Golang GPM 模型剖析
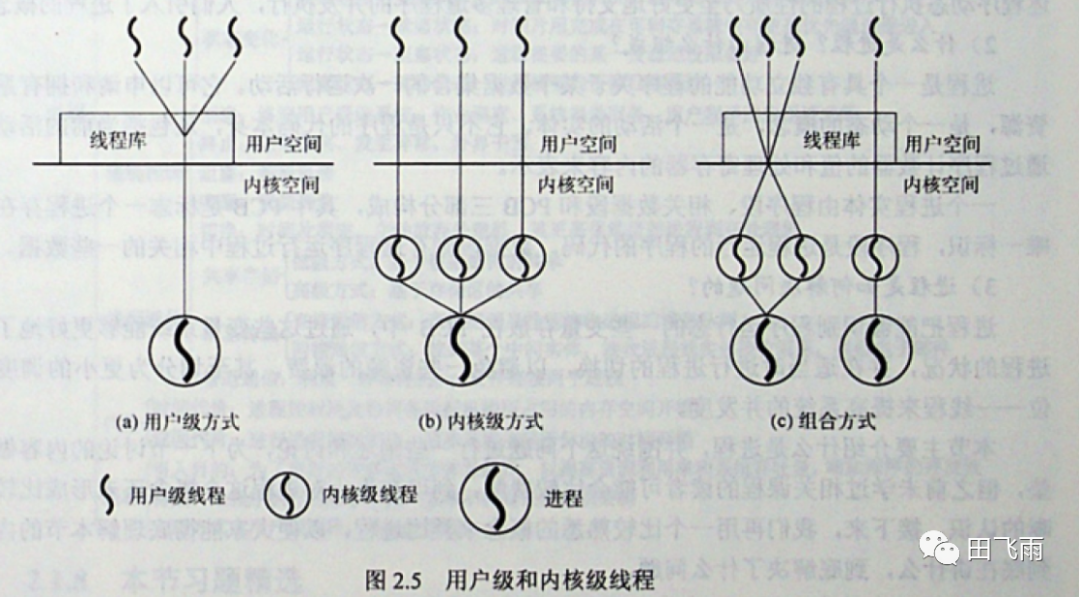
线程、内核线程和用户线程区别
- 线程:从内核角度来说并没有线程这个概念。Linux 把所有的线程都当做进程来实现,内核也没有特别的调度算法来处理线程。线程仅仅被视为一个与其他进程共享某些资源的进程,和进程一样,每个线程也都是有自己的
task_struct,所以在内核中,线程看起来就是一个普通的进程。线程也被称作轻量级进程,一个进程可以有多个线程,线程拥有自己独立的栈,切换也由操作系统调度。在 Linux 上可以通过pthread_create()方法或者clone()系统调用创建; - 内核线程:独立运行在内核空间的标准进程,内核线程和普通线程的区别在于内核线程没有独立的地址空间;
- 用户线程:也被称作协程,是一种基于线程之上,但又比线程更加轻量级的存在,由用户运行时来管理的,操作系统感知不到,它的切换是由用户程序自己控制的,但用户线程也是由内核线程来运行的。Lua 和 Python 中的协程(coroutine)、Golang 的 goroutine 都属于用户级线程;
三者的关系如下所示:
Golang 使用协程的原因
操作系统中虽然已经有了多线程、多进程来解决高并发的问题,但是在当今互联网海量高并发场景下,对性能的要求也越来越苛刻,大量的进程/线程会出现内存占用高、CPU消耗多的问题,很多服务的改造与重构也是为了降本增效。
一个进程可以关联多个线程,线程之间会共享进程的一些资源,比如内存地址空间、打开的文件、进程基础信息等,每个线程也都会有自己的栈以及寄存器信息等,线程相比进程更加轻量,而协程相对线程更加轻量,多个协程会关联到一个线程,协程之间会共享线程的一些信息,每个协程也会有自己的栈空间,所以也会更加轻量级。从进程到线程再到协程,其实是一个不断共享,减少切换成本的过程。
Golang 使用协程主要有以下几个原因:
- (1)内核线程创建与切换太重的问题:创建和切换都要进入到内核态,进入到内核态开销较大,性能代价大,而协程切换不需要进入到内核态;
- (2)线程内存使用太重:创建一个内核线程默认栈大小为8M,而创建一个用户线程即 goroutine 只需要 2K 内存,当 goroutine 栈不够用时也会自动增加;
- (3)goroutine 的调度更灵活,所有协程的调度、切换都发生在用户态,没有创建线程的开销,即使出现某个协程运行阻塞时,线程上的其他协程也会被调度到其他线程上运行;
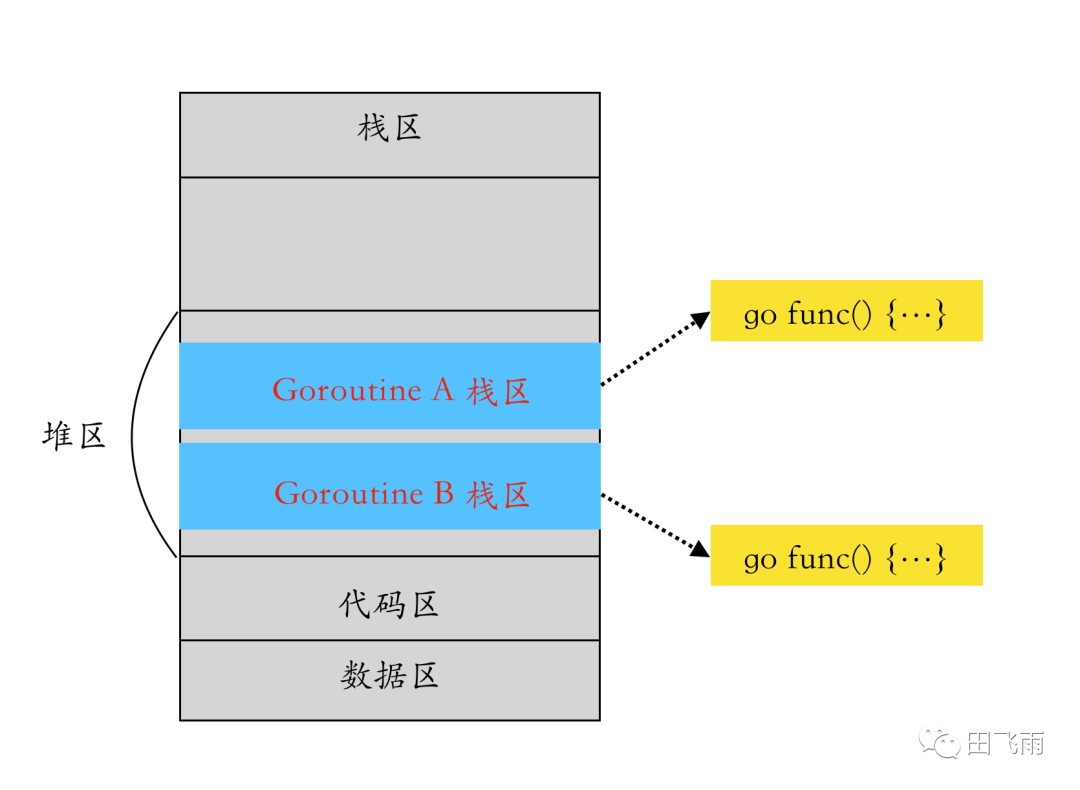
Goroutine 在进程内存空间中的分布
协程的本质其实就是可以被暂停以及可以被恢复运行的函数,创建一个 goroutine 时会在进程的堆区中分配一段空间,这段空间是用来保存协程栈区的,当需要恢复协程的运行时再从堆区中出来复制出来恢复函数运行时状态。
GPM 模型分析
在 Golang 代码的历史提交记录中会发现很多代码都是从 C 翻译到 Go 的,在 go 1.4 前 runtime 中大量代码是用 C 实现的,比如当前版本 proc.go 文件中实现的很多调度相关的功能最开始都是用 C 实现的,后面用 Go 代码进行了翻译,如果需要了解 Golang 最开始的设计细节可以翻阅最早提交的 C 代码。
commit b2cdf30eb6c4a76504956aaaad47df969274296b
Author: Russ Cox <rsc@golang.org>
Date: Tue Nov 11 17:08:33 2014 -0500
[dev.cc] runtime: convert scheduler from C to Go
commit 15ced2d00832dd9129b4ee0ac53b5367ade24c13
Author: Russ Cox <rsc@golang.org>
Date: Tue Nov 11 17:06:22 2014 -0500
[dev.cc] runtime: convert assembly files for C to Go transition
The main change is that #include "zasm_GOOS_GOARCH.h"
is now #include "go_asm.h" and/or #include "go_tls.h".
Also, because C StackGuard is now Go _StackGuard,
the assembly name changes from const_StackGuard to
const__StackGuard.
In asm_$GOARCH.s, add new function getg, formerly
implemented in C.本文主要介绍当前调度器中的 GPM 模型,首先了解下 GPM 模型中三个组件的作用与联系:
- G: Goroutine,即我们在 Go 程序中使用
go关键字运行的函数; - M: Machine,或 worker thread,代表系统线程,M 是 runtime 中的一个对象,每创建一个 M 会同时创建一个系统线程并与该 M 进行绑定;
- P: Processor,类似于 CPU 核心的概念,只有当 M 与一个 P 关联后才能执行 Go 代码;
G 运行时需要与 M 进行绑定,M 需要与 P 绑定,M 在数量上并不与 P 相等,这是因为 M 在运行 G 时会陷入系统调用或者因其他事情会被阻塞,M 不够用时在 runtime 中会创建新的 M,因此随着程序的执行,M 的数量可能增长,而 P 在没有用户干预的情况下,则会保持不变,G 的数量是由用户代码决定的。
GPM 三者的关联如下所示:

- 全局队列:存放等待运行的 G。
- P 的本地队列:同全局队列类似,存放的也是等待运行的 G,存的数量有限。新建 G 时,G 优先加入到 P 的本地队列,如果队列满了,则会把本地队列中一部分 G 移动到全局队列。
- P 列表:所有的 P 都在程序启动时创建,并保存在数组中,最多有
GOMAXPROCS(可配置) 个。 - M:线程想运行任务就得获取 P,然后从 P 的本地队列获取 G,P 队列为空时,M 也会尝试从全局队列拿一批 G 放到 P 的本地队列,或从其他 P 的本地队列偷一半放到自己 P 的本地队列,M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。
GPM 生命周期
1、P 的生命周期
P 对象的结构体如下所示:
type p struct {
id int32
status uint32 // P 的状态
link puintptr
schedtick uint32 // 被调度次数
syscalltick uint32 // 执行过系统调用的次数
sysmontick sysmontick // sysmon 最近一次运行的时间
m muintptr // P 关联的 M
mcache *mcache // 小对象缓存,可以无锁访问
pcache pageCache // 页缓存,可以无锁访问
raceprocctx uintptr // race相关
// 与 defer 相关
deferpool [5][]*_defer
deferpoolbuf [5][32]*_defer
// goroutine ids 的缓存
goidcache uint64
goidcacheend uint64
// P 本地 G 队列,可以无锁访问
runqhead uint32 // 本地队列头
runqtail uint32 // 本地队尾
runq [256]guintptr // 本地 G 队列,使用数组实现的循环队列
runnext guintptr // 待运行的 G,优先级高于 runq
// 已运行结束的 G (状态为 Gdead)会被保存在 gFree 中,方便实现对 G 的复用
gFree struct {
gList
n int32
}
sudogcache []*sudog
sudogbuf [128]*sudog
mspancache struct {
len int
buf [128]*mspan
}
tracebuf traceBufPtr
traceSweep bool
traceSwept, traceReclaimed uintptr
palloc persistentAlloc
_ uint32
timer0When uint64
timerModifiedEarliest uint64
// 与 GC 相关的
gcAssistTime int64
gcFractionalMarkTime int64
gcMarkWorkerMode gcMarkWorkerMode
gcMarkWorkerStartTime int64
gcw gcWork
wbBuf wbBuf
......
// 抢占标记
preempt bool
}(1) 为什么需要 P ?
在 Golang 1.1 版本之前调度器中还没有 P 组件,此时调度器的性能还比较差,社区的 Dmitry Vyukov 大佬针对当前调度器中存在的问题进行了总结并设计引入 P 组件来解决当前面临的问题(Scalable Go Scheduler Design Doc),并在 Go 1.1 版本中引入了 P 组件,引入 P 组件后不仅解决了文档中列的几个问题,也引入了一些很好的机制。
文档中列出了调度器当前主要有 4 个问题,主要有:
-
1、全局互斥锁 (
sched.Lock) 问题:社区在测试中发现 Golang 程序在运行时有 14% 的 CPU 使用率消耗在对全局锁的处理上。没有 P 组件时,M 只能通过加互斥锁从全局队列中获取 G,在加锁阶段对其他 goroutine 处理时(创建,完成,重新调度等)会存在时延;在引入 P 组件后,P 对象中会有一个队列来保存 G 列表,P 的本地队列可以解决旧调度器中单一全局锁的问题,而 G 队列也被分成两类,
sched中继续保留全局 G 队列,同时每个 P 中都会有一个本地的 G 队列,此时 M 会优先运行 P 本地队列中的 G,访问时也不需要加锁。 -
2、G 切换问题:M 频繁切换可运行的 G 会增加延迟和开销,比如新建的 G 会被被放到全局队列,而不是在 M 本地执行,这会导致不必要的开销和延迟,应该优先在创建 G 的 M 上执行就可以;
在引入 P 组件后,新建的 G 会优先放在 G 关联 P 的本地队列中。
-
3、M的内存缓存 (
M.mcache) 问题:在还没有 P 组件的版本中,每个 M 结构体都有一个mcache字段,mcache是一个内存分配池,小对象会直接从mcache中进行分配,M 在运行 G 时,G 需要申请小对象时会直接从 M 的mcache中进行分配,G 可以进行无锁访问,因为每个 M 同一时间只会运行一个 G,但 runtime 中每个时间只会有一部分活跃的 M 在运行 G,其他因系统调用等阻塞的 M 其实不需要mcache的,这部分mcache是被浪费的,每个 M 的mcache大概有 2M 大小的可用内存,当有上千个处于阻塞状态的 M 时,会有大量的内存被消耗。此外还有较差的数据局部性问题,这是指 M 在运行 G 时对 G 所需要的小对象进行了缓存,后面 G 如果再次调度到同一个 M 时那么可以加速访问,但在实际场景中 G 调度到同一个 M 的概率不高,所以数据局部性不太好。在引入了 P 组件后,
mcache从 M 转移到了 P ,P 保存了mcache也就意味着不必为每一个 M 都分配 一个mcache,避免了过多的内存消耗。这样在高并发状态下,每个 G 只有在运行的时候才会使用到内存, 而每个 G 会绑定一个 P,所以只有当前运行的 G 只会占用一个mcache,对于mcache的数量就是 P 的数 量,同时并发访问时也不会产生锁。 -
4、线程频繁阻塞与唤醒问题:在最初的调度器中,通过
runtime.GOMAXPROCS()限制系统线程的数量,默认只开启一个系统线程。并且由于 M 会执行系统调用等操作,当 M 阻塞后不会新建 M 来执行其他的任务而是会等待 M 唤醒,M 会在阻塞与唤醒之间频繁切换会导致额外的开销;在新的调度器中,当 M 处于系统调度状态时会和绑定的 P 解除关联,会唤醒已有的或创建新的 M 来和 P 绑定运行其他的 G。
(2) P 的新增逻辑
P 的数量是在 runtime 启动时初始化的,默认等于 cpu 的逻辑核数,在程序启动时可以通过环境变量 GOMAXPROCS 或者 runtime.GOMAXPROCS() 方法进行设置,程序在运行过程中 P 的数量是固定不变的。
在 IO 密集型场景下,可以适当调高 P 的数量,因为 M 需要与 P 绑定才能运行,而 M 在执行 G 时某些操作会陷入系统调用,此时与 M 关联的 P 处于等待状态,如果系统调用一直不返回那么等待系统调用这段时间的 CPU 资源其实是被浪费的,虽然 runtime 中有 sysmon 监控线程可以抢占 G,此处就是抢占与 G 关联的 P,让 P 重新绑定一个 M 运行 G,但 sysmon 是周期性执行抢占的,在 sysmon 稳定运行后每隔 10ms 检查一次是否要抢占 P,操作系统中在 10ms 内可以执行多次线程切换,如果 P 处于系统调用状态还有需要运行的 G,这部分 G 得不到执行其实CPU资源是被浪费的。在一些项目中能看到有修改 P 数量的操作,开源数据库项目https://github.com/dgraph-io/dgraph 中将 GOMAXPROCS 调整到 128 来增加 IO 处理能力。
(3) P 的销毁逻辑
程序运行过程中如果没有调整 GOMAXPROC,未使用的 P 会放在调度器的全局队列 schedt.pidle ,不会被销毁。若调小了 GOMAXPROC,通过 p.destroy() 会将多余的 P 关联的资源回收掉并且会将 P 状态设置为 _Pdead,此时可能还有与 P 关联的 M 所以 P 对象不会被回收。
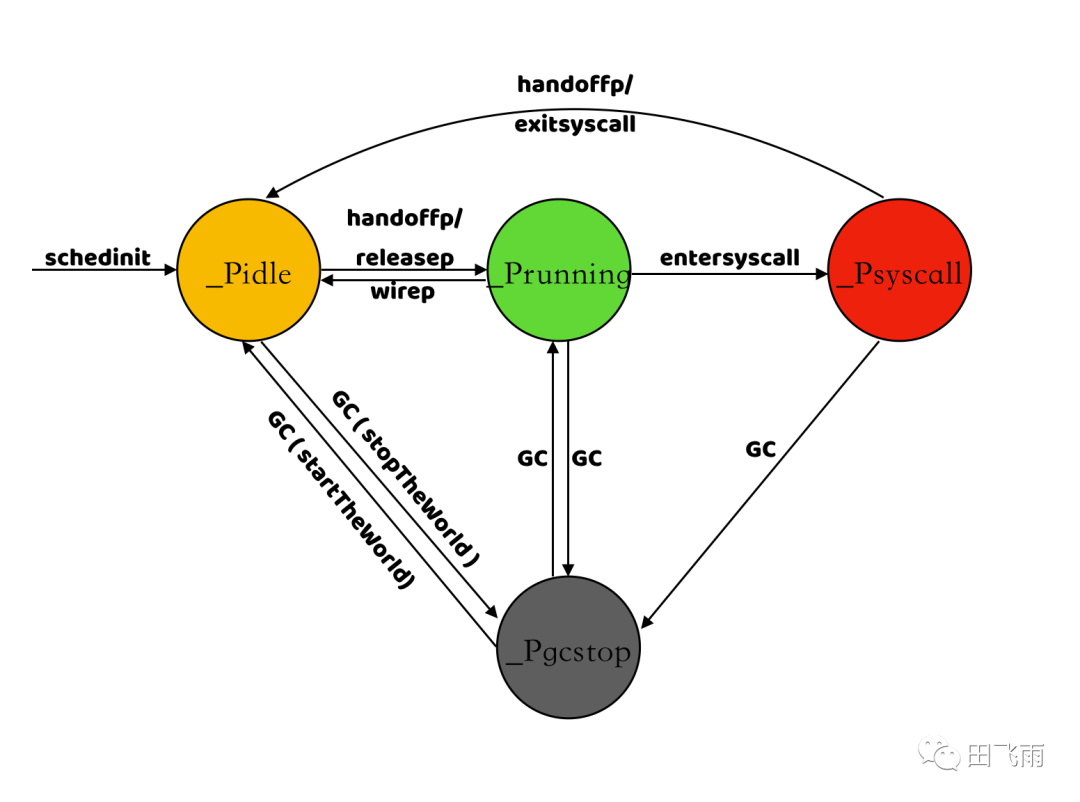
(4) P 的状态
| 状态 | 描述 |
|---|---|
_Pidle |
P 被初始化后的状态,此时还没有运行用户代码或者调度器 |
_Prunning |
P 被 M 绑定并且运行用户代码时的状态 |
_Psyscall |
当 G 被执行时需要进入系统调用时,P 会被关联的 M 设置为该状态 |
_Pdead |
在程序运行中发生 GC 时,P 会被关联的 M 设置为该状态 |
_Pgcstop |
程序在运行过程中如果将 GOMAXPROCS 数量减少时,此时多余的 P 会被设置为 _Pdead状态 |
2、M 的生命周期
M 对象的的结构体为:
type m struct {
// g0 记录工作线程(也就是内核线程)使用的栈信息,在执行调度代码时需要使用
g0 *g
morebuf gobuf // 堆栈扩容使用
......
gsignal *g // 用于信号处理
......
// 通过 tls (线程本地存储)结构体实现 m 与工作线程的绑定
tls [tlsSlots]uintptr
mstartfn func() // 表示m启动时立即执行的函数
curg *g // 指向正在运行的 goroutine 对象
caughtsig guintptr
p puintptr // 当前 m 绑定的 P
nextp puintptr // 下次运行时的P
oldp puintptr // 在执行系统调用之前绑定的P
id int64 // m 的唯一id
mallocing int32
throwing int32
preemptoff string // 是否要保持 curg 始终在这个 m 上运行
locks int32
dying int32
profilehz int32
spinning bool // 为 true 时表示当前 m 处于自旋状态,正在从其他线程偷工作
blocked bool // m 正阻塞在 note 上
newSigstack bool
printlock int8
incgo bool // 是否在执行 cgo 调用
freeWait uint32
fastrand [2]uint32
needextram bool
traceback uint8
// cgo 调用计数
ncgocall uint64
ncgo int32
cgoCallersUse uint32
cgoCallers *cgoCallers
// 没有 goroutine 需要运行时,工作线程睡眠在这个 park 成员上,
// 其它线程通过这个 park 唤醒该工作线程
doesPark bool
park note
alllink *m // 记录所有工作线程的链表
......
startingtrace bool
syscalltick uint32 // 执行过系统调用的次数
freelink *m
......
preemptGen uint32 // 完成的抢占信号数量
......
}(1) M 的新建
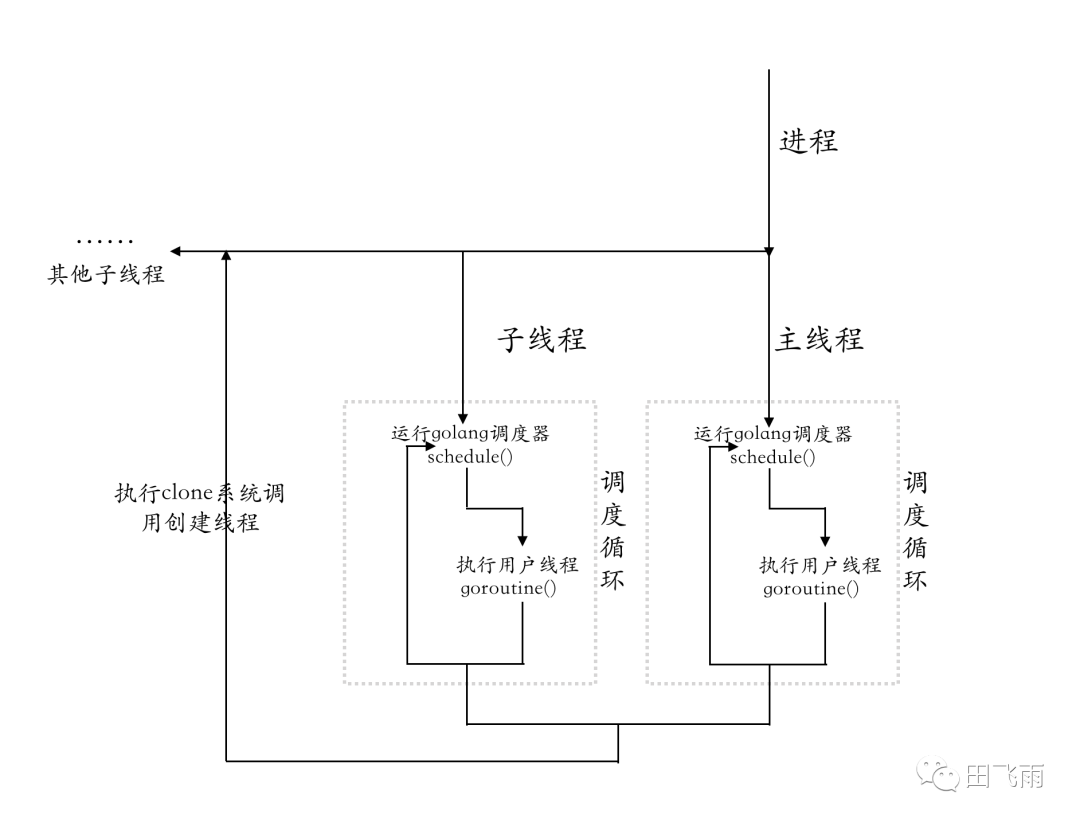
M 是 runtime 中的一个对象,代表线程,每创建一个 M 对象同时会创建一个线程与 M 进行绑定,线程的新建是通过执行 clone() 系统调用创建出来的。runtime 中定义 M 的最大数量为 10000 个,用户可以通过debug.SetMaxThreads(n) 进行调整。
在以下两种场景下会新建 M:
- 1、Golang 程序在启动时会创建主线程,主线程是第一个 M 即 M0;
- 2、当有新的 G 创建或者有 G 从
_Gwaiting进入_Grunning且还有空闲的P,此时会调用startm(),首先从全局队列(sched.midle)获取一个 M 和空闲的 P 绑定执行 G,如果没有空闲的 M 则会通过newm()创建 M;
(2) M 的销毁
M 不会被销毁,当找不到要运行的 G 或者绑定不到空闲的 P 时,会通过执行 stopm() 函数进入到睡眠状态,在以下两种情况下会执行 stopm() 函数进入到睡眠状态:
- 1、当 M 绑定的 P 无可运行的 G 且无法从其它 P 窃取可运行的 G 时 M 会尝试先进入自旋状态 (
spinning) ,只有部分 M 会进入自旋状态,处于自旋状态的 M 数量最多为非空闲状态的 P 数量的一半(sched.nmspinning < (procs- sched.npidle)/2),自旋状态的 M 会从其他 P 窃取可执行的 G,如果 M 在自旋状态未窃取到 G 或者未进入到自旋状态则会直接进入到睡眠转态; - 2、当 M 关联的 G 进入系统调用时,M 会主动和关联的 P 解绑 ,当 M 关联的 G 执行
exitsyscall()函数退出系统调用时,M 会找一个空闲的 P 进行绑定,如果找不到空闲的 P 此时 M 会调用stopm()进入到睡眠状态;
在 stopm() 函数中会将睡眠的 M 放到全局空闲队列(sched.midle)中。
(3) M 的运行
M 需要与 P 关联才能运行,并且 M 与 P 有亲和性,比如在执行 entersyscall() 函数进入系统调用时,M 会主动与当前的 P 解绑,M 会将当前的 P 记录到 m.oldp 中,在执行 exitsyscall() 函数退出系统调用时,M 会优先绑定 m.oldp 中的 P。
(4) M0 的作用以及与其他线程关联的 M 区别?
M0 是一个全局变量,在 src/runtime/proc.go 定义,M0 不需要在堆上分配内存,其他 M 都是通过 new(m) 创建出来的对象,其内存是从堆上进行分配的,M0 负责执行初始化操作和启动第一个 G,Golang 程序启动时会首先启动 M0,M0 和主线程进行了绑定,当 M0 启动第一个 G 即 main goroutine 后功能就和其他的 M 一样了 。
(5) 为什么要限制 M 的数量?
Golang 在 1.2 版本时添加了对 M 数量的限制 (runtime: limit number of operating system threads),M 默认的最大数量为 10000,在 1.17 版本中调度器初始化时在 schedinit() 函数中设置了默认值(sched.maxmcount = 10000)。
为什么要限制 M 的数量?在重构调度器的文章中 Potential Further Improvements 一节,Dmitry Vyukov 大佬已经提到过要限制 M 的数量了,在高并发或者反复会创建大量 goroutine 的场景中,需要更多的线程去执行 goroutine,线程过多时会耗尽系统资源或者触发系统的限制导致程序异常,内核在调度大量线程时也要消耗额外的资源,限制 M 的数量主要是防止程序不合理的使用。
Linux 上每个线程栈大小默认为 8M,如果创建 10000 个线程默认需要 78.125 G 内存,对普通程序来说内存使用量已经非常大了,此外,Linux 上下面这三个内核参数的大小也会影响创建线程的上限:
- /proc/sys/kernel/threads-max:表示系统支持的最大线程数;
- /proc/sys/kernel/pid_max:表示系统全局的 PID 号数值的限制,每一个进程或线程都有 ID,ID 的值超过这个数,进程或线程就会创建失败;
- /proc/sys/vm/max_map_count:表示限制一个进程可以拥有的 VMA(虚拟内存区域)的数量;
(6) M 的状态
通过 M 的新建和销毁流程的分析,M 有三种状态:运行、自旋、睡眠,这三种状态之间的转换如下所示:
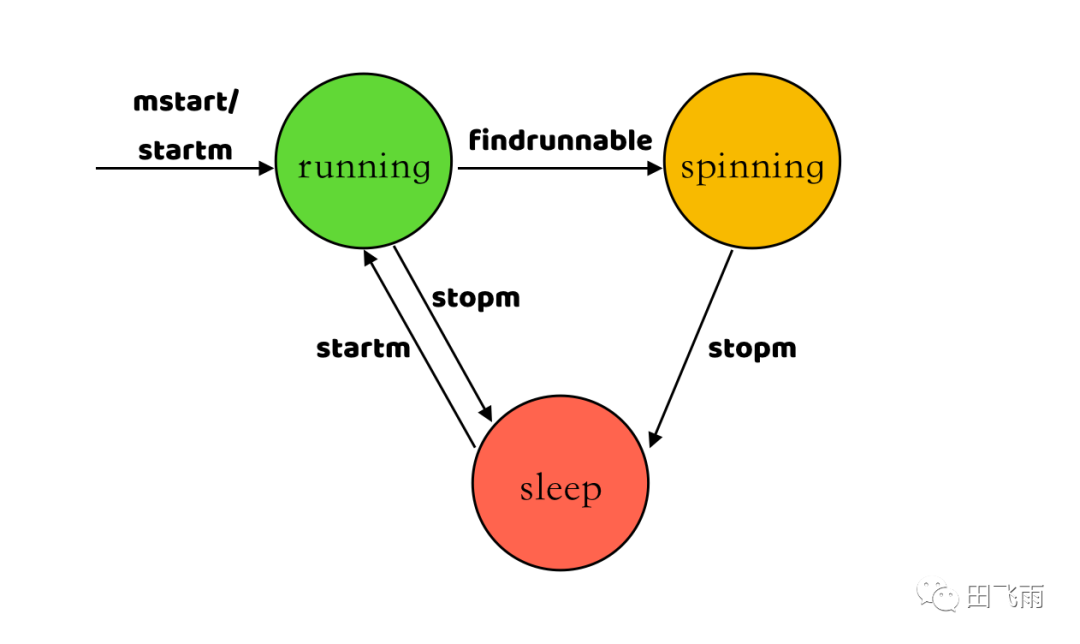
3、G 的生命周期
G 的结构体信息如下所示:
type g struct {
// 当前 Goroutine 的栈内存范围
stack stack
stackguard0 uintptr
stackguard1 uintptr
_panic *_panic // 当前 g 中与 panic 相关的处理
_defer *_defer // 当前 g 中与 defer 相关的处理
m *m // 绑定的 m
// 存储当前 Goroutine 调度相关的数据,上下方切换时会把当前信息保存到这里
sched gobuf
......
param unsafe.Pointer // 唤醒G时传入的参数
atomicstatus uint32 // 当前 G 的状态
stackLock uint32
goid int64 // 当前 G 的 ID
schedlink guintptr
waitsince int64 // G 阻塞时长
waitreason waitReason // 阻塞原因
// 抢占标记
preempt bool
preemptStop bool
preemptShrink bool
asyncSafePoint bool
paniconfault bool
gcscandone bool
throwsplit bool
// 表示是否有未加锁定的channel指向到了g 栈
activeStackChans bool
// 表示g 是放在chansend 还是 chanrecv,用于栈的收缩
parkingOnChan uint8
raceignore int8 // ignore race detection events
sysblocktraced bool // StartTrace has emitted EvGoInSyscall about this goroutine
tracking bool // whether we're tracking this G for sched latency statistics
trackingSeq uint8 // used to decide whether to track this G
runnableStamp int64 // timestamp of when the G last became runnable, only used when tracking
runnableTime int64 // the amount of time spent runnable, cleared when running, only used when tracking
sysexitticks int64 // cputicks when syscall has returned (for tracing)
traceseq uint64 // trace event sequencer
tracelastp puintptr // last P emitted an event for this goroutine
lockedm muintptr
sig uint32
writebuf []byte
sigcode0 uintptr
sigcode1 uintptr
sigpc uintptr
gopc uintptr // goroutine 当前运行函数的 PC 值
ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors)
startpc uintptr // 触发这个 goroutine 的函数的 PC 值
racectx uintptr
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
cgoCtxt []uintptr // cgo traceback context
labels unsafe.Pointer // profiler labels
timer *timer // cached timer for time.Sleep
selectDone uint32 // are we participating in a select and did someone win the race?
// GC 时存储当前 Goroutine 辅助标记的对象字节数
gcAssistBytes int64
}(1) G 的新建
在 Golang 程序启动时,主线程会创建第一个 goroutine 来执行 main 函数,在 main 函数中如果用户使用了 go 关键字会创建新的 goroutine ,在 goroutine 中用户也可以使用 go 关键字继续创建新的 goroutine。goroutine 的创建都是通过调用 golang runtime 中的 newproc() 函数来完成的。每个 goroutine 在新建时仅会分配 2K 大小,在 runtime 中没有设置 goroutine 的数量上限。goroutine 的数量受系统资源的限制(CPU、内存、文件描述符等)。如果 goroutine 中只有简单的逻辑,理论上起多少个 goroutine 都是没有问题的,但 goroutine 里面要是有创建网络连接或打开文件等操作,goroutine 过多可能会出现 too many files open 或 Resource temporarily unavailable 等报错导致程序执行异常。
新建的 G 会通过 runqput() 函数优先被放入到当前 G 关联 P 的 runnext 队列中,P 的 runnext 队列中只会保存一个 G,如果 runnext 队列中已经有 G,会用新建的 G 将其替换掉,然后将 runnext 中原来的 G 放到 P 的本地队列即 runq 中,如果 P 的本地队列满了,则将 P 本地队列一半的 G 移动到全局队列 sched.runq 中。此处将新建的 G 首先移动到 P 的 runnext 中主要是为了提高性能,runnext 是 P 完全私有的队列,如果将 G 放在 P 本地队列 runq 中, runq 队列中的 G 可能因其他 M 的窃取发生了变化,每一次从 P 本地队列获取 G 时都需要执行 atomic.LoadAcq 和 atomic.CasRel 原子操作,这会带来额外的开销。
(2) G 的销毁
G 在退出时会执行 goexit() 函数,G 的状态会从 _Grunning 转换为 _Gdead,但 G 对象并不会被直接释放 ,而是会通过 gfput() 被放入到所关联 P 本地或者全局的闲置列表 gFree 中以便复用,优先放入到 P 本地队列中,如果 P 本地队列中 gFree 超过 64 个,仅会在 P 本地队列中保存 32 个,把超过的 G 都放入到全局闲置队列 sched.gFree 中。
(3) G 的 运行
G 与 M 绑定才能运行,而 M 需要与 P 绑定才能运行,所以理论上同一时间运行 G 的数量等于 P 的数量,M 不保留 G 的状态,G 会将状态保留在其 gobuf 字段,因此 G 可以跨 M 进行调度。M 在找到需要运行的 G 后,会通过汇编函数 gogo() 从 g0 栈切换到用户 G 的栈运行。
(4) G 有哪些状态?
G 的状态在 src/runtime/runtime2.go 文件中定义了,主要分为三种,一个是 goroutine 正常运行时的几个状态,然后是与 GC 有关的状态的,其余几个状态是未使用的。
每种转态的作用以及状态之间的转换关系如下所示:
| 状态 | 描述 |
|---|---|
_Gidle |
刚刚被创建并且还没有被初始化 |
_Grunnable |
没有执行代码,没有栈的所有权,存储在运行队列中 |
_Grunning |
可以执行代码,拥有栈的所有权,已经绑定了 M 和 P |
_Gsyscall |
正在执行系统调用 |
_Gwaiting |
由于运行时而被阻塞,没有执行用户代码并且不在运行队列上 |
_Gdead |
运行完成处于退出状态 |
_Gcopystack |
栈正在被拷贝 |
_Gpreempted |
由于抢占而被阻塞,等待唤醒 |
_Gscan |
GC 正在扫描栈空间 |
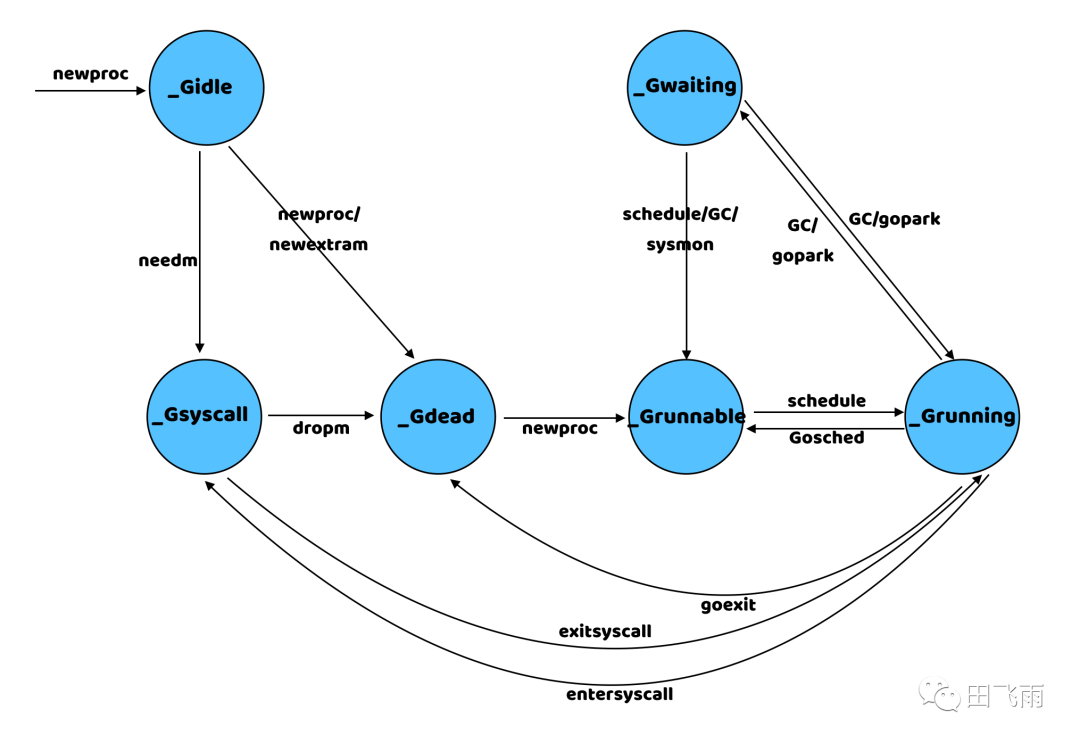
4、g0 的作用
type m struct {
g0 *g // goroutine with scheduling stack
......
}在 runtime 中有两种 g0,一个是 m0 关联的 g0,另一种是其他 m 关联的 g0,m0 关联的 g0 是以全局变量的方式定义的,其内存空间是在系统的栈上进行分配的,大小为 64K - 104 字节,其他 m 关联的 g0 是在堆上分配的栈,默认为 8K。
src/runtime/proc.go#1879
if iscgo || mStackIsSystemAllocated() {
mp.g0 = malg(-1)
} else {
// sys.StackGuardMultiplier 在 linux 系统上值为 1
mp.g0 = malg(8192 * sys.StackGuardMultiplier)
}每次启动一个 M 时,创建的第一个 goroutine 就是 g0,每个 M 都会有自己的 g0,g0 主要用来记录工作线程使用的栈信息,仅用于负责调度,在执行调度代码时需要使用这个栈。执行用户 goroutine 代码时,使用用户 goroutine 的栈,调度时会发生栈的切换。
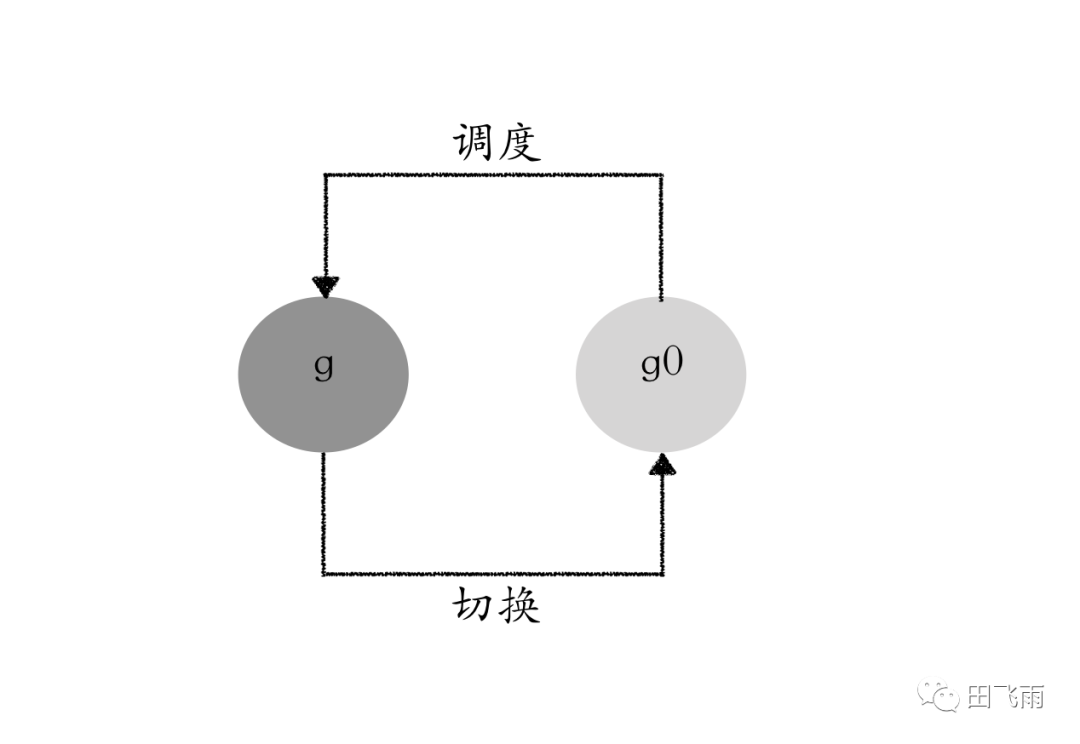
systemstack() 函数封装调用,systemstack() 函数的作用是切换到 g0 栈,然后执行对应的函数最后再切换回原来的栈并返回,为什么这些代码需要在 g0 栈上运行?原则上只要某函数有 nosplit 这个系统注解就需要在 g0 栈上执行,因为加了 nosplit 编译器在编译时不会在函数前面插入检查栈溢出的代码,这些函数在执行时有可能会导致栈溢出,而 g0 栈比较大,在编译时如果对runtime中每个函数都做栈溢出检查会影响效率,所以才会切到 g0 栈。
总结
本文主要分析了 Golang GPM 的模型,在阅读 runtime 代码的过程中发现代码中有很多细节需要花大量时间分析,文中仅对其大框架做了一些简单的说明,也有部分细节顺便被带入,在后面的文章中,会对许多细节再次进行分析。