一个专业的工程师,从做好日志开始
在一开始我仅仅对 Node.js 这个技术栈比较感兴趣,但是随着项目的进行,我发现 Node.js 也仅仅是后台服务开发的冰山一角,你需要考虑的更多,需要对很多的技术领域进行学习,它们可能并不是你感兴趣的,例如 CICD、日志传输、火焰图分析、分布式架构设计,但是只要坚持下去,你会发现很多有趣的 idea,本文也是希望将自己的探索之路分享给大家,亦作参考。
Node.js 目前已经诞生了 11 年,相信各位前端爱好者或多或少已经学习或者实践过了。一般当 Node.js 项目成长到一定阶段后,就不可避免要遇到许许多多的事故,例如服务器无故宕机,线上逻辑出现问题,其中的排查手段多种多样,但是我认为最好的还是拥有细致的上报,是排查这些问题的利器。
本文会涉及一些内部系统,大家理解思路即可,不用过分纠结具体的系统。
前言
根据业内比较标准的日志服务场景,主要有以下四种场景:
- 日志、大数据分析,主要是产品数据分析方面,用于追踪业务关注的一些流程,方便去做一些有利于业务反馈的数据分析。
- 日志审计,项目中一般是用于数据恢复,例如数据库故障之后,根据日志来进行数据恢复或者数据校验
- 问题诊断,面向前端的服务则需要实现全链路日志,服务侧本身则是需要实现 DB、HTTP 等业务模块的联通定位日志,出现问题后可通过全链路日志来快速定位故障点。
- 运维管理,主要是服务器日志,各种第三方模块的日志,例如:redis、mysql、kafka 等,用于日志报警和快速恢复。
本文会针对这些常见给出一些解决方案的选择经验,也会配合一些事故案例来和大家一起讨论。
项目背景
首先给大家描述下后台服务所面临的日志背景,这里以我所开发的系统架构为例:
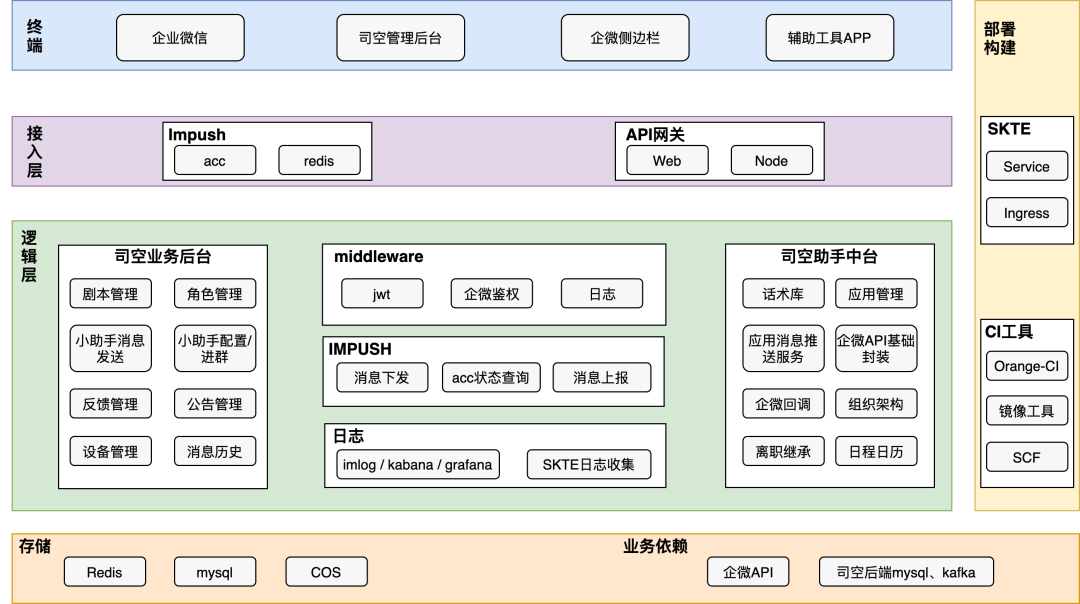
涉及到前端调用、服务器调用、调用第三方服务、存储,在项目初期的时候,由于缺乏完善的日志服务,在面临线上请求错误路径排查、业务故障定位,几乎只能全靠程序员的技术第六感来猜测可能的事故点,因此每次上线新功能都是极其紧张的,也就逼迫着自己去探索和设计完善的日志上报体系。
常规日志技术选型
虽然日志设计很复杂,但是得益于 Node.js 社区生态已经逐渐完善,你可以去根据业务场景也进行灵活选择上报技术、日志分析技术和日志报表技术,本文将在这里对常规日志技术选型进行下简单分类。

上图则展示常见日志技术选型时应当考虑的技术因素。
- 存储位置,一般来说成熟的日志上报系统会提供本地和远程两种日志存储形式,其中本地日志十分有利于容器崩溃或者网络崩溃条件下的系统排查和恢复,线上日志则是有利于脱离对容器环境操作来进行日常问题定位,且线上日志接入日志分析工具或者平台,例如 ES 的通道上报接入 Kibana,使用起来也是十分方便。
- CPU 占用,日志工具在写入本地日志或者远程传输日志时,不可避免的要占用一定的 CPU 载荷,因此其日志收集必须有很好的传输效率且可以分级日志写入,例如日志分为 trace、debug、info、warn、error、fatal 六种级别,如果不能合理进行级别进行过滤日志上报,很容易由于日志过大导致 CPU 或者带宽被迅速消耗殆尽,进而导致服务故障。
- 日志保留时间,目前大多数的日志技术方案中日志存储方案都不是持久化的,原因也很好理解:大多数日志都是没有价值的,全面存储带来的收益和存储激增带来的成本开销是不匹配的。首先本地日志一般是相对比较庞大的,一般都是 GB 级别的,本地保存尽量保持 24h 以上,再结合定期日志转存手段,让这部分的日志能够保留 7day 是最好的。线上日志则需要去除不关注的级别的日志,例如 info、debug 等,在保持日志信息足够丰富度的情况下尽可能精简日志,降低存储开销。一般来说成熟业务是需要持久化一部分核心业务日志数据,例如支付转化率流程,这部分日志需要持久化存储来进行分析和提升和优化业务方向,因此也需要日志服务能够提供一些手段或者通道将一部分日志持久化到你提供的存储空间内。
- 内存占用,这里主要考虑本地日志会大量占据磁盘空间,导致容器空间不足进而导致服务崩溃的情况,本项目中某次业务开发调用了一个批量查询接口,其回包 content-size 是 MB 级别的,上线后高频调用产生 http 监控日志直接把 128G 的磁盘空间占满了,导致服务崩溃,因此在日志开发和技术选型过程中,要注意合理精简日志。
- 日志丢失率,日志上报特别是线上日志,受制于网络波动和高频调用是存在一定的失败率的,但是这个失败率一定要尽可能小,这是技术选型时重点调研的方面。
- 日志分析能力,接入好用的日志分析框架或者工具,能够大大减少你在开发过程中的投入,这里是主要关注你要接入的日志分析工具和你的日志上报系统是否能够融合。
这里给大家介绍下本项目的分梯度的日志存储结构,以供参考。
本地日志
本项目采用团队内部框架(IMServer)集成的日志能力,将数据库日志、请求日志、POD 运行日志等细节日志存储到本地 dist/log 文件夹下,一个 Worker 一个单独的文件且标明时间和 Worker 索引,每 24h 清空一次日志文件。
本地日志是最详细的日志了,往往会占用比较大的内存空间、CPU、IO 读写,因此本地日志不可以无脑全部写入,还是希望开发者能够做区分,保留核心日志,减少内存和 CPU 的占用,这是降低服务器成本、提升服务载荷的一个关键手段。
本地日志相对于远程日志来说具有更好的稳定性,但是日志由于占据服务器宝贵的内存而无法长期保存,因此可以定期转存到腾讯云日志服务等稳定且长期保存的服务中。在本项目中是使用内部容器平台(TKEx-CSIG),该平台使用了腾讯云日志服务(CLS)的日志上报方案,可以将日志文件定期上传到 CLS 即星迹平台上。具体如何使用呢?
首先在内部容器平台(TKEx-CSIG)的日志规则中,增加日志集、日志主题、日志文件目录的配置,如下图:

最终我们在 CLS 平台进行日志的常规检索和分析。
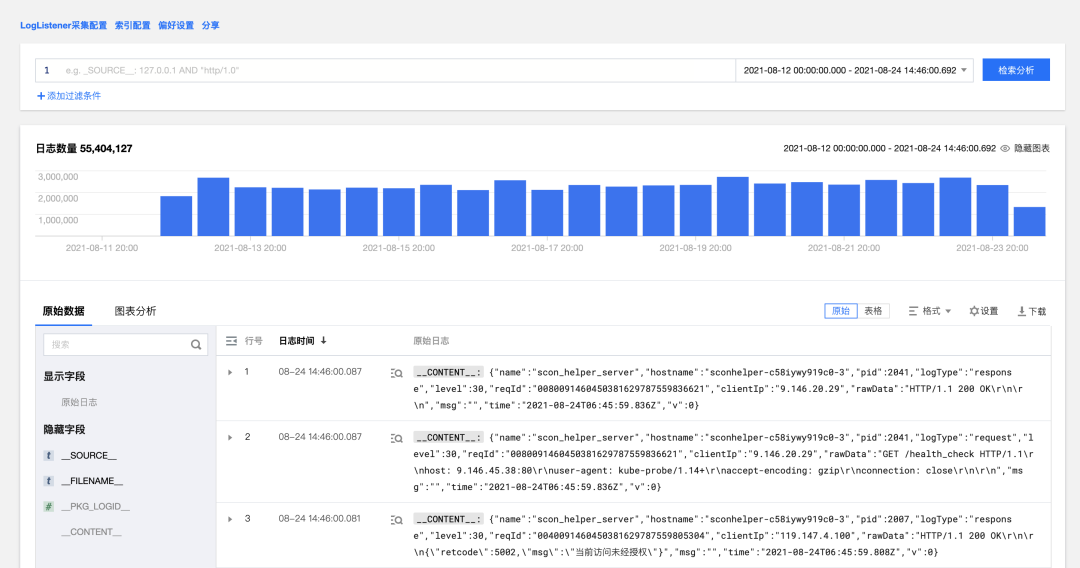
运维日志
相对成熟的容器平台都是会有比较成熟且好用的运维日志系统,Node.js 开发者只需要能够充分利用这些能力就可以满足自己的日常运营需要。例如本项目中使用的内部容器平台(TKEx-CSIG),提供基于 Grafana 的监控面板,如下图:
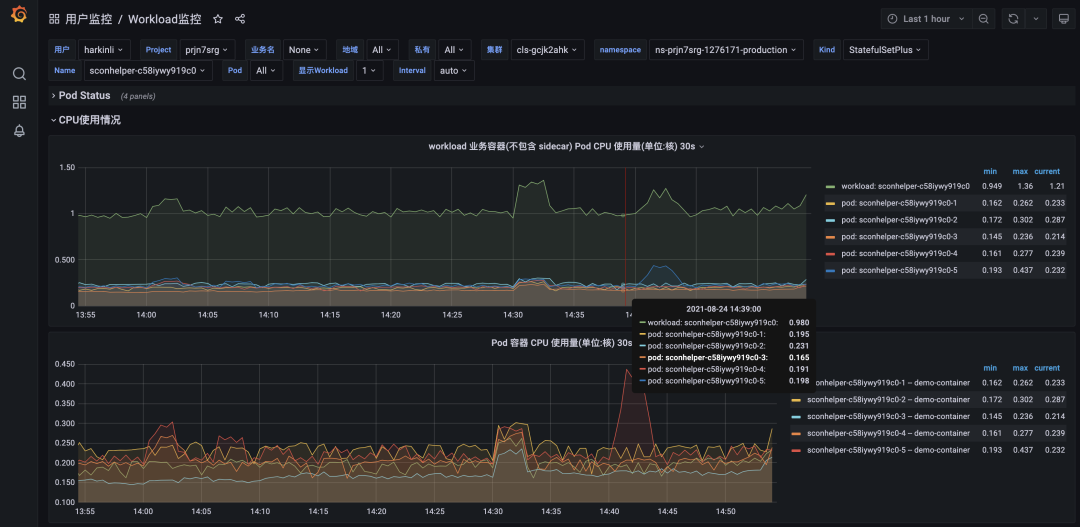
可以实时的去观察 Pod 状态、CPU、内存、磁盘、HPA 等,方便开发者快速解决问题,这个是和 Node.js 无关,大多数平台都是支持的,如果想抓取 Node.js 运行时的堆栈、内存使用、火焰图、内存快照,则可以使用更加定制化的 Node.js 服务监控控件。其中在排查或者优化服务运行性能时,如下图所示的火焰图是个很好的参照。
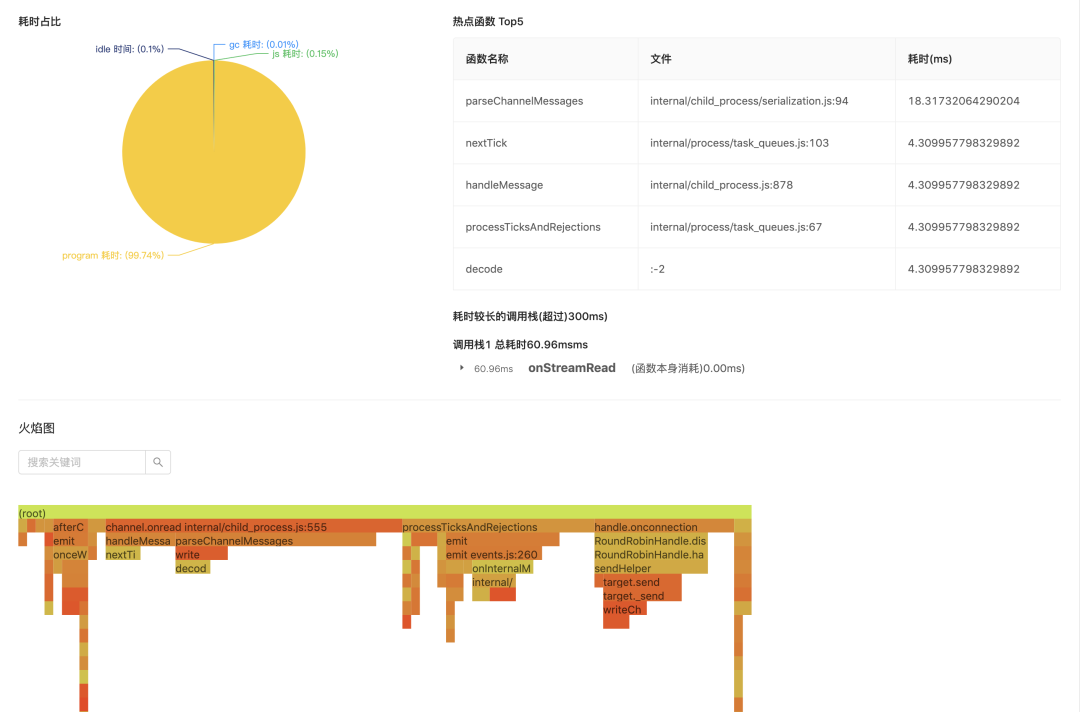
前后端全链路日志设计
关于 Node.js 的日志开发主要是集中在全链路的日志开发设计上,前面的本地日志和运维日志一般只需要少量开发或者配置就可以完成,全链路日志则需要我们去用心设计了。
这里首先介绍了什么是全链路日志?

这是典型的业务调用链示意图,所谓全链路就是把 0-6 个环节串连起来。在进行链路分析时,需要为每次请求定义一个唯一标识 traceid,这样就可以根据 trace_id 查出本次请求调用的所有服务,更进一步可以形成类似下面的调用链静态拓扑:
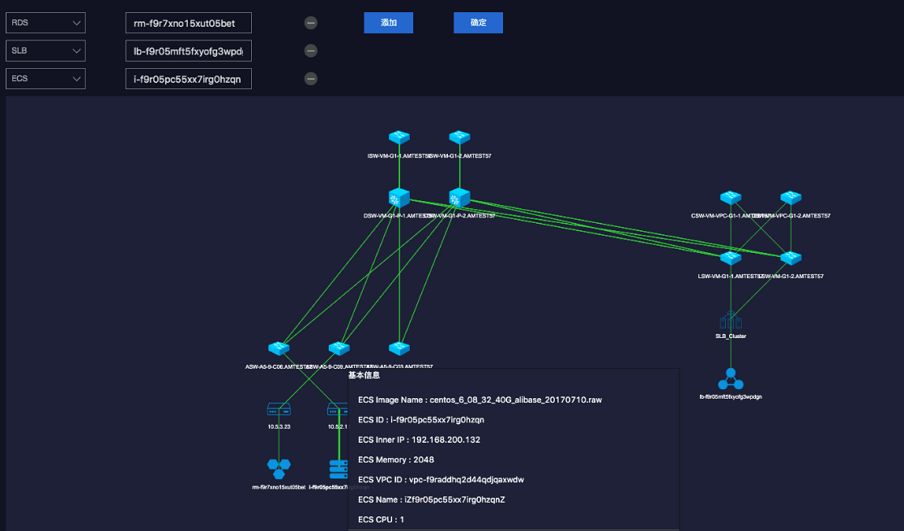
相信有了这套机制,就不在害怕线上问题的定位了。
在大多数场景下,Node.js 服务都是要为前端提供接口服务,因此全链路日志也要将前端日志也要一起纳入全链路流程中,这也是其他后台服务相对比较少考虑的。
首先要和调用方约定通用 TraceId 的协议,例如本项目在前端和后台服务中都是采用了内部上报 SDK(IMLOG SDK),因此约定前端会在请求中带上前端日志的 TraceId 放到 http/request/header/X-Request-Id 属性,这个 TraceId 的生成都是采用 uuid 来生成唯一性的 ID。
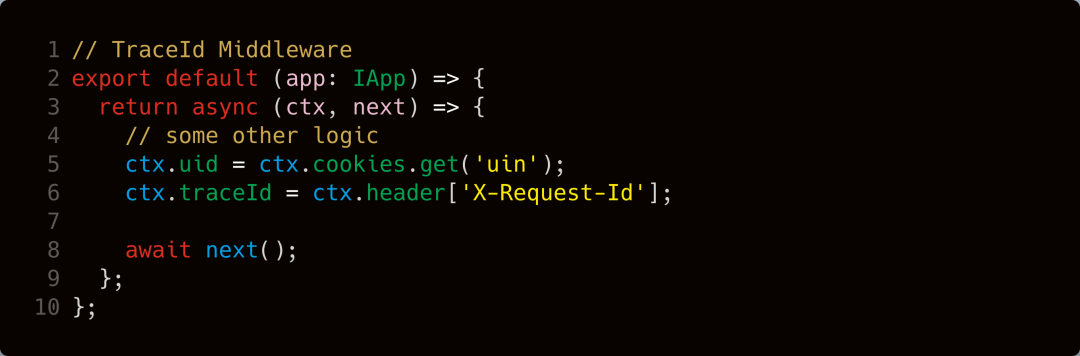
假如你的日志上报是走的自定义日志上报,则需要在 Node.js 的 MiddleWare 中对所有请求和第三方调用进行统一的 TraceId 进行覆盖和传递,类似下面的方式。
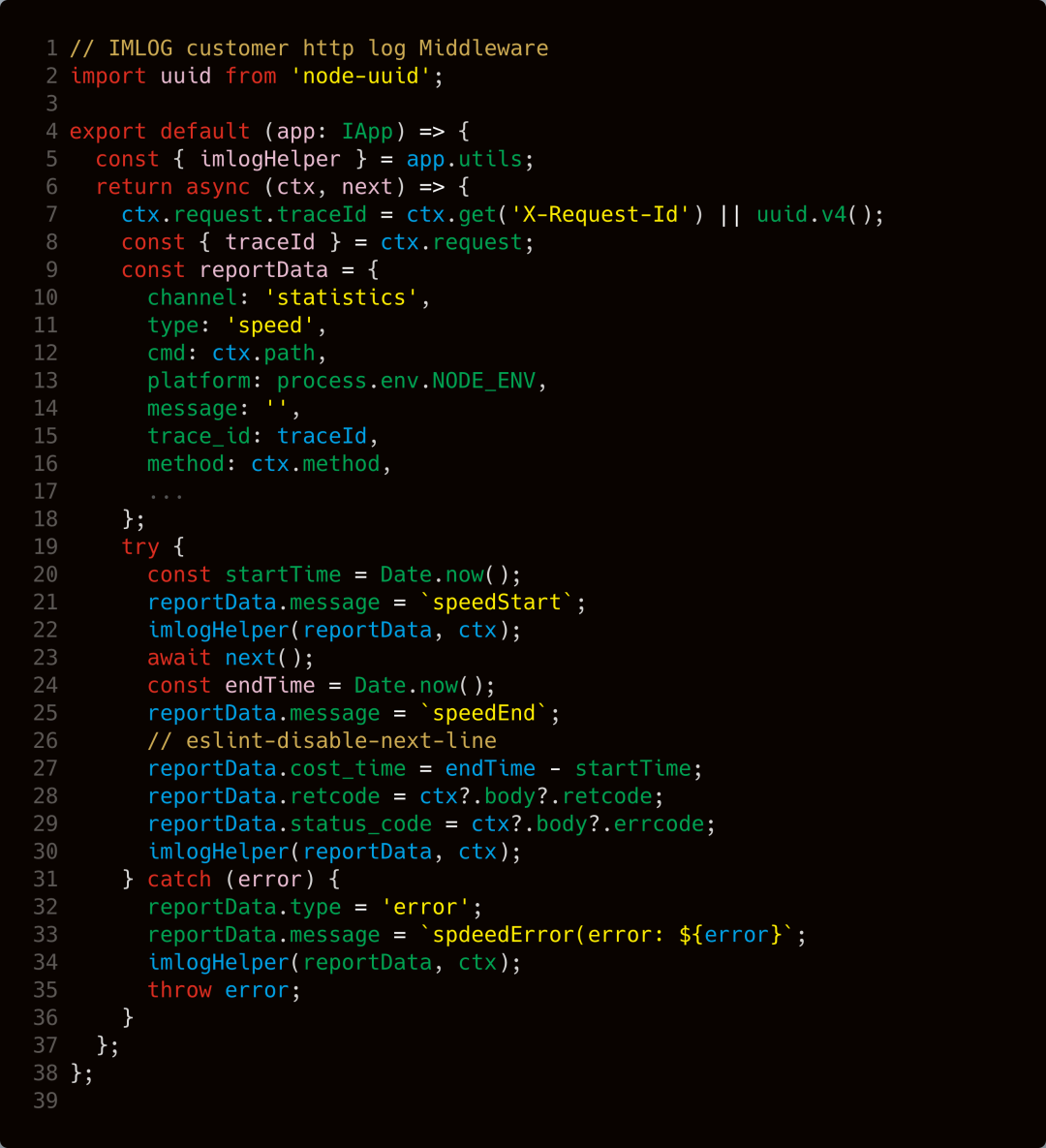
本项目采用的是 imserver-monitor 集成 SDK 进行了自动化上报,它集成了这部分设计:
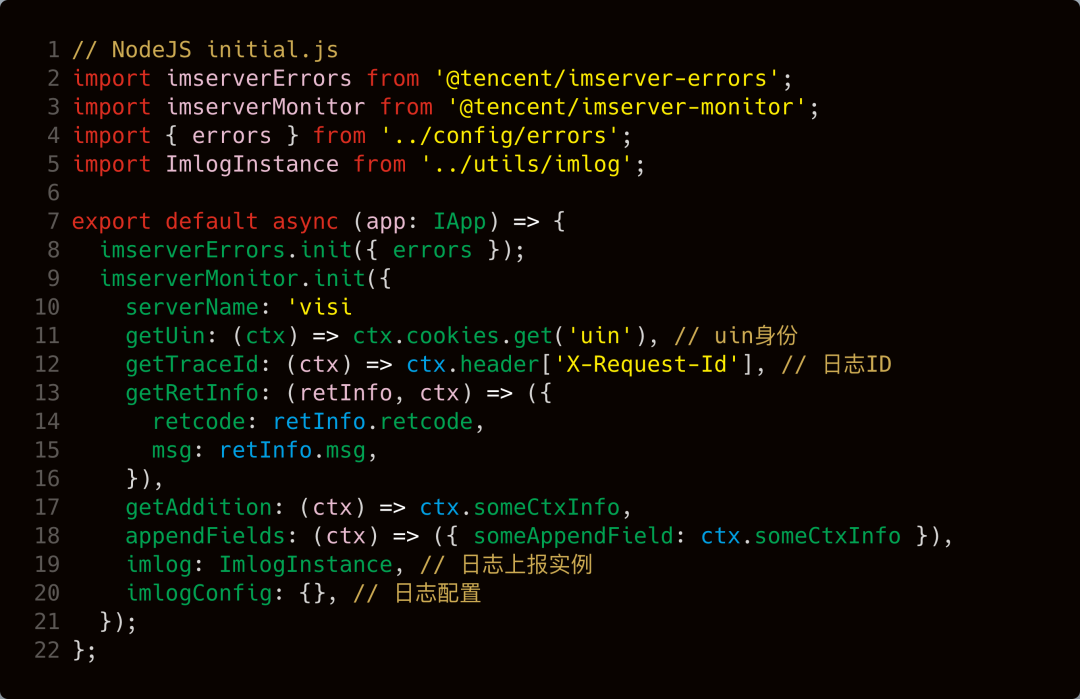
针对第三方调用,也是需要对调用函数进行封装,使其自动上报 ctx 上挂载的 trace_id,例如本项目的异步上报封装的 axios 组件,则是封装了异步请求调用、队列管理、日志上报和返回监控等能力。
最终是将前端日志、服务器日志、第三方调用通过唯一的 trace_id 进行全链路串联起来,方便开发快速定位问题。
日志的科学利用
当然日志的用途不仅仅是应用于问题排查,它还具有业务分析、日志报警等功能,例如在内部容器平台(TKEx-CSIG)上配置容器状态报警:

方便快速预警和响应线上故障。
本项目中使用的内部上报 SDK(IMLOG SDK),它兼顾了日志检索 Kabana:
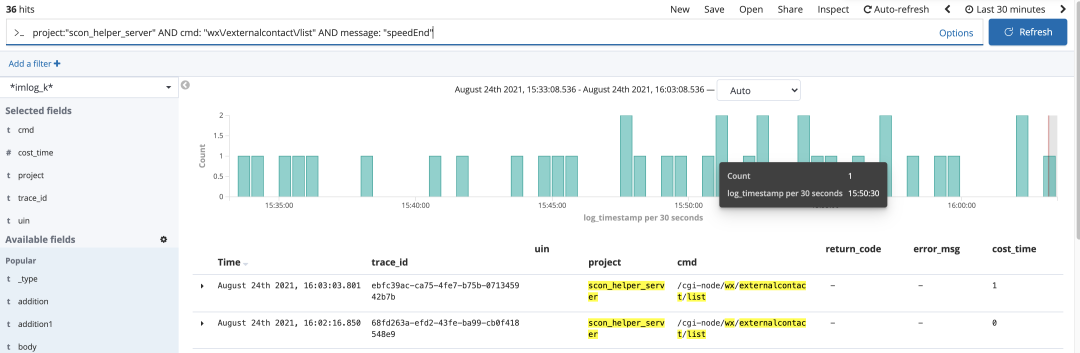
日志分析 Grafana:兼顾可视化分析和报警。
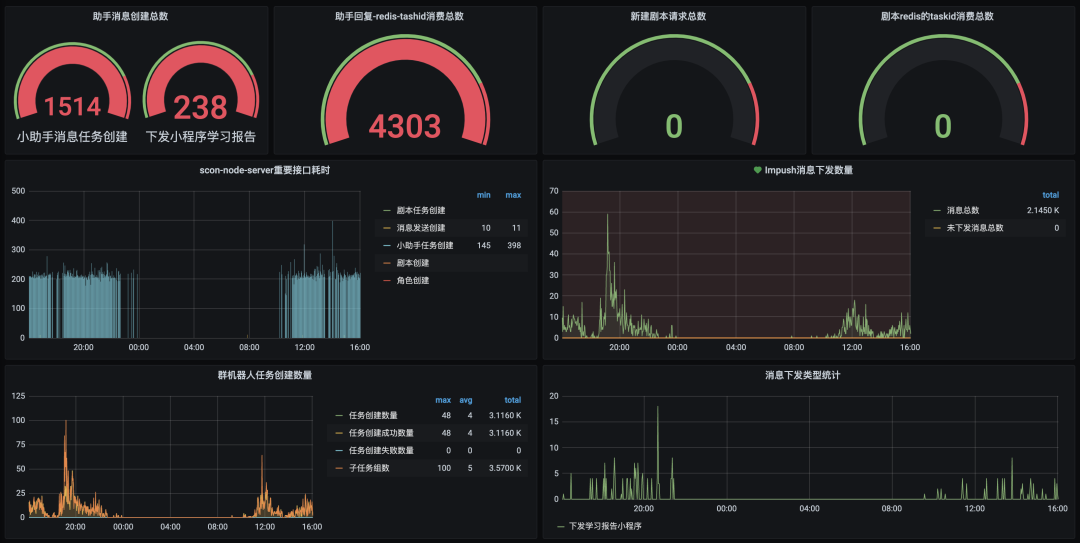
自定义日志开发
业务开发过程中必然存在大量自定义日志开发,首先关于上报字段的选择,这里我建议尽量按照成熟的上报平台的字段约定来上报,这样减少你在日志分析过程的沟通成本,因为分析工作大部分是由数据组的专业同事支持,日志不规范,同事两行泪,血的教训。这里给大家介绍下我们团队内部约定的一些核心字段,仅供参考。
{
"mapping": {
"k12": {
"properties": {
"additional": {
"type": "text"
},
"cmd": {
"type": "keyword"
},
"cost_time": {
"type": "integer"
},
"error_msg": {
"type": "text"
},
"ext": {
"type": "keyword"
},
"geoip": {
"properties": {
"location": {
"type": "geo_point"
}
}
},
"log_level": {
"type": "keyword"
},
"log_timestamp": {
"type": "date",
"format": "epoch_millis"
},
"parent_span_id": {
"type": "keyword"
},
"project": {
"type": "keyword"
},
"request_ip": {
"type": "ip"
},
"return_code": {
"type": "integer"
},
"return_code_2": {
"type": "keyword"
},
"server_ip": {
"type": "ip"
},
"source": {
"type": "keyword"
},
"span_id": {
"type": "keyword"
},
"trace_id": {
"type": "keyword"
},
"uin": {
"type": "long"
},
"url": {
"type": "keyword"
},
"wns_code": {
"type": "keyword"
}
}
},
"_default_": {
"properties": {
"additional": {
"type": "text"
},
"cmd": {
"type": "keyword"
},
"cost_time": {
"type": "integer"
},
"error_msg": {
"type": "text"
},
"ext": {
"type": "keyword"
},
"geoip": {
"properties": {
"location": {
"type": "geo_point"
}
}
},
"log_timestamp": {
"type": "date",
"format": "epoch_millis"
},
"project": {
"type": "keyword"
},
"request_ip": {
"type": "ip"
},
"return_code": {
"type": "integer"
},
"return_code_2": {
"type": "keyword"
},
"server_ip": {
"type": "ip"
},
"trace_id": {
"type": "keyword"
},
"uin": {
"type": "long"
},
"url": {
"type": "keyword"
},
"wns_code": {
"type": "keyword"
}
}
}
}
}自定义日志开发一定要注意性能的优化,在项目的初期,大量使用了 JSON.stringify 对 DB 查询实例、request 实例进行了格式化,导致压测性能指标一直上不去,后来发现是由于 JSON.stringify 性能不佳和对复杂对象进行了错误格式化。后续就替换了 fast-json-stringify 工具,将数据库查询实例通过 toJSON 方法转化成单纯的 JSON 之后再进行格式化,提升日志处理的性能。
结语
到这里本人探索 Node.js 后台服务开发过程中的日志开发经验分享就结束了,但是这并不是日志开发的全部,也有很多领域需要继续探索,例如如何实现常规日志中的部分核心日志进行持久化存储、数据导出和数据分析。
希望本文能够为大家探索 Node.js 开发提供有益的参考,也可以在评论区中沟通交流分享经验哈。