Kafka的心跳处理机制竟然用到了时间轮算法?
Broker端与客户端的心跳在Kafka中非常的重要,因为一旦在一个心跳过期周期内(默认10s),Broker端的消费组组协调器(GroupCoordinator)会把消费者从消费组中移除,从而触发重平衡。在2.4.x以下其版本中,消费组一旦进入重平衡状态,该消费组内所有消费者全部暂停消费,直到重平衡完成。
本文将来探讨Kafka的心跳机制的具体实现。本文的组织结构如下:
- 源码解读Kafka心跳机制
- Kafka心跳架构设计亮点(时间轮调度算法实现原理图)
温馨提示:如果大家对源码阅读不感兴趣,可以直接跳到本文的第二部分,用流程图、数据结构图阐述心跳的实现机制。
1、源码分析Kafka心跳机制
在介绍源码分析之前介绍笔直的一条源码分析经验:找准入口,了解调用链路。故笔者会先寻找归纳出Kafka心跳处理的所有入口。
1.1Kafka心跳入口总结
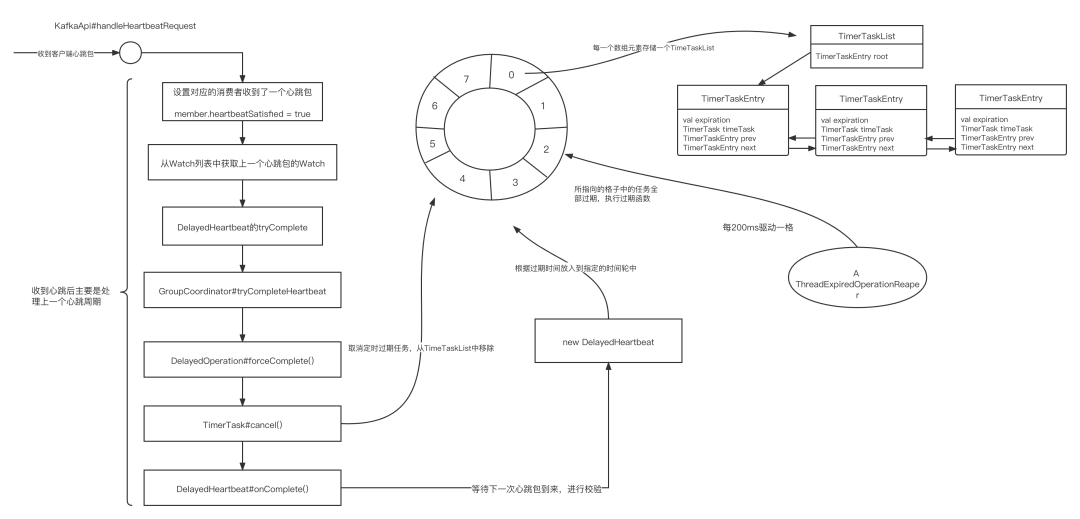
Kafka心跳包的处理流程如下图所示:
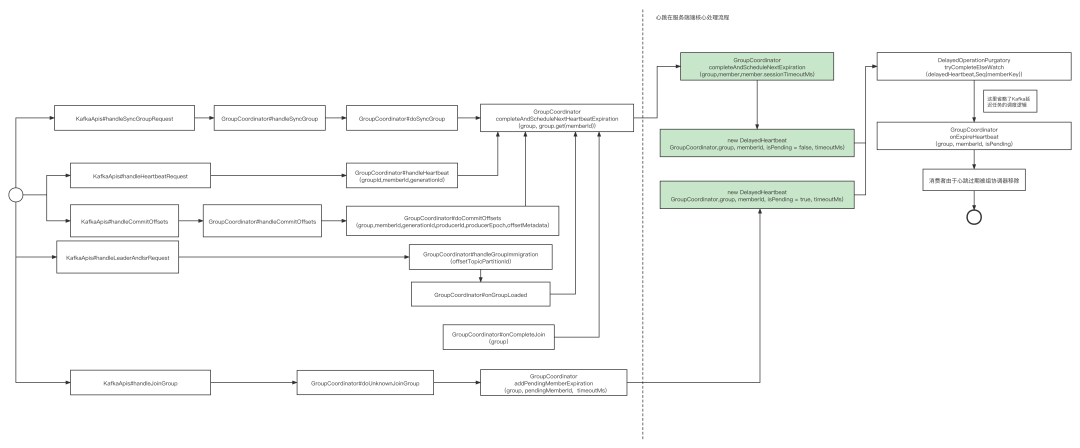
- KafkaConsume主动发送心跳包 消费者会以3s的频率向服务端发送心跳包,服务端对应的入口为 KafkaApis的handleHeartbeatRequest方法。
- 消费者加入消费组 在消费端重平衡过程中,客户端主动向其组协调器发起Join_Group(加入消费组)时,组协调器会认为收到一个有效的心跳包,服务端对应的处理入口:KafkaApis的handleJoinGroup方法。
- 消费者获取队列负载结果 在重平衡的第二个阶段,消费组的Leader在计算出分区负载结果后会发给组协调器,消费组中的其他成员需要发生Sync_Group请求获取负载结果,组协调器同样认为收到了一个有效的心跳包。服务端对应的处理入口:KafkaApis的handleSyncGroupRequest。
- 消费者提交位点 消费者组协调器收到消费者提交位点请求,同样可以认定消费者是存活的。位点提交的处理入口:KafkaApis的handlerCommitOffsets方法。
- __consumers_offsets主题的ISR的Leader发生变化
如果__consumers_offsets主题中的各个分区Leader发生变化,与特定分区的组协调器需要重新选举,与此组协调器相关的消费者将触发重平衡。
上述任何一种请求,都能表明消费端是存活的,故能有效阻止服务端将客户端端心跳设置为过期,进入下一个心跳检测周期。
上述各个入口,特别是__consumers_offsets的ISR对消费组的影响,后续会专门展开研究,现在我们将重心转移到服务端是如何处理一个心跳包的。
1.2 源码分析Kafka心跳处理机制
从上面的流程图可以得出,Kafka收到一个心跳包后的处理入口为GroupCoordinator的completeAndScheduleNextExpiration方法,核心代码如下图所示:
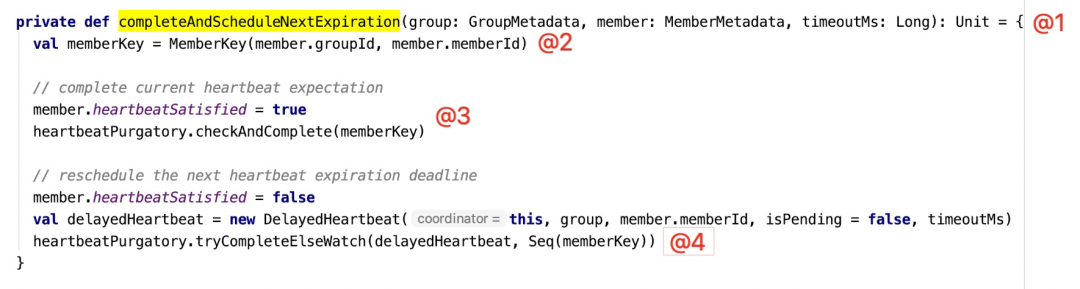
- GroupMetadata group 消费组的元信息。
- MemberMetadata member 消费者的元信息。
- long timeoutMs 心跳超时时间,默认为10s,这个参数是由消费端的session.timeout.ms参数设置,默认为10s。
Step1:为消费组设置唯一标识:groupId + "-" + memberId构成。
Step2:将hearbeatSatisfied设置为true,表示该消费者收到一个有效的心跳包。
Step3:收到一个有效的心跳包,通知定时调度器停止本次的心跳过期检测。
Step4:构建一个DelayedHearbeat,进入下一个心跳检测周期。
接下来将分别对Step3、Step4展开详细介绍。
1.2.1 心跳检测正常处理逻辑
在收到一个心跳包时,尝试将本次检测设置成功,具体的实现由DelayedOperation的checkAndComplete方法,代码如下:

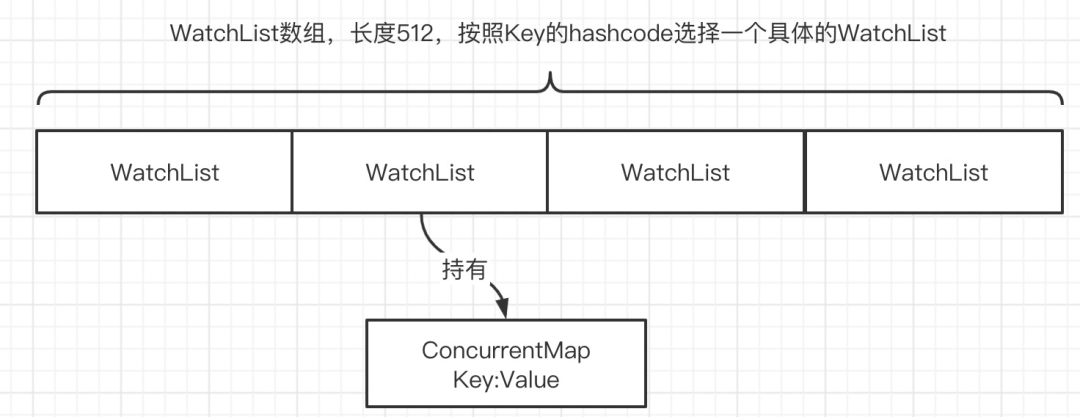
实现要点:根据key获取WatchList,然后从获取的WatchList中内部的ConcurrentMap中再按照Key获取对应与当前消费者对应的Watch。
- 如果没有找到对应消费者的Watch,则直接返回,无需检测,说明已经成功检测。
- 如果找到了对应消费者的Watch,则执行被watch的tryCompleteWatched方法。
Watch的数据结构如下:
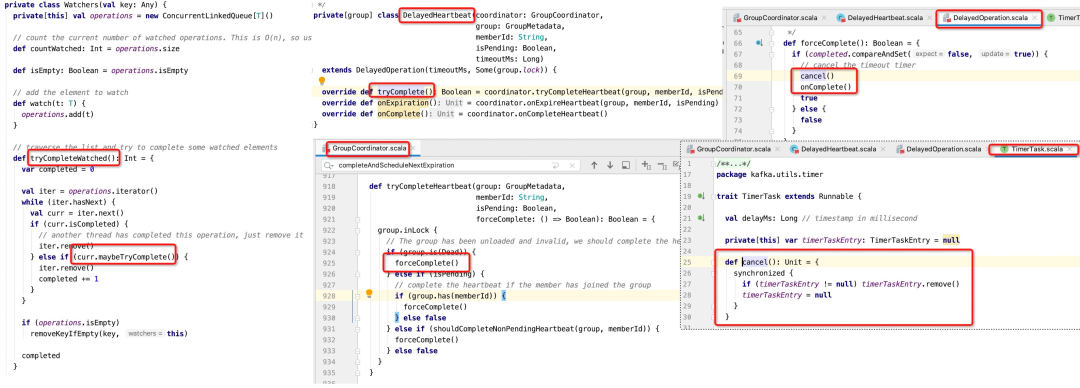
这边先重点介绍一下组协调器判断一次成功的心跳检测的三个标准中满足一个即可(GroupCoordinator的tryCompleteHeartbeat方法):- 如果消费组的状态处于Dead
- 如果消费组的状态为Pending(消费组在重平衡中)
- hearbeatSatisfied为true,即收到了一个有效的心跳包。
上述代码的实现比较简单,这里就不一一罗列,其核心关键点如下:
- 删除对应的Watch,表示一次心跳检测成功。
- Watchs中存储的对象是DelayedOperation(Kafka延迟类型的父类)的子类,在心跳检测中具体为DelayedHeartbeat。
- 最终执行DelayedOperation的是TimeTask的cancel方法(取消延迟任务),就是从延迟调度中移除自己,表示没有超时,结束本轮的超时检测,具体的存储结构,将在下文详介绍如果开启新一轮心跳检测时再详细讲解。
为了方便大家阅读源码,其主要的调用时序图如下:
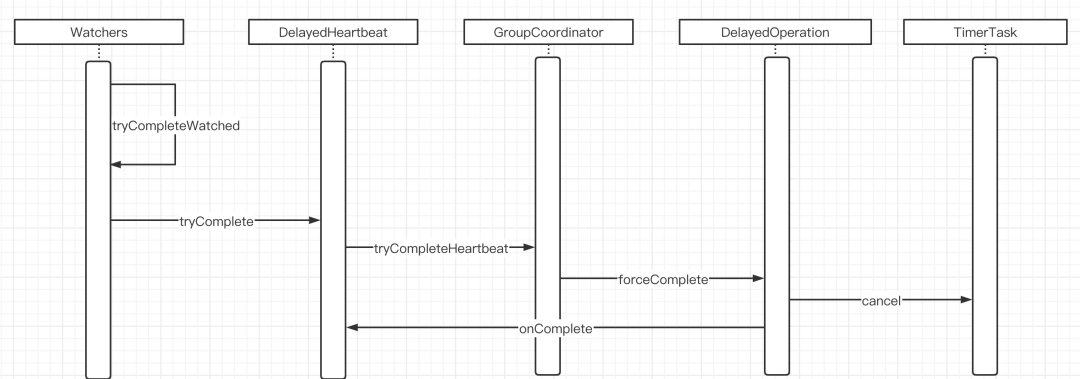
1.2.2 开启下一轮心跳检测
1.2.2.1将延迟任务放入时间轮
在接受到一个新的心跳包首先用于清除上一轮设置的延迟任务,然后需要开启一个新的延迟任务,接下来我们将来具体看看Kafka如何开启新一轮心跳检测机制,**其本质上是Kafka的延迟(定时)实现原理。**代码入口如下图所示:
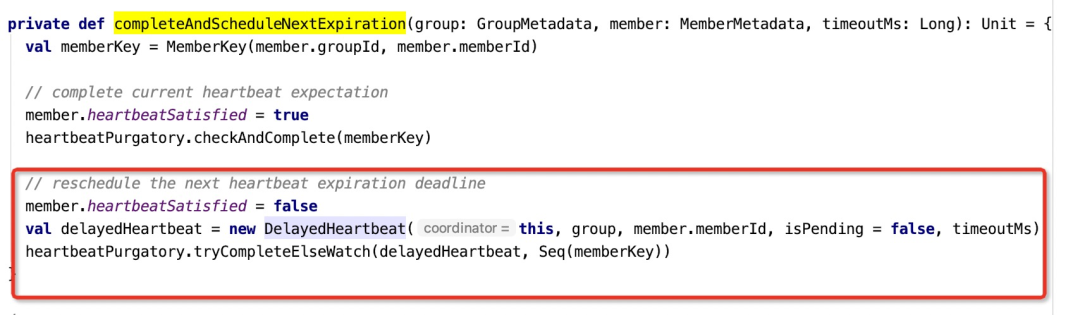
其核心思想是创建一个心跳延迟任务DelayedHeartbeat,并对其检测是否完成或者添加Watch,启动心跳延迟或者等待下一个心跳包的到来。
其实看到这里,我们应该能得到一个关于Kafka心跳检测机制的实现思路:
- 开启一个延迟任务,延迟检查时间为心跳过期时间,一旦延迟任务执行,则意外着心跳超时。
- 当收到一个心跳包时,需要取消上一次设置的延迟任务。
- 使用循环使用延迟任务,从而实现类似定时任务的效果。
接下来我们详细探讨一下DelayedOperationPurgatory的tryCompleteElseWatch方法,其代码如下图所示:
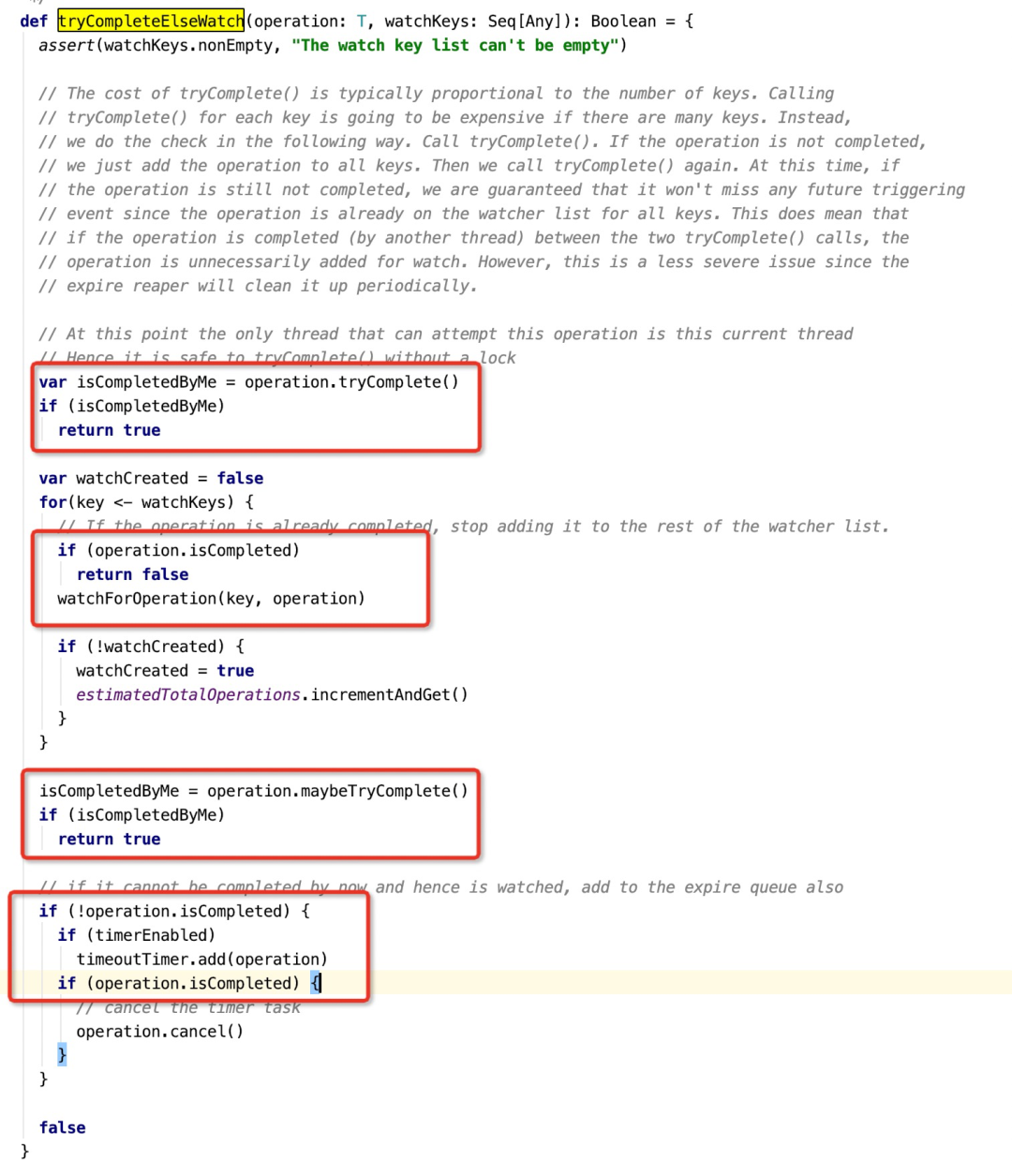
Step2:为该消费者添加到Watch中,表示kafka需要跟踪该消费者的心跳。
Step3:再次调用maybeTryComplete方法,再尝试判断是否该心跳检测完成。
Step4:如果没有完成,则该任务延迟任务(DelayedHeartbeat)添加到定时调度中。
接下来将进入到Kafka心跳的核心机制,即延迟任务的实现机制。
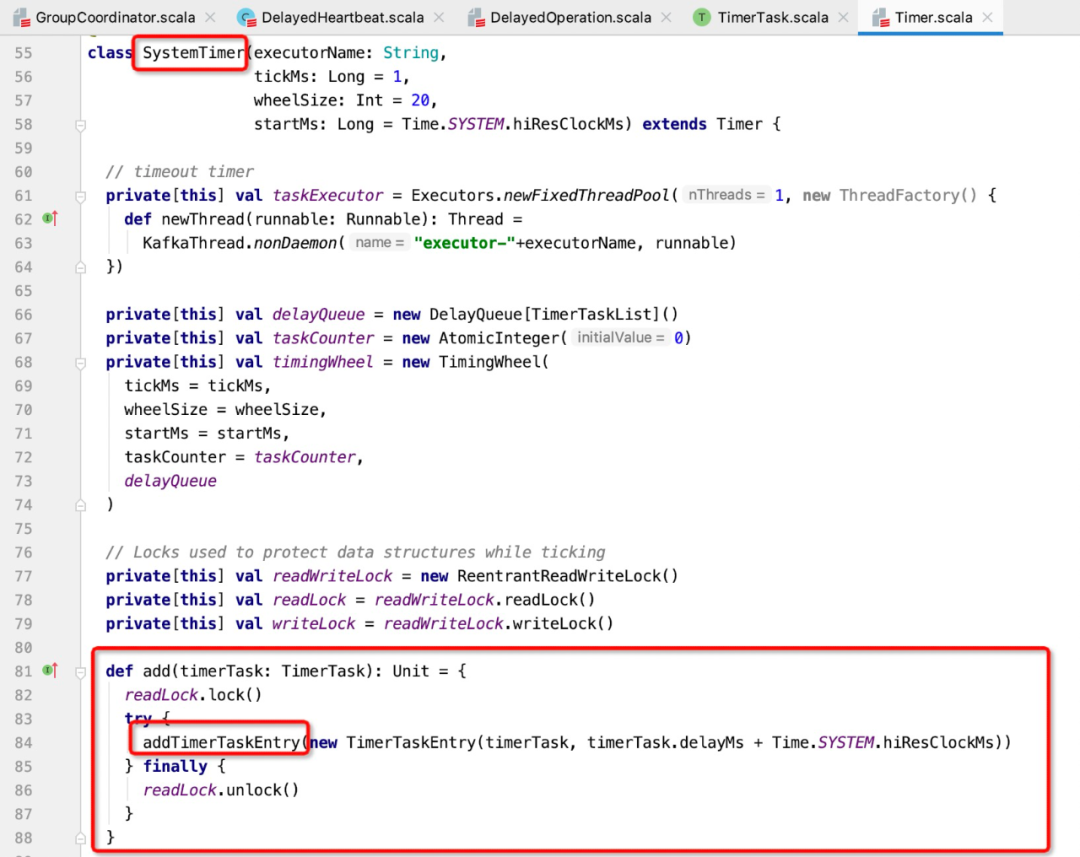
每一个待执行的延迟任务被封装在TimeTaskEntry中,这个一个典型的双链表,数据结构说明说明如下:
继续跟踪SystemTimer的addTimerTaskEntry,其代码如下:
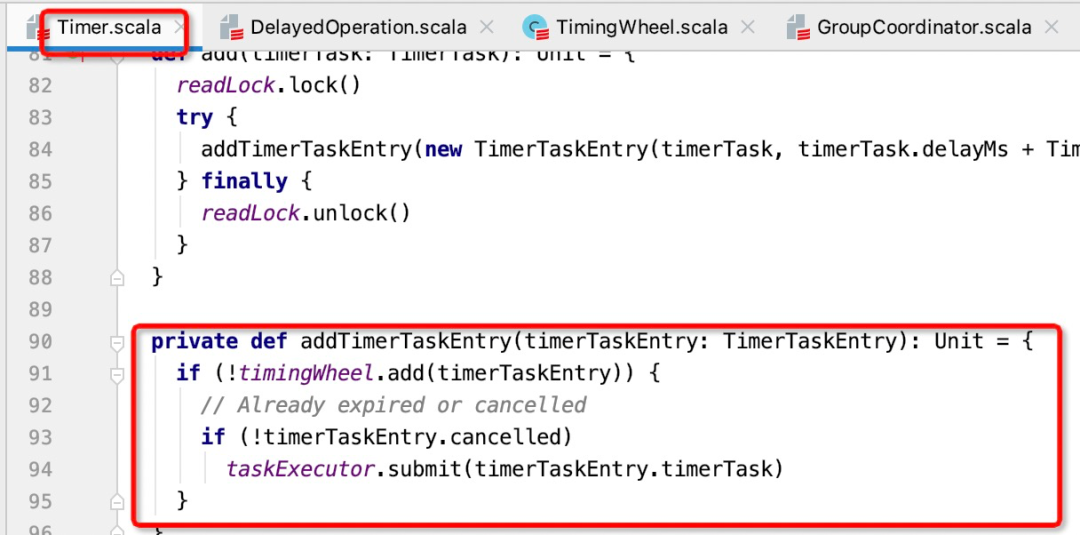
addTimerTaskEntry的核心实现如下:
-
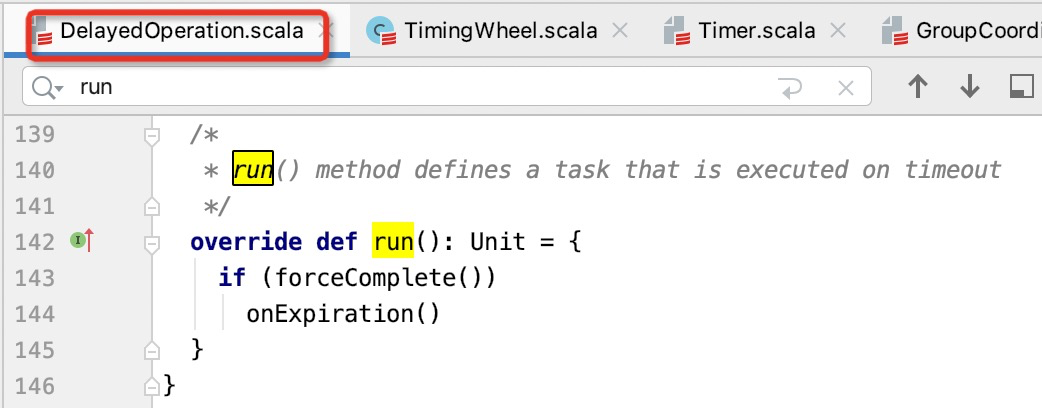
尝试将延迟任务添加到时间轮,如果已经过期,则提交到线程池,触发心跳过期的逻辑,提交到线程后,DelayedOperation的run方法会被调用,最终onExpiration方法被调用。
接下来重点谈一下往时间轮中添加任务的具体实现,核心代码见下图所示:
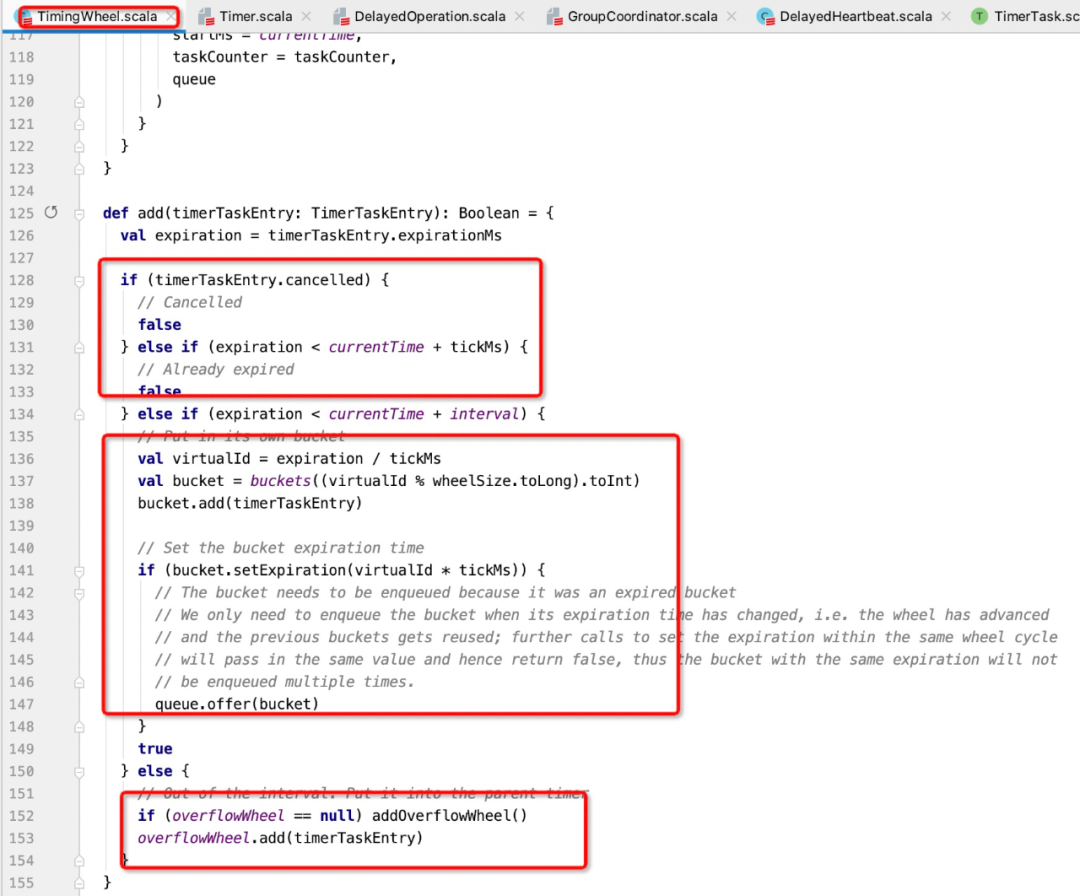
核心实现要点:
Step1:如果任务已经被取消或者已过期,返回false。如果返回false,则会触发定时任务过期。
Step2根据过期时间,放入到时间轮中指定的位置,时间轮的数据结构如下:

另外时间轮的总格子有限,则该时间轮能计算的最大时间是有限的,例如一个8格的时间轮,每一格代表200ms,则如果要在2s后过期,显然这个时间轮无法存储,通常的解决方案是采用多级时间轮,另外一级的时间轮,其时间精度会更粗。
结合上述关于时间轮的原理,再去看上述代码,就显得容易看懂了。
Step3:就是处理第一级时间轮无法满足过期时间,则放入到第二级时间轮中。
1.2.2.2 驱动时间轮
基于时间轮算法,除了数据按找时间轮到方向、触发时间存储在合适的刻度量,还需要驱动时间轮指针。Kafka中的驱动时间轮入口为:
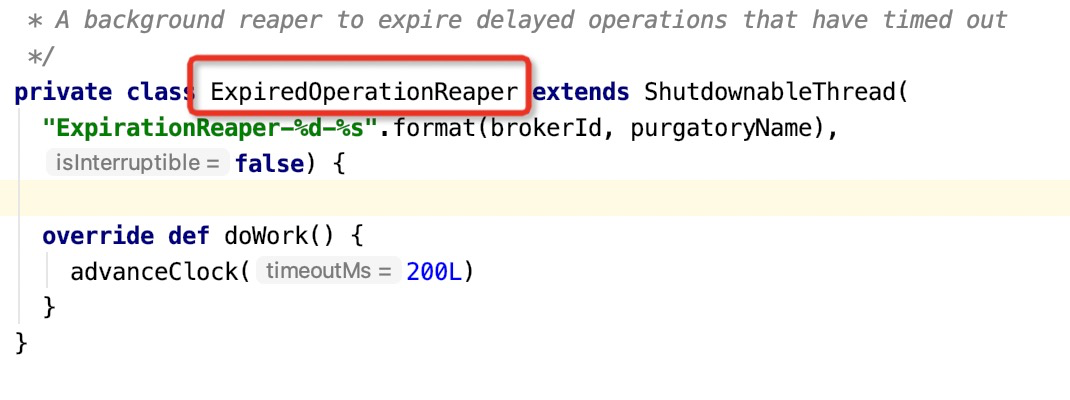
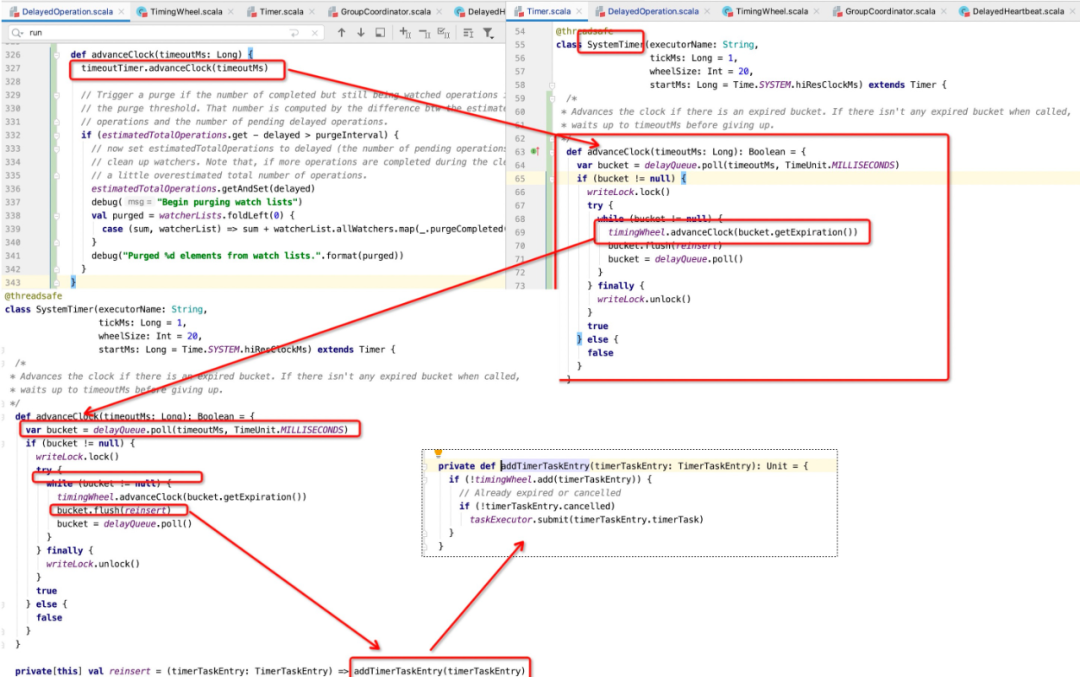
具体就是将指针处的所有任务全部拉取出来,执行addTimeTaskEntry,其中过期的任务将提交到线程池触发延迟任务的执行。
上述代码看起来比较简单,就不一一介绍,为了方便大家读懂上面的代码,我们只需要了解一下kafka采用时间轮的实际存储数据结构,即能很容易理解上述代码:
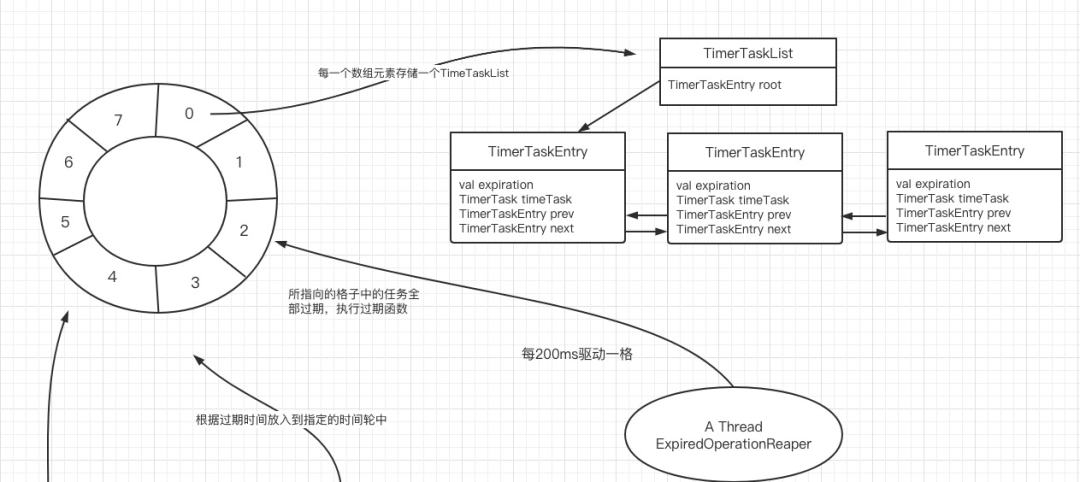
2、图解Kafka心跳架构设计
读起源码来说或许比较枯燥,接下来给出Kafka心跳处理的图解,重点是阐述Kafka时间轮算法的核心数据结构。
最后说一句
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下,您的支持是我坚持写作最大的动力。