微服务系列--聊聊微服务中的接口调用
今天是1024程序员节,首先预祝各位同行们节日快乐!

这次打算整理一期关于微服务系统中接口调用中的相关内容。
在大多数的互联网集群当中,我们通常都是会采用http接口的方式供前端去进行调用,而后端之间的服务调用主要还是会采用rpc的方式进行相互通信。这些相互通信的服务之间可以借助比较常见的如dubbo,grpc,feign,或者一些自研的通信框架。
那么今天我们主要来从http接口的调用规范聊起。
HTTP接口调用设计
在大多数互联网企业的微服务项目中,开发团队都可能会是采用SpringBoot作为web框架去部署应用,大多数时候都会采用到以下注解:
- @RequestMapping
- @GetMapping
- @PostMapping
- @DeleteMapping
- @PutMapping
@RequestMapping
这个注解是Spring框架的web模块中比较早期的一款注解,声明了某个接口支持http协议的调用,同时内部支持设置请求的方法类型,url,以及application-context类型。
使用案例:
例如我们对整个controller的context-type类型都统一设置为application/json的格式,那么便会对整个controller内部的context-type都进行格式的设置,例如我们设置了一个只支持x-www-form-urlencoded格式请求类型的Controller。
@RestController
@RequestMapping(value = "/form-url",consumes = "application/x-www-form-urlencoded")
public class FormUrlEncodedController {
@GetMapping(value = "/test-url")
public void testUrl(){
System.out.println("this is testUrl");
}
}那么当http请求携带了不符合预期的格式时,便会抛出以下异常:
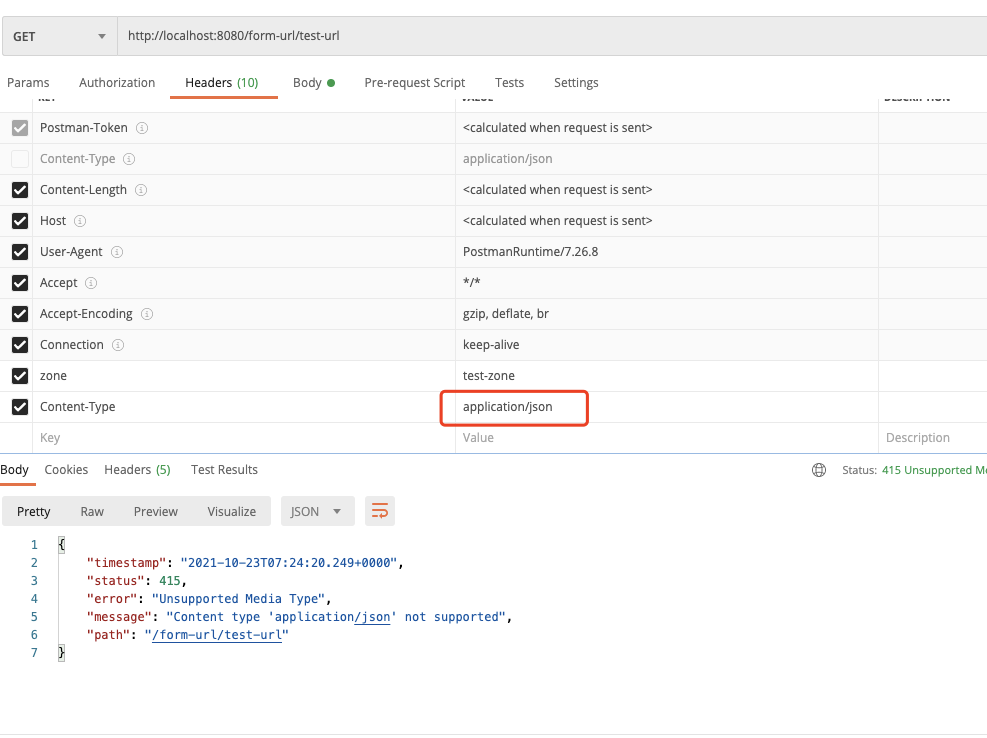
至于其他的几款注解,其实按照名字来看,就很容易理解其内部具体定义了。
@GetMapping
@PostMapping
@PutMapping
@DeleteMapping
主要的差别就在于能够接收的请求类型有所出入。
统一接口的请求类型
如果整个controller都希望统一接收参数的类型以及响应的类型,那么可以在controller的头部做如下声明:
@RestController
@RequestMapping(value = "/simple",
consumes = MediaType.APPLICATION_FORM_URLENCODED_VALUE,
produces = MediaType.APPLICATION_JSON_VALUE,
headers = "version=6.11.2")
public class SimpleRestController {
@GetMapping(value = "/do-test")
public void doTest(){
System.out.println("this is test");
}
}统一设置了header请求的类型,响应类型,以及header中需要携带的版本号,这样可以申明该接口提供给指定版本app的请求。
HTTP请求中的一些规范案例介绍
采用@PathParamter方式接收参数
先来看看以下代码案例:
@RestController
@RequestMapping(value = "/path-parameter")
public class PathParameterController {
@GetMapping(value = "/do-test/{id}")
public void doTest(@PathVariable("id")Integer id){
System.out.println("this is do-test, id is: "+id);
}
}
通过在url中通过路径url的某段内容作为请求参数id。这种风格的接口看似简单,但是其实存在一定的隐患:
- 接口url规律性差,不方便日后做一些线上流量的监控
如果大家有了解过监控系统开发的原理就会发现,其实这类型的url是非常难做流量监管的。(可以思考对于url的日请求频率,限流等方面去思考这个问题。)
例如:我们希望开发一个html页面,展示每个url的日调用量情况,并且通过统计图的形式展现出来。倘若上述接口中传输的id多达上万个,那么这个监控的html页面中就有可能会有上万个统计图。所以个人并不是太推荐在团队开发中使用这种方式来编写接口。
关于APP中不同版本请求接口的平滑升级设计
做过app应用后端接口开发的朋友们应该大多都会遇到过apk进行更新之后,如何在原有接口的基础上兼容老流量的场景。
简单的接口升级
只是简单的url接口升级的话,通过使用if else判断即可,不需要太费心思。
@RequestMapping(value = "/app-version")
public class AppVersionController {
@GetMapping(value = "/do-test")
public void doTest(HttpServletRequest httpServletRequest){
String appVersion = httpServletRequest.getHeader("app-version");
if("1_0_1".equals(appVersion)){
//todo
}else if ("1_0_2".equals(appVersion)){
//todo
}
}
}
整个Controller的升级
可以考虑在对应的url中写入相关的版本号,例如下边的这种
@RequestMapping(value = "/1_0_1/app-version",headers = "version="+VERSION_1_0_1)
public class NewAppVersionController {
//todo
}
@RequestMapping(value = "/app-version",headers = "version="+VERSION_1_0_0)
public class OldAppVersionController {
//todo
}
大版本升级
如果是做系统重构的话,例如做一些微服务拆分之类的操作,这个时候后端的应用集群可能就是要面临拆解的操作,这个时候不妨可以通过搭建nginx之类的中转机器,根据重新设计的url将流量转发到不同的集群,例如:
http://www.xxx.com/api/wxp/opl/user/get-user-info //老接口
http://www.xxx.com/api/wx[/opl/user/v_2/get-user-info //新接口例如在所有请求的url中都包含一个识别服务版本的字段,然后通过nginx去做转发到不同的集群。
但是这种方式一般比较适合用于超大版本重构的时候采纳,例如单体服务拆解为多个微服务,对于日常的一些小版本升级采用header参数或者重写controller判断基本足够。
统一请求的context-type类型
统一的context-type类型可以方便日后运维部门对请求参数的统一采集与流量监控。
RPC调用的原理
在互联网应用中,用户和服务之间的通常会选择采用http的方式进行相互通信,而内部应用之间则通常会选择RPC进行相互调用。
RPC的特点
与传统的http请求相比,传输效率高,发起调用的一方无需知道RPC的具体实现。其调用的基本都有以下共性:
首先通过一个本地的client stub去寻找对应的远程接口,然后发起网络请求,请求抵达到服务端的server stub之后,在服务端处理好计算逻辑再返还给client stub。
在传输的过程中可能需要涉及到相关的网络数据编解码问题。
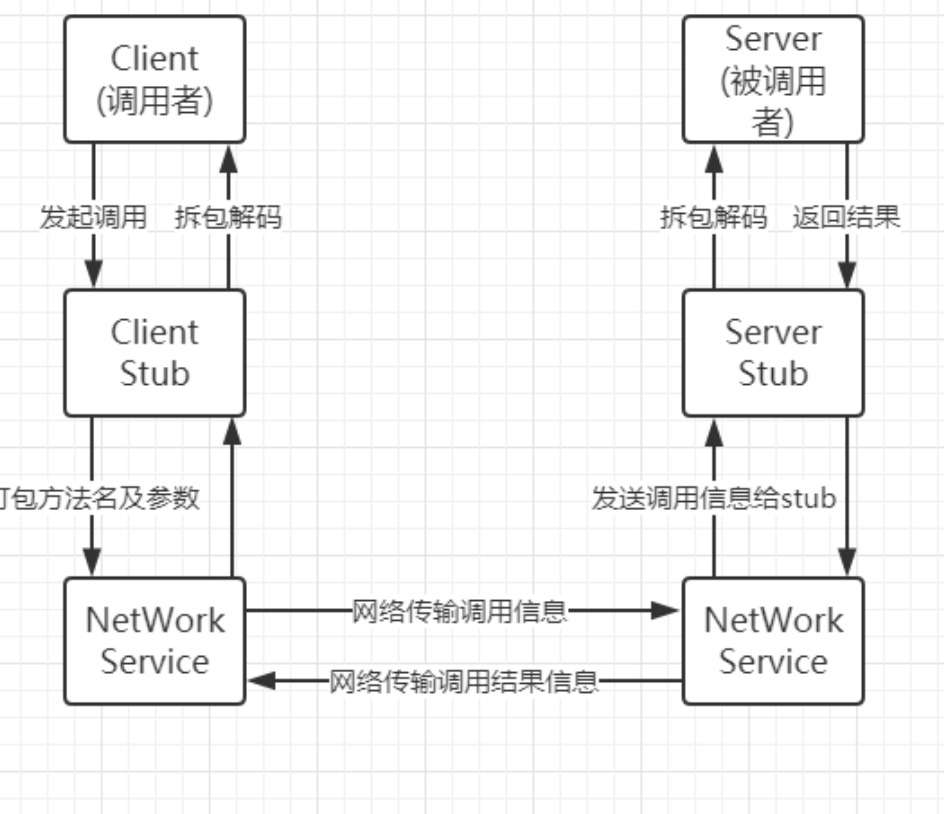
整条链路下来的核心主要在数据的传输编解码和链路的调用上。
数据是如何被编解码的
这里就需要我们重新拾起早期学习计算机原理的知识点了。
| 原码 | 反码 | 补码 | |
|---|---|---|---|
| 正数 | 本身 | 本身 | 本身 |
| 负数 | 最高位为1,剩余还是原码 | 除了最高位之外,其余取反 | 自身反码去掉符号位之后加1 |
举几个栗子:
18的原码和反码,补码都是 10010
-18的原码是:110010
1byte可以存储多少个无符号数字?其区间是多少呢?
1byte中有8个bit位,所以当存储的是无符号数字时,最大的数值存储结构和最小值的存储结构如下:
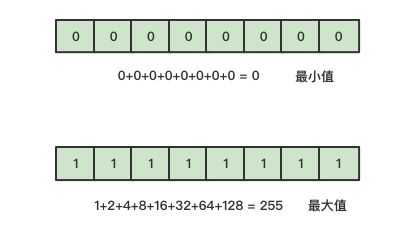
所以在存储无符号数字时候,1byte所能存储的大小范围是0-255.
但是通常我们在业务开发中还是会使用有符号数字的,例如一些错误的状态码可能会用负数来表示,一些初始化字段可能会使用-1来替代。
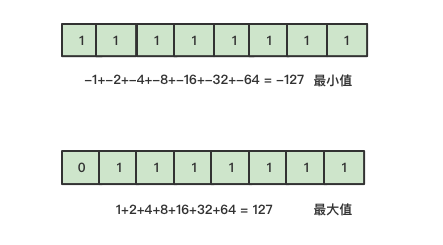
1byte可以存储多少个有符号数字?其区间是多少呢?
所以当存储的数字是个有符号数字时候,通常会将byte的第一个bit位用于表示是正数还是负数。整体的存储区间为-127~127,存储结构如下所示:
用java代码实现一段字节数组和数字之间转换的案例:
/**
* 字节转成数字 int 大小是4个字节
*
* @param bytes
* @return
*/
public static int byteToInt(byte[] bytes) {
if (bytes.length != 4) {
return 0;
}
return (bytes[0]) & 0xff | (bytes[1] << 8) & 0xff00 | (bytes[2] << 16) & 0xff0000 | (bytes[3] << 24) & 0xff000000;
}
/**
* 数字转成字节 int 大小是4个字节
*
* @param n
* @return
*/
public static byte[] intToByte(int n) {
byte[] buf = new byte[4];
for (int i = 0; i < buf.length; i++) {
buf[i] = (byte) (n >> (8 * i));
}
return buf;
}运算符知识补充:
&(按位与)
&按位与的运算规则是将两边的数转换为二进制位,然后运算最终值,运算规则即(两个为真才为真)1&1=1 , 1&0=0 , 0&1=0 , 0&0=0
3的二进制位是0000 0011 , 5的二进制位是0000 0101 , 那么就是011 & 101,由按位与运算规则得知,001 & 101等于0000 0001,最终值为1
7的二进制位是0000 0111,那就是111 & 101等于101,也就是0000 0101,故值为5
|(按位或)
|按位或和&按位与计算方式都是转换二进制再计算,不同的是运算规则(一个为真即为真)1|0 = 1 , 1|1 = 1 , 0|0 = 0 , 0|1 = 1
6的二进制位0000 0110 , 2的二进制位0000 0010 , 110|010为110,最终值0000 0110,故6|2等于6
^(异或运算符)
^异或运算符顾名思义,异就是不同,其运算规则为1^0 = 1 , 1^1 = 0 , 0^1 = 1 , 0^0 = 05的二进制位是0000 0101 , 9的二进制位是0000 1001,也就是0101 ^ 1001,结果为1100 , 00001100的十进制位是12
<<(左移运算符)
5<<2的意思为5的二进制位往左挪两位,右边补0,5的二进制位是0000 0101 , 就是把有效值101往左挪两位就是0001 0100 ,正数左边第一位补0,负数补1,等于乘于2的n次方,十进制位是20
>>(右移运算符)
凡位运算符都是把值先转换成二进制再进行后续的处理,5的二进制位是0000 0101,右移两位就是把101左移后为0000 0001,正数左边第一位补0,负数补1,等于除于2的n次方,结果为1
~(取反运算符)
取反就是1为0,0为1,5的二进制位是0000 0101,取反后为1111 1010,值为-6
>>>(无符号右移运算符)
无符号右移运算符和右移运算符的主要区别在于负数的计算,因为无符号右移是高位补0,移多少位补多少个0。
15的二进制位是0000 1111 , 右移2位0000 0011,结果为3
所以如果要对一个int数字转换为byte数组格式,那么此时可以借助jdk内置的右移操作符>>,按照8个比特位的大小将数字进行移动。同理如果要将byte数组转换为int只需要将逻辑反过来,使用或运算即可。思路可以查看上方的案例代码。
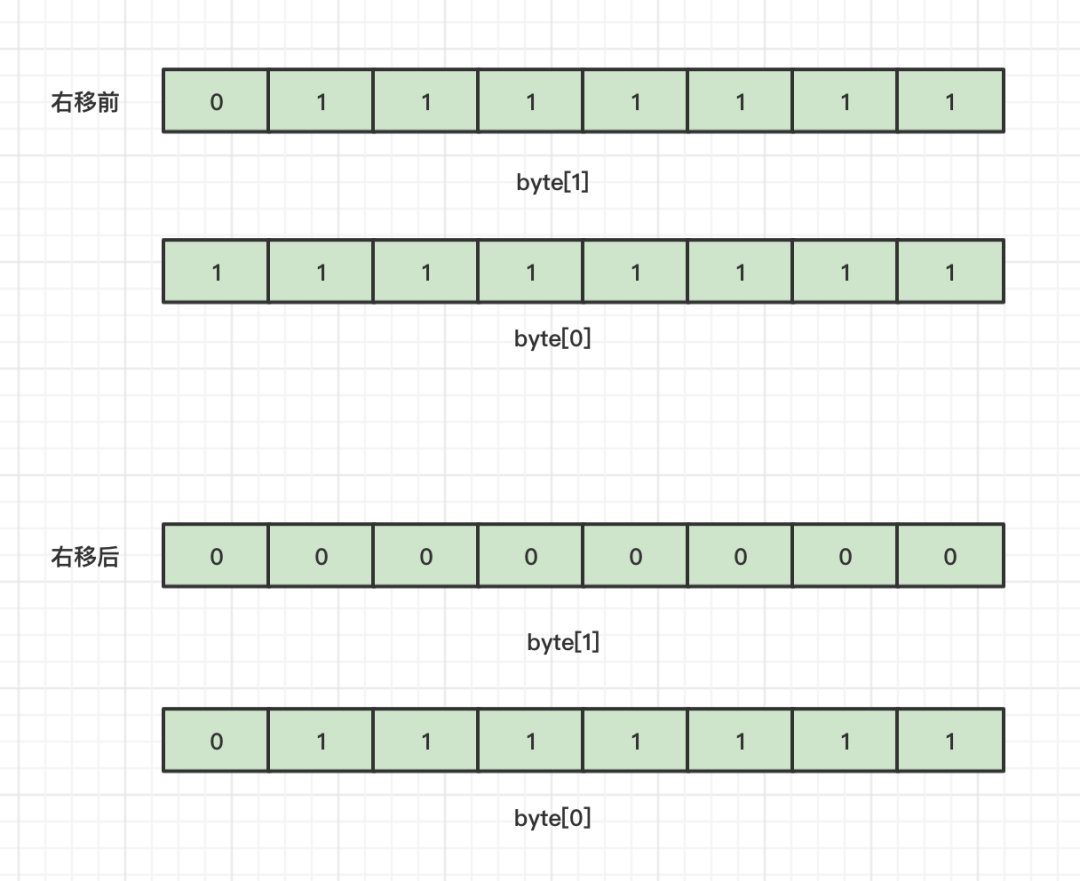
了解了数字如何转换为字节数组之后,那么String类型的数据也好处理了,无非就是将每个字符转换为对应的ASC编码即可。
而RPC通信部分的数据信息序列化和反序列化关键就在于将数据转换为二进制格式传输给对方,对方接受二进制数据之后再转换为对应的格式。