B站高可用架构实践
【导读】本文整理了 B 站在云+社区沙龙分享的高可用架构,一起来学习小破站的稳定性实践吧!
流量洪峰下要做好高服务质量的架构是一件具备挑战的事情,从Google SRE的系统方法论以及实际业务的应对过程中出发,分享一些体系化的可用性设计。对我们了解系统的全貌上下游的联防有更进一步的了解。
负载均衡
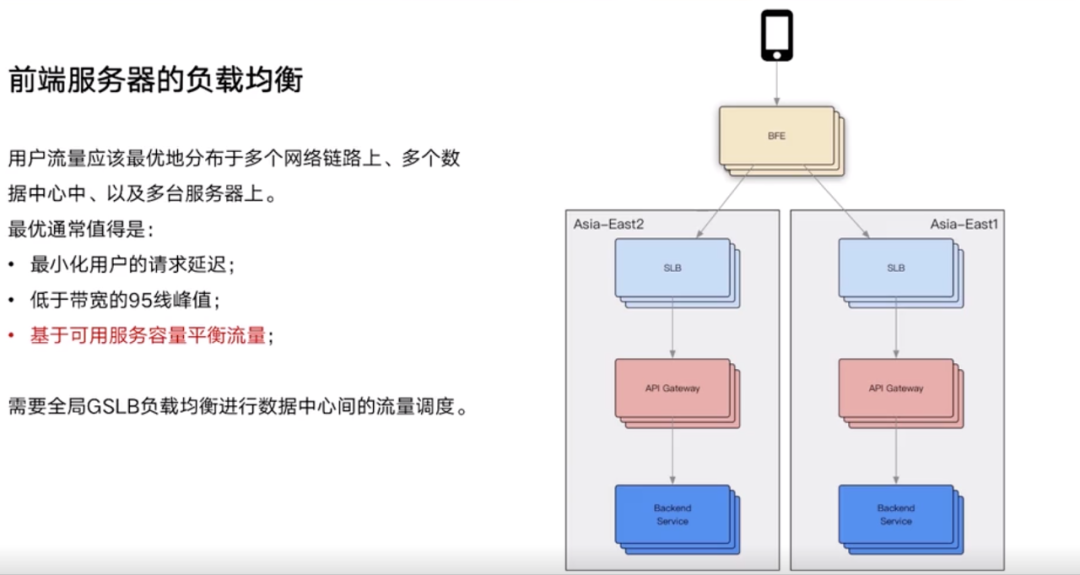
BFE 就是指边缘节点,BFE 选择下游 IDC 的逻辑权衡:
- 离 BFE 节点比较近的
- 基于带宽的调度策略
- 某个 IDC 的流量已经过载,选择另外一个 IDC

当流量走到某个 IDC 时,这个流量应该如何进行负载均衡?
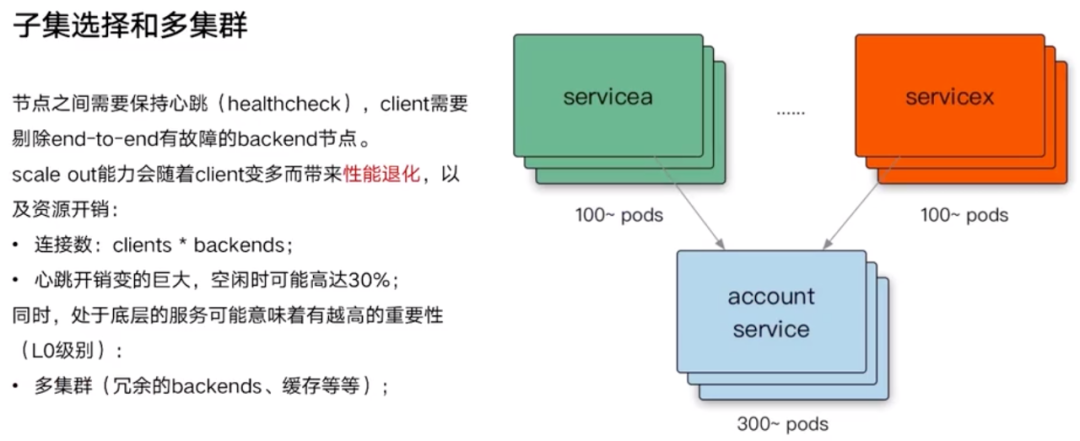
问题:RPC 定时发送的 ping-pong,也即 healthcheck,占用资源也非常多。服务 A 需要与账号服务维持长连接发送 ping-pong,服务 B 也需要维持长连接发送 ping-pong。这个服务越底层,一般依赖和引用这个服务的资源就越多,一旦有任何抖动,那么产生的这个故障面是很大的。那么应该如何解决?
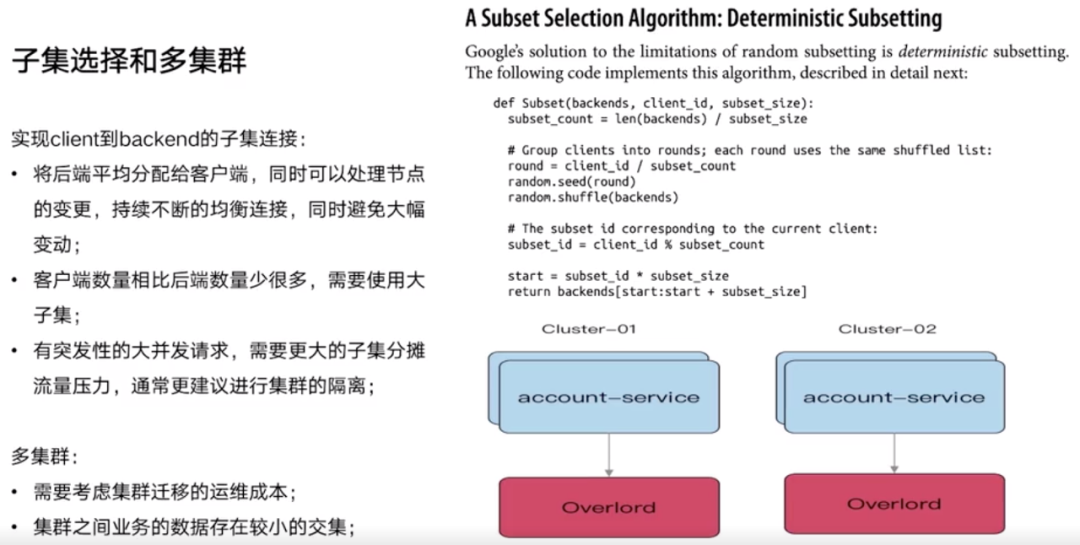
解决:以前是一个 client 跟所有的 backend 建立连接,做负载均衡。现在引入一个新的算法,子集选择算法,一个 client 跟一小部分的 backend 建立连接。图片中示例的算法,是从《Site Reliability Engineering》这本书里看的。
如何规避单集群抖动带来的问题?多集群。
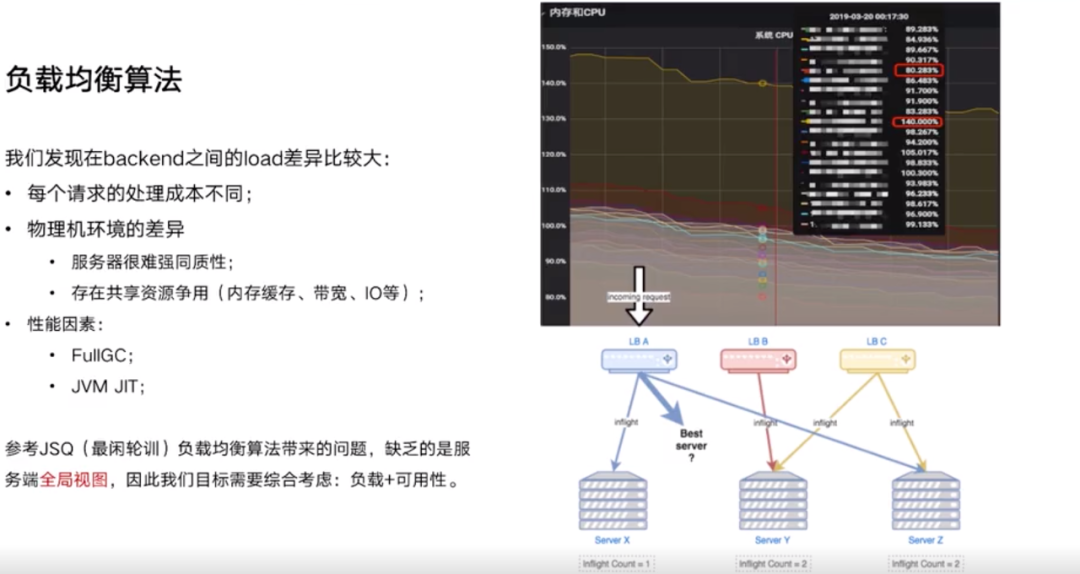
如上述图片所示,如果采用的是 JSQ 负载均衡算法,那么对于 LBA 它一定是选择 Server Y 这个节点。但如果站在全局的视角来看,就肯定不会选择 Server Y 了,因此这个算法缺乏一个全局的视角。
如果微服务采用的是 Java 语言开发,当它处于 GC 或者 FullGC 的时候,这个时候发一个请求过去,那么它的 latency 肯定会变得非常高,可能会产生过载。
新启动的节点,JVM 会做 JIT,每次新启动都会抖动一波,那么就需要考虑如何对这个节点做预热?
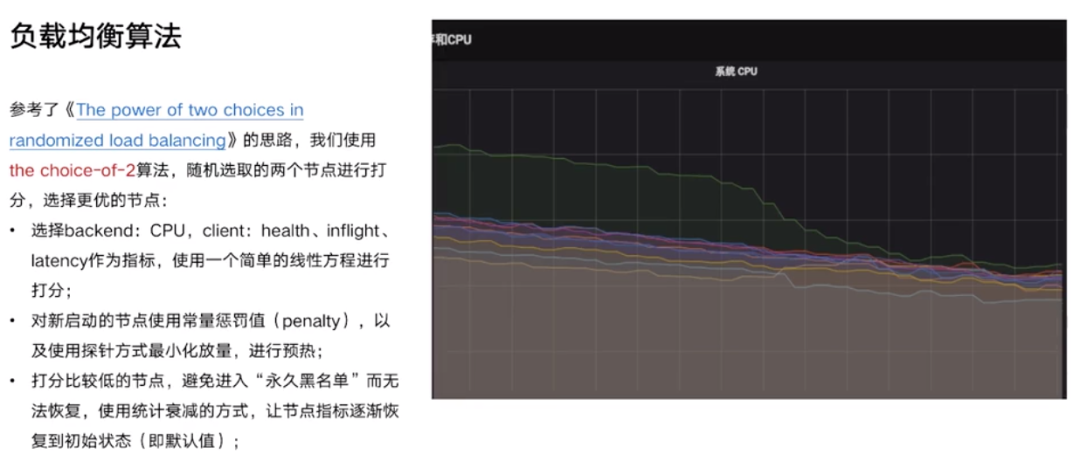
如上图所示,采用 “the choice-of-2” 算法后,各个机器的 CPU 负载趋向于收敛,即各个机器的 CPU 负载都差不多。Client 如何拿到后台的 Backend 的各项负载?是采用 Middleware 从 Rpc 的 Response 里面获取的,有很多 RPC 也支持获取元数据信息等。
还有就是 JVM 在启动的时候做 JIT,以前的预热做法:手动触发预热代码,然后再引入流量,再进行服务发现注册等,不是非常通用。通过改进负载均衡算法,引入惩罚值的方式,慢慢放入流量进行预热。
限流
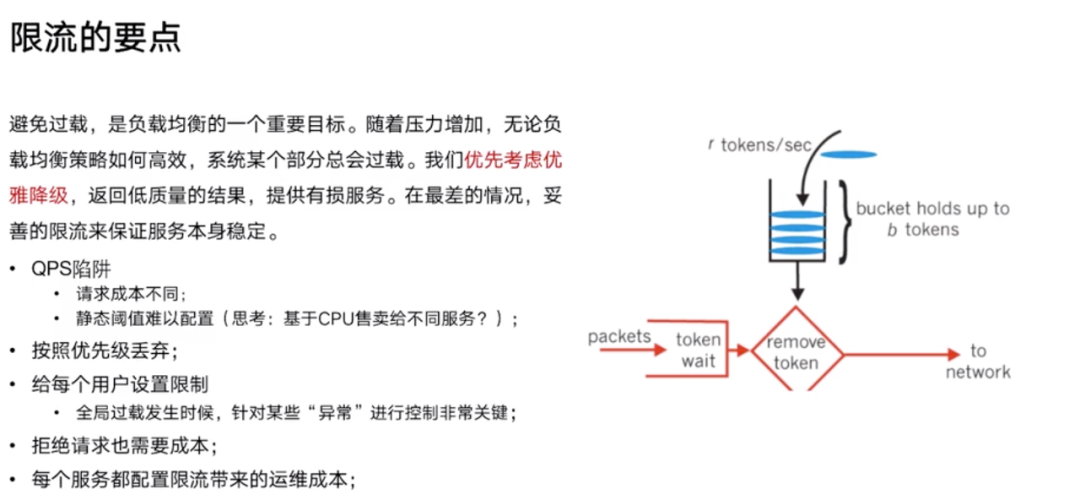
用 QPS 限制的陷阱:
- 不同的参数,请求的数据量是不同的,对一个进程的一个吞吐是有影响的。
- 业务是经常迭代的,配一个静态的阈值,这个非常困难。能否按照每一个服务用多少个 CPU 来做限流?
每一个 API 都是有重要性的:非常重要、次重要,这样配置限流、做过载保护的时候,可以使用不同的阈值。
每个服务都要配一个限流,是非常烦人的,需要压测,是不是可以自适应去限流?
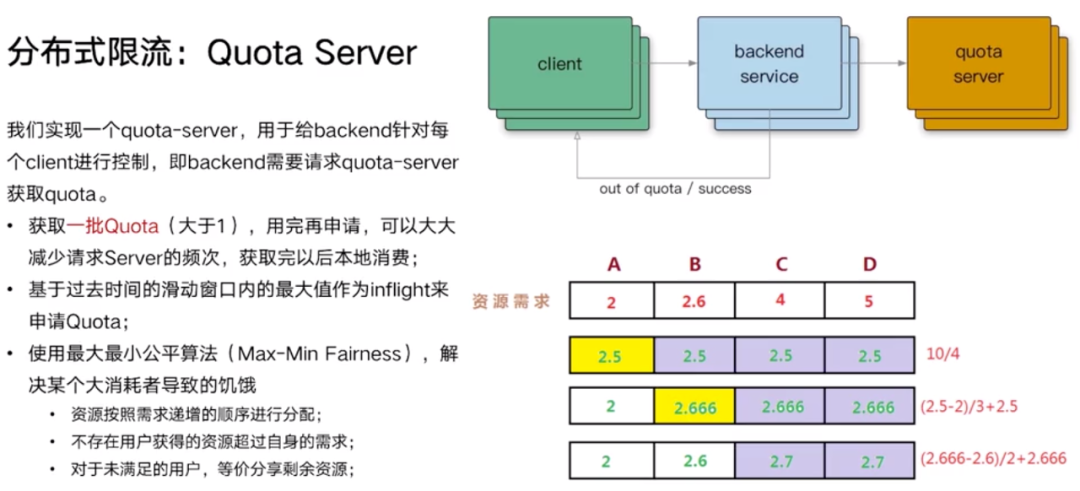
每个 Client 如何知道自己这一次需要申请多少 Quota ?基于历史数据窗口的 QPS。
节点与节点之间是有差异的,分配算法不够好,会导致某些节点产生饥饿。那么可以采用最大最小公平算法,尽可能地比较公平地去分配资源,来解决这个问题。

当量再大一点的时候,如果 Backend 一直忙着拒绝请求,比如发送 503,那么它还是会挂掉。这种情况就要考虑从 Client 去截流。此处,又提到了 Google 《Site Reliability Engineering》这本书里面的一个算法,即 Client 是按照一定概率去截流。那么这个概率怎么计算?一个是总请求量:requests,一个是成功的请求量:accepts。如果服务报错率比较高,意味着 accepts 不怎么增长,requests 一直增长,最终这个公式求极限,它会等于 1,所以它的丢弃概率是非常高的。基于这么一个简单的公式,不需要依赖什么 ZooKeeper,什么协调器之类的,就可以得到一个概率丢弃一些请求。它尽可能的在服务不挂掉的情况下,放更多的流量进去,而不是像 Netflix 一样全部拒掉。
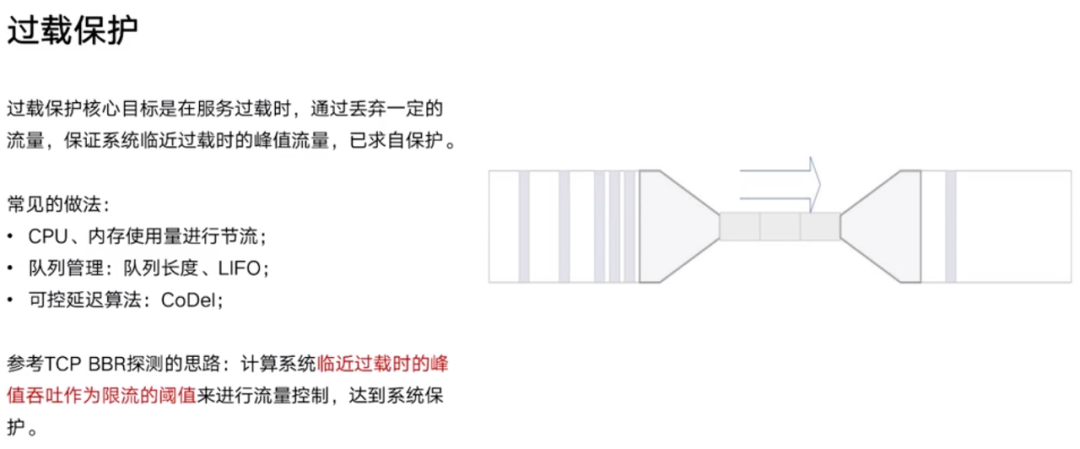
连锁故障通常都是某一个节点过载了挂掉,流量又会去剩下的 n - 1 个节点,又扛不住,又挂掉,所以最终一个一个挨着雪崩。所以过载保护的目的是为了自保。
B 站参考了阿里的 Sentinel 框架、Netflix 的一些文章等,最终采用的是类似于 TCP BBR 探测的思路和算法。简单说:当 CPU 达到 80% 的时候,这个时候我们认为流量过载,如果此时吞吐量比如 100,用它作为阈值,瞬时值的请求比如是 110,那就可以丢掉 10 个流量。这样就可以实现一个限流算法。

CPU 抖来抖去,使用 CPU 滑动均值(绿色线)可以跳动的没有这么厉害。这个 CPU 针对不同接口的优先级,例如低优先级 80% 触发,高优先级 90% 触发,可以定为一个阈值。
那么吞吐如何计算?利特尔法则。当前的 QPS * 延迟 = 吞吐,可以用过去的一个窗口作为指标。一旦丢弃流量,CPU 立马下来,算法抖动非常厉害。图二右侧黄色线表示抖动非常高,绿色线表示放行的流量也是抖动非常高,所以又加了冷却时间,比如持续几秒钟,再重新判断。
重试
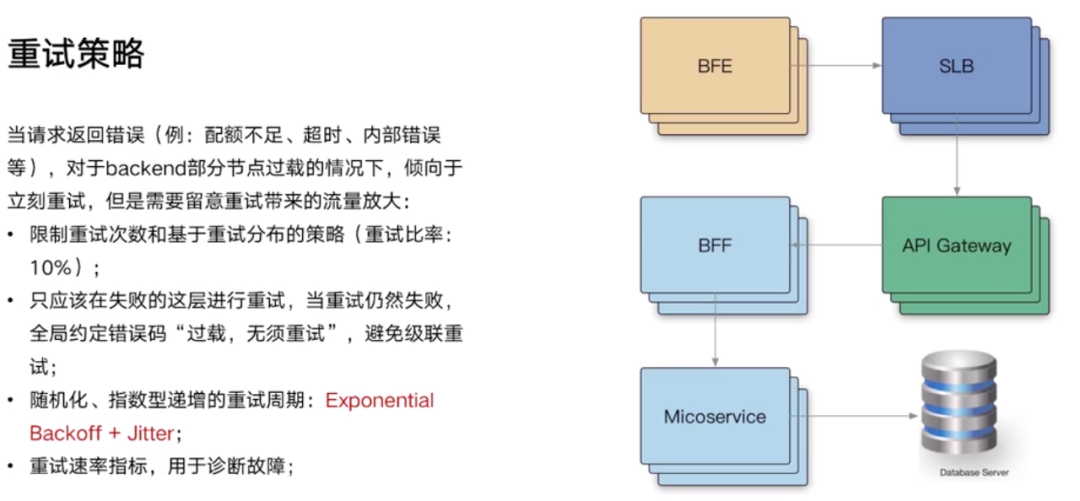
- BFE: 动态 CDN
- SLB: LVS + Nginx 实现,四七层负载均衡
- BFF: 业务逻辑组装、编排
问题:每一层都重试,这一层 3 次,那一层 3 次,会指数级的放大。解决:只在失败这一层重试,如果重试之后失败,请返回一个全局约定好的错误码,比如说:过载,无需重试,发现这个错误码,通通放行,避免级联重试。
重试都应该无脑的重试三次吗?API 级别的重试需要考虑集群的过载情况。是不是可以约定一个重试比例呢?比如只允许 10% 的流量进行重试,Client 端做统计,当发现有 10% 都是重试,那么剩下的都拒绝掉。这样最多产生 1.1 倍的放大,重试 3 次,极端情况下,会产生 3 倍放大。还有在重试的时候,尽量引入随机、指数递增的一个重试周期,大家不要都重试 1 秒钟,有可能会堆砌一个重试的波峰。
重试的统计图和记录 QPS 的图分开。问题诊断的时候,可以知道它是来自流量重试导致的问题放大。
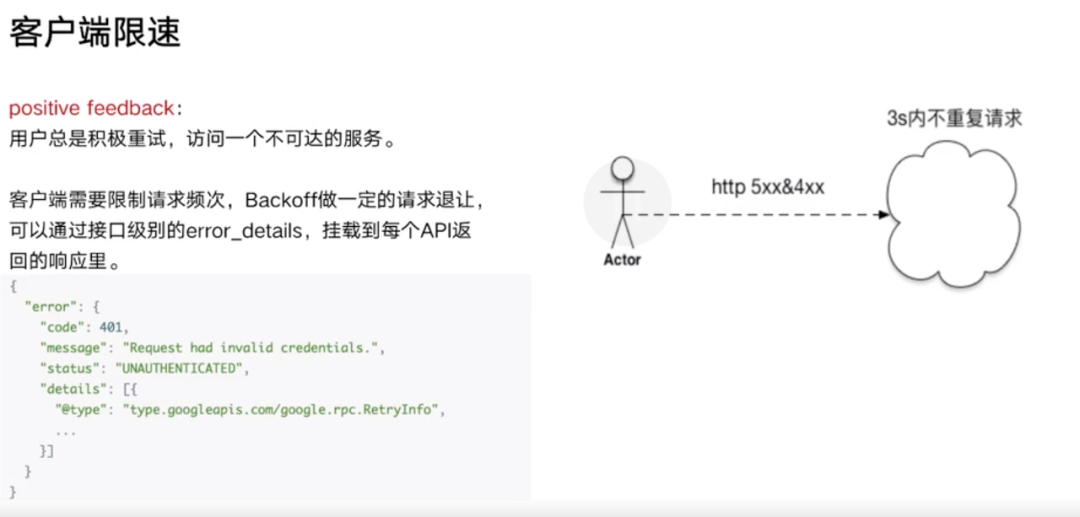
某个服务不可用的时候,用户总是会猛点,那么这个时候,需要去限制它的频次,一个短周期内不允许发重复请求。这种策略,有可能会根据不同的过载情况经常调这种策略,那么可以挂载到每一个 API 里面。
超时
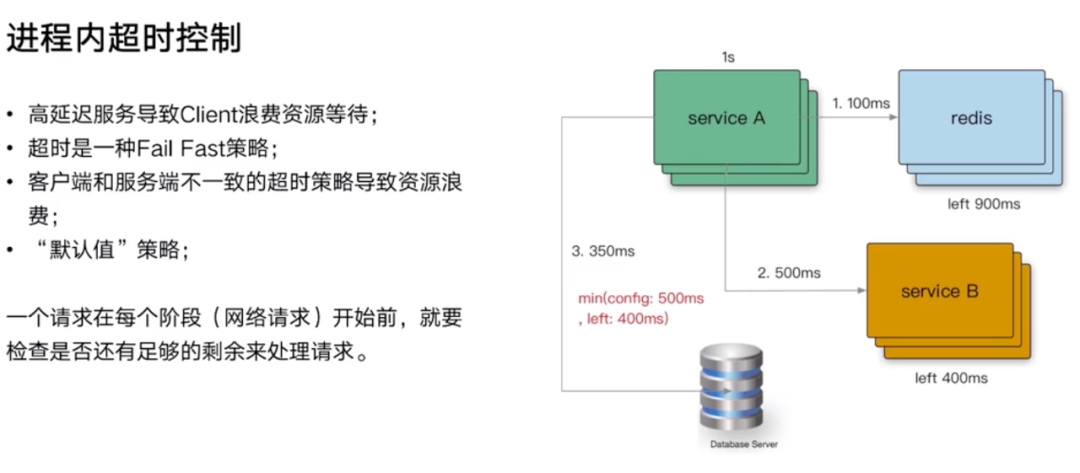
大部分的故障都是因为超时控制不合理导致的。
- 某个高延迟服务可能会导致 Client 堆积,Client 线程会阻塞,上游流量不断进来,下游的消费速度跟不上上游的流入速度,进程会堆积越来越多请求,可能会 OOM。
- 超时的策略本质是就是为了丢弃或者消耗掉请求。
- 下游 2 秒返回,上游配置了 1 秒,上游超时已经返回给用户,下游还在执行,浪费资源。
某个服务需要在 1 秒返回,内部可能需要访问 Redis,需要访问 RPC,需要访问数据库,时间加起来就超过 1 秒,那么访问完每一层,应该计算供下一层使用的超时时间还剩多少可用。在 go 语言里,可能会使用 Context,每一个网络请求开始的阶段,都要根据配置文件配置的超时时间,和当前剩余多少,取一个最小值,最终整个超时时间不会超过 1 秒。
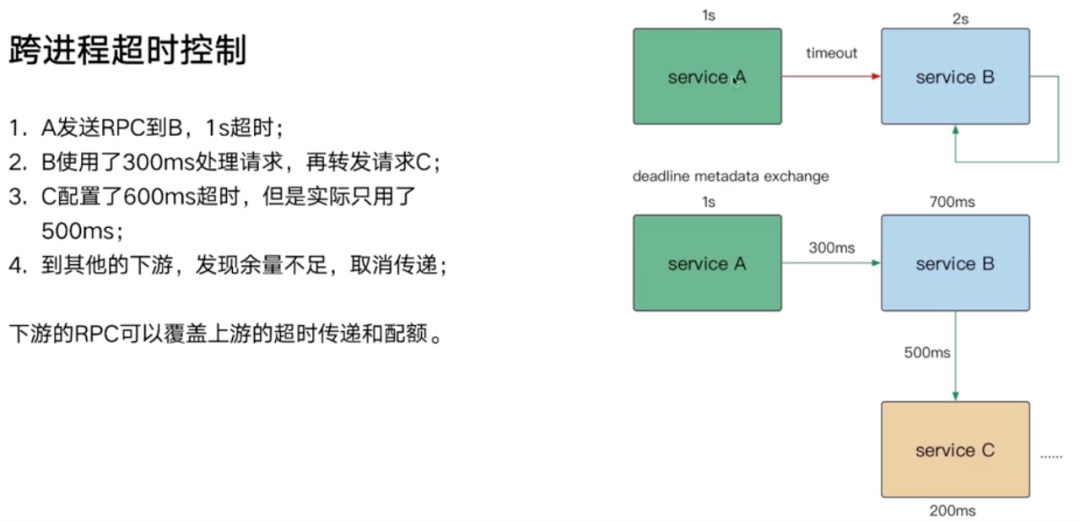
通过 RPC 的元数据传递,类似 HTTP 的 request header,带给其它服务。例如在图中,就是把 700ms 这个配额传递给 Service B。
下游服务作为服务提供者,在他的 RPC.IDL 文件中把自己的超时要配上,那么用 IDL 文件的时候,就知道是 200 ms,不用去问。
应对连锁故障

优雅降级:一开始千人千面,后来只返回热门的
QA
-
Q: 请问负载均衡依据的 metric 是什么?
-
A: 服务端主要用 CPU,客户端用的是健康度,指连接的成功率,延迟也很重要,每个 Client 往不同的 Backend 发了多少个请求,四个指标归一,写一个线性方程,进行打分。
-
-
Q: BFE 到 SLB 走公网还是专线?
-
A: 既有公网,又有专线。
-
-
Q: Client 几千量级,每 10 秒 ping-pong 一下,会不会造成蛮高的 CPU?
-
A: 如果 Backend 很多的话,那么这个的确会造成。
-
-
Q: 多集群切换是否有阻塞的点?
-
A: 一个 Client 连接到各个集群,subset 算法,每个集群都有 Cache
-
-
Q: 负载均衡的探针是怎么做的?
-
A: 惩罚值,比如 5 秒,慢慢放流量
-
-
Q: Quota-Server 限流有开源实现吗?
-
A: 目前看到的都是针对单节点的。
-
-
Q: 客户端统计是否有点太多?
-
A: 可以做到 Sidecar、Service Mesh 里面
-
-
Q: 超时传递是不是太严格?
-
A: 有些情况下即便超时也要运行,可以通过 RPC Context 管控
-
-
Q: 每个 RPC 都获取 CPU 会不会很昂贵?
-
A: 后台开启线程定时计算 CPU 平滑均值
-
-
Q: 线上压测和测试环境压测 CPU 不一致
-
A: RPC 路由加影子库
-
-
Q: CC 攻击
-
A: 边缘节点或者核心机房都有防止 CC 攻击的一些手段,只要不是分布式搞你,都能找到流量特征进行管控