一文读懂Redis的三种模式(下)
在上一篇中,我们简单介绍了Redis三种模式中的两种模式,即主从模式、Sentinel模式,并对这两种模式的优缺点进行了总结:
| 模式 | 主从 | Sentinel |
|---|---|---|
| 优点 | 1、安全可靠 2、主从分离,读写分离 | 1、高可用 2、数据量不限 |
| 缺点 | 1、如果某一个节点挂掉,需要人工介入,尤其是当master节点挂掉之后,整个集群不能写 2、不支持大数据量的操作 3、不支持扩容 | 1、不支持动态扩容 |
从上述可以看出,虽然Sentinel模式在一定程度上解决了主从模式所存在的问题,但是二者有一个共同的缺点,就是不支持动态扩容,为了解决这个问题,Redis引入了第三种模式,即Cluster模式。
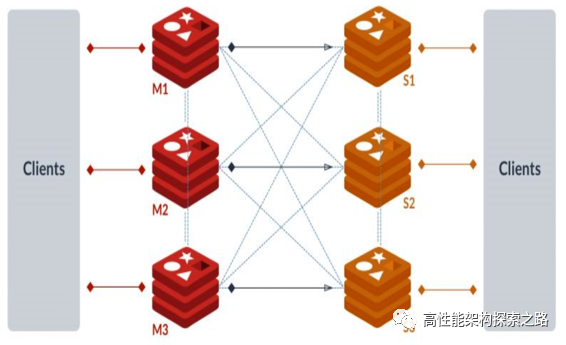
Cluster模式的特点:
1、client直连,没有代理
2、去中心化,两两交互,每个节点都有其他节点的想详细信息
3、内部传输采用自有的gossip协议,减小数据传输量
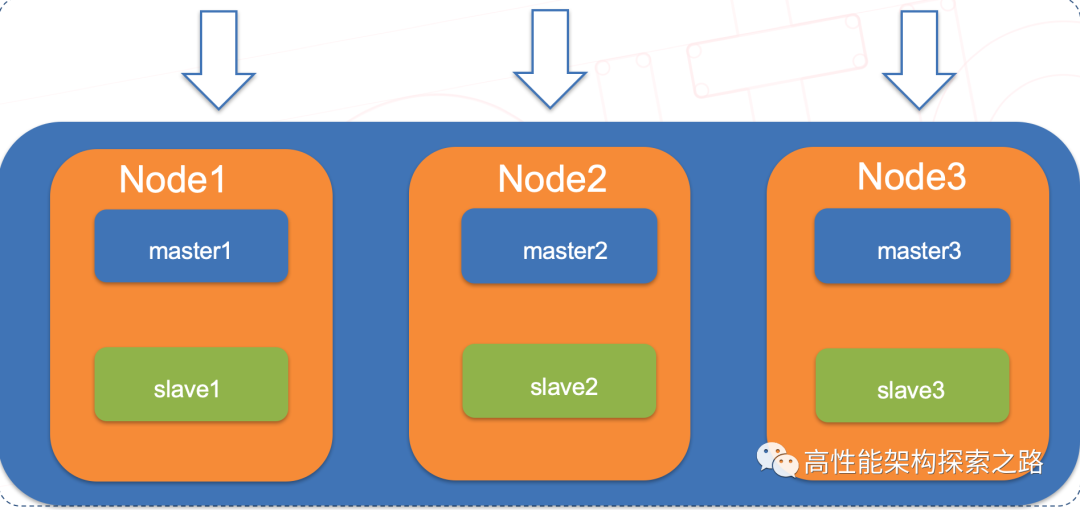
一个稳定的Cluster集群必须有6个节点,即三主三从,之所以是6个,是因为里面涉及到了投票选举。如果此时只有两个节点,即A 和 B,A说B下线,B说A下线,这样永远都不会有定论,如果有三个节点的话,即A B和C。A和B均发现C不通,那么得到一致结论:C已经下线。
Cluster中的每个节点都维护一份在自己看来当前整个集群的状态,主要包括:
1、当前集群状态
2、集群中各节点所负责的slots信息,及其migrate状态
3、集群中各节点的master-slave状态
4、集群中各节点的存活状态及不可达投票
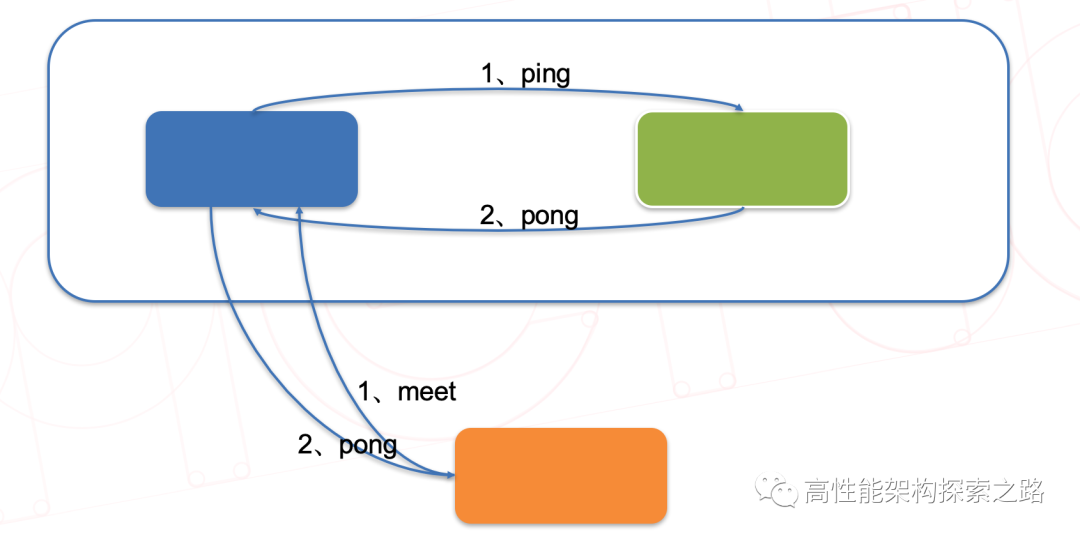
基于Gossip协议当集群状态变化时,如新节点加入、slot迁移、节点宕机、slave提升为新Master,我们希望这些变化尽快的被发现,传播到整个集群的所有节点并达成一致。节点之间相互的心跳(PING,PONG,MEET)及其携带的数据是集群状态传播最主要的途径。
- Gossip协议的概念
Gossip 协议(gossip protocol)又称 epidemic 协议(epidemic protocol),是基于流行病传播方式的节点或者进程之间信息交换的协议。在分布式系统中被广泛使用,比如我们可以使用 gossip 协议来确保网络中所有节点的数据一样。gossip protocol 最初是由施乐公司帕洛阿尔托研究中心(Palo Alto Research Center)的研究员艾伦·德默斯(Alan Demers)于1987年创造的。
Gossip协议已经是P2P网络中比较成熟的协议了。Gossip协议的最大的好处是,即使集群节点的数量增加,每个节点的负载也不会增加很多,几乎是恒定的。这就允许Consul管理的集群规模能横向扩展到数千个节点。
Gossip算法又被称为反熵(Anti-Entropy),熵是物理学上的一个概念,代表杂乱无章,而反熵就是在杂乱无章中寻求一致,这充分说明了Gossip的特点:在一个有界网络中,每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节可以通过网络连通,最终他们的状态都是一致的,当然这也是疫情传播的特点。
- Gossip协议的使用
1、Meet 通过「cluster meet ip port」命令,已有集群的节点会向新的节点发送邀请,加入现有集群。
2、Ping 节点每秒会向集群中其他节点发送 ping 消息,消息中带有自己已知的两个节点的地址、槽、状态信息、最后一次通信时间等。
- 3、Pong 节点收到 ping 消息后会回复 pong 消息,消息中同样带有自己已知的两个节点信息。
- 4、Fail 节点 ping 不通某节点后,会向集群所有节点广播该节点挂掉的消息。其他节点收到消息后标记已下线。
在Cluster中,有如下类型的协议字段:
CLUSTERMSG_TYPE_PING:gossip协议的ping消息。
CLUSTERMSG_TYPE_PONG:gossip协议的pong消息。
CLUSTERMSG_TYPE_MEET:握手消息。
CLUSTERMSG_TYPE_FAIL:master节点检测到,超过半数master认为某master离线,则发送fail消息。
CLUSTERMSG_TYPE_PUBLISH:publish消息,向其他节点推送消息。
CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST:故障转移时,slave发送向其他master投票请求。
CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK:故障转移时,其他master回应slave的请求。
CLUSTERMSG_TYPE_UPDATE:通知某节点,它负责的某些slot被另一个节点替换。
CLUSTERMSG_TYPE_MFSTART:手动故障转移时,slave请求master停止访问,从而对比两者的数据偏移量,可以达到一致。
- 数据访问
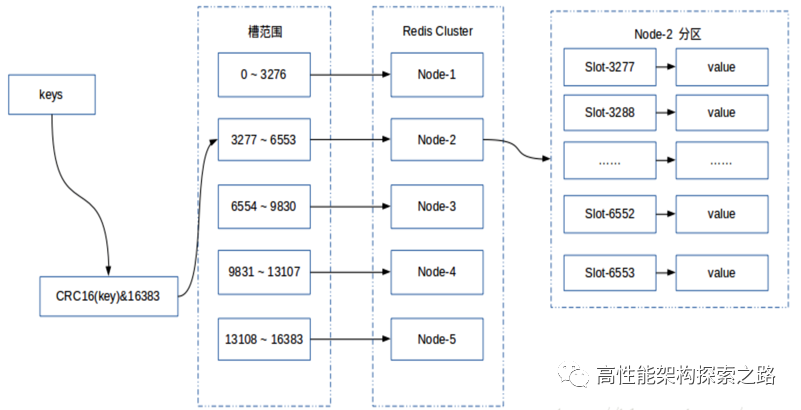
从数据存储的角度来看,cluster如下图所示,即每一次操作key的时候,都先对key通过CRC16(key) & 16383,这样得到slots的位置,然后通过slots来获取该slots所在的node的ip和端口,从而进行key操作。
-
扩容
准备工作:
1、准备新节点
2、加入集群
3、迁移槽和数据
在cluster中,首先通过add-node 将node加入集群中,然后通过cluster meet命令通知集群中的其他机器,是的新节点与老节点互相交换集群信息。这一步可以通过redis cluster提供的工具来实现,即:
redis-trib.rb add-node127.0.0.1:7006127.0.0.1:7007
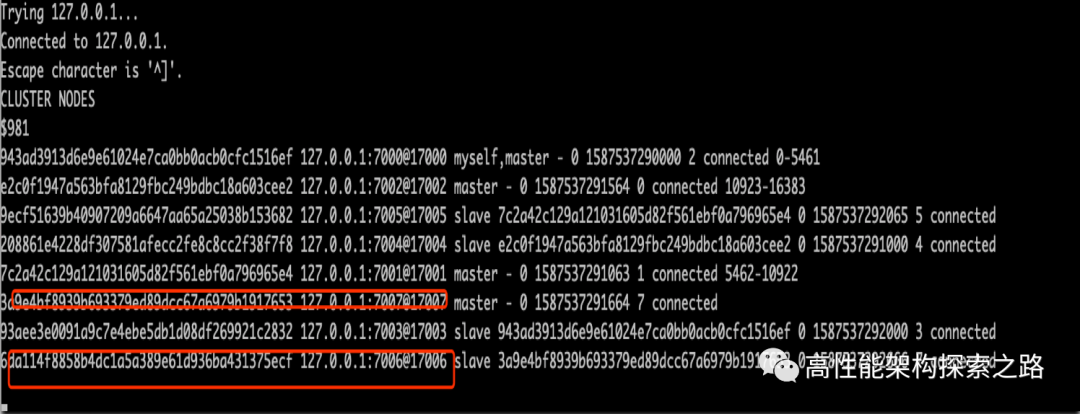
通过add操作后,我们通过cluster nodes 能够看到新增加的节点信息。
下面,我们着重讲下迁移槽和数据
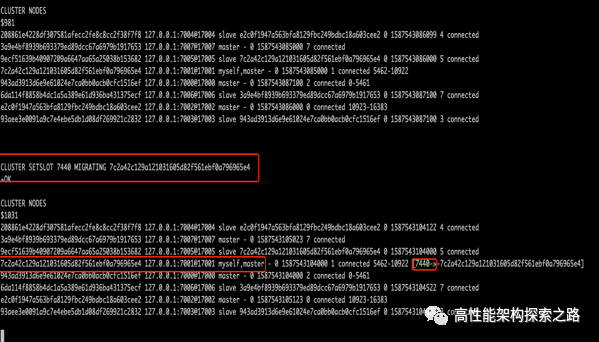
上图是通过命令操作,将slot 7448 给新的节点
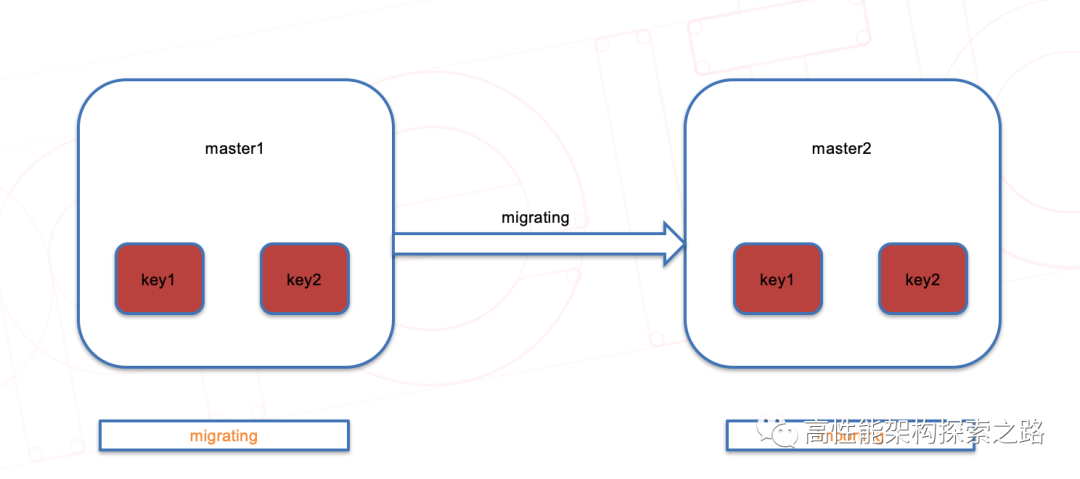
在数据迁移过程中,访问数据可能会有两个状态:
1、ASKING(代表该key正在迁移)
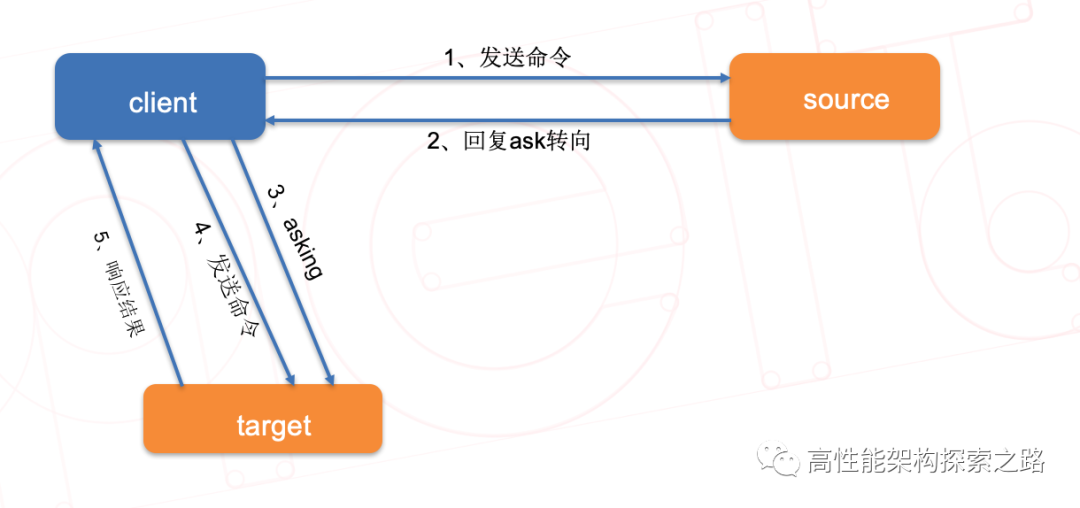
节点可能会返回ASK错误。这种错误是在key对应的slot正在进行数据迁移时产生的,这时候向slot的原节点访问,如果key在迁移源节点上,则该次命令能直接执行。如果key不在迁移源节点上,则会返回ASK错误,描述信息会附上迁移目的节点的地址。客户端这时候要先向迁移目的节点发送ASKING命令,然后执行之前的命令。
2、MOVED(代表该key已经被迁移)
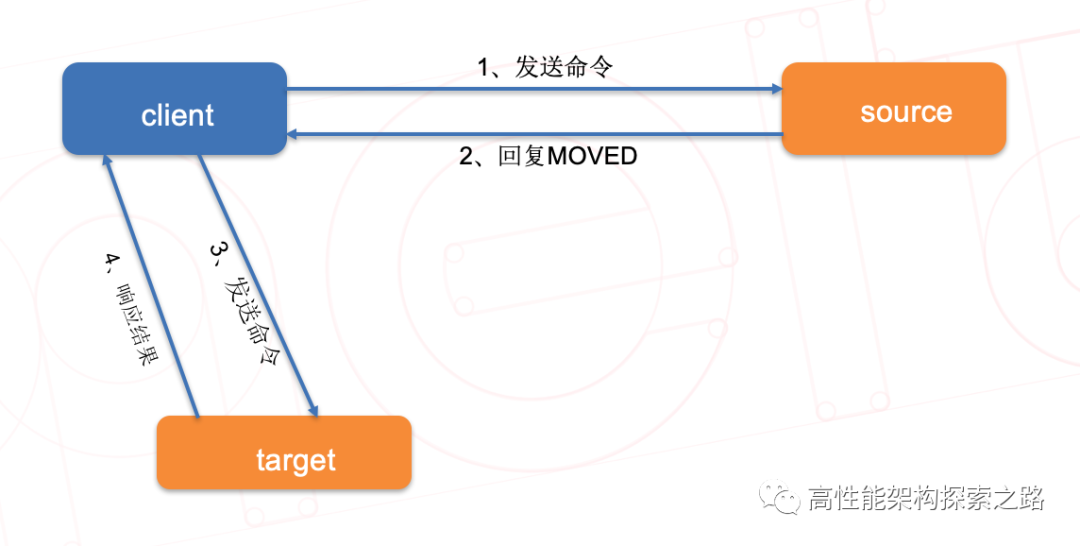
*客户端在初始化的时候只需要知道一个节点的地址即可,客户端会先尝试向这个节点执行命令,比如“get key”,如果key所在的slot刚好在该节点上,则能够直接执行成功。如果slot不在该节点,则节点会返回MOVED错误,同时把该slot对应的节点告诉客户端。客户端可以去该节点执行命令。目前客户端有两种做法获取数据分布表,一种就是客户端每次根据返回的MOVED信息缓存一个slot对应的节点,但是这种做法在初期会经常造成访问两次集群。还有一种做法是在节点返回MOVED信息后,通过cluster nodes命令获取整个数据分布表,这样就*能每次请求到正确的节点,一旦数据分布表发生变化,请求到错误的节点,返回MOVED信息后,重新执行cluster nodes命令更新数据分布表。
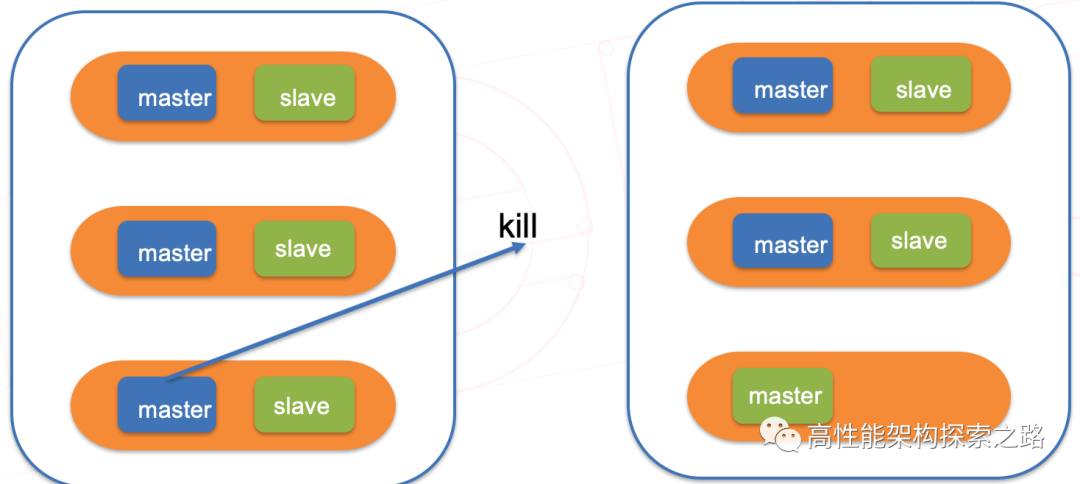
在自动恢复方面,当某个master失败时候,集群中的其他节点可以通过选举策略,重新从该master的slave中选取一个,成为一个新的master,并重新在集群内部广播,当老的master恢复后,会成为新的master的slave节点,如下图所示:
下图中,集群处于falied状态,不可用(有其他方式,可以继续使用其他可用的slot,但是这样是不安全的,不建议这么做)
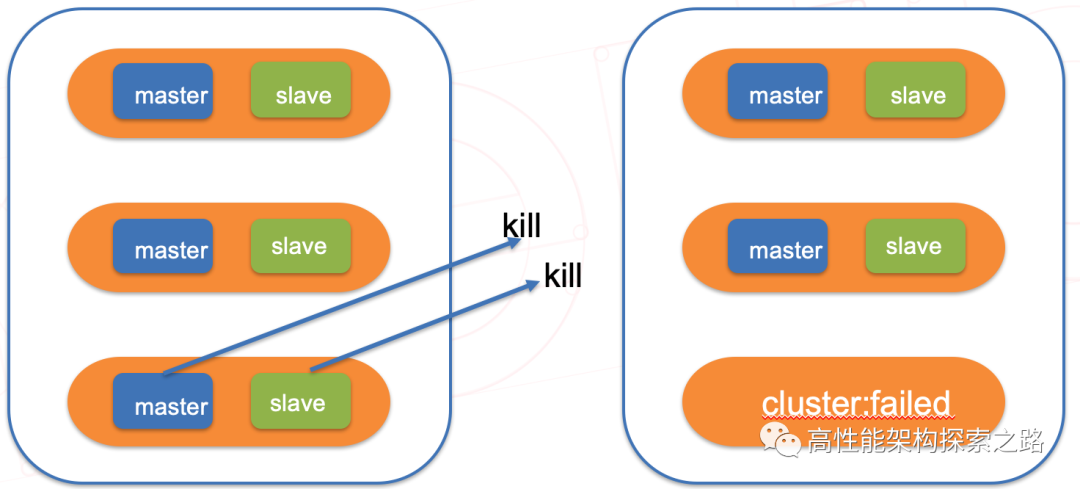
Cluster failed需要满足以下两个条件:
1、至少有一个slot不可用
2、集群中大部分master处于PFAILED状态
- PFAILED状态
1、节点探测超时时间内没有响应,则会标记为PFAIL状态,类似于sentinel的sdown
2、集群节点交换互相认识,超过一半master认为其为PFAIL,
则改为FAIL,类似于sentinel中的odown
集群恢复:
1、slave节点收到fail消息,竞选master
2、竞选方式与sentinel选主类似,都使用raft协议
3、从其他master拉取选票,选票最多的slave被提升为master
4、新master给集群内其他节点发送PONG消息,告知自己角色提升
5、其他slave开始从新master复制数据
5、旧master恢复后,成为新master的slave
Cluster中,slave节点,只是用来备份数据以及在master故障的时候,其用来成为master即实现高可用功能的,在默认情况下,读和写都是在master上面,可以通过向slave发送READONLY命令,来支持在slave上进行数据读取。
综上,虽然Cluster实现了高可用和可扩容的功能,但是其使用上还是很复杂的,尤其对于client的实现来说,需要保存server端slot和ip的对应关系,下面我们总结下其特点:
优点:
1、高性能,避免proxy代理的消耗
2、高可用,自动故障转移
3、自带迁移功能
4、丰富的集群管理命令
缺点或者不足:
1、Client实现复杂,需要实现slot 映射
2、迁移异常不能自修复
3、节点太多时候,节点检测占用带宽
4、不支持不同slot的批量命令(MEGT、MSET等)
5、只支持db0,即只支持select0