每个 JavaScript 开发者都应该了解的 Unicode
在开始之前,我要坦白一点:我很长一段时间都很怕 Unicode。每当我遇到些需要应用 Unicode 知识去解决的编程任务,我就会去搜一个 hack 方案,但其实我并不理解到底在做什么。
我一直在逃避,直到我遇到了一个需要深入理解 Unicode 才能解决的问题。搜索不到适合我当前场景的解决方案了。
我努力的读了一大堆文章 — 令我惊讶的是,其实 Unicode 不难理解。虽说 … 有些文章我读了至少三回。
事实证明,Unicode 是一个通用且优雅的标准。但由于那一大堆的抽象术语,坚持深入学习其实还是挺艰难的。
如果你感觉自己对 Unicode 的理解还不够,那么现在是时候来直面它了!没那么难。给自己泡一杯可口的 茶 或 咖啡 ☕。让我们深入 抽象、字符、星光 和 代理 的美妙世界吧。
本文首先会解释 Unicode 的基本概念,帮你打牢基础。之后会阐述 JavaScript 是如何和 Unicode 协作的,以及在这个过程中你可能会遇到的陷阱。你还会学会如何应用新的 ECMAScript 2015 特性来解决部分问题。
准备好了吗?燥起来!
1 . Unicode 背后的思想
我们先从一个本质上的问题开始。你为何能够阅读理解这篇文章?很简单,因为你知道每一个 字 和 由字组成的词 的含义。
为什么你能理解每一个字的含义呢?简单来说,因为这些图形符号(你在屏幕上看到的东西)和 中文这门语言中的汉字(含义)之间有着联系,而你(读者)和我(作者)都认同这一点。
这对于计算机来说也是一样的。不同之处在于计算机无法理解字的含义,它们对于计算机仅仅是 二进制位序列。
想象这样一个场景, 用户1 通过网络向 用户2 发送了一条消息 hello 。
用户1 的计算机不知道其中每个字母的含义。所以它会将 hello 转换成数字序列 0x68 0x65 0x6C 0x6C 0x6F ,其中每一个字母唯一对应一个数字: h 对应 0x68 , e 对应 0x65 ,诸如此类。这些数字会被发送到 用户2 的计算机上。
用户2 的计算机接收到数字序列 0x68 0x65 0x6C 0x6C 0x6F 后,它会使用同样一套字母和数字的对应关系来还原信息。然后展示出正确的信息: hello 。
两台计算机之间 在 字母和数字的对应关系 这个方面达成的协议 就是 Unicode 标准化的产物。
按照 Unicode 标准, h 是一个叫做 LATIN SMALL LETTER H 的抽象字符。这个字符对应的数字是 0x68 ,其码位(code point)记为 U+0068 。
Unicode 会提供一个 抽象字符列表(字符集),并为每个字符分配一个独一无二的码位标识符(编码字符集)。
2 . Unicode 基础术语
网站 www.unicode.org 提到:
!! “ Unicode 为每个字符提供了一个独一无二的数字,无论是什么平台,无论是什么程序,无论是什么语言。”
Unicode 是一个通用字符集,它为大多数的书写系统定义了 字符列表,并为每个字符关联了一个唯一的数字(码位)。

最初的 Unicode 版本 1.0 在 1991-10 发布,包含 7,161 个字符。最近的一个版本是 14.0 (2021-9 发布)包含 144,697 个字符。
在 Unicode 出现之前,很多厂商实现了大量难以处理的 字符集 和 编码,Unicode 广泛且具有包容性的方法 解决了这个重大问题。
创建一个支持全部字符集和编码的应用程序是非常复杂的。
如果你觉得 Unicode 已经很难,那没了 Unicode 编程会变得更难。
我还记得以前在读取文件的时候,会胡乱地挑选字符集和编码。简直是在抽奖!
2.1 字符 和 码位
!! “ 抽象字符 (或者说 字符)是用于组织、控制 或 表示 文本数据 的 信息单元”
Unicode 将 字符 作为抽象术语。每个抽象字符都有一个关联名称,例如 LATIN SMALL LETTER A 。这个字符的渲染形式(字形)是 a 。
!! “ 码位 是分配给单个字符的一个数字”
码位 是从 U+0000 到 U+10FFFF 的数字。
U+<hex> 是码位的格式,其中 U+ 是代表 Unicode 的前缀,而 <hex> 表示十六进制数字。例如, U+0041 和 U+2603 都是码位。
记住,码位 就是一个简简单单的数字,你不用考虑更多了。码位 就是一种数组中的元素索引。
就是因为 Unicode 将 码位 和 字符 关联起来,才变得不可思议。例如, U+0041 对应的 字符 名为 LATIN CAPITAL LETTER A (渲染为 A ),U+2603 对应的 字符 名为 SNOWMAN (渲染为 ☃ )。
并非所有 码位 都有关联字符。总共有 1,114,112 个码位可用(范围从从 U+0000 到 U+10FFFF ),但是只有 144,697 个(截止 2021.9)被分配了字符。
2.2 Unicode 平面(Unicode Planes)
!! “ 平面(Planes) 是从
U+n0000到U+nFFFF的 65,536(或 ) 个连续的码位,n 的取值范围从 到 ”
平面 将全部的 Unicode 码位分成了 17 个均等的组:
- 平面0 包含从 U+0000 到 U+FFFF 的 码位。
- 平面1 包含从 U+1000 到 U+1FFFF 的 码位。
- …
- 平面16 包含从 U+10000 到 U+10FFFF 的 码位。

基本多文种平面(Basic Multilingual Plane)
平面 0 很特殊,名为 基本多文种平面(Basic Multilingual Plane) 或 简称 BMP 。它包含绝大多数现代语言中的字符 (Basic Latin 基础拉丁字母,Cyrillic 西里尔字母,Greek 希腊字母,等等)和 大量的符号。
综上所述,基本多文种平面 范围是从 U+0000 到 U+FFFF ,最多 4 位十六进制数字。
开发者通常只会处理 BMP 中的字符。BMP 包含了绝大部分必要的字符。
BMP 中的一些字符:
e是U+0065,命名为 LATIN SMALL LETTER E|是U+007C,命名为 VERTICAL BAR■是U+25A0,命名为 BLACK SQUARE☂是U+2602,命名为 UMBRELLA
星光平面(Astral plane)
!! 译者注: Astral Plane,也称为星光界,是古典、中世纪、东方、神秘哲学和神秘宗教所假设的一个存在位面。它是天球的领域,是灵魂诞生和死亡之后的穿梭的地方,通常认为,天使、精灵 或 其他非物质生命在这里居住。"Astral Plane" 是 辅助平面(Supplementary Planes) 的非正式名称,因为(特别是90年代后期)对它们的使用太少了,以至于和神秘学中的 “彼岸”(The Great Beyond)一样虚无缥缈。很多人对这种幽默的称呼持反对意见,而且随着 平面1 和 平面2 的广泛使用,越来越少的人觉得这些平面真的是 “星光界”。但是这种诙谐的引申是无害的,它提醒我们现在还远远达不到那种程度。 详见:http://www.opoudjis.net/unicode/unicode_astral.html
在 BMP 后的 16 个平面(平面 1,平面 2,…,平面 16)被称为 星光平面(Astral Plane) 或 辅助平面(Supplementary Planes)
星光平面 中的 码位 被称为 星光码位。码位范围从 U+10000 到 U+10FFFF 。
一个 星光码位 有 5 或 6 位 十六进制数字:U+ddddd 或 U+dddddd 。
让我们看看 星光平面 中的一些字符:
- `
是U+1D11E` ,命名为 MUSICAL SYMBOL G CLEF - `
是U+1D401` ,命名为 MATHEMATICAL BOLD CAPITAL B - `
是U+1F035` ,命名为 DOMINO TITLE HORIZONTAL-00-04 - `
是U+1F600` ,命名为 GRINNING FACE
2.3 码元(Code Units)
OK,我们刚刚说的 Unicode 的 字符,码位 和 平面 都是抽象的。
现在我们该谈谈 Unicode 在 物理层面、硬件层面 是如何实现的了。
计算机在内存层面上不会使用 码位 或者 抽象字符。它需要一种物理方式来表现 Unicode 码位,那就是 码元。
!! “码元 是用于 以给定编码格式 对每个字符编码 的一个 二进制位序列”
字符编码 将 抽象的 码位 转换为 物理的 二进制位:码元。换句话说,字符编码 将 Unicode 码位 转换为了 唯一的 码元序列。
常用的 字符编码 有 UTF-8、UTF-16 和 UTF-32 。
大多数 JavaScript 引擎 会使用 UTF-16 编码。这影响了 JavaScript 和 Unicode 的协作方式。现在开始,我们聚焦到 UTF-16。
UTF-16 (全称为:16-bit Unicode Transformation Format)是一种可变长度编码:
- BMP 的 码位 会编码为 1个16位长的码元
- 星光平面的 码位 会编码为 2个16位长的码元
我们枯燥的理论谈的有点多了。现在我们来看一些例子。
假设你想将 LATIN SMALL LETTER A 字符 a 保存到硬盘驱动器。Unicode 会告诉你 抽象字符 LATIN SMALL LETTER A 是映射到 码位 U+0061 的。
现在我们来想想 UTF-16 编码 是如何对 U+0061 做的转换。按照 编码规范,对于 BMP 码位,会提取其中的十六进制数字 0061 并将其存储在 1个16位长的码元:0x0061 。
如你所见,BMP 码位 很适合塞进 1个16位长的码元。
2.4 代理对(Surrogate Pairs)
现在让我们研究一个复杂的例子。假设你想保存一个 星光码位(从星光平面):GRINNING FACE 字符 。这个字符映射为码位 U+1F600 。
由于 星光码位 需要 21个二进制位 来存储信息,按照 UTF-16,需要 2个16位长的码元。码位 U+1F600 会被分割位所谓的 代理对:0xD83D (高位代理码元)和 0xDE00 (低位代理码元)。
!! “代理对 是对那些由2个16位长的码元所组成序列的 单个抽象字符 的表示方式,代理对 中的首个值为 高位代理码元 而第二个值为 低位代理码元。”
一个 星光码位 需要两个 码元,这就是代理对。就像之前的例子中展示的,为了将 U+1F600 (`)编码为 UTF-16,使用的代理对是0xD83D 0xDE00` 。
console.log('\uD83D\uDE00'); // => ''
高位代理码元 从 0xD800 到 0xDBFF 取值。低位代理码元 从 0xDC00 到 0xDFFF 取值。
将 代理对 转换为 星光码位 的算法如下,反之亦然:
function getSurrogatePair(astralCodePoint) {
let highSurrogate =
Math.floor((astralCodePoint - 0x10000) / 0x400) + 0xD800;
let lowSurrogate = (astralCodePoint - 0x10000) % 0x400 + 0xDC00;
return [highSurrogate, lowSurrogate];
}
getSurrogatePair(0x1F600); // => [0xD83D, 0xDE00]
function getAstralCodePoint(highSurrogate, lowSurrogate) {
return (highSurrogate - 0xD800) * 0x400
+ lowSurrogate - 0xDC00 + 0x10000;
}
getAstralCodePoint(0xD83D, 0xDE00); // => 0x1F600代理对 用起来可不舒服。在 JavaScript 中处理字符串时,你必须将它们当作特殊情况处理,我会稍后在文章里谈谈这部分。
然而,UTF-16 是内存高效的。我们平时需要处理字符中有 99% 都来自 BMP,只需要一个码元。
2.5 组合符号(Combining Marks)
!! “字位(grapheme,又称 形素、字素),或 符号(symbol),对一些书写系统来说 是最小的构成单位”
字位 就是用户对于一个字符的理解。字位 在显示器上的具体图像称为 字形(glyph)。
在绝大多数情况下,单个 Unicode 字符表示 单个的 字位。例如 U+0066 LATIN SMALL LETTER F 就写作 f 。
但也存在 单个字位 包含一系列 字符 的情况。
例如,å 在丹麦书写系统中是一个原子性的 字位。展示它需要使用 U+0061 LATIN SMALL LETTER A (渲染为 a) 组合一个特殊字符 U+030A COMBINING RING ABOVE (渲染为 ◌̊)。
U+030A 对前面的字符进行了修改,它叫做 组合字符。
console.log('\u0061\u030A'); // => 'å'
console.log('\u0061'); // => 'a'!! “组合字符 是一种在位置在前的 基本字符 上创建 字位 的 字符”
组合字符 包含 重音符号、变音符号、希伯来语点、阿拉伯元音符号 和 印度matras。
组合符号 通常不会独立使用(即没有字符作为基础时)。你应当避免独立使用它们。
就和 代理对 一样,组合符号 在 JavaScript 中也很难处理。
组合字符序列 (基本字符 + 组合字符)会被用户认为是单个符号(例如 '\u0061\u030A' 就是 'å')。但开发者必须使用 2 个 码位 U+0061 和 U+030A 来构造 å 。

3 . JavaScript 中的 Unicode
ES2015 规范 提到 ,源码文本使用 Unicode (版本 5.1 以上)。源码文本是一个从 U+0000 到 U+10FFFF 的码位序列。源码 存储 和 数据交换 的格式在 ECMAScript 规范中没有提到,但通常会使用 UTF-8 编码(Web 的首选编码)。
我建议保留源码中 Unicode 基本拉丁字母块(或者 ASCII)中的字符。超出 ASCII 的字符应该被转义。
深入下去,在语言层面,ECMAScript 2015 提供了 JavaScript 中 String 的明确定义:
!! “String 类型是由零个或多个 16 位无符号整数值(“元素”)组成的所有有序序列的集合,最大长度为 个元素。 String 类型通常用于表示运行中 ECMAScript 程序的文本数据,这时,String 中的每个元素都被视为一个 UTF-16 码元 值。”
字符串中的每个元素都会被引擎解析为一个码元。字符串的渲染方式不会提供一种确定的方法来决定其包含的码元(所表示的码位)。看下面这个例子:
console.log('cafe\u0301'); // => 'café'
console.log('café'); // => 'café''cafe\u0301' 和 'café' 从字面上看,码元略有不同,但两者都会渲染出相同的符号序列 café 。
在之前的 代理对 和 组合符号 这两章,我们知道,一些符号需要 2个 或 更多 码元来表示。因此在计算字符数量 或 通过索引访问字符时,你要小心仔细,做好预防工作:
const smile = '\uD83D\uDE00';
console.log(smile); // => ''
console.log(smile.length); // => 2
const letter = 'e\u0301';
console.log(letter); // => 'é'
console.log(letter.length); // => 2smile 字符串包含2个码元:\uD83D(高位代理) 和 \uDE00 (低位代理)。由于字符串就是一个码元序列,所以 smile.length 就会得出 2。即使 字符串 smile 只渲染出一个符号 ``。
我建议,始终将 JavaScript 中的字符串理解为码元序列。渲染字符串的方式无法清晰地说明其包含的码元。
星光平面的符号 和 组合符号序列 需要 2个 或 更多码元 进行编码。但只会被当作单一的字位。
如果 字符串 中包含 代理对 和 组合符号,开发者在不知情的情况下可能会在 字符串长度的计算 和 用索引访问字符 时感到困惑。
大多数 JavaScript 字符串方法都不是 “Unicode 感知”(Unicode-aware) 的。如果你的字符串中包含 Unicode 复合字符,在调用 myString.slice() ,myString.substring() 这些方法时,请做好防范。
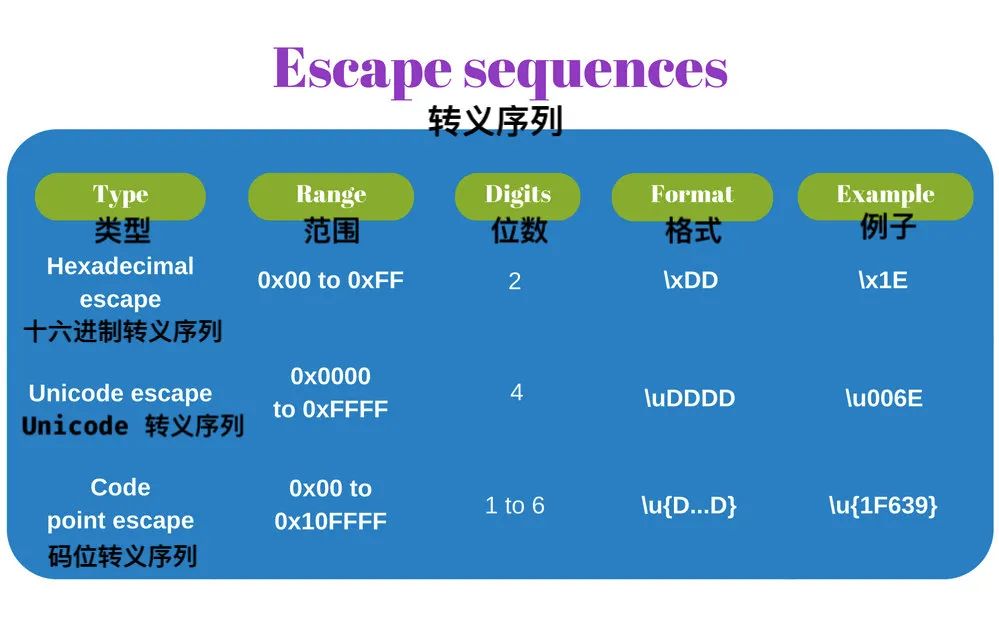
3.1 转义序列(Escape Sequences)
JavaScript 字符串 的 转义序列 是基于 码位数字 来表示 码元 的。JavaScript 提供了 3 种转义类型,其中一种是在 ECMAScript 2015 中引入。
我们来看更多细节。
十六进制转义序列
转义序列最短的形式叫做 十六进制转义序列:\x<hex> ,其中 \x 时前缀,后面跟着的是长度固定为2位的十六进制数字 <hex> 。例如,'\x30'(符号 '0'),'\x5B'(符号 '[')。
十六进制转义序列 的 字符串字面量 和 正则表达式 写法是这样的:
const str = '\x4A\x61vaScript';
console.log(str); // => 'JavaScript'
const reg = /\x4A\x61va.*/;
console.log(reg.test('JavaScript')); // => true因为只能使用 2 位,所以十六进制转义序列 只能转义有限范围内的码位:U+00 到 U+FF 。但它的优点在于短。
Unicode 转义序列
如果你想转义整个 BMP 的码位,那你就应该使用 ** Unicode 转义序列**。其转义格式为 \u<hex>,其中 \u 为前缀,后面跟着一个长度固定为4位的十六进制数字 <hex> 。例如,'\u0051'(符号 'Q'),'\u222B'(积分符号 '∫')。
我们来用用看 Unicode 转义序列:
const str = 'I\u0020learn \u0055nicode';
console.log(str); // => 'I learn Unicode'
const reg = /\u0055ni.*/;
console.log(reg.test('Unicode')); // => true因为只能使用 4 位, Unicode 转义序列 可以转义有限范围内的码位:U+0000 到 U+FFFF (BMP的全部码位),大多数情况下,这已经足够表示那些常用的符号了。
想要再 JavaScript 字面量 中表示一个 星光平面中的符号,需要使用两个连接在一起的 Unicode 转义序列(高位代理 和 低位代理),这就创建了一个 代理对:
const str = 'My face \uD83D\uDE00';
console.log(str); // => 'My face '码位转义序列
ECMAScript 2015 提供了能够表示整个 Unicode 空间(U+0000 到 U+10FFFF) 码位 的 转义序列:即 BMP 和 星光平面。
新的更是被称作 码位转义序列:\u{<hex>} ,其中 <hex> 是一个长度为 1 到 6 位 的十六进制数字 。例如,'\u{7A}'(符号 'z'),'\u{1F639}'(滑稽猫符号 '')。
看看如何再字面量中使用它:
const str = 'Funny cat \u{1F639}';
console.log(str); // => 'Funny cat '
const reg = /\u{1F639}/u;
console.log(reg.test('Funny cat ')); // => true注意,正则表达式 /\u{1F639}/u 中有一个特殊的标志 u ,这是用来开启附加的 Unicode 特性的(详见 3.5 正则表达式匹配)。
我喜欢通过 码位转义 来避免使用 代理对 来表示 星光平面的符号。我们来转义 U+1F607 SMILING FACE WITH HALO 码位:
const niceEmoticon = '\u{1F607}';
console.log(niceEmoticon); // => ''
const spNiceEmoticon = '\uD83D\uDE07'
console.log(spNiceEmoticon); // => ''
console.log(niceEmoticon === spNiceEmoticon); // => true赋给变量 niceEmoticon 的字符串字面量是 转义码位 \u{1F607} ,表示的是星光平面的码位 U+1F607 。不过,其实在底层 码位转义 还是创建了一个 代理对(2个码位)。正如你看到的,spNiceEmoticon 使用 Unicode 转义 '\uD83D\uDE07' 创建了一个代理对,是等同于 niceEmoticon。
RegExp 构造函数创建的,必须在字符串字面量中将 \ 替换为 \\ 来做 Unicode 转义。下面这些正则表达式对象是等价的:
const reg1 = /\x4A \u0020 \u{1F639}/;
const reg2 = new RegExp('\\x4A \\u0020 \\u{1F639}');
console.log(reg1.source === reg2.source); // => true3.2 字符串比较
JavaScript 中的字符串 是 码元序列。那么,我们有理由认为 字符串比较 会涉及对码元的计算,这样的话,比较字符串 就是在比较 两个字符串中包含的码元是否一致。
这种方式快速高效。可以很好的处理 “简单的” 字符串:
const firstStr = 'hello';
const secondStr = '\u0068ell\u006F';
console.log(firstStr === secondStr); // => truefirstStr 和 secondStr 字符串是相同的码元序列。
假设你想比较两个渲染出来相同,但包含不同码元序列的字符串。那么你也许会得到一个意想不到的结果,字符串 看起来相同 但 比较结果是不相等:
const str1 = 'ça va bien';
const str2 = 'c\u0327a va bien';
console.log(str1); // => 'ça va bien'
console.log(str2); // => 'ça va bien'
console.log(str1 === str2); // => falsestr1 和 str2 渲染看起来相同,但码元不同。之所以会发生这种情况,字位 ç 是通过两种不同的方式构造的:
- 使用
U+00E7LATIN SMALL LETTER C WITH CEDILLA - 另一种使用 组合字符序列:
U+0063LATIN SMALL LETTER C 加 组合符号U+0327COMBINING CEDILLA。
如何处理这种情况并正确比较字符串?答案是字符串 正规化(Normalization)。
正规化(Normalization)
!! “正规化 就是将字符串转换为规范的表示形式,以确保 标准等价(canonical-equivalent)和/或 兼容等价(compatibility-equivalent)的 字符串 有标准的表示形式。”
换句话说,当字符串结构复杂(包含组合字符序列 或 其他复杂结构),可以 将它 正规化 得到规范格式。正规化的字符串可以无痛 比较 或 执行文字搜索等字符串操作,以此类推。
Unicode 附加标准 #15 提供了 正规化 过程中有趣的细节。
在 JavaScript 正规化 字符串 可以调用myString.normalize([normForm]) 方法,该方法在 ES2015 中可用。normForm 是一个可选参数(默认为 'NFC'),其值也可以是一下 正规化 格式:
'NFC'为 Normalization Form Canonical Composition'NFD'为 Normalization Form Canonical Decomposition'NFKC'为 Normalization Form Compatibility Composition'NFKD'为 Normalization Form Compatibility Decomposition
我们通过应用字符串正规化来改进之前的例子,这能帮助我们正确的比较字符串:
const str1 = 'ça va bien';
const str2 = 'c\u0327a va bien';
console.log(str1 === str2.normalize()); // => true
console.log(str1 === str2); // => false'ç' 和 'c\u0327' 是 标准等效 的。当调用 str2.normalize() 时,会返回标准版本的 str2('c\u0327' 被替换为 'ç')。因此比较 str1 === str2.normalize() 就会和预期一样返回 true。str1 不受 正规化 影响,因为它已经是规范形式了。
将两个比较的字符串都 正规化,得到两个操作数的规范表示是非常合理的。
3.3 字符串长度
当然,确定字符串长度最常用的方式,就是访问 myString.length 属性。这个属性可以等到一个字符串所拥有的码元数量。
只包含 BMP 中 码位 的字符串确实可以使用这种计算方式 来得到预期结果。
const color = 'Green';
console.log(color.length); // => 5color 中每一个 码元 对应一个单独的 字位。字符串预期长度为 5 。
长度 与 代理对
当字符串包含 代理对 (为了表示 星光平面的码位)时,情况就变得棘手了。因为每个 代理对 包含 2 个 码元(一个高位代理,一个低位代理),因此 length 属性会比预期大。
看下面这个例子:
const str = 'cat\u{1F639}';
console.log(str); // => 'cat'
console.log(str.length); // => 5字符串 str 渲染后,包含 4 个符号 cat。然而 smile.length 得出结果是 5,这是因为 U+1F639 是一个星光平面的码位,被编码成了2个码元(一个代理对)。
很不幸,目前还没有一种原生且高效的方式来解决这个问题。
不过至少 ECMAScript 2015 引入了感知 星光平面符号 的算法。星光平面的符号 即使被编码为 2 个码元,也会被计算为单个字符。
字符串迭代器 String.prototype[@@iterator]() 是 Unicode 感知 的。你可以通过 展开运算符 [...str] 或 Array.from(str) 函数(两者底层都会调用字符串迭代器)来。然后计算返回数组的符号数量。
注意,这种解决如果广泛使用可能会导致性能问题。
我们来通过 展开运算符 来改进之前的例子:
const str = 'cat\u{1F639}';
console.log(str); // => 'cat'
console.log([...str]); // => ['c', 'a', 't', '']
console.log([...str].length); // => 4[...str] 会创建一个包含 4 个符号的数组。 表示 U+1F639 CAT FACE WITH TEARS OF JOY 的 代理对会保持完整,因为字符串迭代器是 Unicode 感知的。
长度 和 组合符号
那组合符号序列该怎么处理呢?因为每个组合符号是一个码元,所以会遇到相同的问题。
利用 字符串正规化 就能解决这个问题。如果足够幸运,组合字符序列 会被 正规化 为单个字符。我们来试试:
const drink = 'cafe\u0301';
console.log(drink); // => 'café'
console.log(drink.length); // => 5
console.log(drink.normalize()) // => 'café'
console.log(drink.normalize().length); // => 4drink 字符串包含 5 个码元(因此 drink.length 得 5),即使它被渲染为了 4 个符号。
drink 正规化 时,很幸运,组合字符序列 'e\u0301' 存在一个标准形式 'é'。所以 drink.normalize().length 会得到预期的 4。
但不幸的是,正规化 不是一个通用的解决方案。较长的 组合字符序列 并不总是有单个字符的标准等价形式。我们来看个例子:
const drink = 'cafe\u0327\u0301';
console.log(drink); // => 'cafȩ́'
console.log(drink.length); // => 6
console.log(drink.normalize()); // => 'cafȩ́'
console.log(drink.normalize().length); // => 5drink 有 6 个码元,drink.length 得 6 。然而 drink 有 4 个符号。
正规化 drink.normalize() 将 组合序列 'e\u0327\u0301' 转换成了 两个字符的标准形式 'ȩ\u0301' (只消去了一个组合符号)。很可悲,drink.normalize().length 得到了 5,仍然不能表示出正确的符号个数。
3.4 字符定位
由于字符串就是一系列码元,所以通过字符串索引来访问字符也是存在一些难题的。
如果字符串只包含 BMP 字符(不包含 U+D800 到 U+DBFF 高位代理 和 U+DC00 到 U+DFFF 的 低位代理),字符定位可以正常运行。
const str = 'hello';
console.log(str[0]); // => 'h'
console.log(str[4]); // => 'o'每个符号都会被编码为单个码元,因此通过索引访问是 OK 的。
字符定位 与 代理对
一旦字符串包含 星光平面的符号 时,情况就不一样了。
星光平面的符号 使用 2 个码元进行编码(代理对)。所以通过索引访问字符串中的字符,可能会得到分离的 高位代理 或者 低位代理,这些东西都不是有效的符号。
const omega = '\u{1D6C0} is omega';
console.log(omega); // => ' is omega'
console.log(omega[0]); // => '' (无法打印的字符)
console.log(omega[1]); // => '' (无法打印的字符)因为 U+1D6C0 MATHEMATICAL BOLD CAPITAL OMEGA 是星光平面的字符,它会被编码为包含两个码元的代理对。omega[0] 会访问到 高位代理码元,omega[1] 会访问到 低位代理码元,代理对 被破坏分解了。
存在 2 种在字符串中正常访问 星光平面符号 的方法:
- 使用 Unicode 感知 的 字符串迭代器 生成符号数组
[...str][index] - 通过调用
number = myString.codePointAt(index)拿到 码位数字,然后通过String.fromCodePoint(number)将数字转换为符号。(推荐选项)
我们来试试看这两种方法:
const omega = '\u{1D6C0} is omega';
console.log(omega); // => ' is omega'
// Option 1
console.log([...omega][0]); // => ''
// Option 2
const number = omega.codePointAt(0);
console.log(number.toString(16)); // => '1d6c0'
console.log(String.fromCodePoint(number)); // => ''[...omega] 返回 omega 包含的符号数组。代理对被正确计算了,因此能够如预期一般访问第一个字符。[...smile][0] 是 ''。
omega.codePointAt(0) 方法调用 是 Unicode 感知的,所以会返回 omega 中第一个字符的 星光码位数字 0x1D6C0。函数 String.fromCodePoint(number) 会基于码位数字返回符号:''。
字符定位 与 组合符号
包含 组合符号 的字符串 进行 字符定位 时 也会有相同的问题。
通过字符串索引访问字符 就相当于 访问码元。然而,组合符号序列 应当被当作一个整体访问,而不应该被分离多个码元。
下面这个例子说明了这个问题:
const drink = 'cafe\u0301';
console.log(drink); // => 'café'
console.log(drink.length); // => 5
console.log(drink[3]); // => 'e'
console.log(drink[4]); // => ◌́drink[3] 只会访问到 基本字符 e,而不会带上 组合字符 U+0301 COMBINING ACUTE ACCENT (渲染为 ◌́)。drink[4] 会访问到独立的 组合字符 ◌́。
这种情况可以将字符串 正规化。U+0065 LATIN SMALL LETTER E 加上 U+0301 COMBINING ACUTE ACCENT 的 组合字符序列 存在 标准等价形式 U+00E9 LATIN SMALL LETTER E WITH ACUTEé 。我们来改进前面的代码示例:
const drink = 'cafe\u0301';
console.log(drink.normalize()); // => 'café'
console.log(drink.normalize().length); // => 4
console.log(drink.normalize()[3]); // => 'é'请注意,并非所有 组合字符序列 都存在 单个字符的标准等价。因此 正规化 并不是一个通用的解决方案。
但幸运的是,这种方式对大部分欧美语言是有效的。
3.5 正则表达式匹配
正则表达式 和 字符串 一样,是基于码元工作的。和之前我提到那些场景类似,代理对 和 组合字符序列 会给正则表达式的使用带来麻烦。
BMP 字符匹配符合预期,因为单一码位表示单一符号:
const greetings = 'Hi!';
const regex = /.{3}/;
console.log(regex.test(greetings)); // => truegreetings 里的 3 个符号被编码为了 3 个码元。正则表达式 /.{3}/ 想要匹配 3 个码元,用于匹配 greetings。
当匹配 星光平面中符号(会被编码为包含 2 个码元的代理对),你可能就会遇到一些问题。
const smile = '';
const regex = /^.$/;
console.log(regex.test(smile)); // => falsesmile 包含 星光平面中的符号 U+1F600 GRINNING FACE。U+1F600 会被编码为代理对 0xD83D 0xDE00。然而,正则表达式 /^.$/ 期望匹配一个码元,所以匹配失败了:regexp.test(smile) 就得 false 了。
当使用 星光平面中的符号 来定义 字符类(Character Classes) 的时候情况会更糟糕,JavaScript 会直接抛出错误:
const regex = /[-]/;
// => SyntaxError: Invalid regular expression: /[-]/:
// Range out of order in character class星光平面中的符号 会被编码为代理对。所以 JavaScript 在正则表达式中会使用码元 /[\uD83D\uDE00-\uD83D\uDE0E]/。每个码元在 pattern 中都被视为分离的元素,因此正则表达式会忽略 代理对 这个概念。因为 \uDE00 大于 \uD83D,所以 字符类 中 \uDE00-\uD83D 这部分就是非法的。因此,错误就产生了。
正则表达式 标志 u
幸运的是,ECMAScript 2015 引入了一个非常有用的 u 标志,它为正则表达式带来了 Unicode 感知 的能力。这个标志开启后,就能够正确处理 星光平面的字符。
你可以在正则表达式中使用 Unicode 转义序列 /u{1F600}/u。这种转义方式的写法是要 短于 高位代理 + 低位代理 的 代理对 /\uD83D\uDE00/ 的。
我们应用 u 标志 来看看 . 运算符()是如何匹配 星光平面的符号的:
const smile = '';
const regex = /^.$/u;
console.log(regex.test(smile)); // => true/^.$/u 正则表达式,因为 u 标志的原因 变得 Unicode 感知 了,现在可以匹配 ``。
开启 u 标志后,也能正常处理 字符类 中的 星光平面符号了:
const smile = '';
const regex = /[-]/u;
const regexEscape = /[\u{1F600}-\u{1F60E}]/u;
const regexSpEscape = /[\uD83D\uDE00-\uD83D\uDE0E]/u;
console.log(regex.test(smile)); // => true
console.log(regexEscape.test(smile)); // => true
console.log(regexSpEscape.test(smile)); // => true[-] 现在可以得到 星光平面符号的范围了。/[-]/u 匹配到了 ``。
正则表达式 与 组合符号
不幸的是,无论在正则表达式中是否使用 u 标志,正则表达式都会将其视为分离的码元。
如果你需要匹配一个 组合字符序列,你必须分别匹配 基本字符 和 组合符号。
看下面的例子:
const drink = 'cafe\u0301';
const regex1 = /^.{4}$/;
const regex2 = /^.{5}$/;
console.log(drink); // => 'café'
console.log(regex1.test(drink)); // => false
console.log(regex2.test(drink)); // => true渲染出的字符串包含 4 个符号 café。
不过,正则表达式 /^.{5}$/ 匹配到了 'cafe\u0301' ,认为其有 5 个元素。
4 . 总结
可能在 JavaScript 中,Unicode 最重要的概念就是:将 字符串 视为 码元序列,那是字符串真正的样子。
一旦开发者将 字符串 理解为由 字位(或符号) 组成,而忽落了 码元序列 的概念,就会产生困惑了。
在处理字符串时,如果包含 代理对 或 组合字符序列,就容易出现一些坑:
- 获取字符串长度
- 字符定位
- 正则表达式匹配
注意,JavaScript 中大部分方法不是 Unicode 感知的:比如 myString.indexOf(),myString.slice() 等等。
ECMAScript 2015 引入了很棒的特性,诸如 字符串 和 正则表达式 中的 码位转义序列 \u{1F600} 。
新的正则表达式标志 u 可以开启 Unicode 感知 的 字符串匹配。这简化了 星光平面中符号 的匹配。
字符串迭代器 String.prototype[@@iterator]() 是 Unicode 感知的。你可以使用 展开运算符 [...str] 或 Array.from(str) 来创建 符号数组,然后就可以在不破坏代理对的条件下,计算字符串长度 或 通过索引访问其中的字符。注意,这些操作会影响性能。
如果你需要更好的方式来处理 Unicode 字符,你可以使用 工具库 punycode 或 generate 来生成专业的正则表达式。
我希望这篇文章能帮助你掌握 Unicode!
你还知道 JavaScript 中 Unicode 其他有趣的点吗?欢迎在下方评论!