你真的了解二叉树吗?(树形结构基础篇)
树形结构,尤其是二叉树,在我们平时开发过程中使用频率比较高,但之前对于树形结构没有一个比较系统全面的了解和认知,所以借此机会梳理一下。
本文属于《你真的了解二叉树吗》系列文章之一,主要介绍的是树形结构的基础,在看完这篇文章之后,如果想要更加熟练掌握二叉树的话,可以看另一篇《你真的了解二叉树吗(手撕算法篇)》(下周发布)。
一、树形结构基础
ydtech
相较于链表每个节点只能唯一指向下一个节点(此处说的链表是单向链表),树则是每个节点可以有若干个子节点,因此,我们一个树形结构可以如下表示:
interface TreeNode {
data: any;
nodes: TreeNode[]
}1.1 树的度
PS: 在图结构中,也有度的概念,分为出度和入度,如果把树看作是图的一部分的话,那么严格来说,树的度其实是出度。不过,在树形结构中,我们通常把度这个概念作为描述当前树节点有几个子节点。
即每个节点拥有几个孩子,因此,二叉树的度最大是2,链表(可以看成只有一个孩子的树)的度最大是1。
- 定理:在一个二叉树中,度为 0 的节点比度为 2 的节点多1。
- 证明:假如一个树有 n 个节点,那么,这棵树肯定有 n-1 条边,也就是说,点的数量=边的数量+1(这个结论针对所有树形结构都适用,不仅仅是二叉树)如下图:
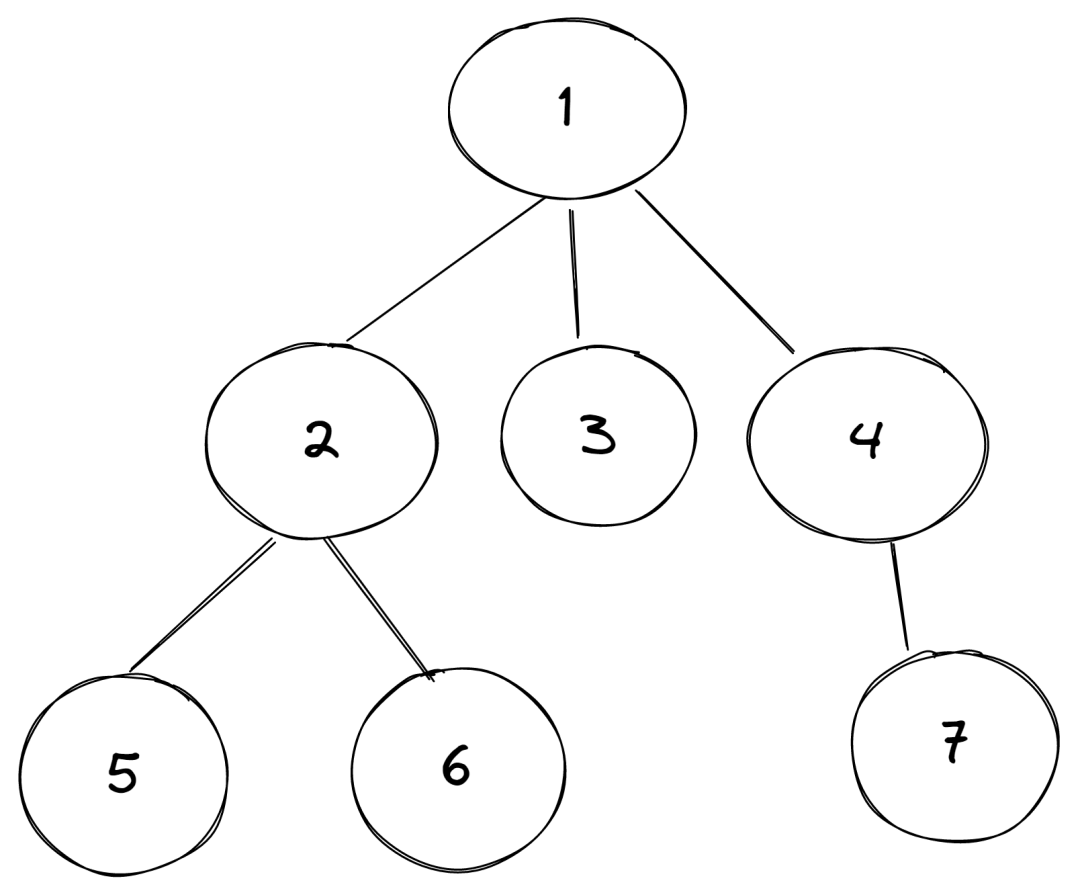
那么,我们假设度为 0 的节点数量为 n0,度为 1 的节点为数量 n1,度为 2 的节点数量为n2,又因为是度为 0 的节点,说明他的边的数量 N0=0,度为 1 的节点边的数量为N1=n1*1,度为2的节点边的数量为N2=n2*2,那么总共的节点数量为:
# 由上可知,边数量的表达式如下
N0=0;
N1=1*n1;
N2=2*n2;
# 由上可知,节点的数量=边的数量+1
n0 + n1 + n2 = N0 + N1 + N2 + 1;
# 代入N0,N1,N2得:
n0 + n1 + n2 = 0 + n1 + 2*n2 + 1;
# 化简得:
n0 = n2 +1;
# 即度为0的节点数量永远比度为2的节点多一个
由此,我们就证明了上面的定理,我们把这个定理换个描述或许更容易理解:
在二叉树中,只要你知道了有多少个叶子节点,那么度为2的节点数量就是叶子节点的数量减1,反之,知道度为 2 的节点数量,那么叶子节点的数量就是度为2的节点数量加1。
1.2 树的遍历
5
/ \
1 4
/ \
3 6
| 名称 | 遍历顺序 |
|---|---|
| 前序遍历 | 根节点 左子树 右子树 5->1->4->3->6 |
| 中序遍历 | 左子树 根节点 右子树 1->5->3->4->6 |
| 后序遍历 | 左子树 右子树 根节点 1->3->->6->4->5 |
| 层序遍历 | 即从上往下一层层遍历,根节点 根节点上所有子节点 下一层的子节点 5->1->4->3->6 |
1.3 树的遍历思想
树天生就是一个适合递归遍历的数据结构,因为每一次处理左子树和右子树的时候,其实就是递归遍历的过程。
- 前序遍历:「根节点」「递归遍历左子树的输出结果」「递归遍历右子树的输出结果」
- 中序遍历:「递归遍历左子树的输出结果」「根节点」「递归遍历右子树的输出结果」
- 后序遍历:「递归遍历左子树的输出结果」「递归遍历右子树的输出结果」 「根节点」
1.4 思维发散
看到这里,有一些小伙伴可能会感觉似曾相识,是不是在哪里看过树相关的一些知识呢。
其实在之前我们学习栈这个数据结构的时候,就有讨论过这个话题。我们知道,栈天生适合用于表达式求值,那么,它在处理表达式求值的过程中,是怎样的一个逻辑结构呢?
如:3*(4+5)这个表达式。其实,虽然我们在解答的时候,使用的是栈的思想,但实际上在逻辑层面,我们是在模拟一棵树的操作过程。不相信?那我们来看看:
[ * ]
[ 3 ] [ + ]
[ 4 ] [ 5 ]
上面,我们将这个表达式拆借成了一个树形结构,当我们表达式中遇到 () 时,说明里面的子表达式需要优先处理,那么,我们就把他看作是我们二叉树的一个子树。
我们都知道,树的遍历思想是递归遍历,是由下往上逐层解决问题,这样,在递归调用的过程中,他就会先解决右子树的子问题,得到结果之后,再与左子树计算出来的结果进行最终运算得出最终结果。
1.5 还原二叉树
如果我们已知前序遍历结果、中序遍历结果、后续遍历结果三者中的任意两个,我们就能够完整的还原一颗二叉树。例如:
# 前序遍历输出结果
1 5 2 3 4
# 中序遍历输出结果
5 1 3 2 4
上面是两种遍历方式的输出结果,我们知道,前序遍历的第一个节点一定是根节点,所以,此时,我们就已经知道,原二叉树的根节点为 1,接下来,我们拿这个 1 的节点到中序遍历的输出结果中,找到 1 的位置。
又因为中序遍历的输出结果是左根右,那么,我们不难知道,在1左边的就是原二叉树的左子树的中序遍历输出,在 1 右边的就是原二叉树的右子树的中序遍历输出。这样,我们就可以把中序遍历输出分成以下几块:

上面只有5个节点的树,是不是很简单呢?接下来,我们再来一个稍微难一点的的思维题:
已知10个节点的二叉树的前序遍历结果和中序遍历结果,还原这个二叉树
前序遍历输出序列:1 2 4 9 5 6 10 3 7 8
中序遍历输出序列:4 9 2 10 6 5 1 3 8 7
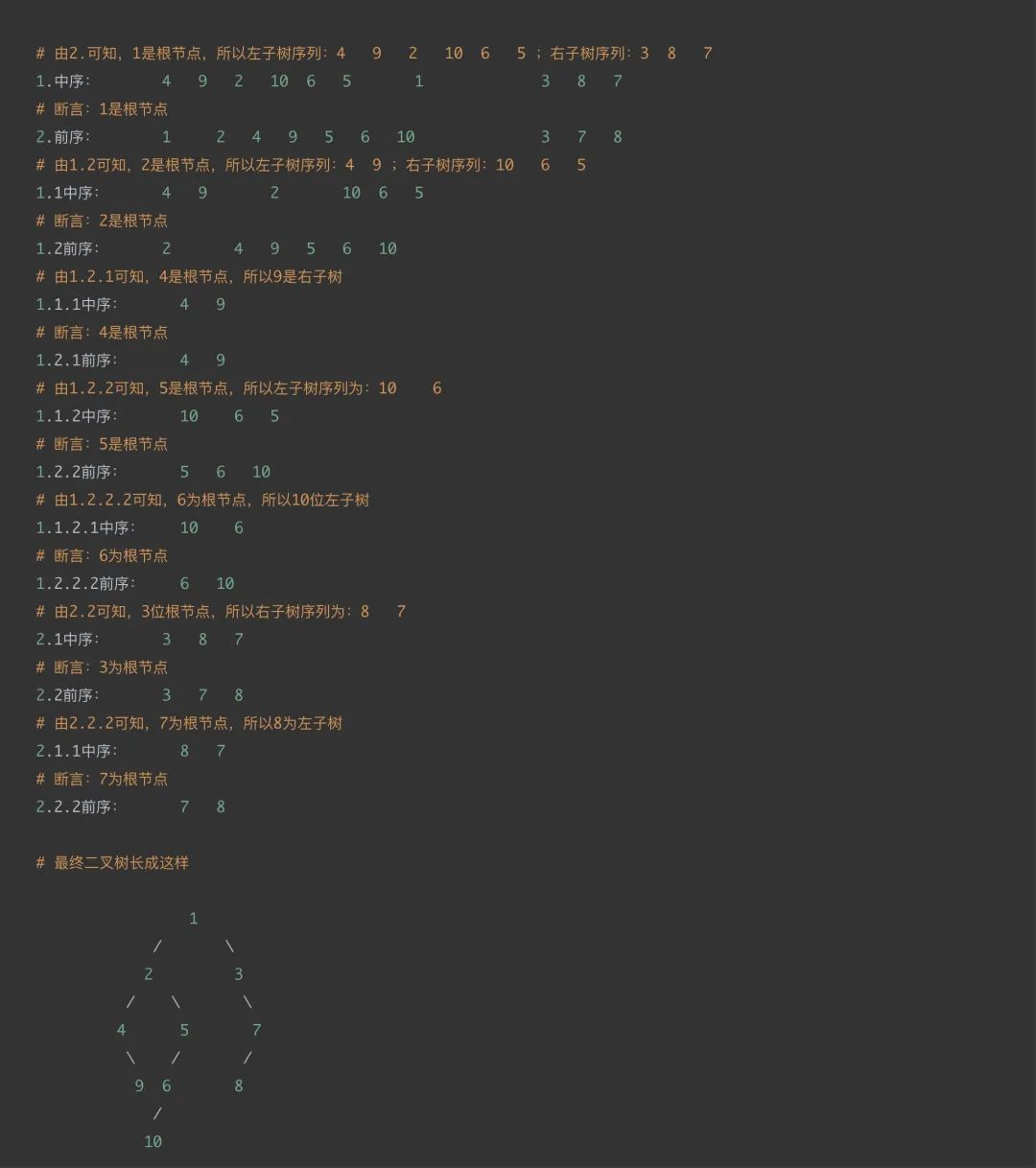
1.6 二叉树的常见分类
1.6.1 完全二叉树(Complete Binary Tree)
只有在最后一层的右侧缺少节点的二叉树叫做完全二叉树,也就是说,完全二叉树的左侧是满的,只有右侧才允许有空节点。
1
/ \
2 3
/ \ / \
4 5 6
完全二叉树是一个非常优秀的一个数据结构,它有以下两个主要的特点,能够让我们在性能和程序实现上有更好的体验。
- 节点编号可计算
从上面的完全二叉树中,我们可以看出一个规律:
编号为n的节点,他的左子树根节点的编号必定为 2n,他的右孩子的根节点的编号必定为2n+1,如上图2的左子树根节点的编号为 4,就是 2*2=4。右子树根节点的编号为 5,也就是 2*2+1=5。
那么利用这个规律,我们可以干什么呢?
我们知道,普通的二叉树,除了存储数据用的数据域之外,还需要额外的存储空间用来存储左子树和右子树的指针,也就是指针域。如果我们能通过上面的规律直接计算出当前节点左子树和右子树根节点的编号,那是不是就不需要额外的存储空间去存储左右子树的存储地址了,当一个树足够大的时候,这可以给我们节省相当大的一个存储空间。
上面通过计算来替代记录存储地址的方法,引申出一个我们在日常工作中经常会使用到的一个算法思想:记录式与计算式思想的转换。
- 记录式(节省时间,耗费空间,无需计算,直接取值,即:空间换时间):把信息存起来,用到的时候取出来用。
- 计算式(节省空间,耗费时间,无需存储,计算取值,即:时间换空间):通过计算得到的,如 1+1=2 中的 2 就是我们通过计算 1+1 这个表达式得到的结果。
这两种方式各有各的优缺点,脱离问题本身比较这两种方式的优劣是没有意义的,我们应该结合具体问题,看使用哪种方式能给你带来更大的收益。
场景一:当内存空间有限,对计算时间要求不强时,如在一个内存较小的机器中运行一段程序,我们会选择计算式,用时间换空间。
场景二:当我们内存空间足够大,并且对计算速度有要求时,如企业级应用服务器上运行实时计算数据时,我们会选择记录式,用空间换时间,因为一个企业级的应用,一般内存是足够大的,还可以动态扩容,这时候,时间所带来的效益就远大于空间所带来的的效益了。
- 可使用连续的存储空间存储
除了节点编号(即节点地址)可计算这个特性外,完全二叉树由于它的编号是连续的,从上到下升序且连续的序列,因此,我们可以把完全二叉树存储在一个连续的存储区,如:数组中,数组下标为 0 的元素存放 1 号节点,为 1 的元素存放 2 号节点。
利用这个特性,我们在实现一个完全二叉树时,可以无需像实现普通二叉树一样单独定义一个结构,并分别定义数据域和指针域来分别存储数据和指针,我们完全可以使用一个数组直接存储数据,这也是我们完全二叉树最常见的表现形式。
我们来想象一下:你在程序中实现时用的是一维的线性结构,即数组来表示的,但在你的脑海里,应该要把它转化为二维的树形结构来思考问题,这也是一个相对高级的编程逻辑思维能力,让我们能够在脑海中将看到的数据结构“编译”成它真正运行时的模样。
当然,要有这样的能力,可不是一朝一夕的事情,需要经过大量的锻炼才能具备这种能力,至少,笔者写下此行的这一刻,是没办法达到这个境界的。
1.6.2 满二叉树(Full Binary Tree)
没有度为1的节点的二叉树叫做满二叉树,即所有节点要么没有子节点,要么有两个子节点。
(PS: 我们经常在网上看到很多文章博客上会把完美二叉树的定义放在满二叉树上,其实是错误的,完美二叉树的具体定义见下文。)
1
/ \
2 3
/ \ / \
4 5 6 7
/ \
8 9
1.6.3 完美二叉树(Perfect Binary Tree)
所有节点的度都为2。由此可以看出完美二叉树的定义还是与满二叉树有区别的。我们可以说完美二叉树是特殊的满二叉树。
1
/ \
2 3
/ \ / \
4 5 6 7
二、树结构深入理解
ydtech
2.1 节点
树的节点代表一个集合,子节点就代表在父集合下互不相交的子集,这样说可能难以理解,那么,咱们来看下面的一个图:
5
/ \
2 3
# 上面的二叉树,5节点,我们可以把它当做是一个全集,而下面的两个子节点2和3则是这个全集下的两个互不相交的子集,两个子集相加应该等于全集。
由上图我们可以得出一个结论:
树的一个节点代表一个集合,而子节点代表全集下面互不相交的子集,所有的子集相加能够得到全集。
2.2 边
树的每一条边代表关系。
三、学习二叉树的作用
ydtech
3.1 应用于各种场景下的查找操作
由于二叉树结构包括天然递归结构、与二分思想完美契合的特性,使得二叉树及其各种变种结构极其适合在各种场景下进行高效的查找操作,我们计算机底层也有诸多设计时基于二叉树与二叉树变种结构的,便是由于其优秀的性能能够提供高效而稳定的查找效率。
3.2 有助于理解高级数据结构的基础
- 完全二叉树(维护集合最值的神兵利器)
- 堆
- 优先队列
- 多叉树/森林
- 解决字符串及相关转换问题的神兵利器
a . 字典树
b . AC自动机
2 . 解决连通性问题的神兵利器
a . 并查集
- 二叉排序树
- 语言标准库中重要的数据检索容器的底层实现
a . AVL树(二叉平衡树)
b . 2-3树(二叉平衡树)
c . 红黑树(二叉平衡树)
- 文件系统、数据库底层的重要数据结构
- B树/B+树(多叉平衡树)
3.3 练习递归技巧的最佳选择
学习递归的顶层思维方式:
设计/理解一个递归程序:
1 . 数学归纳法 => 结构归纳法
若 k0 是正确的,假设 ki 是正确的,那么 k(i+1) 也是正确的。如求解斐波那契数列:
function fib(n) {
// 首先要确定k0是正确的,也就是前提条件(边界条件)是正确的,在这题中,k0就是n=1时,结果为1,n=2时,结果为2
if(n <= 2) return n;
return fib(n - 1) + fib(n - 2);
}2. 赋予递归函数一个明确的意义
上面代码中,fib(n) 代表第 n 项斐波那契数列的值。
3. 思考边界条件
在上面的代码中,我们的边界就是已知条件,n=1 时为 1,n=2 时为2,需要对这个边界进行特殊处理。
4. 实现递归过程
处理完边界问题后,就可以递归继续往下走了。
如果让你设计一个二叉树的前序遍历的程序,你会怎么设计呢?
- 函数意义:前序遍历以 root 为根节点的二叉树;
- 边界条件:root 为空时无需遍历,直接返回 root;
- 递归过程:分别前序遍历左子树和前序遍历右子树。
// 函数意义:前序遍历以root为根节点的二叉树
function pre_order(root) {
// 边界条件:root为空时无需遍历,直接返回root
if(!root) return root;
console.log(root.val);
// 递归过程:分别前序遍历左子树和前序遍历右子树
pre_order(root.left);
pre_order(root.right);
}3.4 使用左孩子有兄弟法节省空间
将任意的非二叉树转换成二叉树,如将一个三叉树转换成二叉树:
# 注意,要始终保证二叉树的左边是子节点,右边是兄弟节点
# 原三叉树
1
/ | \
2 3 4
/ \
5 6
# 按照左孩子右兄弟的方式转换成二叉树
1
/
2
\
3
/ \
5 4
\
6
# 因为2是1的孩子,所以放在左子树,因为3是2的兄弟,所以放在2的右子树,4是3的兄弟,放在3的右子树,5是3的孩子,放在3的左子树,6是5的兄弟,所以放在5的右子树。
大家可以发现,当只是将一棵树通过左孩子右兄弟法转换成二叉树时,根节点的右子树始终为空,那么,我们是不是可以有效地利用这个右子树,把多棵树合并到一棵二叉树中呢?例如下面的示例,就是将两颗二叉树**合并**到了一起,形成了森林。
# 如果要把下面的两棵树合并到一个二叉树中呢?
1 7
/ | \ / \
2 3 4 8 9
/ \
5 6
1
/ \
2 7
\ /
3 8
/ \ \
5 4 9
\
6
# 这样,我们就将两棵树合并成一颗树了,也就是森林了。这棵树看似一颗二叉树,但其实表示的是两棵树组成的森林。
众所周知的 Alpha Go 的算法源码中实现的蒙特卡罗树搜索算法框架的具体实现算法,称之为信心上限树算法(UCT)就是采用了左孩子右兄弟法实现的一颗搜索树,用来表示整个棋盘的局面,正常来说,如果要存储一个棋盘的局面的话,会存储一个树形的结构中,但因为棋盘局面情况太多了,有可能形成一个100多叉以上的树,在 Alpha Go 中为了避免这种情况,就把这个100多叉树通过左孩子有兄弟的表示法转换成了二叉树。有兴趣的同学可以去看一下pachi。
那么,为什么说这种方式能够节省空间呢?大家想想,一个三叉树,他的每个节点都会有三个指针域用于存储他的子树,不管是否有子树,都要预留这些空间,如上面的三叉树,有6个节点,总共有18个指针域,其中有效的指针域只有5个(所谓有效指针域就是指针域不是指向空的,即边的数量=节点数量-1),那么就还有18-5=13个指针是空着的。如果采用左孩子右兄弟的方式转换成二叉树,我们来看看总共有12个指针域,而有效指针域有5个,那么就只有12-5=7个指针域空着,明显比之前的13个节省了大量空间。
一个拥有 n 个节点的 k 叉树,他最多会有 k*n 条边,他的边实际上只有 n-1 条,那么他浪费了:k*n - (n-1)=(k-1)*n+1条边,这就意味着,当我们分叉越多,我们浪费的空间就会越多,所以,我们要把k叉树转换成二叉树,因为二叉树浪费的边为:n+1,只跟我们实际存储数据的节点有关。
四、结语
ydtech
到了这里,我们关于二叉树的一些基础知识就聊的差不多了,为了控制篇幅以及不同基础的小伙伴的接受程度,就不再展开更深的讨论了。本来还要跟大家一起刷一刷关于二叉树的算法题巩固一下二叉树的一些相关知识的,不过这样就会导致这篇文章又臭又长,所以,还是把它拆分成两篇文章吧。下一篇文章将会直接跳过树的基础,直接开撸二叉树算法题。敬请期待。