如何编写好的代码?
hi,各位小伙伴,大家好,最近主导项目正在进行code review,发现不同人写代码风格不一样:
- 完成任务型,怎么简单怎么来,目的快速完成任务,尽量复制粘贴搞定,没有自己的代码设计思想,代码杂乱无章,不喜欢重构,bug多。
- 实用性,注重简洁,能不新增代码,就尽量不新增代码,设计比较简单,扩展性一般,但可以满足需求,不到万不得已不会重构代码,对系统侵入性小,bug少。
- 过度设计型,注重解耦(添加中间层),可以称为解耦大师,代码层次丰富,可扩展强,喜欢重构老代码,一般人不易看懂,需要花大量时间理解其设计,对系统侵入性大,bug多(因为新增代码多,bug也会增多,需要各种测试手段才能让其稳定下来)。
你是哪种类型呢,还是混合型(不同情况,不同比例)?
让我们看一看如何编写好的代码。
Programs are meant to be read by humans and only incidentally for computers to execute. ——Donald Knuth “代码始终是写给人看的,只是恰好能被计算机执行。”
什么是好的代码?局部干净,核心逻辑简洁。
本文是一篇总结笔记,是以往工作学习中关于如何实现“局部干净”的一些见闻、教训、团队实践和一些思考。写出整洁代码不仅需在函数、类级别上用功,也应该理解一些其他主题,如项目架构、设计原则等,软件工程是复杂(complex)的,只有各个方面都处理得干干净净,才能在整体上做到代码整洁。
指导原则:消除重复,分离关注点,统一抽象层次
程序员终其一生所做得事大抵不超过这几个层次
- 函数与类
- 包与模块(依赖)
- 服务(系统)与服务域
- 产品
在各个层面,这十五个字都足以作一些指导或参考。
消除重复
重复的代码会让系统臃肿,难以维护,增加程序员的心智负担。消除重复的手段不外乎封装,抽取函数、类等。
1 . 代码重复
完完全全重复的代码,应该抽取出公共的函数。同一段代码出现两次及以上,就应该抽取出函数。
2 . 结构重复
代码虽然不一样,但结构类似,也应该抽取。结构重复可以推导出一些高级技术,如
- 继承体系
- 泛型
- 模板方法(template method,四人帮 23 种设计模式之一)
- 高阶函数,lambda
可惜的是,这些在 golang 里支持不够,各有喜忧。
3 . 过程重复
如果总是重复做同一件事,应该使其自动化。
分离关注点
物以类聚,人以群分,代码也是一样。关注点相同的代码应该在一起,天然具有亲和性,这句话的另一个含义,对关注点不同的代码天然具有隔离性,相互之间不应该太深入了解。
1 . 分离主线和支线
这是最应该注意的,特别是在业务代码开发中。主要业务逻辑是主线,应该突出主线,淡化支线,按照人的思维,这样才是好理解的。例如旋律音和伴奏音,应该突出旋律,而淡化伴奏。假使伴奏音和旋律音差不多强,喧宾夺主,这样的音乐一定是难听的,因为我们听不出旋律。代码也是这样,应该突出主线,使核心逻辑一目了然。
例如在下单的逻辑中,可能的主线是:检查库存、检查余额、生成订单。那这个下单方法里就应该只有 3 行代码,而不应该有诸如权限判断、性能记录等,如果出现就会有 2 行代码是跟主线无关的,造成不必要的干扰,不要造成无谓的心智负担,应该解放心智去完成更复杂的事情。
分离主线和支线的技术如:
- AOP
- interceptor、filter 等
2 . 分离技术和业务
技术型代码常常是公用的,如日期计算、日志记录、性能测量、数据库链接、基础工具类。这些应该和业务逻辑分开,相信这点大家都没有疑问。
3 . 按业务性质分离
对业务开发来说,业务知识永远都是第一位的。一个技术水平很高的程序员,但是对业务不理解,他也发挥不了全部水平,就像杀鸡用牛刀,施展不了全部功力。不同业务应该分开,在模块级、服务级甚至更高的产品级,这也应该是共识。但是在一个系统内部,推荐也应该按业务分成不同的包,同一业务下的对象是天然亲和的,同样也是对不同业务的对象是隔离的。
4 . 分离变化快慢的代码
变化快的代码和长年不变的代码分开。
5 . 分离性能高低的代码
重 I/O 的代码和重 CPU 的代码理应分开,方便合理分配资源,其他诸如此类的代码应该注意分开。
统一抽象层次
将有关认识与那些在实际中和他们同在的所有其他认识隔离开,这就是抽象,所有具有普遍性的认识都是这样得到的。——John Locke 《关于人类理解的随笔》
怎么理解抽象?抽象的反面是具体,具体是细节,可见抽象是细节的反面,抽象刻画了统一的画像,描述能力,是对事物在某些方面的特征的提取总结。总之,抽象表达的是意图,另一个理解就是,它不表达细节。“Tom 要成为世界首富”,这句话的抽象层次就很高,意图很明显,但是关于 Tom 如何成为世界首富、用什么货币衡量等细节,一概不知。抽象层次高,偏意图,语义(代码在上下文中表达的语义)清晰,信息量小;抽象层次低,偏实现,语义模糊,信息量大。
两个原则:
- 同一抽象层次上的对象才能直接对话;
- 同一抽象层次上的对象之间存在着紧密合作;
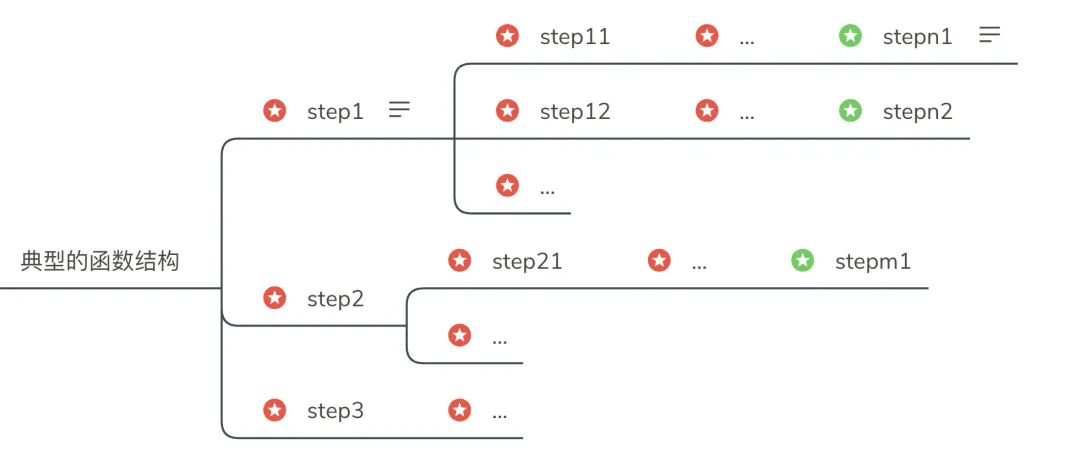
典型的函数结构
以“把大象装进冰箱”为例,不外乎三步:
- 打开冰箱门
- 放进大象
- 关闭冰箱门
所以关于如何把大象切成碎片,不应该出现在上面,应该在步骤 2 的后续调用中。
由这个函数结构还可以得见,好的程序读起来应该像自然语言,极少部分像数学语言(偏算法),不好的程序读起来就像是程序。当我们读一段程序,一眼看去它就像是程序,那不是它太好,它就是不够好的。一直认为,写作能力才是成为优秀程序员最重要的能力。
隔离与隐藏
信息隐藏,是抽象的一种手段。通过信息隐藏,来暴露只想让外界知道的东西,表达意图。隔离是实现信息隐藏的重要手段。隐藏与隔离有一个天然的好处,例如我们有一个包,我们只提供数个 public 的方法,包内的其他对象、方法都只是包可见的,这样,我们可以随意修改内部实现,只要保证那些 public 方法的行为不变。特别是对于复杂系统,如果做不好隔离与隐藏,到处都是 public 方法,到后面谁都不敢随意改动代码,谁也不知道哪位大哥在方法上加了一个 if-else 分支。
编码 tips
以下都是一些简单实用的技术,以如何写出整洁代码,很多是出自《代码整洁之道》,一些是出自过去团队的经验。
1. 类
1 . 类应该足够小
最初级的程序员可能会在一个 Controller 里做完所有的业务逻辑,最终会使这个类成为 God Class。一个类太大,代码太多,会使类的结构不清晰,职责混乱,维护代码时花费很多时间去寻找修改位置。譬如我们所见的世界,由分子、原子甚至更小的粒子排列组合而成,所以才有缤纷多彩的各色物质(对象),但如果构成物质的最小粒子就是人,那还能组合出什么其他物质呢?代码也是如此,类应该足够小,才能发挥排列组合的威力。
2 . 单一职责
类的职责应该单一,即“SOLID”五大原则的 S,职责单一意味着,“只有一个理由可以修改它”。另外,类名一般而言应该是名词,且描述其职责。
如果无法为一个类名以精确的名称,这个类大概就太长了。类名越含混,该类越有可能拥有过多的权责。
——《Clean Code》
3 . 内聚
内聚的含义是,类的每一个字段都应该被某个(些)方法所使用到。如果不能达到这个结果,应该考虑是否类的字段应该拆分出去成为新的类。
4 . 严格控制访问权限,注意信息隐藏,OCP
访问权限应该能小则小。能 private 就不要 package,能 package 就不要 protected。这样做能使我们更好的遵循 OCP 原则。最稳定的系统,是从不修改的系统。
2. 函数
1 . 尽可能小
经过漫长的试错,经验告诉我,函数就应该小 ——《Clean Code》
应该控制在 10 行以内,至多 20 行,除非是细节代码。这是完全可以做到的,做不到的原因可能有:函数功能太多,职责不单一;函数抽象层次划分不清;语言支持不够等。前面已经说过,做一件事大概也就 2~5 步,每一步一个函数,加上可能的条件判断,10 行是一个比较合理的数字。而且,函数越小,功能越集中,越便于取一个好名字。
2 . 单一职责
一个函数只做一件事。这一点很容易理解,难的是我们如何确定函数做的那件事是什么。一千个读者就有一千个哈姆雷特,同样的,不同的人对一个函数的理解也有所不同,对于做一件事的步骤拆分也可能有所不同。对此,一个可靠的判断准则是:函数的内容(函数体内的代码)只是做了函数所在抽象层级的步骤,那这个函数就是只做了一件事。函数所在抽象层级,根据对业务的理解,应该用良好的函数名加以示意。
3 . 单一抽象层次
一个函数应该只在一个抽象层次上。计算机世界都是层层叠加的,例如:寄存器 -> 高速缓存 -> 主存 -> 硬盘 -> 网络(可参见《CSAPP》第六章),再如硬件 -> 机器指令 -> 汇编 -> C -> C++ -> JVM -> Java -> Servlet -> Spring -> SpringBoot。严格禁止跨层次搞事。我们应该熟悉业务,根据业务上的一次用例,划分抽象层次,使每一个函数都只在某一个抽象层次上,不要跨层次。还是以把大象装进冰箱为例:
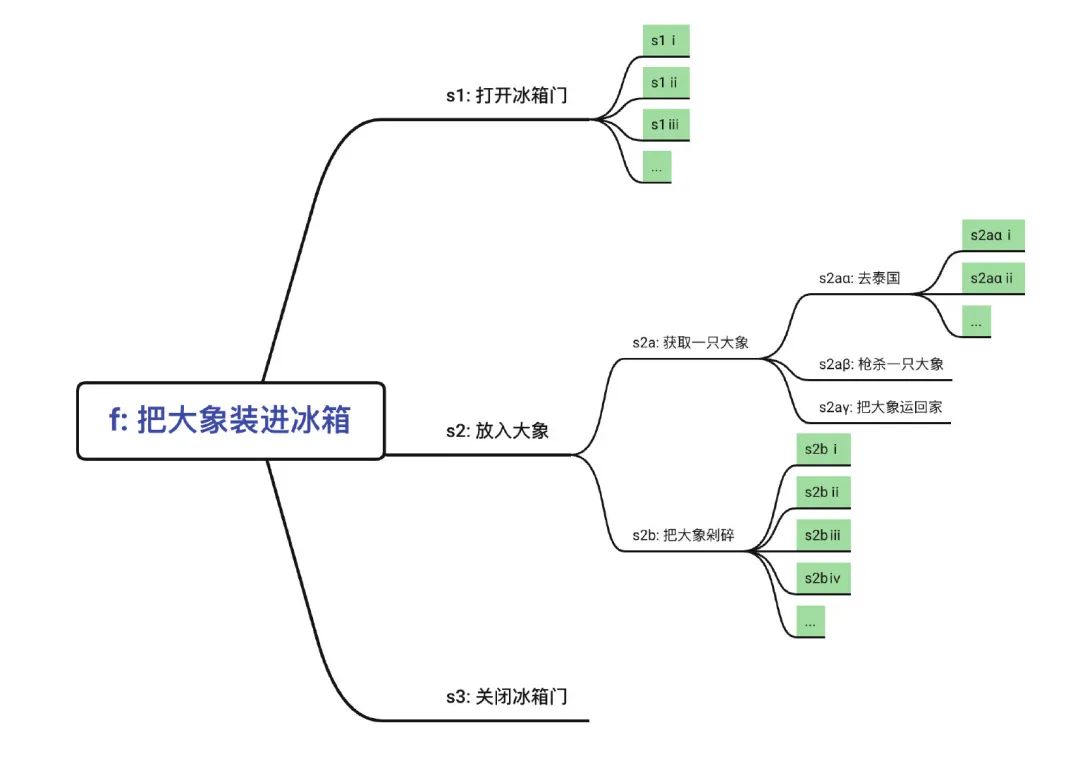
绿色部分是最低抽象层次的具体实现,这部分是无法拆分,且难以控制代码行数的,因为有些情况下做一件事就是有很多细节实现步骤。
4 . 参数尽量少
最理想是 0 个,其次是 1 个,2 个,最多 3 个参数,不要超过 3 个参数,除非你有非常特殊的理由。——《Clean Code》
参数带了极大的语义干扰,而且也难于测试。一个典型的不好的设计,就是用 bool 作为公开函数的参数,因为 bool 变量天然地会使人想到这个函数不会只做一件事,它分情况处理,bool 入参的命名稍有歧义就会使人困惑。例如
func GoToWork(raining bool) {
if raining {
// 开车去
} else {
// 走路去
}
}更推荐的做法是,将 bool 参数的函数私有,另外公开两个语义清晰的函数。
func WalkToWork() {
goToWork(false)
}
func DriveToWork() {
goToWork(true)
}
// 私有
func goToWork(raining bool) {
if raining {
// 开车去
} else {
// 走路去
}
}任何时候,我们维护代码,最关心的都是对外可访问的函数,这些函数应该尽我们所能使其整洁。另一个例子,在 JUnit 里曾有这样的方法,不知给多少初学者带来困扰
assertEquals(expected, actual)
对使用者来说,完全没有必要去记忆两个参数的相对位置。相较而言,assertJ 里的连贯式接口就要友好得多
assertThat(actual).isEqualTo(expected)
golang 里能够返回多个返回值,但这绝不可以滥用。试看
func func1(/* params */) (string, string, string, string, string) {
// 函数职责不单一,功能太多
}
func func2(/* 此处多达6个参数 */) {
// 函数职责不单一,功能太多
}这样多入参、多返回值,给调用方造成很大困扰,调用方需要反复分辨每个参数、返回值的对应关系。不能因为眼前就只有自己调用自己写的函数而这样放纵,我们写的代码,终究是会由别人接手的。
5 . 无副作用
一般而言,函数应该是无副作用的,对于调用方来说,它就是一个黑盒:给定输入,产生输出。仅此而已。不要让调用方去思考我这次调用会不会产生输出以外的其他结果。例如应该尽量避免这种情况:一个函数,以指针作为参数,返回一个结果的同时,还修改了指针所指向的内容。一个函数的作用,要么是 get,要么是 post,即要么函数无修改的 get 一个结果,要么就是单纯修改而不返回修改以外的结果。jdk 里有一个典型的反例,各种集合的 add/set 总返回了一个 bool 值,就会出现这样的代码
// numbers is a list
if (numbers.add(1)) {
//
}对于新手这可能就是一个让人迷惑的地方,可见,无副作用也不是绝对的,强如 JDK 也有不得已的折衷处理。
6 . if 嵌套不应超过 2 层
if 不要嵌套超过 2 层,这初听起来有些强人所难,仿佛要求每个职业篮球运动员都应该以乔丹的能力作为基准。可人的天性就是不喜欢思考的,喜欢简单。在此再一次强调统一抽象层次,if 嵌套太多,一定要思考,是不是函数做的事情太多,跨层次在搞事情。我们应该用一些高标准去检验自己的代码,想办法去满足,这个过程才会有所成长,否则除了收获经验以外,不会有进阶的成长(其实人生又何尝不是如此)。
消除多层 if 嵌套的一些手段
- 提前返回,将嵌套 if 铺陈开来,使不满足条件的分支提前返回;
- 碰到第三个 if,直接将其抽取为函数(简单粗暴);
- lambda,在 Java 里利用 stream 的扁平化处理,使 filter、map 等语法元素都可以接收简单的函数,从而避免在 for 里加 if 判断。对于集合的遍历处理,都应该尽量先采用 stream 的做法,这种流水线的思想,在一个步骤里就剔除了不满足条件的对象,然后流转到下一个步骤。
7 . 语义和实现距离不为 0 时应该抽取函数
好的代码读起来就应该像自然语言,而不是像程序,这就要求在高抽象层次时,函数应该表达意图,而只有在叶子结点——抽象层次最低的实现部分才表达实现,这个地方的代码更像是程序。所以,在代码中的某个位置,我们本应该表达意图,却写了细节实现代码,这就应该抽取出函数。以下面这段代码为例。
tom := &Person{}
if tom.Age >= 18 {
// do your bussiness
}一般认为这是表达 tom 是否成年,但实际的业务含义中却是判断 tom 是否可以申领 C1 驾照。即使是想表达是否成年,这样也要使大脑经过一层转换,由<span style="font-family: Arial, Helvetica, sans-serif;">Age >= 18推理一次,才能得出结论这是表达是否成年,这是典型的“代码 prase 语义”,不要小看这层 parse 对人脑的开销,特别是所见之处都是这样的代码会让我们的大脑长期忙于“线程切换”活动,造成的思维停顿让人非常沮丧;此外,如果一个日本人看到这段代码,一定不会想是表达是否成年这个语义,因为他们的法定成年年龄是 20 岁(2022 年 4 月 1 日起改为 18 岁),这是代码不灵活的体现。推荐的做法是
if tom.isAdult() {
// do your bussiness
}
func (p *Person) isAdult() bool {
return p.Age >= 18
}这样,在isAdult方法里还可以更改实现,也更灵活,很多时候,如果我们程序写得好,实现比较灵活,就能够从容的应对经常变化的需求;如果需求稍微变化一下,现有代码就顶不住了,就应该思量实现是否足够好。代码应该表达意图,特别是 if 条件分支里,不要让人再去推理,直接表达语义。就像人走路,相比于一马平川,我们不会更喜欢岔路;但凡岔路,就应该明确指明路线,而不是在路口打个机锋,才让你思考十年然后顿悟才选择出了某一条路。
8 . 童子军军规
走的时候,比来的时候干净一点。代码中如果我们能经常注意这一点,那我们每时每刻都在改善代码。世界是朝着熵增的方向发展的,譬如一个房间,即使我们完全不去干扰它,久而久之它也会变得更加混乱,代码也是这样,它终究会变得越来越混乱、难以修改、难以维护。如果我们不注意这一点,反而每次来都扔一点垃圾,久而久之就会成为“破窗”直至“破楼”。
9 . hardcode
任何时候都不应该在代码中直接出现 hardcode,hardcode 难以表达语义,且难以管理。
3. 命名与注释
命名是一个哲学问题,我们所知的一切,都是命名,存在、宗教、知识、伦理...没有命名,我们所知的一切所谓知识都将崩塌。
There are only two hard things in Computer Science: cache invalidation and naming things. ——Phil Karlson
“计算机世界只有两个难题:缓存失效和命名。”(可读一读《CSAPP》关于存储层次结构的描述,对此会深有体会。)
坊间流传着一句话,给变量命名犹如给自己亲女儿命名一般,只因如此,就不会随意命名了。命名的一般原则无外乎完整、简洁、准确等。
1 . 顾名思义、望文知义、无歧义
清楚明白无歧义地表达含义,不要让别人猜你的意思。在 API 设计里,有一条原则即是“Don't Let Me Think”,命名也应该如此,乃至日常工作沟通中也应当如此。
2 . 名副其实
cat := &Dog{}?
3 . 表达语义,避免误导
userList实际实现是一个 Set,users 这个命名会更好,语义更清晰,userList 有一些语义干扰。命名不应该表达实现(如 List 实现,数据结构等),而应该表达语义。
4 . 使用读得出来的名字,谨慎使用缩写
人看代码,实际是在默读代码,包括你现在看到这句话的时候,心里也是在默念出来的。如<span style="font-family: Arial, Helvetica, sans-serif;">xxCmd这样的命名,一定会在脑海中多了一次 parse,对于一些更不常见的缩写,这种情况更严重。前面提过,这种脑内 parse 会使大脑忙于“线程切换”,思维停顿更是让人沮丧。
5 . 团队统一业务术语
DDD 的一个重要理念就是同一术语,在一个团队内部就应该统一术语,从运营产品到开发测试等,都应该对某一个业务专有词不产生任何歧义。我见过太多因为产品和开发对某一个词的理解不同而“大打出手”的事。
6 . 注释
好的代码是自注释的。
命名虽然重要,但也无需发展成为圣战。
4. 单元测试
应该重视单元测试。单元测试,保证软件质量和代码质量。单元测试是我们所写函数的第一个调用者,如果发现单元测试很难写,那不用说,函数实现绝对是有问题的,或者抽象层次划分不清,或者依赖复杂等。如果连我们自己调自己的方法都用得这么不爽,那可想而知其他调用者,特别是网络接口。这是为什么单元测试可以保证代码质量,它可以检验我们的代码是否写得足够好。
单元测试对于修改代码或重构的重要性无可替代,对于拥有一组完善单测的函数,我们可以随意更改,只要让修改后的函数通过单测,就几乎是安全修改的,单元测试铺了一张安全网,让我们像走钢丝一样地写代码不至于失足跌入深渊万劫不复。
关于单元测试有很多实践,最著名的可能莫过于 TDD,我们虽不至于按 TDD 的实践来开发,但我们应该善用单元测试,来检验我们的函数实现是否合理,实现得好的函数,单测一定是好写的,逆否亦然。
一些 tips:
- 不能依赖真实依赖,这是大忌。如依赖真实数据库且数据库出错,并不能检验单测所测函数逻辑失败,而是外部造成的,应该 mock,且对一般对象也应该尽量使用 mock 对象;否则即为集成测试;
- 路径应该尽可能全;
- 不能有条件分支,任何条件分支都应该新开单测;
- 单测也应该像业务代码一样,干净整洁;
- realBug 测试是必要的,发生过一次的事情很有可能会反复发生,我们选择题第一次选错了,第二次还是很可能选择上次的那个错误答案;
- ...
其他话题
以下这些话题,单独拎出来都是一个很大的主题,这里只是抛砖引玉,简单谈谈一些和整洁代码相关的感悟和实践,实是整洁代码需要各个方面的努力,而非仅代码一途用功。
心智负担与复杂
Complexity is caused by two things: dependencies and obscurity.
软件开发的复杂性由两样东西带来:依赖和晦涩。这两者都会加重心智负担。消除心智负担一定程度上意味着增加可读性和可维护性。
其实我们所做的一切,都是在驯服复杂度。人脑终究是有限的,我们眼所能见、脑所能别的资源几乎都是有限的。驯服复杂度,代码写好了,升职加薪,业余时间没有 bug 找上门,提高生活质量,我们所做的一切不就是为了这个吗?
复杂是我们软件生涯的一生之敌。
分层分包
分层是除“模块化”之外最古老的架构模式,冯诺依曼计算机模型是模块化的架构,但同时计算机世界也是层层叠加的。分层分包的本质就是隔离,人处理难题的能力是有限的,无法同时处理很多复杂的事情,所以不把所有东西都放在同一层次,譬如行政体系也是分层的。隔离使得各个层次职责更清晰,更容易管理。
分层的原则是只能上层调用下层,而不能反过来,反之容易导致循环依赖。分包的原则是,同一个包中的对象天然是亲和的,同时对包外的对象是不亲和(隔离)的。
从分层的理念理解,则 controller/api 层 的 request 不应该一直传递到 service 层甚至是 dao 层,然而这种现象却是非常常见。业务层不应该对界面层有所了解,而是相反,界面层调用业务层来完成一次用户用例。凡是进入业务层,就不应该有界面层的对象,而应该在界面层转换成业务对象,进而使业务层只处理它所能知的业务对象。这种跨层次的信息传递,无异于乡长直接向省长汇报工作。
传统 MVC 的分层对于简单业务而言,是简单实用的。但是其对于复杂业务系统的架构能力十分有限,一个 service 包里有上百个 xxxService 类,业务表达能力有限,如果所有对外服务都可以叫做 service,那为何要区分餐厅、医院、商场,统一叫服务不就好了?而且很多时候,往往就是一些无法准确划分职责的类干脆就合并到 Service 类里,这让 Service 类成了一个大杂烩直至成为 God Class,最终退化成过程式代码,只是机械的代码堆积,没有层次分明、职责分明的对象,没有设计感。
对于业务复杂的系统,DDD 微服务经典四层分层是一个更好的实践,重视业务、重视 OO,整个系统设计感十足,对象林立,可以做一些了解。但是对于业务简单的系统,则不应该为了炫技而使用技术。因地制宜,学会取舍。
此外,关于 dao,业务复杂情况下应该避免使用。dao 的表达能力同样很弱,dao 里的方法很难表达意图,语义表达能力很弱,findByXXX 实际是没有业务语义的,例如 findByAge 接受参数 18,还是上面的例子,并不是选择成年的业务意义。此外 dao 难以管理。例如一个 dao 里有上百个 findByXXX 方法,如果业务需要新增方法,一般最省事的做法就是直接又加一个 findByXXX 方法,这样下去 dao 会越来越膨胀并趋于崩坏。业务复杂情况应该使用 repository,repository 通过组合规格(specification)来表达查询语义,repository 是仓储的概念,类似一个 ADT,只有有限几个经过仔细设计的方法,类比一个 map 就理解了。关于更多为何不使用 dao 而应该使用 repository 的知识,可参考 https://thinkinginobjects.com/2012/08/26/dont-use-dao-use-repository/
设计原则
遵循良好的设计原则,能使代码更整洁,当然意义不仅于此。有关设计原则的资料很多,我们也应该对此有所了解。常见设计原则如:
- SOLID
- ADP
- REP
- CCP
- CRP
- SDP
- SAP
- DRY
- KISS
- YAGNI
- SLAP
- POLA
- LoD
代码的非功能特性
只完成功能的代码,是最基础的代码。好的代码还应该尽量完成代码的非功能特性,有兴趣可以了解下,不外乎:
- 可操作性
- 健壮性
- 可测试性
- 可维护性
- 易用性
- 可重用性
其实还有些主题是无法避而不谈的,如错误处理,但限于篇幅和能力,只能推荐读两遍《Clean Code》。
最后,人生不过是“看山是山,看山不是山,看山仍是山”,代码也是如此,不要着相。
- END -