图解Kafka线程模型及其设计缺陷
采用何种线程交互模型,如何高效率的提高网络处理能力是面向网络编程中一个非常重要的议题。
深入研究Kafka Broker服务端线程模型也是理解Kafka工作机制必备不可少的一环。
本文的探讨主要分成如下三个部分:
- 网络相关配置参数
- 图解线程模型工作机制
- 对Kafka线程模型的一点思考
1、网络相关的配置参数
Kafka Broker端与网络相关的线程主要被分成network、IO两类线程,与之对应的是Kafka分别提供了两个参数用来设置其线程个数,分别如下:
- num.network.threads 网络线程的个数,默认值为3。
- num.io.threads IO线程的个数,默认值为8。
那什么是网络线程,什么又是IO线程呢?请带着上述疑问,进入本文的学习交流中来。
2、线程模型探究
笔者崇尚“眼见为实”,故喜欢对其源码进行分析,从而提炼总结,故本文的探究手段还是以源码阅读为主,同时为了提高可读性,将提炼各种流程图。
理解上述几个参数的含义,通常运用的手段是查看这些参数的调用链,根据上下文进行理解与分析。
num.io.threads参数的使用调用链如下图所示:
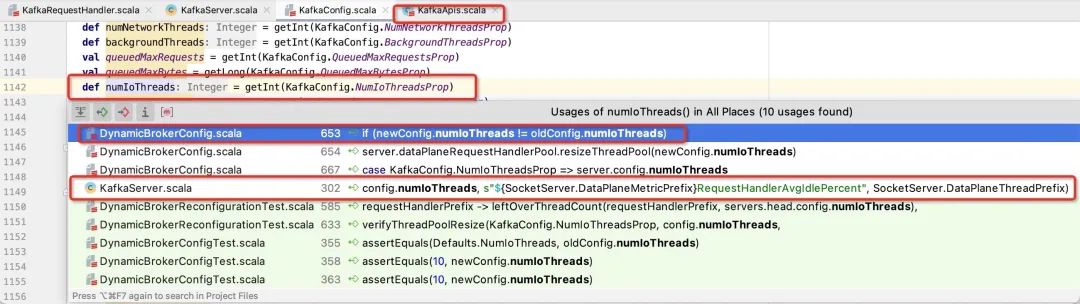
- Network、IO线程相关的参数支持动态修改
- Network、IO线程相关参数使用者是KafkaServer。
接下来将目光锁定在KafkaServer上。
2.1 IO线程工作机制
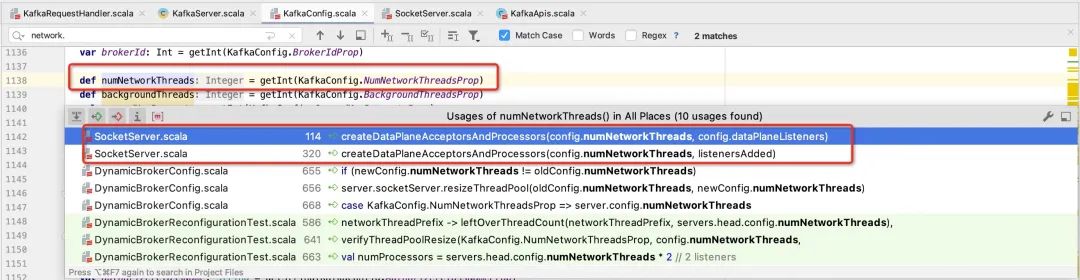
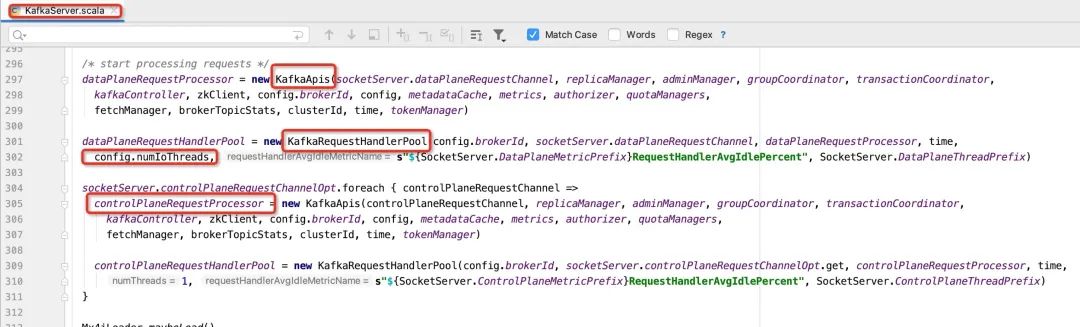
从上文的调用栈,我们不难找到使用num.io.threads的具体使用代码如下图所示:
-
KafkaApis主要定义各个请求的处理逻辑,例如消息发送、消息拉取、位点提交等具体实现逻辑,其具体可以参考如下代码:
-
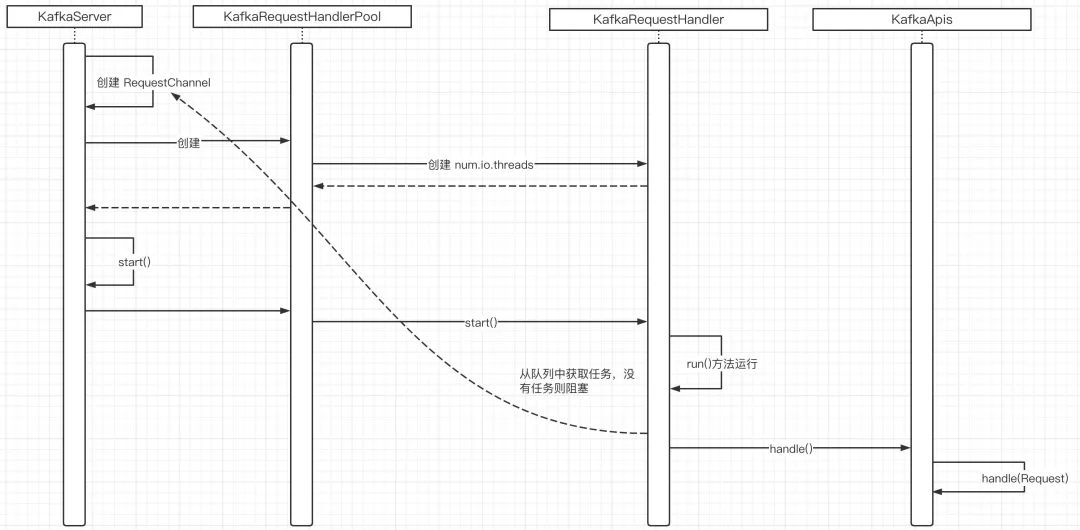
引入KafkaRequestHandlerPool(IO线程池),里面持有的线程个数由num.io.threads决定。
-
KafkaRequestHandlerPool内部持有一个线程池,每一个线程的行为由KafkaRequestHandler类定义,即可以称KafkaRequestHandler为IO线程,并且由KafkaRequestHandler来调用KafkaApis中的具体实现,其代码如下所示:
温馨提示:KafkaRequestHandler的实现非常简单,主要是从RequestChannel(处理队列中)获取请求并执行之,这里在稍后会重点介绍关于IO线程执行相关的监控指标(IO线程空闲率)。
-
一个KafkaRequestHandlerPool线程池拥有一个RequestChannel**(请求待处理队列)**,并创建KafkaRequestHandler,代码如下所示:
指的注意的是在Kafka中,IO线程名的命名规则:“data-plane-kafka-request-handler-” + {brokerId} + "-" + 序号。
-
Kafka在2.2版本开始引入了控制面与数据面概念,用以区分不同的请求,稍后在第三部分还会重点介绍。
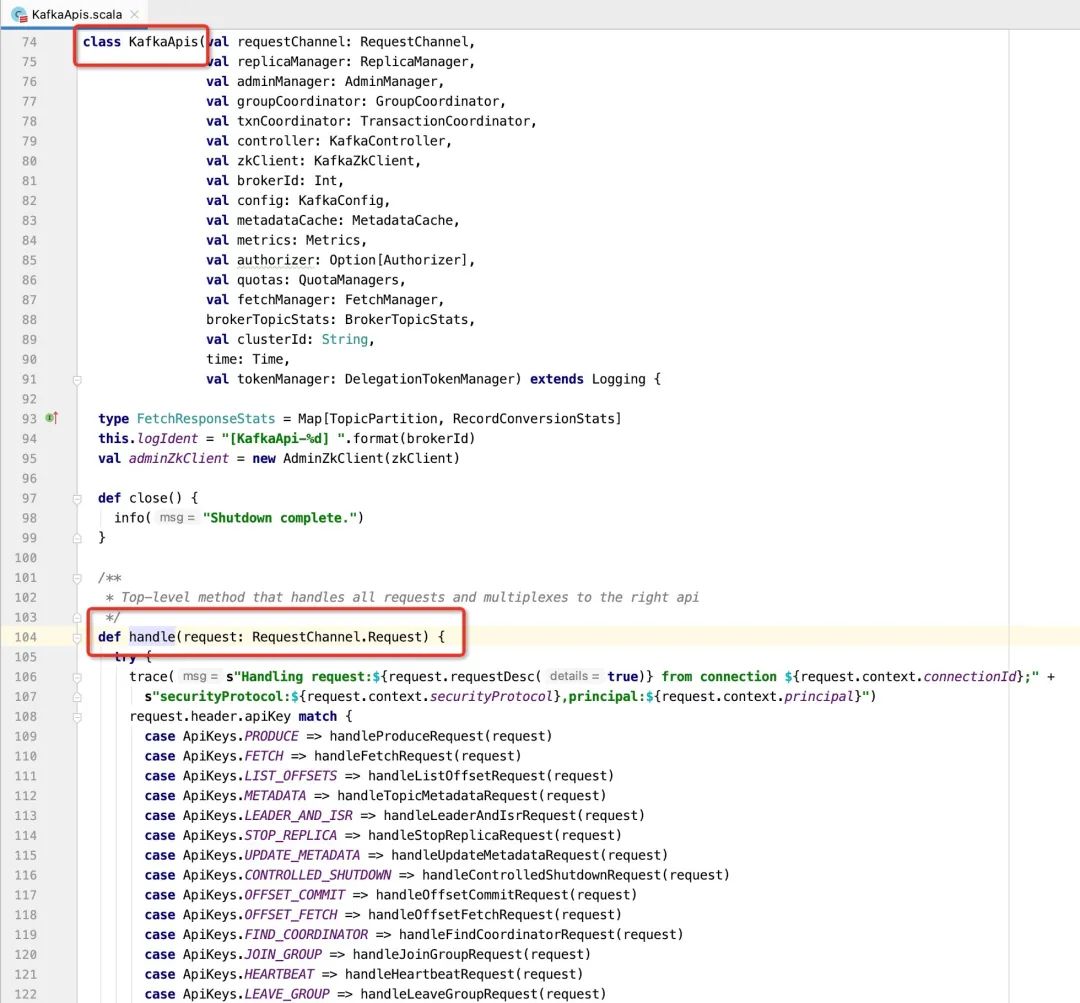
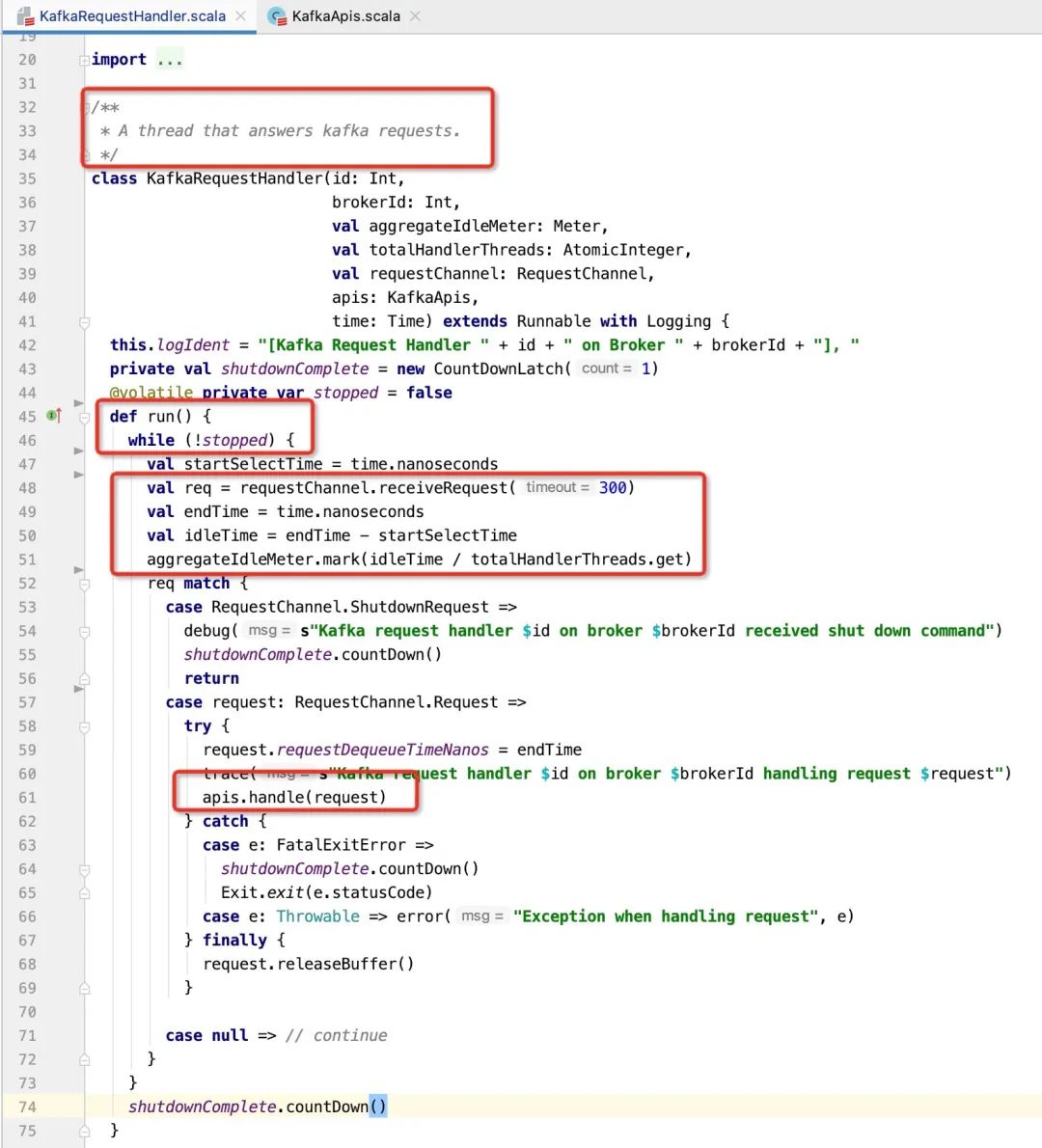
通过对上述代码进行解读,我想不难得出如下时序图:
2.2 NetWork线程工作机制
network线程的初始化代码在SocketServer的createDataPlaneAcceptorsAndProcessors方法,详情如下图所示:

-
介绍该方法之前先介绍该方法的两个参数的含义:
-
int dataProcessorsPerListener 网络处理线程的个数,取自 num.network.threads。
-
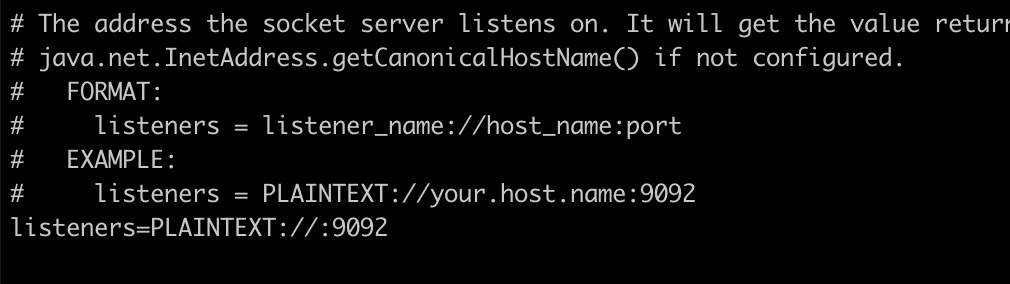
Seq[EndPoint] endpoints kafka设置的endpoint,其实就配置在Kafka server中的listeners,如下图所示:
-
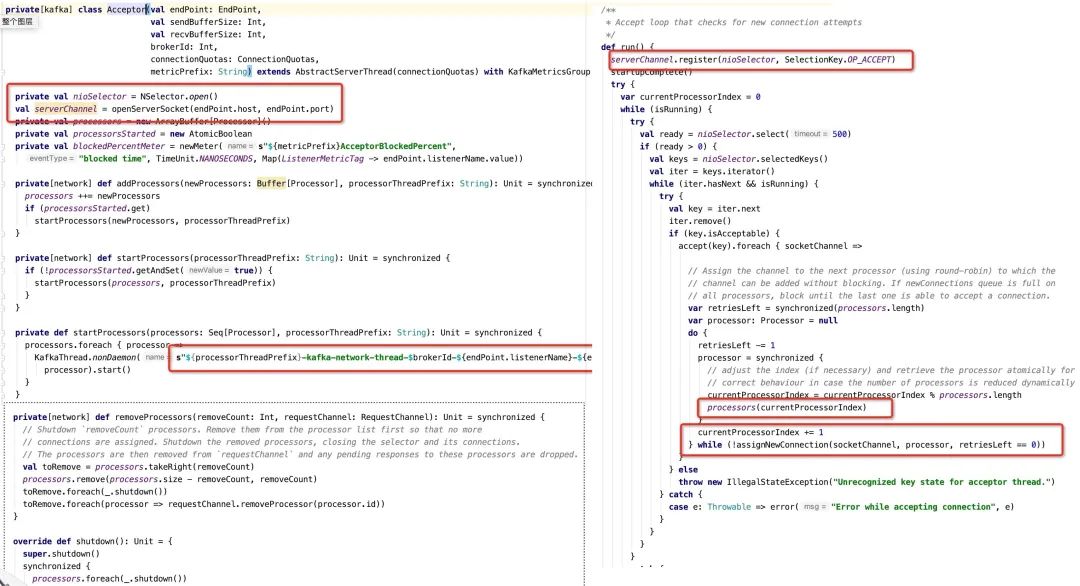
根据kafka endpoint创建Acceptor。所谓的Kafka endpoint指的就是配置的listeners,即监听的端口与协议,Kafka支持多协议多端口监听,可充分利用宿主机的网卡进行分流,Kafka的网络模型是真正的主从多Reactor模型,支持多个Acceptor。Acceptor线程的命名规则:data-plane-kafka-socket-acceptor-{listeners-name}-{securityProtocol}-port,其中securityProtocol指的是url冒号之前的字符串,例如 PLAINTEXT。
Acceptor的主要职责:监听OP_ACCEPT事件,接受链接并将其转发给NetWork线程处理。
-
通过调用addDataPlaneProcessors方法为每一个Acceptor创建num.network.threads个处理线程,用来处理网络的读写事件,即负责从网络中解码出Request、将响应结果写入到客户端,每一个网络线程的命名规则为:data-plane(数据面)||control-plane(控制面)"--kafka-network-thread-{brokerId}-{endPoint.listenerName}-{endPoint.securityProtocol}-{processor.id}。
-
每一个NetWork线程对应一个Processor对象,其核心代码示例如下:
网络线程从网络中解析到请求后放入RequestChannel,从而供IO线程获取并处理。
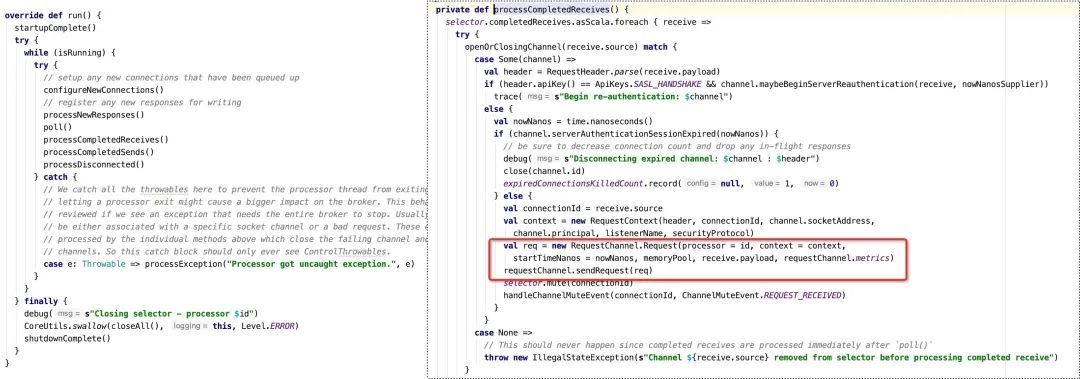
为了方便大家理解,同样给出工作的顺序图如下:
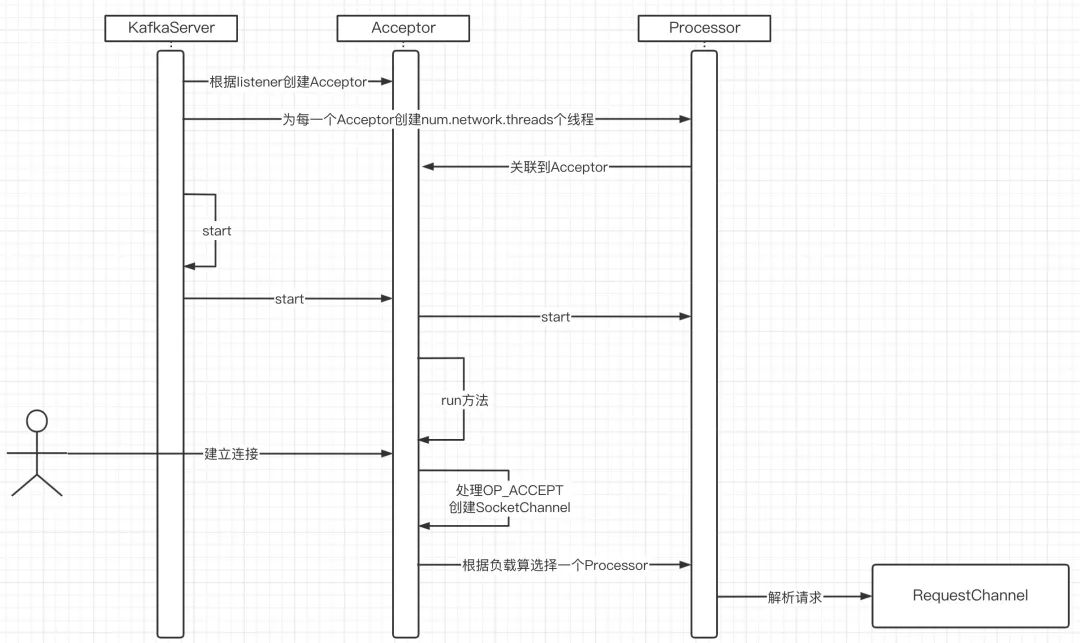
2.3 图解Kafka线程模型
源码讲解确实比较抽象,接下来结合笔者对源码的阅读,总结提炼出Kafka线程模型如下图所示:
-
Kafka可以根据listener的数量,创建对应的Acceptor,实现多Acceptor。
-
Acceptor的职责就是处理OP_ACCEPT事件,即接受客户端的连接,连接建立成功后将其转发给Procesor线程。
-
Processor线程,在Kafka中称之为网络线程(network),主要负责网络的读写。
-
network需要处理OP_READ、OP_WRITE事件。
-
OP_READ事件主要是将从客户端发送端服务端的二进制流解码成一个个独立的请求,丢到全局请求队列(RequestChannel)。
-
当Kafka的IO线程处理完一个请求后,会将该请求转发到解码这个请求的Processor(network)线程中去返回给客户端。
-
Kafka IO线程从全局请求队列中获取任务,并调用KafkaApis中相关的方法完成对应的逻辑处理,并将响应结果发送给Netwok线程,从而完成一次任务的执行。
3、关于线程模型的一点思考
我们再次来总结一下Kafka线程模型中的几类线程(类比主从多Reactor模型):
-
kafka-socket-acceptor 对标主从多Reactor模型中的Main-Reactor,主要负责连接事件的建立(OP_ACCEPT)。
-
kafka-network-thread 对比主从多Reactor模型中的Sub-Reactor,主要负责网络的读写。
备注:如果大家看过我以前分析RocketMQ、Netty等框架的网络模型,他们对这类线程的称呼为IO线程,我也倾向于这种称呼,因为它是调用底层的IO API进行网络的读写。
-
kafka-request-handler 类比主从多Reactor模型中的业务线程池,因为该线程池的职责也是对每一个具体的请求进行逻辑响应,但在Kafka中被称之为IO线程。
备注:命名本身没有对错,但让我们容易想当然的认为Kafka的IO线程是处理网络读写的,如果我们要深入了解一款开源框架底层的运作机制,阅读源码是一个非常不错的方式,因为眼见为实嘛。
Kafka的线程模型毫无疑问采取的是网络编程领域最经典的主从多Reactor模型,但个人觉得上述实现存在一个比较大的缺陷:业务线程隔离性不足,换句话说就是请求无优先级,容易相互影响。
然后值得关注的是在Kafka2.2版本中引入来数据面、控制面的概念,用来隔离kafka内部的控制命令与数据命令:
-
控制面 kafka集群内部的controller发送给Broker节点的命令,主要包含如下几个命令:
-
LEADER_AND_ISR 分区Leader发生和ISR发生变化。
-
STOP_REPLICA 停止复制。
-
UPDATE_METADATA
向从各个Broker同步元数据。
-
数据面 除上述3个命令之外的其他命令。
但笔者觉得上述隔离程度远远不够,就拿客户端心跳包请求、数据拉取请求来说,如果多个消费组都去消费过早的数据,导致pagecache未命中,需要从磁盘加载数据,读磁盘如果出现瓶颈,会导致客户端端心跳请求无法及时处理,Broker在10s内没有收到(准确来讲是10s内没有触发心跳包处理流程),将导致消费组由于心跳超时而被Broker标记为宕机,从而触发重平衡,导致消费组无法消费,并且容易造成雪崩,该集群中所有消费组全部不可消费,其影响可想而知。
在这里不得不和RocketMQ来做一个横向对比,RocketMQ的线程处理模型就支持不同的命令类型使用不同的线程池,消息发送处理线程池、消息拉取线程池就分别拥有独立的线程池,起到了线程资源隔离的效果,不至于由于一类请求处理缓慢而导致其他更加重要的命令处于饥饿停滞不前,造成不可估量的后果。