破玩意 | 多线程 +1 的最快操作
直奔主题,多个线程,一个共享变量,不断 +1。
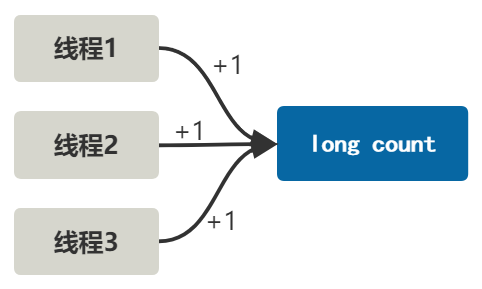
如果代码直接这样写,会产生线程安全问题。
public class LongAdder {
private long count = 0L;
public void add() {
count++;
}
}可以加锁去实现,但效率太低。
public class LongAdder {
private long count = 0L;
public void add() {
synchronized(this){
count++;
}
}可以用原子类这种乐观锁实现,比加 synchronized 锁效率高很多。
public class LongAdder {
private AtomicLong count = new AtomicLong(0L);
public void add() {
count.incrementAndGet();
}
}当然,更高级的玩法也可以自己调用 UNSAFE 模拟原子类里的 CAS 操作,但实际上就是把原子类的源码给展开了。(v = count 应该放在循环里)
public class LongAdder {
private volatile long count = 0L;
public void add() {
boolean success = false;
int v = count;
while(!success) {
success = UNSAFE.compareAndSwapLong(
LongAdder.class, countOffset, v, v + 1);
}
}
}这几段多线程 +1 的代码如果看不明白,可以找些资料把这块的基础补一下哈,本文就不赘述了,我们继续。
关于这个多线程 +1 操作,有没有效率更高的办法呢?
分析需求
我们先别急着想,怎么把它变快,一头扎到技术实现上。
同我们接一个新产品的需求一样,我们首先分析一下,这个产品提出这个需求的核心目的是什么,有时候往往可以使问题简化。
我们想一个极端的场景,成百上千个线程一直连续不断对这个 count 进行 +1 操作,一直加上个一年,一年后,我们只需要看一下最终的值是多少,即可。
整个功能就是这样,加一年,最后看那么一下。
我们看看之前的原子类 +1 的代码。
public class LongAdder {
private AtomicLong count = new AtomicLong(0L);
public void add() {
count.incrementAndGet();
}
}每时每刻都将 +1 的操作真真正正计算了一遍,并赋值给 count。
但我们只是一年后要读取这个 count 值一次,显然,中间这一年对 count 值准确地计算出结果,就是不必要的。
而恰恰是因为每次都要准确计算出它的结果,导致多线程之间发生了竞争,浪费了资源。
那思路就打开了!
设计思路
我们事先搞出多个这种 count 变量,并且用某种方式让不同线程对应到不同 count 变量上。

你看这样,如果仅仅有四个线程,就完全不存在线程竞争的问题,每个线程操作唯一的变量。
过一段时间后, 获取最终的值,只需要把它们加和即可。
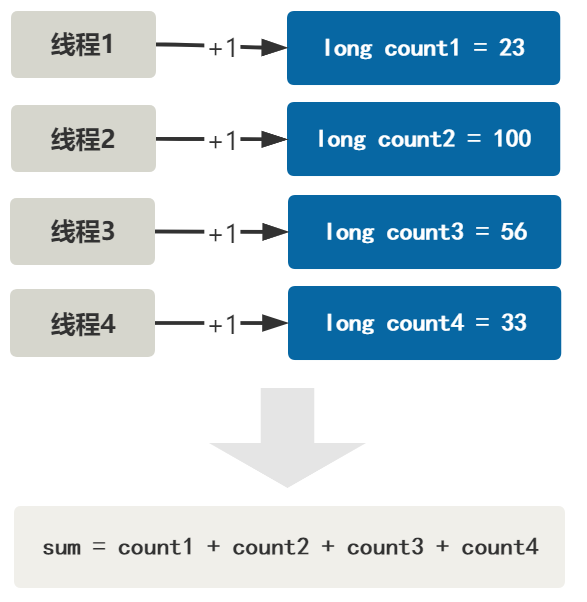
这样,获取 count 值的复杂度增加了,需要做个加和操作,但却是整个过程完全没有线程竞争。
牺牲读性能,换取写性能。用空间换时间。
你看,即使一个小小的多线程 +1 操作的设计,也存在架构思维中的 trade off 思想,这在我之前两篇架构文章中多次提到。
正所谓,不存在完美的算法,我们都只是在做平衡,牺牲这个,才能换取那个。
具体实现
设计思路中,我们尽可能把问题简化,才能得到一个大方向。
现在我们要具体设计了,就要把刚刚懒得思考的问题,拿出来了,这个过程的确比较痛苦。
懒加载
首先,我们当然希望,整个过程都不存在线程竞争。
这样我们一开始就创建了那么多 count,并且把线程一一映射过去,假如本来他们共同对同一个共享变量 +1 就不会产生竞争,那这种方式就有很大问题了:
- 浪费了空间
- 多了线程映射的算法逻辑
- 最终获取值时还要加和
得不偿失呀。
所以我们采用懒加载的办法,一开始,仍然是对同一个共享变量 +1,等真正出现竞争了,再开始启用更多的 count。
我们把一开始使用的唯一共享变量叫做 base,把之后开启的多个变量叫做 Cell 类,放在一个 Cell[] 数组里。Cell 类里只有一个变量就是 value,存储累加过程中的值。
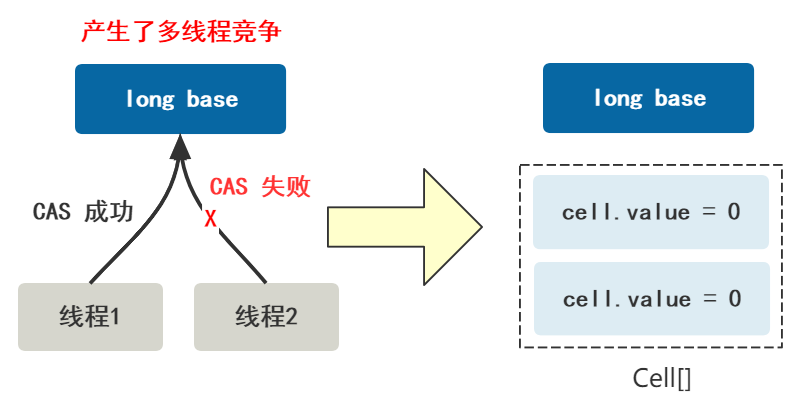
数组扩容
一开始,这个 Cell 数组是空的。
等 base 变量出现了一次竞争失败的情况,就初始化这个 Cell[] 数组,第一次里面放两个 Cell。
此时,如果只有三个线程 +1,就可以保证不会发生竞争。
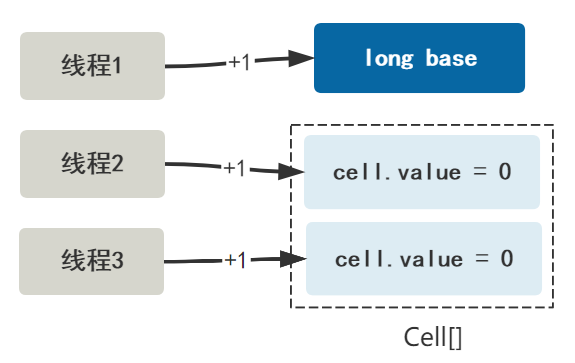
但如果此时又来了一个线程,导致了竞争,即 CAS 失败,那么可以扩容 Cell[] 数组。
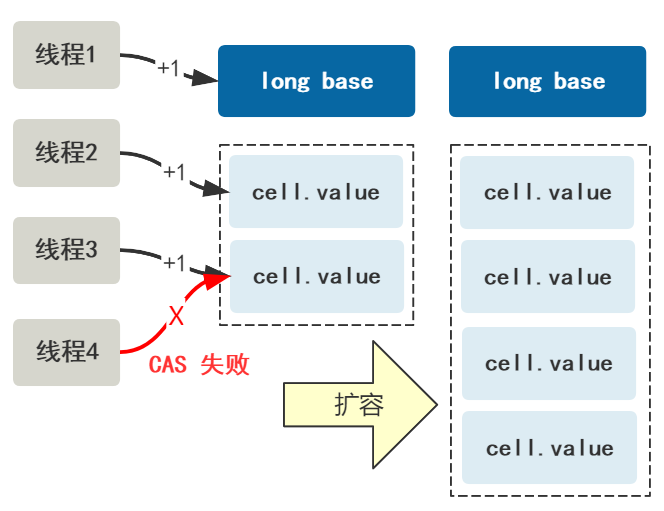
可以注意到我画的,Cell 数组初始大小为 2,之后扩容也是翻倍的方式,不知道你有没有想到些什么,我们接着往下看。
线程映射绑定
刚刚,我们一直默认,线程和 Cell 数组中的每个 Cell 是一一对应的关系,可是怎么做到这一点呢?
我们在每个线程中,维护一个局部变量,这个变量属于这个线程,这个变量的值根据 Cell[] 数组的大小哈希取模,就可以映射到其中一个 Cell 上了。
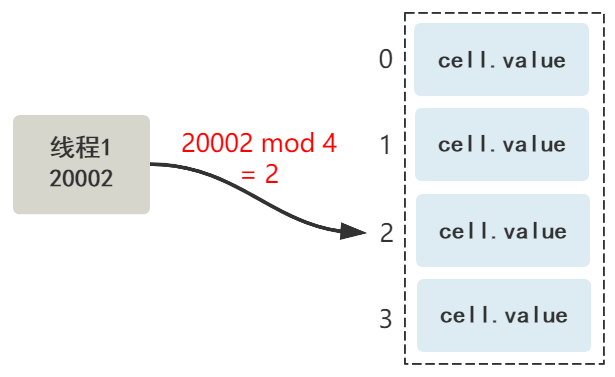
那同线程绑定的这个局部变量是怎么来的呢?
别担心,JDK 已经帮我们设计好了,这就是 Thread 类里的变量 probe。
public class Thread implements Runnable {
...
int threadLocalRandomProbe;
...
}但是我们不能直接获取,需要借助 ThreadLocalRandom 类的如下办法获取。
static final int getProbe() {
return UNSAFE.getInt(Thread.currentThread(), PROBE);
}当然,获取出的这个值,可能哈希取模后也会发生冲突。
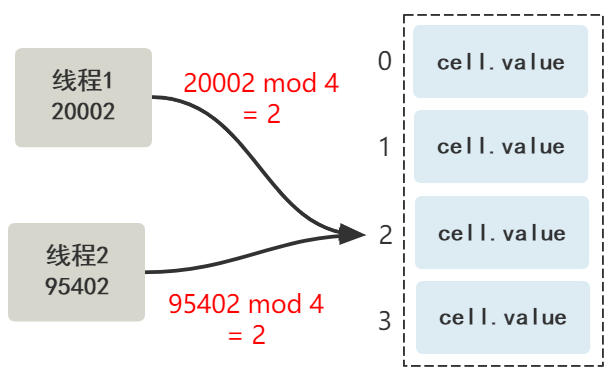
没关系,请注意,这只是哈希取模冲突,也就是多个线程可能要对同一个 Cell 里的 value 进行 CAS +1 操作,但不一定会产生竞争。
所以,发生哈希取模冲突后,先直接尝试 CAS +1 操作,如果能成功,就没那么多事了。
但假如恰好,CAS 的时候又发生了竞争,导致操作失败怎么办?
还好,可以用这种方式为该线程的 probe 重新赋值。
probe = 新的值,自己生成一个;
UNSAFE.putInt(Thread.currentThread(), PROBE, probe);重新赋值后的 probe,再次经过哈希取模后,就不会和之前的冲突了。
但很不幸,假如再冲突怎么办?
那就再次尝试 CAS +1 操作。
但假如又很不幸,CAS +1 操作又失败了,要不要继续重新赋值 probe 呢?
要,不过,此时说明竞争已经很激烈了。
简单说就是,这个 Cell 数组有点拥挤了,此时我们选择将数组扩容!
扩容大家还记得吧,就是上一节中的。
这就又回到了上一节中的步骤,如此循环往复。
当然,扩容也要有个限度,我们规定,数组大小超过 CPU 核心数后,就不再扩容了。
CPU 核心数,可以用如下方式获取。
Runtime.getRuntime().availableProcessors();
如果再发生冲突和竞争的情况,那就不断重新赋值 probe,不断尝试 CAS。
有同学可能会说,那一直不成功咋办呢?
别忘了,如果不使用我们这个 LongAdder,仅仅用一个原子类不断 +1,失败的概率是更高的,我们已经通过将线程分散到不同 Cell,降低了发生竞争失败的概率了。
执行流程
至此,设计思路和实现过程,就都搞定了,我们来看一下整个流程。
1. 最开始只有一个 base 变量,多个线程和谐地进行 CAS +1 操作。 2. 直到有一天,两个线程发生了竞争,即其中一个线程 CAS 时失败了,那么就创建一个大小为 2 的 Cell[] 数组,用线程私有的局部变量 probe 取模,映射到一个 Cell 上,对其 CAS +1 操作。 3. 不过假如线程 probe 取模后,发现那个 Cell 已经被绑定过了,不要紧,先 CAS +1 试一试。 4. 但如果没试成功,说明此处有竞争,那重新计算一下线程的 probe 值,映射到一个新的 Cell 上。 5. 如果此时又冲突,并且 CAS +1 又失败,那么将 Cell[] 数组扩容。 6. 最后当要获取最终的累计和时,用 base 的值,加上所有 Cell[] 数组里的 value 值,得出一个和,返回给调用方。
这个破玩意,其实 JDK 中早有实现,又是 Doug Lea 大神写的一个类,名为
LongAdder
LongAdder
通过我们刚刚眼花缭乱的分析,再看 Doug Lea 大神的 LongAdder 就非常容易了。
我们看最核心的 add 方法,这是最外层的逻辑,很容易理解。
public class LongAdder extends Striped64 implements Serializable {
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
// 已经初始化了 Cell 数组
// 或者对 base 变量 CAS +1 操作失败
// 就走到这里了
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
// 下面这行就是 probe 取模操作
(a = as[getProbe() & m]) == null ||
// 取模后发现已经被绑定,冲突了,先不管,直接 cas 试试
!(uncontended = a.cas(v = a.value, v + x)))
// 这里数组未初始化完全、或取模后未冲突、或冲突后 cas 失败,都会往下走
longAccumulate(x, null, uncontended);
}
}
}increment,decrement,sum 方法不说了,太简单。
add 方法看注释,重重条件后,会执行到那个非常庞大的方法。
longAccumulate(x, null, uncontended);
这个方法里面非常长,我就不放在这里了,感兴趣的同学可以去翻翻源码。相信结合我上面带着你走过的分析过程,很快就可以看懂。

LongAdder 源码非常建议大家读一读,即使你不能全局掌握它,也可以学到很多并发编程方面的小知识。
比如,并发编程包经常见的伪共享问题,就体现在 Cell 这个类的设计上。
本来 Cell 这个类应该长这个样子。
static final class Cell {
volatile long value;
...
}但由于伪共享问题,它被设计成了这个样子。
static final class Cell {
volatile long p0, p1, p2, p3, p4, p5, p6;
volatile long value;
volatile long q0, q1, q2, q3, q4, q5, q6;
...
}在 JDK 1.8 提供了新注解后,又变成了这个样子。
@sun.misc.Contended
static final class Cell {
volatile long value;
...
}再比如说,刚刚说的重复两轮如果都失败,再走数组扩容,这个重复两轮,其实代码中就是用一个布尔值去玩的。
else if (!collide)
collide = true;你看,第一次来的时候,走了这个分支,把布尔值改了。
第二次再来,就进不了这个分支了。
反正感觉很妙。
希望大家平时,不要每个代码都嫌头大就不去钻研,感觉花上一天时间就看个 LongAdder,面试再不考,就觉得是浪费了时间。
其实不然,这个小小的 LongAdder 你要是能琢磨透了,很多多线程的知识点,也就都搞定了。
上两篇文章,我写的都是架构设计,站在一个很宏观的视角。
本篇文章,一个不起眼的 LongAdder 方法,其实展开来看也是个大世界,也有着相当多的架构思维。
慢慢你会发现,很多大小技术思想,都是相通的。