深入理解一致性与 C++ 内存模型
本文旨在对计算机科学下的一致性模型以及 C++ 的内存模型做一个系统的、深入浅出的介绍。一共 3 个 章节:第 1 章介绍一致性模型,第 2 章介绍 C++ 内存模型,第 3 章是参考资料。
1 . Consistency model
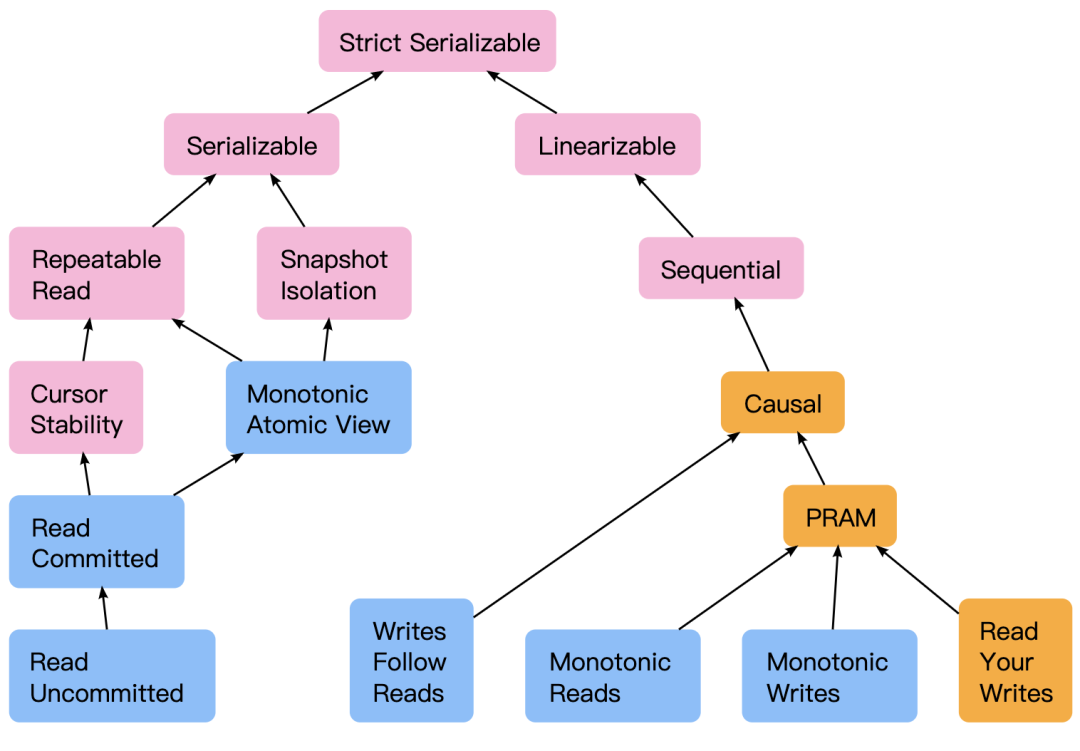
右面的分支表达了 operations 之间的顺序以及可见性,左面的分支表达了 operations 作为 group 时的特性,比如一组 operations 可能需要和另一组 operations 具有某种组级别的作为整体来看的一致性语义,一般来说就是事务性,要满足一定的完整性约束。下面分别就两个方向所涉及到的各种主要的一致性概念进行介绍。
1.1 Non Transaction
本节关于一致性的介绍是按照严格到放松的顺序来介绍的,在每一个一致性介绍的开始处都有相比较上一个一致性的说明,因此最好按照顺序去理解概念。
Data-centric consistency models
严格一致性 Strict consistency
严格一致性是最强的一致性保证,任意处理单元对变量的写入要求对所有处理单元立刻可见。
可以看出这样实现对性能的影响非常不好,需要有很大的通信开销来保证可见性,实际上基本没有实现这个一致性级别的系统。
线性一致性 Linearizability(Atomic consistency)
线性一致性不是一个很容易深入理解的简单概念,很多人都误会线性一致性为作用在一个对象上的概念,其实这么理解是错误的,线性一致性没有作用到一个对象上的约束,如开头分类时提到的,只不过没有对 operations 进行 group 行为(一般来讲就是事务性)的约束而已,是面向多对象下一般化场景的。线性一致性没有严格一致性要求的那么强,只是“看起来像”严格一致性,没有那么强的瞬时性(instantaneousness)要求。这里分两个方面介绍线性一致性:一个是个人的提炼直观理解,一个是 wikipedia 中的定义。
- 直观理解
对于一个系统如果所有 调用(Invocations) 和 响应(Responses) 从特性上描述满足如下条件,则满足线性一致性:
- 满足 real-time,即在 invocation 和 reponse 之间产生影响。
- 具有原子性,不会比如因为 client 自身的 retry 导致一个自增动作执行多次。
- 正式定义
Wikipedia 中更正式的概念是(解释翻译版,Wikipedia 词条中有原文)。
对于一个 invocations 和 responses 的历史 H,如果满足下面的条件则 H 就是线性化的:
- 对于 H 中完成的所有操作,返回的结果必须等价于某一个操作看成原子(invocation 得到 reponse 是立刻的) 的情况下构成的串行执行的历史。
- 实际执行过程中如果一个操作 op1 在另一个操作 op2 完成之前,那么在 H 中 op1 也必须在 op2 之前。
换句话说:
- H 的所有 invocations 和 responses 可以被重排序成一个按顺序(串行)的历史;
- 如果满足程序的语义(sequential definition of the object or semantics of the program),则这个顺序历史就是正确的;
- 如果在原始的历史中一个响应在另一个调用的前面,那在重排序的顺序历史中也必须同样如此。
单看概念有点抽象,下面举个例子。假设有这样一个并发执行下的 real-time 观察到的历史:


根据 wikipedia 定义中的规则,我们可以 reorder 出下面几个符合规则的调度历史:


如果在原始的历史中一个响应在另一个调用的前面,那在重排序的顺序历史中也必须同样如此。
那么现在有了这些,我们怎么判定 H_C 是一个正确的历史?答案就是只要任何一个根据 reorder 规则得到的调度历史是正确的(如果满足程序的语义 sequential definition of the object or semantics of the program),则 H_C 就是一个正确的历史,这个调度就是线性化的。进一步,如果一个系统所有的历史都是线性化的,则这个系统是满足线性一致性的。
上述的描述还是有一点太抽象,这里给出直观的解释。
- 满足程序序:reorder 的时候不会破坏具有时序关系的操作的顺序,但是对于并发的操作 reorder 的时候顺序任意,因为并发了本身结果就是无法预测,进而怎么 reorder 都可以。
- 对于 reorder 之后得到的调度历史,只要有任何一个满足程序的语义,则可以认为这个调度就是正确的。为什么任何一个正确就可以认为实际的 real-time 历史是正确的?可以分为两个方面:
a . 没有并发。按照 reorder 规则,非并发的由于不会破坏 real-time 的 操作顺序,那么 reorder 之后只会有一个 real-time 的实际调度,这个调度的正确性就是代表了实际 real-time 历史的正确性。 b . 有并发。按照 reorder 规则,并发的部分才可以任意 reorder,所以 reorder 的所有历史都只是不同并发 reorder 之后的组合得到的结果集,并发本身就是不确定的执行序,只要 reorder 得到的历史有任何一个正确,那么就可以认为实际执行就是这个顺序,也就是这个正确的顺序。
下面 wikipedia 给出的例子可以更为直观的理解这件事,两个线程 A 和 B 去拿同一个锁,执行的 real-time 实际历史 H_C 如下:



现在根据上面提到的直观的解释来理解这件事:根据 real-time 实际历史可以看出,A 和 B 在并发争锁,所以谁先谁后是不确定的,因为并发,所以也就能 reorder 出 2 个 结果了,并发本身执行序就不可确定,所以怎么解释都是可以的,又因为第 2 个 reorder 的历史是满足正确调度的程序语义的,则可以作为并发执行过程的解释,所以实际历史满足线性一致性。
顺序一致性 Sequential consistency
顺序一致性相对严格一致性和线性一致性有了一些放松,放松了对 real-time 的要求,不要求立刻可见,但是要求:
- 单个处理单元内要满足程序序
- 所有处理单元的内存操作具有全局序,即每个处理单元见到的内存操作顺序是一致的
由于没有 real-time,所以只能通过程序序后面的逻辑观察基于全局序来推导出被观察事件的发生,进而得到同步点。
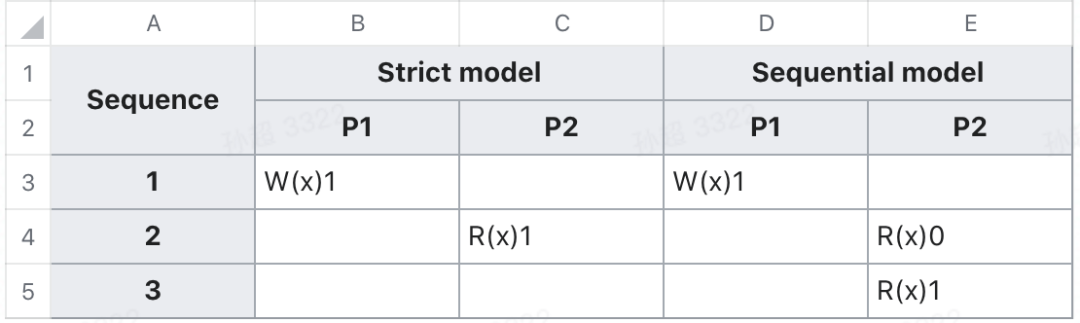
一个 wikipedia 的例子:其中 x 的初始值是 0,P 代表 processor, W 代表 write,R 代表 read。
因果一致性 Causal consistency
因果一致性相对顺序一致性又有一些放松,不仅没有 real-time 的要求,不再要求所有操作的全局序,只要求具有因果关系操作的全局序。同样的由于没有 real-time 的保证,所以只有观察到了果,才能得到因发生的结论。
因果关系:如果一个处理单元执行了一个写操作 A,自己或者另一个处理单元观察了 A 之后执行了写操作 B,则 A 是 B 的因,也就是 Lamport's happened-before A -> B 关系。
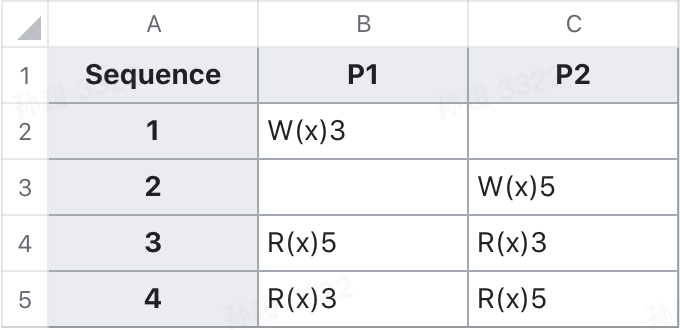
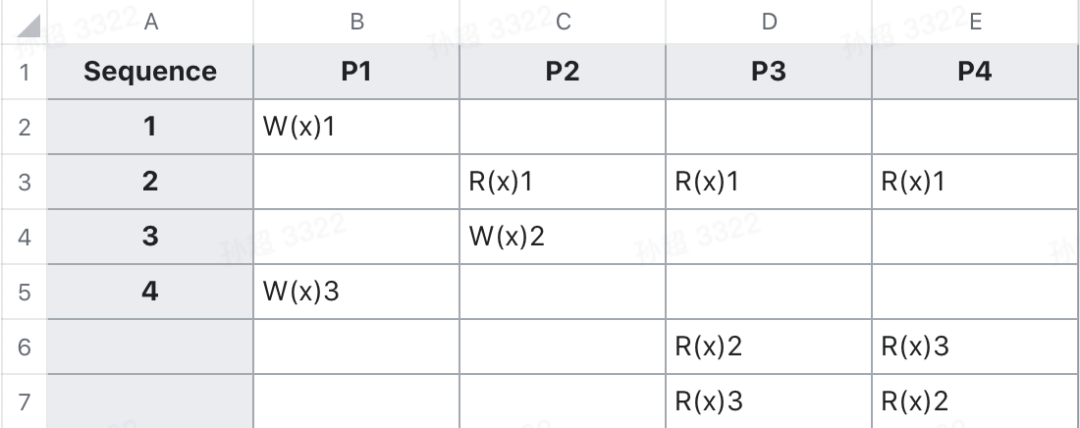
因果一致性保证了在处理单元之间具有因果关系的操作间的全局顺序,但是不保证没有因果关系的操作间的顺序。可以通过下面 2 个 例子加深一下理解。
PRAM(Pipelined RAM consistency, or FIFO consistency)
PRAM 要求所有处理单元观察到的同一个处理单元的写入满足其写入的顺序,但是不同处理单元观察到的不同处理单元的写入的顺序没有保证。
Client-centric consistency models
对于强调 AP 的系统来说,为了性能和可用性,经常会放松一致性的要求。但是往往也需要一定的 client session 级别的规范化的一致性语义,可以称之为 “Session Guarantees for Weakly Consistent Replicated Data”。这一部分介绍 4 个 常见的 Session guarantees 下的一致性模型。
Read Your Writes
在一个 session 内,读取会得到最近写入的值。比如初始值为 0,如果写入了 1,之后再读取,那么一定会得到 1 而不是 0。但是对于跨 session 则没有这样的保证,比如其他 sessions 写入,本 session 则不一定会读取到其他 sessions 的写入。
Monotonic Reads
Monotonic Reads 相比 Read Your Writes 弱,没有了 session 内 real-time 可见性的保证,只要求在一个 session 内,读取永远不会回退。比如写入序列为 1、2、3、4,一旦读取到了 2,就永远不会再读取到 1,只会读取到 3 或者 4。
Writes Follow Reads
这个定义本身描述比较复杂,这里简单描述就是:对于一个 session,如果一个写 W2 在读 R1 之后,并且 R1 是在 server S1 在 t1 时刻发生的,则对于任意其他的 server S2,如果 W2 同步到了 S2,则 S2 需要包含 S1 中对 R1 产生作用的所有写 Wall,且 WriteOrder(Wall, W2)。
可以看出 Writes Follow Reads 不同于前两个只规范单个 session 内的一致性,也会要求一个 session 内的顺序在所有 servers 上同步,因而也就具备了跨 session 的同步能力,基本上和 PRAM 是很相似的,一个 session 可以看成一个 pipeline。
Monotonic Writes
类似于 Writes Follow Reads,monotonic writes 要求对于一个 session,如果 W1 在 W2 之后,那么对于任意 servers,如果同步到了 W2,那么也必然同步了 W1 且 WriteOrder(W1, W2)。
1.2 Transaction
这里只介绍串行化相关的概念,因为这个概念是理解一切事务隔离级别的基础,最难理解也最为重要。为了精简概念突出重点,其他的非可串行化的一致性本文都没有做说明。
串行 (Serial)
事务一个接着一个的执行,完全没有并行,也就是说事务之间没有时间上的交叠,一个事务的所有操作一定是在另一个事务之前。可以看出串行化调度性能不怎么样,不论是不是冲突的部分都得串行执行。
可串行化 Serializability
对事务 T1,T2,...,Tn 调度的执行产生了一个历史,如果这个历史的影响等价于任何一种 T1 到 Tn 的串行组合的执行结果,称这个调度是可串行化的。可以看出可串行化调度放松了约束,不要求一个接一个执行,只要等价于某一种串行化调度就可以了。这样的定义本身也比较泛泛,对于具体如何等价没有明确的说明。下面则对如何等价进行了定义,进而发展出来几种等价关系概念下的可串行化模型。
可串行化的一节的 2 点 说明:
- 由于没有找到比较好的对这几个概念的翻译,这里的 终态和视图可串行化 都是个人的翻译,这一点需要注意。
- 由于终态可串行化和视图可串行化实际上没有实现的,而且由于 Herbrand semantics 概念也相对复杂,就不过多介绍了,只是简单说明,否则就背离了本文的目的。
下面对可串行化下的概念进行介绍,其中 Herbrand Semantics of Steps、Herbrand Universe 和 Schedule Semantics 三个概念没兴趣可以不去了解。另外对于后面的每一个可串行化概念,都可以不看定义,直接看图下的文字解释。
Herbrand Semantics of Steps



终态可串行化通过终态等价关系来定义,由于其等价关系是不完整的,且验证复杂度太高,所以实际中没有使用的。
- 终态等价

简单来说,对于两个调度 s 和 s',如果他们的所有操作相同,并且每一个数据项的最后写入相同,则 s 和 s' 是终态等价的。
- 终态可串行化

总结
终态可串行化实际没有应用的,且不说终态等价的验证复杂度,从定义可以看出对于终态的等价性上并没有考虑只读事务的终态,而这会导致读不一致异常的发生:

既然终态可串行化没有考虑读会导致等价关系不完整进而会出现异常,那么想办法让整个验证完整不就行了么?视图可串行化就是这样的背景产生的,视图可串行化会验证调度中每一个步骤的等价关系。
- 视图等价

简单来说,对于两个调度 s 和 s',如果满足终态等价的要求之外,还要满足 过程中每一个操作的 Herbrand 语义(上下文和作用效果) 相同,则 s 和 s' 是视图等价的。
- 视图可串行化

由于 视图等价 基于 终态等价 的等价关系之外额外附加了调价,所以可以直观的了解到:VSR ⊂ FSR。
总结
由定义可以看出,视图可串行化要求非常严谨,会要求整个事务过程的所有过程必须等价,这导致验证的开销会非常大,所以实际中没法应用。验证调度是否是视图可串行化的是一个 NP complete 问题:

更进一步,引起调度是非串行化的根本原因是事务的操作之间有 read-write 或者 write-write 冲突,无冲突的部分互相无关,不会对彼此造成影响。因此基于这个出发点,就有了相比视图等价进一步缩小约束范围的冲突等价性,即只考虑冲突部分的等价关系。

- 冲突等价

- 冲突可串行化

总结
冲突可串行化是主流数据库系统中实现串行化隔离级别最为常见的模型。一般通过 Two-Phase Locking Protocol 来实现,另外主流数据库也都是 SS2PL 的方式来实现,这一点可以参考 Wikipedia Two-Phase Locking。
严格可串行化 Strict Serializability
通过上述对可串行化的定义可以看出,只要求等价性,并没有 real-time 的约束,也就是说任意事务可以任意乱序。比如对于 T1, T2 和 T3,T1 和 T2 有并发,T3 时序上在 T1 和 T2 之后,前面提到的可串行化可以调度成最终结果等价于 T3 -> T1 -> T2 这样一个违背 real-time 的串行历史。
严格可串行化相比前面的可串行化,多了 real-time 的约束,所以对上述例子的调度结果只可能是等价于 T1 -> T2 -> T3 或者 T2 -> T1 -> T3。所以严格可串行化也是一个在可串行化概念上添加 real-time 额外约束衍生出来的概念。更多的理解可以参见下面外部一致性部分的内容。
读未提交 Read Uncommitted(Dirty)
一个事务读到了另一个进行中事务的中间结果。实现比如读和写的锁都仅限于读写的时刻,用完之后立刻释放。一般情况下应该没有人用这种隔离级别,这基本相当于没有事务,那也就没必要使用事务了,这里只是介绍一下概念。

读已提交 Read Committed(RC)
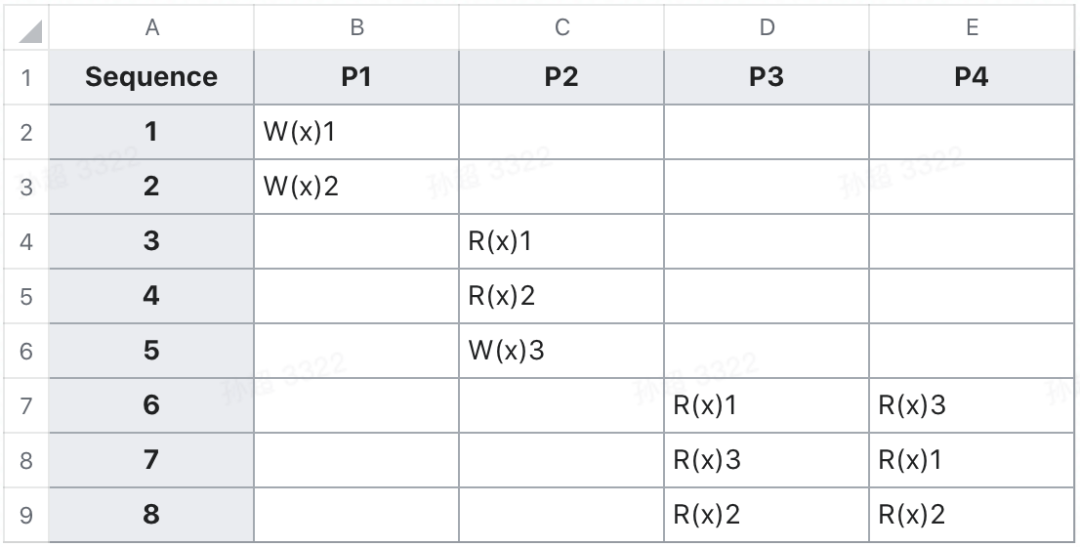
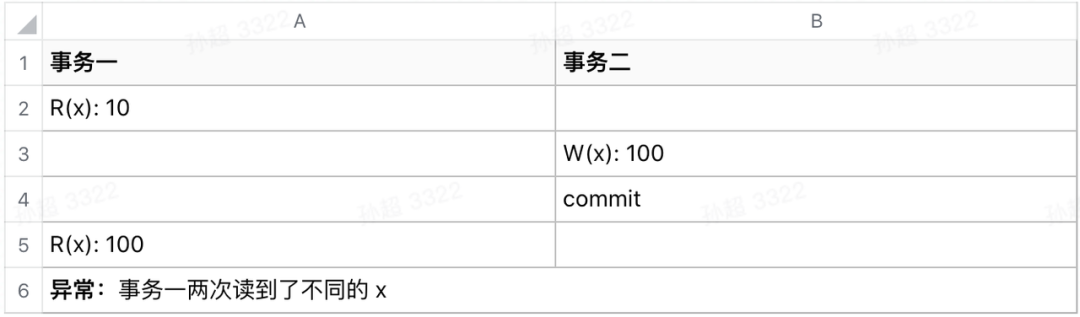
一个事务执行过程中可以读到另一个已提交事务的数据。存在不可重复读和幻读异常:事务进行中读到了不一致的数据。现实比如读的时候加锁但完成之后立刻释放,写的时候加锁且直到事务提交才释放。
可重复读 Repeatable read(RR)
一个事务执行过程中不会读到本事务具体行的其他事务提交的数据。存在幻读异常:事务进行中读到了不一致的数据。现实比如读写都加锁且持续到事务结束,但并没有加表锁,不相关的行还是可以变更。

快照隔离 Snapshot Isolation(SI)
事务是满足快照隔离的,不存在不可重复读和幻读。存在写偏斜(WriteSkew)异常:读和写之间没有并发控制。

一般化的隔离级别
由于 ANSI 提出的隔离级别比较老旧,不太能表达乐观锁和 MVCC 的情况,有人提出了更为精准的隔离级别的分类方法,这方面可以参考论文:《Generalized Isolation Level Definitions》。
1.3 外部一致性 External Consistency
外部一致性是一个相对泛泛的概念,可以分为 2 个方面:
- 用在非事务操作上,则等价于 Linearizability。
- 用在事务操作上,则类似于 Strict Serializability,比 Serializability 要强,相当于事务级别的 Linearizability,给事务调度加了 real-time 的约束但是并不要求瞬时性(instantaneousness)。简单来说假如有这样一个场景:事务 T1 和 T2,用户先执行了 T1 且提交成功之后再执行 T2。对于 Serializability 来说,先 T1 再 T2 或者先 T2 再 T1 都是满足语义的;但是对于 Strict Serializability 来说看起来就必须是先 T1 再 T2。
注:对于 Google Spanner 来说,除了上面描述的之外,还蕴含着内部数据物理时间与外部物理时间一致的外部一致性。另外还有只读事务以快照的方式读任意副本都能够保证读取到最近快照的外部一致性。
2 . C++ memory model
在第 1 章介绍了普遍意义下各个一致性模型的语义,那到了单机系统中,对于系统编程来说,面对着多核系统以及不同架构下的不同一致性语义,该如何理解不同内存模型下的一致性语义进而写出符合正确同步语义代码呢?本节要基于 C++11 定义的内存模型来展开讨论这个问题。
为了追求性能,各种 CPU 架构尤其是 ARM 提供的一致性模型都是比较松散的,在多 cores 间默认可以理解为是达不到 causal consistency 的,不仅硬件一致性协议会导致一致性的不确定,CPU 的流水线优化、乱序执行以及编译器的优化都会导致一致性的不确定性,因此我们想做到 causal 甚至 sequential 一致性就需要通过一定的同步语义来做到。在 C++11 之前 C++ 标准并没有给出相关的标准化规范,linux 侧都需要通过 programmer 基于 GCC 或汇编下的原子操作和内存屏障来达到目的,好在 C++11 抽象了相应的内存模型,从语言层面提供了同步语义。
我们这里不需要深入了解 MESI 协议在不同 CPU 架构下是有怎样的一致性保证以及如何人为做同步的,有了 C++ 内存模型这一层抽象,我们只需要面向 C++ 内存模型去实现就好了。所以这里不会对 MESI 及其衍生协议进行介绍,对于 programmer 来说其实意义不是很大,另外也不是本文的主题。
下面首先介绍 C++ 中用于同步的语义以及相关的概念;之后具体的基于不同原子操作提供的语义介绍如何建立同步语义。其他语言也是如此,只需要面向具体语言规范来理解和实现即可。
2.1 Concepts



因果关系,最初是由 Lamport 在 《Time, Clocks, and the Ordering of Events in a Distributed System》paper 中提出的 happened-before 关系发展而来。Lamport 在 paper 中称之为 happened-before,但是 C++ 称之为 happens-before,为了统一描述在 C++ memory model 这个主题中后续均采用 happens-before 这一说法。在 C++ 中,说 A happens-before B,那么可以明确的就是时序上可以认为 A 先发生 B 后发生,B 可以观察到 A。因此只要我们在程序中建立了 happens-before 关系,那么就能得到因 happens-before 而来的同步关系。下面介绍 C++ 内存模型中 happens-before 相关的概念。
Sequenced-before
在同一线程中,evaluation A 根据语言定义的执行序 sequenced-before evaluation B。比如

Carries dependency
简单理解,在同一线程中,如果 A sequenced-before B 且 evaluation B 用到了 A,则 A carries dependency into B,即 B depends on A。
Modification order
对于单个变量的原子操作,无论以什么样的 memory_order,都是有全局序的,但是不同变量间的原子操作是没有这样的保证的,想要这种保证就需要有一定的同步语义或者完全使用 memory_order_seq_cst。
Modification order 指的就是单个对象上原子操作的全局序。可以看出,C++ 约束了对于同一个变量原子操作的 total order,其实就是具备 sequential consistency。
Release sequence
对于一个变量 M,evaluation A 是作用在 M 的一个 release operation,那么在 A 之后由下面两种情况:
- 同一线程内以任意 memory_order 执行的原子操作,
- 不同线程内 read-modify-write 类的所有原子操作,比如 fetch_add、cas 等
构成的 modification order(包括 A) 称之为 以 A 为 head 的 release sequence。
比如对于 M,A 是一个 release operation,之后本线程内有 relaxed 的任意操作 B,其他线程有 read-modify-write 类操作如 fetch_add C、D,那么 A -> {B、C、D } 是以 A 为 head 的 release sequence。由于 B、C、D 顺序不确定,所以这里放到了一个大括号内。具体为什么这么设计,可以参考 <<C++ Concurrency in Action>> 5.3.4 一节。
Dependency-ordered before
在线程间,如果满足下面任一情况,则 evaluation A dependency-ordered before evaluation B:
- A 在 M 上执行了一个 release operation,在另一个不同的线程,B 对 M 执行了一个 consume operation,并且 B 读了以 A 为 head 的 release sequence 中的任意一个操作的写入值。
- A dependency-ordered before X 并且 X carries a dependency into B。
Synchronizes-with
在线程间,同一变量的一对具备 Release - Acquire 语的义原子操作会建立 同步。比如 evaluation A 是对 M 的 release operation,而之后 evaluation B 是对 M 的 acquire/consume operation,则称 A synchronizes-with B。根据 memory_order 中介绍的内容,能够在线程间构成 synchronizes-with 的 operations 如下:
- Mutex 的 lock() 和 unlock()
- 具有 Release-Acquire 语义的原子操作
- 具有 Release-Acquire 语义的 fences
需要注意的是,memory_order_seq_cst 是包含 release & acquire 语义的,更多的细节参考 memory_order 文档即可。
Inter-thread happens-before
在线程间,如果满足下面任一情况,则 A Inter-thread happens-before B:
-
- A synchronizes-with B
-
- A is dependency-ordered before B
-
- A synchronizes-with some evaluation X, and X is sequenced-before B
-
- A is sequenced-before some evaluation X, and X inter-thread happens-before B
-
- A inter-thread happens-before some evaluation X, and X inter-thread happens-before B
Happens-before
如果满足下面任一情况,则 A happens-before B(以后偶尔会用 “->” 简化):
-
- 单线程内 A is sequenced-before B
-
- 多线程间 A inter-thread happens-before B
至此,我们由 sequenced-before 一步步走到了 happens-before 关系。因为 A happens-before B 则 A 对 B 可见,所以只要构建了 happens-before 关系就具备了同步能力。
需要注意的是,从文档可以看出 C++ 的 happens-before 强调的是 visible 性,而没有 execution order 的约束。比如如下例子:

下面 2.2 节会结合具体的 memory_order 类型以及例子进一步强化理解。
2.2 Atomic Operations
memory_order_relaxed
宽松操作:没有同步或顺序约束,仅对此操作要求原子性。
memory_order_consume
可以与其他线程的 release operation 构成 synchronization。另外不仅如此,还具有一个 副作用(side effects,memory barrier 的作用) :所有本线程内依赖于该 memory_order_consume operation 得到的 value 的所有读或者写不可以重排到该操作之前。
memory_order_acquire
类似于 memory_order_consume 但是副作用强于 memory_order_consume,要求所有 memory_order_acquire 操作后面的读或者写都不可以重排到该操作之前。
memory_order_release
可以与其他线程的 acquire/consume operation 构成 synchronization,副作用是所有当前线程的读或者写不可以重排到该操作后面。具体的 synchronization 行为如下:
- 与 acquire:当前线程的所有写入对具备 acquire operation 的其他线程可见。
- 与 consume:当前线程所有 carry a dependency into memory_order_release 变量的写入对具备 consume operation 的其他线程可见。
memory_order_acq_rel
memory_order_acq_rel 只能作用在 read-modify-write 动作上,语义上是 memory_order_acquire 和 memory_order_release 的结合。
memory_order_seq_cst
不仅具有 memory_order_acquire、memory_order_release 和 memory_order_acq_rel 有的语义,额外保证所有 memory_order_seq_cst 作用的变量具备全局序。
2.3 Examples
这里的例子都以原子操作为基础,但是其实通过 std::atomic_thread_fence 结合 Release-Acquire 语义也一样可以实现同步。
Sequential

直观的理解:由于 x 和 y 都是 memory_order_seq_cst memory_order,所以具有全局序。因此当 B 判定失败导致 z 没有 ++,那说明对于 read_x_then_y 来说,顺序是 x = true -> y = true -> x = true -> y = false,这个顺序对于 read_y_then_x 来说,一旦 C 通过,因为 x = true 在 D 之前,所以 D 也会判定通过,进而 z 会 ++,其他情况读者可以自行分析。另外,语义上的理解可以参考 <<C++ Concurrency in Action>> 的 5.3.3 一节。
Relaxed

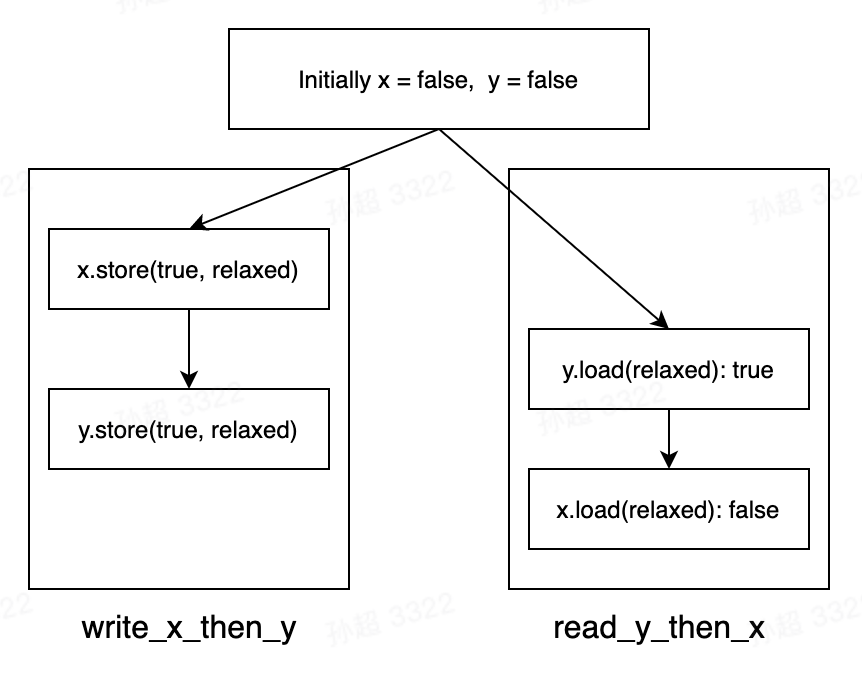
直观的理解:relaxed 没有同步语义,因此 A、B、C、D 可以乱序,没法判定先后顺序。
语义上理解:如下图,不同线程中的 A 没有和 C 建立 synchronizes-with 关系,所以 也就没有 A happens-before C 的关系,所以 read_y_then_x 中 d 执行见到的 x 可能还是 false。
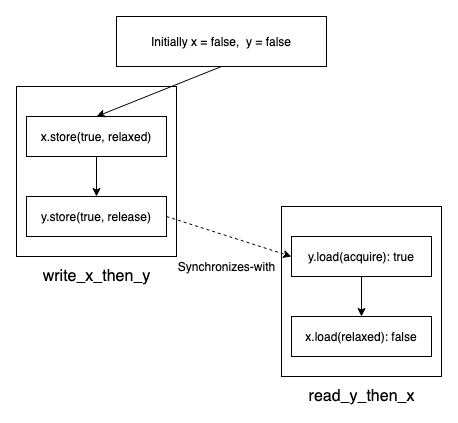
Release-Acquire


3 . References
- <
> - https://en.wikipedia.org/wiki/Consistency_model
- https://en.wikipedia.org/wiki/Linearizability
- https://en.cppreference.com/w/cpp/atomic/memory_order
- https://stackoverflow.com/questions/9762101/what-is-linearizability
- https://timilearning.com/posts/consistency-models/
- https://cloud.google.com/spanner/docs/true-time-external-consistency
- https://timilearning.com/posts/mit-6.824/lecture-13-spanner/
- https://jepsen.io/consistency
- <<C++ Concurrency in Action>>
- <
> - http://www.bailis.org/blog/linearizability-versus-serializability/
- http://www.cs.cornell.edu/courses/cs734/2000FA/cached%20papers/SessionGuaranteesPDIS_1.html#HEADING1