1.1w字,10图彻底掌握阻塞队列(并发必备)

什么是队列
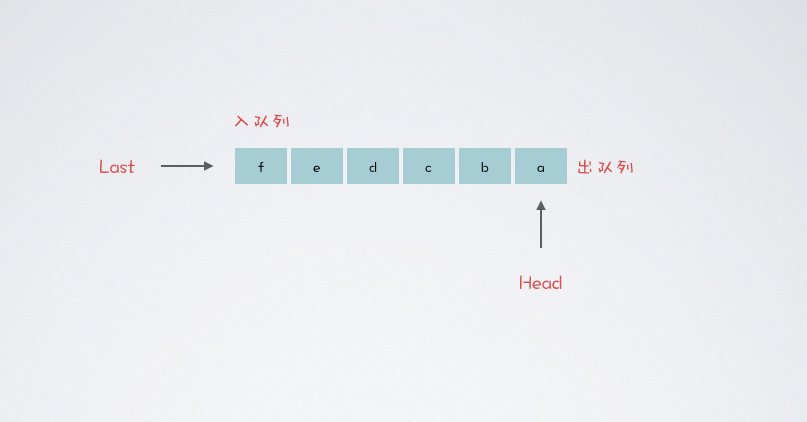
队列是一种 先进先出的特殊线性表,简称 FIFO。特殊之处在于只允许在一端插入,在另一端删除
进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列
什么是阻塞队列
队列就队列呗,阻塞队列又是什么鬼

- 支持阻塞的插入方法:队列容量满时,插入元素线程会被阻塞,直到队列有多余容量为止
- 支持阻塞的移除方法:当队列中无元素时,移除元素的线程会被阻塞,直到队列有元素可被移除
文章以 LinkedBlockingQueue 为例,讲述队列之间实现的不同点,为方便小伙伴阅读,LinkedBlockingQueue 取别名 LBQ
因为是源码解析文章,建议小伙伴们在 PC 端观看。当然,如果屏足够大当我没说~
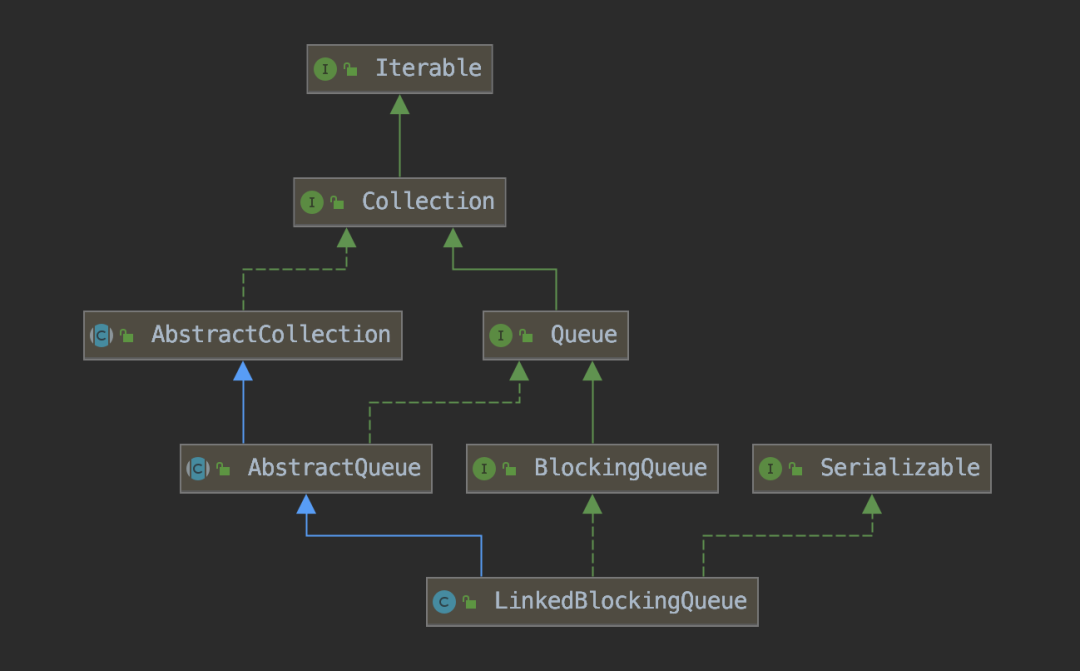
阻塞队列继承关系
阻塞队列是一个抽象的叫法,阻塞队列底层数据结构 可以是数组,可以是单向链表,亦或者是双向链表...
LBQ 是一个以 单向链表组成的队列,下图为 LBQ 上下继承关系图
Queue 接口分析
我们以自上而下的方式,先分析一波 Queue 接口里都定义了哪些方法
// 如果队列容量允许,立即将元素插入队列,成功后返回
// 如果队列容量已满,则抛出异常
boolean add(E e);
// 如果队列容量允许,立即将元素插入队列,成功后返回
// 如果队列容量已满,则返回 false
// 当使用有界队列时,offer 比 add 方法更何时
boolean offer(E e);
// 检索并删除队列的头节点,返回值为删除的队列头节点
// 如果队列为空则抛出异常
E remove();
// 检索并删除队列的头节点,返回值为删除的队列头节点
// 如果队列为空则返回 null
E poll();
// 检查但不删除队列头节点
// 如果队列为空则抛出异常
E element();
// 检查但不删除队列头节点
// 如果队列为空则返回 null
E peek();总结一下 Queue 接口的方法,分为三个大类:
- 新增元素到队列容器中:add、offer
- 从队列容器中移除元素:remove、poll
- 查询队列头节点是否为空:element、peek
从接口 API 的程序健壮性考虑,可以分为两大类:
- 健壮 API:offer、poll、peek
- 非健壮 API:add、remove、element
接口 API 并无健壮可言,这里说的健壮界限指得是,使用了非健壮性的 API 接口,程序会出错的几率大了点,所以我们 更应该关注的是如何捕获可能出现的异常,以及对应异常处理
BlockingQueue 接口分析
BlockingQueue 接口继承自 Queue 接口,所以有些语义相同的 API 接口就没有放上来解读
// 将指定元素插入队列,如果队列已满,等待直到有空间可用;通过 throws 异常得知,可在等待时打断
// 相对于 Queue 接口而言,是一个全新的方法
void put(E e) throws InterruptedException;
// 将指定元素插入队列,如果队列已满,在等待指定的时间内等待腾出空间;通过 throws 异常得知,可在等待时打断
// 相当于是 offer(E e) 的扩展方法
boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException;
// 检索并除去此队列的头节点,如有必要,等待直到元素可用;通过 throws 异常得知,可在等待时打断
E take() throws InterruptedException;
// 检索并删除此队列的头,如果有必要使元素可用,则等待指定的等待时间;通过 throws 异常得知,可在等待时打断
// 相当于是 poll() 的扩展方法
E poll(long timeout, TimeUnit unit) throws InterruptedException;
// 返回队列剩余容量,如果为无界队列,返回 Integer.MAX_VALUE
int remainingCapacity();
// 如果此队列包含指定的元素,则返回 true
public boolean contains(Object o);
// 从此队列中删除所有可用元素,并将它们添加到给定的集合中
int drainTo(Collection<? super E> c);
// 从此队列中最多移除给定数量的可用元素,并将它们添加到给定的集合中
int drainTo(Collection<? super E> c, int maxElements);可以看到 BlockingQueue 接口中个性化的方法还是挺多的。本文的猪脚 LBQ 就是实现自 BlockingQueue 接口
源码解析
变量分析
LBQ 为了保证并发添加、移除等操作,使用了 JUC 包下的 ReentrantLock、Condition 控制
// take, poll 等移除操作需要持有的锁
private final ReentrantLock takeLock = new ReentrantLock();
// 当队列没有数据时,删除元素线程被挂起
private final Condition notEmpty = takeLock.newCondition();
// put, offer 等新增操作需要持有的锁
private final ReentrantLock putLock = new ReentrantLock();
// 当队列为空时,添加元素线程被挂起
private final Condition notFull = putLock.newCondition();ArrayBlockingQueue(ABQ)内部元素个数字段为什么使用的是 int 类型的 count 变量?不担心并发么
- 因为 ABQ 内部使用的一把锁控制入队、出队操作,同一时刻只会有单线程执行 count 变量修改
- LBQ 使用的两把锁,所以会出现两个线程同时修改 count 数值,如果像 ABQ 使用 int 类型,两个流程同时执行修改 count 个数,会造成数据不准确,所以需要使用并发原子类修饰
接下来从结构体入手,知道它是由什么元素组成,每个元素是做啥使的。如果数据结构还不错的小伙伴,应该可以猜出来
// 绑定的容量,如果无界,则为 Integer.MAX_VALUE
private final int capacity;
// 当前队列中元素个数
private final AtomicInteger count = new AtomicInteger();
// 当前队列的头节点
transient Node<E> head;
// 当前队列的尾节点
private transient Node<E> last;看到 head 和 last 元素,是不是对 LBQ 就有个大致的雏形了,这个时候还差一个结构体 Node
static class Node<E> {
// 节点存储的元素
E item;
// 当前节点的后继节点
LinkedBlockingQueue.Node<E> next;
Node(E x) { item = x; }
}构造器分析
这里画一张图来理解下 LBQ 默认构造方法是如何初始化队列的
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}可以看出,默认构造方法会将容量设置为 Integer.MAX_VALUE,也就是大家常说的无界队列
内部其实调用的是重载的有参构造,方法内部设置了容量大小,以及初始化了 item 为空的 Node 节点,把 head last 两节点进行一个关联

节点入队
需要添加的元素会被封装为 Node 添加到队列中, put 入队方法语义,如果队列元素已满,阻塞当前插入线程,直到队列中有空缺位置被唤醒
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node<E>(e); // 将需要添加的数据封装为 Node
final ReentrantLock putLock = this.putLock; // 获取添加操作的锁
final AtomicInteger count = this.count; // 获取队列实际元素数量
putLock.lockInterruptibly(); // 运行可被中断加锁 API
try {
while (count.get() == capacity) { // 如果队列元素数量 == 队列最大值,则将线程放入条件队列阻塞
notFull.await();
}
enqueue(node); // 执行入队流程
c = count.getAndIncrement(); // 获取值并且自增,举例:count = 0,执行后结果值 count+1 = 2,返回 0
if (c + 1 < capacity) // 如果自增过的队列元素 +1 小于队列容器最大数量,唤醒一条被阻塞在插入等待队列的线程
notFull.signal();
} finally {
putLock.unlock(); // 解锁操作
}
if (c == 0) // 当队列中有一条数据,则唤醒消费组线程进行消费
signalNotEmpty();
}入队方法整体流程比较清晰,做了以下几件事:
- 队列已满,则将当前线程阻塞
- 队列中如果有空缺位置,将数据封装的 Node 执行入队操作
- 如果 Node 执行入队操作后,队列还有空余位置,则唤醒等待队列中的添加线程
- 如果数据入队前队列没有元素,入队成功后唤醒消费阻塞队列中的线程
继续看一下入队方法 LBQ#enqueue 都做了什么操作
private void enqueue(Node<E> node) {
last = last.next = node;
}代码比较简单,先把 node 赋值为当前 last 节点的 next 属性,然后再把 last 节点指向 node,就完成了节点入队操作
假设 LBQ 的范型是 String 字符串,首先插入元素 a,队列如下图所示:
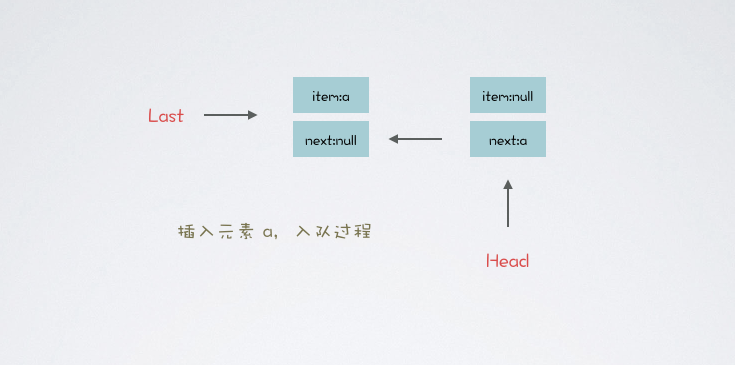
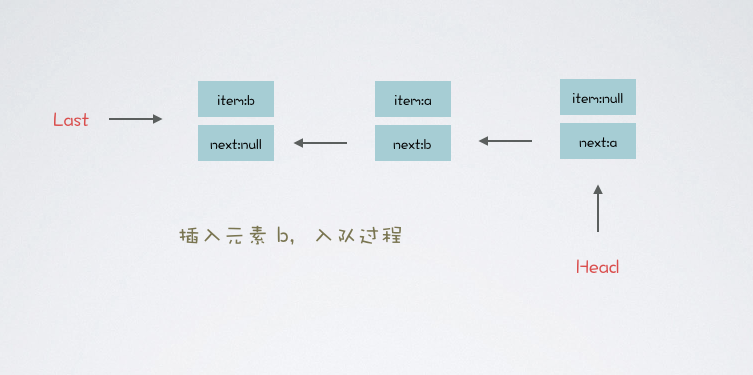
LBQ#offer 也是入队方法,不同的是:如果队列元素已满,则直接返回 false,不阻塞线程
节点出队
LBQ#take 出队方法,如果队列中元素为空,阻塞当前出队线程,直到队列中有元素为止
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count; // 获取当前队列实际元素个数
final ReentrantLock takeLock = this.takeLtakeLocock; // 获取 takeLock 锁实例
takeLock.lockInterruptibly(); // 获取 takeLock 锁,获取不到阻塞过程中,可被中断
try {
while (count.get() == 0) { // 如果当前队列元素 == 0,当前获取节点线程加入等待队列
notEmpty.await();
}
x = dequeue(); // 当前队列元素 > 0,执行头节点出队操作
c = count.getAndDecrement(); // 获取当前队列元素个数,并将数量 - 1
if (c > 1) // 当队列中还有还有元素时,唤醒下一个消费线程进行消费
notEmpty.signal();
} finally {
takeLock.unlock(); // 释放锁
}
if (c == capacity) // 移除元素之前队列是满的,唤醒生产者线程添加元素
signalNotFull();
return x; // 返回头节点
}出队操作整体流程清晰明了,和入队操作执行流程相似
- 队列已满,则将当前出队线程阻塞
- 队列中如果有元素可消费,执行节点出队操作
- 如果节点出队后,队列中还有可出队元素,则唤醒等待队列中的出队线程
- 如果移除元素之前队列是满的,唤醒生产者线程添加元素
LBQ#dequeue 出队操作相对于入队操作稍显复杂一些
private E dequeue() {
Node<E> h = head; // 获取队列头节点
Node<E> first = h.next; // 获取头节点的后继节点
h.next = h; // help GC
head = first; // 相当于把头节点的后继节点,设置为新的头节点
E x = first.item; // 获取到新的头节点 item
first.item = null; // 因为头节点 item 为空,所以 item 赋值为 null
return x;
}出队流程中,会将原头节点自己指向自己本身,这么做是为了帮助 GC 回收当前节点,接着将原 head 的 next 节点设置为新的 head,下图为一个完整的出队流程

LBQ#poll 出队方法,如果队列中元素为空,返回 null,不会像 take 一样阻塞
节点查询
因为 element 查找方法在父类 AbstractQueue 里实现的,LBQ 里只对 peek 方法进行了实现,节点查询就用 peek 做代表了
peek 和 element 都是获取队列头节点数据,两者的区别是,前者如果队列为空返回 null,后者抛出相关异常
public E peek() {
if (count.get() == 0) // 队列为空返回 null
return null;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock(); // 获取锁
try {
LinkedBlockingQueue.Node<E> first = head.next; // 获取头节点的 next 后继节点
if (first == null) // 如果后继节点为空,返回 null,否则返回后继节点的 item
return null;
else
return first.item;
} finally {
takeLock.unlock(); // 解锁
}
}看到这里,能够得到结论,虽然 head 节点 item 永远为 null,但是 peek 方法获取的是 head.next 节点 item
节点删除
删除操作需要获得两把锁,所以关于获取节点、节点出队、节点入队等操作都会被阻塞
public boolean remove(Object o) {
if (o == null) return false;
fullyLock(); // 获取两把锁
try {
// 从头节点开始,循环遍历队列
for (Node<E> trail = head, p = trail.next;
p != null;
trail = p, p = p.next) {
if (o.equals(p.item)) { // item == o 执行删除操作
unlink(p, trail); // 删除操作
return true;
}
}
return false;
} finally {
fullyUnlock(); // 释放两把锁
}
}链表删除操作,一般而言都是循环逐条遍历,而这种的 遍历时间复杂度为 O(n),最坏情况就是遍历了链表全部节点
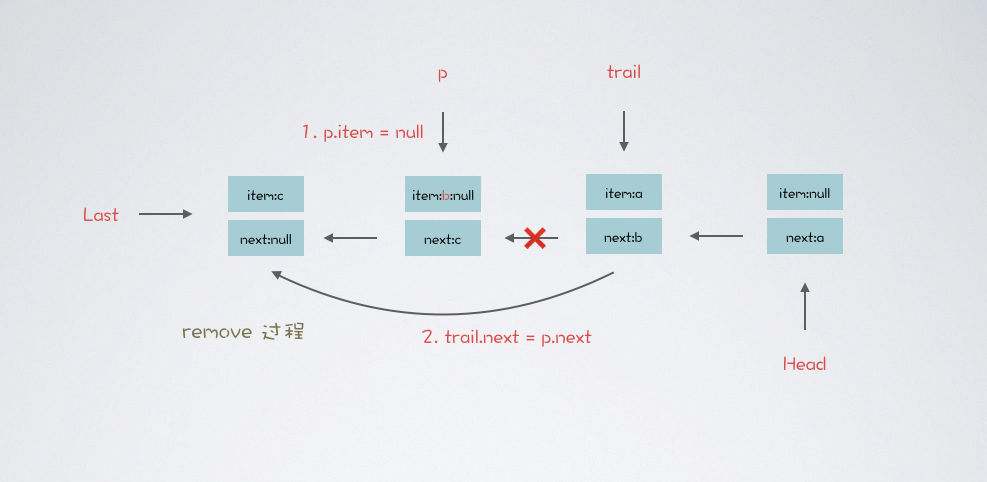
看一下 LBQ#remove 中 unlink 是如何取消节点关联的
void unlink(Node<E> p, Node<E> trail) {
p.item = null; // 以第一次遍历而言,trail 是头节点,p 为头节点的后继节点
trail.next = p.next; // 把头节点的后继指针,设置为 p 节点的后继指针
if (last == p) // 如果 p == last 设置 last == trail
last = trail;
// 如果删除元素前队列是满的,删除后就有了空余位置,唤醒生产线程
if (count.getAndDecrement() == capacity)
notFull.signal();
}remove 方法和 take 方法是有相似之处,如果 remove 方法的元素是头节点,效果和 take 一致,头节点元素出队
为了更好的理解,我们删除中间元素。画两张图理解下其中原委,代码如下:
public static void main(String[] args) {
BlockingQueue<String> blockingQueue = new LinkedBlockingQueue();
blockingQueue.offer("a");
blockingQueue.offer("b");
blockingQueue.offer("c");
// 删除队列中间元素
blockingQueue.remove("b");
}执行完上述代码中三个 offer 操作,队列结构图如下:
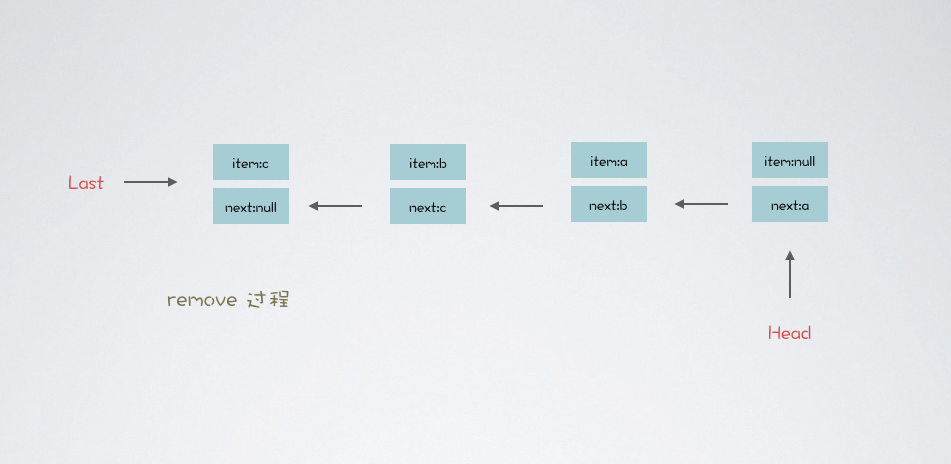
应用场景
上文说了阻塞队列被大量业务场景所应用,这里例举两个实际工作中的例子帮助大家理解
生产者-消费者模式
生产者-消费者模式是一个典型的多线程并发写作模式,生产者和消费者中间需要一个容器来解决强耦合关系,生产者向容器放数据,消费者消费容器数据
生产者-消费者实现有多种方式
- Object 类中的 wait、notify、notifyAll
- Lock 中 Condition 的 await、signal、signalAll
- BlockingQueue
阻塞队列实现生产者-消费者模型代码如下:
@Slf4j
public class BlockingQueueTest {
private static final int MAX_NUM = 10;
private static final BlockingQueue<String> QUEUE = new LinkedBlockingQueue<>(MAX_NUM);
public void produce(String str) {
try {
QUEUE.put(str);
log.info(" 队列放入元素 :: {}, 队列元素数量 :: {}", str, QUEUE.size());
} catch (InterruptedException ie) {
// ignore
}
}
public String consume() {
String str = null;
try {
str = QUEUE.take();
log.info(" 队列移出元素 :: {}, 队列元素数量 :: {}", str, QUEUE.size());
} catch (InterruptedException ie) {
// ignore
}
return str;
}
public static void main(String[] args) {
BlockingQueueTest queueTest = new BlockingQueueTest();
for (int i = 0; i < 5; i++) {
int finalI = i;
new Thread(() -> {
String str = "元素-";
while (true) {
queueTest.produce(str + finalI);
}
}).start();
}
for (int i = 0; i < 5; i++) {
new Thread(() -> {
while (true) {
queueTest.consume();
}
}).start();
}
}
}线程池应用
阻塞队列在线程池中的具体应用属于是生产者-消费者的实际场景
线程池在 Java 应用里的重要性不言而喻,这里简要说下线程池的运行原理
- 线程池线程数量小于核心线程数执行新增核心线程操作
- 线程池线程数量大于或等于核心线程数时,将任务存放阻塞队列
- 满足线程池中线程数大于或等于核心线程数并且阻塞队列已满, 线程池创建非核心线程
重点在于第二点,当线程池核心线程都在运行任务时,会把任务存放阻塞队列中。线程池源码如下:
if (isRunning(c) && workQueue.offer(command)) {}
看到使用的 offer 方法,通过上面讲述,如果阻塞队列已满返回 false。那何时进行消费队列中的元素呢。涉及线程池中线程执行过程原理,这里简单说明
- 线程池内线程执行任务有两种方式,一种是创建核心线程时 自带 的任务,另一种就是从阻塞队列获取
- 当核心线程执行一次任务后,其实和非核心线程就没什么区别了
线程池获取阻塞队列任务使用了两种 API,分别是 poll 和 take
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
Q:为啥要用两个 API?一个不香么?
A:take 是为了要维护线程池内核心线程的重要手段,如果获取不到任务,线程被挂起,等待下一次任务添加
至于带时间的 pool 则是为了回收非核心线程准备的
结言
LBQ 阻塞队列到这里就讲解完成了,总结下文章所讲述的 LBQ 基本特征
- LBQ 是基于链表实现的阻塞队列,可以进行读写并发执行
- LBQ 队列容量可以自己设置,如果不设置默认 Integer 最大值,也可以称为无界队列
文章结合源码,针对 LBQ 的入队、出队、查询、删除等操作进行了详细讲解
LBQ 只是一个引子,更希望大家能够通过文章 掌握阻塞队列核心思想,继而查看其它实现类的代码,巩固知识
小伙伴现在已经知道 LBQ 是通过锁的机制来实现并发安全控制,思考一下 不使用锁,能否实现以及如何实现?我们下期再见!