Flutter 流畅度优化实践总结
“围绕 Flutter 流畅度体感优化,分享了挑战、线上线下监控工具建设、优化手段在组件容器沉淀,最后给出了优化建议。"
大纲
本次分享围绕 flutter 流畅度,分别讲述:1.Flutter 流畅度优化挑战;2.列表容器和 FlutterDx 组件优化;3.性能衡量和 devtool 扩展;4.Flutter 滑动曲线优化;5.性能优化建议。
Flutter 流畅度优化挑战
▐ 业务复杂度挑战
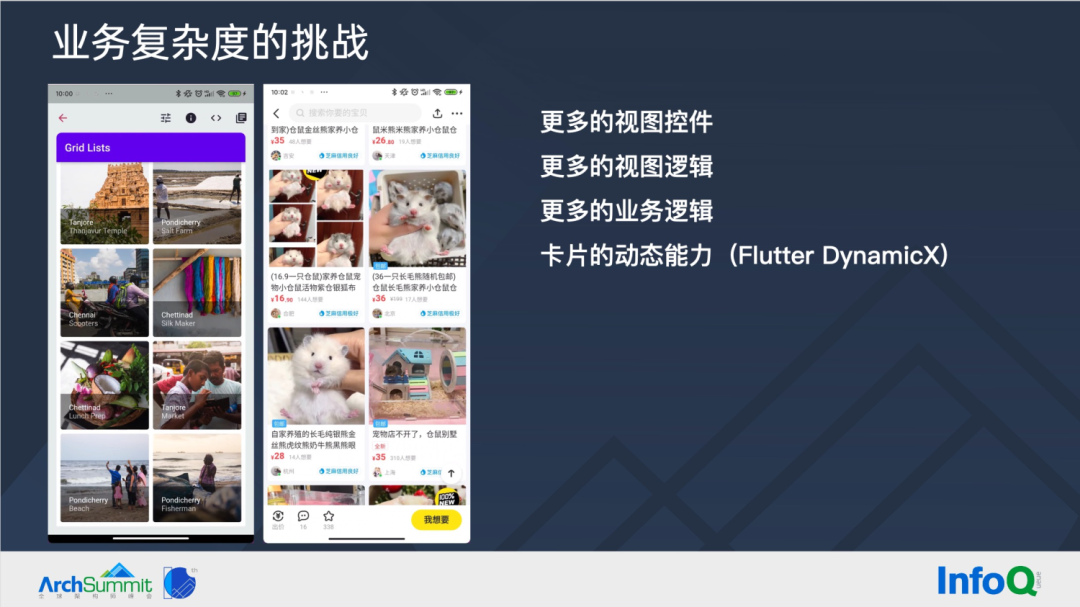
Flutter 一直以高性能被大家所认知,Flutter Gallery(左图所示)展示的列表控件,也确实非常流畅。但实际业务场景(右图所示)比 Gallery 列表 demo 复杂的多:
- 相同的卡片,有更多和复杂(如圆角)的视图控件;
- 列表滚动时,有更多的视图逻辑,如滚动控制其他控件渐显和消失;
- 卡片控件,也有更多的业务逻辑,如基于后台数据控制不同的标签、活动价等,也有埋点等常见业务逻辑;
- 因为闲鱼是电商 App,所以我们需要有一定的动态能力应对频繁多变的活动。这里我们使用阿里自研的 Flutter DynamicX 组件实现我们的动态能力。
▐ 框架实现的挑战
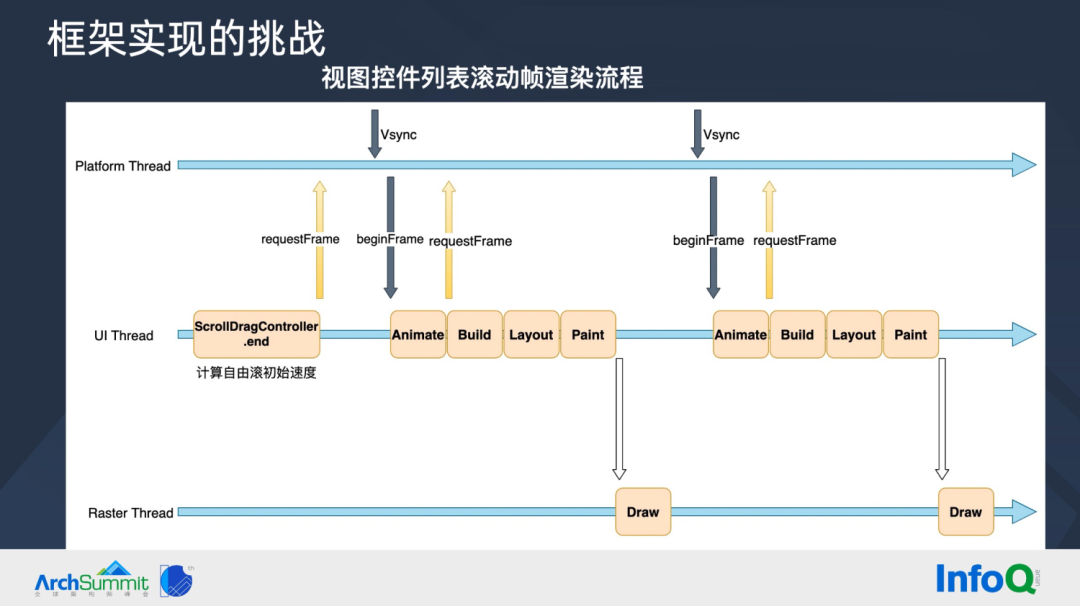
我们再来看列表滚动的整体流程,这里只关注手指放开后的自由滚动阶段。
- 手指松开时,基于 ScrollDragController.end 计算初始速度;
- UI Thread 向 Platform Thread 请求 requestFrame,在 Platform Thread 收到 Vsync 信息,则向 UI Thread 调用 beginFrame;
- UI Thread Animate 阶段触发列表滑动一点距离,同时向 Platform Thread 注册下一帧回调;
- UI Thread Build Widget,再通过 Flutter 三棵树 Diff 算法生成/更新 RenderObject 树;
- UI Thread RenderObject 树 Layout、Paint 生成 Scene 对象,最后传递给 Raster Thread 进行绘制上屏;
上述流程,必须要 16.6 ms 内完成,才能保证不掉帧。大部分情况,不需要构建新的卡片,但当新卡片进入列表区域时,整个计算量就会变得巨大,尤其是在复杂的业务场景下,如何保证在一帧 16.6ms 内完成全部计算,是一个不小的挑战。
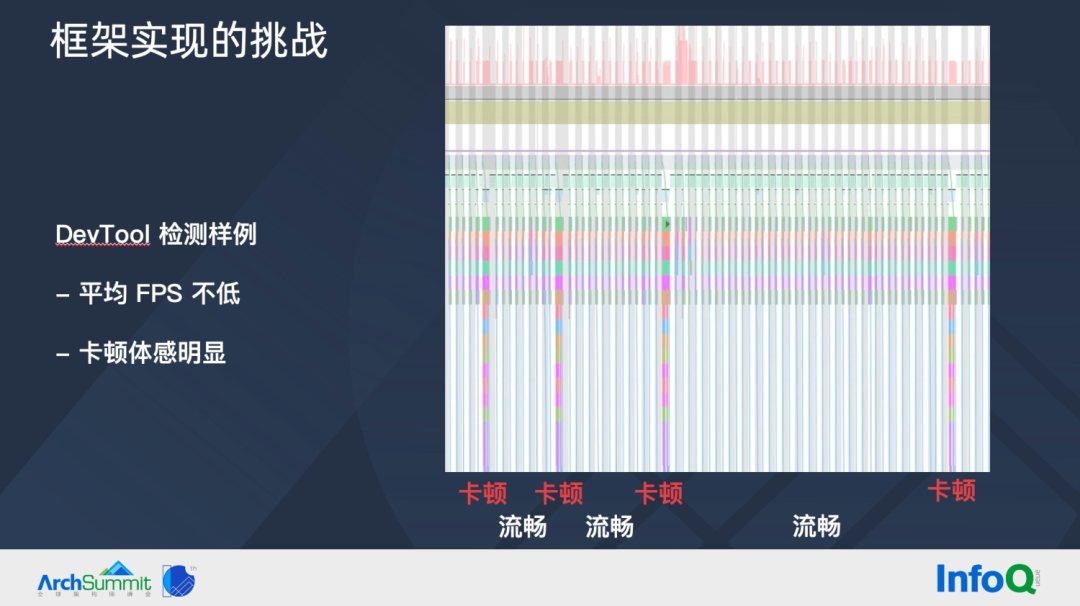
上图是一次滑动 devtool 样例,卡顿阶段都是新卡片上屏时发生,其他阶段均很流畅,因为滚动速度在衰减,所以卡顿间隔也在变大。因为大部分时候都很流畅,所以平均 FPS 不低。但新卡片构建时的产生画面停顿,给我们的卡顿体感却很明显。
▐ 动态能力的挑战 - Flutter DynamicX

闲鱼 App 卡片使用自研 Flutter DynamicX 来支持我们的动态能力。基本原理:在线编辑布局 DSL,生成 dx 文件并下发。端侧通过解析 dx 文件,并结合后台卡片数据,生成 DXComponentWidget,最后生成 Widget Tree。Flutter DynamicX 技术给闲鱼带来动态更新的能力,统一监控能力(如在 DXComponentWidget 监控卡片创建),良好研发体感(在线 DSL 和 Android Layout 基本一致,对 Android 开发优化),在线编辑能力;
但在性能上,我们也付出了一定的代价:DX 卡片相比增加了模板装载和数据绑定开销,Widget 要通过 WidgetNode 递归遍历动态创建,视图嵌套层级会更得更深(后续讲述)。
说明:Flutter DynamicX 参考阿里集团 DSL 规则实现
▐ 用户体感的挑战

前面已经讲述过,相同 FPS 下,Flutter 列表的卡顿体感更明显;
在 Android RecycleView 发生小卡顿(16.6*2ms)时,体感并不明显,而 Flutter 列表在发生卡顿时,不仅时间上停顿,滑动 Offset 上也发生了跳变,为此小卡顿的体感也变得明显了;
假设列表内容足够简单,滚动不会发生卡顿,我们也发现 Flutter 列表和 Android RecycleView 也不太一样:
- 使用 ClampingScrollPhysics,在列表快停止的时候,会感受到类似磁铁吸住的感觉。
- 使用 BouncingScrollPhysics,列表滚动开始时,速度衰减的更快;
在 90hz 机器上,早期 Flutter 列表并不流畅,原因是部分机器上,触控采样率是 120hz,屏幕刷新率是 90hz,导致部分画面是 2 次触控事件,部分是 1 次触控事件,最后导致滚动 offset 发生跳变。在 Flutter 1.22 版本时,可以使用 resamplingEnabled 对触控事件进行重采样。
列表容器和FlutterDx组件优化
讲述了 Flutter 流畅度优化的挑战,现在来分享闲鱼如何优化流畅度,并沉淀进 PowerScrollView 和 Flutter Dynamic 组件。
▐ Power ScrollView 设计和性能优化
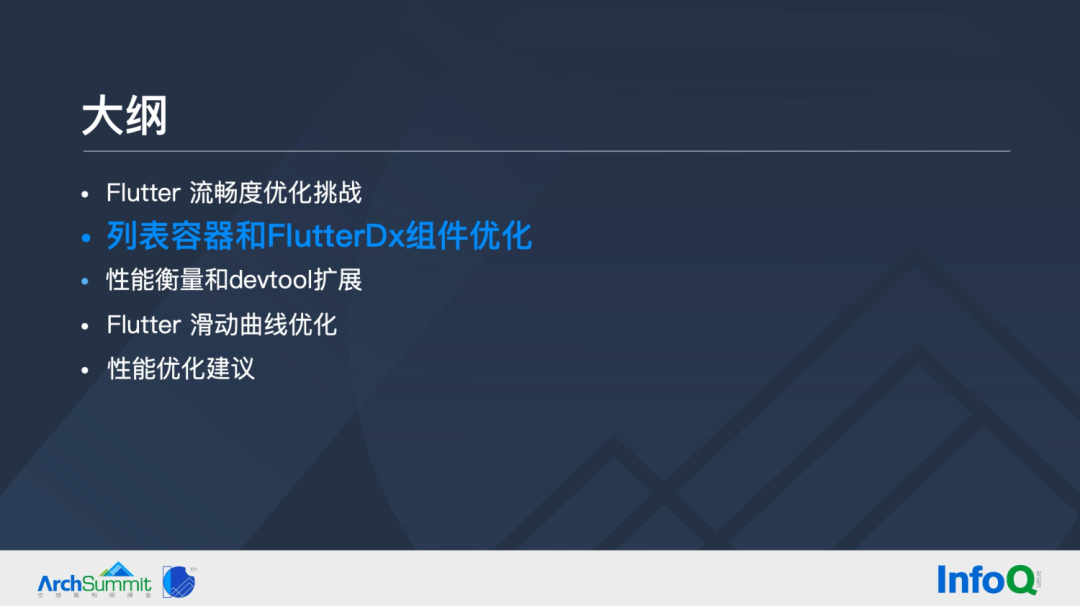
PowerScrollView 是闲鱼团队自研 Flutter 列表组件,在 Sliver 协议上有了更好的封装和补充:数据增删改方面,补充了局部刷新;布局方面,补充了瀑布流;事件方面,补充了卡片上屏、离屏、滚动事件;控制方面,补充了滚动到 index 的能力。
在性能方面,补充了瀑布流布局优化、局部刷新优化、卡片分帧优化和滑动曲线优化。
▐ Powe rScrollView 瀑布流布局
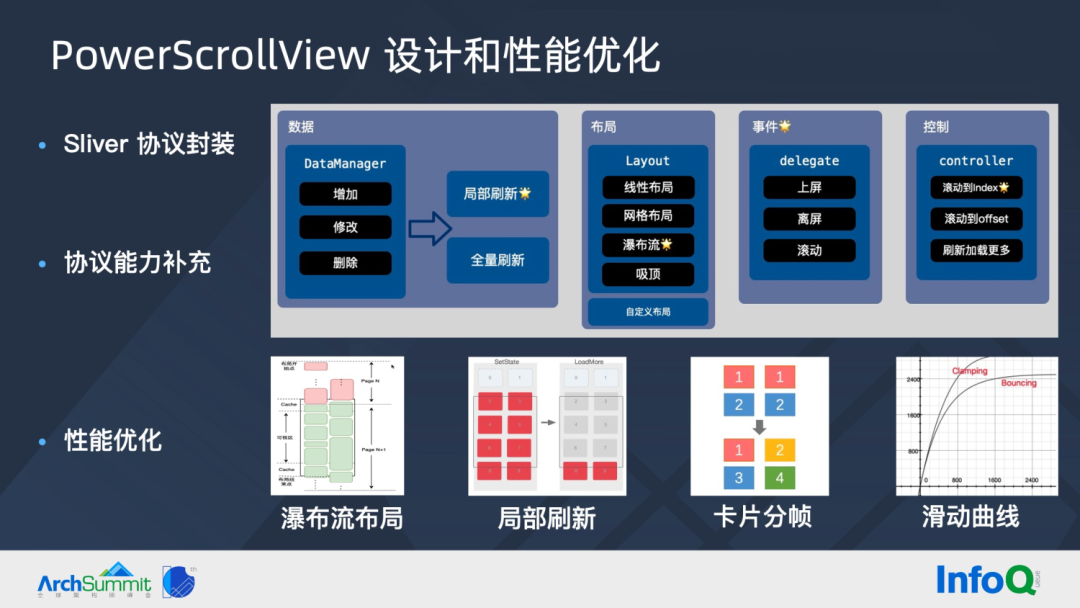
PowerScrollView 瀑布流布局提供了纵向布局、横向布局、混排布局(横向卡片和普通卡片混排)。现在闲鱼大部分列表页面均采用 PowerScrollView 的瀑布流布局,如首页同城页、搜索结果页等。
▐ PowerS crollView 瀑布流布局优化
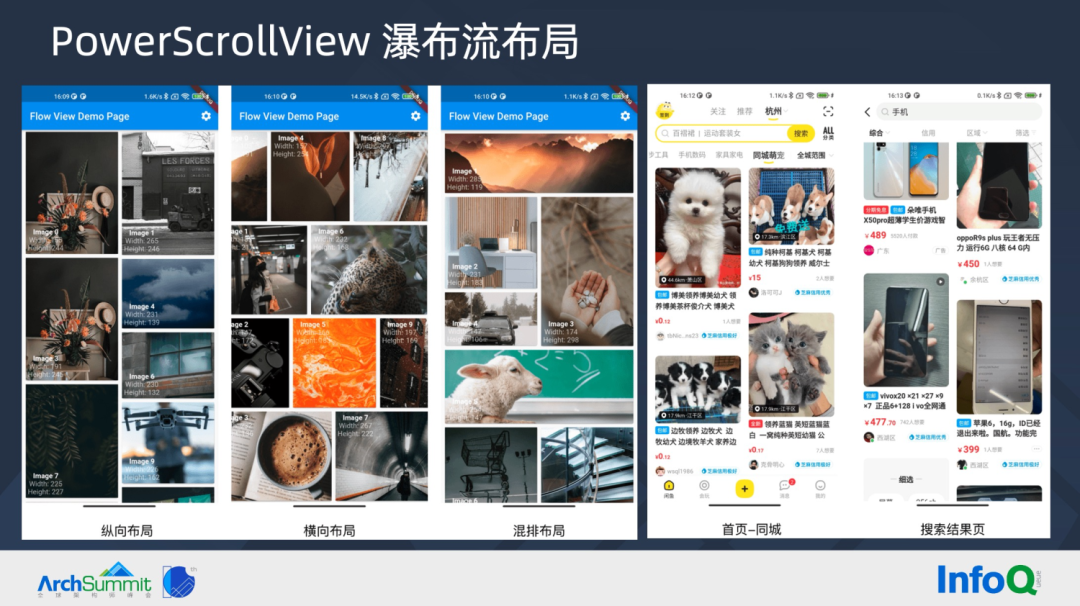
首先通过常规的缓存优化,缓存每个卡片左上角 x 值和属于哪一列。
相比 SliverGrid 卡片是并排进入列表区域,而瀑布流布局,我们需要定义 Page,卡片入场创建和离场销毁需要以 Page 为单位。优化前,Page 以屏幕可视区域为单位计算卡片,同时为了确定 Page 的起点 Y 值,一次布局需要计算 Page N 和 N+1 二页,所以参与布局计算的卡片量较多,性能变低。优化后,使用全部卡片高度平均值的近似值计算 Page,极大减少参与布局卡片的数量,同时 Page 离场销毁的卡片数量也变少。
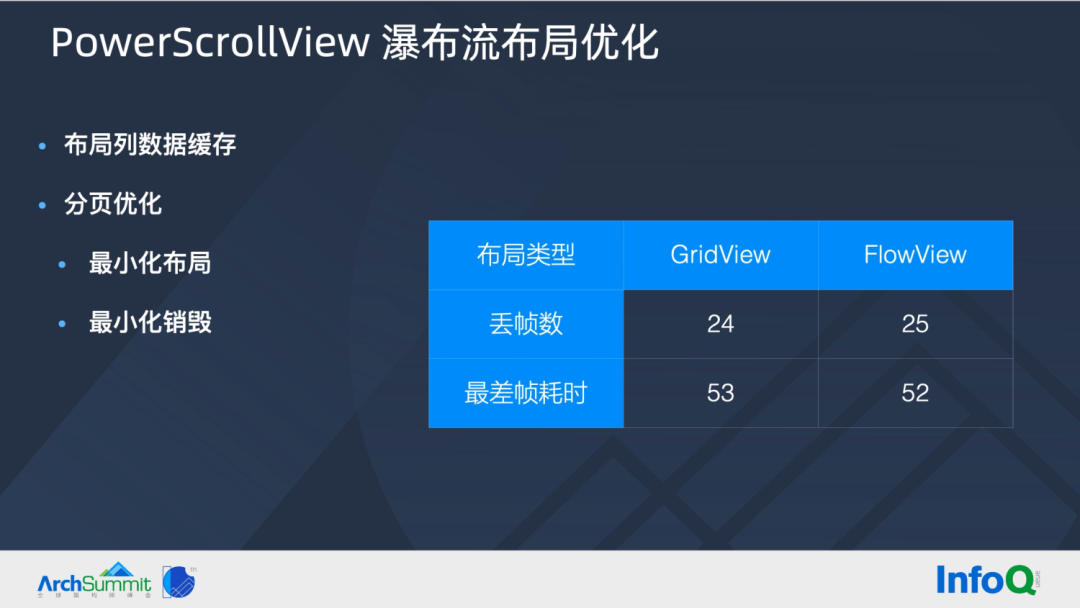
经过列缓存和分页优化,使用闲鱼自研 benchmark 工具(后续介绍)对比瀑布流和 GridView,查看丢帧数和最差帧耗时,能发现性能表现基本一致。
▐ PowerScrollVi ew 局部刷新优化
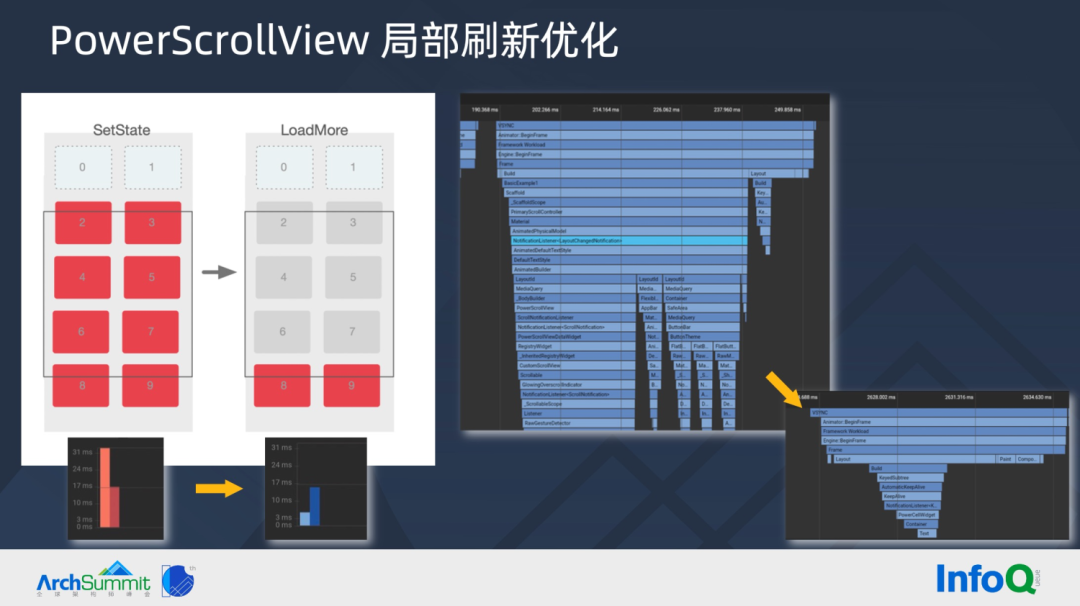
闲鱼产品期望用户浏览商品更流畅,不会被 loadmore 加载打断,所以列表在滚动过程中就需要触发 loadmore。Flutter SliverList 在 loadmore 补充卡片数据时,会对 List 控件标脏,而标脏后 SliverList build 会销毁全部卡片并重新创建,此刻性能数据能想象非常的差。PowerScrollView 提供了布局刷新优化:缓存屏幕上的全部卡片,不再重新创建,UI Thread 耗时从原来的 34ms 优化至 6ms(见左下图),右图查看 Timeline,视图构建的深度和复杂度均有明显优化。
▐ PowerScrollView 卡片分帧优化

左图2个卡片是闲鱼早期搜索结果页,当时还不是瀑布流。查看卡片创建时的 Timeline 图(补充了 Dx Widget 创建 和 PerformLayout 开销),可以发现一次卡片创建的复杂度极大,在普通中端机器上,UI Thread 耗时机已经超出 30ms,要优化至 16.6ms 以内,用常规的优化手段就很困难了。为此想象 2 个卡片能否拆解掉,各自使用 1 帧的时间去渲染。
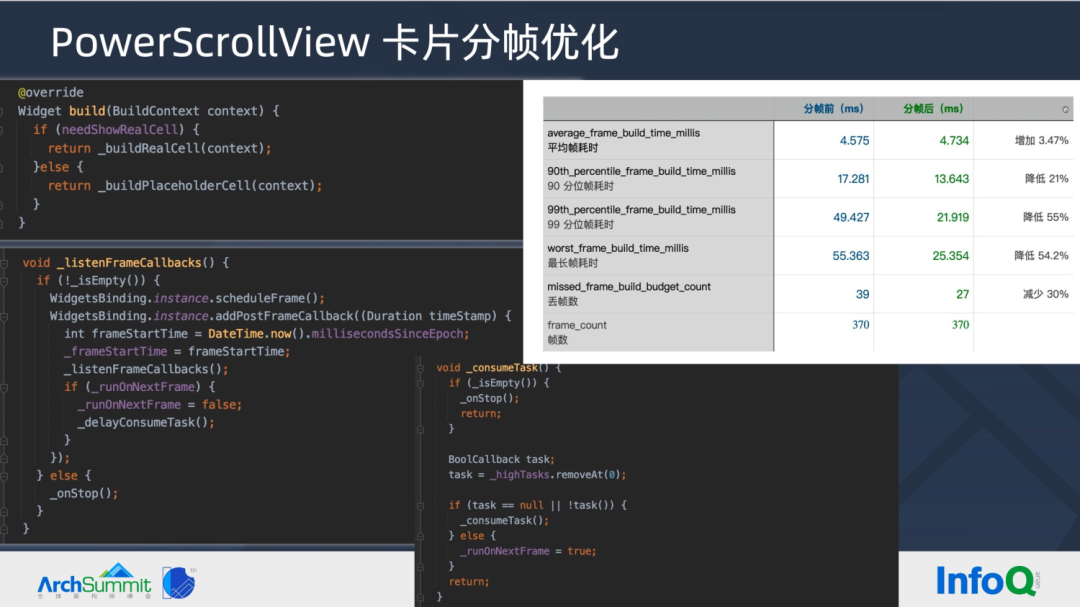
直接看源码,基本思想是:对卡片 Widget 进行标记,在左边卡片真实创建的时候,右边卡片先 _buildPlaceholderCell 构建占位 Widget(空的 Container),并注册监听下一帧。在下一帧,右边卡片进行修改 needShowRealCell 为 true,并自我标脏,此后构建真实内容。 延迟构建卡片真实内容,是否会对显示内容产生影响?因为 Flutter 列表在可视区域上下还有 CacheExtends 区域,这部分区域用户不可见。为此在大部分场景下,用户并不会看到空白卡片的场景。
同样使用 Flutter BenchMark 工具进行性能测试,能看到卡片分帧前后 90分位,99分位帧耗时都有明显的降级,丢帧数也从 39 降低至 27
这里注意,监听下一帧的时候,需要 WidgetsBinding.instance.scheduleFrame() 触发 requestFrame。因为在列表首屏显示的时候,有可能因为没有下一帧的回调,导致延迟显示队列的任务没有执行,最终使得首屏内容显示不正确。
▐ 延迟 分帧优化思路和使用建议

对比 Flutter 和 H5 设计比较接近:
- dart 和 js 都是单线程模型,跨线程通信需要走序列化和反序列化;
- Flutter Widget 和 H5 vDom 类似,都有一个 Diff 过程。
早期 FaceBook 在 React 优化时,提出了 Fiber 架构:基于 vDom tree 的父节点→子节点→兄弟节点→子节点的方式,将 vDom tree 转化为 fiber 数据结构(链式结构),进而实现 reconcile 阶段的可中断可恢复;基于 fiber 数据结构,控制部分 fiber 节点在下一帧继续操作。
基于 React Fiber 思路,我们提出了自己的延迟分帧优化,不只是左右卡片粒度,更进一步,将渲染内容拆解为当前帧任务、高优延迟任务和低优延迟任务,上屏优先级依次变低。其中当前帧任务,是左右 2 个空白 Container;高优延迟任务独占一帧,其中图片部分也使用 Container 占位;在闲鱼场景,我们把全部的 DX Image Widget 从卡片内拆解出来,作为低优延迟任务,并设置在一帧消费不超过 10 个。
通过将 1 帧显示任务拆解到 4 帧时间,高端机上最高 UI 耗时从 18ms 优化至 8ms。
说明1:不同业务场景下,高优任务和低优任务设置要有所不同 说明2:在低端机(如 vivo Y67)上快速列表滑动,分帧方案会让用户看到列表变白和内容上屏的过程
▐ Flu tter-DynamicX组件优化-原理详解

在线编辑“类 Android Layout DSL”,编译生成二进制 dx 文件。端侧通过文件下载、加载和解析,生成 WidgetNode Tree,见右图。
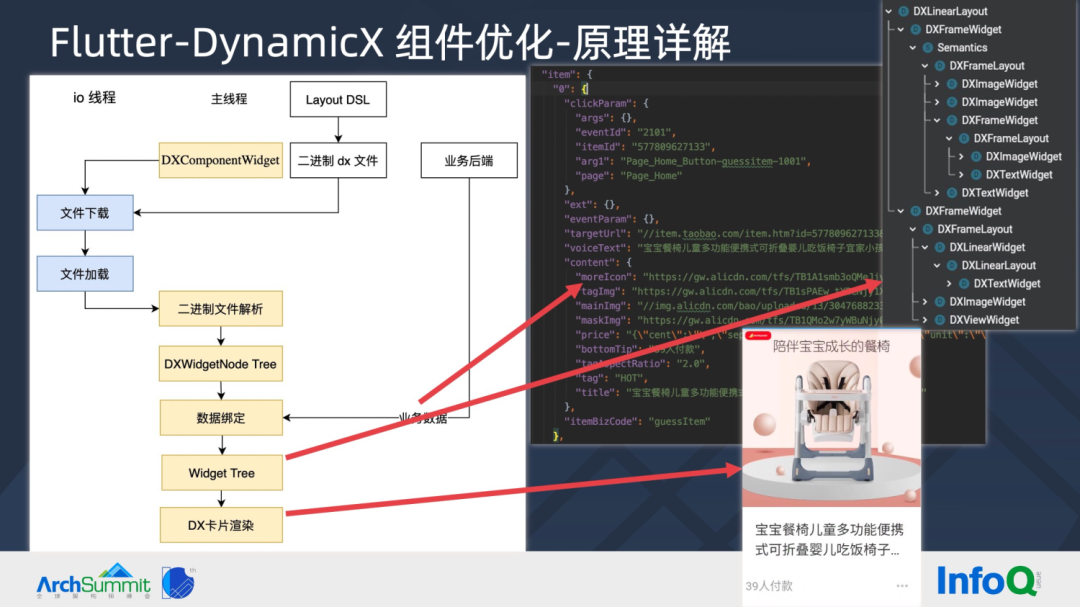
之后结合后台下发的业务数据,通过递归遍历 WidgetNode Tree 动态生成 Widget Tree,最后显示上屏。
说明:Flutter DynamicX 参考阿里集团 DSL 规则实现
▐ Flutt er-DynamicX组件优化-缓存优化
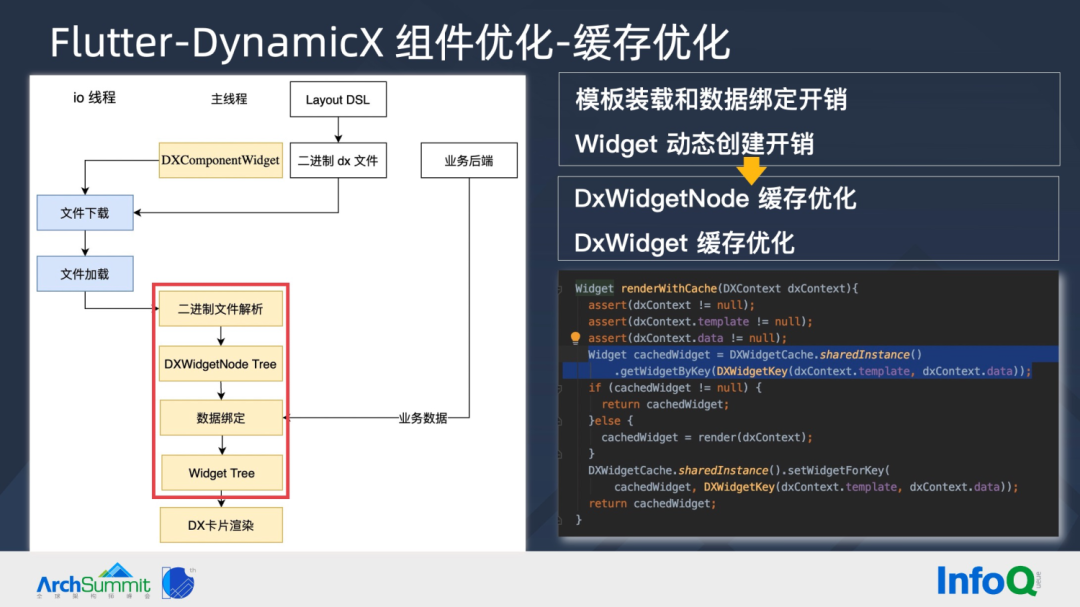
知道了原理,就容易发现上图红色框中的流程:二进制(模板)文件解析装载、数据绑定、Widget 动态创建都有一定的开销。为避免反复开销,我们对 DxWidgetNode 和 DxWidget 均进行了缓存,蓝色选中代码展示了 Widget 缓存。
▐ Flutte r-DynamicX组件优化-独立 isolate 优化
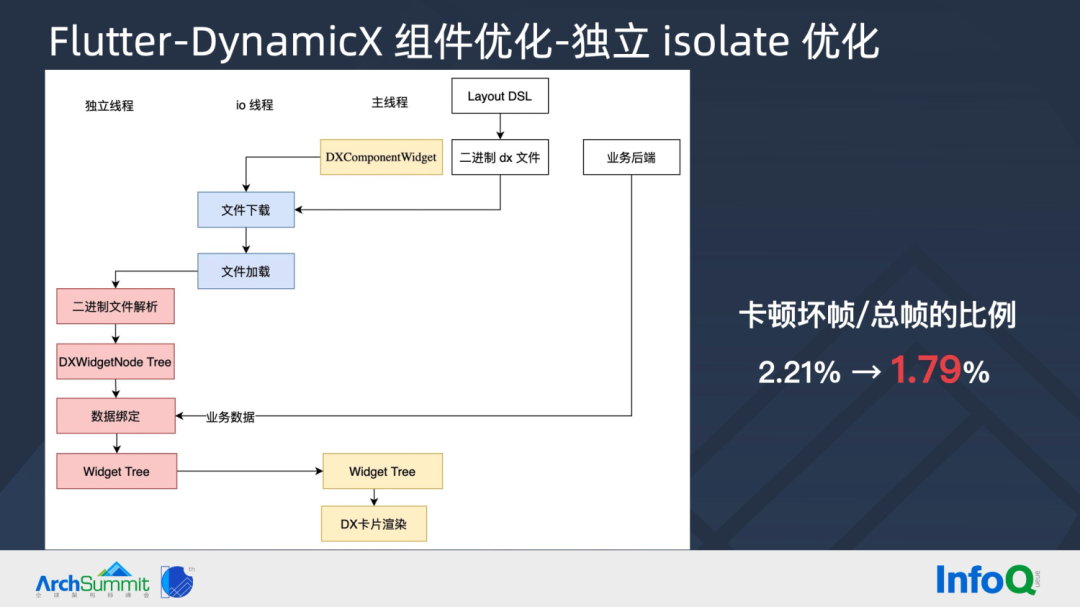
此外,将上述逻辑放置到独立 isolate 中,最大限度的将开销降低至最低。经过线上技术灰度 AB 实验,平均卡顿坏帧比例从 2.21% 降低至 1.79%。
▐ Flut ter-DynamicX组件优化-层级优化

Flutter DynamicX 提供了类 Android Layout DSL,为实现每个控件 padding、margin、corner 等属性,增加了 Decoration 层;为实现类 Android FrameLayout、LinearLayout 布局能力,增加了 DXContainerRender 层。每一层都有自己的清晰职责,代码层次清晰。但也因为增加 2 层导致 Widget Tree 层级变深,3棵树的 Diff 逻辑变得复杂,性能变低。为此,我们将 Decoration 层和 DXContainerRender 层进行了合并,查看中间 Timeline 图,可以发现优化后的燃焰图层级和复杂度都变低。经过线上技术灰度 AB 实验,平均卡顿坏帧比例从 2.11% 降低至 1.93%。
性能衡量和devtool扩展
讲述了优化手段,这里讲述我们的流畅度性能如何做衡量,以及工具的构建/扩展。
▐ 线 下场景-flutter benchmark

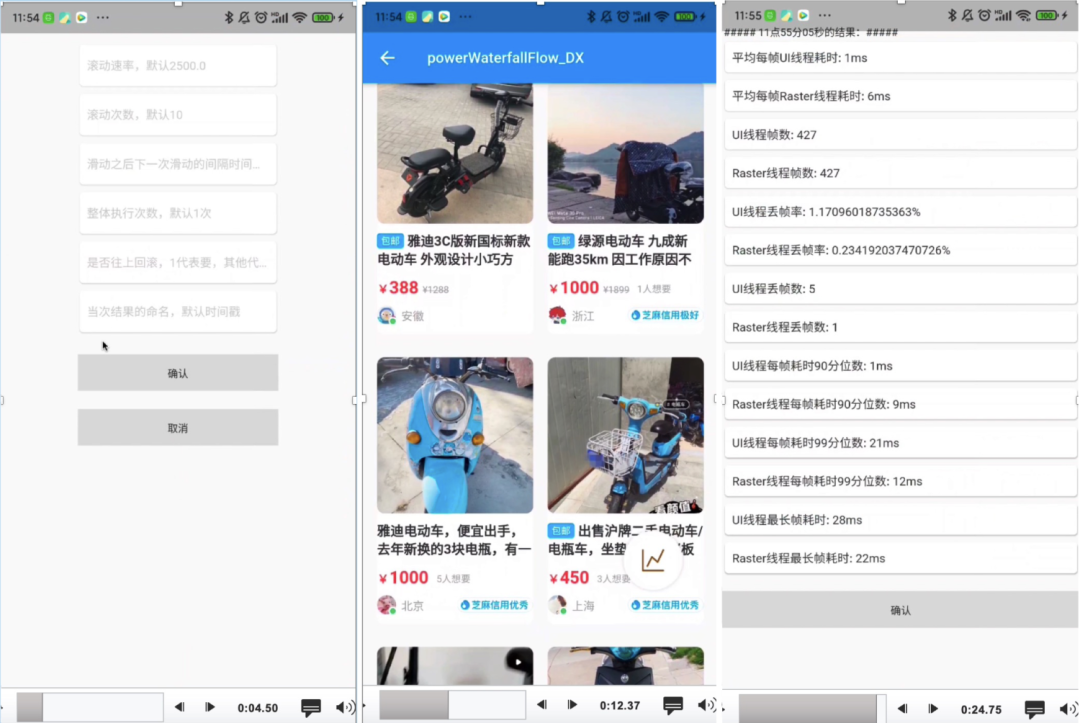
检测 Flutter 每帧耗时,需要统计 UI Thread 和 Raster Thread 上的计算耗时。所以 Flutter 优化前后比较,使用 SchedulerBinding.instance.addTimingsCallback 获取每一帧的 UI Thread 和 Raster Thread 的耗时数据。
此外,流畅度性能数值受操作手势、滚动速度影响,所以基于人工操作的测量结果会存在误差。这里使用 WidgetController 控制列表控件 fling。
工具提供设置滚动速度、滚动次数、滚动之间的间隔时间等。滚动测试完成后,显示 UI 和 Raster Thread 丢帧数,50分位、90分位、99分位的帧耗时等数据,从多种维度给出了性能数据。
▐ 线 下场景-基于录屏的流畅度检测
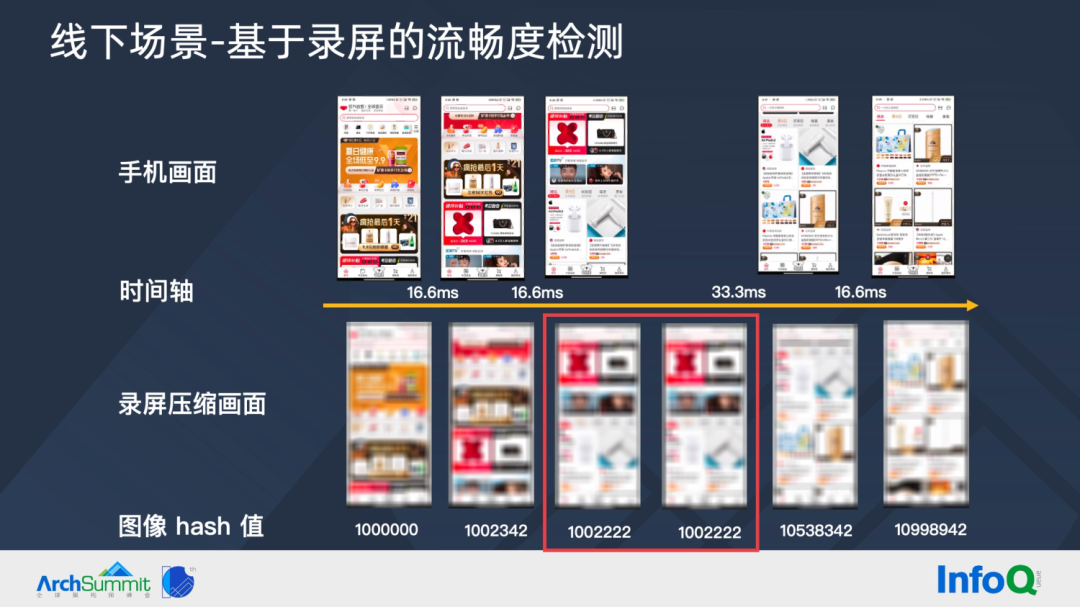
flutter benchmark 在 flutter 页面给出了多维度的测量数据,但有时候我们需要横向比较竞品 App,所以我们需要有工具横向比较不同技术栈的页面流畅度。闲鱼在 Android 端自研了基于录屏数据的流畅度检测。将手机界面想象成多个画面,通过向系统录屏服务 MediaProjection 注册获取 VirtualDisplay,间隔 16.6 ms读取其中的画面数据(字节数组),这里使用字节数组的 hash 值代表当前画面,当前后 2 次读取的 hash 值不变,则认为发生了卡顿。
为了保证流畅度检测工具 app自身不发生卡顿,这里读取的是压缩画面数据,低端机上压缩比例要更高
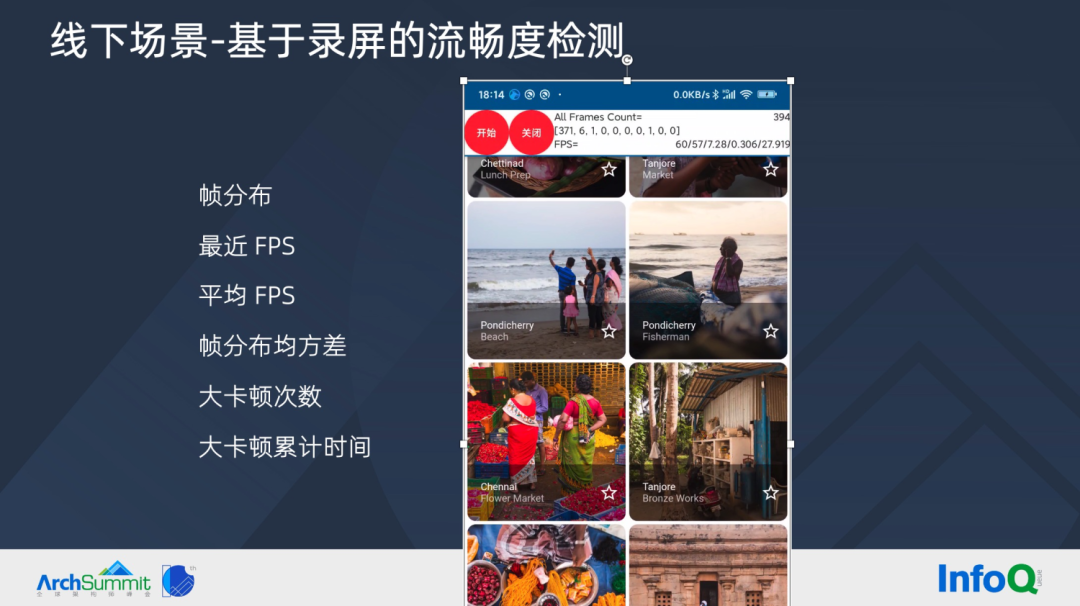
通过工具无侵入的检测,可以检测到一次滚动测试,平均 FPS 值(图中 57),帧分布均方差(7.28),1s 时间发生的大卡顿次数平均值(0.306),大卡顿累计时间(27.919)。中间数组展示帧分布情况:371 代表正常帧数量,6 代表 16.62ms 的小卡顿数量,1 代表 16.63ms 的卡顿数量。
这里大卡顿的定义是:大于 16.6*2 ms 的卡顿
▐ 线下 场景-基于devtool的性能检测
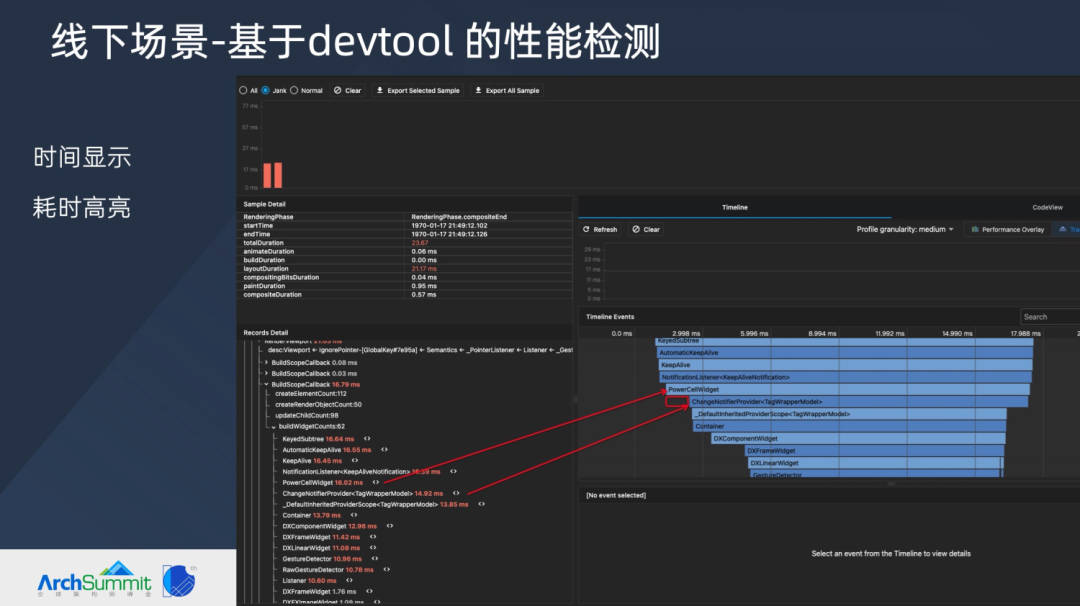
此外,闲鱼线下场景也扩展了 devtool。在一次 Timeline 图扩展了每个阶段的耗时,大于 16.6ms 红色高亮显示,便捷了开发使用。
▐ 线下场 景 -Flutter高可用检测FPS实现原理
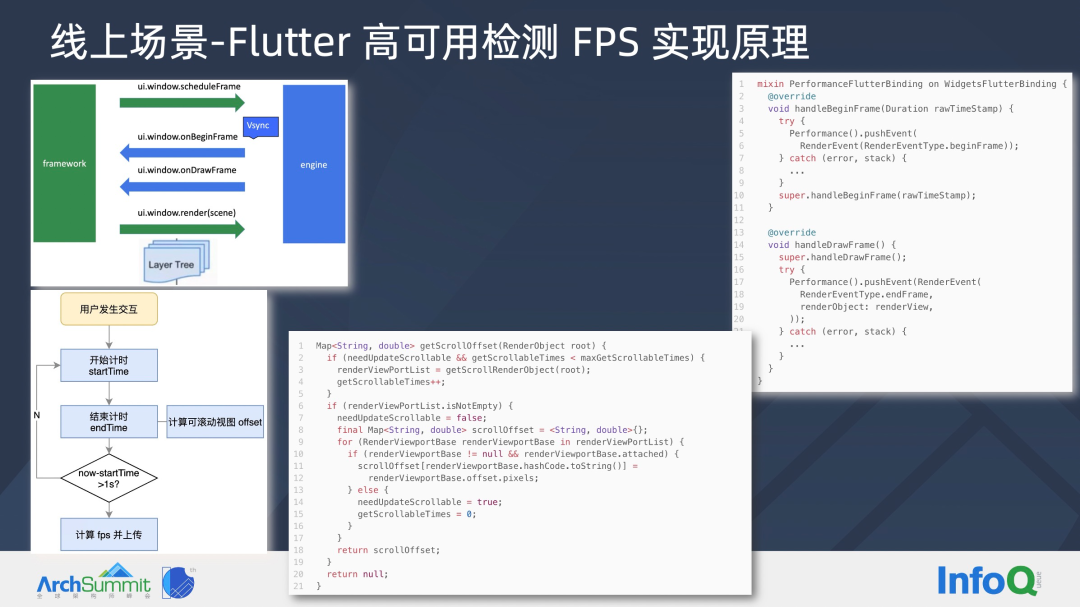
在线上场景,闲鱼自研了 Flutter 高可用。基本原理是基于2个事件:
-
ui.window.onBeginFrame 事件
-
engine 通知 Vysnc 信号到来,通知 UI Thread 开始准备下一帧画面构建
-
触发 SchedulerBinding.handleBeginFrame 回调
-
ui.window.onDrawFrame 事件
-
engine 通知 UI Thread 开始绘制下一帧画面
-
触发SchedulerBinding.handleDrawFrame 回调
这里我们在 handleBeginFrame 处理之前,记录一帧开始事件,在 handleDrawFrame 之后记录一帧的结束。这里每一帧都需要计算列表控件 offset 值,具体代码实现见右图。在整个累计超过 1s 时,执行一次计算,使用 offset 过滤掉没有发生滚动的场景,使用每一帧的时间计算 fps 值。
▐ 线上 场景-FlutterBlockCanary线上卡顿堆栈检测
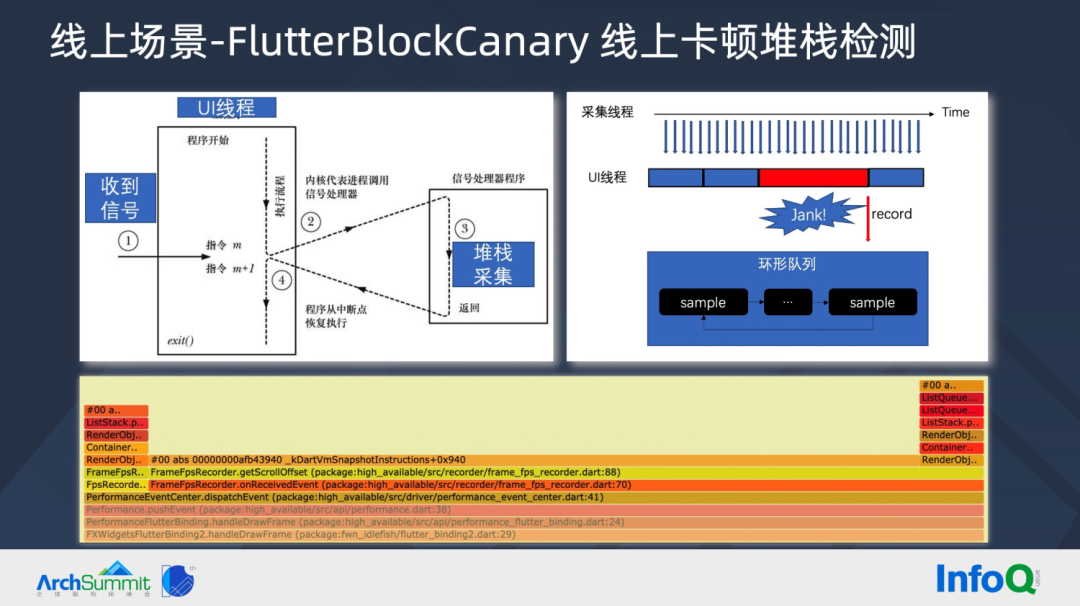
使用 Flutter 高可用计算得到线上 FPS 数值后,如何定位卡顿问题,需要收集堆栈信息。闲鱼使用自研的 FlutterBlockCanary 收集卡顿堆栈。基本原理是,在 C 层轮询发送信号,比如 5ms 一次,每次信号接收触发 dart UI Thread 堆栈采集,对得到的一系列堆栈进行聚合,连续多次相同堆栈就认为是发生了卡顿,这时这个堆栈就是我们想要的卡顿堆栈。
上图是 FlutterBlockCanary 采集的堆栈信息,中间 FrameFpsRecorder.getScrollOffset 就是发生卡顿的调用。
▐ 线 上场景- FlutterBlockCanary检测过度渲染

此外,FlutterBlockCanary 也集成了过度渲染检测的能力。通过复写 WidgetsFlutterBinding 的 buildOwner 方法替换 BuildOwner 对象,进而重写 scheduleBuildFor 方法,实现拦截脏 element。基于脏 element 节点,提取出脏节点的深度、直接子节点的数量、全部子节点的数量。
基于全部子节点数量,在闲鱼详情页,我们定位到“快速提问视图”在滚动过程中,频繁被标脏和全部子节点数量过大。查看代码,定位该视图层级过高,通过将视图下沉到叶子节点,一次标脏 build 节点数量从 255 优化至 43。
Flutter 滑动曲线优化
前面讲述了卡顿优化手段和衡量工具和标准,主要还是围绕着 FPS。但从用户体感出发,我们发现 Flutter 也有很多可优化点。
▐ Flutter 列表滑动曲线和原生曲线
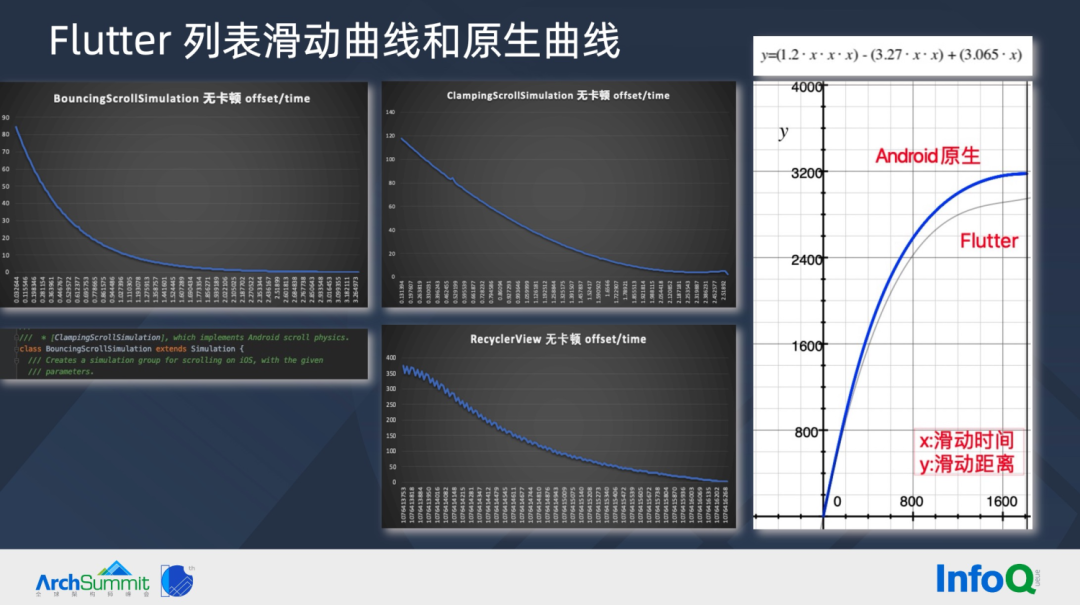
分别对比 offset/time 的滚动曲线,可以发现 Flutter BouncingScrollSimulation 和iOS 滚动曲线接近,ClampingScrollSimulation 和 RecyclerView 接近。查看 Flutter 源码注释,也确实是如此。
因为 BouncingScrollSimulation 具有回弹能力,所以很多下拉刷新和加载更多功能,都是基于 BouncingScrollSimulation 封装实现,这也就造成 Flutter 页面滑动时,体感和原生 Android 页面不一致的原因。
▐ Flutter 列表在快速滑动下的表现和优化
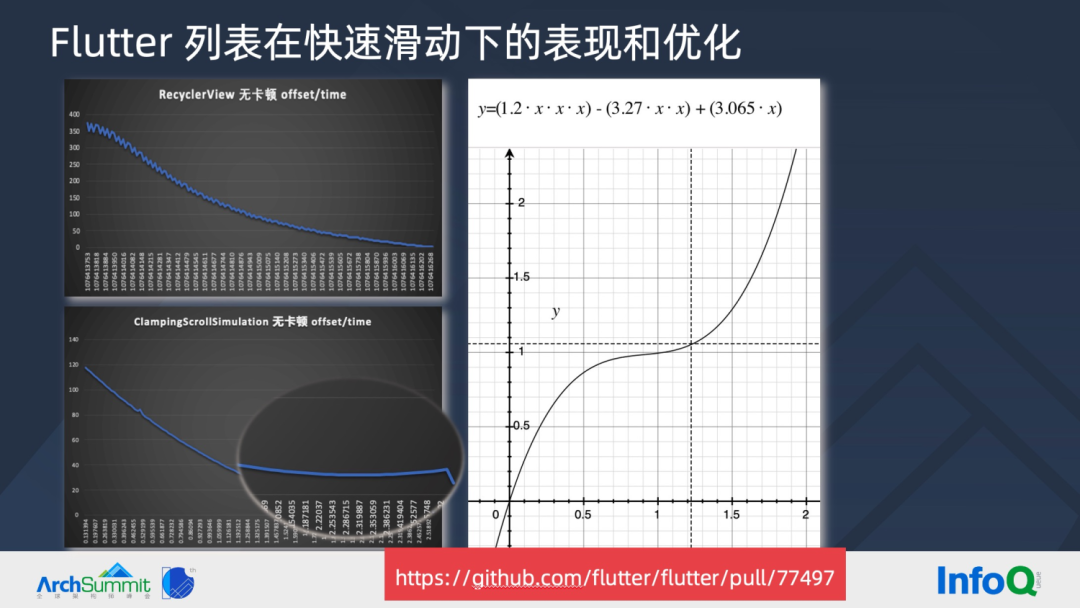
虽然 ClampingScrollSimulation 滑动曲线和 Android RecyclerView 接近,但在快速滑动场景下,可以发现 Flutter 列表滚动快停止的时候会像磁铁吸住一般,快速滑动一下停止。究其原因,可以看到滑动曲线快停止的瞬间,速度并不是下降,而会加快,最后到达终点,快速停止。基于源码公式,绘制曲线,可以发现,Flutter ClampingScrollSimulation 是通过公式拟合方式,去逼近 Android RecyclerView 曲线(BSpline)。在快速滑动的情况下,公式曲线的重点并不是 1 对应的值,而是右图虚线位置,速度会变快。
可以理解 Flutter 的公式拟合结果并不理想,为此近期也有 PR 提出使用 dart 实现了 RecyclerView 曲线。
▐ Flutter 列表在卡顿情况下的表现和优化
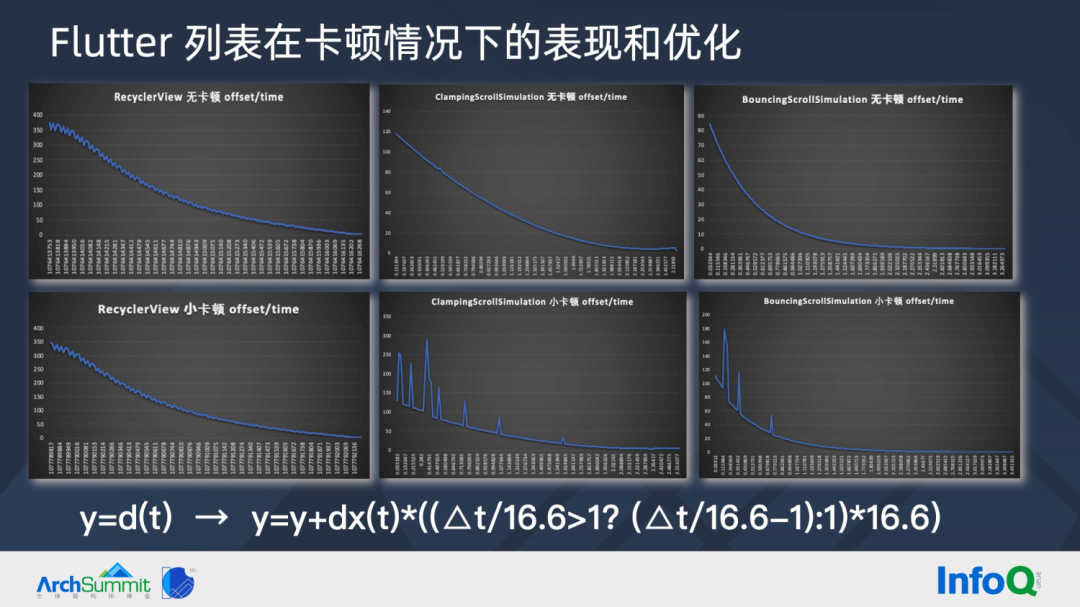
第一章提过相同 FPS 情况下,如 FPS 55,原生列表感受流畅,而 Flutter 列表的卡顿体感更明显。这里一个原因是原生列表通常有多线程操作,出现大卡顿的概率更低;另一个原因是,相同小卡顿的体感,Flutter 有明显的卡顿感,而原生列表几乎感受不出来。那这是为什么呢?
我们在构建卡片的时候,故意制造小卡顿,在前后对比 Flutter 列表和 RecyclerView,可以发现 RecyclerView offset 并不会发生跳变,而 Flutter 曲线有很多毛刺,因为 Flutter 滚动是基于 d/t 曲线计算,当发生卡顿的时候,△t 发生翻倍,offset 也发生跳变。也正是因为时间停顿和 Offset 跳变,让用户明显感受到 Flutter 列表在小卡顿的不流畅感。
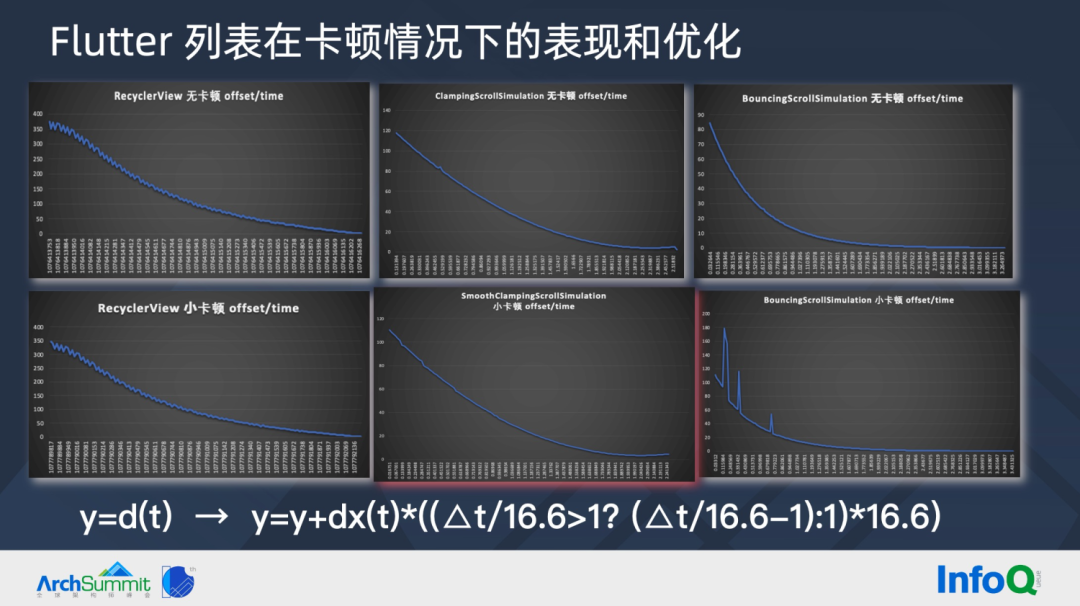
通过修改 y=d(t) 公式,在卡顿情况下,将△t-16.6ms,保证小卡顿情况下,offset 不发生跳变。而在大卡顿情况下,就没有必要将 △t 重置为 16.6ms 了,因为在停顿时长上,已经明显让用户给感受到卡顿了,offset 不发生跳变只会让列表滚动距离变短。
性能优化建议

最后分享一些性能优化的建议。
- 在优化时,我们更应该关注用户体感,而不是只看性能数值。右上图可见,即便 FPS 值一样,但 offset 发生跳变,体感就会有明显的不同;右下2个游戏录屏,左边平均 40 FPS,右边平均 30 FPS,但体感上却是右边的更顺畅。
- 不仅要关注 UI Thread 的性能,也要关注 Raster Thread 的开销,如视图圆角、save layer 等特性/操作,也可能导致卡顿
- 在工具方面,建议在不同场景下使用不同的工具。需要注意的是,工具检测的问题,是稳定复现问题还是数据抖动产生的偶现问题。此外,也要考虑工具自身的性能开销,工具自身的 CPU 占用和主线程占用都需要尽可能降低。
- 在优化思路方面,我们要扩宽方向,Flutter 大部分优化思路都是优化计算任务;而多线程方向也并不是不可以,参考前面 Flutter DynamicX 的独立 isolate 优化;此外,一帧时间难以消化的任务,是否有可能拆解到多个帧时间,尽量让每帧时间不发生卡顿,优先响应用户。
- 最后,推荐关注 Flutter 社区。Flutter 社区持续有各种优化合入,定期升级 Flutter 或维度自己的版本,cherry-pick 优化提交,都是不错的选择。
▐ 性能分析工具使用建议
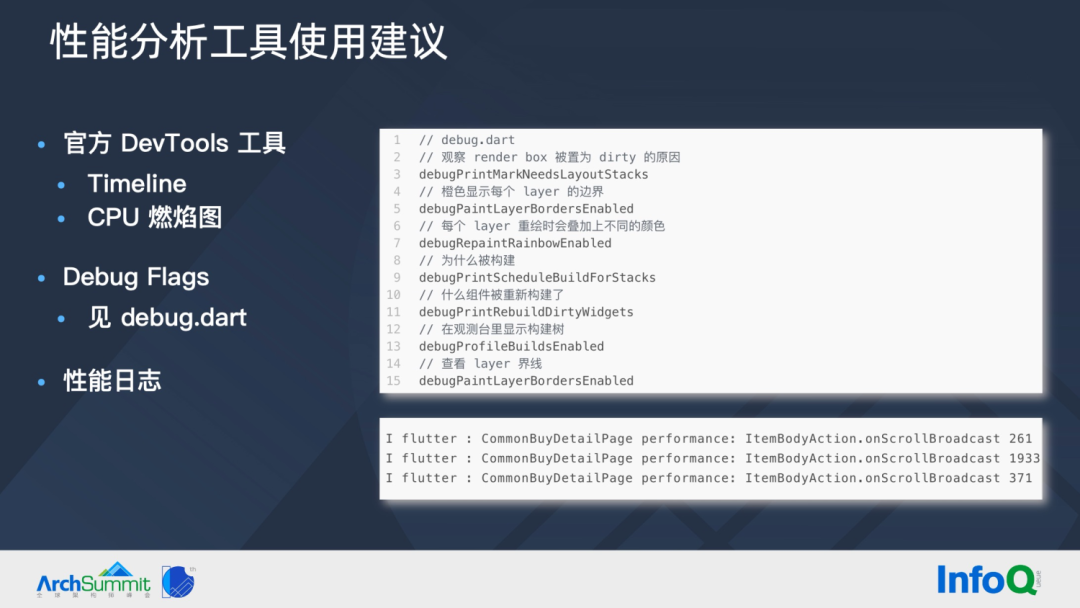
Flutter 工具方面,首推的就是官方的 DevTools 工具,里面的 Timeline 和 CPU 燃焰图能很好的协助我们发现问题;此外,Flutter 也提供了丰富的 Debug Flags 协助我们定位问题,熟悉每一个 debug 开关作用,相信对我们日常研发也会有不小的帮助;除了官方工具,性能日志也是很好的辅助信息,如右下角所示,闲鱼 fish-redux 组件输出了滚动中的任务开销时长,能方便的看出那一时刻发生了卡顿。
▐ 性能分析工具自身开销

性能检测工具不可避免会有一定的开销,但一定要控制在可接受范围内,特别是线上使用。前面分享过 FlutterBlockCanary 检测工具的一个案例,发现了 FrameFpsRecorder.getScrollOffset 有耗时情况,而这处逻辑正好是 Flutter 高可用计算滚动 Offset。见右图的优化前源码,每一帧都需要递归遍历收集 RenderViewPortBase,是一个不小的开销。最后,我们通过缓存优化的方式,避免了滚动过程中的反复计算。
▐ 卡顿优化建议
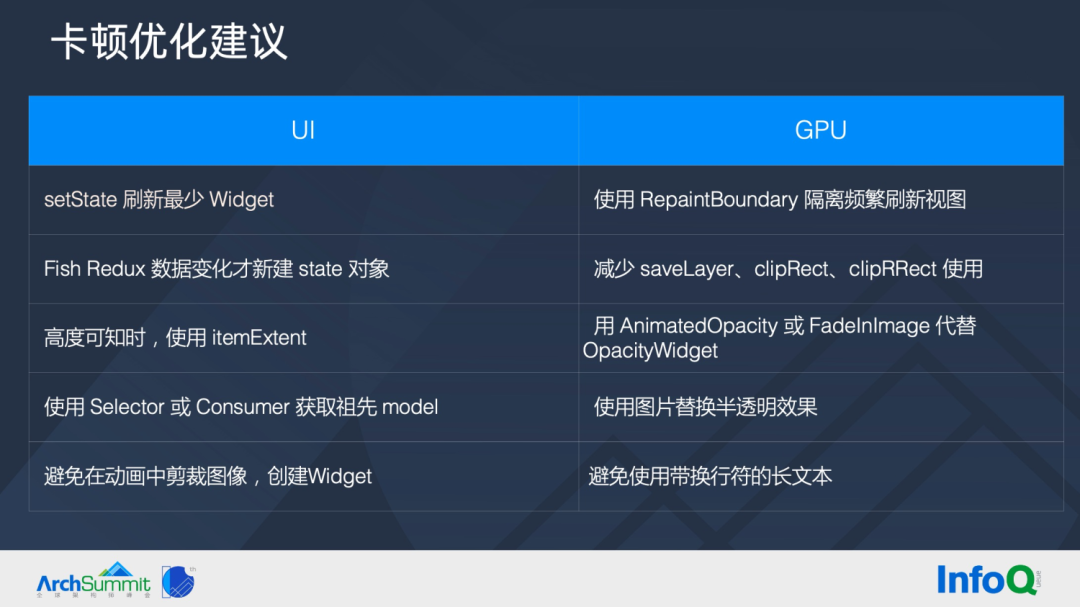
参考官方文档和优秀的性能文章,在 UI 和 GPU 侧都沉淀了很多常规优化手段,如刷新最小 Widget,使用 itemExtent,推荐使用 Selector 和 Consumer 等,避免了不必要的 Diff 计算、布局计算等;如减少 saveLayer、使用图片替换半透明效果等减轻了 Raster 线程的开销。
因为篇幅原因,这里只列了一部分,更多的常见优化建议见官方文档。
▐ 使用最新 flutter engine

前面提过,Flutter 社区还在活跃,Framework 和 Engine 层持续的有优化 PR 合入,这些优化手段大部分可以让业务层无感知,并且从底层视角更好的优化性能。
这里举一个典型的优化方案:现有 Flutter 方案:在每次 VSync 信号到来时,触发 Build 操作,在 Build 结束时,开始注册下一个 VSync 回调。在没有发生卡顿的情况下,见图 Normal。但在发生卡顿的情况下,见图 Actual results,这里2 Build耗时刚刚超过了 16.6ms,由于是注册监听下一个 VSync 回调时触发下一次 Build,为此中间空余了大量的时间。明显,我们所期望的是,2 Build结束时,立即执行3 Build,假设3 Build执行的足够快,这个时候用户看到的画面还是流畅的。
如果团队允许,建议定期升级 Flutter 版本;或者维护自己的 Flutter 独立分支也是不错的选择,从社区 Cherry-Pick 优化提交,既能保证业务稳定也能享受社区贡献。总之,推荐大家关注社区。
总结
综上,分享了 Flutter 流畅度优化的挑战、监控工具、优化手段和建议。性能优化要以人为中心,从实际体感入手制定监控指标和优化点;流畅度优化并不是一蹴而就,以上分享也不是全部,还有很多优化手段可以关注:如何更好的复用 Element,如何避免 Platform Thread 繁忙导致 Vsync 信号缺失等都是可以关注的点,只有持续的技术热情和匠心精神才能把 App 性能优化到极致;技术团队也要和开源社区、其他团队/公司建立连接,他山之石,可以攻玉。