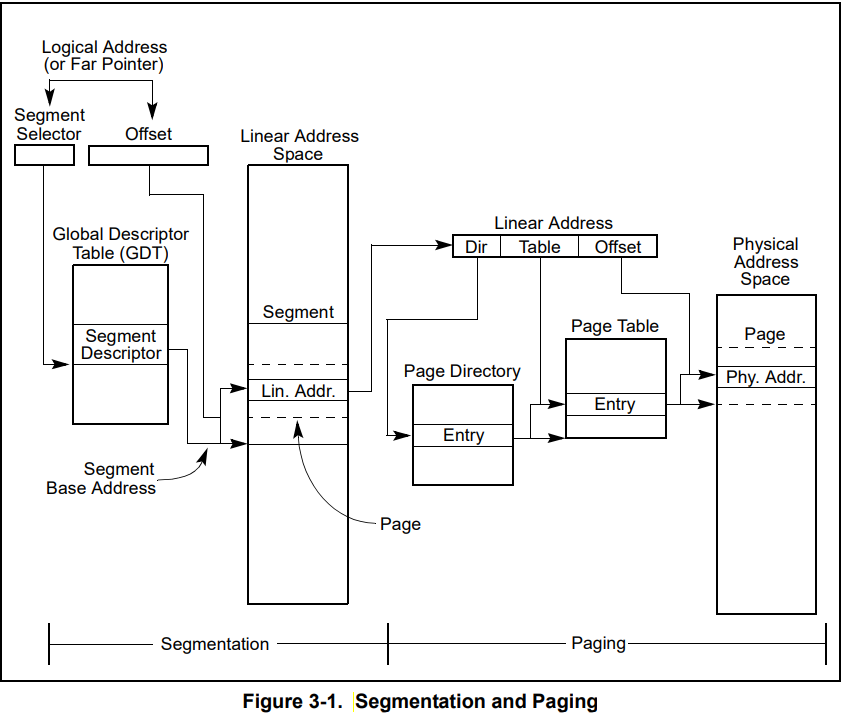
-
段级转换
-
根据段选择子去 GDT 中寻找段描述符从中获取段基址
-
段基址加上段内偏移量就是线性地址
-
页级转换
-
根据线性地址的高 10 位去页目录中寻找相应页目录项,取页表物理地址
-
根据线性地址的中 10 位去页表中寻找页表项,取物理页基址
-
物理页基址加上线性地址中的后 12 位得到目标物理地址
注:地址转换过程中有一些缓存来提高地址转换的速度,比如段寄存器的不可见部分,TLB。段寄存器的不可见部分存放的是描述符,其中有段基址,所以段寄存器不可见部分可看作地址转换的段级缓存。TLB 每一行保存着一个 PTE(页表项),页表项里面有物理页基址,所以 TLB 可以看作是地址转换的页级缓存
平坦模式
分段模式,采用 段基址选择子段内偏移 的形式来访问内存其实是件很麻烦的事,访问不同的段还需要更换段寄存器里面的选择子,因为段基址不同,对于我们平时编程也有不小的挑战。所以就想了个办法规避绕开分段,于是就有了平坦模式。
实现平坦模式主要就两个方面:
- 共用选择子也就是共用描述符
- 描述符的段基址设为 0,界限拉满设为 4G
想想段描述符有什么作用,恰如其名,用来描述一个段,再想想它的内容,描述符其实描述了一个段的两个方面:位置和属性。现在平坦模式将起始位置设为 0,界限都设为一样的 4G,所以描述位置这个作用其实就不大了,也就是说平坦模式下描述符的作用就是来说明一个段的属性。
关于段的属性,很多段之间的属性应该是一样的,比如说不同进程在用户态下的代码段,用户态下的数据段,后面还会说共用的 TSS 段,以及对于所有进程来说,虚拟地址空间的内核部分本身就是相同的,所以还有内核代码段,内核数据段,xv6 也就是这 5 个选择子和段描述符。
在平坦模式下,段基址选择子段内偏移 的访问策略就不是很明显了,因为段基址都是 0,真正有效的就是段内偏移量,我们平时编程使用的指针啊之类的,就是这个东西。
一定要注意,绕开分段的限制不是说就没有分段了,再次强调分段是必须的,使用分段来将相同类型的数据集合在一起,加以段级的保护是计算机法治社会的重要特征,抛弃不用(虽然不可能)是十分不明智的。
页面大小扩展
将 CR4 寄存器的 PSE 位置 1,以及设置页目录项的 PS 位,便可以设置每页的大小为 4M,但是此时对虚拟地址的解析有了变化,如果使用二级页表的话,我们是将虚拟地址的高 10 位作为页目录的下标,得到一级页表的物理地址,将中 10 位作为页表的下标,得到页框的物理地址,再加上后面 12 位的偏移地址得到最终目标的物理地址。示意图如下:
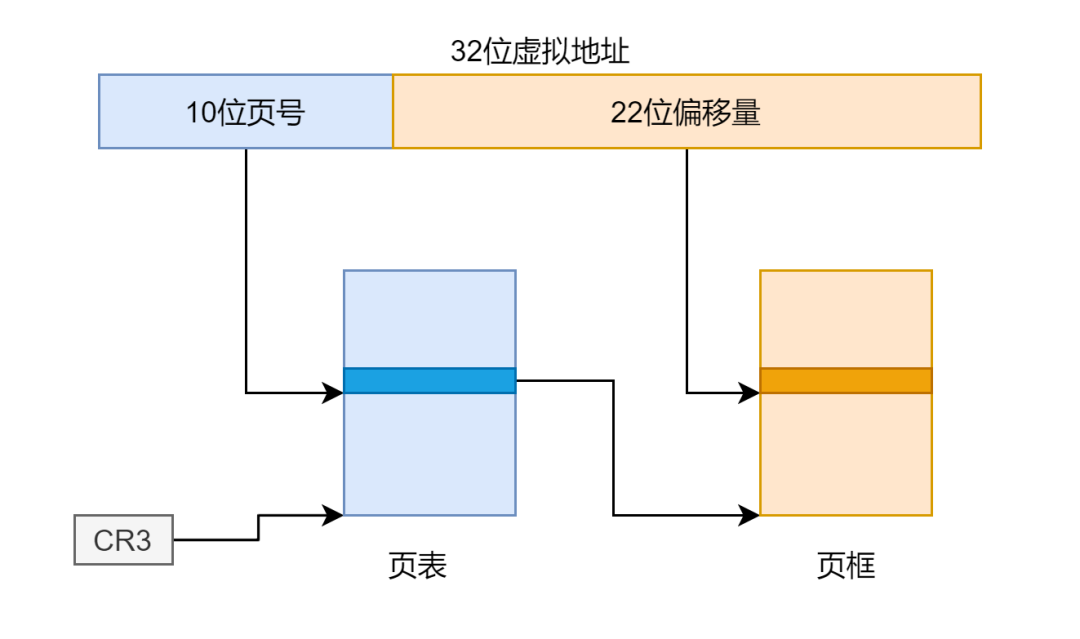
启动流程简要介绍
计算机的启动过程好比一场接力赛,各选手如上图所示,BIOS, MBR, Bootloader, OS, 一个程序接一个程序的运行,而传递的接力棒便相当于对计算机的控制权。如果是多处理器的情况,则会再加上一个选手 MultiProcessor。
启动可以分为两种,一种为冷启动,是指计算机在关机状态下按 POWER 键启动,又叫硬件启动,比如开机,这种启动方式在启动之前计算机处于断电状态,像内存这种需要加电维持的存储部件里面的内容都丢失了,加电开机那一刻里面的值都是随机的,操作系统会对其进行初始化。
而热启动是在加电的情况下启动,又叫软件启动,比如重启,这种启动方式在启动之前和启动之后电没断过,内存等存储部件里面的值不会改变,但毕竟是启动过程,操作系统会对其进行初始化。
下面来看看计算机启动的简要流程,看看这些选手到底做了些什么事
BIOS
启动的第一步便是运行 BIOS 程序,平常要运行某个程序时一般分为两步:
- 将程序加载到内存
- 使 cs : ip 指向程序入口地址
而 BIOS 作为开机运行的第一个程序,运行方式与普通程序稍稍有所不同。
- BIOS 程序不需要由谁加载,本身便固化在ROM只读存储器中
- 开机的一瞬间 cs:ip 便被初始化为0xf000 : 0xfff0。开机的时候处于实模式,其等效地址为0xffff0,如上图所示此地址为BIOS的入口地址。
BIOS 程序做了以下事情:
- POST 自检,检验主板,内存,各类外设
- 对设备进行初始化
- 建立中断表、构建 BIOS 数据区、加载中断服务程序
- 权力交接给 MBR
BIOS 最后一项工作便是加载启动盘最开始那个扇区里面的引导程序到 0x7c00,然后跳去执行
MBR
MBR(Main Boot Record)主引导记录,它位于整个硬盘最开始的那个扇区分为三部分:
- 引导程序和一些参数,446 字节
- 分区表 DPT,64 字节
- 结尾标记 0x55 和 0xAA,2字节
分区表
分区表有 4 个表项,每个表项 16 字节,结构如下:
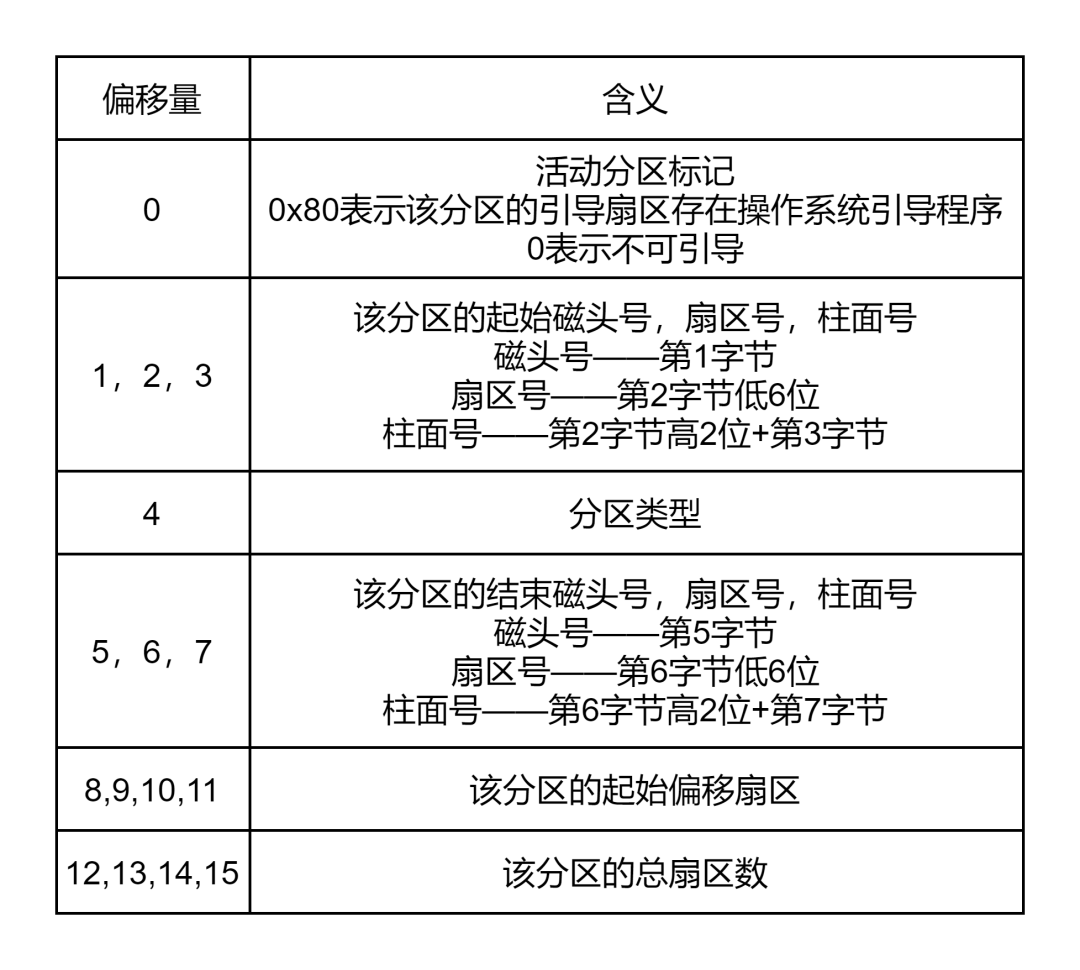
Bootloader
Bootloader,操作系统引导程序,操作系统加载器,不论怎么叫,它的主要作用就是将操作系统加载到内存里面。操作系统也是一个程序,需要加载到内存里面才能运行。平常正在运行的计算机我们可以使用 exec 族函数来加载运行一个程序,同样的要加载运行操作系统这个程序就使用 Bootloader。
OSinit
操作系统内核加载到内存之后,就做一些初始化工作建立好工作环境,比如各个硬件的初始化,重新设置 GDT,IDT ,创建第一个 init 进程等等初始化的操作。这里准备环境就是最后正式的环境,其实在这之前有建立临时的环境,比如 xv6 在 MBR、Bootloader 阶段建立了临时的 GDT 和页表供启动的时候使用。这里点到为止不细说,也不好叙述,等后面直接看实例 xv6 做了哪些事,怎么做的。
MultiProcessor
上述的启动过程是单处理情况下的启动过程,多处理器的情况下有些不同,用一句话先来简单概括多处理器情况下的启动:先启动一个 ,用它作为基础启动其他的处理器。
先启动的这个 称作 ( ),其他处理器叫做 ( )。 是由系统硬件或者 动态选择决定的。
多处理器启动过程大致分为以下几个大步骤,这里简单看看,实现时细说:
- BIOS 启动 BSP,流程与上述讲的 BIOS-MBR-bootloader-OS 差不多
- BSP 从 MP Configuration Table 中获取多处理器的的配置信息
- BSP 启动 APs,通过发送 INIT-SIPI-SIPI 消息给 APs
- APs 启动,各个 APs 处理器要像 BSP 一样建立自己的一些机制,比如保护模式,分页,中断等等
先简要说下第四点,要明确一点:每个处理器都有自己的一套寄存器,不光是通用的那几个寄存器,像是一些 GDTR IDTR 等等都是,所以每个处理器都要对自己的寄存器初始化,设置其值,建立属于自己的一些机制比如说保护模式,分页,中断等等。
MP Configuration Table
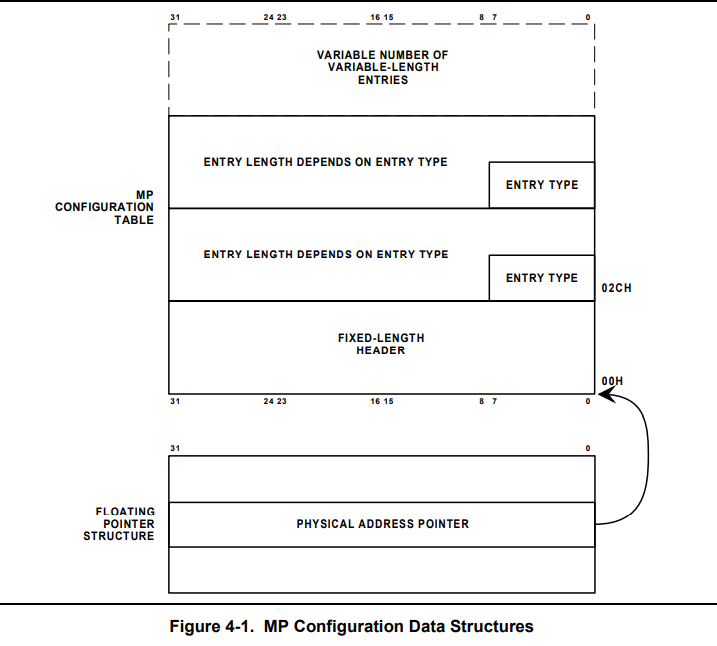
第二点,获取多处理器的配置信息,计算机里面专门设有数据 MP Configuration Table 来描述,还有一个数据结构 Floating Pointer Structure 来指向 MP Configuration Table。
先来看 Floating Pointer 的结构:
struct mp { // floating pointer
uchar signature[4]; // "_MP_"
void *physaddr; // phys addr of MP config table MP配置表地址
uchar length; // 1 结构长度
uchar specrev; // [14] MP版本
uchar checksum; // all bytes must add up to 0 校验和应为0
uchar type; // MP system config type 如果为0表示配置表存在
uchar imcrp; //只使用了第7位,0表示pic模式,1表示apic模式
uchar reserved[3];
};这个结构只可能出现在三个位置,寻找 floating pointer 的时候就按下面的顺序查找:
- EBDA(Extended BIOS Data Area)最开始的 1KB
- 系统基本内存的最后 1KB (对于 640 KB 的基本内存来说就是 639KB-640KB,对于 512KB 的基本内存来说就是 511KB-512KB)
- BIOS 的 ROM 区域,在 到 之间
然后是 MP Configuration Table 的结构,为 头部条目 的形式,头部 MP Configuration Table Header 的结构为:
struct mpconf { // configuration table header
uchar signature[4]; // "PCMP",签名
ushort length; // total table length
uchar version; // [14],版本
uchar checksum; // all bytes must add up to 0,校验和和应为0
uchar product[20]; // product id 产品的id
uint *oemtable; // OEM table pointer,OEM表可选,若无则0
ushort oemlength; // OEM table length OEM表长度
ushort entry; // entry count 表项个数
uint *lapicaddr; // address of local APIC Lapic地址
ushort xlength; // extended table length 扩展表的长度
uchar xchecksum; // extended table checksum 扩展表的校验和
uchar reserved; //保留
};接着是 MP Configuration Table Entry 的结构,它是配置表的表项,表项种类有很多,我们只列出处理器的表项结构:
struct mpproc { // processor table entry
uchar type; // entry type (0) 表项类型:处理器
uchar apicid; // local APIC id Lapic id
uchar version; // local APIC verison 版本
uchar flags; // CPU flags 0x02表示这是BSP
#define MPBOOT 0x02 // This proc is the bootstrap processor.
uchar signature[4]; // CPU signature CPU签名
uint feature; // feature flags from CPUID instruction
uchar reserved[8];
};上面这些数据结构了解就好(好吧我承认是有些我也不清楚),这些数据结构的布局关系图如下:
启动是个大工程,涉及到方方面面,本文也没有全部覆盖,比如说加载内核的时候会涉及到磁盘读写,期间还会涉及到内联汇编的使用,内容较多我就不放在本文了,前面有相应的文章,感兴趣的看可以看看。
BSP BOOT APs
启动 APs 的过程在 MP spec 附录 B 有很详细的说明,感兴趣的可以看看,手册我公众号后台回复手册就有。
一个 AP 可以被 BSP 或者已启动的 AP 启动,APs 启动有个通用算法,使用这个通用算法之前要做两件事:
- BSP 设置 CMOS 的 shutdown code 为 0xA,shutdown code 位于 CMOS 第 0xF 个寄存器
- 设置 warm reset vector,位于 40:67,这是 段基址段内偏移 形式的地址,实际地址就是 0x467,我们需要在这个地址填写 AP 将要执行的代码地址,也是以 段基址段内偏移 的形式填写地址
为什么要设置这些,有什么用?没有为什么,设计者这么规定的,AP 启动是用 warm reset 的方式启动的,warm reset,相当于热启动吧,它是一种复位时 BIOS 不执行整个初始化程序的一种技术,如果 shutdown code 为 0xA,那么 BIOS POST 程序的第一条指令就是读取 warm reset vector,然后跳去执行,即 jmp [40:67]
来看通用启动算法
/*Universal Start-up Algorithm from MP spec*/
BSP sends AP an INIT IPI
BSP DELAYs (10mSec)
If (APIC_VERSION is not an 82489DX) {
BSP sends AP a STARTUP IPI
BSP DELAYs (200µSEC)
BSP sends AP a STARTUP IPI
BSP DELAYs (200µSEC)
}
BSP verifies synchronization with executing AP一句话总结就是 BSP 向 AP 发送 INIT-SIPI-SIPI,AP 就会进行复位启动操作,执行 BIOS POST 时跳去 [40:67] 执行我们安排的启动程序。
这个启动程序与 BSP 执行的差不多,只是一些所有处理器共享的东西比如说内存初始化操作 APs 不会执行,处理器之间共享的东西都由 BSP 来操作。前面说过,每个处理器都有自己的一套寄存器,不止是一些通用常见的寄存器,像 GDTR,IDTR,CR0-4 等等都是私有的。这些寄存器就与一些机制挂钩啊,比如说保护模式,分页机制,中断机制,所以 APs 主要就是重复这些操作,建立这些机制。
本文就这么多吧,启动是个很大的工程,涉及到各个方面,所以其实还有一些没说,比如可执行文件 elf 的格式,磁盘的读写操作,某些地方还涉及到内联汇编操作,这些东西有些多,我就没放进来了。
好了就这样吧,有什么问题还请批评指正,也欢迎大家来同我讨论交流学习进步。