node_module 困境与破局
大家好, 这是字节跳动的同学的一篇文章,已经发表了一年半,但每次重读时都与收获。
「目录」
-
1. 术语: -
2. Dependency Hell -
3. npm解决方式 -
4. node_modules的目录结构 -
5. doppelgangers -
6. 版本重复会有问题吗? -
7. 全局types冲突 -
8. 破坏单例模式 -
9. Phantom dependency -
10. Semver 当理想遇到现实 -
10.1. lock 非灵药 -
11. 直接写死版本 -
12. yarn lock vs npm lock -
12.1. Resolutions 救火队长 -
13. 库里应该提交lock文件吗 -
14. determinism !!! -
15. 相对路径是有害的 -
16. 拓扑结构 matters -
16.1. monorepo:link is hard -
16.2. hoist并非安全,考察如下结构 -
17. PNPM: Explicit is better than implicit. -
17.1. phantom dependency -
18. doppelgangers -
18.1. global store -
18.2. cargo: 全局store的包管理系统 -
19. monorepo支持 -
20. 禁止隐式依赖 -
20.1. vendor: for serverless
1 . 术语:
- package:包含了package.json, 使用package.json定义的一个package,通常是对应一个module,也可以不包含module,比如bin里指明一个shell脚本,甚至是任意文件(将registry当做http服务器使用,或者利用unpkg当做cdn使用),一个package可以是一个tar包,也可以是本地file协议,甚至git仓库地址
- module:能被require加载的就叫一个module,如下都是module,只有当module含有package.json的时候才能叫做package,
- 一个包含package.json且含有main字段的文件夹
- 一个含有index.js的文件夹
- 任意的js文件
综合:module不一定是package,package不一定是module
2 . Dependency Hell
现在项目里有两个依赖A和C,A和C分别依赖B的不同版本,如何处理

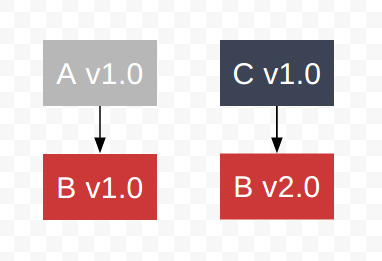
- 首先是B本身支持多版本共存,只要B本身没有副作用,这是很自然的,但是对于很多库如core-js会污染全局环境,本身就不支持多版本共存,因此我们需要尽早的进行报错提示(conflict的warning和运行时的conflict的check)
- 如果B本身支持多版本共存,那么需要保证A正确的加载到B v1.0和C正确的加载到B v2.0
我们重点考虑第二个问题
3 . npm解决方式
node的解决方式是依赖的node加载模块的路径查找算法和node_modules的目录结构来配合解决的
如何从node_modules加载package
核心是递归向上查找node_modules里的package,如果在 '/home/ry/projects/foo.js' 文件里调用了 require('bar.js'),则 Node.js 会按以下顺序查找:
/home/ry/projects/node_modules/bar.js/home/ry/node_modules/bar.js/home/node_modules/bar.js/node_modules/bar.js
该算法有两个核心
https://mp.weixin.qq.com/s/EADPJbjdOR4OLdTW9EzLvQ该算法即简化了 Dependency hell的解决方式,也带来了非常多的问题
4 . node_modules的目录结构
nest mode
利用require先在最近的node_module里查找依赖的特性,我们能想到一个很简单的方式,直接在node_module维护原模块的拓扑图即可
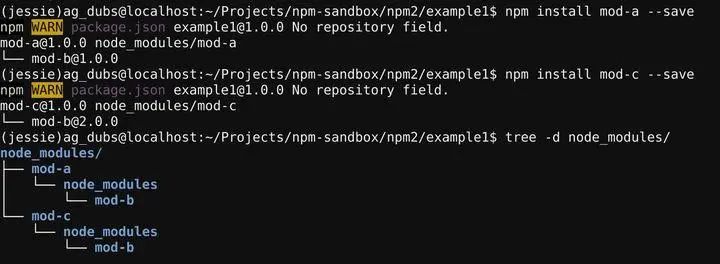


我们还可以利用向上递归查找依赖的特性,将一些公共依赖放在公共的node_module里
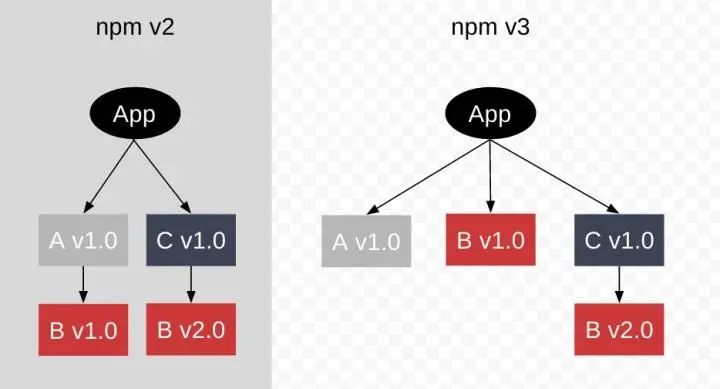
- A和D首先会去自己的node_module里去查找B,发现不存在B,然后递归的向上查找,此时查找到了B的 v1.0版本,符合预期
- C会先查找到自己的node_module里查找到了B v2.0,符合预期
这时我们发现了即解决了depdency hell也避免了npm2 的nest模式导致的重复依赖问题
5 . doppelgangers
但是问题并没有结束,如果此时引入的D依赖的是B v2.0而引入的E依赖的是B v1.0,我们发现无论是把Bv2.0还是Bv1.0放在top level,都会导致另一个版本任何会存在重复的问题,如这里的B的v2.0的重复问题
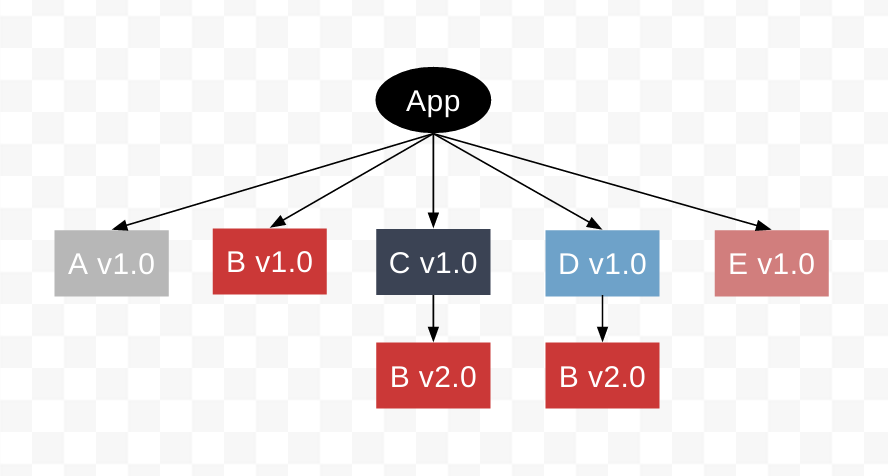
6 . 版本重复会有问题吗?
你也许会说版本重复不就是浪费一点空间吗,而且这种只有出现版本冲突的时候才会碰到,似乎问题不大,事实的确如此,然而某些情况下这仍然会造成问题
7 . 全局types冲突
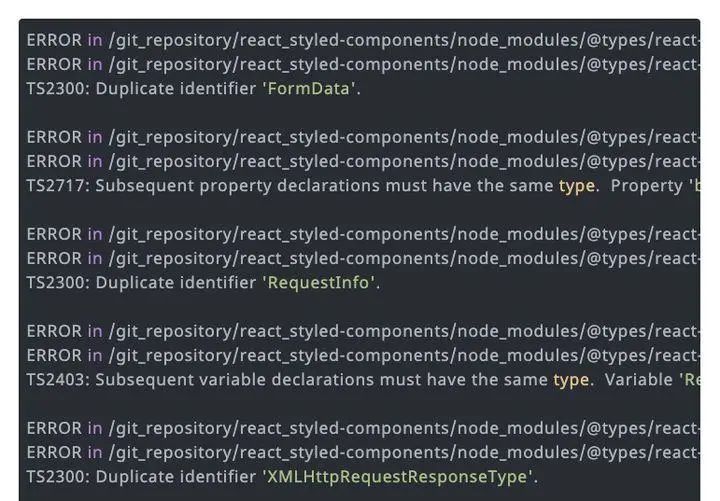
虽然各个package之前的代码不会相互污染,但是他们的types仍然可以相互影响,很多的第三方库会修改全局的类型定义,典型的就是@types/react,如下是一个常见的错误
8 . 破坏单例模式
require的缓存机制 node会对加载的模块进行缓存,第一次加载某个模块后会将结果缓存下来,后续的require调用都返回同一结果,然而node的require的缓存并非是基于module名,而是基于resolve的文件路径的,且是大小写敏感的,这意味着即使你代码里看起来加载的是同一模块的同一版本,如果解析出来的路径名不一致,那么会被视为不同的module,如果同时对该module同时进行副作用操作,就会产生问题。 以react-loadable为例,其同时在browser和node层使用 browser里使用



9 . Phantom dependency
我们发现flat mode相比nest mode节省了很多的空间,然而也带来了一个问题即phantom depdency,考察下如下的项目
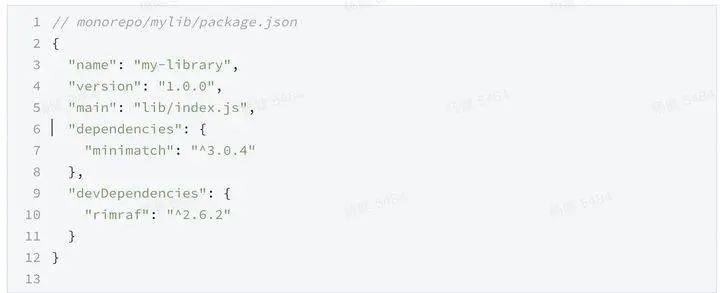

在基于yarn或者npm的node_modules的结构下,doppelganger和phantom dependency似乎并没有太好的解决方式。其本质是因为npm和yarn通过 node resolve算法 配合node_modules的树形结构对原本depdency graph的模拟,哪有没有更好的模拟方式能够避免上述问题呢。
10 . Semver 当理想遇到现实
npm对package版本号采用语义化版本,Semver本身也是为了解决Depdency Hell而引入的解决方案,如果你的项目引入的第三方依赖越来越多,你将会面临一个困境
- 如果你为你的每一个版本都写死依赖,那么如果某个底层的依赖需要修复或者升级,你难以评估这个升级会修复的影响范围,这可能导致级联反应,与其协作的任何包都可能会挂掉,导致整个系统都需要全量的测试回归,最后的结果很大可能是整个应用彻底锁死版本,再也不敢做任何升级改动
因此semver的提出主要是用于控制每个package的影响范围,能够实现系统的平滑升级和过渡,npm每次安装都会按照semver的限制,安装最新的符合约束的依赖。

- 不可预知的bug,本来以为某个版本只是bugfix,发布了patch版本,但是该patch却引入了未预料的breaking change导致semver被破坏
- semver的设计过于理想,实际上即使是最小的bugfix,如果业务方无意中依赖了这个bug,仍然会导致breaking change,bug和breaking change的界限是模糊的
- 认为semver没有太大意义,例如Typescript官方就承认从未遵循semver语义,实际上typescript经常在minor版本引入各种breaking change. https://github.com/microsoft/TypeScript/issues/14116
10.1. lock 非灵药
那么在现实世界该如何处理这种问题,你肯定不希望自己的代码在本地是正常运行的,但是当你上线的时候就挂了吧。 在你的测试完成和业务上线前的gap期间,如果你的某个依赖不遵循semver,产生了breaking change,那么你可能得半夜上线查bug了。我们发现问题的根源在于如何保证测试时候的代码和上线的代码是完全一致的。
11 . 直接写死版本
一个很自然的想法就是,我直接把我的第三方依赖版本都写死不就行了

12 . yarn lock vs npm lock
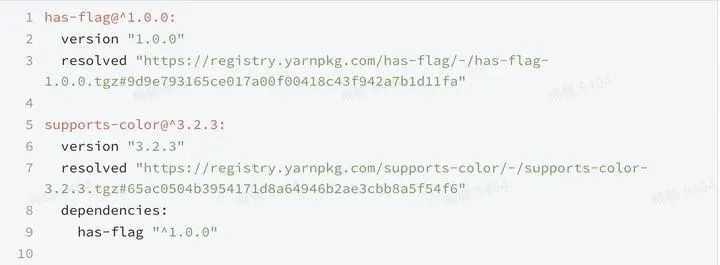
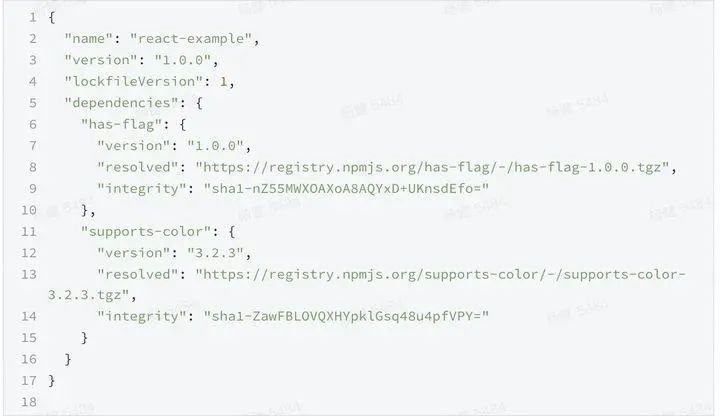
一个更加靠谱的写法是将项目里的依赖和第三方的依赖同时锁定,yarn的lock和npm的lock都支持该功能,一个常见的lock文件如下 如我们的项目安装了express的依赖


然而还是有一些场景lock无法覆盖,当我们第一次安装创建项目时或者第一次安装某个依赖的时候,此时即使第三方库里含有lock文件,但是npm install|(yarn install) 并不会去读取第三方依赖的lock,这导致第一次创建项目的时候,用户还是会可能触发bug。这在全局安装cli的场景下非常常见,经常会碰到上一次安装全局cli的时候正常,但是重新安装这个版本的cli却挂了,这很有可能是该cli的版本的某个上游依赖发生了breaking change,因为不存在全局环境的lock,因此目前没有较好的解决方式。
12.1. Resolutions 救火队长
如果你某天安装了一个新的webpack-cli,却发现这个webpack-cli并不能正常工作,经过一番定位发现,是该cli的一个上游依赖portfinder的最近一个版本有bug,但是该cli的作者在休假,没办法及时修复这个cli,但项目赶着上线该怎么处理?yarn提供了一个叫做[https://classic.yarnpkg.com/en/docs/selective-version-resolutions/](https://classic.yarnpkg.com/en/docs/selective-version-resolutions/)的机制,使得你可以忽略dependency的限制,强行将portfinder锁定为某个没有bug的版本,以解燃眉之急

npm-froce-resolution这个库实现类似机制
13 . 库里应该提交lock文件吗
前面提到npm和yarn在install的时候并不会读取第三方库里的lock文件,那么我们编写库的时候还有必要提供lock文件吗。
不知道大家有没有过这种经验,某天发现了某个第三方库存在某个bug,摩拳擦掌的将该库下载下来,准备修复下发个mr,一顿npm install && npm build 操作猛如虎,然后就见到了一堆莫名其妙的编译错误,这些错误很可能个是编译工具的某个上游依赖的breaking change所致,经过一番google + stackoverflow仍然没有修复,这时候就基本上断了提mr的冲动,如果库的开发者将当前的编译环境的lock提交上来,则很大程度上可以避免该问题。
14 . determinism !!!
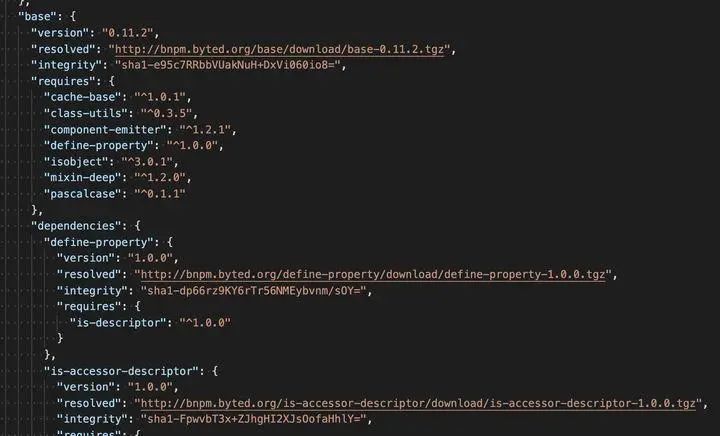
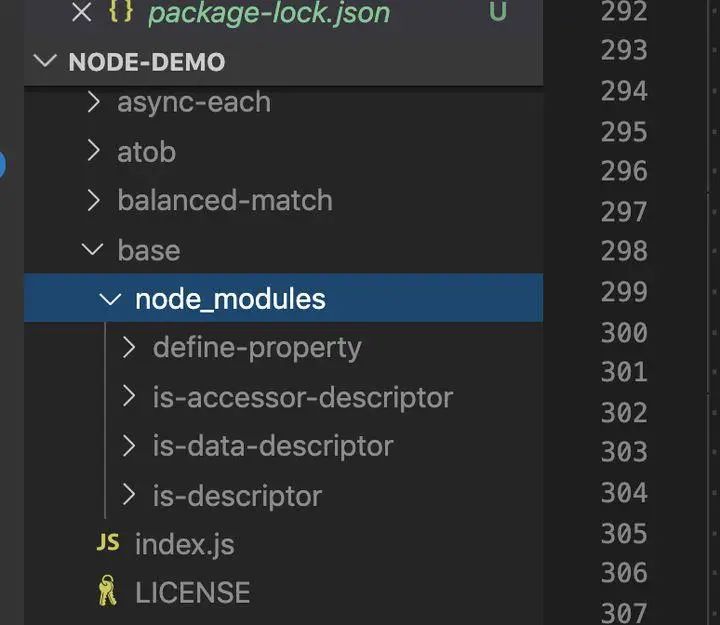
determinism指的是在给定package.json和lock文件下,每次重新install都会得到同样的node_modules的拓扑结构。 事实上yarn仅保证了同一版本的确定性而无法保证不同版本的确定性,npm则保证了不同版本的确定性。 版本确定性 !== 拓扑确定性 我们之前说到yarn.lock保证了所有第三方库和其依赖的版本号是锁定的,虽然保证了版本,但是实际上yarn.lock里并没有包含任何的node_modules拓扑信息
第一种


15 . 相对路径是有害的
16 . 拓扑结构 matters
大部分场景下锁定版本号 + depdency的拓扑结构一致基本上已经没啥问题了,即使node_modules的拓扑结构不一致,也不会产生问题,然而在某些场景下仍然会有问题。 如下的代码实际上是对ndoe_modules的拓扑结构有强假定,一旦@types的位置出现问题就可能存在问题。
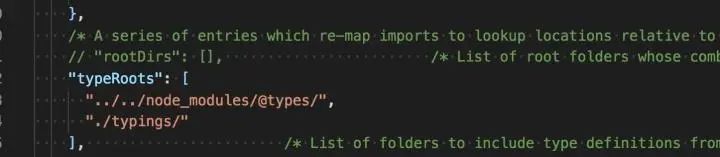
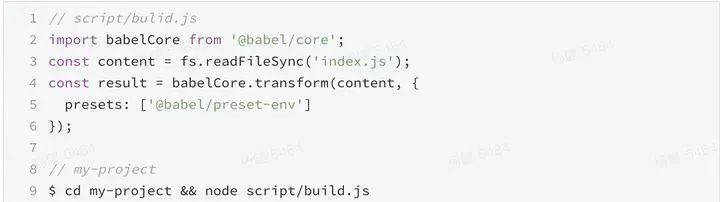
- 当前的工作区:即process.cwd()的返回值这里是my-project
- 当前代码的位置:即my-project/build.js
- 编译工具的位置:即xxx/node_modules/@babel/core
问题来了,这里的@babel/preset-env位置是相对于谁呢,这完全取决于babel/core里的内部实现。
16.1. monorepo:link is hard
如果说第三方库里存在的依赖问题一定程度上还比较可控,那么当我们进入monorepo领域,问题就会被加倍放大。当我们用一个仓库管理多个package的时候,有两个比较严重的问题
- 第三方依赖的重复安装问题,如果packageA和packageB里都使用了lodash的同一版本,没有优化的情况下,需要两个package都重复安装相同的lodash版本
- link hell: 如果A依赖B,B依赖C和D,我们每次开发,都需要执行将C和Dlink到B里,如果拓扑图很复杂的话,手动做这些link操作是难以接受的
无论是lerna还是yarn工作机制核心都是
- 将所有package的依赖都尽量以flat模式安装到root level的node_modules里即hoist,避免各个package重复安装第三方依赖,将有冲突的依赖,安装在自己package的node_modules里,解决依赖的版本冲突问题
- 将各个package都软链到root level的node_modules里,这样各个package利用node的递归查找机制,可以导入其他package,不需要自己进行手动的link
- 将各个package里node_modules的bin软链到root level的node_modules里,保证每个package的npm script能正常运行。
这种方式尽管解决了依赖重复和link hell两个核心问题,却引入了其他问题
- packageA可以轻松的导入packageB,即使没有在packageA里声明packageB为其依赖,甚者packageA可以轻松地导入packageB的第三方依赖,这实际上将Phantom dependency加剧放大了
- packageA里的依赖和packageB的第三方依赖的冲突可能性更大了,如packageA用了webpack3和packageB用了webpack4,这就很容易产生冲突,实际上是加剧了doppelgangers 问题
16.2. hoist并非安全,考察如下结构


17 . PNPM: Explicit is better than implicit.
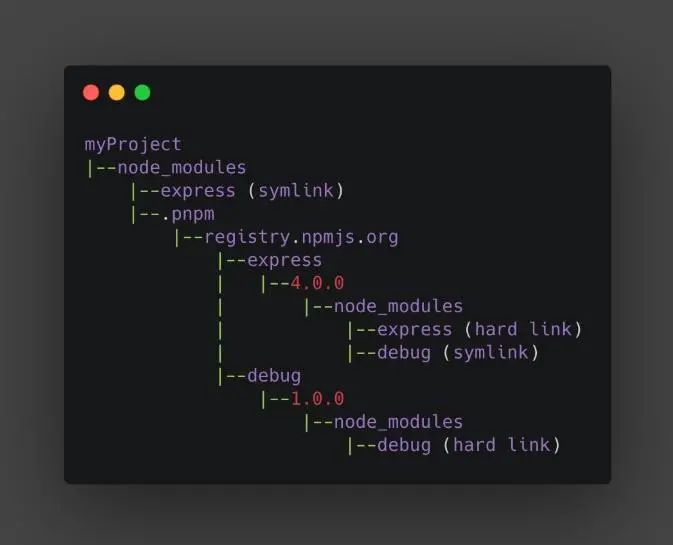
在不考虑循环依赖的情况下,我们实际的depdency graph实际上某种有向无环图(DAG),但是npm和yarn通过文件目录和node resolve算法模拟的实际上是有向无环图的一个超集(多出了很多错误祖先节点和兄弟节点之间的链接),这导致了很多的问题,所以我们需要个更加接近DAG的模拟。pnpm正是采取了这种解决方式,通过更加精确的模拟DAG来解决yarn和npm代理的问题。
17.1. phantom dependency
相比于yarn尽可能的将package放到root level,pnpm则是只将显式写明的dependency的依赖写入root-level的node_modules,这避免了业务里错误的引入隐式依赖的问题,即解决了phantom dependency 以如下例子为例

// src/index.js
const debug = require('debug')如果有一天express决定将debug模块换成了better-debug模块,那么我们的代码就会挂掉。
npm的结构
18 . doppelgangers
pnpm在解决phantom depdency问题的同时,在此基础上也解决了doopelganger问题。 考察如下代码
// package.json
{
"dependencies": {
"debug": "3",
"express": "4.0.0",
"koa": "^2.11.0"
}
}使用pnpm安装相关依赖后,我们发现项目中存在debug的两个版本
dependencies:
debug 3.1.0
express 4.0.0
├── debug 0.8.1
├─┬ send 0.2.0
│ └── debug 1.0.5
└─┬ serve-static 1.0.1
└─┬ send 0.1.4
└── debug 1.0.5
koa 2.11.0
└── debug 3.1.0%查看node_modules里的版本,我们发现区别于yarn,pnpm是将不同版本放在同一层级里通过软链选择加载版本,而yarn则是放在不同层级,依赖递归查找算法来选择版本
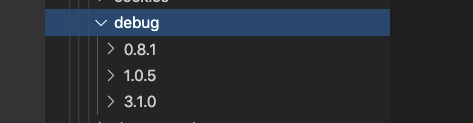

我们可以发现pnpm避免直接依赖node_modules的递归查找依赖的性质,而是直接通过软链解决了phantom dependency和doppelgangers 问题。因为彻底的避免了包的重复问题,其节省了大量的空间和加快了安装速度 以一个monorepo项目为例

18.1. global store
pnpm不仅仅能保证一个项目里的所有package的每个版本是唯一的,甚至能保证你使得你不同的项目之间也可以公用唯一的版本(只需要公用store即可),这样可以极大的节省了磁盘空间。核心就在于pnpm不再依赖于node的递归向上查找node_modules的算法,因为该算法强依赖于node_modules的物理拓扑结构,这也是导致不同项目的项目难以复用node_modules的根源。(还有一种干法,就是使用代码的地方写死依赖的版本号,这是deno的干法)
18.2. cargo: 全局store的包管理系统
实际上除了node的npm,很少有其他的语言是需要每个项目都维护一个node_modules这种依赖(听说过其他语言有node_modules hell的问题吗),其他语言也很少有这种递归查找依赖的做法,所以其他语言很多都采用了全局store的管理系统。我们可以看一下rust是如何进行包管理的。 新建一个rust项目很简单,只需要运行
$ rust new hello-cargo // 创建项目,包含可执行的binary
$ rust new hello-lib --lib // 创建lib,其生成目录结构如下
.
├── Cargo.toml
└── src
└── main.rs其中的Cargo.toml和package.json的功能几乎一致(相比json,tom支持注释),包括如下一些信息
[package]
name = "hello_cargo" // 包名
version = "0.1.0" // 版本号
authors = ["Your Name <you@example.com>"]
edition = "2018"
[dependencies]其中的dependencies用于存放第三方依赖 cargo的src/main.rs为项目的主入口,类似index.js
// src/main.rs
fn main() {
println!("Hello, world!");
}cargo内置了rust的编译功能(相比于js生态里丰富的工具,cargo内置rustc编译的好处是很明显,所有的第三方库只需要提供源码即可,cargo自己完成第一方依赖的递归编译操作)
$ cargo build // 编译生成binary文件
$ cargo run // 执行binary文件我们尝试添加一个第三方依赖看看,与npm类似,cargo的dependencies也支持git协议和file协议。
[dependencies]
time = "0.1.12"
rand = { git = "https://github.com/rust-lang-nursery/rand.git" } // 支持git协议执行build安装依赖,此时发现多了个Cargo.lock,其类似于yarn.lock文件,里面包含了第三方库的及其依赖的确定性版本
# This file is automatically @generated by Cargo.
# It is not intended for manual editing.
[[package]]
name = "hello_cargo"
version = "0.1.0"
dependencies = [
"time",
]
[[package]]
name = "libc"
version = "0.2.69"
source = "registry+https://github.com/rust-lang/crates.io-index"
checksum = "99e85c08494b21a9054e7fe1374a732aeadaff3980b6990b94bfd3a70f690005"
[[package]]
name = "time"
version = "0.1.43"
source = "registry+https://github.com/rust-lang/crates.io-index"
checksum = "ca8a50ef2360fbd1eeb0ecd46795a87a19024eb4b53c5dc916ca1fd95fe62438"
dependencies = [
"libc",
"winapi",
]
[[package]]
name = "winapi"
version = "0.3.8"
source = "registry+https://github.com/rust-lang/crates.io-index"
checksum = "8093091eeb260906a183e6ae1abdba2ef5ef2257a21801128899c3fc699229c6"
dependencies = [
"winapi-i686-pc-windows-gnu",
"winapi-x86_64-pc-windows-gnu",
]
[[package]]
name = "winapi-i686-pc-windows-gnu"
version = "0.4.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
checksum = "ac3b87c63620426dd9b991e5ce0329eff545bccbbb34f3be09ff6fb6ab51b7b6"
[[package]]
name = "winapi-x86_64-pc-windows-gnu"
version = "0.4.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
checksum = "712e227841d057c1ee1cd2fb22fa7e5a5461ae8e48fa2ca79ec42cfc1931183f"此时的目录结构如下
.
├── Cargo.lock
├── Cargo.toml
├── src
└── target // 编译产物我们发现项目里并没有类似node_modules存放项目所有依赖的东西。
那么他的依赖都存放到哪里了?
cargo home
cargo将所有的第三方依赖的代码,都存放在了称为cargo home的目录里,默认为~/.cargo,其包含三个主要目录
/bin // 存放executable的bin文件
/git // 存放从git协议拉取的第三方库代码
/registry // 存放从registry拉取的第三方库代码19 . monorepo支持
cargo本身也提供了对monorepo的支持,和yarn类似,cargo也是通过workspace的概念来支持monorepo
// Cargo.tom
[workspace]
members = [
"adder",
"hardfist-add-one"
]其几乎等价于下面的yarn.lock
// package.json
{
"workspaces":["adder","hardfist-add-one"]
}我们看下workspace的目录结构
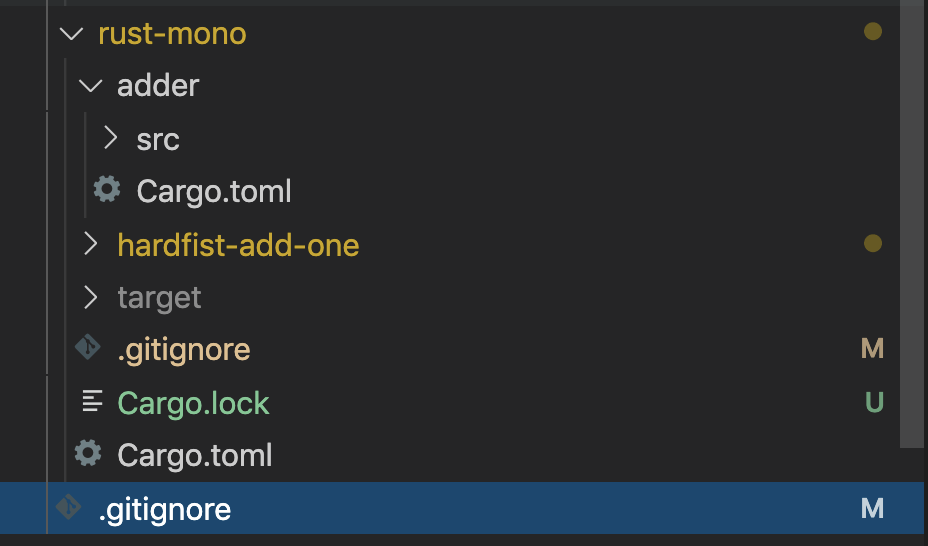
// adder/Cargo.toml
[package]
name = "hardfist-adder"
version = "0.1.0"
authors = ["hardfist <1562502418@qq.com>"]
edition = "2018"
description = "test publish"
license = "MIT"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
hardfist-add-one = { path = "../hardfist-add-one", version="0.1.0" }
rand="0.7"我们可以将hardfist-add-one通过path协议指向本地。 当我们需要将adder进行发布的时候,cargo是不允许发布只包含path路径的dependency的,因此我们需要同时给hard-fist-one指明version用于发布。
20 . 禁止隐式依赖
虽然在同一个workspace里,如果我们的hardfist-add-one依赖了rand,同时hardfist-adder依赖了hardfist-add-one,如果hardfist-adder本身没有将rand声明为其依赖,cargo则进行报错处理
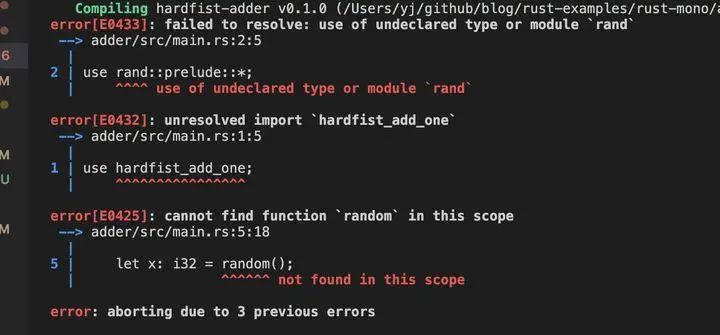
20.1. vendor: for serverless
monorepo还存在的一个较大的问题就是如何分别部署每个package,这在serveless场景下问题更为突出,因为一般serveless的环境对于用户的资源大小都有较大的限制。 当我们使用monorepo管理应用时,部署存在两个问题
- 第三方依赖都安装到root level上,导致package内的node_modules并不包含所有的依赖信息,在scm等构件产物的地方,我们只能选择将所有package的在root-level的node_modules一起打包
- 由于各个package是通过软链来实现互相支持导入的,这导致即使我们打包了node_modules,里面仍然只是包含依赖package的软链,仍然会存在问题。
针对这个问题,基本上有两种解决方式
- 通过打包工具将代码打包为一个bundle,运行时不依赖node_modules
- 将hoist的第三方依赖和link的package都抽取出来放到package里的node_modules里
这两种方案遇到的最大问题就是隐式依赖
对于前端应用bundle习以为常,但是对于服务端应用bundle却并不常见,实际上很多的服务端语言都是采用bundle的方案,如deno、rust、go等,上线的都是一个bundle文件,这个bundle文件可能是binary也可能是其他格式。 实际上node生态里即使服务端也有一些比较成熟bundle方案,如https://github.com/zeit/ncc, 其会智能的处理将server端的代码bundle成一个js文件,更有甚者可以将runtime连同业务代码打包为一个binary文件,如https://github.com/zeit/pkg的方案。 服务端bundle存在最大的问题就是文件读写和动态导入,因为编译功能无法在编译时获取需要读写|导入文件的的信息,因此很难适用于一些约定大于配置的框架(如egg和gulu),但如果是express和koa这种需要显示的写明依赖的框架,是没有问题的。