当通用优化已完成,我们应该做什么? --- 飞书文档移动端优化实践
背景
去年下半年业务高速迭代,大量新 feature 上线,但同时带来的问题是首屏耗时数据日渐上涨,同学们纷纷表示"移动端文档打开越来越慢,太影响工作效率了"。
于是去年年底我做了下优化:
| 视频 1 | 视频 2 |
|---|---|
 |
 |
线上用户数据:
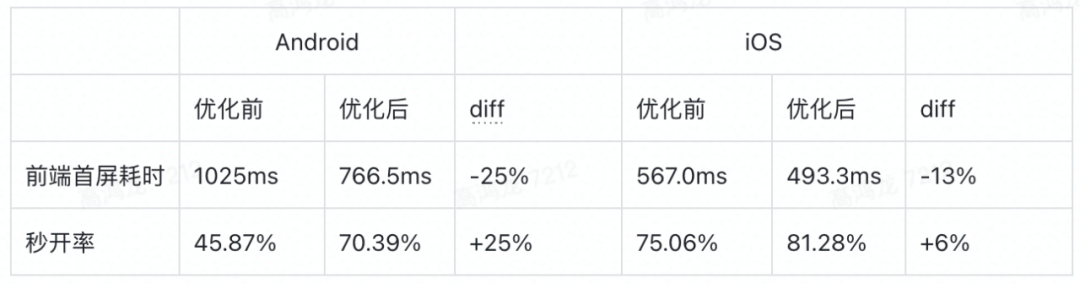
可见,无论是用户体验还是指标数据都有了明显的优化。
是不是我有神秘的魔法?并没有,甚至可以说魔法已经用完了。为什么这么说呢?我们先看飞书文档移动端(以下简称为 Doc )的现状:
1 . **业界公认有效的通用优化基本已经完成。**在大部分场景都可以实现:
-
JS 加载/JS 解析/请求数据耗时为 0
-
仅渲染前 50 行
2 . **业务复杂。**经历了 4 年迭代的大型前端项目,历史问题多。 3 . **文档应用的业务特点导致优化困难。**文档应用内容由用户自定义,因此影响打开性能的因素非常多,如长度、内容、设备性能、网络情况、用户使用习惯等等。
第一条和第三条叠加特别致命,意味着只能根据文档应用的特点做优化,而且这样的针对性优化还存在困难且没有现成的经验,那么优化项的效果难以衡量。此外还有一个难题:不能做大型技术改造,原因是 PC 与移动端存在代码复用,改造成本过高,人力上不允许。

怎么找有效的优化项?
做性能优化时,找优化项才是最难的,解决问题反而比较简单。
前置步骤:我该优化哪里?
在找优化前,我们首先要知道自己要优化什么。而上手业务最快的方式是画图:如图为 Doc 的打开流程:
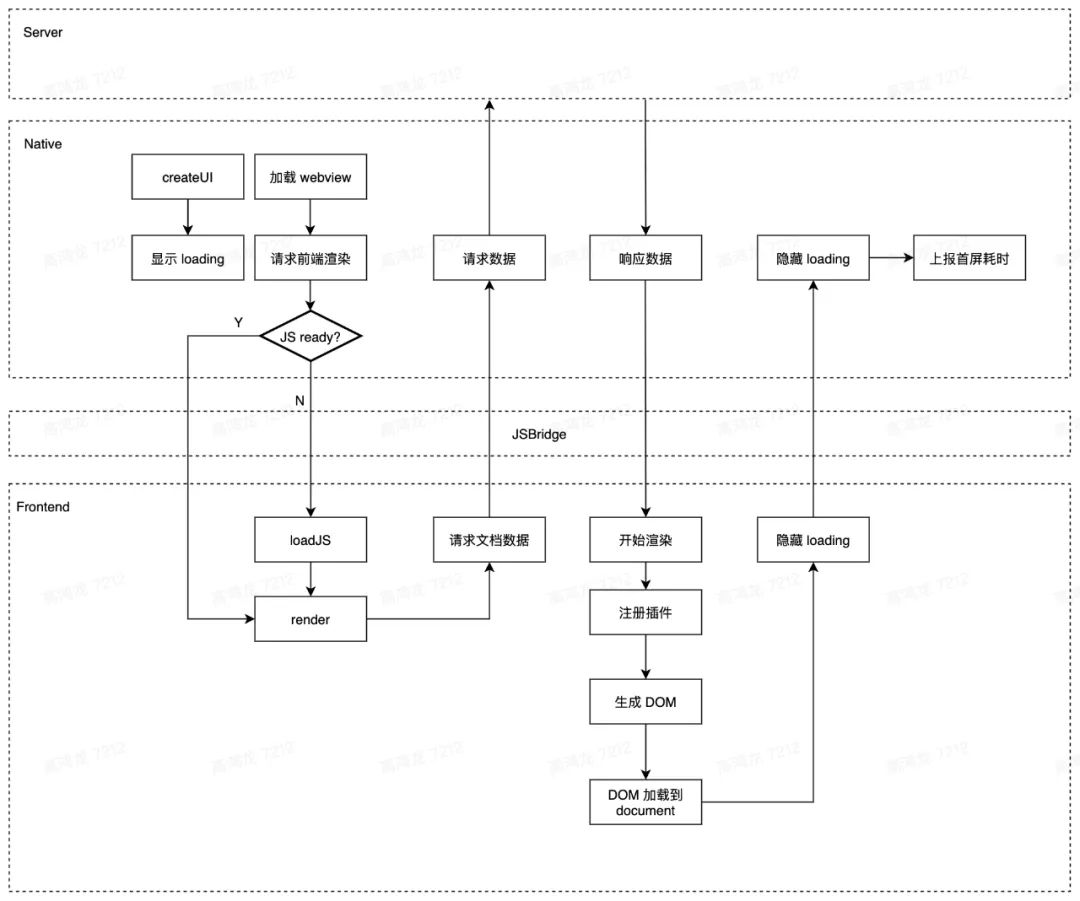
那可以哪一个流程是可以被优化的呢?在回答这个问题前,我们先看看前人为 Doc 做了什么优化。
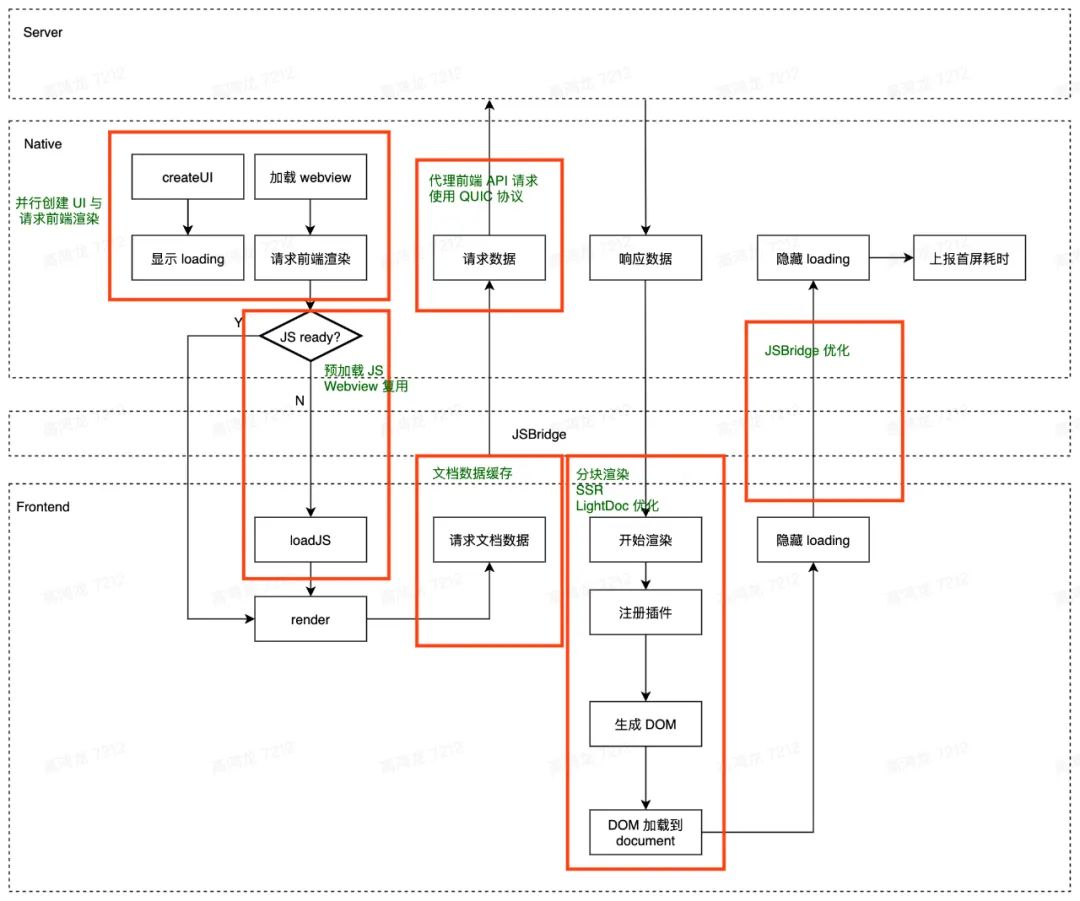
我们在前面说过,大多数场景下, Doc 可以做到:
-
JS 加载/JS 解析/请求数据耗时为 0;
-
仅渲染前 50 行。
因此优化空间相对较大的节点只有如下图绿框所示中的一小块,而且这一小块也已存在大量优化。
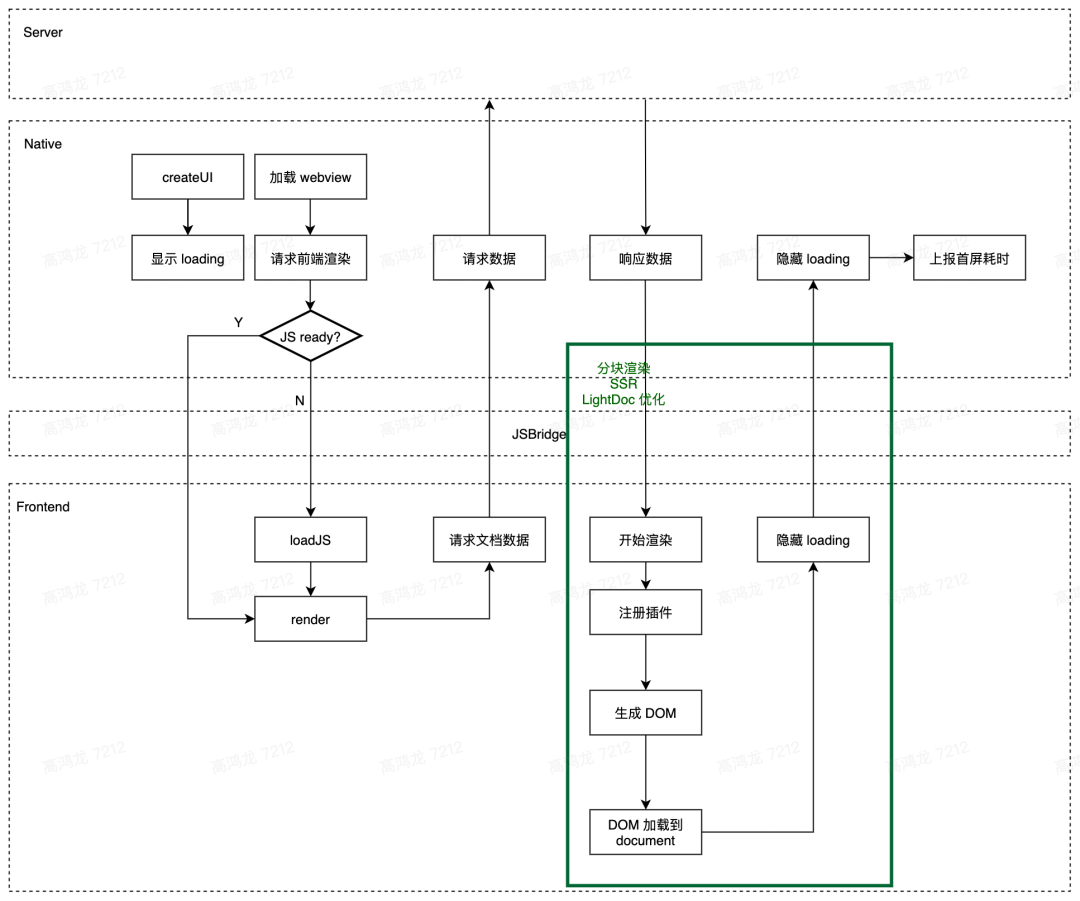
- 小优化怎么找?
- 怎么判断小优化的收益?
我们下面开始介绍如何解决这两个问题。
1 . 科学分析
我司对外的主要印象是:数据推动决策。那么,可以让数据驱动性能优化吗?这肯定可以的。
比如,某天我突然想到一个 idea:“文档内容非常丰富,针对内容进行优化?”,但是怎么验证这个想法是否靠谱呢?
首先是找数据,通过 Tea (Toutiao Event Analyze) ,我找到了文档打开耗时与各因素的关系:文档大小,block 类型,用户设备性能变化,缓存预加载比例,Webview 预加载比例等等。
但问题也来了:茫茫数据的海洋里,能猜想出无数的优化点,哪个优化点是有效的?可以分成两步:
- 分析一下
- 试一试
分析一下
面对茫茫数据海洋,我选择两个符合直觉的线索进行分析:
文档长度

可以看出:
- 大文档(大于 300 行) 在打开 PV 占比小于 10%(左图绿色);
- 大文档打开速度比较慢,可能是个优化点。(右图浅蓝色曲线,约 600ms)。
分析收益
如果大文档耗时可以优化掉 500ms,这样大盘数据的平均耗时可降低 50ms(500ms*10%),看起来变化并不太明显。而且这个目标几乎是不可能的,因为由图中数据可以看出,降低 500ms 意味着耗时比中小文档还要小。
结论
优化大文档成本高,而且耗时优化少,ROI 低。
文档内容
Doc 有很多 block,比如 Table,@人名,Sheet,文件卡片,图片等等。这些 block 也会影响首屏性能。
遗憾的是,由于设计埋点时缺少考虑,我们没法直观地通过 TEA 分析各类型 block 对首屏耗时的影响。
我们换个角度,收集数据:
- 通过 performance 工具分析发现,Table 比其他 block 渲染耗时长很多;
- 此外在 TEA 中发现 Table 在打开 pv 中的渗透率是 30%,与其他 block 的渗透率相比较高;
- 经验上 Doc 常用于会议中,会议文档 Table 通常较多。
虽然无法完全确定优化效果,但分析下来是一个非常值得尝试的点。那就来到了下一步:
试一试
我花了点时间进行优化,将 Table 在首屏的渲染耗时降为原来 50%,上线后观察大盘数据:
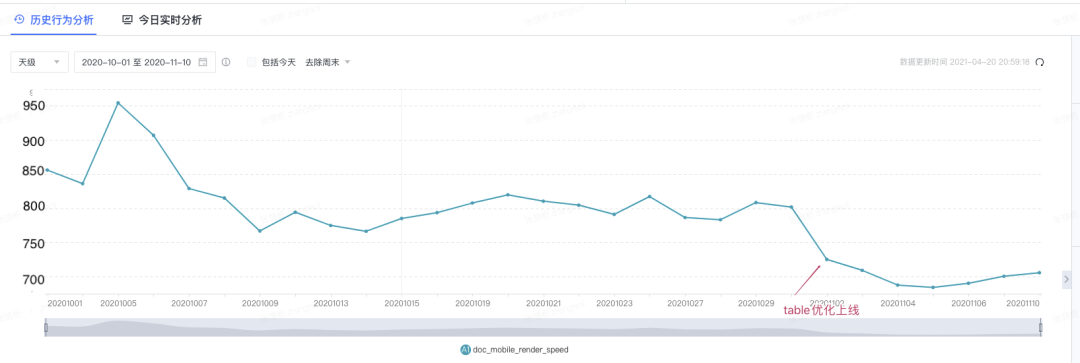
那么类似的 block 有哪些呢?
- @人名:35%+
- Sheet:40%+
- 图片:70%+
这样后续的优化计划便可以开始制定了,而且优化效果可预测,项目风险低。
2 . 数据挖掘

我们先举个例子,在文档这一场景,我们凭经验可以推断出:
- 高端手机理论上可以秒开任意文档
- 小文档在大多数手机中可实现秒开
那如果有一批线上用户的打开耗时违反了上面的经验呢?新的优化点!
但这里有两个问题:
- 怎么找到这部分用户
- 怎么分析这用户问题
通过 TEA 我们能找到可以筛选出"使用高端手机且打开文档耗时较长"的用户 id。
而分析问题,则需要使用日志。
日志
首先,怎么记录日志呢?
追查首屏性能至少需要以下信息:
-
记录渲染各阶段耗时,比如 Doc 会记录以下信息:
-
调用 render -> 开始获取数据
-
开始获取数据 -> 获取数据完毕
-
获取数据完毕 -> 开始渲染
-
开始渲染 -> 渲染结束
-
辅助排查的信息,比如:
-
文档各 block 数量
-
文档行数
-
文档字数
**注意:**不能在日志中收集用户隐私,文档内容,作者信息等都是信息红线。
分析问题
大多数情况下都可以通过复现来解决:
- 制作一篇与日志内描述的内容差不多的文档;
- bytest (内部云真机平台) 上找一台性能差不多的手机打开该文档。
大多数情况下都可以找到问题,前提是需要:
- 对打开链路有影响的业务了如指掌
- 熟悉打开过程的 performance trace/日志内容
可能有人会问:为什么不直接请求用户协助?如前面所说,日志收集的信息非常有限,而且通过日志定位用户是违规的。
那么,通过上面两种方法就能搞定优化了?还有更追求极致的方法吗?
3 . 聚沙成塔
思考一个灵魂问题:
10ms 的优化有没有意义?
下图是 Doc 打开流程的的 performance trace,火焰图最下方非常细碎(<10ms),简单看没有发现明显性能问题。难道要把每个细碎的小块都要看一遍?一个个优化掉?
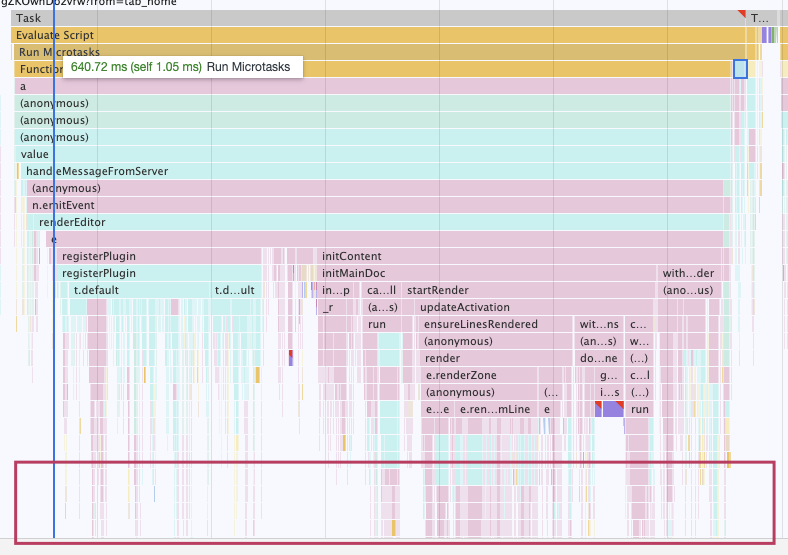
这样工作量也太大了吧?
确实很大,而且最可怕的是,做完不一定有用。同时,追求极致不等于不计成本,我们需要聪明一点。那么,如何区分一个 10ms 的价值?
还是**利用**数据! 我们简单分析一下:
- 让空文档打开耗时降低 10ms 很有意义,因为所有文档都会受益;
- 大文档打开耗时降低 10ms 意义很小,因为 tea 可以看出大文档占比不到 10%,反映在大盘数据上只会有 1ms 的下降;
- Table block 优化 10ms 也很有意义。因为 Table 渗透率虽然只有 30%,但每一个文档平均有 1.067 个 Table,优化的影响面很广。
再考虑下:
10 个高 ROI 的 10ms 优化有意义吗?
这意味着首屏平均耗时降低 100ms,在现在的 Doc 中已经非常可观的优化了,可谓是“聚沙成塔”。
怎么安全地做优化
Doc 有很多问题:
- 陈年代码多且复杂;
- 模块多,熟练每个业务不容易;
- 优化涉及打开流程,出问题就是 P0 问题。
那么如何优化性能且不影响质量呢?
质量保障机制
Doc 的质量保障机制:
- Code review
- 单元测试
- 研发主流程自测
- QA 测试
- 灰度上线
质量保障机制很重要,但每个团队都不一样,这里我就不详细说了。
分析修改的影响范围
- 谁依赖了这个方法
- 这个方法的副作用
但这只适合影响范围较小的代码,如果影响范围不明呢?这里介绍几种方法。
相对安全的修改
延后渲染
Doc 每块内容都相对独立,延后渲染(懒加载)不存在风险,但需要注意:同步代码改为异步代码除外。
他懒我也懒
如果某段逻辑是已经异步的,那执行实际再延后一点也是安全的,举个例子:
async function init() {
await import('./code');
longTask();
}init 发生在首屏,由于移动端 Doc 的机制,前端代码都在本地,所以 longTask 会在当前任务的下个微任务执行,即会阻塞首屏。
longTask 能不能延迟都首屏后执行?
我们分析一下:
- longTask 依赖 code 加载完毕;
- 作者写这段代码时已经准备好 code 会加载一段时间,那么 code 在下个微任务加载完毕,还是在 10 秒后加载完毕其实没区别。
因此可以这么修改:
async function init() {
await import('./code');
await sleep(500);
longTask();
}增加 sleep 让 longTask 延后到首屏后执行。
危险的修改怎么办
有时候明明觉得自己的优化可行,收益也不错,但碍于影响范围没法估计,保证质量的信心不够,但不上线又有点不甘心该怎么办?
可以通过以下方法提高保证质量:
- 与对应模块负责人充分交流,review 修改方案是否会有问题,如果上线出现问题也可以及时修复;
- 通过灰度上线,出现问题及时回退;
- 观察线上指标变化,以 Doc 为例,打开成功率低于 99.9%时,说明这次优化有质量问题;
- 进入灰度后多留意各种反馈渠道。
总结
这篇文档我们介绍了 Doc 移动端的优化方法。以数据与事实为基础分析出高 ROI 优化项,以实现在"通用优化"已完成后的进一步优化。此外还介绍了如何在历史问题繁多,业务复杂的文档中保证优化项实现的质量。