手写Redis的LRU淘汰策略
大家好, 这是我的第27篇原创文章。
今天我们这篇文章的目的是要搞懂LRU淘汰策略以及实现一个LRU算法。
文章会结合图解循序渐进的讲解,跟着我的思路慢慢来就能看懂,我们开始吧。
文章导读
Redis的淘汰策略
为什么要有淘汰策略呢?
因为存储内存的空间是有限的,所以需要有淘汰的策略。
Redis的清理内存淘汰策略有哪些呢?

LRU算法简介
LRU是Least Recently Used的缩写,即最近最少使用,是一种常见的页面置换算法。
我们手机的后台窗口(苹果手机双击Home的效果),他总是会把最近常用的窗口放在最前边,而最不常用的应用窗口,就排列在后边了,如果再加上只能放置N个应用窗口的限制,淘汰最不常用的最近最少用的应用窗口,那就是一个活生生的LRU。
实现思想推导

从上边的示意图,我们可以分析出这么几个点:
- 有序;
- 如果应用开满3个了,要淘汰最不常用的应用,每次新访问应用,需要把数据插入队头(按照业务可以设定左右哪一边是队头);
- O(1)复杂度是我们查找数据的追求,我们什么结构能够实现快速的O(1)查找呢?
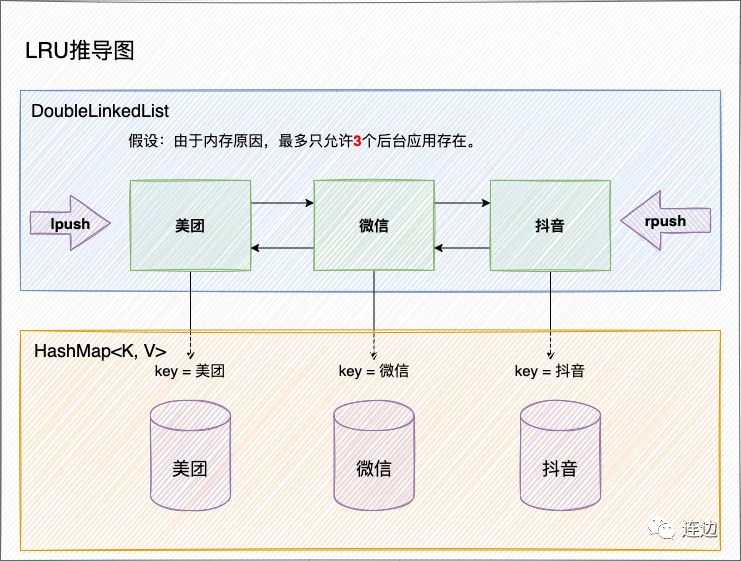
通过上边的推导,我们就能得出,LRU算法核心是HashMap + DoubleLinkedList。
思想搞明白了,我们接下来编码实现。
巧用LinkedHashMap
我们查看Java的LinkedHashMap使用说明。

翻译:这种Map结构很适合构建LRU缓存。
继承LinkedHashMap实现LRU算法:
public class LRUDemo<K, V> extends LinkedHashMap<K, V> {
private int capacity;
public LRUDemo(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return super.size() > capacity;
}
public static void main(String[] args) {
LRUDemo lruDemo = new LRUDemo(3);
lruDemo.put(1, "a");
lruDemo.put(2, "b");
lruDemo.put(3, "c");
System.out.println(lruDemo.keySet());
lruDemo.put(4, "d");
lruDemo.put(5, "e");
System.out.println(lruDemo.keySet());
}
}重点讲解:
- 构造方法:
super(capacity, 0.75F, true),主要看第三个参数:
a . 
b . true -> access-order // false -> insertion-order即按照访问时间排序,还是按照插入的时间来排序
// 构造方法改成false
super(capacity, 0.75F, false);
// 使用示例
public static void main(String[] args) {
LRUDemo lruDemo = new LRUDemo(3);
lruDemo.put(1, "a");
lruDemo.put(2, "b");
lruDemo.put(3, "c");
System.out.println(lruDemo.keySet());
lruDemo.put(1, "y");
// 构造方法order=true,输出:[2,3,1],
// 构造方法order=false,输出:[1,2,3],
System.out.println(lruDemo.keySet());
}2 . removeEldestEntry方法:什么时候移除最年长的元素。
通过上面,相信大家对LRU算法有所理解了,接下来我们不依赖JDK的LinkedHashMap,通过我们自己的理解,动手实现一个LRU算法,让我们的LRU算法刻入我们的大脑。
手写LRU
上边的推导图中可以看出,我们用HashMap来做具体的数据储存,但是我们还需要构造一个DoubleLinkedList对象(结构体)来储存HashMap的具体key顺序关系。
第一步:构建DoubleLinkedList对象
1 . 所以我们现在第一步,就是构建一个DoubleLinkedList对象:
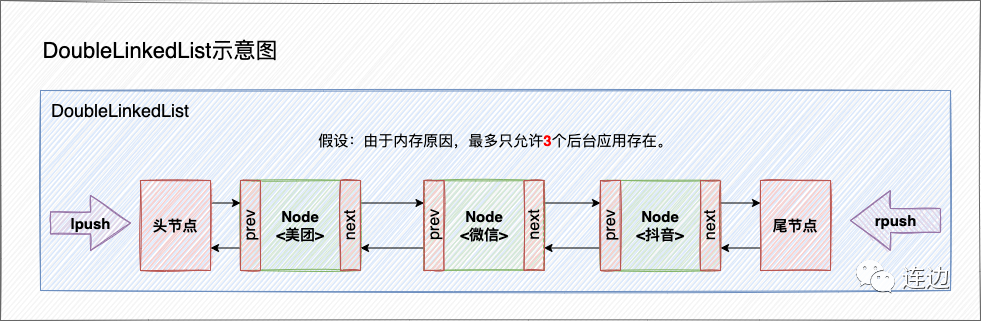
我们可以从HashMap源码中找一些灵感,他们都是使用一个Node静态内部类来储存节点的值。
第二步:构建节点
通过上边的示意图,我们可以得知节点应该要储存的内容:
- key
- value
- prev节点
- next节点
翻译成代码:
class Node<K, V> {
K key;
V value;
Node<K, V> prev;
Node<K, V> next;
public Node() {
this.prev = this.next = null;
}
public Node(K key, V value) {
this.key = key;
this.value = value;
this.prev = this.next = null;
}
}第三步:初始化DoubleLinkedList对象

还是通过上边的示意图,我们可以得知DoubleLinkedList对象应该要储存的内容:
- 头节点
- 尾节点
翻译成代码:
class DoubleLinkedList<K, V> {
Node<K, V> head;
Node<K, V> tail;
// 构造方法
public DoubleLinkedList(){
head = new Node<>();
tail = new Node<>();
head.next = tail;
tail.prev = head;
}
}从头添加节点
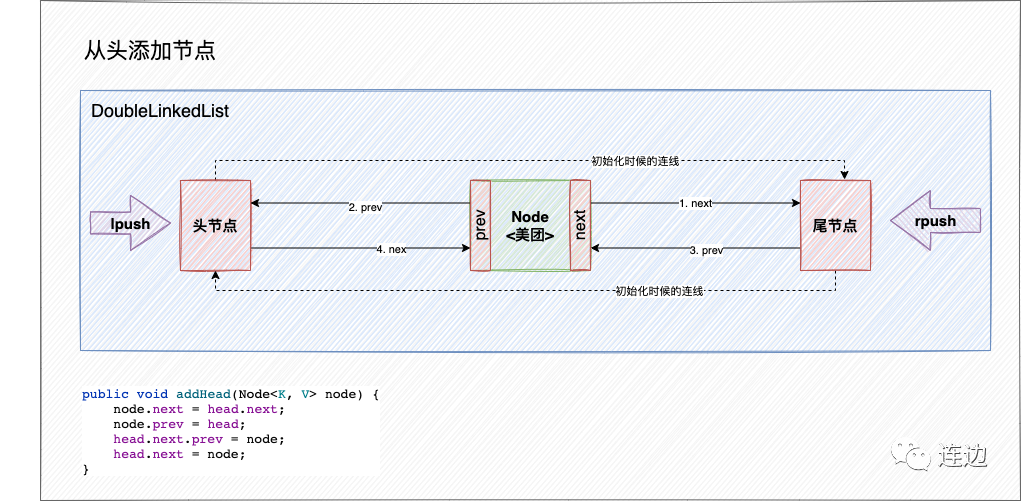
翻译成代码:
public void addHead(Node<K, V> node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}删除节点
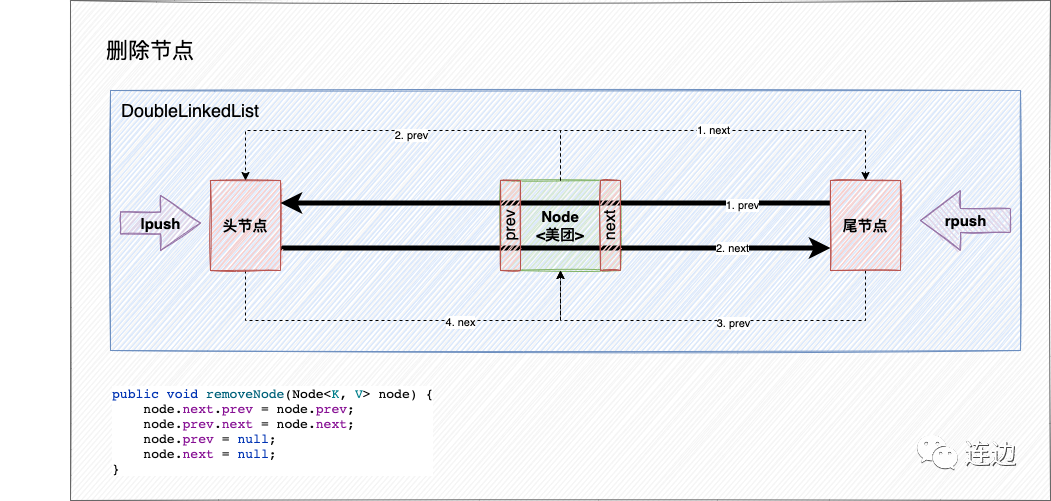
翻译成代码:
public void removeNode(Node<K, V> node) {
node.next.prev = node.prev;
node.prev.next = node.next;
node.prev = null;
node.next = null;
}获取最后一个节点
public Node getLast() {
return tail.prev;
}第四步:LRU对象属性
cacheSize
private int cacheSize;
map
Map<Integer, Node<Integer, String>> map;
doubleLinkedList
DoubleLinkedList<Integer, String> doubleLinkedList;
第五步:LRU对象的方法
构造方法
public LRUDemo(int cacheSize) {
this.cacheSize = cacheSize;
map = new HashMap<>();
doubleLinkedList = new DoubleLinkedList<>();
}refreshNode刷新节点
public void refreshNode(Node node) {
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
}get节点
public String get(int key) {
if (!map.containsKey(key)) {
return "";
}
Node<Integer, String> node = map.get(key);
refreshNode(node);
return node.value;
}put节点
public void put(int key, String value) {
if (map.containsKey(key)) {
Node<Integer, String> node = map.get(key);
node.value = value;
map.put(key, node);
refreshNode(node);
} else {
if (map.size() == cacheSize) {
Node lastNode = doubleLinkedList.getLast();
map.remove(lastNode.key);
doubleLinkedList.removeNode(lastNode);
}
Node<Integer, String> newNode = new Node<>(key, value);
map.put(key, newNode);
doubleLinkedList.addHead(newNode);
}
}第六步:测试
public static void main(String[] args) {
LRUDemo lruDemo = new LRUDemo(3);
lruDemo.put(1, "美团");
lruDemo.put(2, "微信");
lruDemo.put(3, "抖音");
lruDemo.put(4, "微博");
System.out.println(lruDemo.map.keySet());
System.out.println(lruDemo.get(2));
}总结
LRU算法到这里就写完啦,完整的代码可以从阅读原文的链接地址获取。
希望看完这篇文章之后,彻底弄懂LRU算法,如果有疑问欢迎留言或者加我微信跟我交流。
衷心感谢每一位认真读文章的人,我是连边,专注于Java和架构领域,坚持撰写有原理,有实战,有体系的技术文章。
参考资料:
https://www.bilibili.com/video/BV1Hy4y1B78T?p=64