线上问题复盘,JVM Fast Throw 的故事
首先,这是一个 悲伤的故事,涉及到JVM 底层优化的知识点。想到第一次碰到这种问题时的懵逼,应了句老话:书到用时方恨少!
负责的消息中台在 晚上八点左右,运维群里反馈大量用户接收不到短信消息。登陆 Kibana 查找对应的 Error 日志,发现出现了 大量的下标越界异常
当时更...,线上问题得到了修复。但是,出现问题可不得找到问题的产出原因,不然下次有可能还会出现
因为在 ELK 上进行 日志分析不太方便,难以根据对应异常进行不同纬度上的统计分析,所以联系运维同学将故障产生当天的 Info、Error 日志 拉下来进行线下分析
经过日志分析得知,异常的产出有两种,一种是有堆栈信息,比如:
java.lang.ArrayIndexOutOfBoundsException: -1
... 省略堆栈信息另外一种,就比较诡异,只有异常,没有对应的堆栈信息
java.lang.ArrayIndexOutOfBoundsException: null
第一种问题比较好定位,根据 异常堆栈信息,定位到了具体代码,直接进行了修复,难就难在第二种
其实这两个是一个异常,往后看小伙伴就明白了。后面做的所有事情,都是为了搞清楚两件事情
- 为什么异常 message 会输出 null
- 为什么堆栈信息没有输出打印
JVM Fast Throw
什么是 Fast Throw?
大白话一点来说,就是:当一些异常类型(空指针、下标越界、算术运算等...)在代码里的固定位置被抛出多次,虚拟机(HotSpot VM)会直接 抛出一个事先分配好、类型匹配的异常对象。此异常对象的 message 和 stack trace 都为空
看到这里相信读者朋友已经明白了为什么同一种异常,打印出来的日志却是不一样内容 了吧。就是因为某一个异常在同一个地方多次被抛出,JVM 抛出一个预分配异常,那么 message、stack trace 相当于被吞掉了
The compiler in the server VM now provides correct stack backtraces for all "cold" built-in exceptions. For performance purposes, when such an exception is thrown a few times, the method may be recompiled. After recompilation, the compiler may choose a faster tactic using preallocated exceptions that do not provide a stack trace. To disable completely the use of preallocated exceptions, use this new flag: -XX:-OmitStackTraceInFastThrow.
JDK 1.5 的发布文档介绍中描述了此情况,出现这种优化方案的原因是 为了提高性能。当同一种异常在相同的位置被抛出多次,编译器就会重新编译此方法。重编译后,编译器可能会 使用不提供堆栈跟踪的预分配异常 来选择更快的策略
如果想要关闭这种预分配异常的机制,可以使用 -XX:-OmitStackTraceInFastThrow。感兴趣的读者朋友可以看一下发布说明:https://sourl.cn/PMzVkC
另外通过 JVM 的源码得知,Fast Throw 机制目前支持五种异常情况,截图如下
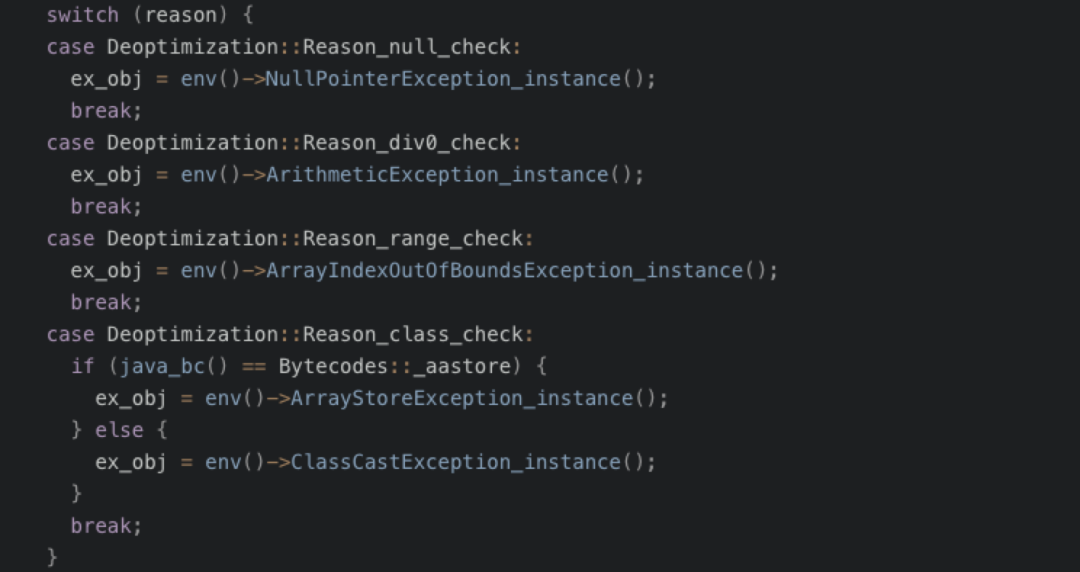
模拟 Fast Throw
上面说的都是理论部分,这个章节使用代码来实战下
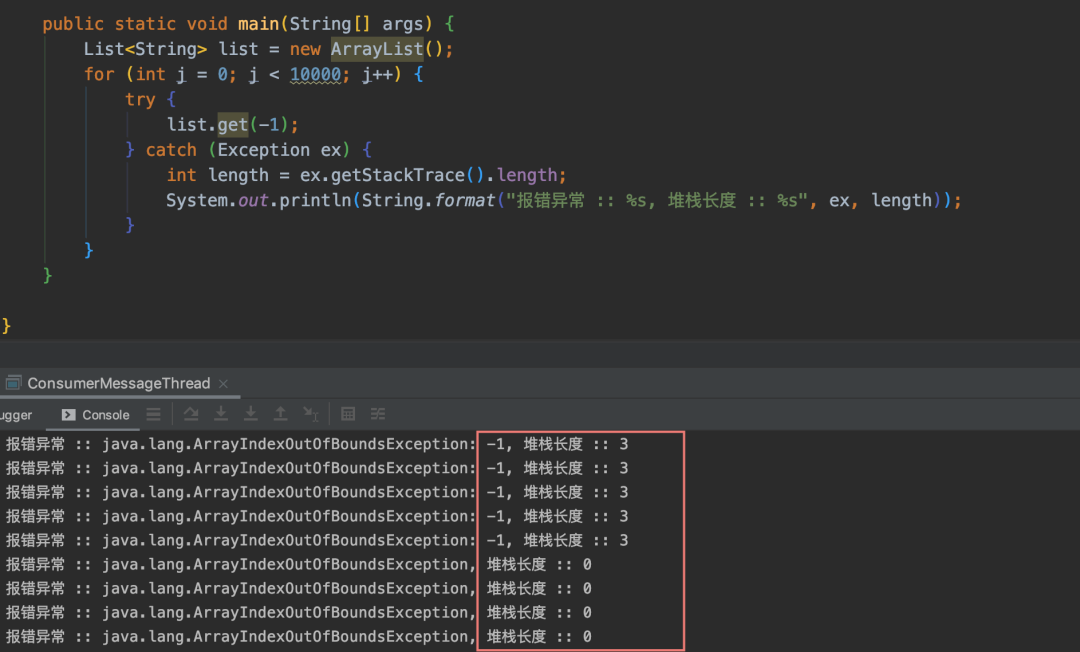
List<String> list = new ArrayList();
for (int j = 0; j < 10000; j++) {
try {
list.get(-1);
} catch (Exception ex) {
int length = ex.getStackTrace().length;
System.out.println(String.format("报错异常 :: %s, 堆栈长度 :: %s", ex, length));
}
}上面程序跑在了 Java8 的环境中,通过运行程序结果可以看出来,Fast Throw 在 Java 8 中依然生效
| 开启 Fast Throw | 关闭 Fast Throw | |
|---|---|---|
| 10w | 1004ms | 3547ms |
| 100 w | 6193ms | 30928ms |
| 500w | 37492ms | ... |
如果线上环境触发了 Fast Throw 机制,可以通过 向前追溯相同位置、相同异常的日志 来定位问题的产出原因
结言
千言万语汇成一句话就是,重构有风险,上线需谨慎
针对公共功能的重构,需要包含全量的测试用例,要将问题的产出背景考虑到 极致,亦或者和身边同事说明需求背景,大家一起想下,可以极大程度避免极端问题的产出
必要的压力测试 是很重要的,这一点可以很好的将 流量大才能显现的问题 提前暴露出来
故障的产生带来的意义,有好有坏,坏的点大家都懂得;好的点自然是 积累了线上问题故障排查的经验,这样的话,后面公司妹子再遇到相同的问题,大喊一声:妹子,放开那 BUG,让我来!