云原生 etcd 系列|快照技术是什么?
坚持思考,就会很酷

什么是快照?
快照是存储系统中一个非常重要的功能。快照的英文名:Snapshot 。SNIA( 存储网络行业协会 )对此的定义是:关于指定数据集合的一个完全可用拷贝,该拷贝包括相应数据在某个时间点(拷贝开始的时间点)的映像。
大白话:就是某个时刻的数据镜像。这跟照相一样,数据打了一个快照之后,这一时刻的数据就是快照数据。
快照和时间点对应,所以快照是不能变的,因为历史不能改变,变了的话就不是快照了。
先看个 etcd 内部的例子,直观感受下它的快照是什么一个样子。
Etcd raftexample 的 快照
raftexample 实现的是一个极简的 kv 存储,基于 raft 的分布式 kv 系统。对于 raft 状态机来说,快照的生成需要业务自己实现。那 raftexample 是怎么生成的呢?
在 main 函数中,有这么一行代码:
getSnapshot := func() ([]byte, error) { return kvs.getSnapshot() }
其中 getSnapshot 的实现极其简单:
func (s *kvstore) getSnapshot() ([]byte, error) {
s.mu.RLock()
defer s.mu.RUnlock()
return json.Marshal(s.kvStore)
}这里做的事情非常简单:
- 加锁,所有逻辑在锁内操作;
- 直接对 s.kvStore 这个 map 做序列化,生成一串字节数组;
这生成的字节数组就是快照数据,把这个保存下来,后续反序列化这个字节数组则能得到完整的 map ,也就是恢复这个 kv 的系统数据。
上面的例子有个重要知识点:锁 ,锁的作用是让生成快照的这一段时间数据不变 ( 停服 ),这个很重要。其实在加上锁的那一刻,这个快照的数据就确定了。
恢复快照也很简单:
func (s *kvstore) recoverFromSnapshot(snapshot []byte) error {
// 把数据反序列化出来
if err := json.Unmarshal(snapshot, &store); err != nil {
return err
}
s.mu.Lock()
defer s.mu.Unlock()
// 锁内恢复到系统
s.kvStore = store
return nil
}划重点:最简单的快照的技术就是冻结一切更新操作,快照生成完成之后才放开。
etcdserver 的快照
etcdserver 的快照则是通过 blotdb 来实现的,其实这个内部是用 cow 实现的( cow 后面讲 )。
快照实现的技术
下面深入聊聊通用的快照技术。
究竟怎么才能生成某个时刻的数据镜像呢?
首先,上面提到的停止系统更新( 加锁 )是一种有效的方法,但是这种方法的最大弊端就是要停服,在一些快照生成过慢的系统,巨长的停服时间是无法忍受的。
再思考一个问题,如果产生快照的时间过长,数据一直在变,这种快照又怎么算?
划重点:快照是某个时刻的数据镜像,它是一个时间点的数据。
你 09:00 00:00 按下快照的“快门”,生成快照却需要 30 分钟,那生成出来的快照究竟是怎么样子的呢?
快照只能是:你按下快门的那一刻的数据。 所以,任何快照系统的关键都在于:怎么保留好“按下快门”那一刻系统的数据。
1 极简的栗子,聊聊思路
接下来就聊聊怎么去实现快照?
前面提到,快照的关键在于:怎么保留好“按下快门”那一刻系统的数据。 这个很容易想到解决方案,还能怎么保留?
拷贝嘛。把原来的数据拷贝出来,放好,这不就保留好了嘛。
怎么拷贝,这里又有学问了。下面看下例子。
假设有 1G 的数据文件,要对此做快照,怎么做?怎么保留好“按下快门”那一刻系统的数据?
想到一个最简单的办法:
加锁,先 hold 住系统,不让更新数据。把这 1G 的数据拷贝到一个新文件,才放开写。系统停服的时间就是这 1G 数据拷贝的时间。
这就是 停服 + 全拷贝 的方式。功能实现上没问题,但是非常不友好。系统需要停服(禁止更新)这么久,无法忍受,怎么办?
有的童鞋会说:直接搞嘛,就不停服嘛,业务直接写,快照数据后台拷贝。
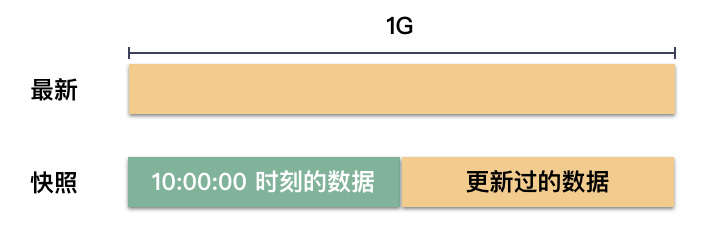
这是不行的,因为生成的数据将牛头不对马嘴,不属于任何时刻的数据。
举个例子,拷贝到 512M 的时候,业务把 600M 地方的数据更新了,后续如果当作快照数据拷贝过去,那这份快照数据将不属于任何时刻,它是一个混乱的拼接。
那的优化思路就在于两个:
- 能否不停服(停写)?
- 能否不全拷贝?
如果原数据还没有保存好,那么停服处理是必须的。因为一旦被更新掉,就永远找不到那个时刻的数据了。但是,换一句话说,一旦快照原数据被保存好了,那么数据更新是可以放开的。 这点很重要。
再说说能不能不全拷贝?
当然可以,把粒度搞小一点嘛,不要一眼就看到 1G 的整体,可以把这 1G 按照 1M 的单位划分,每个 1M 单独处理。

这样就可以做到在禁止写的范围在 1M ,用户体验大大提升。
那怎么才能分清哪个是旧的数据,哪个是新的数据呢?
有办法的:同一个位置的数据多版本。数据每次更新都对应不同的版本,每个打快照都递增版本号,这样快照的数据就和时刻对应上了。
比如,这 1G 的数据,初始版本号为 1,10:00:00 的时候打了一个快照,版本号变成 2。这样后续的更新就在版本 2 上。快照 10:00:00 的数据则对应版本 1 。
好,现在结合多版本和细粒度,再看看这个例子:
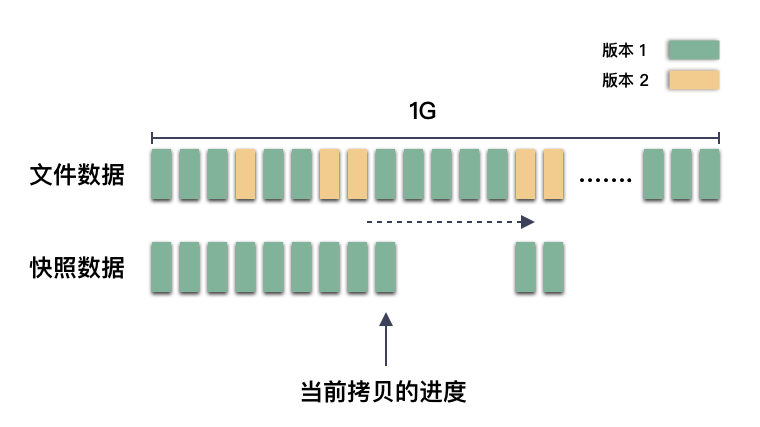
- 这 1G 数据初始化版本为 1;
- 10:00:00 打了个快照,版本递增为 2(注意,此时不必停写);
- 这个时候用户更新第 100 个 1M 的位置,我们只需要把这 1M 的位置拷贝出来,保存好即可;
这样,以后查找 10:00:00 的快照只需要看版本 1 的数据块。而且快照数据的拷贝也可以慢慢拷,完全不用着急。
所以,通过 细粒度 + 多版本 基本可以消除停服时间(控制在一个很小的范围)。
这里说个题外话:打了快照就要立马复制一个完整镜像吗?
其实不是的,这个看系统的需求。如果需要一个非常高的数据安全,那么无论用户更新了多少数据,后台都要完整的拷贝一份数据出来作为快照数据。但是有些系统考虑到成本和效率,则往往只在用户更新的时候和位置才会去做拷贝。
回到上面的例子,细心的童鞋可能注意到,上面的例子是把原版本的数据拷贝出去,拷贝到另外的位置,用户更新的位置则不变。这种方式就叫做写时复制技术,简称 cow 。
说到 cow ,不得不提 row ,这是快照实现的两大技术,下面简单看下这两种技术。
2 copy-on-write
简称 cow,写时复制。为了保护原副本数据,在写入操作修改数据时,会复制原始副本数据到别的位置。这是一种触发式的复制。
比如,打了快照,数据不做任何拷贝( 你就可以声称快照已经完成 ),等到业务需要更新某个位置的数据的时候,再把原来的这一小块的数据拷贝出来。
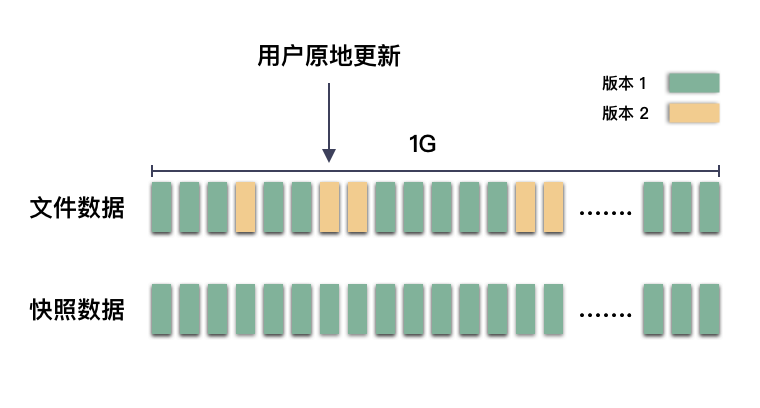
这样就保证了快照数据的不变,也保证了业务的正常更新。cow 的特点是数据更新的位置不变,快照的数据则存储到别的位置。快照则是通过和时间对应的版本号的数据块串联起来,形成一个完整的快照数据。
比如,linux 的 fork 进程,其实就是用的 cow 技术。
划重点:cow 是原地更新,触发拷贝。
3 redirect-on-write
简称 row,写时重定向。为了保护原副本数据,将对其存储空间的写操作重新定向到另一个存储空间。
比如,打了快照,快照数据保持原来位置不变( 可以声称快照已经完成 ),而如果要更新数据,则把新的数据写到别的位置(一般的操作是把原数据读出来,内存更新,然后写到别的位置去)。最新的数据则是通过最新的版本号串联出来。
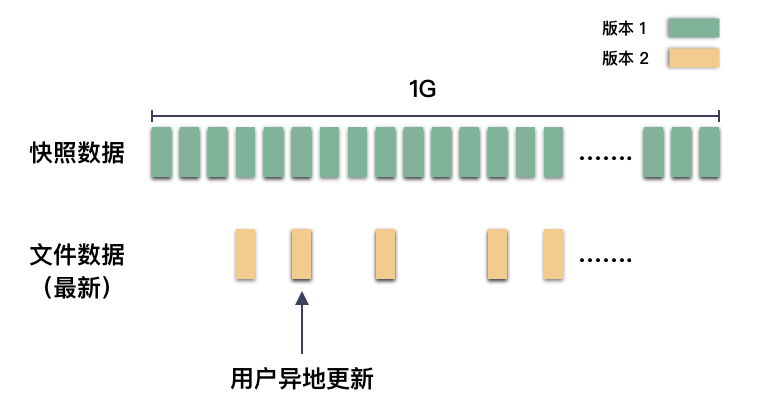
划重点:row 是异地更新,原快照数据不动。
4 cow 和 row 的适用场景
其实 cow 和 row 都是很好的技术,究竟哪些场景用哪个技术,这个要看用户的需求。
一般来说,某些情况下 cow 可能对写请求有一些性能影响,row 对读请求有一些性能影响。这个很容易理解,因为对于 cow 来说如果遇到了要拷贝的数据,需要等待拷贝完之后才能下发更新操作,而对于 row 来说,由于读的链路变长了(因为要寻路了),所以读的性能某些场景会受些影响。
快照有什么用?
快照“打”出来就是用于恢复的,有很多应用场景:
- 比如,etcd 里面就是用快照来快速恢复数据用;
- 比如,块存储就可以经常打一打快照,可以在误操作和中毒等故障恢复起到作用;
- 比如,虚拟机也能打快照,每一个历程点都打一个快照,这样以后能随时回溯;
- 比如,mac 的 time machine 其实也是快照做的,快照更进一步的加强就是 CDP 啦;
总结
- 快照是某个时刻的数据,跟时间点对应。所以,恢复某个快照的数据则等价于系统回溯到某个时间点的状态;
- 快照数据不能变,因为历史不能改;
- 最简单的快照生成手段其实是加锁,冻结写操作,保证生成快照的时候系统无法更改;
- 细粒度的管理 + 数据的多版本配合 cow 或者 row 就可以把数据停服控制在一个很小的时间窗;
- cow 和 row 是快照实现的核心技术,适用于不同的需求场景;
后记
从 ectd 的快照生成,稍微分享了一点快照技术的通用知识。 ~完~