谈谈浏览器中富文本编辑器的技术演进
发展历程

富文本编辑器按发展历程而言,分为 L0、L1、L2 三个阶段,每个阶段都比上一个阶段定制程度更高,由浏览器导致的问题也更少(因为强依赖浏览器 API 的情况更少),同时开发难度也更大。本文将详细讲解各个阶段,然后列举一些相关的产品来加以说明。
L0 阶段
这是富文本编辑器的早期阶段,这个阶段的编辑器强依赖于 DOM API,包括:
- 可编辑内容依赖
contenteditableAPI; - 编辑内容使用
document.execCommandAPI。
并且没有抽象的数据模型来描述富文本编辑器的内容与状态。这个阶段的编辑器有大名鼎鼎的 UEditor,也有 CKEditor 1 - 4,至今许多邮件编辑器也依然处于这个阶段。
Content Editable
L0 阶段的编辑器主要就是依赖于 Content Editable API 来实现功能的。首先,任何 HTML 元素加上 contenteditable="true" 之后里面的内容都可以被编辑,然后,如果想点击某个按钮来操控这些内容,则可以通过浏览器提供 document.execCommand API 来实现。document.execCommand 支持的操作类型多种多样,包括加粗、改背景、绑定链接、复制、剪切等等。
查看有哪些 command[1]。(链接见文末)
优势
L0 阶段的编辑器主要优势有:
- 技术门槛低;
- 基于浏览器原生编辑能力,输入非常流畅;
- 没有令人头疼的组合输入问题,这点会在后文中详细说明。
劣势
当然,这个阶段的劣势也比较明显。
劣势一
首先,第一个问题就是不同浏览器对于同一个操作有不同的实现,导致视觉与实际 DOM 存在一对多的关系。比如对于设置 粗斜体 这个操作,不同浏览器的实现的 DOM 就不同,可能存在以下情况:
<strong><em>粗斜体</em></strong>
<em><strong>粗斜体</strong></em>
<strong><em>粗</em></strong><strong><em>斜</em></strong><strong><em>体</em></strong>
<em><strong>粗</strong></em><em><strong>斜</strong></em><em><strong>体</strong></em>这种结构最直接的影响就是样式不好设置,上例还好,有些操作会用不同标签实现,这样一来就得兼容多个浏览器,给多个标签设置样式。
劣势二
第二个问题是不同浏览器的选区实现也不同,导致视觉选区与实际 DOM 选区之间存在多对多的关系。
再以选中 粗斜体 的斜体为例,视觉上选中了斜体,实际上就不清楚了,假设 DOM 结构是 <em>粗斜体</em>,那么就存在下列可能:
- 选中了
粗斜体,如果做删除操作,会遗留标签; - 选中了
<em>粗斜体</em>,如果做删除操作,也会遗留strong标签; - 选中了
<em>粗斜体</em>。
再结合上面多种 DOM 结构,每种都可能有多种选区,那么我们要做的兼容处理就更加复杂。
劣势三
第三个问题是光标放置的位置也是不确定的。
假设在 粗斜体 前插入 i 字符,实际上可能是这些情况:
- i****粗斜体 =>
i<em>粗斜体</em>; - i粗斜体 =>
<em>i粗斜体</em>; - i 粗斜体 =>
i<em>粗斜体</em>。
劣势四
第四个问题发生在复制粘贴操作上,永远都不可能确定从别的地方复制过来的内容粘贴到 L0 阶段的编辑器上会发生什么,因为:
- 复制的内容的
HTML标签充满着可能性; - 永远不知道浏览器是怎么处理这些标签的。
劣势五
没有办法实现协同。
总结
随着浏览器的演变,上述问题可能有些已经越来越趋向于统一,但仍不可避免的还会有许多,更关键的是不受控制,BUG 随时可能会出现,修修补补也将会越来越多,项目也会越来越难以维护。因此,L1 阶段的编辑器就应运而生。
L1 阶段
这个阶段是大多数现在富文本编辑器所处在的阶段,比如 Quill,CKEditor 5,Slate,Draft.js 等等,它最明显的两个特点是:
- 仍然依赖于
contenteditableAPI 来使得内容能编辑,但是不再依赖document.execCommandAPI 来操作内容,而是改为自己实现。 - 有抽象的数据模型来描述富文本编辑器的内容与状态。
Modal - 编辑器内容的抽象
上面说到,L1 阶段的编辑器会有抽象的数据模型来描述富文本编辑器的内容与状态,这个数据模型就被称为 Modal,当然,不同编辑器给取的名字会不一样,下面举两个编辑器来说明。
L1 阶段的鼻祖 Quill 的 Modal
例如下面这段话:
A B C D
在 Quill 就会用这样一个数据结构去表示:
{
"ops": [
{
"insert": "A\nB "
},
{
"insert": "C",
"attributes": {
"bold": true
}
},
{
"insert": "D"
}
]
}Quill 的 Modal 基于 OT 模型,有 retain,insert,delete 三种操作类型,使用可选的 attributes 属性来标记内容的一些特性。这种模型使得它天生就支持协同。Quill 管这个 Modal 叫 Delta。
Quill 抛弃了 DOM 的节点树的层次,因此完全看不出包裹文字的标签和节点关系,只有一个扁平化后的数组 ops。几乎所有的 L1 阶段的富文本编辑都会做或多或少的扁平化,Quill 是最彻底的那一类。当然,扁平化带来的好处是对性能提升有帮助,弊端则是在表示一些复杂的嵌套内容时会比较吃力,比如在表格的单元格中插入另一个表格。
Slate 编辑器的 Modal
Slate 保留了 DOM 的树形结构,因此节点的层次关系是比较直观明了的。下面是上面那个例子的表示:
[
{
"type": "paragraph",
"children": [
{
"text": "A"
}
]
},
{
"type": "paragraph",
"children": [
{
"text": "B "
},
{
"text": "C",
"bold": true
},
{
"text": " D"
}
]
}
]View - 将 Modal 渲染出来
View 层类似 React 中的 render,将 Modal 数据给渲染出来,渲染出来的内容包括编辑器内的内容和选区等。这样一来,就能够自己决定什么样的内容输出什么样的 DOM 结构,不依靠浏览器的实现,从而避免 L0 中 DOM 结构多样性的问题。不同编辑器对 View 层的称呼不一样,比如 Slate 就称之为 Rendering。如今,很多编辑器都基于 VM 框架(如 React)来实现 View 层。
Selection 的进一步封装
无论是 L0 还是 L1 阶段,选区都需要在原生 Selection API 的基础上进行封装来实现。原生的 Selection 对象是由多个 Range 对象组成的,Range 对象内包含以下四个属性:
anchorNode:代表鼠标开始按下处的文字或叶子节点;anchorOffset:代表鼠标开始按下处的文字在文字节点中的第几个或叶子节点之前的同级节点数;focusNode:代表鼠标松开时的文字或叶子节点;focusOffset:代表鼠标松开时的文字在文字节点中的第几个或叶子节点之前的同级节点数。
相比 L0 阶段,L1 阶段的编辑器会将 Modal 的一些数据封装到 Selection 对象中去。下面举几个编辑器的例子来说明。
Quill 的抽象
Quill 的 Selection 与原生的不同,只有一个 Range 对象。Range 也只由 { index, length } 这种极其简单的数据组成:
-
index表示选区开始的内容距离开头的绝对位置; -
绝对位置的计算就是把当前内容之前所有的内容数量都加起来;
-
单个文字、图片、视频等这样的内容都是按数量 1 来计算的。
-
length表示选中区域的内容的数量。
Quill 的 Range 能这么设计与它的 Modal 设计是强相关的。
Slate 的抽象
Slate 的 Selection 对象也只有一个 Range 对象。它 的 Selection 对象参考了原生的实现,有 anchor 和 focus 两个对象。
anchor 对象由 path 和 offset 属性组成,path 相当于 anchorNode 的角色,用来确定节点的位置 offset 相当于 anchorOffset,用来确定文字等内容在节点中的位置,focus 也类似。
例如下例中的 Text 节点的 path 是 [0, 1, 0],然后假设 Text 节点的内容是 123,那么其中 2 的 offset 就是 1。

总结
L1 阶段的编辑器对 Selection 的封装方式使得选区也有一种数据结构,从而使得同一份数据结构有唯一的渲染,避免 L0 中选区的问题。
Commands - 能被称为 L1 阶段的核心要点
L1 阶段的编辑器摒弃了浏览器的 document.execCommand,从而完全自己来实现对编辑器内容的操作,它能在很大程度上避免 L0 中浏览器操作的不确定性。
事件监听
L1 阶段的编辑器大都会通过事件监听来猜测用户想要对内容的操作。这种方式的好处显而易见:通过监听 DOM 事件来操作 Modal,从而能保证唯一的渲染。
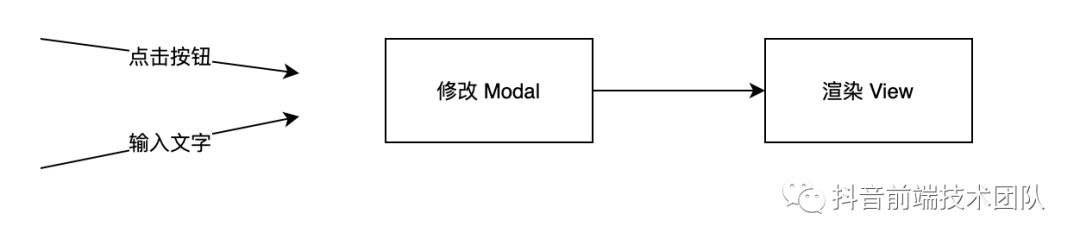
如果用户在编辑区域进行输入的话,那么可以通过 beforeinput 之类的事件知道用户准备输入什么。但这种方法依然会遇到一些问题,最大的问题就是上文中提到的组合输入问题。
组合指的就是 操作系统、输入法、浏览器 加在一起的组合。一个用户输入的内容经过这三者才到达我们的事件监听函数中。那么其中任何一环出现差错就可能会带来如下问题:
- 不是所有的用户操作都有事件支持,例如某些安卓机输入法的联想词;
- 有些操作触发的事件是错误的,例如用户在输入文字,但识别成删除文字;
- 浏览器对事件支持的兼容性问题,例如
beforeinput就有些浏览器不支持,或支持不全面。
DOM 变更监听
除了事件监听,另一个方式就是 DOM 变更监听。我们依然使用 contenteditable="true" 来使得编辑器内容是可以被编辑的。然后使用 Mutation Observer[2] 来监听编辑器内容的变化,接着根据内容的变化反推用户的操作,从而修改 Modal,最后再次根据 Modal 渲染一遍编辑器内的内容,确保内容的确定性。
这种方式弥补了一些事件监听的不足,但仍然有缺陷:
- 反推的过程完全是根据经验,难免有经验不足,某些情况没考虑到的情况;
- 可能发生错误的推测,造成错误的渲染。
使用 VM 框架带来的一些问题
上文中说到现在很多编辑器会使用 VM 框架来做渲染,这就使得 Modal 和 View 之间还存在 Virtual DOM。但由于 contenteditable 能绕开 VM 框架直接操作 DOM,所以可能会遇到状态不一致或者渲染错误的问题,这就需要去花时间解决。
Slate 的 Commands 实现
Slate 完全重写了 Commands API,它是结合事件监听和 Mutation Observer 一起来实现的,它自己定义了一套 Transform API 去更改 Modal,使用者可以自定义 Modal 到 DOM 的渲染逻辑。它的渲染层可以是 React,也可以是其他框架。
Operations - 多人协同必备
Operations 就是记录了一系列原子化操作的数组。以 Quill 为例,它的 Operations 的数据结构与 Modal 一致(上文提到过 Quill 的 Modal 就是一系列原子化的操作),不过与 Modal 描述当前内容不同,Operations 记录了所有的原子化操作,也可以说 Modal 是 Operations 经过一定的转换(例如合并一些项)得到的。
Operations 对实现 OT 算法很有帮助。OT 算法本质上是将不同用户的原子化操作合并的过程,目的是为了解决多人编辑之间的冲突。Quill 的 OT 算法在 quill-delta 库中实现的。
要了解 OT 算法可以 阅读这篇文章[3]。(链接见文末)
优势
L1 阶段的编辑器总结下来有这么一些优点:
- 从原理上解决了大部分 L0 中各种不确定的问题,减少了 BUG 的产生;
- 能支持多人协同;
- 能满足大部分使用场景。
劣势
- 相比 L0 阶段,引进了一些组合输入问题;
- 相比 L0 阶段,引进了可能要处理一些 DOM 变更监听的未知性问题;
- 依然拥有
contenteditable的一些问题,比如光标的兼容性问题等等。
L1 阶段富文本编辑器的比较
下面举了一些富文本编辑器的例子做了些简单的比较:
| 编辑器 | 优点 | 缺点 |
|---|---|---|
| Quill | 首创的 Delta 抽象数据模型 | 数据模型是线性的,无法较容易的支持复杂的嵌套场景,未来可能有大版本改动 |
| Prosemirror | 强大的定制能力 | 新概念和 API 比较多,有着高昂的学习上手成本 |
| Draft.js | React 友好的编辑器 | 数据模型是线性的,无法较容易的支持复杂的嵌套场景 |
| CKEditor 5 | 强大的功能和定制能力 | 几乎没有缺点 |
| Slate | 强大的数据模型,灵活的设计,理论上能实现任何强大的功能 | 底层重构多次,目前版本可能还不稳定 |
L2 阶段
Google Docs 的问世开创了 L2 级别编辑器的时代,它完全不依赖 Content Editable API,包括选区、光标等,都是是自己绘制的,甚至自己实现了一个基于元素和绝对定位的排版引擎,基本上脱离了浏览器自身的大部分排版规则,可以说是非常复杂了。这样做带来的好处是显而易见的:
- 所有浏览器无论做什么操作进行选区的选中,都能够保持一致性,例如在不同浏览器中双击选中,可能有些浏览器选中的是一个词语,有些浏览器选中的是一句话,这是由浏览器自身逻辑决定的,而自己绘制则完全能避免这些问题;
- 不会有光标的兼容性问题,比如光标位置问题偏移、光标显示不正常等等,自行绘制光标无论是在哪个浏览器下,都是一致的;
- 不依赖于浏览器大部分的排版,虽然说 L1 阶段我们可以控制渲染的 DOM 结构和 CSS,但仍然依赖浏览器去排版绘制,像 Google Docs 这种直接基于绝对定位等少量的浏览器特性去自行计算各元素的位置,进行排版,就能极大程度上避免浏览器在排版上的问题。
同时,像分页、标尺、脚注等一些高级功能在有了自己的排版引擎后实现起来就比较简单了。当然,这个阶段的编辑器已经极为复杂了,一般的团队不需要自研这么复杂的编辑器,也用不到。
未来
Google 在今年发表了一篇文章 Google Docs will now use canvas based rendering: this may impact some Chrome extensions[4],宣布将来将进一步脱离 DOM,使用 Canvas 来进行渲染。对于 Google Doc 这样一种极为专业的编辑器来说,这是肯定要走的路,因为上面也说到了,Google Doc 并没有完全脱离浏览器的排版与绘制,另外,像一些字体的渲染仍需要利用浏览器基本的实现,这可能导致不同浏览器的效果存在差异。使用 Canvas 来自己绘制会进一步减少这种问题。另一条需要关注的路线是浏览器的实现逐渐靠着标准进行统一,说不定哪天很多功能又能重回原生了!
参考资料
[1]查看有哪些 command: https://developer.mozilla.org/zh-CN/docs/Web/API/Document/execCommand#%E5%91%BD%E4%BB%A4
[2]Mutation Observer: https://developer.mozilla.org/en-US/docs/Web/API/MutationObserver
[3]阅读这篇文章: https://nicodechal.github.io/2020/08/10/ot-js-transform-analysis/
[4]Google Docs will now use canvas based rendering: this may impact some Chrome extensions: http://workspaceupdates.googleblog.com/2021/05/Google-Docs-Canvas-Based-Rendering-Update.html