保姆级教学!这次一定学会babel插件开发!
如果你有babel相关知识基础建议直接跳过 前置知识 部分,直接前往 "插件编写" 部分。
前置知识
什么是AST
学习babel, 必备知识就是理解AST。
那什么是AST呢?
先来看下维基百科的解释:
在计算机科学中,抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构
"源代码语法结构的一种抽象表示" 这几个字要划重点,是我们理解AST的关键,说人话就是按照某种约定好的规范,以树形的数据结构把我们的代码描述出来,让js引擎和转译器能够理解。
举个例子:就好比现在框架会利用虚拟dom这种方式把真实dom结构描述出来再进行操作一样,而对于更底层的代码来说,AST就是用来描述代码的好工具。
当然AST不是JS特有的,每个语言的代码都能转换成对应的AST, 并且AST结构的规范也有很多, js里所使用的规范大部分是 estree[1] ,当然这个只做简单了解即可。
AST到底长啥样
了解了AST的基本概念, 那AST到底长啥样呢?
astexplorer.net[2]这个网站可以在线生成AST, 我们可以在里面进行尝试生成AST,用来学习一下结构
babel的处理过程
问:把冰箱塞进大象有几个阶段?
打开冰箱 -> 塞进大象 -> 关上冰箱
babel也是如此,babel利用AST的方式对代码进行编译,首先自然是需要将代码变为AST,再对AST进行处理,处理完以后呢再将AST 转换回来
也就是如下的流程
code转换为AST -> 处理AST -> AST转换为code
然后我们再给它们一个专业一点的名字
解析 -> 转换 -> 生成
解析(parse)
通过 parser 把源码转成抽象语法树(AST)
这个阶段的主要任务就是将code转为AST, 其中会经过两个阶段,分别是词法分析和语法分析。当parse阶段开始时,首先会进行文档扫描,并在此期间进行词法分析。那怎么理解此法分析呢 如果把我们所写的一段code比喻成句子,词法分析所做的事情就是在拆分这个句子。如同 “我正在吃饭” 这句话,可以被拆解为“我”、“正在”、“吃饭”一样, code也是如此。比如: const a = '1' 会被拆解为一个个最细粒度的单词(tokon): 'const', 'a', '=', '1' 这就是词法分析阶段所做的事情。
词法分析结束后,将分析所得到的 tokens 交给语法分析, 语法分析阶段的任务就是根据 tokens 生成 AST。它会对 tokens 进行遍历,最终按照特定的结构生成一个 tree 这个 tree 就是 AST。
如下图, 可以看到上面语句的到的结构,我们找到了几个重要信息, 最外层是一个VariableDeclaration意思是变量声明,所使用的类型是 const, 字段declarations内还有一个 VariableDeclarator[变量声明符] 对象,找到了 a, 1 两个关键字。
除了这些关键字以为,还可以找到例如行号等等的重要信息,这里就不一一展开阐述。总之,这就是我们最终得到的 AST 模样。
那问题来了,babel里该如何将code 转为 AST 呢?在这个阶段我们会用到 babel 提供的解析器 @babel/parser,之前叫 Babylon,它并非由babel团队自己开发的,而是基于fork的 acorn 项目。
它为我们提供了将code转换为AST的方法,基本用法如下:

更多信息可以访问官方文档查看@babel/parser[3]
转换(transform)
在 parse 阶段后,我们已经成功得到了AST。babel接收到 AST后,会使用 @babel/traverse 对其进行深度优先遍历,插件会在这个阶段被触发,以vistor 函数的形式访问每种不同类型的AST节点。以上面代码为例, 我们可以编写 VariableDeclaration 函数对 VariableDeclaration节点进行访问,每当遇到该类型节点时都会触发该方法。如下:

该方法接受两个参数,
path
path为当前访问的路径, 并且包含了节点的信息、父节点信息以及对节点操作许多方法。可以利用这些方法对 ATS 进行添加、更新、移动和删除等等。
state
state包含了当前plugin的信息和参数信息等等,并且也可以用来自定义在节点之间传递数据。
生成(generate)
generate:把转换后的 AST 打印成目标代码,并生成 sourcemap
这个阶段就比较简单了, 在 transform 阶段处理 AST 结束后,该阶段的任务就是将 AST 转换回 code, 在此期间会对 AST 进行深度优先遍历,根据节点所包含的信息生成对应的代码,并且会生成对应的sourcemap。
经典案例尝试
俗话说,最好的学习就是动手,我们来一起尝试一个简单的经典案例:将上面案例中的 es6 的 const 转变为 es5 的 var
第一步: 转换为 AST
使用 @babel/parser 生成AST
比较简单,跟上面的案例是一样的, 此时我们ast变量中就是转换后的 AST
const parser = require('@babel/parser');
const ast = parser.parse('const a = 1');
复制代码第二步:处理 AST
使用 @babel/traverse 处理 AST
在这个阶段我们通过分析所生成的 AST 结构,确定了在 VariableDeclaration 中由 kind 字段控制 const,所以我们是不是可以尝试着把 kind 改写成我们想要的 var ?既然如此,我们来尝试一下

const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default
const ast = parser.parse('const a = 1');
traverse(ast, {
VariableDeclaration(path, state) {
// 通过 path.node 访问实际的 AST 节点
path.node.kind = 'var'
}
});
复制代码好,此时我们凭借着猜想修改了 kind ,将其改写为了 var, 但是我们还不能知道实际是否有效,所以我们需要将其再转换回 code 看看效果。
第三步:生成 code
使用 @babel/generator 处理 AST
const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default
const generate = require('@babel/generator').default
const ast = parser.parse('const a = 1');
traverse(ast, {
VariableDeclaration(path, state) {
path.node.kind = 'var'
}
});
// 将处理好的 AST 放入 generate
const transformedCode = generate(ast).code
console.log(transformedCode)
复制代码我们再来看看效果:

执行完成,成功了,是我们想要的效果~
如何开发插件
通过上面这个经典案例, 大概了解了 babel 的使用,但我们平时的插件该如何去写呢?
实际上插件的开发和上面的基本思路是一样的, 只是作为插件我们只需要关注这其中的 转换 阶段
我们的插件需要导出一个函数/对象, 如果是函数则需要返回一个对象, 我们只需要在改对象的 visitor 内做同样的事情即可,并且函数会接受几个参数, api继承了babel提供的一系列方法, options 是我们使用插件时所传递的参数,dirname 为处理时期的文件路径。
以上面的案例改造为如下:
module.exports = {
visitor: {
VariableDeclaration(path, state) {
path.node.kind = 'var'
}
}
}
// 或是函数形式
module.exports = (api, options, dirname) => {
return {
visitor: {
VariableDeclaration(path, state) {
path.node.kind = 'var'
}
}
}
}
复制代码插件编写
在有前置知识的基础上,我们来一步步的讲解开发一个 babel 插件。首先我们明确接下来要开发的插件的核心需求:
- 可自动插入某个函数并调用。
- 自动导入插入函数的相关依赖。
- 可以通过注释指定需要插入的函数和需要被插入的函数,若未用注释指定则默认插入位置在第一列。
基本效果展示如下:
处理前
// log 声明需要被插入并被调用的方法
// @inject:log
function fn() {
console.log(1)
// 用 @inject:code指定插入行
// @inject:code
console.log(2)
}
复制代码处理后
// 导入包 xxx 之后要在插件参数内提供配置
import log from 'xxx'
function fn() {
console.log(1)
log()
console.log(2)
}
复制代码思路整理
了解了大概的需求,先不着急动手,我们要先想想要怎么开始做,已经设想一下过程中需要处理的问题。
- 找到带有 @inject 标记的函数,再查看其内部是否有 @inject:code 的位置标记。
- 导入所有插入函数的相应包。
- 匹配到了标记,要做的就是插入函数,同时我们还要需要处理各种情况下的函数,如:对象方法、iife、箭头函数等等情况。
设计插件参数
为了提升插件的灵活度,我们需要设计一个较为合适的参数规则。插件参数接受一个对象。
-
key 作为插入函数的函数名。
-
kind 表示导入形式。有三种导入方式 named 、 default、 namespaced, 此设计参考 babel-helper-module-imports[4]
-
named 对应
import { a } from "b"形式 -
default 对应
import a from "b"形式 -
namespaced 对应
import * as a from "b"形式 -
require 为依赖的包名
比如,我需要插入 log 方法,它需要从 log4js 这个包里导入,并且是以 named 形式, 参数便为如下形式。
// babel.config.js
module.exports = {
plugins: [
// 填写我们的plugin的js 文件地址
['./babel-plugin-myplugin.js', {
log: {
// 导入方式为 named
kind: 'named',
require: 'log4js'
}
}]
]
}
复制代码起步
好,知道了具体要做什么事情并且设计好了参数的规则, 我们就可以开始动手了。
首先我们进入 astexplorer.net/[5] 将待处理的 code 生成 AST 方便我们梳理结构, 然后我们在进行具体编码
首先是函数声明语句,我们分析一下其 AST 结构以及该如何处理, 来看一下demo
// @inject:log
function fn() {
console.log('fn')
}
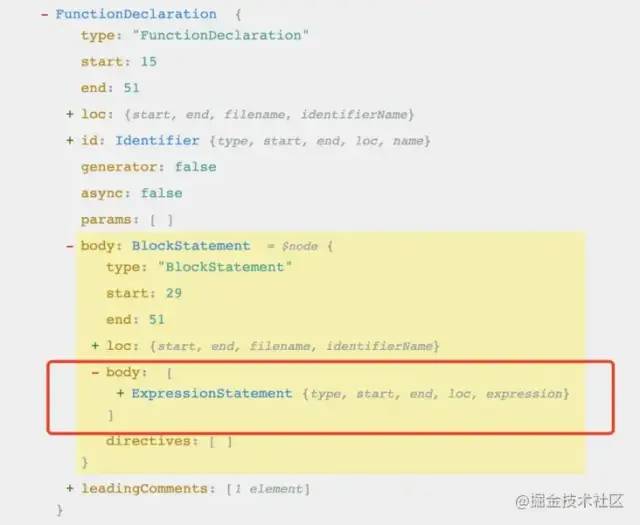
复制代码其生成的 AST 结构如下,可以看到有比较关键的两个属性:
- leadingComments 表示前方注释,可以看到内部有一个元素,就是我们demo里所写的
@inject:log - body 是函数体的具体内容, demo 所写的
console.log('fn')此时就在里面,我们等会代码的插入操作就是需要操作它

好,知道了可以通过 leadingComments 来获知函数是否需要被插入, 对 body 操作可以实现我们的代码插入需求。。
首先我们得先找到 FunctionDeclaration 这一层,因为只有这一层才有 leadingComments 属性, 然后我们需要遍历它,匹配出需要插入的函数。再将匹配到的函数插入至 body 只中, 但我们这里需要注意可插入的body 所在层级, FunctionDeclaration 内的body 他不是一个数组而是 BlockStatement,这表示函数的函数体,并且它也有body , 所以我们实际操作位置就在这个BlockStatement 的 body 内
代码如下:
module.exports = (api, options, dirname) => {
return {
visitor: {
// 匹配函数声明节点
FunctionDeclaration(path, state) {
// path.get('body') 相当于 path.node.body
const pathBody = path.get('body')
if(path.node.leadingComments) {
// 过滤出所有匹配 @inject:xxx 字符 的注释
const leadingComments = path.node.leadingComments.filter(comment => /\@inject:(\w+)/.test(comment.value) )
leadingComments.forEach(comment => {
const injectTypeMatchRes = comment.value.match(/\@inject:(\w+)/)
// 匹配成功
if( injectTypeMatchRes ) {
// 匹配结果的第一个为 @inject:xxx 中的 xxx , 我们将它取出来
const injectType = injectTypeMatchRes[1]
// 获取插件参数的 key, 看xxx 是否在插件的参数中声明过
const sourceModuleList = Object.keys(options)
if( sourceModuleList.includes(injectType) ) {
// 搜索body 内部是否有 @code:xxx 注释
// 因为无法直接访问到 comment,所以需要访问 body内每个 AST 节点的 leadingComments 属性
const codeIndex = pathBody.node.body.findIndex(block => block.leadingComments && block.leadingComments.some(comment => new RegExp(`@code:\s?${injectType}`).test(comment.value) ))
// 未声明则默认插入位置为第一行
if( codeIndex === -1 ) {
// 操作`BlockStatement` 的 body
pathBody.node.body.unshift(api.template.statement(`${state.options[injectType].identifierName}()`)());
}else {
pathBody.node.body.splice(codeIndex, 0, api.template.statement(`${state.options[injectType].identifierName}()`)());
}
}
}
})
}
}
}
})
复制代码编写完后我们看看结果, log成功被插入了, 因为我们没有使用 @code:log所以就默认插入在了第一行

然后我们试试使用 @code:log 标识符, 我们将 demo 的代码改为如下
// @inject:log
function fn() {
console.log('fn')
// @code:log
}
复制代码再次运行代码查看结果, 确实是在 @code:log 位置成功插入了

处理完了我们第一个案例函数声明,这时候可能有人会问了, 那箭头函数这种没有函数体的你怎么办, 比如:
// @inject:log
() => true
复制代码这有问题吗?没有问题!

没有函数体我们给它一个函数体就是了,怎么做呢?
首先我们还是先学会来分析一下 AST 结构, 首先看到最外层其实是一个ExpressionStatement表达式声明,然后其内部才是 ArrowFunctionExpression箭头函数表达式, 可见跟我们之前的函数声明生成的结构是大有不同, 其实我们不用被这么多层结构迷了眼睛,我们只需要找对我们有用的信息就可以了,一句话:哪一层有 leadingComments 我们就找哪一层。这里的 leadingComments 在 ExpressionStatement 上,所以我们找它就行
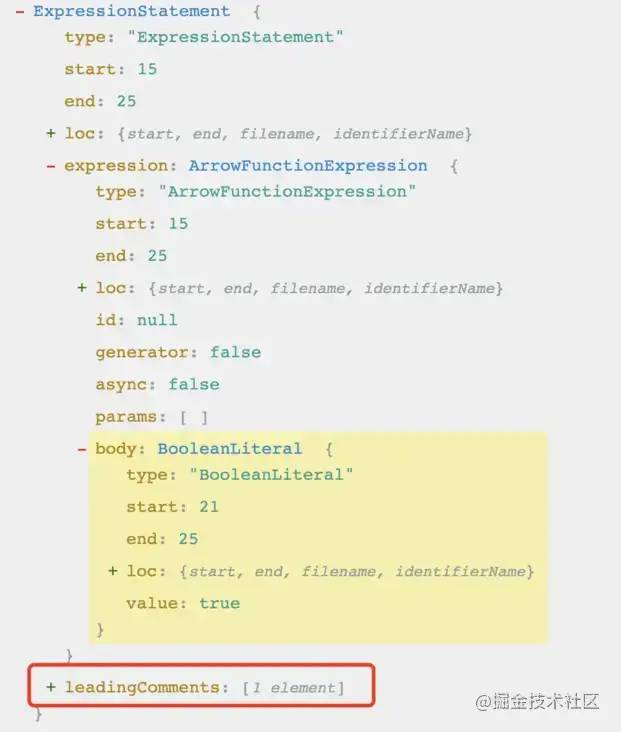
分析完了结构,那怎么判断是否有函数体呢?还记得上面处理函数声明时,我们在 body 中看到的 BlockStatement 吗,而你看到我们箭头函数的 body 却是 BooleanLiteral。所以,我们可以判断其 body 类型来得知是否有函数体 具体方法可以使用babel 提供的类型判断方法 path.isBlockStatement() 来区分是否有函数体。
module.exports = (api, options, dirname) => {
return {
visitor: {
ExpressionStatement(path, state) {
// 访问到 ArrowFunctionExpression
const expression = path.get('expression')
const pathBody = expression.get('body')
if(path.node.leadingComments) {
// 正则匹配 comment 是否有 @inject:xxx 字符
const leadingComments = path.node.leadingComments.filter(comment => /\@inject:(\w+)/.test(comment.value) )
leadingComments.forEach(comment => {
const injectTypeMatchRes = comment.value.match(/\@inject:(\w+)/)
// 匹配成功
if( injectTypeMatchRes ) {
// 匹配结果的第一个为 @inject:xxx 中的 xxx , 我们将它取出来
const injectType = injectTypeMatchRes[1]
// 获取插件参数的 key, 看xxx 是否在插件的参数中声明过
const sourceModuleList = Object.keys(options)
if( sourceModuleList.includes(injectType) ) {
// 判断是否有函数体
if (pathBody.isBlockStatement()) {
// 搜索body 内部是否有 @code:xxx 注释
// 因为无法直接访问到 comment,所以需要访问 body内每个 AST 节点的 leadingComments 属性
const codeIndex = pathBody.node.body.findIndex(block => block.leadingComments && block.leadingComments.some(comment => new RegExp(`@code:\s?${injectType}`).test(comment.value) ))
// 未声明则默认插入位置为第一行
if( codeIndex === -1 ) {
pathBody.node.body.unshift(api.template.statement(`${injectType}()`)());
}else {
pathBody.node.body.splice(codeIndex, 0, api.template.statement(`${injectType}()`)());
}
}else {
// 无函数体情况
// 使用 ast 提供的 `@babel/template` api , 用代码段生成 ast
const ast = api.template.statement(`{${injectType}();return BODY;}`)({BODY: pathBody.node});
// 替换原本的body
pathBody.replaceWith(ast);
}
}
}
})
}
}
}
}
}
复制代码可以看到除了新增的函数体判断,生成函数体插入代码再用新的 AST 替换原本的节点,除掉这些之外,大体上的逻辑跟之前的函数声明的处理过程没有区别。
生成 AST 所使用的
@babel/template的 API 相关用法可以查看文档 @babel/template[6]
针对不同情况的下的函数大体上相同,总结就是:
分析 AST 找到 leadingComments 所在节点 -> 找到可插入的 body 所在节点 -> 编写插入逻辑
实际处理的情况还有很多,如:对象属性、iife、函数表达式等很多, 处理思路都是一样的,这里就不过重复阐述。我会将插件完整代码发在文章底部。
自动引入
第一条完成了,那需求的第二条,我们使用的包如何自动引入呢, 如上面案例使用的 log4js, 那么我们处理后的代码就应该自动加上:
import { log } from 'log4js'
复制代码此时,我们可以思考一下,我们需要处理以下两种情况
- log 已经被导入过了
- log 变量名已经被占用
针对 问题1 我们需要先检索一下是否有导入过 log4js ,并且以 named 的形式导入了 log 针对 问题2 我们需要给 log 一个唯一的别名, 并且要保证在后续的代码插入中也使用这个别名。所以这就要求了我们要在文件的一开始就处理完成自动引入的逻辑。
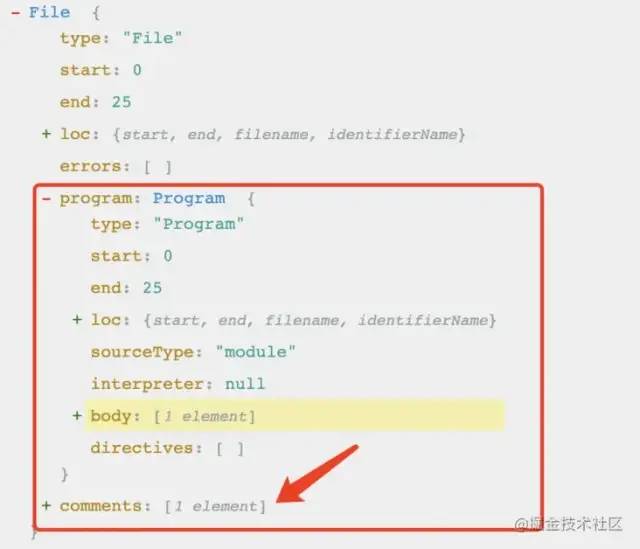
有了大概的思路,但是我们如何提前完成自动引入逻辑呢。抱着疑问,我们再来看看 AST 的结构。可以看到 AST 最外层是 File 节点, 他有一个 comments 属性,它包含了当前文件里所有的注释,有了这个我们就可以解析出文件里需要插入的函数,并提前进行引入。我们再往下看, 内部是一个 Program, 我们将首先访问它, 因为它会在其他类型的节点之前被调用,所以我们要在此阶段实现自动引入逻辑。
小知识:babel 提供了 path.traverse 方法,可以用来同步访问处理当前节点下的子节点。
如图:
代码如下:
const importModule = require('@babel/helper-module-imports');
// ......
{
visitor: {
Program(path, state) {
// 拷贝一份options 挂在 state 上, 原本的 options 不能操作
state.options = JSON.parse(JSON.stringify(options))
path.traverse({
// 首先访问原有的 import 节点, 检测 log 是否已经被导入过
ImportDeclaration (curPath) {
const requirePath = curPath.get('source').node.value;
// 遍历options
Object.keys(state.options).forEach(key => {
const option = state.options[key]
// 判断包相同
if( option.require === requirePath ) {
const specifiers = curPath.get('specifiers')
specifiers.forEach(specifier => {
// 如果是默认type导入
if( option.kind === 'default' ) {
// 判断导入类型
if( specifier.isImportDefaultSpecifier() ) {
// 找到已有 default 类型的引入
if( specifier.node.imported.name === key ) {
// 挂到 identifierName 以供后续调用获取
option.identifierName = specifier.get('local').toString()
}
}
}
// 如果是 named 形式的导入
if( option.kind === 'named' ) {
//
if( specifier.isImportSpecifier() ) {
// 找到已有 default 类型的引入
if( specifier.node.imported.name === key ) {
option.identifierName = specifier.get('local').toString()
}
}
}
})
}
})
}
});
// 处理未被引入的包
Object.keys(state.options).forEach(key => {
const option = state.options[key]
// 需要require 并且未找到 identifierName 字段
if( option.require && !option.identifierName ) {
// default形式
if( option.kind === 'default' ) {
// 增加 default 导入
// 生成一个随机变量名, 大致上是这样 _log2
option.identifierName = importModule.addDefault(path, option.require, {
nameHint: path.scope.generateUid(key)
}).name;
}
// named形式
if( option.kind === 'named' ) {
option.identifierName = importModule.addNamed(path, key, option.require, {
nameHint: path.scope.generateUid(key)
}).name
}
}
// 如果没有传递 require 会认为是全局方法,不做导入处理
if( !option.require ) {
option.identifierName = key
}
})
}
}
}
复制代码Program 节点内我们先将接收到的插件配置 options 拷贝了一份,挂到了 state 上, 之前有说过 state 可以用作 AST 节点之间的数据传递,然后我们首先访问 Program 下的 ImportDeclaration 也就是 import 语句, 看看 log4js 是否有被导入过, 若引入过便会记录到 identifierName 字段上,完成对 import 语句的访问后,我们就可根据 identifierName 字段判断是否已被引入,若未引入则使用 @babel/helper-module-imports[7] 创建 import ,并用 babel 提供的 generateUid 方法创建唯一的变量名。
这样在之前的代码我们也需要略微调整, 不能直接使用从注释 @inject:xxx 提取出的方法名, 而是应该使用 identifierName, 关键部分代码修改如下:
if( sourceModuleList.includes(injectType) ) {
// 判断是否有函数体
if (pathBody.isBlockStatement()) {
// 搜索body 内部是否有 @code:xxx 注释
// 因为无法直接访问到 comment,所以需要访问 body内每个 AST 节点的 leadingComments 属性
const codeIndex = pathBody.node.body.findIndex(block => block.leadingComments && block.leadingComments.some(comment => new RegExp(`@code:\s?${injectType}`).test(comment.value) ))
// 未声明则默认插入位置为第一行
if( codeIndex === -1 ) {
// 使用 identifierName
pathBody.node.body.unshift(api.template.statement(`${state.options[injectType].identifierName}()`)());
}else {
// 使用 identifierName
pathBody.node.body.splice(codeIndex, 0, api.template.statement(`${state.options[injectType].identifierName}()`)());
}
}else {
// 无函数体情况
// 使用 ast 提供的 `@babel/template` api , 用代码段生成 ast
// 使用 identifierName
const ast = api.template.statement(`{${state.options[injectType].identifierName}();return BODY;}`)({BODY: pathBody.node});
// 替换原本的body
pathBody.replaceWith(ast);
}
}
复制代码最终效果如下:
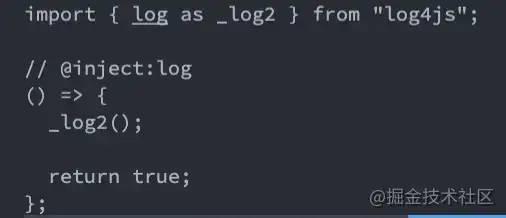
我们实现了函数自动插入并自动引入依赖包。
结尾
本篇文章是对自己学习 “Babel 插件通关秘籍” 小册子后的一个记录总结,我开始和大部分想写babel插件却无从下手的同学一样,所以这篇文章主要也是按自己写插件时摸索的思路去写。希望也是能给大家提供一个思路。
完整版已支持 自定义代码片段 的插入,完整代码已上传至 github:https://github.com/nxl3477/babel-plugin-code-inject,同时也发布至了 npm:https://www.npmjs.com/package/babel-plugin-code-inject。 欢迎大家 star 和 issue。
给 star 是人情,不给是事故,哈哈。