有道云笔记新版编辑器架构设计(下)

上期文章,我们从整体上介绍了富文本编辑器的背景,并分享了有道云笔记新版编辑器技术选型中的模型和渲染部分。
[有道云笔记新版编辑器架构设计(上)]
本期文章,我们将继续分享技术选型中的编辑和指令部分内容,并详细解读有道云笔记编辑器的分层架构设计。
02
云笔记新版编辑器技术选型
2.3 编辑
由于 contentEditable 会产生不受控事件,导致很多 bug,例如,一开始数据是 abc,对应渲染出的视图是一个 span,内容是 abc。由于需要提供可编辑,span abc 是一个 contentEditable 的元素。
正常情况下,当编辑 span abc 时,例如输入了 d,我们拦截 keyup 事件,在处理函数中将事件 preventDefault,这一步是不让 contentEditable 元素自己修改 span abc为abcd,然后我们在处理函数里调用自定义的 insertText 指令,修改数据 abc 变为 abcd,再用新的数据进行渲染,修改 span abc 为 span abcd。
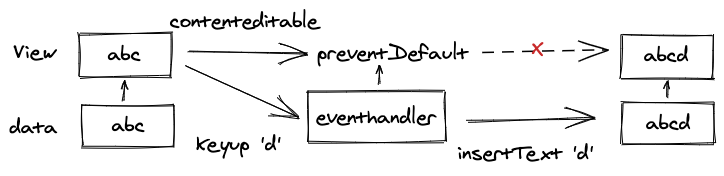
但是,一旦出现 span abc 上的事件没有被拦截或拦截了但没有正常处理,就会出现 bug。
例如我们旧版的编辑器就没有拦截 ctrl + delete 的事件,如果在 abc 这一行按 ctrl + delete 就没有对应的事件处理函数修改数据模型,数据模型还是 abc,但是由于 span abc 是 contentEditable 的,ctrl + delete 事件会直接修改 span abc 将 abc 整行删除,这样数据模型和视图上就出现了不一致。后续如果再输入 d,则会将数据模型修改成 abcd,这时候视图会根据新数据渲染为 span abcd,表现为已经删除的 abc 再次出现,对用户的使用造成困扰。

针对 contentEditable 的问题,我们决定将完全抛弃它,由此带来两个问题:
- 没有可编辑的元素,不会触发输入事件
- 没有可编辑的元素,无法使用浏览器自带的光标
触发输入事件:
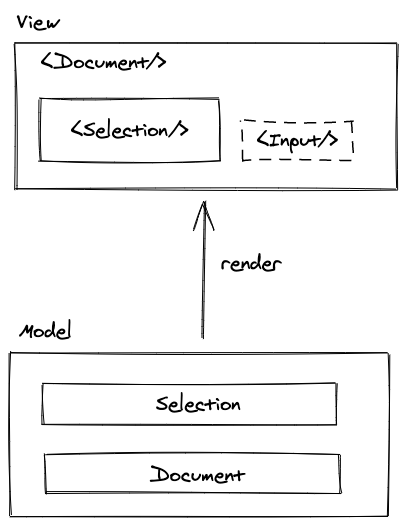
我们采用了在用户光标位置后画一个隐藏的 Input 组件,Input 组件中有一个 textarea 来接受用户的输入,触发输入相关的事件,如下图所示:

自绘光标/选区:
由于不能使用浏览器默认的光标,我们只能自绘光标。
我们参考浏览器的 Selection 的结构,设计了类似的Selection模型,并用Selection组件渲染 Selection 模型,在屏幕上用绝对定位画出用户的光标,同时用户拖蓝时产生的选区,也可以用这种办法绘制,由于光标和选区本质上一样,我们就放弃了浏览器的选区绘制,也改为自己绘制选区。具体流程如下:

我们用 anchor 表示用户开始托选的位置,focus 表示用户结束托选的位置。anchor 和focus 都包含了 nodeId 和 offset 两个属性,nodeId 表示位置所在的文本节点,offset 表示位置相对于文本节点开始的偏移量,以字符为单位。
当用户点击鼠标开始拖选时,找到鼠标所在的 dom 节点对应模型上的文本节点,我们拿到 id 存储在 anchor 的 nodeId 中,再计算鼠标在 dom 节点上的位置,转换为数据模型上相对文本节点开始处的偏移量,存储在 anchor 的 offset 中。
当用户移动鼠标或者抬起鼠标时,我们用类似的办法更新 focus 数据,将 anchor 和 focus 数据组合成为一个区域(Range)放入 Selection 模型中。这样我们就可以根据用户的点击/拖蓝操作构造出用户的光标/选区对应的Selection模型了。
然后,我们开发 Selection 组件渲染 Selection 模型。当 anchor 和 focus 在同一个位置时,Selection 组件将 Selection 模型渲染为一个闪烁的短线,表示用户的光标,当 anchor 和 focus 不在同一个位置时,Selection 组件将 Selection 模型渲染为一个从 anchor 位置到 focus 位置的一个或者多个矩形区域,表示用户的选区。
总结这一节,我们用 Input 组件触发用户输入事件,构造 Selection 模型和 Selection 组件用于自己绘制光标和选区,最终我们的模型层和视图层如下图所示:
2.4 指令
新版编辑器实现了丰富的自定义的富文本编辑指令,自己实现了 execCommand 方法来执行指令。
下面以输入文字的指令作为例子说明指令是如何生成的。
输入文字:
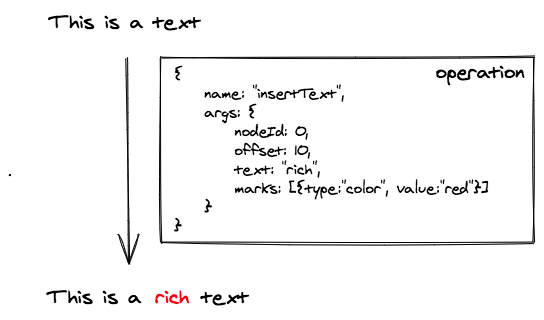
输入文字的指令名称是 'insertText',它需要传入以下四个参数:
- nodeId: 插入到的文本节点的 id
- offset: 插入的位置相对文本节点起始位置的偏移量
- text: 插入的文本内容
- marks: 插入文本的行内样式
在下面的例子中,我们想在 'This is a text' 的位置10处插入一个红色的 'rich' 变为 'This is a rich text',需要生成的指令如图所示:
生成指令上述的指令,需要我们将光标定位到 ‘This is a ’ 之后,然后点击工具栏的颜色按钮设置颜色为红色,再输入字符串 'rich ',根据用户操作生成指令的过程如下图所示:

在用户点击将光标定位到 ‘This is a ’ 之后时,我们更新了 Selection 模型,它的 anchor 和 focus 中的 nodeId 变为当前文本的 id,而 offset 变为 10。
然后,用户点击了红色按钮,这时候我们在Selection模型上记录用户当前设置的行内样式,将在下一次输入时生效(如果点击其他地方,这个行内样式将会重置为新光标前面一个字符的行内样式)。
最后,在用户按下按键输入文字时,我们拦截用户的keydown事件,从event.data中拿到需要插入的文本r,再根据当前的Selection模型,拿到anchor节点的nodeId和offset,以及存储在Selection模型上的行内样式,根据这几个参数就可以生成insertText指令了。
指令的组合:
指令直接会有一些公用的逻辑,为了指令逻辑的复用,我们将一些公用逻辑也封装成指令。简单的指令(Operation)可以组合成复杂的命令(Command)。例如选中一块区域并输入文字,理想的表现是删除区域内的所有文字,再插入输入的文字,如下图所示:

这个复杂的命令我们将它定义为 insertTextAtRange,它实际上是由三步组成:
第一步,先删除选区中的所有文字,这里我们用 deleteByRange 命令实现。而要删除选区中所有的内容,因为选区跨了三个段落,我们需要首先将第一个段落中的 ‘world’ 删除,用到了 deleteText 指令;然后将第二个段落节点 ‘hello javascript’ 整个删除,这里用的是 deleteNode 指令;最后我们还需要将最后一段中的 hello 删除,这里用的也是 deleteText 指令。所以一个 deleteByRange 命令又由多个 deleteText 和 deleteNode 指令组成。
第二步,删除完选区所有文字之后,我们需要插入 editor 到第一段的 hello 之后,用到了上面提到的 insertText 指令。
第三步,我们发现 hello editor 和2020都是文本段落,按照需求我们要将他们合并到一起变为'hello editor 2020',就用到了mergeNode 的指令。
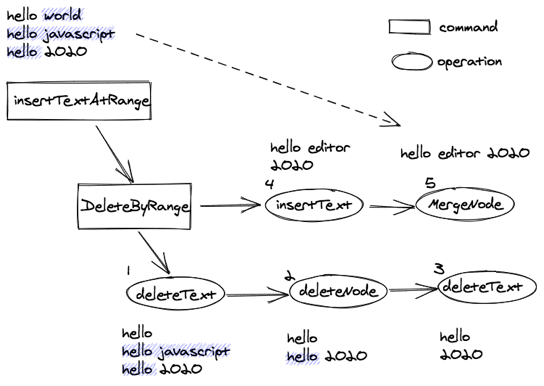
由此可见一个复杂操作对于的命令是有多个指令和命令共同组成的,这种方式能充分解耦和复用的指令,让每个指令只关注于实现一类对数据模型的修改。
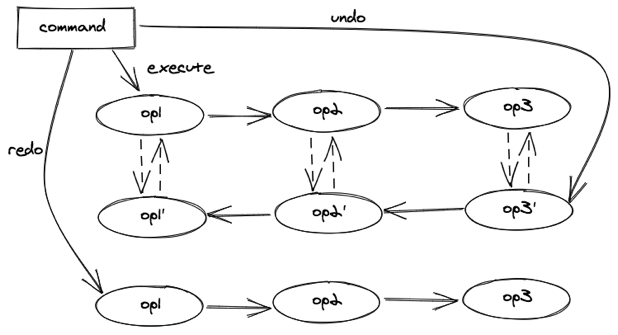
撤销重做:
将对数据模型的修改抽象成指令之后,撤销重做就变得比较好实现。
我们规定指令都是成对出现的,每个指令都有对应的逆指令,例如 insertText 的指令它的逆指令是 deleteText,文档模型 Document 在 insertText 指令的修改下变为了Document',那么根据 insertText 指令构造出的逆指令 deleteText 就可以修改Document‘ 让它恢复成 Document,这就是实现撤销重做的基础。
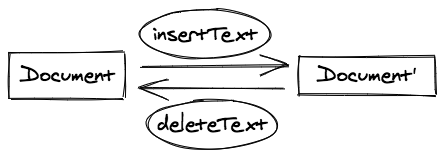
对于复杂的命令,我们会在他执行的时候收集执行的所有简单指令。在撤销时,根据指令的执行顺序,反向的执行所有收集到的指令的逆指令。在重做时,则只需要正向的执行所有收集到的指令。
2.5 小结
本章从模型、渲染、编辑、指令四个角度中的前两个说明了新编辑器的技术选型。
总结起来,新编辑器采用典型的 MVC 模式,结合了 React 等前端框架的数据驱动的思想,通过修改数据模型来解决更新视图,由于放弃了 execCommand 和 contentEditable 这两个浏览器的 API,所以自己实现了指令系统、事件拦截和光标绘制。
整个富文本编辑的模块如下图所示:

但是由于富文本编辑器除了需要支持富文本的编辑功能,还需要支持图片、附件、表格、代码块等其他复杂功能,在上述框架内如何扩展支持这些功能,**如何实现功能的解耦和可配置,**这就是下一节我们讨论的问题。
03
新编辑器的分层架构
首先我们用图片功能为例,说明如何在现有框架下实现。
3.1 实现图片功能
我们先只考虑占据一行的图片,这类图片可以单独当做一个段落,所以是可以放入我们的三层文档模型的第二层,如下图所示:
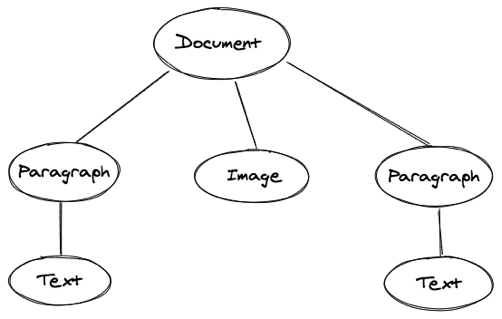
对应的我们需要开发 Image 组件渲染图片,它与 Paragraph 组件一样,也是 Document 组件的子组件,如下图所示:
点击工具栏按钮,我们需要在文档光标处插入对应的图片,这就需要我们生成 insertImage 命令,用它修改文档模型,生成 insertImage 命令的过程如下:
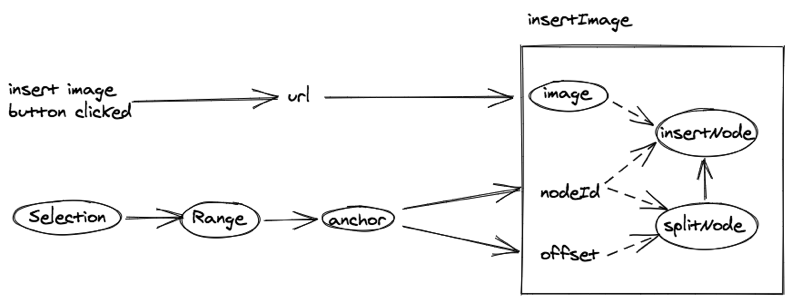
由上述添加图片功能的做法可以看出,新添加一个功能,我们需要设计实现对应的模型、组件和命令,每个功能都涉及到这三处功能的修改,随着功能越来越多,不同功能之间的代码会互相耦合。
并且,在不同应用场景下,需要不同的功能,例如编辑器 A 只需要图片附件和表格的功能,编辑器 B 需要图片、代办、列表的功能,这种编辑器定制是比较难实现的,之前只能通过屏蔽入口实现,js 包里有很多无用代码。
如何解决这些问题呢?
3.2 分层架构
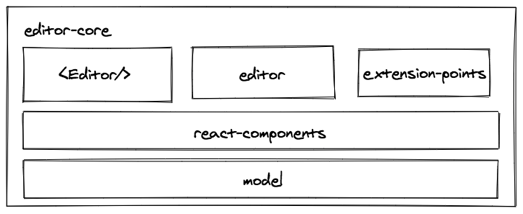
为了解决编辑器核心功能和业务功能的解耦,我们将云笔记新版编辑器的架构分为了核心层和业务层:
- 核心层 只负责提供富文本的编辑能力,以及多种拓展机制。
- 业务层 负责实现各种各样的扩展功能,例如图片、附件、表格、代办、列表等。
核心层:
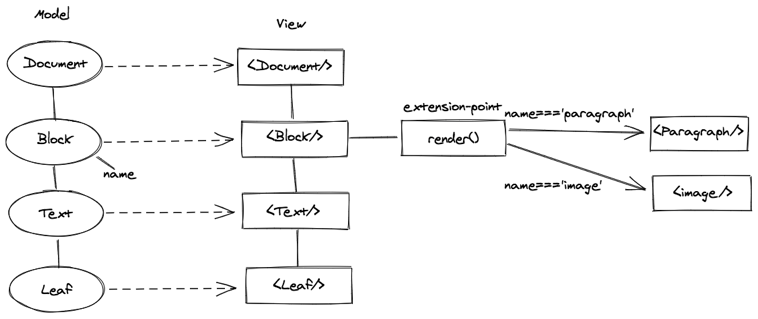
核心层的主要能力是通过第二节的 MVC 框架提供富文本编辑能力。它暴露了以下接口:
- 首先,是 Editor 组件,Editor 组件提供包含富文本编辑能力的编辑器组件,业务层只需要将它作为一个 React 组件进行调用就可以了。
- 其次,是 editor 全局对象,它上面挂在了执行编辑命令、撤销、重做等富文本编辑的核心接口。
- 最后,核心层还提供了丰富的扩展机制,用于业务层对编辑器能力进行扩展。常见的扩展机制包含数据模型扩展、组件扩展、插件扩展、自定义命令等。
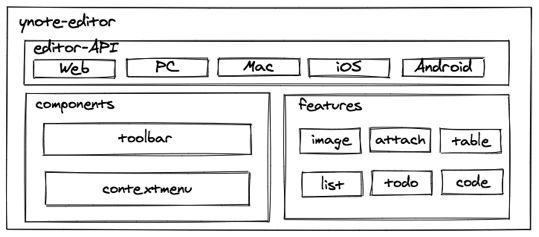
业务层:
在核心层提供的富文本编辑器的基础上实现云笔记编辑器的众多复杂的业务功能。大致包含以下几个需要开发模块:
- 首先,需要将核心层提供的 Editor 组件与业务层开发的工具栏、右键菜单等组件组合成为一个功能完整编辑器。
- 其次,需要利用核心层的扩展机制开发相互解耦的编辑器特性,扩展编辑器的功能,例如图片、附件、表格、代办、列表等等。
- 最后,还需要开发与云笔记编辑器与不同平台宿主 WebView 交互的接口层 editorAPI,实现云笔记编辑器的跨平台特性。
所以用如下图这样的分层结构,我们就可以解决**编辑器功能耦合和定制化的问题。**
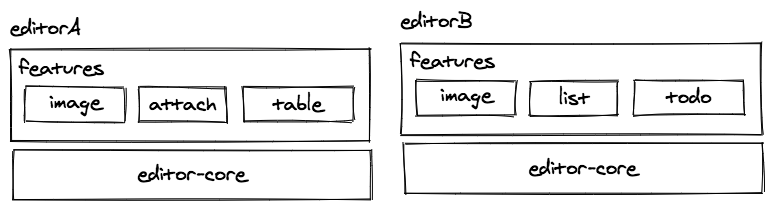
编辑器和核心富文本编辑功能和扩展功能之间以及不同的扩展功能之间都是单独开发的,耦合的可能性大大降低。同时针对不同的编辑器定制需求,可以组合不同的编辑器特性进行打包,这样就可以实现按需打包出定制版的编辑器。
3.3 扩展机制
用核心层提供的扩展机制,我们重新实现图片的功能。
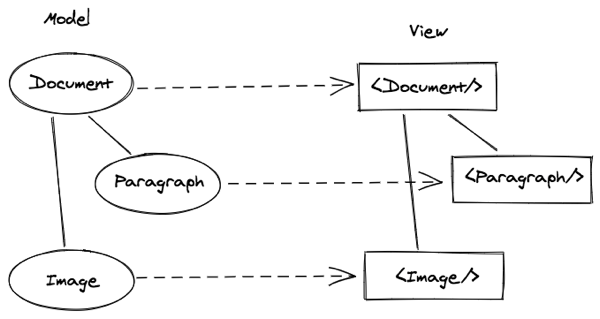
首先,我们将三层文档模型的第二层由段落泛化为块(Block),块上提供 name 字段表示块的类型,默认类型为表示段落的 paragraph,针对图片类型,name 可以标志位 image。
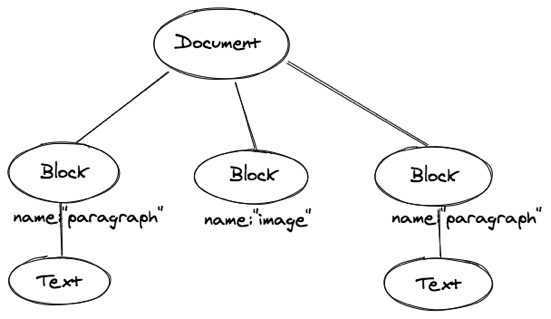
图片模型中我们需要记录图片的地址,我们在块的模型中添加 data 字段用于存储不同类型块的自定数据,对于图片就可以在 data 中存储 url 字段。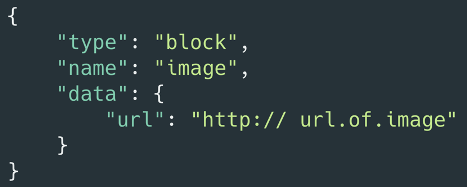
例如,针对 name 是 paragraph 的段落数据用 Paragraph 组件进行渲染,针对 name 是 image 的图片组件,则用 Image 组件进行渲染。
最后,我们需要实现 insertImage 的自定义命令,通过 editor 的 registerCommand 注册命令,就可以在点击工具栏插入图片时调用 insertImage 的命令修改数据模型。
在实现 insertImage 自定义命令的过程中,我们可能会用到 editor 上保留的编辑器内置命令和指令。
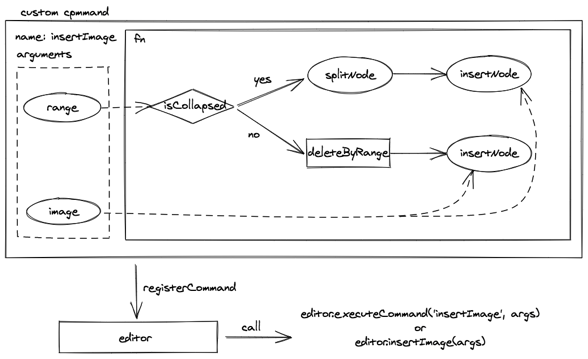
做完这三步,我们就利用编辑器的扩展机制实现了图片的功能。可以看出这样实现的图片功能,有扩展性强、耦合低、可插拔等优点。
04
总结
综上所述,云笔记新版编辑器采用了核心层和业务层的两层架构,如下图所示:

在核心层,舍弃了存在较多问题的 contentEditable 和 execCommand 接口,自定义了数据格式,攻克了光标绘制、事件拦截、命令系统等技术难题,实现了富文本编辑的核心功能。同时还暴露了丰富的扩展机制。
在业务层,通过核心层暴露的扩展机制,我们可以开发各种不同编辑器特性,通过注册机制将它们注册回编辑器丰富编辑器的功能。
在开发有道云笔记的新版编辑器的过程中,我们遇到很多实际问题,愈发感觉到这是一个非常有深度的前端技术领域,所以我们将新版编辑器的技术选型、架构和部分实现细节拿出来分享给大家,希望对大家开发富文本编辑器、做复杂系统的架构设计有一定参考意义。