Load_balance函数情景分析
前言
我们描述CFS任务负载均衡的系列文章一共三篇,第一篇是框架部分,第二篇描述了task placement和active upmigration两个典型的负载均衡场景,第三篇是负载均衡的情景分析,包括tick balance、nohz idle balance和new idle balance。在负载均衡情景分析文档最后,我们给出了结论:tick balancing、nohz idle balancing、new idle balancing都是万法归宗,汇聚到load_balance函数来完成具体的负载均衡工作。本文就是第三篇负载均衡情景分析的附加篇,重点给大家展示load_balance函数的精妙。
本文出现的内核代码来自Linux5.10.61,为了减少篇幅,我们对引用的代码进行了删减(例如去掉了NUMA的代码,毕竟手机平台上我们暂时不关注这个特性),如果有兴趣,读者可以配合完整的源代码代码阅读本文。
一、概述
本文主要分成三个部分,第一个部分就是本章,简单的描述了本文的结构和阅读前提条件。第二章是对load_balance函数设计的数据结构进行描述。这一章不需要阅读,只是在有需要的时候可以查阅几个主要数据结构的各个成员的具体功能。随后的若干个章节是以load_balance函数为主线,对各个逻辑过程进行逐行分析。
需要强调的是本文不是独立成文的,很多负载均衡的基础知识(例如sched domain、sched group,什么是负载、运行负载、利用率utility,什么是均衡......)在CFS任务负载均衡系列文章的第一篇已经描述,如果没有阅读过,强烈建议提前阅读。如果已经具体负载均衡的基础概念,那么希望本文能够给你带来研读代码的快乐。
二、load_balance函数使用的数据结构
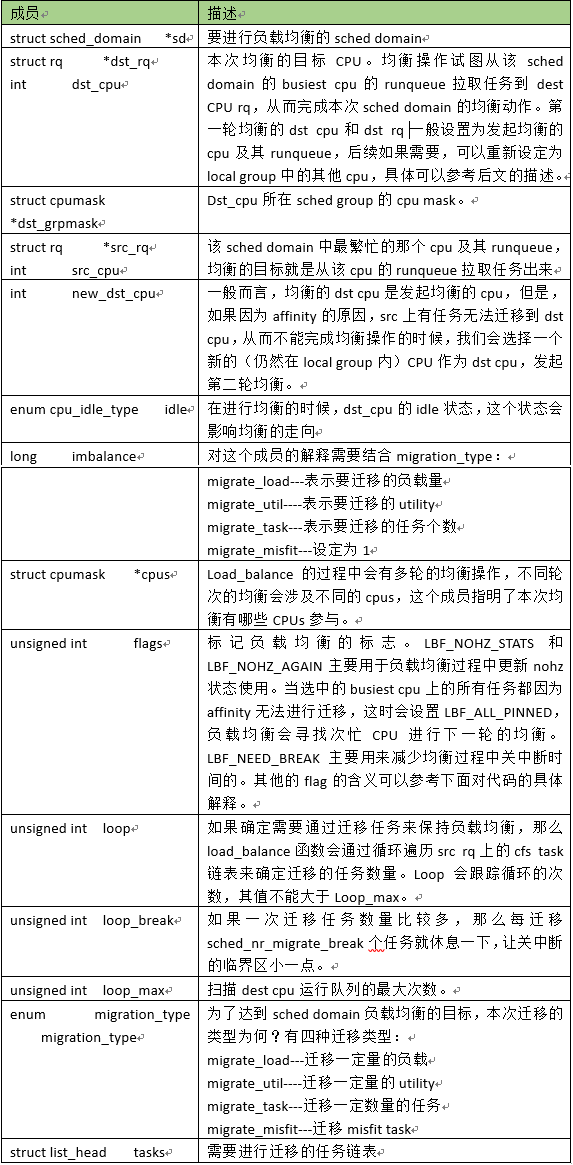
1、structlb_env
在负载均衡的时候,通过 lb_env数据结构来表示本次负载均衡的上下文:
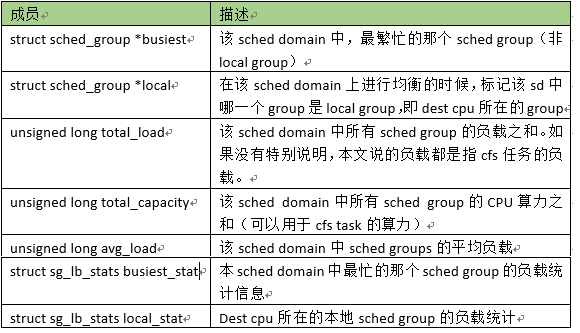
2、structsd_lb_stats
在负载均衡的时候,通过sd_lb_stats数据结构来表示scheddomain的负载统计信息:
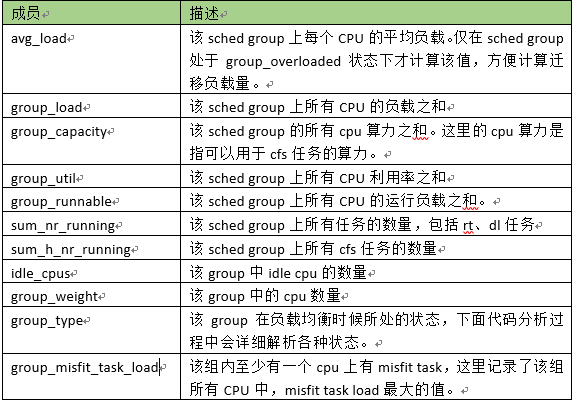
3、structsg_lb_stats
在负载均衡的时候,通过sg_lb_stats数据结构来表示schedgroup的负载统计信息:
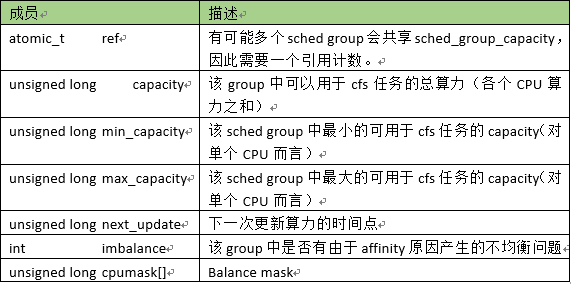
4、structsched_group_capacity数据结构sched_group_capacity用来描述schedgroup的算力信息:
三、load_balance函数整体逻辑
从本章开始我们进行代码分析,这一章是load_balance函数的整体逻辑,后面的章节都是对本章中的一些细节内容进行补充。load_balance函数实在是太长了,我们分段解读。第一段的逻辑如下:

A、对load_balance函数的参数以及返回值解释如下:
A、初始化本次负载均衡的上下文信息。具体可以参考对struct lb_env的解释。初始化完第一轮均衡的上下文,下面就看看具体的均衡操作为何。第二段的逻辑如下:
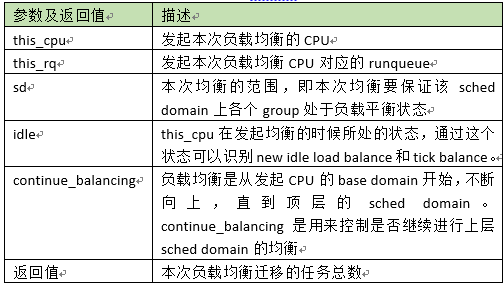
A、确定本轮负载均衡涉及的cpu,因为是第一轮均衡,所以所有的sched domain中的cpu都参与均衡(cpu_active_mask用来剔除无法参与均衡的CPU)。后续如果发现一些异常状况(例如由于affinity原因无法完成任务迁移),那么会清除选定的busiest cpu,跳转到redo进行全新一轮的均衡。
B、判断env->dst_cpu这个CPU是否适合做指定scheddomain的均衡。如果被认定不适合发起balance,那么后续更高层level的均衡也不必进行了(设置continue_balancing等于0)。在base domain,每个group都只有一个CPU,因此所有的cpu都可以发起均衡。在non-base domain,每个group有多个CPU,如果每一个cpu都可以进行均衡,那么均衡就太密集了,白白消耗CPU资源,所以限制只有第一个idle的cpu可以发起均衡,如果没有idle的CPU,那么group中的第一个CPU可以发起均衡。
C、在该sched domain中寻找最繁忙的schedgroup。具体逻辑后文会详细描述。如果没有找到busiest group,那么退出本level的均衡
D、在最繁忙的sched group寻找最繁忙的CPU。具体逻辑后文会详细描述。如果没有找到busiest cpu,那么退出本level的均衡至此已经找到了source CPU,dest cpu就是发起均衡的thiscpu,那么就可以开始第一轮的任务迁移了,具体的代码逻辑如下:

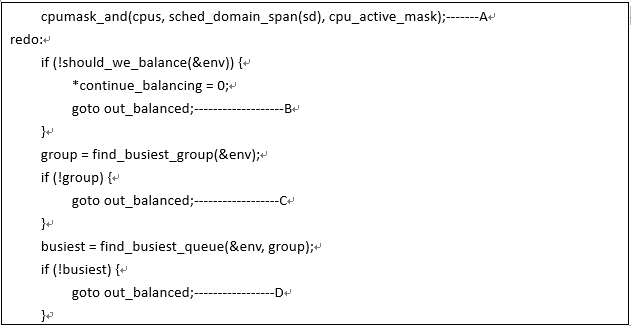
A、如果要从busiest cpu迁移任务到this cpu,那么至少要有可以拉取的任务。在拉取任务之前,我们先设定all pinned标志。当然后续如果发现不是all pinned的状况就会清除这个标志。
B、为了达到sched domain的负载均衡,我们需要进行任务的迁移,因此我们这里需要遍历busiest rq上的任务,看看哪些任务最适合被迁移到this cpu rq。 loop_max就是扫描src rq上runnable任务的次数。一般而言,任务迁移上限就是busiest runqueue上的任务个数,确保了每一个任务都被扫描到,但是一次均衡操作不适合迁移太多的任务(关中断区间太长),因此,即便busiest runqueue上的任务个数非常多,一次任务迁移不能大于sysctl_sched_nr_migrate个(目前设定是32个)。
C、和redo不同,跳转到more_balance的新一轮迁移不需要寻找busiestcpu,只是继续扫描busiest rq上的任务列表,寻找适合迁移的任务。
D、detach_tasks函数用来从busiestcpu的rq中摘取适合的任务。具体逻辑后面会详细描述。由于关中断时长的问题,detach_tasks函数也不会一次性把所有任务迁移到dest cpu上。
E、将detach_tasks函数摘下的任务挂入到srcrq上去。由于detach_tasks、attach_tasks会进行多轮,ld_moved记录了总共迁移的任务数量,cur_ld_moved是本轮迁移的任务数
F、在任务迁移过程中,src cpu的中断是关闭的,为了降低这个关中断时间,迁移大量任务的时候需要break一下。至此已经对dest rq上的任务列表完成了loop_max次扫描,要看情况是否要发起下一轮次的均衡。具体代码如下:

A、如果sched domain仍然未达均衡均衡状态,并且在之前的均衡过程中,有因为affinity的原因导致任务无法迁移到dest cpu,这时候要继续在src rq上搜索任务,迁移到备选的dest cpu,因此,这里再次发起均衡操作。这里的均衡上下文的dest cpu设定为备选的cpu,loop也被清零,重新开始扫描。
B、本层次的sched domain因为affinity而无法达到均衡状态,我们需要把这个状态标记到上层sched domain的group中去,在上层sched domain进行均衡的时候,该group会被判定为group_imbalanced,从而有更大的机会选定为busiest group,从而解决该sched domain的均衡问题。
C、如果选中的busiest cpu上的任务全部都是通过affinity锁定在了该cpu上,那么清除该cpu(为了确保下轮均衡不考虑该cpu),再次发起均衡。这种情况下,需要重新搜索source cpu,因此跳转到redo。
至此,source rq上的cfs任务链表已经被遍历(也可能遍历多次),基本上对runnable 任务的扫描已经到位了,如果不行就只能考虑running task了,具体代码逻辑如下:

A、经过上面的一系列操作,没有完成任何任务的迁移,那么就需要累计sched domain的均衡失败次数。这个失败次数会导致后续进行更激进的均衡,例如迁移cache hot的任务、启动active balance。此外,这里过滤掉了new idle balance的失败,仅统计周期性均衡失败的次数,这是因为系统中new idle balance次数太多,累计其失败次数会导致nr_balance_failed过大,容易触发后续激进的均衡。
B、判断是否要启动active balance。所谓activebalance就是把当前正在运行的任务迁移到dest cpu上。也就是说经过前面一番折腾,runnable的任务都无法迁移到dest cpu,从而达到均衡,那么就考虑当前正在运行的任务。
C、在启动active balance之前,先看看busiestcpu上当前正在运行的任务是否可以运行在dest cpu上。如果不可以的话,那么不再试图执行均衡操作,跳转到out_one_pinned
D、Busiest cpurunqueue上设置active balance的标记
E、发起主动迁移F、完成了至少一个任务迁移,重置均衡失败计数Load_balance最后一段的程序逻辑主要是进行一些清理工作和设定balance_interval的工作,逻辑比较简单,不再详述,我们会在随后的章节中对load_balance函数中的一些过程做进一步的描述。
四、寻找sched domain中最繁忙的group
判断当前sched domain是否均衡并返回最忙group的功能是在find_busiest_group函数中完成的,我们分段来描述该函数的逻辑,我们先看第一段代码:
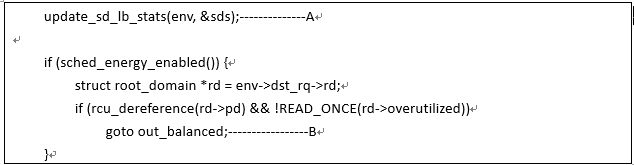
A、负载信息都是不断的在变化,在寻找最繁忙group的时候,我们首先要更新scheddomain负载均衡信息,以便可以根据最新的负载情况来搜寻。update_sd_lb_stats会更新该sched domain上各个sched group的负载和算力,得到local group以及非local group最忙的那个group的均衡信息,以便后续给出最适合的均衡决策。具体的逻辑后面的章节会详述
B、在系统没有进入overutilized状态之前,EAS起作用。如果EAS起作用,那么负载可能是不均衡的(考虑功耗),因此,这时候不进行负载均衡,依赖task placement的结果。update_sd_lb_stats函数找到了busiestgroup,结合local group的状态就可以判断系统的不均衡状态了。当然有一些比较容易判断的场景,具体代码如下:

A、如果没有找到最忙的那个group,说明当前scheddomain中,其他的非local的最繁忙的group(后文称之busiest group)没有可以拉取到local group的任务,不需要均衡处理。
B、Busiestgroup中有misfit task,那么必须要进行均衡,把misfit task拉取到local group中
C、Busiestgroup是一个由于cpu affinity导致的不均衡,这个不均衡在底层sched domain无法处理。
D、如果local group比busiestgroup还要忙,那么不需要进行均衡(目前的均衡只能从其他group拉任务到local group)其他的复杂场景需要进一步比拼local group和busiest group的情况,group_overloaded状态下判断是否均衡的代码如下:

A、如果local group处于overloaded状态,那么需要通过avg_load的比拼来做均衡决策
B、如果local group的平均负载比busiestgroup还要高,那么不需要进行均衡
C、如果local group的平均负载高于scheddomain的平均负载,那么不需要进行均衡
D、虽然busiest group的平均负载高于localgroup,但是高的不多,那也不需要进行均衡,毕竟均衡需要额外的开销。具体的门限是有sched domain的imbalance_pct确定的。
非group_overloaded不看平均负载,主要看idlecpu的情况,具体代码如下:

A、这里处理busiest group没有overload的场景,这时候说明该scheddomain中其他的group的算力都是cover当前的任务负载,是否要进行均衡,主要看idle cpu的情况
B、反正busiest group当前算力能处理其runqueue上的任务,那么在本CPU繁忙的情况下没有必要进行均衡,因为这时候关注的是idle cpu,即让更多的idle cpu参与运算,因此,如果本CPU不是idle cpu,那么判断sched domain处于均衡状态。
C、如果busiest group中有更多的idle CPU,那么也没有必要进行均衡
D、如果busiest group中只有一个cfs任务,那么也没有必要进行均衡
E、所有其他情况都是需要进行均衡。calculate_imbalance用来计算scheddomain中不均衡的状态是怎样的。具体如何进行均衡决策可以参考下面的表格:


Balanced:该scheddomain处于均衡状态,不需要均衡。Force:该scheddomain处于不均衡状态,通过calculate_imbalance计算不均衡指数,并有可能通过任务迁移让系统进入均衡状态。Avg load:通过schedgroup的平均负载来判断是否需要均衡。尽量不均衡,除非非常的不均衡(通过sched domain的imbalance_pct参数来设定)Nr idle:dest cpu处于idle状态,并且localgroup的idle cpu个数大于busiest group的idle cpu个数,只有在这种情况下才进行均衡。
五、更新sched domain的负载统计
Sched domain的负载统计更新主要在update_sd_lb_stats函数中,其逻辑大致如下:

这一段主要是遍历该sched domain的所有group,对其负载统计进行更新。更新完负载之后,我们选定两个sched group:其一是local group,另外一个是最繁忙的non local group。具体逻辑过程解释如下:
A、更新sched group的算力。在basedomain(在手机平台上就是MC domain)上,我们会更新发起均衡所在CPU的算力。注意:这里说的CPU算力指的是该CPU可以用于cfs任务的算力,即需要去掉由于thermal pressure而损失的算力,去掉RT/DL/IRQ消耗的算力。具体请参考update_cpu_capacity函数。在其他non-base domain(在手机平台上就是DIE domain)上,我们需要对本地sched group(包括发起均衡的CPU所在的group)进行算力更新。这个比较简单,就是把child domain(即MC domain)的所有sched group的算力加起来就OK了。更新后的算力保存在sched group中的sgc成员中。另外,更新算力没有必要更新的太频繁,这里做了两个限制:其一是只有local group才进行算力更新,其二是通过时间间隔来减少new idle频繁的更新算力。
B、更新该sched group的负载统计,下面的章节会详细描述。
C、在sched domain的各个group遍历中,我们需要两个group信息,一个是localgroup,另外一个就是non local group中的最忙的那个group。显然,如果是local group,不需要下面的比拼最忙的过程。
D、找到non local group中的最忙的那个group。由于涉及各种grouptype,我们在下一章详述如何判断一个group更忙。E、更新sched domain上各个schedgroup总的负载和算力F、更新root domain的overload和overutil状态。对于顶层的scheddomain,我们需要把各个sched group的overload和overutil状态体现到root domain中。
六、更新sched group的负载
更新sched group负载是在update_sg_lb_stats函数中完成的,我们分段来描述该函数的逻辑,我们先看第一段代码:

A、sched group负载有三种,load、runnableload和util,把所有cpu上load、runnable load和util累计起来就是sched group的负载。除了PELT跟踪的load avg信息,我们还统计了sched group中的cfs任务和总任务数量。
B、只要该sched group上有一个CPU上有1个以上的任务,那么就标记该schedgroup为overload状态。
C、只要该sched group上有一个CPU处于overutilized(该cpu利用率已经达到cpu算力的80%),那么就标记该schedgroup为overutilized状态。
D、统计该sched group中的idle cpu的个数
E、当sched domain包括了算力不同的CPU(例如DIE domain),那么即便cpu上只有一个任务,但是如果该任务是misfit task那么也标记sched group为overload状态,并记录sched group中最大的misfit task load。需要注意的是:idle cpu不需要检测misfit task,此外,对于local group,也没有必要检测misfit task,毕竟同一个group,算力相同,不可能拉取misfit task到本cpu上。第二段代码如下:

A、更新sched group的总算力和cpu个数。再次强调一下,这里的capacity是指cpu可以用于cfs任务的算力
B、判定sched group当前的负载状态
C、计算sched group平均负载(仅在groupoverloaded状态才计算)。在overload的情况下,通过sched group平均负载可以识别更繁忙的group。
sched group负载状态如下(按照负载从重到轻排列),括号中的数字是该group type的值,数值越大,载荷越重:

判断sched group繁忙程度的函数是group_classify,可以对照代码理解各schedgroup繁忙状态的含义。
在对比sched group繁忙程度的时候,我们主要是对比group_type的值,大的值更忙,小的值比较闲,在相等的时候的判断规则如下:

七、如何计算sched domain的不均衡程度
一旦通过local group和busiestgroup的信息确定sched domain处于不均衡状态,我们就可以调用calculate_imbalance函数来计算通过什么方式(migrate task还是migrate load/util)来恢复sched domain的负载均衡状态,也就是设定均衡上下文的migration_type和imbalance 成员,下面我们分段来描述该函数的逻辑,我们先看第一段代码:

A、如果busiest group上有misfit task,那么优先对其进行misfit任务迁移,并且一次迁移一个misfittask。
B、如果busiest group是因为cpuaffinity而导致的不均衡,那么通过通过迁移任务来达到平衡,并且一次迁移一个任务。上面的代码主要处理busiest group中的一些特殊情况,后面的代码主要分两段段来根据local group的状态来进行不均衡的计算。我们首先看local group有空闲算力的情况,我们分成两段分析,第一段代码如下:

A、如果local group有一些空闲算力,那么我们还是争取把它利用起来,只要迁移的负载量既不overload local group,也不会让busiest group变得无事可做。
B、如果sched domain标记了SD_SHARE_PKG_RESOURCES(MC domain),那么其在task placement的时候会尽量选择idlecpu。这里load balance路径需要和placement对齐:不使用空闲capacity而是使用nr_running来进行均衡。如果没有设置SD_SHARE_PKG_RESOURCES那么考虑使用migrate_util方式来达到均衡。
C、如果local group有一些空闲算力,busiestgroup又处于繁忙状态(大于full busy),同时满足未设定SD_SHARE_PKG_RESOURCES(对于手机场景就是DIE domain,MC domain需要使用nr_running而不是util来进行均衡)。这种状态下,我们采用util来指导均衡,具体迁的utility设定为local group当前空闲的算力。
D、有些场景下,local group的util大于其groupcapacity,根据步骤C计算的imbalance等于0(意味着不需要均衡)。然而,在这种场景下,如果local cpu处于idle状态,那么需要从busiest group迁移过来一个runnable task,从而确保了性能。
Local gorup有空闲算力的第二段代码如下:

代码逻辑走到这里,说明busiest group也有空闲算力(local group也一样),这时候主要考虑的是任务的迁移,让sched domain中的idle cpu尽量的均衡。还有一种可能就是busiest group的状态是繁忙(大于fully busy),但是是在MC domain中进行均衡,这时候均衡的逻辑也是一样的看idle cpu。
A、对于base domain(group只有一个CPU),我们还是希望任务散布在各个sched group(cpu)上。因此,这时候需要从busiest group中迁移任务,保证迁移之后,local group和busiest group中的任务数量相等。
B、如果group中有多个CPU,那么我们的目标就是让localgroup和busiest group中的idle cpu的数量相等
上面处理了local group有空闲算力的情况,下面的代码处理local group处于非group_has_spare状态的情况,代码如下:

如果local group没有空闲算力,但是也没有overloaded,可以从busiest group迁移一些负载过来,但是这也许会导致local group进入overloaded状态。因此这里使用了avg_load来进一步确认是否进行负载迁移。具体的判断方法是local group的平均负载是否大于sched domain的平均负载。如果local group和busiest group都overloaded并且走入calculate imbalance,那么早就确认了busiest group的平均负载大于local group的平均负载。当local group或者busiest group都进入(或者即将进入)overloaded状态,这时候采用迁移负载的方式进行均衡,具体代码如下:

具体迁移的负载量是综合考虑localgroup、busiest group和sched domain的平均负载情况,确保迁移负载之和,local group、busiest group向sched domain的平均负载靠拢。
八、如果寻找busiest group中最忙的CPU
find_busiest_queue函数用来寻找busiestgroup中最繁忙的cpu。代码逻辑比较简单,和buiest group在上面判断的migrate type相关,不同的type使用不同的方法来寻找busiest cpu:

一旦找到最忙的CPU,那么任务迁移的目标和源头都确定了,后续就可以通过detach tasks和attach tasks进行任务迁移了。
九、detach_tasks和attach_tasks
至此,我们已经确定了从src cpu runqueue(即最繁忙的group中最繁忙的cpu)搬移若干load/util/task到dest cpu runqueue。不过无论是load还是util,最后还是要转成任务。detach_tasks就是确定具体从src rq迁移哪些任务,并把这些任务挂入lb_env->tasks链表中。detach_tasks函数第一段的代码逻辑如下:
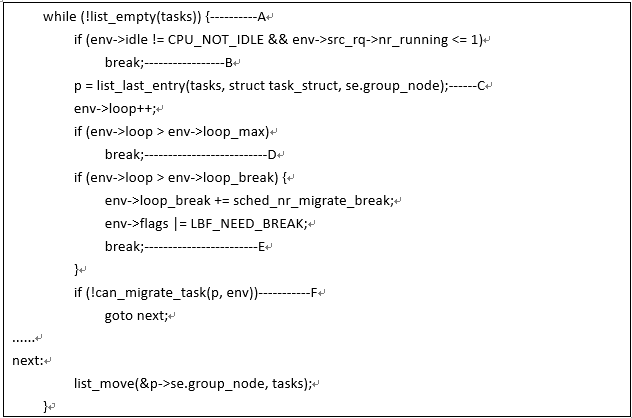
A、src rq的cfs_tasks链表就是该队列上的全部cfs任务,detach_tasks函数的主要逻辑就是遍历这个cfs_tasks链表,找到最适合迁移到目标cpurq的任务,并挂入lb_env->tasks链表
B、在idle balance的时候,没有必要把src上的唯一的task拉取到本cpu上,否则的话任务可能会在两个CPU上来回拉扯。
C、从cfs_tasks链表队尾摘下一个任务。这个链表的头部是最近访问的任务。从尾部摘任务可以保证任务是cache cold的。
D、当把dest rq上的任务都遍历过之后,或者当达到循环上限(sysctl_sched_nr_migrate)的时候退出循环。
E、当dest rq上的任务数比较多的时候,并且需要迁移大量的任务才能完成均衡,为了减少关中断的区间,迁移需要分段进行(每sched_nr_migrate_break暂停一下),把大的临界区分成几个小的临界区,确保系统的延迟性能。
F、如果该任务不适合迁移,那么将其移到cfs_tasks链表头部。上面对从cfs_tasks链表摘下的任务进行基本的判断,具体迁移该任务是否能达到均衡是由detach_tasks函数第二段代码逻辑完成的,具体如下:

A、计算该任务的负载。这里设定任务的最小负载是1。
B、LB_MIN特性限制迁移小任务,如果LB_MIN等于true,那么task load小于16的任务将不参与负载均衡。目前LB_MIN系统缺省设置为false。
C、不要迁移过多的load,确保迁移的load不大于env->imbalance。随着迁移错误次增加,这个限制可以适当放宽一些。
D、对于migrate_util类型的迁移,我们通过任务的util和env->imbalance来判断是否迁移了足够的utility。需要注意的是这里使用了任务的estimation utilization。
E、migrate_task类型的迁移不关注load或者utility,只关心迁移的任务数
F、找到misfit task即完成迁移
detach_tasks函数最后一段的代码逻辑如下:
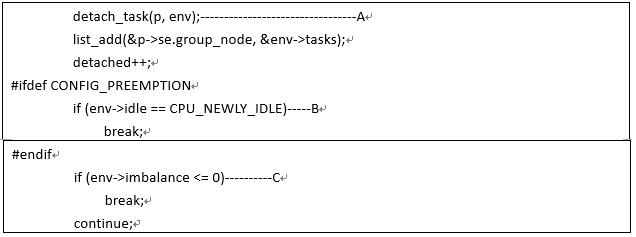
A、程序执行至此,说明任务P需要被迁移(不能迁移的都跳转到next符号了),因此需要从src rq上摘下,挂入env->tasks链表
B、New idlebalance是调度延迟的主要来源,所有对于这种balance,我们一次只迁移一个任务C、如果完成迁移,那么就退出遍历src rq的cfs task链表。attach_tasks主要的逻辑就是遍历均衡上下文的tasks链表,摘下一个个的任务,挂入目标cpu的队列。
十、如何判断一个任务是否可以迁移至目标CPU
can_migrate_task函数用来判断一个任务是否可以迁移至目标CPU,具体代码逻辑如下:

A、如果任务p所在的task group在src或者dest cpu上被限流了,那么不能迁移该任务,否者限流的逻辑会有问题
B、Percpu的内核线程不能迁移
C、任务由于affinity的原因不能在destcpu上运行,因此这里设置上LBF_SOME_PINNED标志,表示至少有一个任务由于affinity无法迁移
D、下面的逻辑(E段)会设备备选目标CPU,如果是已经设定好了备选CPU那么直接返回,如果是newidle balance那么也不需要备选CPU,它的主要目标就是迁移一个任务到本idle的cpu。
E、设定备选CPU,以便后续第二轮的均衡可以把任务迁移到备选CPU上can_migrate_task函数第二段代码逻辑如下
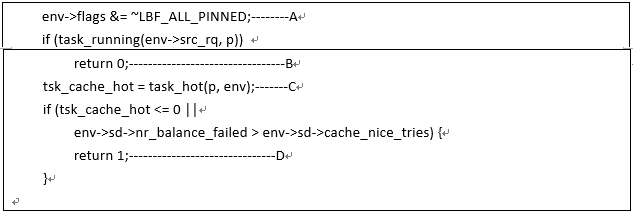
A、至少有一个任务是可以运行在dest cpu上(从affinity角度),因此清除allpinned标记
B、正处于运行状态的任务不参与迁移,迁移runningtask是后续active migration的逻辑。
C、判断该任务是否是cache-hot的,这主要从近期在srccpu上的执行时间点来判断,如果上次任务在src cpu上开始执行的时间比较久远(sysctl_sched_migration_cost是门限,目前设定0.5ms),那么其在cache中的内容大概率是被刷掉了,可以认为是cache-cold的。此外如果任务p是src cpu上的next buddy或者last buddy,那么任务是cache hot的。
D、一般而言,我们只迁移cache cold的任务。但是如果进行了太多轮的尝试仍然未能让负载达到均衡,那么cache hot的任务也一样迁移。