巧用 maxTimeMS 服务端超时,避免承载亿级用户的腾讯云数据库MongoDB服务雪崩
腾讯云数据库MongoDB作为一款基于开源社区MongoDB版本的文档数据库产品,其承载着公司内外包括微信、看点、QQ音乐在内的亿级用户重量级APP产品。在某些场景的使用过程中,用户在客户端请求超时后会不断重试,可能导致服务端大量请求积压,出现恶性循环甚至导致服务雪崩。一般遇到这种情况,后台会自动检测并做服务降级,主动拒绝一部分用户请求,或者重启后端服务等举措来应对。但是这些措施对业务有损,或者不可自行恢复。
本文围绕 MongoDB 原生 maxTimeMS 特性和腾讯云MongoDB的优化,并结合 4.0 版本代码,详细阐述如何巧用 maxTimeMS 服务端超时,来避免服务端请求积压导致雪崩的情形。
背景
业务方在腾讯云MongoDB运营过程中,曾有业务集群出现过:慢请求 -> 客户端断开重试 -> 服务端累积的请求越来越多 -> 服务雪崩 -> 人工重启解决的问题。
过去,为了防止服务雪崩,腾讯云MongoDB应对的解决方案是:在内核中实现了连接状态检测、自适应限流等功能进行过载保护,并开发了外围工具 kill 长时间运行的请求等。但是过载保护本质上会进行服务降级,对业务还是会产生一定影响,而外围工具处理起来也不够及时,甚至可能在节点 hang 住时无法工作,以上解决举措都存在着一定程度的弊端。
为了更好地避免服务雪崩,腾讯云MongoDB建议设置服务端超时,并和客户端超时保持一致。这样在客户端出现超时后,服务端也立刻终止这些“无意义”请求的执行。通过避免服务端资源的无效占用,极大地降低客户端不断重试导致服务雪崩的概率。
MongoDB原生服务端超时原理
当一个用户请求到达 mongos 或者 mongod 时,会生成一个对应的 OperationContext 对象,来记录这个请求从开始到结束期间的完整上下文信息。上下文信息中就包含了后面要介绍的“时间信息”:起始时间,已执行时间,超时时间,以及是否是 kill 状态等。相关成员和接口如下图所示:
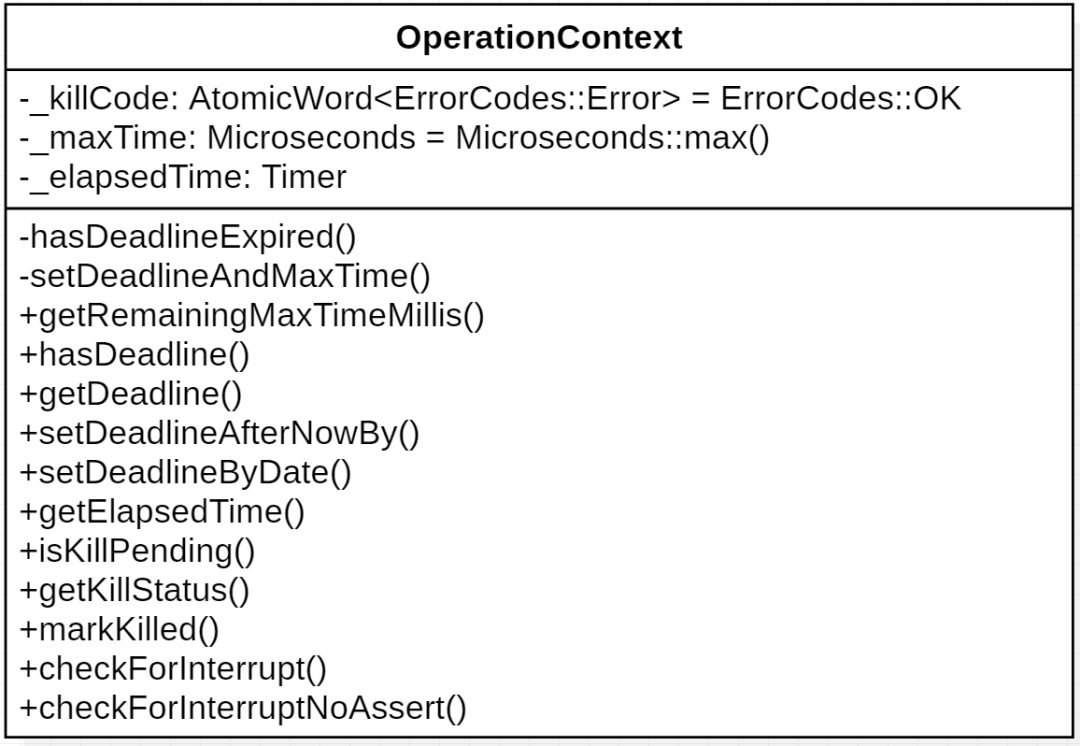
其中 checkForInterrupt() 接口的作用就是检测请求是否应该终止,需满足以下 3 个条件之一:
1.实例处于 shutdown 状态;
2.用户使用 killOp 命令,调用 markKilled() 接口,将 OperationContext 标记为了终止状态;
3.用户通过 maxTimeMS 参数给 OperationContext 配置了超时 Deadline,然后检测到 hasDeadlineExpired() 为 true;
一个请求在执行过程中会多次调用 checkForInterrupt() 检测自己是否超时,比如在获取Global ticket,获取资源锁,yield,内部迭代重试等阶段会主动检测并超时退出。
备注1:原生 MongoDB 在 3.7.3 版本通过 SERVER-33473 (https://jira.mongodb.org/browse/SERVER-33473)才支持获取 Global Ticket 时能够主动超时和打断,因此更低版本在 qr/qw 较大,请求排队比较严重时无法及时超时退出;而且在 3.7.3 版本通过 SERVER-32638 (https://jira.mongodb.org/browse/SERVER-32638)才支持获取资源锁时主动超时,因此更低版本在获取互斥锁卡住时也无法及时超时退出。
因此,为了有更好的体验,强烈建议升级到 4.0 或更高版本。
备注2:终止OperationContext 和 kill 进程/线程行为不同。OperationContext 自己检测和主动退出的机制使得 killOp 和 maxTimeMS 不会绝对精确。从我们对 maxTimeMS 的测试来看,能够保证误差在 1 秒内,大部分在 10ms 级别。也就是说用户设置的 100ms 超时,在后台可能会执行 110ms 左右。
使用小贴士:
以常见的 CRUD 操作为例,用户在命令参数中加上 maxTimeMS 的设置即可。
例如将以下操作的服务端超时设置为 100ms:
// 查询操作
db.runCommand({find:"cmongo_test", filter:{a:1} , maxTimeMS: 100})
// 插入操作
db.runCommand({insert:"cmongo_test", documents: [{a:1}], maxTimeMS: 100})
// 更新操作
db.runCommand({update:"cmongo_test", updates:[{q:{a:1}, u:{$set:{b:3}}}], maxTimeMS: 100})
// 删除操作
db.runCommand({delete:"cmongo_test3", deletes: [{q : {a :1}, limit:1}], maxTimeMS: 100})如果服务端超时,客户端会收到类似如下的错误(客户端还没超时断开的情况下):
{
"ok" : 0,
"errmsg" : "Encountered non-retryable error during query :: caused by :: operation exceeded time limit",
"code" : 50,
"codeName" : "MaxTimeMSExpired",
}MongoDB 原生版本问题
在腾讯云MongoDB运营过程中,发现原生版本有 2 个比较大的使用痛点:一是原生 5.0 以下版本,在分片集群模式下不支持insert/update/delete 写命令的超时;二是缺乏服务端默认的 maxTimeMS 配置。
1.原生 5.0 以下版本,在分片集群模式下不支持 insert/update/delete 写命令的超时
在 4.4 及以下版本中,mongos 在接收到写命令时,会使用 maxTimeMS 设置请求的 OperationContext 超时,然后将写入的数据拆分成子请求发给 mongod. 但是 mongod 侧收到的子请求中已经没有了 maxTimeMS 参数,因此 mongod 侧不会主动超时。
所以用户在对 mongos 发起一个携带 maxTimeMS 的写命令时,迟迟等不到超时报错。
以 4.0 版本为例,常用命令对 maxTimeMS 的支持情况如下:
| 命令 | mongos | mongod | 备注 |
|---|---|---|---|
| find | 支持 | 支持 | https://docs.mongodb.com/v4.0/reference/command/find/ |
| getmore | 支持 | 支持 | https://docs.mongodb.com/v4.0/reference/command/getMore/ getMore 这里特指 awaitDataTimeOut 超时,即 cursor 等待有新数据的时间。 SERVER-34277 (https://jira.mongodb.org/browse/SERVER-34277)提议引入新字段进行区分,不过社区还没有做 |
| findAndModify | 支持 | 支持 | https://docs.mongodb.com/v4.0/reference/command/findAndModify/ |
| aggregate相关 aggregate/count/distinct | 支持 | 支持 | https://docs.mongodb.com/v4.0/reference/command/aggregate/ https://docs.mongodb.com/v4.0/reference/command/count/ https://docs.mongodb.com/v4.0/reference/command/distinct/ |
| insert | × | 支持 | https://docs.mongodb.com/v4.0/reference/command/insert/ |
| update | × | 支持 | https://docs.mongodb.com/v4.0/reference/command/update/ |
| delete | × | 支持 | https://docs.mongodb.com/v4.0/reference/command/delete/ |
这个 Bug 直到 4.7.0 版本通过 SERVER-46187 *(https://jira.mongodb.org/browse/SERVER-46187**)*才修复,并随着今年 5.0 版本的推出才解决。但是,5.0 新版本尝鲜的寥寥无几,绝大部分用户都在使用比较成熟的 4.0 / 4.2 / 4.4 版本。
2.缺乏服务端默认的 maxTimeMS 配置
MongoDB 的命令和参数众多,普通用户很难注意并理解 maxTimeMS 的配置,即使想开启这个功能也需要修改代码并上线发布。而且如果多租户共享一个集群,怎么保证其他人也开启了默认超时也是一个问题。因此,整体使用体验上需要改进。
另外,和 maxTimeMS 参数对比,原生MongoDB 允许在服务端配置默认的 writeConcern 级别,并在最新发布的 5.0 版本中将默认设置调整为 majority ,防止新手用户不理解规则导致重要数据出现安全性问题。本质上来说,是通过服务端默认配置来降低用户的使用成本。
因此,腾讯云MongoDB作为一个注重用户体验的云数据库,认为有必要在服务端支持默认的 maxTimeMS 配置。
腾讯云MongoDB对 maxTimeMS 服务端超时的优化
1.完善 mongos 写命令对 maxTimeMS 的支持
Mongos 会根据原始请求按目标 shard 分组之后重构子请求,并将每个子请求转发给对应的 shard。
下图展示一个写请求在mongos 上的执行路径,比较关键的点有:
- 在 runCommand 函数中,会从命令中解析 maxTimeMS(客户指定的),并设置 OperationContext 的 deadline;
- 在BatchWriteExec::executeBatch 函数中,会重构子请求,加上 sessionId 和 transactionId 等信息,但是没有携带 maxTimeMS 信息;
这时会出现 2 个问题:
- OperationContext 只能跟踪 1 个请求在 1 个进程中的执行信息,也就是说 mongos 和 mongod 各自有自己独立的 OperationContext。因此,虽然请求在 mongos 中有 deadline,但是 mongod 上没有;
- 子请求没有将 maxTimeMS 透传给 mongod,因此 mongod 侧也无法根据子请求信息设置 OperationContext 的 deadline;
解决方法:在生成子请求时,计算总请求当前还剩余多少执行时间,并作为 maxTimeMS 参数增加到子请求中,再透传给 mongod。
整体架构如下所示:

备注:社区 5.0 版本 *SERVER-46187 (https://jira.mongodb.org/browse/SERVER-46187**)*的修复思路和腾讯云MongoDB的修复方法类似。
2.支持腾讯云MongoDB服务端默认配置
腾讯云MongoDB支持分片和副本集 2 种使用模式。
对于分片集群,可以通过 mongos 在 configSvr 的 config.cmongo_settings 中配置默认参数。mongos 在处理请求时,如果请求中携带了用户指定的 maxTimeMS 参数,则以用户指定的为准;如果用户没有指定,则增加默认配置。
整体架构如下图所示:
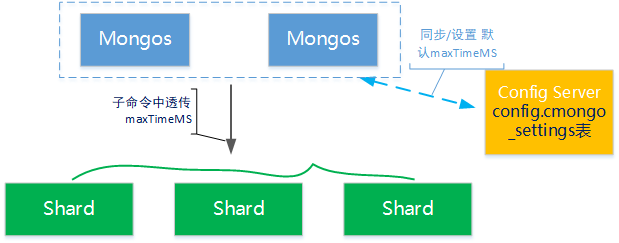
对于副本集集群,也是在副本集的 config.cmongo_settings 表中存储默认配置,如下图所示:
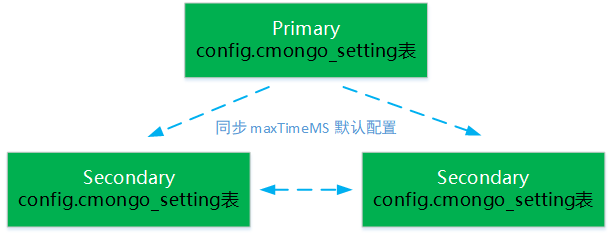
备注:默认配置只对用户请求生效,腾讯云MongoDB集群内部的行为。(比如主从同步,session 上下文信息持久化等请求不受影响)
使用小贴士
腾讯云MongoDB在 4.0 和 4.2 版本进行了上述优化。
对于需要使用 maxTimeMS 功能的用户,建议先将腾讯云MongoDB的小版本升级到最新,然后通过如下方式进行默认配置:
- 分片集群登陆 mongos, 副本集登陆 mongod;
- 配置 config.cmongo_settings 表(在 1 个 mongos 或者 mongod 节点上配置即可,其他 mongos 或者 mongod 节点会在 10 秒内自动同步配置);
# 切换到 config DB
use config
# 第 1 次配置
db.cmongo_settings.insert({"_id" : "maxTimeMS", "value": 1000})
# 配置变更
db.cmongo_settings.update({"_id" : "maxTimeMS"} , {$set: {"value": 2000}})
# 关闭配置
db.cmongo_settings.update({"_id" : "maxTimeMS"} , {$set: {"value": 0}}总结
本文通过对 MongoDB 服务端超时原理和原生版本存在的问题做了分析阐述。腾讯云MongoDB在原生版本的基础上,解决了 4.0 和 4.2 版本无法在 mongos 侧正确处理写命令超时的问题,并支持了服务端的默认配置,保证服务端超时后能很快退出,防止后端请求积压导致服务雪崩,最终在功能正确性和用户体验上实现了相关优化目标。