云原生环境下对“多活”架构的思考
互联网公司发展到一定的规模,系统的高可用就变得极其重要。为了应对那些随时可能发生的意外,“多活”在如今互联网公司好像变得是必备的手段了。甚至一些公司发生一些 P0 事故之后,多活也会出现在 case study 的列表之内。
在云原生比较流行的今天,很多公司都会选择某云服务厂商来部署公司的相关服务。当公司规模较小时,一般情况下公司的架构会像下图所示。
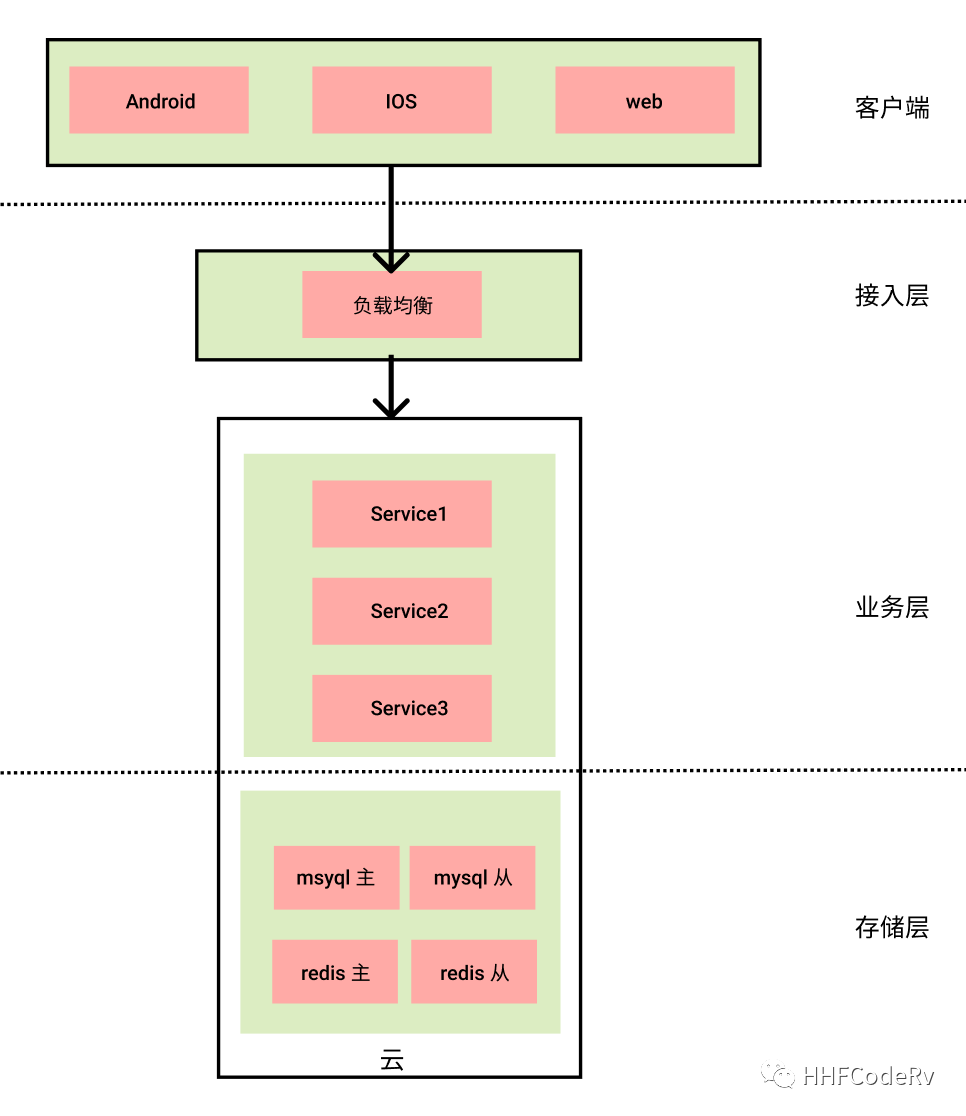
当公司的业务达到了一定的规模,一般情况都会再选一个云服务商形成“多云多活”来保证系统的稳定性、高可用。有幸参与过某公司的双云方案的落地,这里聊聊这种多云多活的方案的一些思考。
多活为什么重要?
这里就举两个实际的例子。
- 2021年7月13日,B 站部分服务器机房发生故障,整个故障持续超过一小时。
- 2021年10月9日,富途证券的 IDC 机房网络故障事件导致某些客户资产清零、无法交易。
这两起故障都是比较基础的服务出现的故障导致高可用受损,这个基础服务的故障一般恢复起来都是比较麻烦,为了实现高可用,将多活容灾推到了解决方案的层面。特别当 B 站故障后,各路文章出来解读多活,如何实施多活(很多的文章当个乐子看即可)。像这种比较基础的服务故障,往往恢复时间都是不确定的,多活确实是解决问题的有效手段,能大大提高我们系统的容灾能力。
服务容灾有哪些方案
主备
在比较小点公司内,提起比较多的方案应该是主备方案。这种方案的特点是有一套主、备集群,正常情况下都只有主集群在工作,当主集群出现故障的时候,备用集群启用。
这种方案其实不太靠谱,因为备用集群正常情况下是不启用的,所以其代码,配置,数据都有可能是没有经过验证的,万一真的发生问题时,慌忙启动的备用集群大多数情况也是不可用的。
多活
多活就是所有的集群都是正常提供服务的。正常情况下会按照流量划分,将流量归属到不同的集群,当某集群出现问题时,将流量切换到其他集群正常提供服务。
多活是高可用架构设计的保障,根据多活等级的要求不同,多活还有同城双活,异地双活,两地三中心,三地五中心等。对多活的要求越高,投入的资源也就会越高。这里就不再详细讲述这些名字背后的技术细节了。
多云多活的技术细节
多云多活指的是公司选择两家云服务商,将服务部署两个云上,正常情况两个云同时对外提供服务,当其中一个云出现问题时,将流量全都切换到另外一个云。
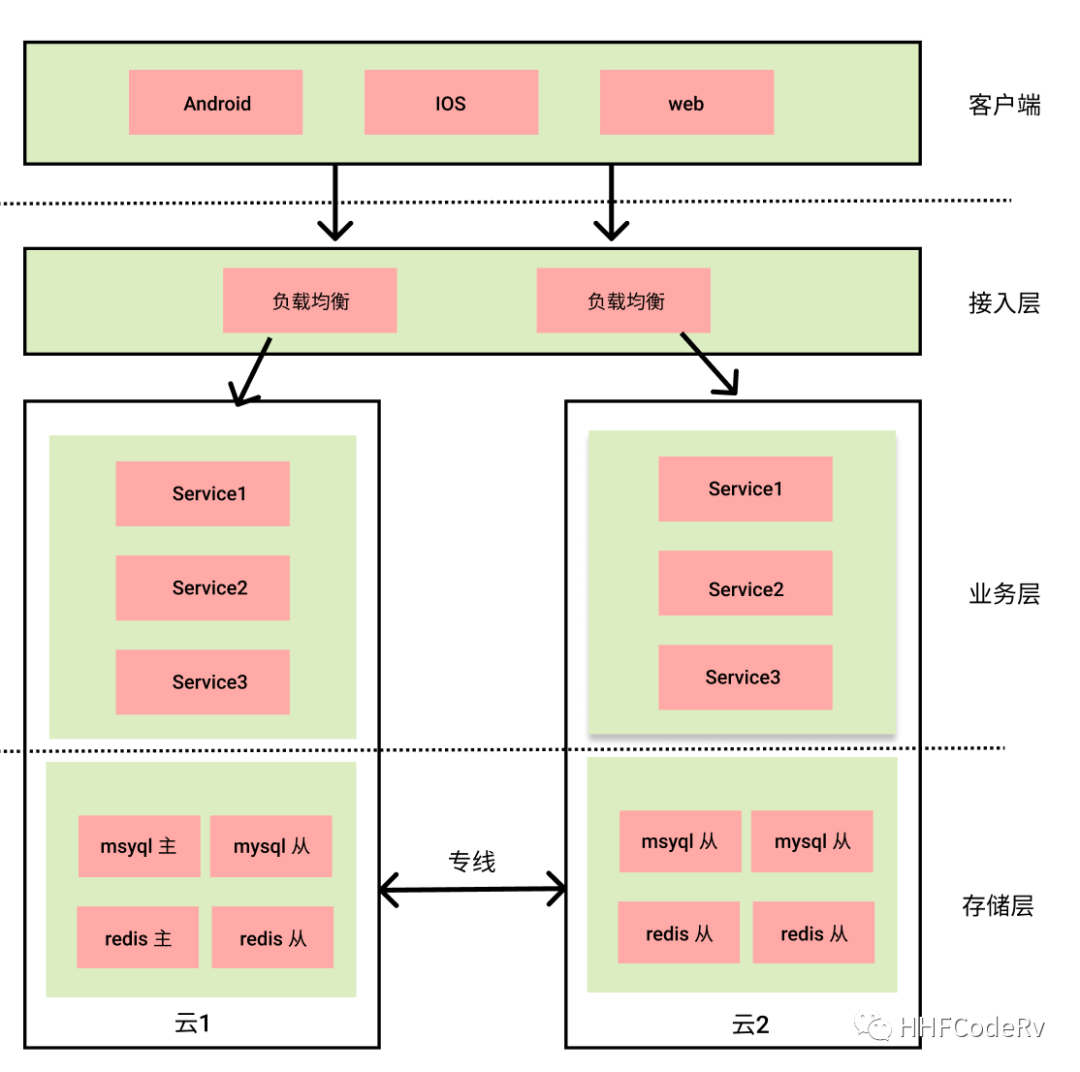
这个架构的大概流程:
- 客户端通过接入层访问系统相关服务
- 接入层根据流量分发规则,将流量向下分发到业务层
- 业务层经过相关的业务逻辑处理,将相关数据写入到相关的存储中
流量分发/切换
分布在不同的两个云的集群的系统承载能力是需要经过评估的,流量接入层按照系统承载能力的差异,将流量按照不同的比例进行分发。不过一般情况下,两个云的系统会尽量保证系统的承载能力是一致的,所以流量是平分到两个集群中。
当某个云发生故障的时候,在流量接入层会将流量全部切换到另外一个云上,保证另外一个云的故障不会用户造成影响。由此可见流量接入的层的重要性,不过这一层组件比较成熟,在我经历的项目中,这一层确实没有发生过故障。
业务层双活
业务层对于双云双活来说,其实比较简单的,就是将同样的代码分别部署到两个云即可。
但是要注意的是,这一层是有 IDC 之分的,要保证的是云1 的服务不能访问到云2 去,对于开发人员来说也不用太担心,只要配置不出错,一般业务框架会保证这个事情。
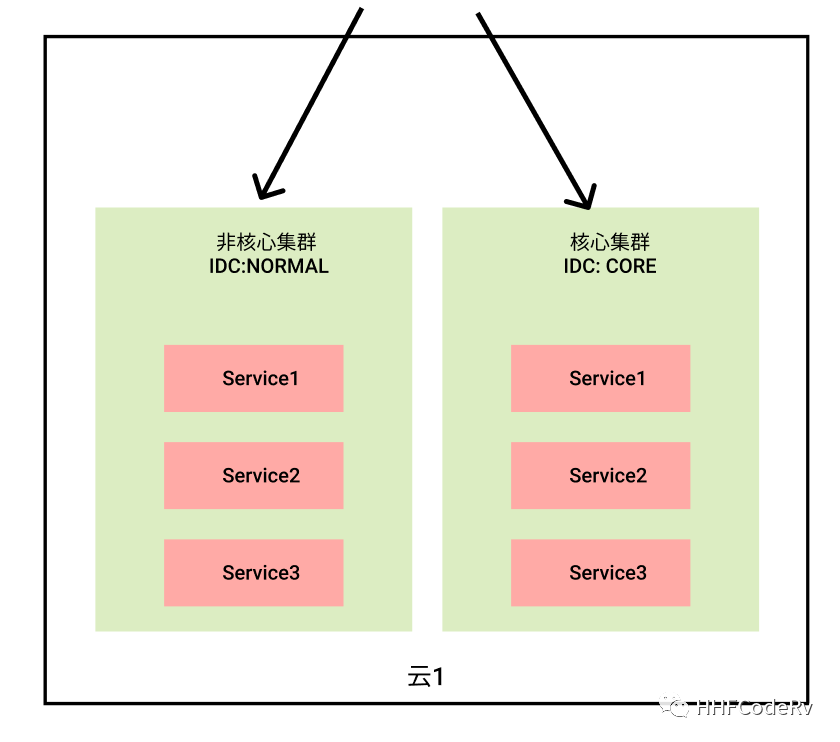
再扯一点其他的,业务层正常情况下会根据业务需求快速迭代,这就给业务系统带来了不稳定性。如果 CI/CD 做的好的话,能够让业务做到快速回滚,但是这也会给核心业务造成一定的影响。为了解决这个问题,需要将核心业务进行隔离,让新上线的业务在非核心集群进行验证,等待稳定后再部署到核心集群。
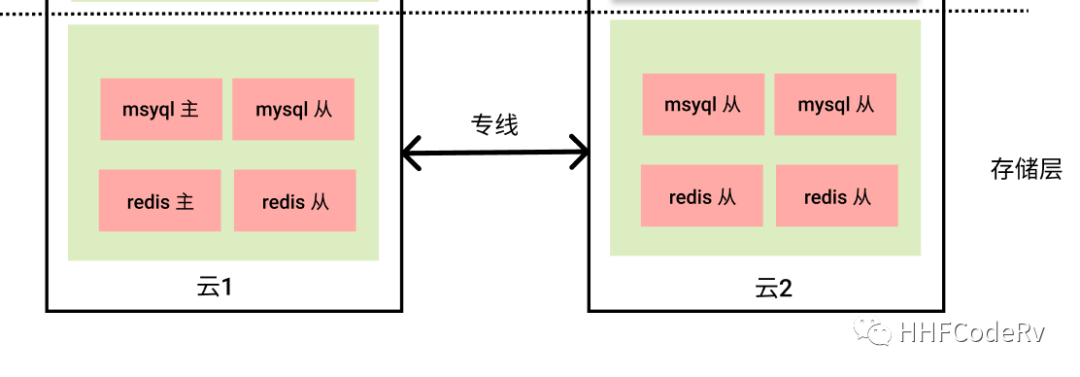
存储层
这个设计还是蛮普遍的,比如 [《斗鱼基于etcd和ZooKeeper的注册中心实践案例》] 这篇文章中,对于存储基本也是这样设计的。
redis、mysql 还是选择经典的一主多从的设计方式。
- 选择一个 “云” 将 mysql/redis 的主节点和部分从节点部署到这个云上
- 将 mysql/redis 其他的从节点部署到另外一个云上
- redis/mysql 之间利用主从同步机制进行数据同步
- 云1 和 云2 之间由一条专线连接
优点
架构简单,可以利用 redis、mysql 自身的机制进行数据同步,让数据的访问在各自的云进行。
缺点
其实缺点一眼就看出来了,这整个“双云双活”的设计的缺点太依赖于主节点所在的云的稳定性和专线的稳定性。
在我经历的项目,云的稳定性还是可以的,最容易出现问题的其实这条专线,比如:专线被打满。当专线出现问题时,研发只能傻乐,等待运维恢复专线,如何保证这个专线的稳定性成为这个架构最重要的事情。
当然另外一个问题也是很难解决:主节点所在的云或者专线发生故障的时候,整个项目其实也就瘫痪了大半。
因为当主节点所在的云出现故障时,在流量接入层可以将流量切换到另外一个集群,但是我们的主业务肯定不是”只读“的,肯定还有写业务存在, 于是出现故障的时候,只能看到一堆堆的写失败报警,有些业务接口肯定也在报错,只能等待故障恢复后,人工补偿这些写失败的数据。
所以为了解决这个系统设计的缺陷,就是要将 redis/mysql 做成多主多从,主与主集群之间做数据同步。这个方案说起来容易,但是实践起来就太困难了。
这里只使用 mysql/redis 作为示例来解释双云双活,其实我们的系统还有另外一些分布式一致性系统如:ectd,读者可以考虑一下如何部署到双云上面。
结论
其实很多的公司的多活最终都因为各种原因沦为了“伪多活”。 非云,非BAT级别的厂,一般建义先做到核心数据(交易,用户)多中心备份,毕竟不是每次火灾水灾都能赶上,当某云出现问题时可以快速恢复,这才是重中之重。
上面提高的“双云双活”方案的瓶颈就在于存储层,让整个集群处于“伪多活”的状态。这个方案确实能解决一些问题,但是高可用并没有想象中的那么出色,更多时候这样项目一般都沦落成某些人晋升的 KPI。