亿级流量实验平台设计实践
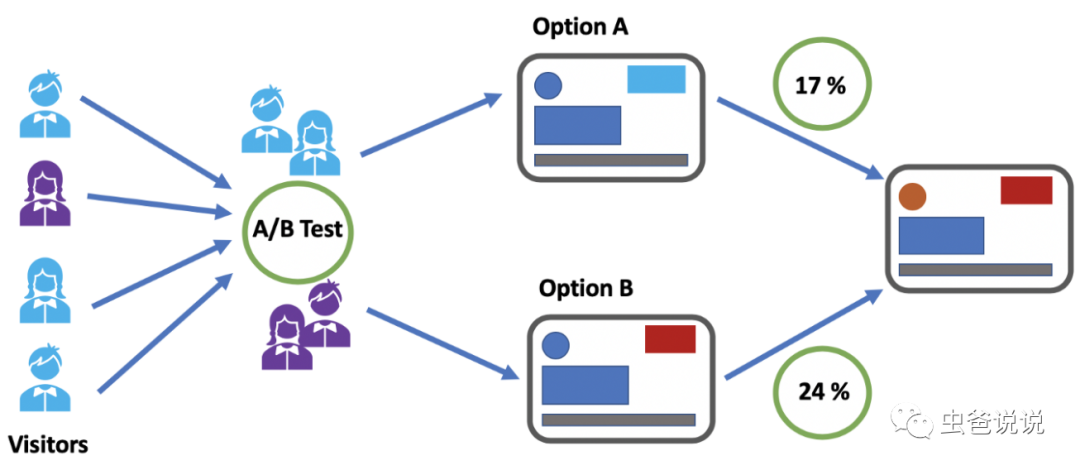
大家好, 今天给大家分享一款亿级流量实验平台。在互联网行业,要上线一个策略(CTR预估、CVR预估等),或者一个功能,如果贸然全量上线,那么如果新策略效果不佳,可能会造成不小的损失,要么丢失用户,要么损失收入。
那么怎样才能避免此问题发生呢?这就引入了实验平台,通过对流量打标签,然后分析实验效果,从而再决定是否实验推全还是下线。
一、概念
实验平台,从字面意思来看,就是一个用来做实验的平台。其 基本原理 就是把流量进行分流,特定流量,匹配特定策略。不同批次的用户,看到的不同的策略。然后通过曝光、点击等数据进行统计分析,得出实验效果的好坏,从而决定是否推全该实验。
换句话说,就是为同一个目标制定两个方案(比如两个页面),将产品的用户流量根据特定策略分割成 A/B 两组,一组实验组,一组对照组,两组实验同时运行一段时间后分别统计两组用户的表现,再将相关结果数据(比如 pv/uv、商机转化率等)进行对比,就可以科学地帮助决策。
通过对流量进行分流,运行实验,统计实验数据,进行数据分析,然后得出实验效果。如下图所示:
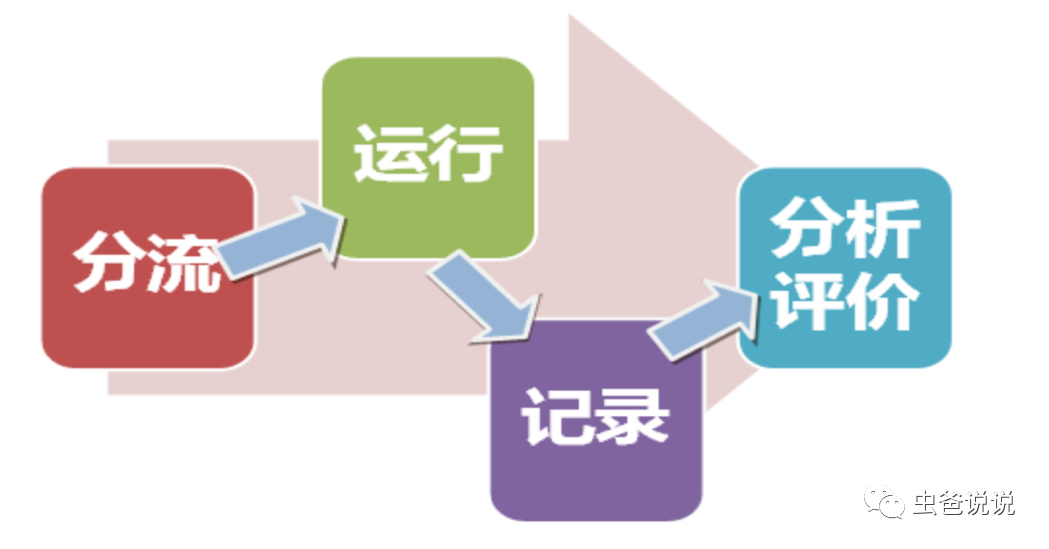
再根据实验效果,进行反向数据分析,定位出实验效果不好的源,进行头脑风暴,再次做实验,从而最终达到理想的实验目的。如下图所示:

二、分层实验模型
在进行实验平台讲解之前,先介绍下实验平台的理论基础,以便大家能够更好的理解后面的内容。
现在业界大部分实验平台,都基于谷歌2017年的一篇论文《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》,其模型架构如下图所示:
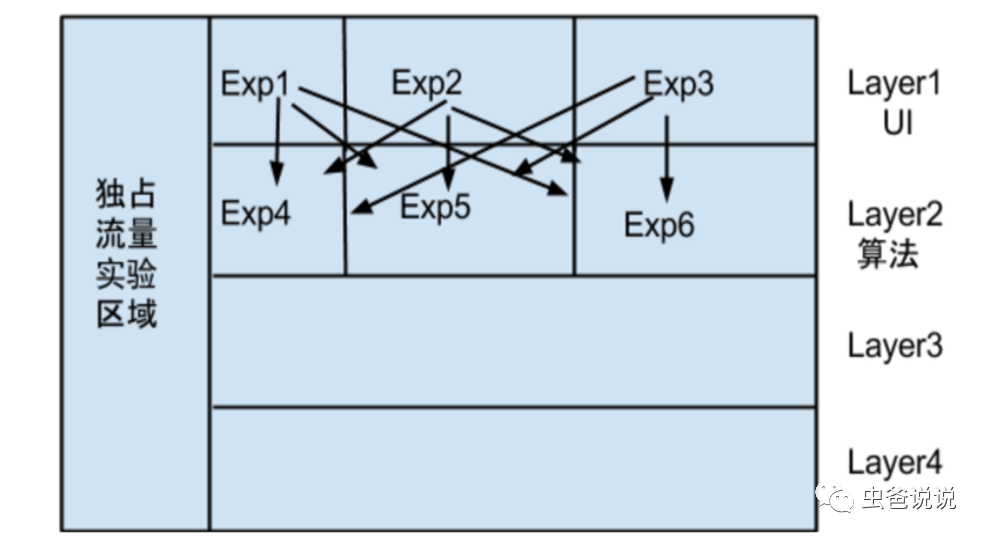
在该模型中,有几个概念:
- 域(domain):划分的一部分流量
- 层(layer):系统参数的一个子集
- 实验(exp):在一个域上,对一个或者多个参数修改,都将影响效果
- 流量在每个层被打散(分配函数),层与层之间流量正交
下图【图四】为笔者线上实验的一个简略图,在该图中,总共有三个实验层,分别为CTR预估层,用户画像层和频次策略层。
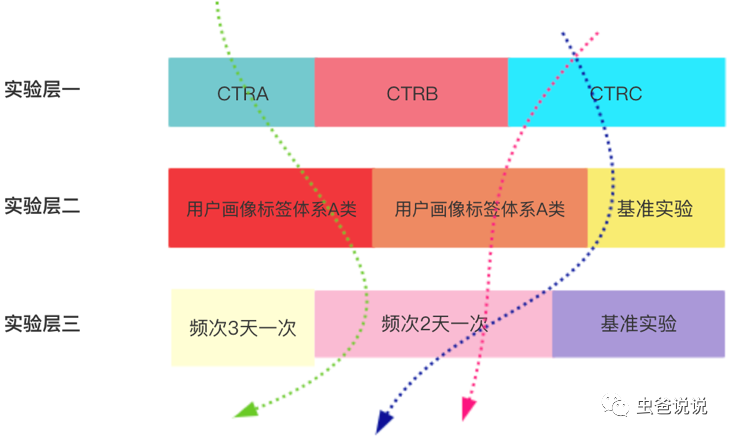
从图四可以看到,流量在层之间穿梭,而一个流量只能命中一个层中的一个实验,一个流量请求过程可能会命中多个层中的多个实验(每层命中一个实验)。
使用分层实验模型,需要满足以下几点:
- 相关联的策略参数位于同一实验层(即都是做CTR预估,那么CTR预估相关的实验,就放在同一层,即CTR预估层,以方便做实验对比)
- 相互独立的策略参数分属于不同的实验层(如上图中 ,CTR预估的实验和频次实验是两种性质不同的实验,因此要放在两层来实现,如果在一层的话,由于实验性质不同,难以比较实验效果)
- 一个流量只能命中一个层中的一个实验
- 层之间的流量正交,不会互相影响(即层与层之间的实验不会互相影响,如【图五】)

使用该分层模型作为实验平台理论基础的好处有以下几点:
- 可以作为一个独立的部分,不与系统中的其他业务或者功能相互 影响
- 每一层流量都是100%的全量,可以避免流量切分过细,保证实验间的可对比性、客观性
- 层与层之间,流量独立正交,不会互相影响
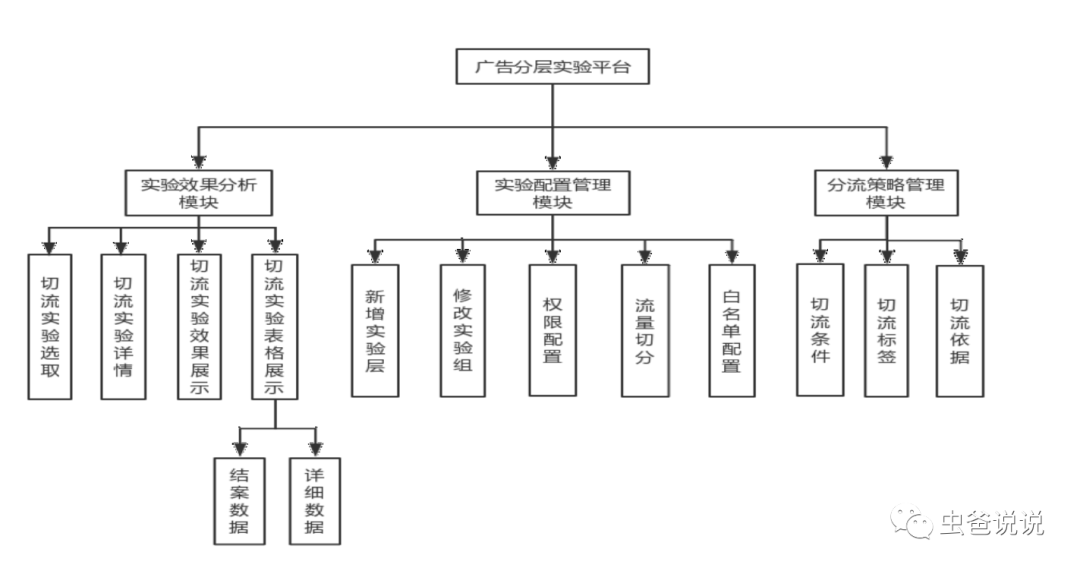
三、功能特点
一个可用或者完善的实验平台,需要有以下几个功能:
- 支持多实验并发迭代
- 支持白名单体验
- 提供便捷的管理工具
- 便捷的查看实验效果分析数据
- 支持实验的切流和关闭
- 保证线上实验安全性
- 支持实验推全
- 支持功能定制化
下面,我们将从几个功能点出发,详细讲述各个功能的原理。
支持多实验并发迭代,指的是一个完善的实验平台,在功能上,需要支持多个实验同时运行(包括同一层和不同层之间)。
支持白名单体验:因为实验分流有自己的策略,创建实验的用户不一定能够命中这个实验,而白名单的功能就是让在白名单的用户能够每次都命中该实验。
便捷的管理工具:这个指的是实验后台,一个实验后台需要能够创建实验,打开关闭实验等
查看实验效果分析数据:判断一个实验效果的好坏,就是通过实验标签分析实验数据,能够很直观的观察到实验效果,从进行下一步实验决策
实验的切流和关闭:实验的切流,指的是该实验需要一定百分比的流量进行实验,而实验关闭,则指的是停掉该实验
支持线上安全性:实验平台,本身就是起锦上添花的作用,其只是用来打实验标签的,不可本末倒置,影响了线上业务的正常功能
支持实验推全:一个实验效果如果好的话,就需要将全部的流量都命中该实验,而实验推全就是达到此效果
支持功能定制:没有一个实验平台能够满足不同公司,甚至同一个公司不同部门之间的业务需求,但是,为了尽可能的向这个目标靠拢,实验平台需要尽可能的灵活,低耦合,能够尽量的配置化。
四、架构及模块
实验平台必备的三个模块,分别为:
- 管理后台
- 实验后台
- 分流平台
管理后台主要是管理实验的,包括创建和停止实验等。
实验后台与管理后台进行数据上的交互,将管理后台的消息转换成特有的消息,进行转发和持久化。
分流平台,其一接收实验后台的实验消息建立内部维度索引,其二接收线上流量,根据流量属性,给流量打上对应的标签。
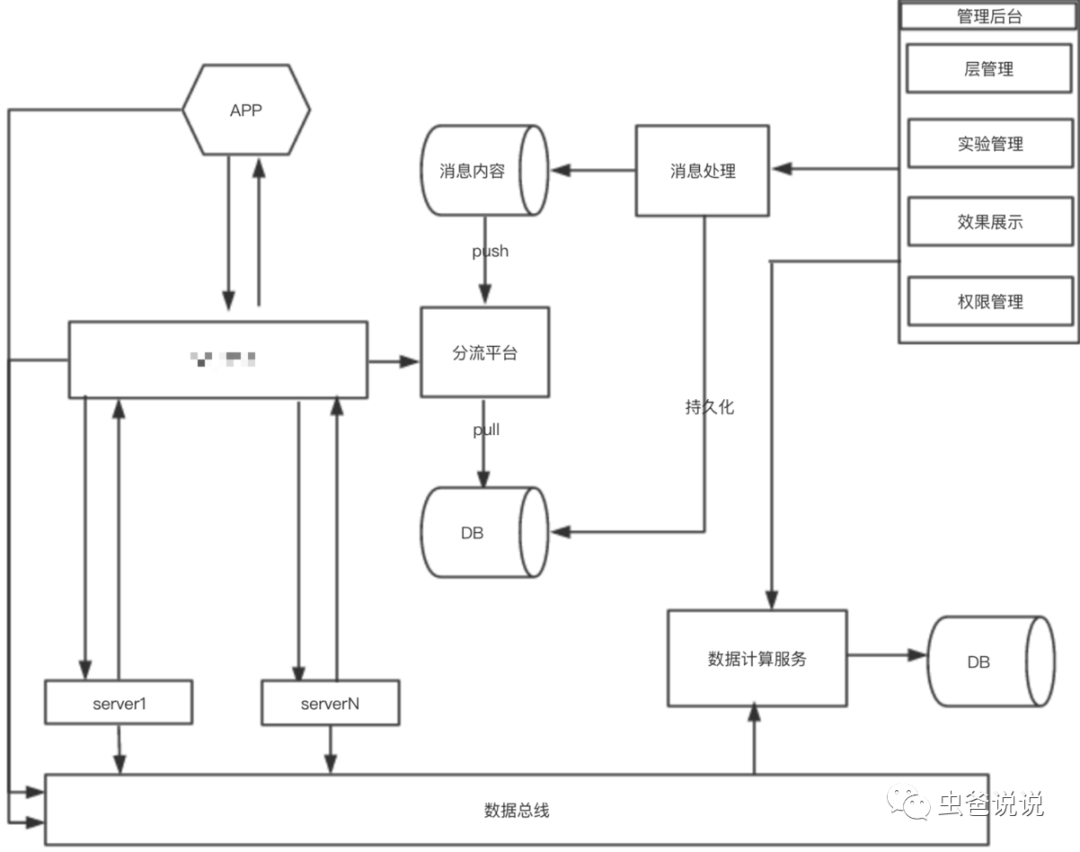
上图,是一个实验平台架构图,下面从创建实验角度,和流量的角度进行讲解。
创建实验角度:
1、在管理后台创建对应的实验
2、管理后台将创建的实验信息发送给实验后台
3、实验后台将实验首先发送至消息系统(kafka等),然后将实验落地持久化(DB)
4、分流平台消耗消息系统中的实验消息,加载至内存
流量角度:
1、 流量携带其基本属性(用户画像,app信息等)请求分流平台
2、 分流平台根据流量属性,进行定制化匹配,然后使用分流算法,计算实验标签
3、流量返回至调用方SDK后,SDK上报曝光、点击等信息至数据总线(大数据集群)
4、数据计算服务分析大数据集群的数据,计算对应的指标展示在管理后台。
实验平台,从模块划分上 ,如下图所示:
五、设计与实现
在具体介绍下文之前,我们先理解一个概念,以便能更方便的理解下述内容。

bucket即桶。实验平台最底层,将流量进行hash之后,只能流入某一个桶里。
流量划分
一般有以下几种划分方式:
-
完全随机
-
用户id哈希。
-
该流量划分会使同一个用户会一直命中同一实验,从而保证了用户体验的一致性;而且也满足对同一用户具有累积效应的策略的实验需求。但存在的问题就是,对于一些工具类属性,没有用户id一说,只有设备id比如idfa和imei这些标记,但是随着系统升级,这俩标记很难再获取到,所以就需要系统能够生成用户唯一id
-
用户id + 日期作为一个整体进行哈希 这是一种更为严格的保证流量均匀性的分流方式,可以保证流量划分在跨时间维度上更为均匀。
-
会牺牲用户请求跨时间区间的一致性
-
跟上面这种用户id哈希存在同样的问题
-
用户id尾号进行哈希
-
流量不均匀
-
也会存在用户id所存在的问题
为了兼容上述几种哈希划分方式的优点,而摒弃其缺点,我们引入了第四种流量划分方式:
bucket_id = hash(uid + layer_id) % 1000
常见的哈希算法有md5,crc以及MurmurHash等。
- MD5消息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),MD5算法将数据(如一段文字)运算变为另一固定长度值,是散列算法的基础原理。由美国密码学家 Ronald Linn Rivest设计,于1992年公开并在 RFC 1321 中被加以规范。
- CRC循环冗余校验(Cyclic Redundancy Check)是一种根据网络数据包或电脑文件等数据,产生简短固定位数校验码的一种散列函数,由 W. Wesley Peterson 于1961年发表。生成的数字在传输或者存储之前计算出来并且附加到数据后面,然后接收方进行检验确定数据是否发生变化。由于本函数易于用二进制的电脑硬件使用、容易进行数学分析并且尤其善于检测传输通道干扰引起的错误,因此获得广泛应用。
- MurmurHash 是一种非加密型哈希函数,适用于一般的哈希检索操作。由 Austin Appleby 在2008年发明,并出现了多个变种,与其它流行的哈希函数相比,对于规律性较强的键,MurmurHash的随机分布特征表现更良好。
其中,第三种MurmurHash算法,已经被很多开源项目使用,比如libstdc++ (4.6版)、Perl、nginx (不早于1.0.1版)、Rubinius、 libmemcached、maatkit、Hadoop以及redis等。而且经过大量的测试,其流量分布更加均匀,所以笔者采用的是此种哈希算法。
白名单
白名单,在实验平台中算是比较重要的功能,其目的就是存在于白名单中的用户优先于流量分桶,命中某个实验。
需要注意的一点是,假如白名单所在实验和流量经过哈希分桶之后的实验是两个不同的实验,这就只能以白名单优先级为最高,换句话说,如果白名单命中了某个实验,那么在该层上,就不该再命中其他实验。
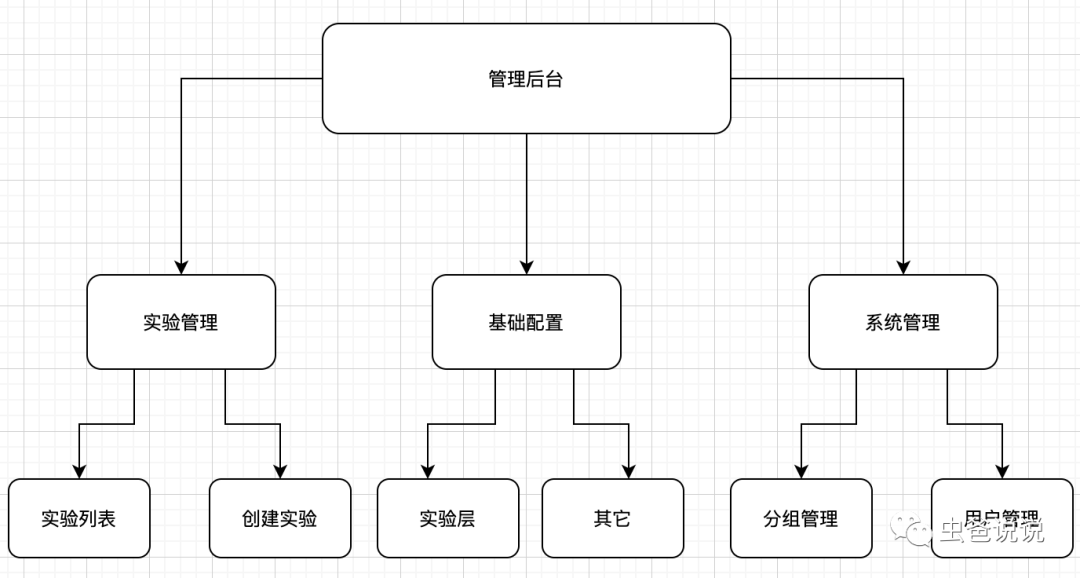
管理后台
用来管理实验的,比如权限管理、层管理等,如下图:
-
实验管理,顾名思义,管理现有实验和创建新实验
-
实验列表:现有已经创建的所有实验
-
创建实验:创建新实验
-
基础配置,一些配置管理信息都在此模块中
-
实验层:增删改实验层
-
其他:针对实验做的一些定制化,比如增加广告位定向、年龄定向等
-
系统管理,主要针对用户及其分组
-
分组管理,管理用户属于某个分组
-
实验平台的用户权限管理,比如普通权限或者管理员权限
需要注意的是,用户管理这块的权限非常重要,因为实验平台可能涉及到很核心的实验,比如商业化中策略影响的实验,所以用户之间不能看到其他人创建的实验,这层物理隔离非常重要。
分流平台
分流评估 ,顾名思义,对流量进行分离,有两个功能:
- 承接实验后台的实验消息,建立维度索引
- 接收线上流量,根据维度索引、白名单以及对用户设备哈希分桶后,给流量打标签
分流平台,是整个实验平台的核心模块,一定要高性能,高可靠。
六、实验效果
请求的实验信息会以标签的形式上报给sdk,sdk在进行曝光点击的时候,会将这些信息上报,比如"123_456_789"格式。最终,这些会经过广告实时流系统进行消费、数据清洗、实验效果指标计算等工作。由于广告系统是多业务指标系统,包括售卖率,ECPM, CTR, ACPE,负反馈率、财务消耗计算等。广告实时流系统还需要日志的关联工作,比如关联广告互动日志,广告负反馈日志。实时流的计算的结果,会落地到druid 系统,方便实验效果数据的快速检索和二度加工。实验效果实时指标数据计算延迟控制在一定的范围内。
七、结语
最后需要提的是,实验平台在效果跟踪决策方面是有一定的局限性的。实验平台可以进行实验效果的快速跟踪,但是却很难进行实验效果好坏的决策。比如:如果对比实验效果指标值全部提高或下降了,可以简单认为对比实验的策略调整起正向作用或者反向作用;如果对比实验的实验效果指标值部分提高了,部分下降了,就不太好认定了。还有,实验效果的短期效应和长期效应也可能是不一致,这将大大增加了实验效果好坏的决策难度。
因此,实验平台是可以快速提升广告业务策略迭代效率的工具,但是要想进行实验好坏评定的决策,还需要很长的路要走。