云原生 etcd 系列|存储引擎 boltdb 的设计奥秘?
etcd 的存储
etcd v3 是使用的持久化存储来存储它的 kv 数据,etcd 存储的是非常核心的元数据信息,所以最重要的是稳定。使用的是 boltdb 。下面说道说道这个 boltdb 。
boltdb 是什么?
boltdb 是一个非常出名的存储引擎,纯 Go 语言实现的 KV 存储引擎。
boltdb 项目非常值得学习,封装的 API 简单,内部实现很精巧。整个项目去掉注释,测试代码啥的,就几千行代码。Github 地址为 https://github.com/boltdb/bolt 。但 boltdb 项目已经由原作者封版了,不再迭代更新。
etcd 自己 fork 了一个 boltdb 分支出来,上面做了一些自己的小优化。
boltdb 启发于 Howard Chu's LMDB[1] 项目,感兴趣的也可以去看下。
特点:
- 整个数据库就一个 db 文件,贼简单;
- 基于 B+ 树的索引,读效率高效且稳定;
- 读事务可多个并发,写事务只能串行;
缺点:
- 事务的实现贼简单,但是写的开销太大;
- boltdb 写事务不能并发,只能靠批量操作来缓解性能问题;
下面我们从外到内一步步探索下 boltdb 的实现。
boltdb 看起来是什么样子?
整个 db 就一个单文件,只不过这个文件内容是有格式的。先用 hexdump 看一眼:
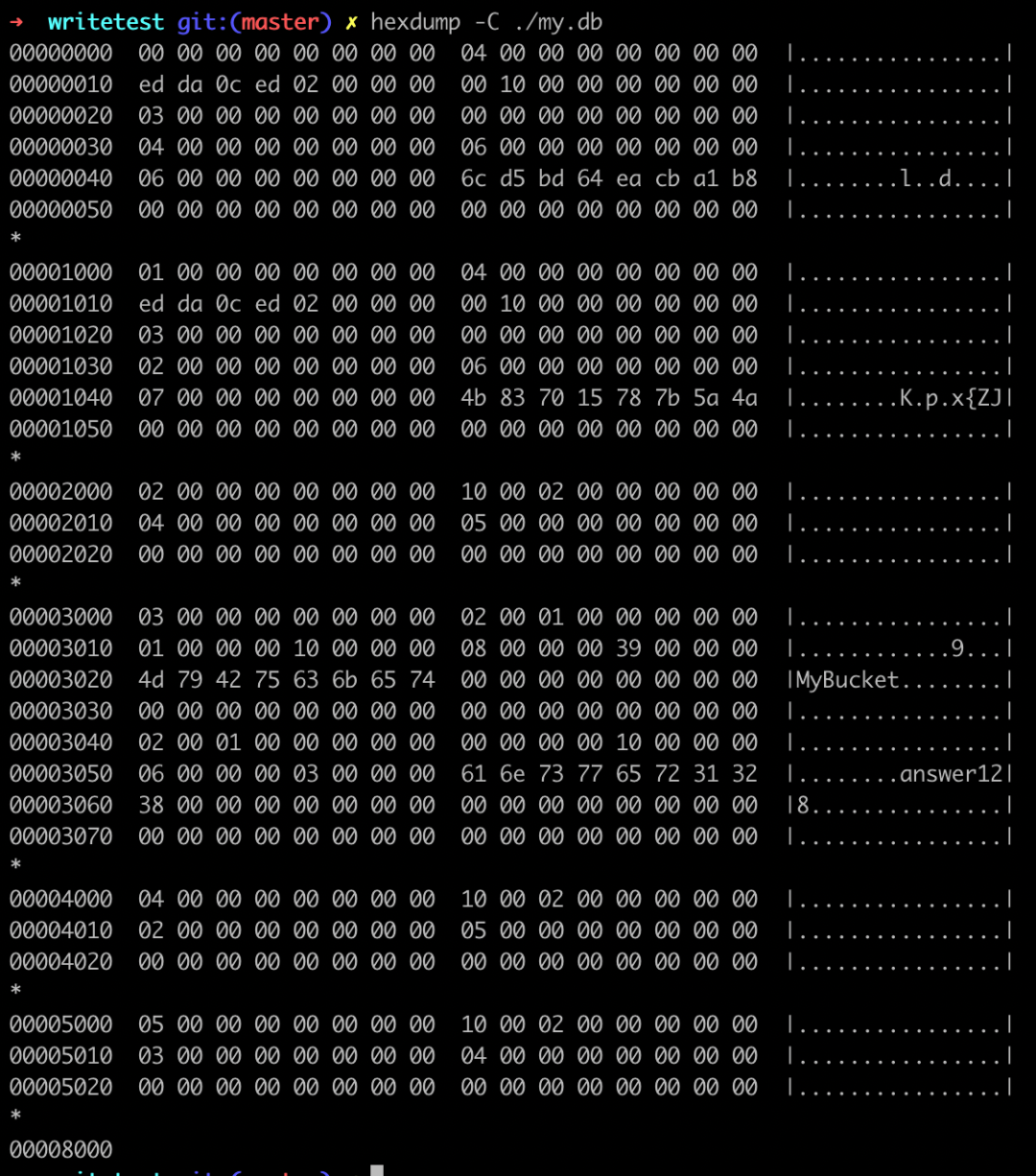
仔细的童鞋会发现,这个数据间隔有点意思?
0000 // 0 偏移
1000 // 4k 偏移
2000 // 8k 偏移
3000 // 12k 偏移
4000 // 16k 偏移
5000 // 16k 偏移每个偏移都是 4k 的间隔,里面还有一些看不懂的二进制数据。以前奇伢说过,越往底层都会有一个存储单元的概念,因为要合并一些边际开销,比如,文件系统大多以 4k 为单位进行管理,page cache 也以 4k 为单位管理。再看硬件,也是如此,磁盘的最小处理单位是扇区( 512字节 ),ssd 的读写是以 4k 为单位管理的。
boltdb 作为一个存储引擎,自然要统筹管理空间的使用,自然也有这么一个概念。boltdb 以 4k 定长为存储单元划分空间,这一个个 4k 叫做 page,boltdb 在上面建立更抽象的概念。
来看看 boltdb 怎么管理空间的吧。
怎么管理空间?
上面提到是以 4k 为粒度来管理空间的,每个 4k 叫做 page 。
1 page 页
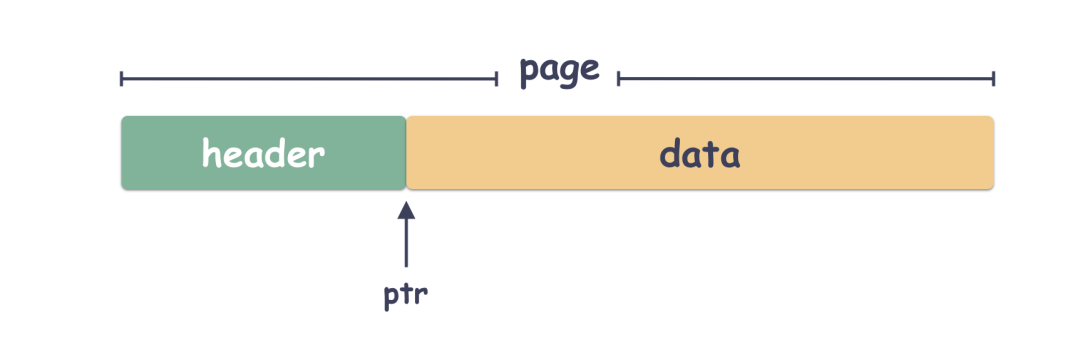
为了方便管理,page 自然也是会有格式的,每个 page 都会有 header ,header 后面是 data 数据。
// header 结构体
type page struct {
id pgid // page 编号
flags uint16 // 标明 page 的属性
count uint16 // 标明 page 上有多少个元素
overflow uint32 // 标明后面是不是还有连续的页跟着
ptr uintptr // 这就是个用来定界的
}示意图:
从物理层面来说
boltdb 的 db 文件来说就是由这样一个个 page 组成的。举个例子,如果是一个 32K 的文件,那么就由 8 个 page 组成,每个 page 都有自己的唯一编号( pgid ),从 0 到 7 。
从逻辑层面来说
boltdb 把这一个个 page 组成了一个树形结构,它们之间通过 page id 关联起来。我们再往下思考:
- 第一个点:树自然会有个源头,比如从那个 page 开始索引,还有一些最关键的元数据( meta 数据 );
- 第二个点:既然是一颗树,那么自然有中间节点、叶子节点;
- 第三个点:既然是空间管理,那么自然要知道哪些是存储了用户数据 page ,哪些是空闲的 page ;
上面提到的三个点都指向一个结论:page 的用途是不一样的。也就是说,虽然大家都是 page,但是身份不一样。有的是叶子节点,有的是中间节点,有的是 meta 节点,有的是 free 节点。这个由 page.flag 来标识。
const (
branchPageFlag = 0x01
leafPageFlag = 0x02
metaPageFlag = 0x04
freelistPageFlag = 0x10
)下面分开聊聊这几种 page 页。
2 meta page
元数据的 page ,这可太重要了。对于 boltdb 来说,meta 的 page 位置是固定的,就在 page 0,page 1 这两个位置( 也就是前两个 4k 页 )的位置。一切索引从此开始,简单看下里面的数据含义:
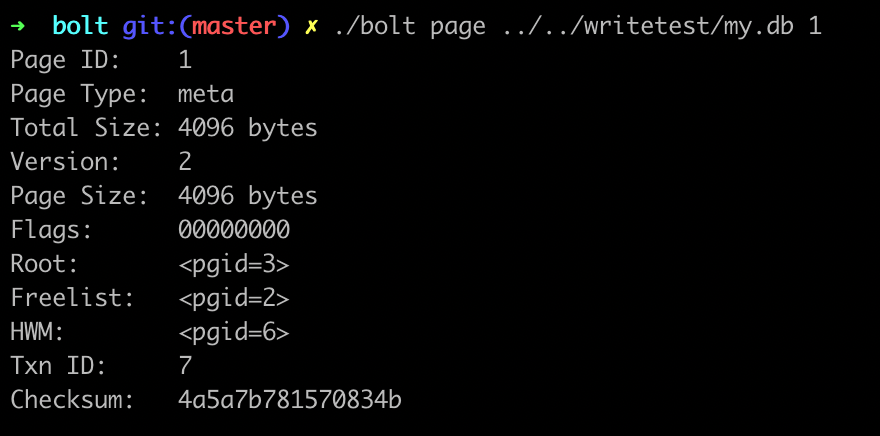
- Root :指明树根的位置;
- Freelist :指明空闲列表的位置;
- Txn :事务编号(写事务的时候,事务号会递增);
有童鞋可能会疑惑了,为什么会有两个 meta 页?
这是一个非常重要的设计,在 boltdb 里有一个非常重要的设计:没有覆盖写,也就是不会原地更新数据。这个是 boltdb 实现 ACID 事务的秘密。
以前也提过,覆盖写是数据损坏的根源之一。因为写数据的时候可能会出现任何异常,比如写部分成功,部分失败 这种就不符合事务的 ACID 原则。
但由于 meta 是 boltdb 一切的源头,所以它必须是固定位置( 不然就找不到它 )。但为什么会有 paid 0,1 两个位置呢?
诀窍就在于:通过轮转写来解决覆盖写的问题。 每次 meta 的更新都不会直接更新最新的位置,而是写上上次的位置。

// 计算 page id 的位置
p.id = pgid(m.txid % 2)举个例子:
- 事务 0 写 page 0 ;
- 事务 1 写 page 1 ;
- 事务 2 写 page 0 ;
- 事务 3 写 page 1 ;
3 branch page
branch 的 page 就是做了树的叶子节点,这个没啥讲的,里面就是存储的 branch 的节点。本质也是 key/value,key 是用户的 key,只不过 value 是 page 的索引而已。看一下结构体:
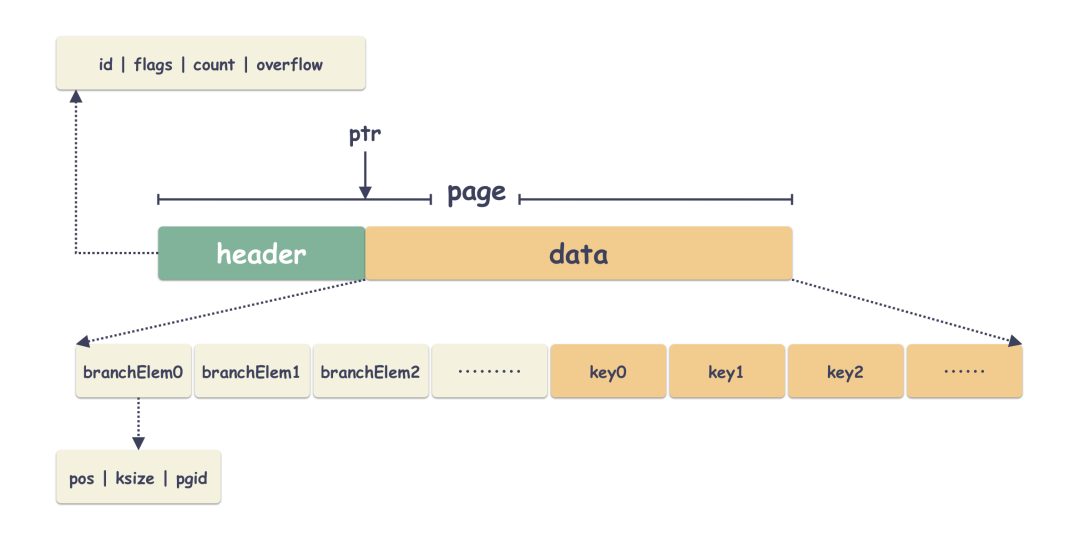
4 leaf page
叶子节点里面主要存储的是用户的数据,这个没啥讲的,一堆 key/value ,key 是用户的 key,value 是用户的数据。
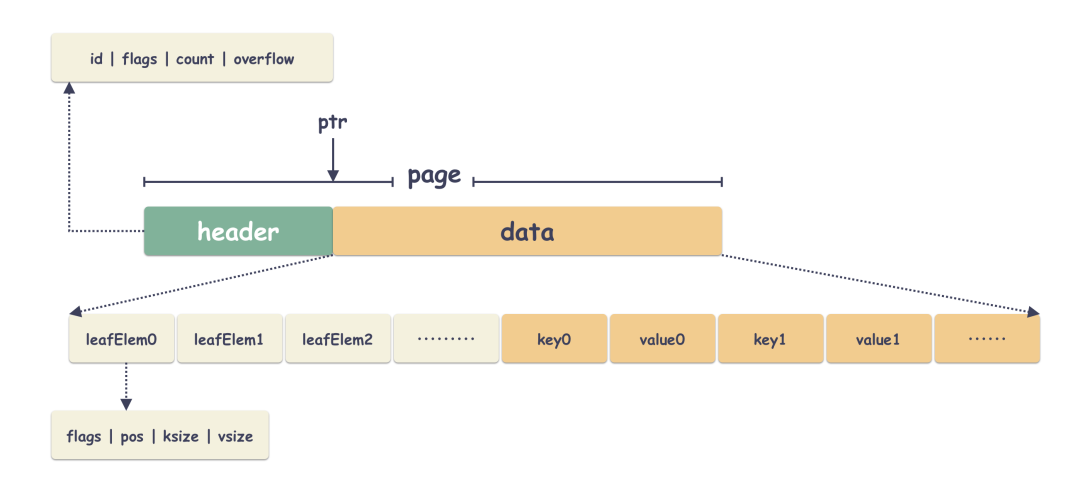
5 freelist page
所谓 freelist page 也就是说 page 里面存储的是一个个 pgid ,这些个 pgid 都是空闲可用的 page 的 id 。当写事务需要空闲的 page 存储数据的时候,就可以从这个里面捞一个来用。
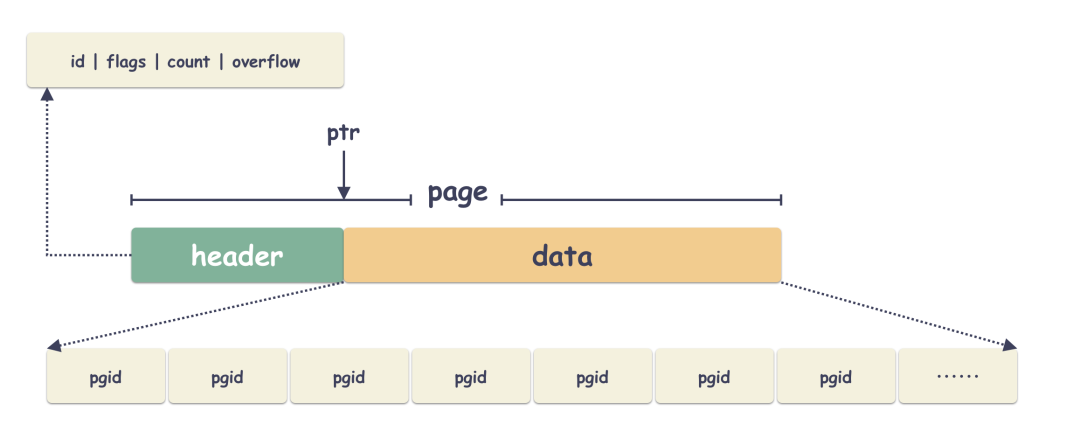
怎么索引数据的?
现在我们知道了存储的管理单元是 page,每个都由 header + data 组成,page 的类型则决定了 data 里面装什么数据。最主要是四种 page :
- meta 的数据;
- 中间节点的数据(主要是索引数据);
- 叶子节点,存储的是 key/value 数据( 有意思的是这里的 key/value 也是有讲究的,既可能是用户的 key/value 数据,也可能是 bucket 的结构数据 );
- freelist 的数据,里面存储的是一个个 pgid ;
那现在我们看 boltdb 是怎么来组织 page,索引这些数据。
1 B+ 树 ?
都说 boltdb 用的是 B+ 树的形式,说的也是对的,但是 boltdb 的 B+ 树有些变异,几点差异如下:
- 节点的分支个数不是固定值;
- 叶子节点不相互感知,它们之间不存在相互的指向引用;
- 并不保证所有的叶子节点在同一层;
划重点:boltdb 它用的是一个不一样的 B+ 树。 除了上面的,索引查找和数据组织形式都是 B+ 树的样子。
在 boltdb 里面有几个封装的概念:
- Bucket :这是一个 boltdb 封装的一个抽象概念,但本质上呢它就是个命名空间,就是一些 key/value 的集合,不同的 Bucket 可以有同名的 key/value ;
- node :B+ 树节点的抽象封装,可以说 page 是磁盘物理的概念,node 则是逻辑上的抽象了;
在 boltdb 中,Bucket 是可以嵌套的,这一点也带来了很大的灵活性,同样也是代码略微难懂的地方。其实 boltdb 天生就有一个 Bucket ,这个是自动生成的,由 meta 指向,不是用户创建的,后续创建的 Bucket 都是这个 Bucket 的 subbucket 。
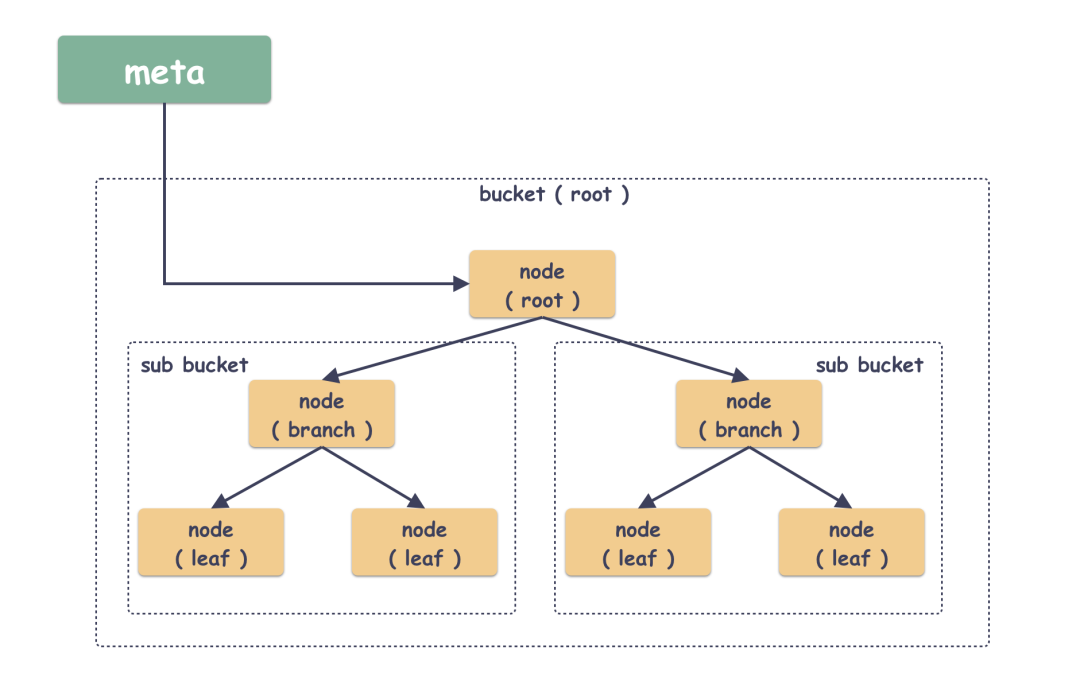
怎么实现的事务?
划重点:boltdb 实现事务的方式非常简单,就是绝对不覆盖更新数据。 其中 meta 是通过两个互为备份的 page 页轮转写实现的,数据页又是怎么实现的呢?
秘密就是:每次都写新的地方,最后更改路径引用。我们来看一下它是怎么做的?看一下演绎的过程:
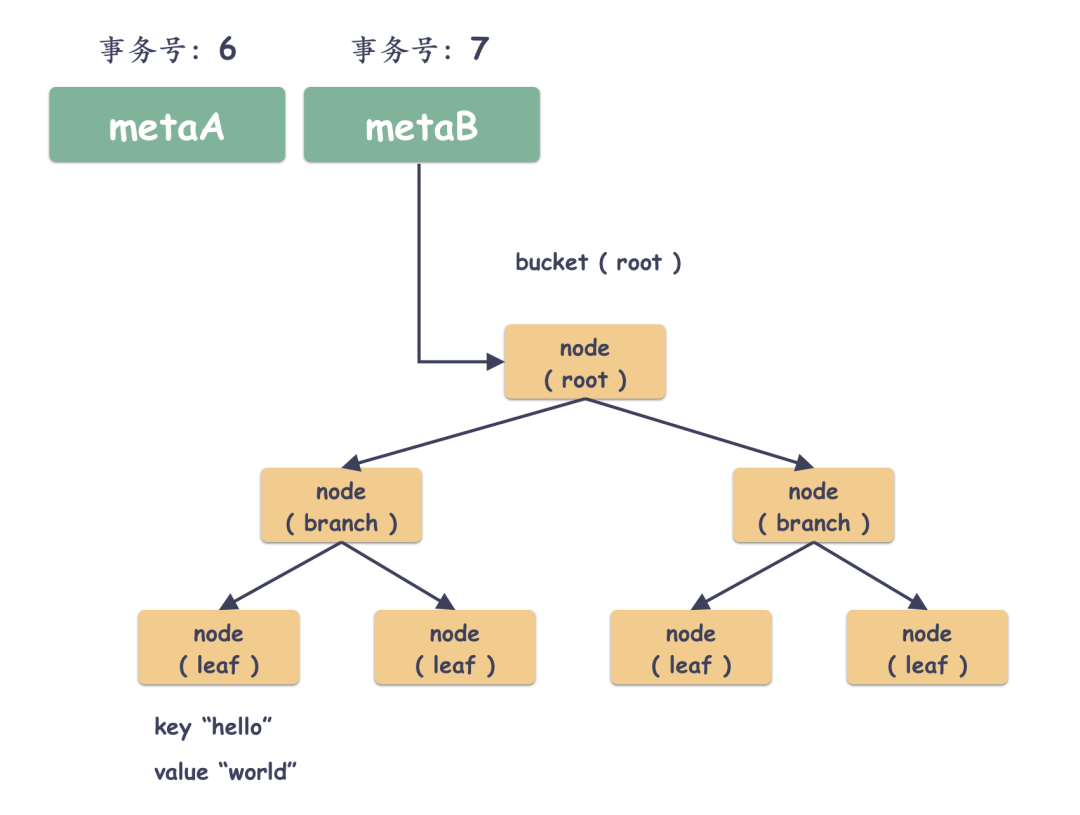
1 现状一棵树
假如当前如下,有个 key/value 键值对( "hello", "world" )存储在一个叶子 page 上。
2 更新前先找位置
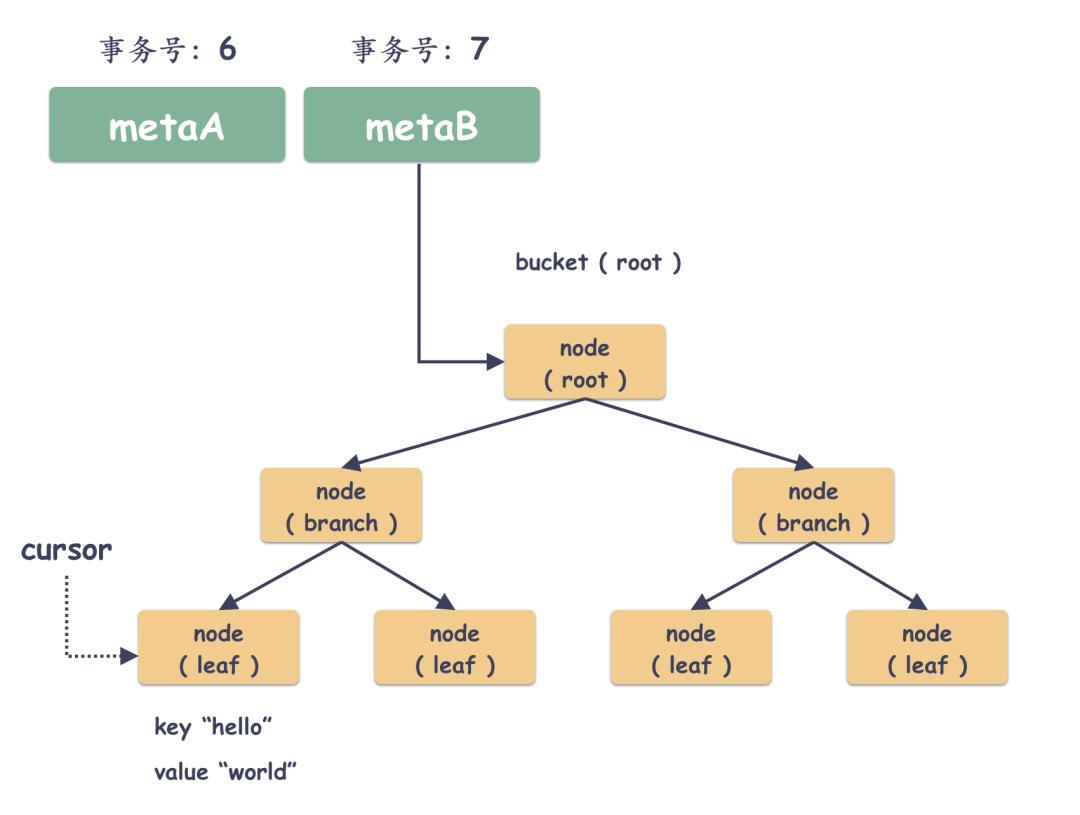
现在用户要更新这个 key="hello" 的值,更新 value 为 "qiya" ,那么很自然的,开启一个写事务,事务号递增+1,boltdb 需要通过 B+ 树的搜索算法定位到叶子节点。
3 定位到后,读改写
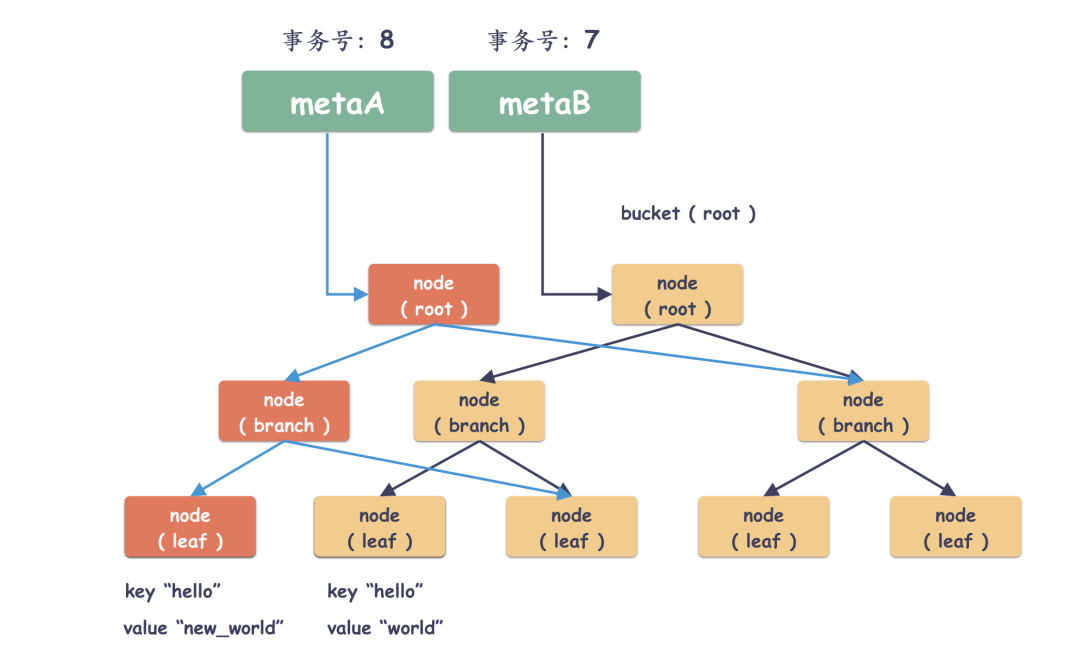
定位到 node 节点之后,怎么修改呢?这个节点里面可不止这一对 key/value,里面还有很多 key/value 。
做法很简单,读改写!也就是先把这个 node 对应的 page 读到内存,把所有的 key/value 加载出来,然后把 key="hello" 的值更新到 value="new_world" ,并且写到新的 page 里。
那问题来了,叶子节点更新了,那指向这个叶子节点的 branch 节点要不要更新呢 ?
自然是要的。那 branch 节点更新了,那 branch 的 branch 节点要不要更新呢?自然是要的。所以这一层层往上推,最终要更新到 meta page 的,也就是树根。
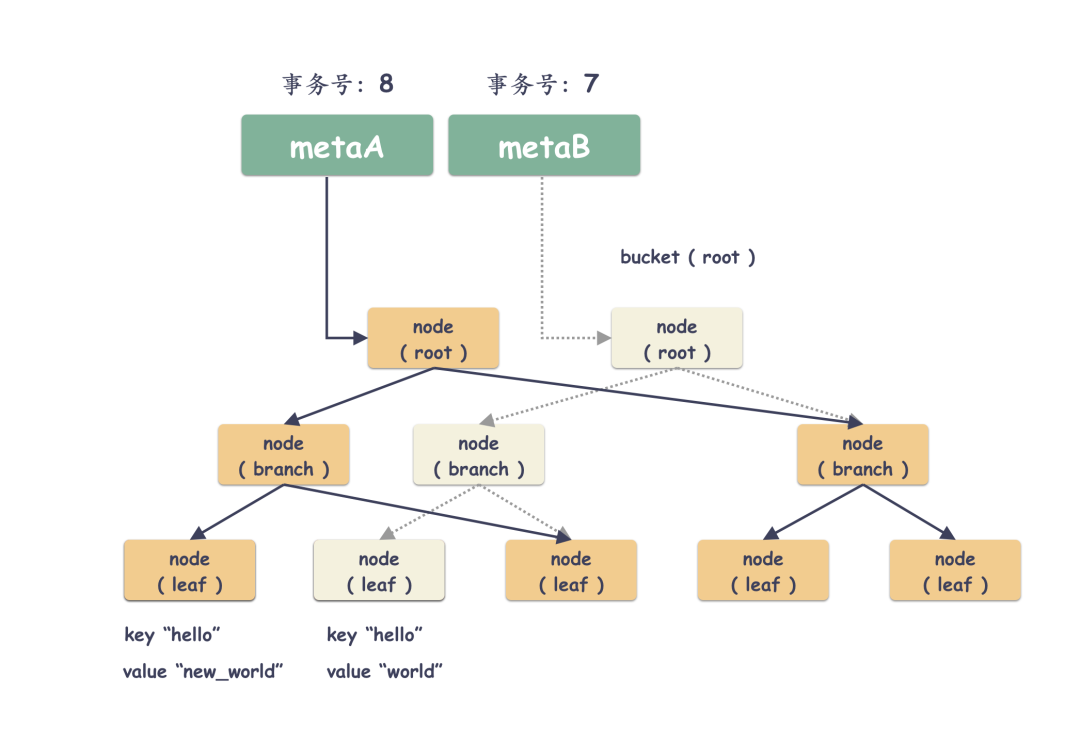
4 最后切换树根,被新 page 替换的最终会被释放
最终这些被替换的 page 就会被纳入到 freelist 里面,完全没有事务引用的话就会被释放。
5 小结一下
上面就是写事务的方式,总结一下:
- 通过 key 查询到位于 B+ 树的那个 page ;
- 把这个 page 读出来,构建 node 节点,更新 node 的内容;
- 把 node 的内容写到空闲的的 page ,并且一层层往上;
- 最终更新 meta 索引内容;
这里我先提一点个人的思考,很多人提到 boltdb 这是一种 cow ( copy-on-write )的方式,但其实我更偏向于把这个理解成 row 的方式。你觉得呢?
总结
- etcd 使用 boltdb 来做存储引擎,读性能还行,写性能很一般,但是它稳;
- boltdb 的物理存储单元是 page ,一般为 4k 一个;
- page 有不同的类型,里面的内容根据类型不一样而不同;
- boltdb 使用 row 的方式(个人理解),保证无覆盖写,等到 commit 的时候,最终修改引用,从而切换整个 db 的路径。这样的方式几乎是 0 成本实现的 ACID 事务;
- meta 的 page 有两个,它们通过轮转写来实现的不覆盖写,从而保证了数据更新的安全;
- B+ 树相比 LSM Tree 天然就有随机读的性能优势,它的树高度稳定,boltdb 通过 mmap 把文件映射到内存,这样简化了代码,读的缓存交给了操作系统的 page cache ;
- boltdb 写性能可能很差,因为只要改了一点点东西,都会导致这个节点到 root 节点整条链路的更新,写放大挺严重的,所以它只能靠 batch 操作来安慰自己;
参考资料
[1]LMDB Github 地址: https://github.com/LMDB
后记
boltdb 我觉得很赞,设计巧妙,安全稳定。
~完~