V8引擎的JavaScript内存机制
前言
对于前端攻城师来说,JS的内存机制不容忽视。如果想成为行业专家,或者打造高性能前端应用,那就必须要弄清楚JavaScript的内存机制了
先看栗子
function foo (){
let a = 1
let b = a
a = 2
console.log(a) // 2
console.log(b) // 1
let c = { name: '掘金' }
let d = c
c.name = '沐华'
console.log(c) // { name: '沐华' }
console.log(d) // { name: '沐华' }
}
foo()可以看出在我们修改不同数据类型的值后,结果有点不一样。
这是因为不同数据类型在内存中存储的位置不一样,在JS执行过程中,主要有三种内存空间:代码空间、栈、堆
代码空间主要就是存储可执行代码,关于这个内容有点多,可以看我另一篇文章有详细介绍
咱们先看一下栈和堆
栈和堆
在JS中,每一个数据都需要一个内存空间。而不同的内存空间有什么区别特点呢?,如图
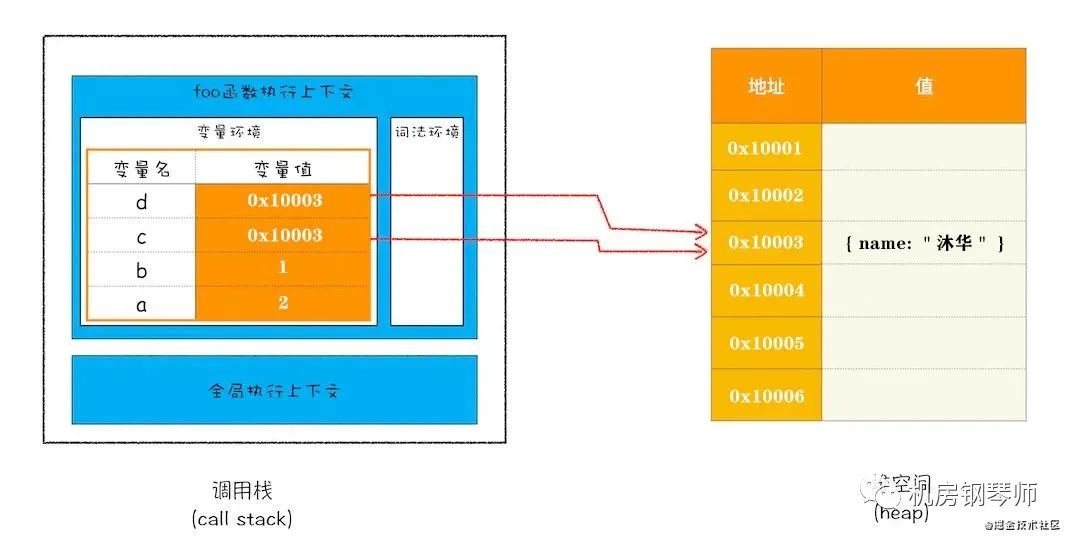
调用栈也叫执行栈,它的执行原则是先进后出,后执行的会先出栈,如图

存储基础类型:Number, String, Boolean, null, undefined, Symbol, BigInt- 存储和使用方式
后进先出(就像一个瓶子,后放进去的东西先拿出来) - 自动分配内存空间,自动释放,占固定大小的空间
- 存储引用类型的变量,但实际上保存的不是变量本身,而是指向该对象的
指针(在堆内存中存放的地址) - 所有方法中定义的变量存在栈中,方法执行结束,这个方法的内存栈也自动销毁
- 可以递归调用方法,这样随着栈深度增加,JVW维持一条长长的方法调用轨迹,内存不够分配,会产生栈溢出
堆:
存储引用类型:Object(Function/Array/Date/RegExp)- 动态分配内存空间,大小不定也不会自动释放
- 堆内存中的对象不会因为方法执行结束就销毁,因为有可能被另一个变量引用(参数传递等)
为什么会有栈和堆之分
通常与垃圾回收机制有关。每一个方法执行时都会建立自己的内存栈,然后将方法里的变量逐个放入这个内存栈中,随着方法执行结束,这个方法的内存栈也会自动销毁
为了使程序运行时占用的内存最小,栈空间都不会设置太大,而堆空间则很大
每创建一个对象时,这个对象会被保存到堆中,以便反复复用,即使方法执行结束,也不会销毁这个对象,因为有可能被另一个变量(参数传递等)引用,直到对象没有任何引用时才会被系统的垃圾回收机制销毁
而且JS引擎需要用栈来维护程序执行期间上下文的状态,如果所有的数据都在栈里在,栈空间大了的话,会影响到上下文切换的效率,进而影响整个程序的执行效率
内存泄露和垃圾回收
上面说了在JS中创建变量(对象,字符串等)时都分配内存,并且在不再使用它们时“自动”释放内存,这个自动释放内存的过程称为垃圾回收。也正是因为垃圾回收机制的存在,让很多开发者在开发中不太关心内存管理,所在在一些情况下导致内存泄露
内存生命周期:
- 内存分配:当我们声明变量,函数,对象的时候,系统会自动为它们分配内存
- 内存使用:即读写内存,也就是使用变量,函数,参数等
- 内存回收:使用完毕,由垃圾回收机制自动回收不再使用的内存
局部变量(函数内部的变量),当函数执行结束,没有其他引用(闭包),该变量就会被回收
全局变量的生命周期直到浏览器卸载页面才会结束,也就是说全局变量不会被垃圾回收
内存泄露
程序的运行需要内存,对于持续运行的服务进程,必须及时释放不再用到的内存,否则内存占用越来越大,轻则影响系统性能,严重的会导致进程崩溃
内存泄露就是由于疏忽或者错误,导致程序不能及时释放那些不再使用的内存,造成内存的浪费
判断内存泄露
在Chrome浏览器中,可以这样查看内存占用情况
开发者工具 => Performance => 勾选Memory => 点左上角Record => 页面操作后点stop
然后就会显示这段时间内的内存使用情况了
- 一次查看内存占用情况后,看当前内存占用趋势图,走势呈上升趋势,可以认为存在内存泄露
- 多次查看内存占用情况后截图对比,比较每次内存占用情况,如果呈上升趋势,也可以认为存在内存泄露
在Node中,使用 process.memoryUsage 方法查看内存情况
console.log(process.memoryUsage());
- heapUsed:用到的堆的部分。
- rss(resident set size):所有内存占用,包括指令区和堆栈。
- heapTotal:"堆"占用的内存,包括用到的和没用到的。
- external:V8 引擎内部的 C++ 对象占用的内存
判断内存泄露以heapUsed字段为准
什么情况下会造成内存泄露
- 没有声明而意外创建的全局变量
- 被遗忘的定时器和回调函数,没有及时关闭定时器中的引用会一直留在内存中
- 闭包
- DOM操作引用(比如引用了td却删了整个table,内存会保留整个table)
内存泄露如何避免
所以记住一个原则:不用的东西,及时归还,有道是,有借有还,再借不难
- 减少不必要的全局变量,比如使用严格模式避免创建意外的全局变量
- 减少生命周期较长的对象,避免过多的对象
- 使用完数据后,及时解除引用(闭包中的变量,DOM引用,定时器清除)
- 组织好逻辑,避免死循环造成浏览器卡顿,崩溃
垃圾回收
JS是有自动垃圾回收机制的,那么这个自动垃圾收集机制是怎么工作的呢?
回收执行栈中数据
看栗子
function foo(){
let a = 1
let b = { name: '沐华' }
function showName(){
let c = 2
let d = { name: '沐华' }
}
showName()
}
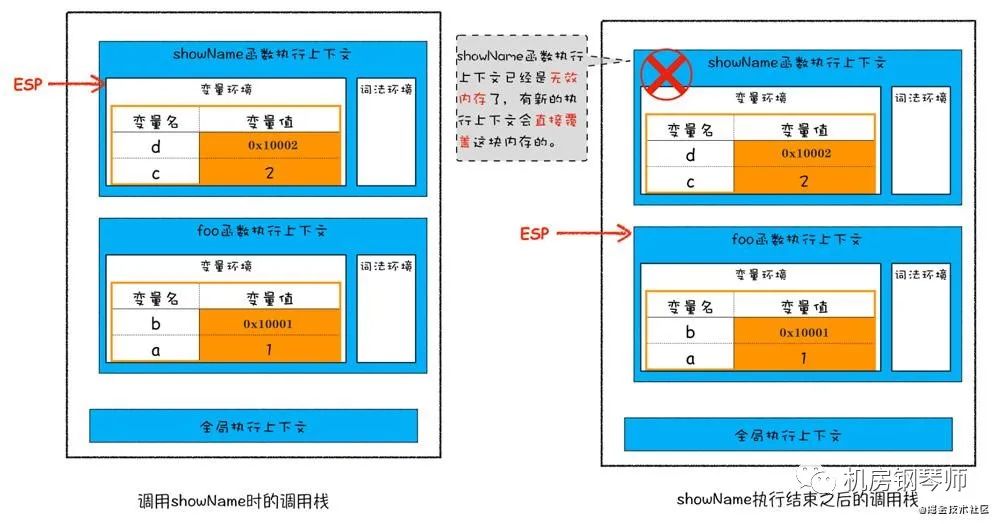
foo()执行过程:
- JS引擎先为foo函数创建执行上下文,并将执行上下文压入执行栈
- 执行遇到showName函数,再为showName函数创建执行上下文,并将执行上下文压入执行栈中,所以在栈中showName压在foo的上面
- 然后先执行showName函数的执行上下文,JS引擎中有一个记录当前执行状态的指针(ESP),会指向正在执行的上下文,也就是showName
- 当showName执行结束之后,执行流程就进入下一个执行上下文,也就是foo函数,这时就需要销毁showName执行上下文了。主要就是JS引擎将ESP指针下移,指向showName下面的执行上下文,也就是foo,
这个下移操作就是销毁showName函数执行上下文的过程
如图
回收堆中的数据
其实就是找出那些不再继续使用的值,然后释放其占用的内存。
比如刚才的栗子,当foo函数和showName函数执行上下文都执行结束就清理了,但是里面的两个对象还依然占用着空间,因为对象的数据是存在堆中的,清理掉的栈中的只是对象的引用地址,并不是对象数据
这就需要垃圾回收器了
垃圾回收阶段最艰难的任务就是找到不需要的变量,所以垃圾回收算法有很多种,并没有哪一种能胜任所有场景,需要根据场景权衡选择
引用计数
引用计数是以前的垃圾回收算法,该算法定义"内存不再使用"的标准很简单,就是看一个对象是否有指向它的引用,如果没有其他对象指向它,就说明该对象不再需要了
但它却有一个致命的问题:循环引用
就是如果有两个对象互相引用,尽管他们已不再使用,但是垃圾回收不会进行回收,导致内存泄露
为了解决循环引用造成的问题,现代浏览器都没有采用引用计数的方式
在V8中会把堆分为新生代和老生代两个区域
新生代和老生代
V8实现了GC算法,采用了分代式垃圾回收机制,所以V8将堆内存分为新生代(副垃圾回收器)和老生代(主垃圾回收器)两个部分
新生代
新生代中通常只支持1~8M的容量,所以主要存放生存时间较短的对象
新生代中使用Scavenge GC算法,将新生代空间分为两个区域:对象区域和空闲区域。如图:
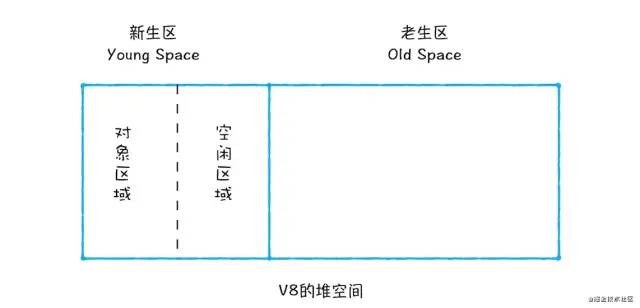
顾名思义,就是说这两块空间只使用一个,另一个是空闲的。工作流程是这样的
- 将新分配的对象存入对象区域中,当对象区域存满了,就会启动GC算法
- 对对象区域内的垃圾做标记,标记完成之后将对象区域中还存活的对象复制到空闲区域中,已经不用的对象就销毁。这个过程不会留下内存碎片
- 复制完成后,再将对象区域和空闲互换。既回收了垃圾也能让新生代中这两块区域无限重复使用下去
正因为新生代中空间不大,所以就容易出现被塞满的情况,所以
- 经历过两次垃圾回收依然还存活的对象会被移到老生代空间中
- 如果空闲空间对象的占比超过25%,为了不影响内存分配,就会将对象转移到老生代空间
老生代
老生代特点就是占用空间大,所以主要存放存活时间长的对象
老生代中使用标记清除算法和标记压缩算法。因为如果也采用Scavenge GC算法的话,复制大对象就比较花时间了
标记清除
在以下情况下会先启动标记清除算法:
- 某一个空间没有分块的时候
- 对象太多超过空间容量一定限制的时候
- 空间不能保证新生代中的对象转移到老生代中的时候
标记清除的流程是这样的
- 从根部(js的全局对象)出发,遍历堆中所有对象,然后标记存活的对象
- 标记完成后,销毁没有被标记的对象
由于垃圾回收阶段,会暂停JS脚本执行,等垃圾回收完毕后再恢复JS执行,这种行为称为全停顿(stop-the-world)
比如堆中数据超过1G,那一次完整的垃圾回收可能需要1秒以上,这期间是会暂停JS线程执行的,这就导致页面性能和响应能力下降
增量标记
所以在2011年,V8从 stop-the-world 标记切换到增量标记。使用增量标记算法,GC 可以将回收任务分解成很多小任务,穿插在JS任务中间执行,这样避免了应用出现卡顿的情况
并发标记
然后在2018年,GC 技术又有重大突破,就是并发标记。让 GC 扫描和标记对象时,允许JS同时运行
标记压缩
清除后会造成堆内存出现内存碎片的情况,当碎片超过一定限制后会启动标记压缩算法,将存活的对象向堆中的一端移动,到所有对象移动完成,就清理掉不需要的内存
结语
点赞支持、手留余香、与有荣焉
感谢你能看到这里,加油哦!
参考
浏览器工作原理与实践