Go语言入门系列二
运算符优先级
高 * / % << >> & &^
+ - | ^
== != < <= > >=
&&
||
低二元运算符中,除了位移操作符外,操作数类型必须相同。如果其中一个是无显示类型声明的常量,那么该常量操作数会自动转型。
func main() {
const v = 20; //无显式类型声明的常量
var a byte = 10;
b := v + a
fmt.Printf("%T,%v\n",b,b) //v 自动转换为 byte/uint8类型
}自增、自减不再是运算符,而是独立的语句
指针
指针类型与C语言中大体相同,但是多了一些限制:
- 不支持加减法运算和类型转换
- 指针没有专门的 -> 符合,而是都使用. 选择表达式
- 零长度对象的地址是否相等和具体实现有关但是一定不等于nil
复合类型初始化
Go语言在C语言的基础上加了一些限制,舍弃了C语言的灵活,但是换来的是整齐统一的书写形式和规范。
限制:
- 初始化表达式必须包含类型标签
- 左花括号必须在类型尾部,不能另起一行
- 多个成员初始值以逗号分隔
- 允许多行,但每行须以逗号或右花括号结束
type data struct{
x int
s string
}
var a data = data{ 1, "abc"}
b := data{
1,
"abc",
}基本语法区别
if...else..
- 条件表达式必须是布尔类型,左花括号不能另起一行
- 可定义块局部变量或执行初始化函数
func main(){
x := 3
if xinit();x > 5{ //可以这儿执行初始化函数或定义局部变量
println("a")
} else if x < 5 && x > 0{
println("b")
} else {
}
}switch
- switch后面也不需要加括号
- case 中不需要加break,会自动加
- 想要执行下一个case必须在当前case中添加fallthrough
- 都不匹配会执行default与其顺序无关
func main(){
switch x := 5;x{
case 5:
x += 10
fallthrough //继续向下执行
case 6:
x += 20 //在此处加fallthrough 会报错
default:
pirntln(x)
}
}for
- 可使用for...range完成数据迭代
- 允许返回单值,使用_来忽略
- 定义的局部变量会重用地址(对闭包有影响)
- range会复制目标数据,受影响的是数组,可改用数组指针或切片类型
func main(){
data :=[3]int[10,20,30]
for i, x := range data{ //i是索引,x是值
if i == 0 {
data[0] += 100
data[1] += 200
data[2] += 300
}
}
for i, _ := range data{ //忽略值
if i == 0 {
data[0] += 100
data[1] += 200
data[2] += 300
}
}
}函数
使用关键字func定义函数,限制:
- 不支持命名嵌套定义
- 不支持同名函数重载
- 不支持默认参数
灵活点:
- 无须前置声明
- 支持不定变参
- 支持多返回值
- 支持命名返回值
- 支持匿名函数和闭包
函数签名:这里函数签名指的是参数和返回值构成的一对,都相同才是同一类型
func test(){ //左花括号不能另起一行
}
func test1(f func()){ //左花括号不能另起一行
f() //可以传入函数作为参数,然后直接调用
if( f == nil) //函数只能用来判断是否为nil,不支持其他比较方式
}
type FormatFunc func (string, ...interface{})(string,error) //定义函数类型更方便
Go支持返回局部变量指针,并且是安全的
函数参数
Go不支持有默认值的可选参数,不支持命名实参,调用时必须按照签名顺序传递指定类型和数量的实参,就算以"_"命名的参数也不能忽略
不管是指针、引用类型、还是其他类型参数,都是值拷贝传递,区别无非是拷贝目标对象还是拷贝指针
func test(x *int){
fmt.Printf("pointer: %p,target: %v\n",&x, x)
}
func main(){
a := 0x100
p := &a
fmt.Printf("pointer: %p,target: %v\n", &p, p)
}
指针传参是拷贝
可见依然把指针做了一次拷贝,两个指针内存是不一样的,但是指向的是相同的
变参
变参本质上就是切片,只能接受同类型的,并且只能放在末尾。因为是切片所以可以修改源数据,如果想拷贝底层数据需要调用copy函数
func test(a...int){
fmt.Println(a)
}
func main(){
a := [3]int{1,2,3}
test(a[:]...) //转换为slice后展开 注意需要加三个点
}返回值
- 有返回值的函数必须有return,除非有panic或Z者无break的死循环
- 可以用"_"忽略不想要的返回值,返回值可用作其他调用参数或当作结果返回
- 命名返回值可以隐式返回
- 命名时我们必须对全部返回值命名,否则会编译错误
func div(x,y int) (z int, err error){
if y == 0 {
err = errors.New("division by zero")
return //默认返回 0 和 "division by zero"
}
z = x/y
return //返回 z 和 nil
}返回值类型就能看出用意的时候尽量不要采用命名返回值
匿名函数
即没有定义名字符合的函数,但是其可以在函数内部定义,形成类似嵌套效果。还可直接调用,保存到变量作为参数或返回值。
func main(){
add := func(x, y int) int{
return x + y
}
printfln(add(1, 2))
}匿名函数优势:
- 除闭包因素外,匿名函数是常见的重构手段
- 可将大函数分解成多个相对独立的匿名函数块,实现框架的细节分离
- 匿名函数的作用域隔离,更加灵活
- 没有应以顺序限制,必要时可抽离
闭包
闭包指的是可以包含代码块中未定义但是本身在其上下文中 并没有被销毁的自由变量
闭包的价值在于可以作为函数对象或者也匿名函数,对于类型系统而言,这不仅以为这数据还要表示代码。支持闭包的多数语言都将函数作为第一级数对象,就是说这些函数可以存储到被闭包引用的变量会一直存在
Go语言中的闭包同样也会引用到函数外的变量。闭包的实现却表里只要闭包还被使用,那么帮你报被引用的变量就会一直存在
package main
import{
"fmt"
}
func main(){
var j int = 5;
a := func()(func()){
var i int = 10
return func() {
fmt.Printf("i , j: %d, %d\n", i ,j)
}
}()
a()
j *= 2
a()
}
//i , j : 10 , 5
//i , j : 10 , 10
//变量a指向的闭包函数引用了局部变量i和j,i的指被隔离,在闭包外不能被修改,改变j的值以后,再次调用a,发现结果是修改过的值
//在变量a指向的闭包函数中,只有内部的匿名函数才能访问变量i,而无法通过其他途径访问到,因此保证了i的安全性延迟调用
语句defer向当前函数注册稍后执行的函数调用。
一个函数中可以存在多个defer语句,因此需要注意的是defer语句的调用是先进后出的原则,即最后一个defer语句将最先被执行。
只是注册,不论在函数的什么位置,直到函数结束前才执行,常用于资源释放、解除锁定、错误处理等
func main(){
f,err := os.Open("./main.go")
if err != nil {
log.Fatalln(err)
}
defer f.Close() //最后调用
... //其他事
}
func main(){
x, y := 1, 2
defer func(a int){
println("defer x, y = ", a, y) //y 为闭包引用
}(x) //注册时复制调用参数
x += 100 //对 x 的修改不会影响延迟调用
y += 200
println(x, y)
}
//输出:
//101 202
//defer x, y = 1 102编译器通过插入额外指令来实现延迟调用执行,而return 和 panic 语句都会终止 当前函数流程,引发延迟调用。因此defer可以修改命名返回值,因为ret汇编指令是在defer之后执行。
- 延迟调用不能误用,导致本来要执行的命令声明周期被延长
- 延迟调用需要花费更大的代价,对性能有要求且压力大的算法应该尽量避免使用延迟调用
错误处理
Go语言引入了一个标准的接口error,函数可以将其作为返回值的最后一个,但这并不是强制要求,我们还可以自己包装一个错误处理对象
defer关键字用于解决C++中的抛出异常后相应的资源无法得到释放导致资源泄露的问题
//标准库将error定义为接口类型,便于自定义错误类型
type error interface{
Error() string
}
//自定义错误类型
type DivError struct{
x ,y int
}
func (DivError) Error() string{ //实现error接口方法
return "division by zero"
}
func div(x,y int)(int, error){
if y == 0 {
return 0, DivError{x,y} //返回自定义错误类型
}
return x/y, nil
}
func main(){
z, err := div(5,0)
if err != nil {
switch e := err.(type){ //根据类型进行匹配
case DivError:
fmt.Println(e, e.x, e.y)
default:
fmt.Println(e)
}
log.Fatalln(err)
}
println(z)
}panic()和recover()
这两个内置函数用以报错和处理运行时错误和程序错误场景
import(
"runtime/debug" //用来输出完整调用堆栈信息
)
func test(){
panic("I am dead")
}
func main(){
defer func(){
if err := recover();err != nil {
debug.PrintStack()
}
}()
test()
}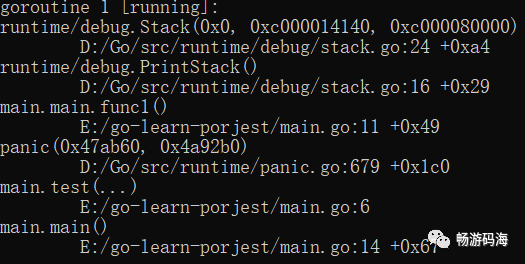
错误处理堆栈信息
除非是不可恢复性、导致系统无法正常工作的错误,否则不建议使用panic