有道云笔记新版编辑器架构设计(上)

在开发有道云笔记的新版编辑器的过程中,我们遇到很多实际问题,愈发感觉到这是一个非常有深度的前端技术领域,所以我们将新版编辑器的技术选型、架构和部分实现细节拿出来分享给大家,希望对大家开发富文本编辑器、做复杂系统的架构设计有一定参考意义。
01
富文本编辑器背景
1.1 什么是编辑器
编辑器在前端开发领域是指可以提供给用户编辑纯文本、富文本、代码、多媒体内容等的功能模块,例如以云笔记为例,编辑器指下图中绿色的区域。
编辑器一般由编辑区域、光标、工具栏、右键菜单等功能模块组成,一般都包含编辑文字、设置文字样式、设置段落样式、插入多媒体内容、撤销重做、复制剪切粘贴等功能。
1.2 编辑器发展简史
编辑器的由来可以追溯到打字机时代,下图是一个常见的打字机。

我们可以将打字机的构造与编辑器进行类比,打字机的纸张对应于编辑器的编辑,打字机的游标对应于编辑器的光标,甚至敲击键盘的表现,编辑器也与打字机一脉相承:
-
当敲击字母时,在光标后输入该字符;
-
当敲击空格键时,在游标之后插入空格;
-
当敲击回格键时,删除游标之前的字符;
-
当敲击换行键时,游标换到下一行开始;
而在计算机中,出现的最早的是文本编辑器,例如我们在 Linux 系统中常用的 vi,vim,emacs 等,它们可以对纯文本数据进行编辑,并引入了撤销重做、复制剪切粘贴、查找替换等编辑器的核心功能。

随着用户图形界面的兴起,人们对于文本的编辑不止满足于纯文本了,还需要给文本段落加上各种格式和排版信息。
同时,人们对于在文档中插入图片、图形、表格等更丰富格式的需求也越来越多。为了满足这些需求,富文本编辑器就出现了,其中的集大成者就是微软的 Word 和金山的 WPS。

Word 和 WPS 可以说将桌面客户端中的富文本编辑器做到了极致,至今也是功能强大的富文本编辑器。
但是它们的设计初衷就是做一款单机的文字处理软件,自然会遇到不支持互联网上的音视频格式、存储备份依靠本地计算机的文件系统、多人协作依靠文件拷贝等问题。
在互联网遍及千家万户的今日,人们反而不太需要 Word 提供的交互复杂的各种强大功能,而是需要支持更多互联网数据格式、存储备份更加方便、能够提供多人协同编辑功能的轻量级富文本编辑器。
基于浏览器的富文本编辑器就是在这样的设计思路下产生的,其中的代表产品有 Google Docs、有道云笔记、印象笔记、石墨文档等。
这些基于浏览器的富文本编辑器都有以下特点:
-
利用 Web 技术开发,需要在浏览器环境中使用;
-
功能相对 Word 更加简单,只保留了最常用的富文本编辑功能;
-
支持图片、附件、视频、音频、地图等多种互联网资源;
-
可以将文档备份在网盘中,实现多端同步;
-
文档可以分享查看,可以进行多人实时协同编辑。
当然基于浏览器的富文本编辑器,也是经过了几轮的技术迭代和创新,才到了今天这种百花齐放的局面。
1.3 基于浏览器的富文本编辑器四要素
在现代的浏览器框架下,利用 Web 技术开发一款富文本编辑器,一般采用经典 MVC 模型,根据数据模型渲染视图,视图操作通过控制器修改数据模型。具体要解决以下四个问题:
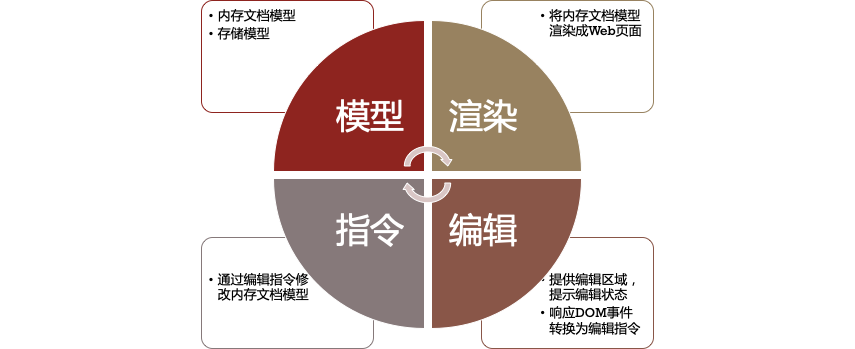
模型:
模型包含内存模型和存储模型。存储模型是数据存储、同步和备份时的模型,需要考虑带宽、存储体积、模型序列化效率、模型正确性验证效率等因素。内存模型则是数据渲染时的模型,结构一般比存储模型复杂,会在存储模型的基础上添加其他渲染时需要用到的属性。
渲染:
渲染指如何将内存模型渲染成 Web 页面。所有的基于浏览器富文本编辑器都将内存模型渲染成为了 HTML 页面。但是它们在排版上的策略略有不同,大多数编辑器都采用了基于 HTML 和 CSS 的排版方式,也有少数编辑器自己实现了排版引擎,例如 Google Docs。
编辑:
编辑指如何提供编辑区域让用户在编辑区域编辑文档,以及如何感知用户编辑区域的编辑动作通知控制器以修改数据模型。浏览器提供了 contentEditable 的属性可以把元素变为可编辑状态,大部分编辑器都是以这个思路进行编辑的,并且它们可以拦截 contentEditable 元素的事件,将事件通知给控制器。也有少数编辑器自己实现了编辑区域和事件系统,例如 Google Docs。
指令:
指控制器根据收到的编辑区域的编辑动作,生成对应指令修改内存模型,内存模型得以更新完成循环。这部分与数据模型相关,如果数据模型是 HTML,编辑器可以通过 execCommand 直接修改 HTML 数据,如果是自定义数据,监听或拦截编辑区域上的事件,也可以推测意图生成出修改数据模型的指令。通过指令修改数据,可以更方便的实现撤销重做、历史版本恢复、协同编辑等功能。
1.4 基于浏览器的富文本编辑器技术演进
基于以上四个问题,可以将基于浏览器的富文本编辑器划分为四代:
第一代:
完全基于浏览器 API 设计,数据模型直接采用 HTML 数据,渲染用原生 HTML,编辑区域用 contentEditable 生成,通过 execCommand 执行浏览器自带的修改 HTML 数据的指令。
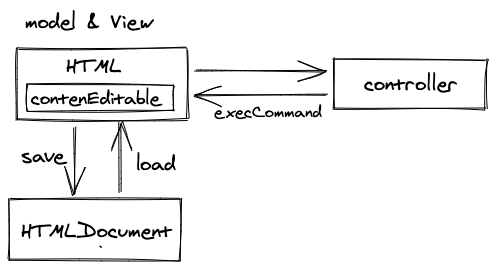
这类编辑器一般都出现在各类《XX 行代码教你实现富文本编辑器》的博客里,基本没有成熟的开源编辑器或者商用编辑器采用这一种设计方式。它们的主要问题处在 execCommand 接口上:
- 只提供了有限的几个命令,例如 execCommand 就没有办法支持插入待办列表。
- 提供的命令有些有功能受限,例如 'fontSize' 命令只能支持 1-7,导致不能自定义字体的大小。
- 修改的结果与浏览器有关,例如 'bold' 命令在一些浏览器上会给选区中的文字添加' b '标签,而在另一些浏览器上则会添加' strong '标签。
第二代:
由于 execCommand 功能上的限制,第二代的编辑器普遍抛弃了用浏览器的 execCommand 接口直接修改 HTML 文档的办法,而是用自己实现的 execCommand 和指令修改 HTML 文档,这样做就可以实现更加灵活多样的功能。
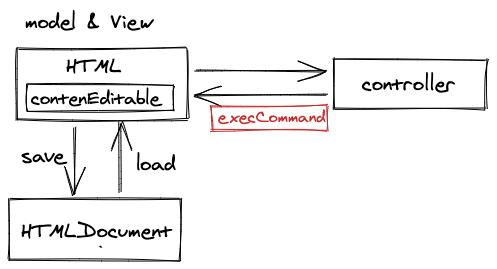
这类编辑器的主要问题是:不同的 HTML 结构可能表示的含义一样。例如下面两行 HTML 都表示一段既加粗又斜体的文字,但是他们的 HTML 结构却不一样,这样对比较数据是否一样就变得非常困难。

第三代:
针对 HTML 含义不一致的问题,第三代编辑器则抛弃了既用 HTML 做文档模型,又用 HTML 做渲染的策略,而是采用自定义的数据模型,例如 XML 数据模型或者 JSON 数据模型。同样的数据模型渲染生成的 HTML 一样,自定义的操作则可以保证同样的操作修改之后的文档模型也是一样的。
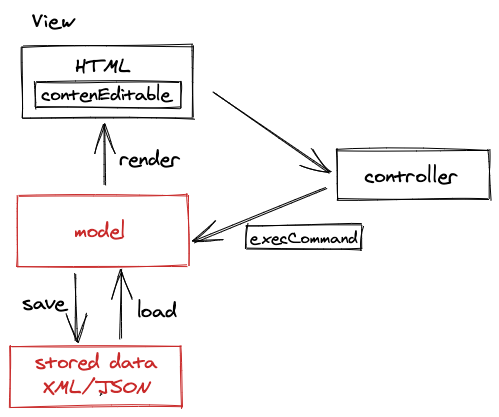
目前常见的编辑器产品例如:有道云笔记、石墨文档等,以及开源的编辑器库例如 Slate、Draft、Quill 等,都是第三代编辑器,它们已经能够满足大多数应用场景。但是由于渲染出的页面中,可编辑区域还是基于 contentEditable,需要根据拦截的事件判断用户行为,生成对应的指令修改数据模型。一旦有用户数据没有拦截,或者处理的行为不对,用户的行为就可能直接修改了 contentEditable 的元素,导致数据和视图的不一致。因此产生的 bug 定位和修复都比较难,在编辑器的移动端适配中经常出现。
第四代:
为了解决 contentEditable 引起的不可控事件,以 Google Docs 为代表的第四代编辑器则彻底抛弃的 contentEditable,自己实现排版引擎。排版引擎控制了文档的页面和布局,将数据渲染成为页面上的HTML。同时由于抛弃了contentEditable,还需要解决实现光标和选区的绘制、监听文字输入事件等技术问题,才可以做到和浏览器类似的编辑体验。
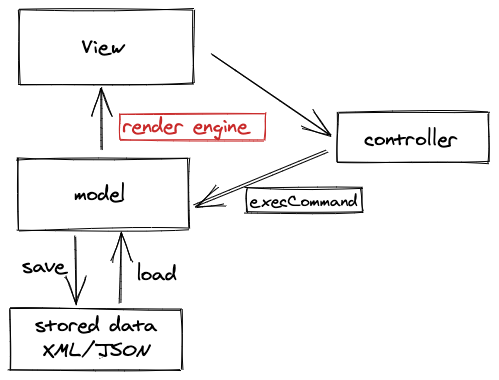
第四代编辑器相对于第三代,优点是彻底解决了contentEditable 引起的 bug,有更好的可扩展性。对应的代价是开发难度更高、体验不如原生、可能会遇到性能问题。目前只有 Google Docs 等采用了这种架构开发编辑器。
02
云笔记新版编辑器技术选型
根据上节所述的实现富文本编辑器的四要素,我们总结了四代编辑器的技术选型,如下表所示:

有道云笔记新版编辑器综合了项目的可扩展性和实现难度,作出了以下的技术选型:
- 模型:自定义的 JSON 数据格式作为内存模型,它的压缩版本作为存储模型;
- 渲染:借助浏览器排版,用 React 框架渲染视图;
- 编辑:不依赖 contenteditable,拦截浏览器事件判断用户交互,自己实现了光标和选区;
- 指令:实现了丰富的自定义的富文本编辑指令,重新实现了 execCommand 执行指令。
2.1 模型
有道云笔记新版编辑器采用了自定义的 JSON 数据格式作为内存模型。存储模型与内存模型基本对应,是内存模型的压缩版本,这样可以减少在数据序列化和反序列化过程中出现的错误。
文档模型:
新版编辑器的内存模型采用了文档-段落-文本的三层模型,顶层对象是文档(下图黄色区域),一篇文档包含多个段落(下图蓝色区域),每个段落中有至少一个文本(下图红色区域)。

对于三层的文档模型,我们可以很自然的想到用树的结构来表示它,如下图所示:
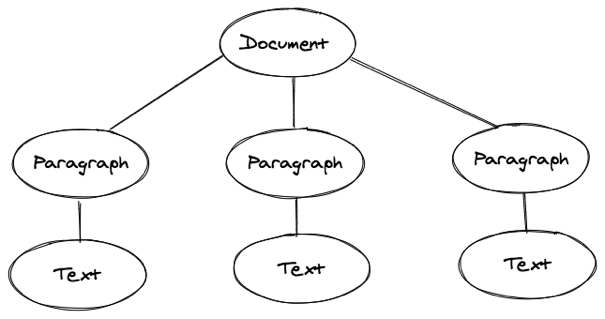
由于 JSON 格式天然的就可以表示嵌套的树状结构,所以我们的三层文档模型可以表示为以下的 JSON 结构:

富文本表示:
对于富文本编辑器的数据模型,需要考虑文本的行内样式和段落样式:
行内样式是作用于文字的样式,每个文字都可能有不同的行内样式,例如文字的粗体、斜体、文字颜色、背景色、字体、字号等
段落样式是用作与段落的样式,整段文字只会有一个段落样式,例如对齐方式、行高、段落缩进等。
由于我们三层文档模型中段落是单独一层,有对应的段落节点,所以对于段落样式只需要在段落节点上添加表示段落样式的字段,我们是在 paragraph 添加了 data 字段,其中添加了 style 属性表示该段落的段落样式,如下图所示:

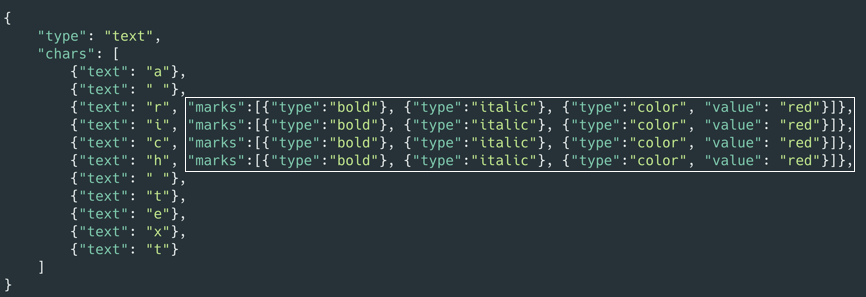
如果要表示行内样式,目前文本节点中只保存一个 content 字段就没有办法胜任了,需要将它拆分为一个一个字符在每个字符上添加表示行内样式的字段,例如我们可以用一个 chars 数组,里面的每个元素表示一个字符,text 字段表示字符的内容,marks 数组表示字符上的行内样式,如下图表示 a rich text。
叶子节点:
上述的富文本行内样式的表示方法中,我们可以看到rich的样式粗体、斜体、红色背景色保存在了 r, i, c, h 四个字符上,存在着冗余数据。我们参考了HTML渲染结果和部分开源编辑器的实现定义了合并规则。
如果连续的字符节点,具有完全相同的行内样式,则它们可以合并成一个叶子节点。
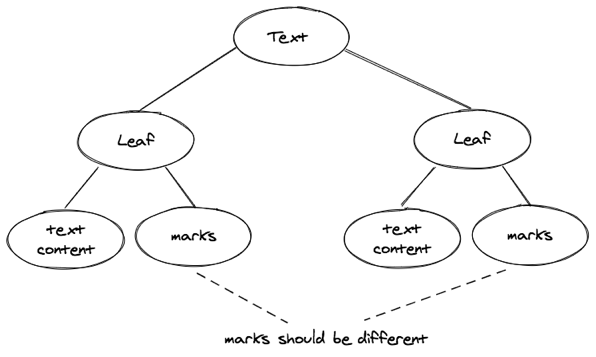
例如上面的例子里,r, i, c, h 四个字符连续且具有完全相同的行内样式,它们是可以合并成为一个叶子节点的。类似的 “a ”、“ text” 也分别可以合并成叶子节点,所以我们可以将文本节点简化表示为:

综上, 简化后支持行内样式的文本节点也是一个树状结构,它包含一个或多个叶子节点,每个叶子节点包含文本的内容和这些内容共同的行内样式,且相邻的叶子节点的行内样式必须不完全一致,如下图所示:
2.2 渲染
云笔记新版编辑器依旧采用了浏览器进行排版渲染,没有像 Google Docs 那样自研排版引擎,原因是我们认为浏览器的排版引擎已经足够强大,基本满足日常的文本编辑需求,只有诸如图片的文字环绕、分页、分栏等比较高级的功能无法实现,而自研排版引擎需要大量的开发和测试工作量,还可能会产生性能问题,所以我们暂时还是用来浏览器进行排版和渲染。
我们采用了 React 框架,采用了组件化的方式渲染数据模型。针对文档-段落-文本的三层数据模型,以及文本节点的叶子模型,我们设计了对应 React 组件嵌套进行渲染,如下图所示:
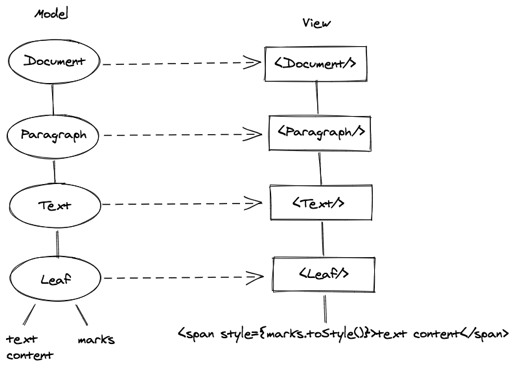
- Document 组件渲染文档数据。
- Paragraph 组件渲染段落数据,它是 Document 组件的子组件。
- Text 组件渲染文本数据,它是 Paragraph 组件的子组件。
- Leaf 组件渲染叶子节点,它是 Text 组件的子组件。
对于叶子节点包含的文本片段和行内样式,只需要渲染成一个带 style 属性的标签就可以了,这也印证了我们设计的富文本模型,简化了富文本的渲染逻辑,使得富文本渲染代码变得非常的轻量化。