前端模块依赖关系分析与应用
Meta
摘要
这篇分享主要的内容是是如何使用webpack的stats对象进行依赖和编译速度的解析,该对象包含大量的编译时信息,我们可以用它生成包含有关于模块的统计数据的 JSON 文件。这些统计数据不仅可以帮助开发者来分析应用的依赖图表,还可以优化编译的速度。
大纲
1、描述开发过程中遇到的问题,以及本文致力提供的解决的问题思路
2、说明webpack以及文章中常用到的module、chunk、bundle等概念
3、描述webpack运行中module依赖关系的构建以及webpack关键对象的职能
4、引出webpack的stats对象,介绍一下该对象的来源以及包含的信息和如何导出stats.json文件
5、如何使用该对象来分析模块之间的依赖关系以及部分相关工具的使用
观众收益
希望大家在听完此次分享后,对webpack的以来构建以及chunk和module的关系有一定的了解,能够通过webpack导出的的stats.json文件,检索出模块的依赖关系,判断出组件的修改会影响哪些业务,进行合理的回归测试
引言
在日常的开发过程中,经常会遇到的场景是对某一个公共组件进行修改的场景,公共组件可能是在多个地方进行引用,那么组件的修改可能是会影响多个业务场景的,但是往往会由于刚刚接手项目或者随着时间的跨度加大,依靠人力找出所有引入该组件的场景是极其困难的,只能不停的搜索组件名,甚至引入该组件的组件,也可能被多个场景引入,可能会导致回归测试无法全面覆盖,进而导致线上问题
解决方案
概念声明
首先我们要声明几个概念,以便接下来的大家的理解:
1、Module: Module 是离散功能块,相比于完整程序提供了更小的接触面。精心编写的模块提供了可靠的抽象和封装界限,使得应用程序中每个模块都具有条理清楚的设计和明确的目的。简单来说就是没有被编译之前的代码,我们书写的一个个文件就是一个个的module。
2、Chunk: 此 webpack 特定术语在内部用于管理捆绑过程。输出束(bundle)由块组成,其中有几种类型(例如 entry 和 child )。通常,块 直接与 输出束 (bundle)相对应,但是,有些配置不会产生一对一的关系。简单来说是通过 webpack 的根据文件引用关系生成 chunk 文件,基本是一个入口文件对应一个chunk。
3、Bundle: bundle 由许多不同的模块生成,包含已经经过加载和编译过程的源文件的最终版本。webpack 处理好 chunk 文件后,生成运行在浏览器中的代码就是bundle,需要注意的是理论上chunk和bundle一一对应的,但是当你配置了代码分离、代码提取等时,一个chunk会根据配置生成多个bundle文件
依赖关系的建立过程
构建阶段从 entry 开始递归解析资源与资源的依赖,在 compilation 对象内逐步构建出 module 集合以及 module 之间的依赖关系,核心流程:
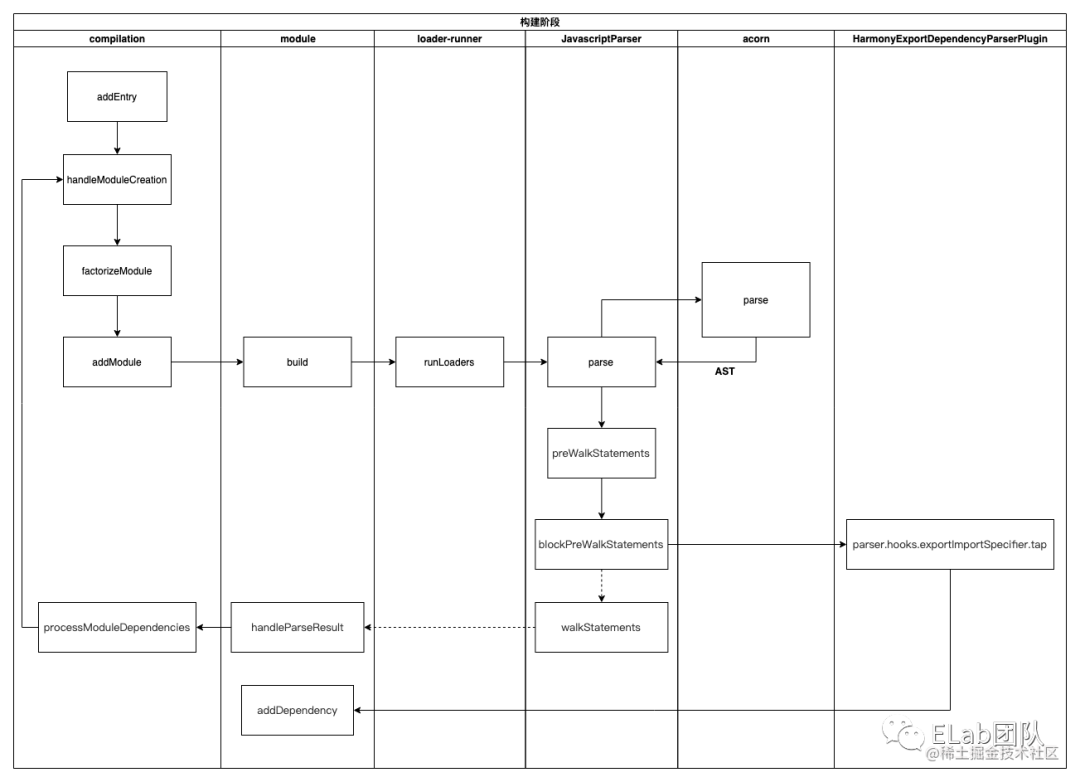
说明一下,构建阶段从入口文件开始:
- 调用
handleModuleCreate,根据文件类型构建module子类 - 调用 loader-runner[1] 仓库的
runLoaders转译module内容,通常是从各类资源类型转译为 JavaScript 文本 - 调用 acorn[2] 将 JS 文本解析为AST
- 遍历 AST,触发各种钩子
a . 在 HarmonyExportDependencyParserPlugin 插件监听 exportImportSpecifier 钩子,解读 JS 文本对应的资源依赖
b . 调用 module 对象的 addDependency 将依赖对象加入到 module 依赖列表中
5 . AST 遍历完毕后,调用 module.handleParseResult 处理模块依赖
6 . 对于 module 新增的依赖,调用 handleModuleCreate ,控制流回到第一步
7 . 所有依赖都解析完毕后,构建阶段结束
这个过程中数据流 module => ast => dependences => module ,先转 AST 再从 AST 找依赖。这就要求 loaders 处理完的最后结果必须是可以被 acorn 处理的标准 JavaScript 语法,比如说对于图片,需要从图像二进制转换成类似于 export default "data:image/png;base64,xxx" 这类 base64 格式或者 export default "http://xxx" 这类 url 格式。
compilation 按这个流程递归处理,逐步解析出每个模块的内容以及 module 依赖关系,后续就可以根据这些内容打包输出。
示例:层级递进
假如有如下图所示的文件依赖树: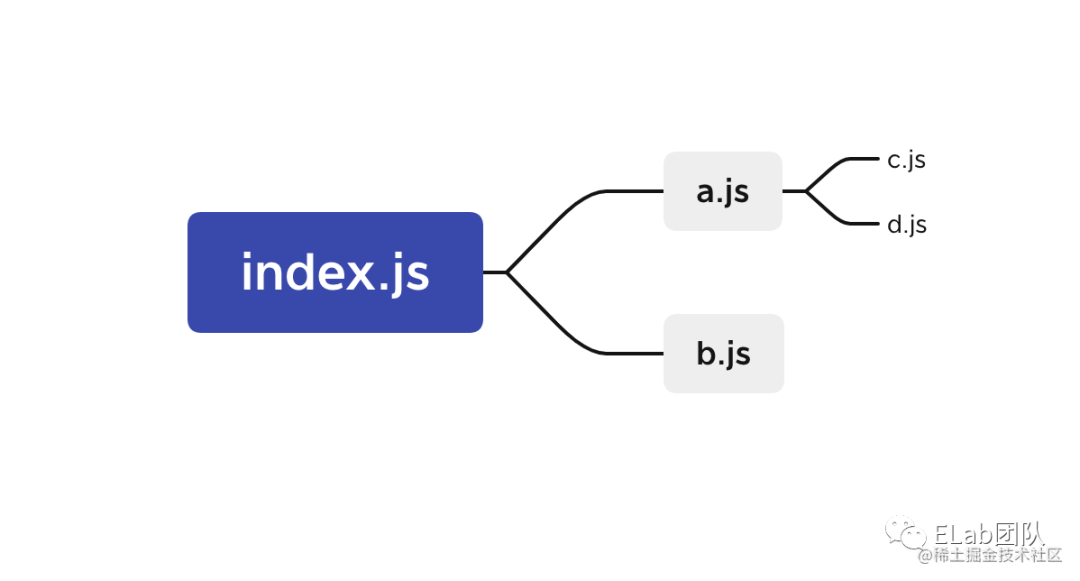
index.js 为 entry 文件,依赖于 a/b 文件;a 依赖于 c/d 文件。初始化编译环境之后,EntryPlugin 根据 entry 配置找到 index.js 文件,调用 compilation.addEntry 函数触发构建流程,构建完毕后内部会生成这样的数据结构:
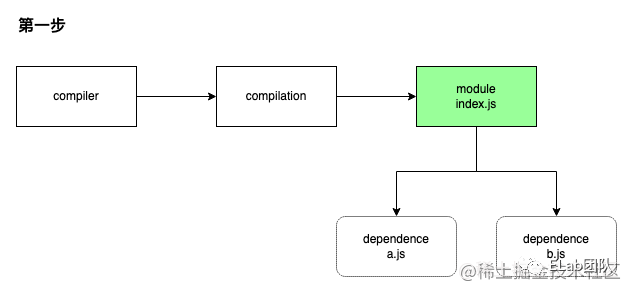
此时得到 module[index.js] 的内容以及对应的依赖对象 dependence[a.js] 、dependence[b.js] 。OK,这就得到下一步的线索:a.js、b.js,根据上面流程图的逻辑继续调用 module[index.js] 的 handleParseResult 函数,继续处理 a.js、b.js 文件,递归上述流程,进一步得到 a、b 模块:
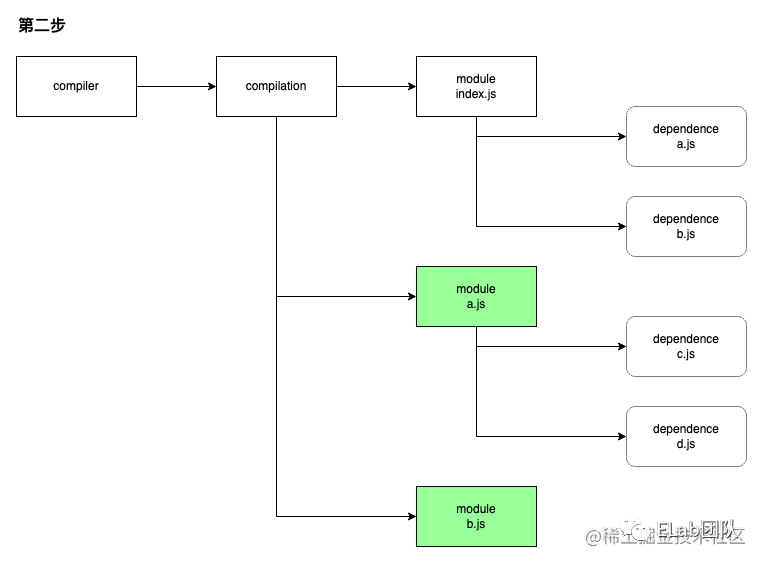
从 a.js 模块中又解析到 c.js/d.js 依赖,于是再再继续调用 module[a.js] 的 handleParseResult ,再再递归上述流程:
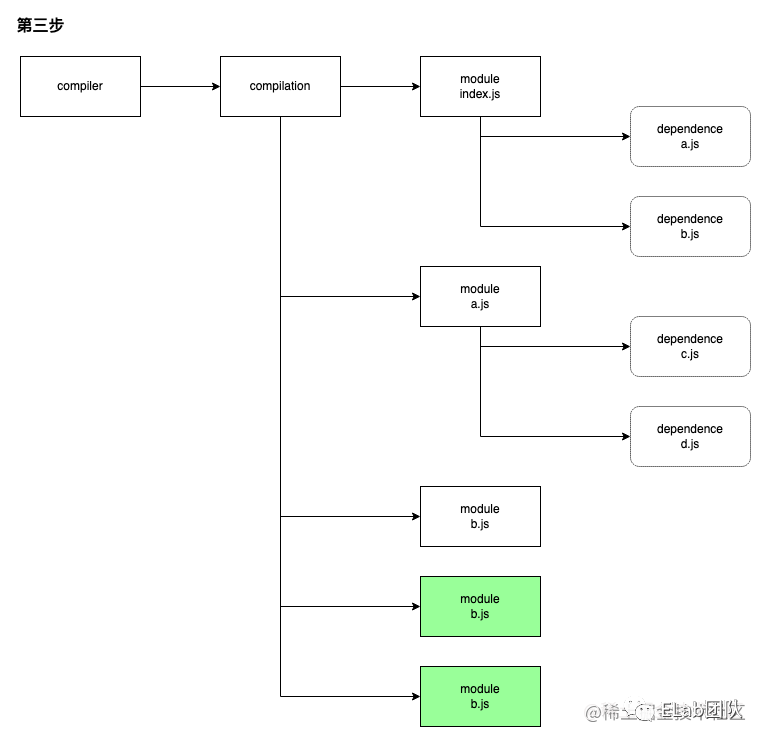
到这里解析完所有模块后,发现没有更多新的依赖,就可以继续推进。
从构建流程中我们可以清楚地知道,webpack如何检索出所有的依赖,而且它也会把这些处理关系清晰的记录下来,那我们就要说到stata对象了,给大家一张webpack的知识体系图,可以看到核心类Stats:
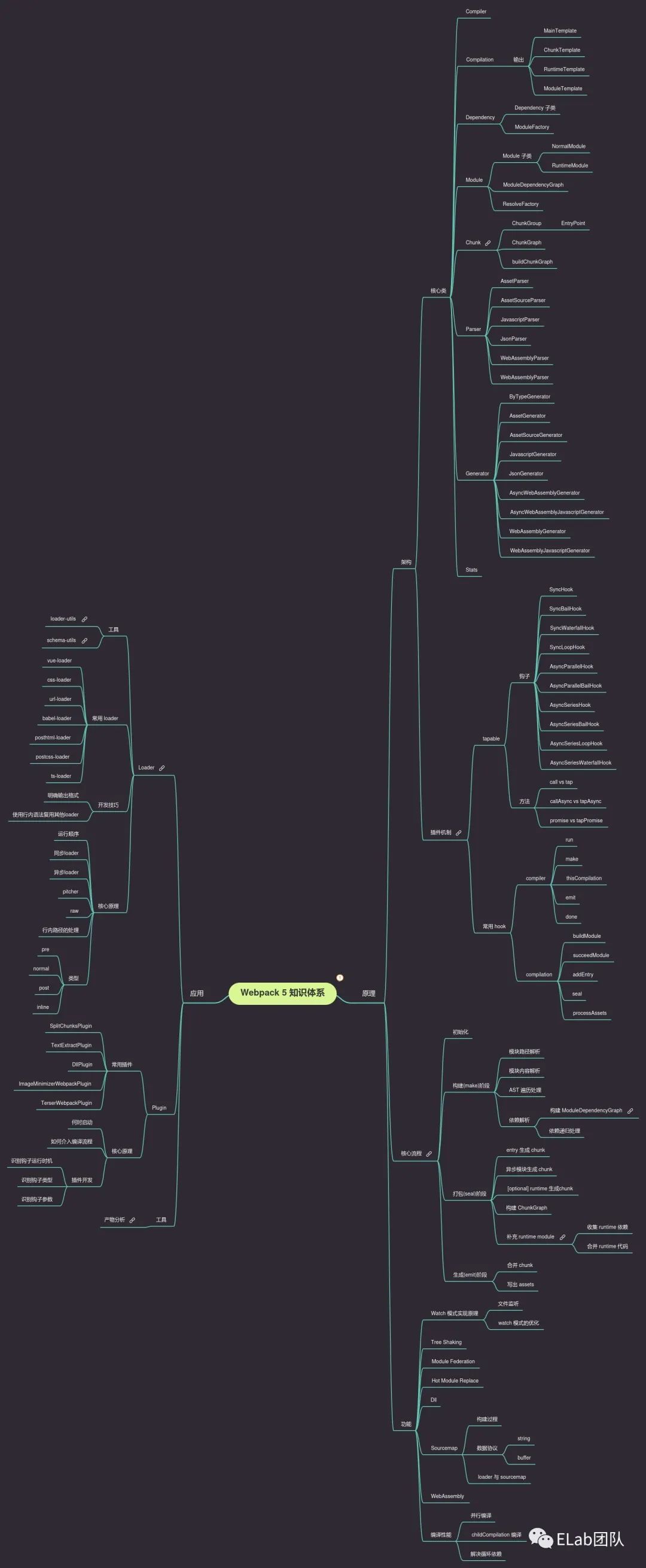
Stats 配置
stats:是控制 webpack 如何打印出开发环境或者生产环境的打包结果信息,这些统计信息不仅可以帮助开发者来分析应用的依赖图表,还可以优化编译的速度。这个 JSON 文件可以通过以下的命令来生成:
webpack --profile --json > stats.json
stats.json文件中包含的信息是可以在配置文件的进行配置的,下面是它的的配置项,每一个配置项都有它的默认值:
module.exports={
...
stats: {
// 未定义选项时,stats 选项的备用值(fallback value)(优先级高于 webpack 本地默认值)
all: undefined,
// 添加资源信息
assets: true,
// 对资源按指定的字段进行排序
// 你可以使用 `!field` 来反转排序。
assetsSort: "field",
// 添加构建日期和构建时间信息
builtAt: true,
// 添加缓存(但未构建)模块的信息
cached: true,
// 显示缓存的资源(将其设置为 `false` 则仅显示输出的文件)
cachedAssets: true,
// 添加 children 信息
children: true,
// 添加 chunk 信息(设置为 `false` 能允许较少的冗长输出)
chunks: true,
// 将构建模块信息添加到 chunk 信息
chunkModules: true,
// 添加 chunk 和 chunk merge 来源的信息
chunkOrigins: true,
// 按指定的字段,对 chunk 进行排序
// 你可以使用 `!field` 来反转排序。默认是按照 `id` 排序。
chunksSort: "field",
// 用于缩短 request 的上下文目录
context: "../src/",
// `webpack --colors` 等同于
colors: false,
// 显示每个模块到入口起点的距离(distance)
depth: false,
// 通过对应的 bundle 显示入口起点
entrypoints: false,
// 添加 --env information
env: false,
// 添加错误信息
errors: true,
// 添加错误的详细信息(就像解析日志一样)
errorDetails: true,
// 将资源显示在 stats 中的情况排除
// 这可以通过 String, RegExp, 获取 assetName 的函数来实现
// 并返回一个布尔值或如下所述的数组。
excludeAssets: "filter" | /filter/ | (assetName) => ... return true|false |
["filter"] | [/filter/] | [(assetName) => ... return true|false],
// 将模块显示在 stats 中的情况排除
// 这可以通过 String, RegExp, 获取 moduleSource 的函数来实现
// 并返回一个布尔值或如下所述的数组。
excludeModules: "filter" | /filter/ | (moduleSource) => ... return true|false |
["filter"] | [/filter/] | [(moduleSource) => ... return true|false],
// 和 excludeModules 相同
exclude: "filter" | /filter/ | (moduleSource) => ... return true|false |
["filter"] | [/filter/] | [(moduleSource) => ... return true|false],
// 添加 compilation 的哈希值
hash: true,
// 设置要显示的模块的最大数量
maxModules: 15,
// 添加构建模块信息
modules: true,
// 按指定的字段,对模块进行排序
// 你可以使用 `!field` 来反转排序。默认是按照 `id` 排序。
modulesSort: "field",
// 显示警告/错误的依赖和来源(从 webpack 2.5.0 开始)
moduleTrace: true,
// 当文件大小超过 `performance.maxAssetSize` 时显示性能提示
performance: true,
// 显示模块的导出
providedExports: false,
// 添加 public path 的信息
publicPath: true,
// 添加模块被引入的原因
reasons: true,
// 添加模块的源码
source: true,
// 添加时间信息
timings: true,
// 显示哪个模块导出被用到
usedExports: false,
// 添加 webpack 版本信息
version: true,
// 添加警告
warnings: true,
// 过滤警告显示(从 webpack 2.4.0 开始),
// 可以是 String, Regexp, 一个获取 warning 的函数
// 并返回一个布尔值或上述组合的数组。第一个匹配到的为胜(First match wins.)。
warningsFilter: "filter" | /filter/ | ["filter", /filter/] | (warning) => ... return true|false
}
};stats.json文件
结构 (Structure)
最外层的输出 JSON 文件比较容易理解,但是其中还是有一小部分嵌套的数据不是那么容易理解。不过放心,这其中的每一部分都在后面有更详细的解释。
{
"version": "1.4.13", // 用来编译的 webpack 的版本
"hash": "11593e3b3ac85436984a", // 编译使用的 hash
"time": 2469, // 编译耗时 (ms)
"filteredModules": 0, // 当 `exclude`传入`toJson` 函数时,统计被无视的模块的数量
"outputPath": "/", // path to webpack 输出目录的 path 路径
"assetsByChunkName": {
// 用作映射的 chunk 的名称
"main": "web.js?h=11593e3b3ac85436984a",
"named-chunk": "named-chunk.web.js",
"other-chunk": [
"other-chunk.js",
"other-chunk.css"
]
},
"assets": [
// asset 对象 (asset objects) 的数组
],
"chunks": [
// chunk 对象 (chunk objects) 的数组
],
"modules": [
// 模块对象 (module objects) 的数组
],
"errors": [
// 错误字符串 (error string) 的数组
],
"warnings": [
// 警告字符串 (warning string) 的数组
]
}Asset对象 (Asset Objects)
每一个 assets 对象都表示一个编译出的 output 文件。assets 都会有一个共同的结构:
{
"chunkNames": [], // 这个 asset 包含的 chunk
"chunks": [ 10, 6 ], // 这个 asset 包含的 chunk 的 id
"emitted": true, // 表示这个 asset 是否会让它输出到 output 目录
"name": "10.web.js", // 输出的文件名
"size": 1058 // 文件的大小
}Chunk 对象 (Chunk Objects)
每一个 chunks 表示一组称为 chunk[3] 的模块。每一个对象都满足以下的结构。
{
"entry": true, // 表示这个 chunk 是否包含 webpack 的运行时
"files": [
// 一个包含这个 chunk 的文件名的数组
],
"filteredModules": 0, // 见上文的 结构
"id": 0, // 这个 chunk 的id
"initial": true, // 表示这个 chunk 是开始就要加载还是 懒加载(lazy-loading)
"modules": [
// 模块对象 (module objects)的数组
"web.js?h=11593e3b3ac85436984a"
],
"names": [
// 包含在这个 chunk 内的 chunk 的名字的数组
],
"origins": [
// 下文详述
],
"parents": [], // 父 chunk 的 ids
"rendered": true, // 表示这个 chunk 是否会参与进编译
"size": 188057 // chunk 的大小(byte)
}chunks 对象还会包含一个 来源 (origins) ,来表示每一个 chunk 是从哪里来的。来源 (origins) 是以下的形式
{
"loc": "", // 具体是哪行生成了这个chunk
"module": "(webpack)\test\browsertest\lib\index.web.js", // 模块的位置
"moduleId": 0, // 模块的ID
"moduleIdentifier": "(webpack)\test\browsertest\lib\index.web.js", // 模块的地址
"moduleName": "./lib/index.web.js", // 模块的相对地址
"name": "main", // chunk的名称
"reasons": [
// 模块对象中`reason`的数组
]
}模块对象 (Module Objects)
每一个在依赖图表中的模块都可以表示成以下的形式,这一部分正是我们需要重点关注的,模块之间的依赖信息都在这一部分,
{
"assets": [
// asset对象 (asset objects)的数组
],
"built": true, // 表示这个模块会参与 Loaders , 解析, 并被编译
"cacheable": true, // 表示这个模块是否会被缓存
"chunks": [
// 包含这个模块的 chunks 的 id
],
"errors": 0, // 处理这个模块发现的错误的数量
"failed": false, // 编译是否失败
"id": 0, // 这个模块的ID (类似于 `module.id`)
"identifier": "(webpack)\test\browsertest\lib\index.web.js", // webpack内部使用的唯一的标识
"name": "./lib/index.web.js", // 实际文件的地址
"optional": false, // 每一个对这个模块的请求都会包裹在 `try... catch` 内 (与ESM无关)
"prefetched": false, // 表示这个模块是否会被 prefetched
"profile": {
// 有关 `--profile` flag 的这个模块特有的编译数据 (ms)
"building": 73, // 载入和解析
"dependencies": 242, // 编译依赖
"factory": 11 // 解决依赖
},
"reasons": [
// 见下文描述
],
"size": 3593, // 预估模块的大小 (byte)
"source": "// Should not break it...\r\nif(typeof...", // 字符串化的输入
"warnings": 0 // 处理模块时警告的数量
}每一个模块都包含一个 理由 (reasons) 对象,这个对象描述了这个模块被加入依赖图表的理由。每一个 理由 (reasons) 都类似于上文 chunk objects[4]中的 来源 (origins):
{
"loc": "33:24-93", // 导致这个被加入依赖图标的代码行数
"module": "./lib/index.web.js", // 所基于模块的相对地址 context
"moduleId": 0, // 模块的 ID
"moduleIdentifier": "(webpack)\test\browsertest\lib\index.web.js", // 模块的地址
"moduleName": "./lib/index.web.js", // 可读性更好的模块名称 (用于 "更好的打印 (pretty-printing)")
"type": "require.context", // 使用的请求的种类 (type of request)
"userRequest": "../../cases" // 用来 `import` 或者 `require` 的源字符串
}错误与警告
错误 (errors) 和 警告 (warnings) 会包含一个字符串数组。每个字符串包含了信息和栈的追溯:
../cases/parsing/browserify/index.js
Critical dependencies:
2:114-121 This seem to be a pre-built javascript file. Even while this is possible, it's not recommended. Try to require to orginal source to get better results.
@ ../cases/parsing/browserify/index.js 2:114-121最佳实践
给出总结、方法论、套路,让观众有强烈的成长感和获得感。
总结一下,实现过程如下:
在webpack.config.js文件中添加关于stats的配置,如:
module.exports={
...
stats:{
chunkModules: false,
chunks: false,
modules: true,
children: false,
exclude: [/.*node_modules\/.*/]
},
}
运行:webpack --config webpack.config.js --profile --json > stats.json
--profile:提供每一步编译的具体时间
--json:将编译信息以JSON文件的类型输出wen
这样就能在项目的根目录即webpack.config.js的同级目录生成一个stats.json文件。
在线分析,可以使我们对构建结果有全方位的分析
Webpack 官方提供了一个可视化分析工具 Webpack Analyse[5],它是一个在线 Web 应用。
打开 Webpack Analyse 链接的网页后,你就会看到一个弹窗提示你上传 JSON 文件,也就是需要上传上面讲到的 stats.json 文件,如图:
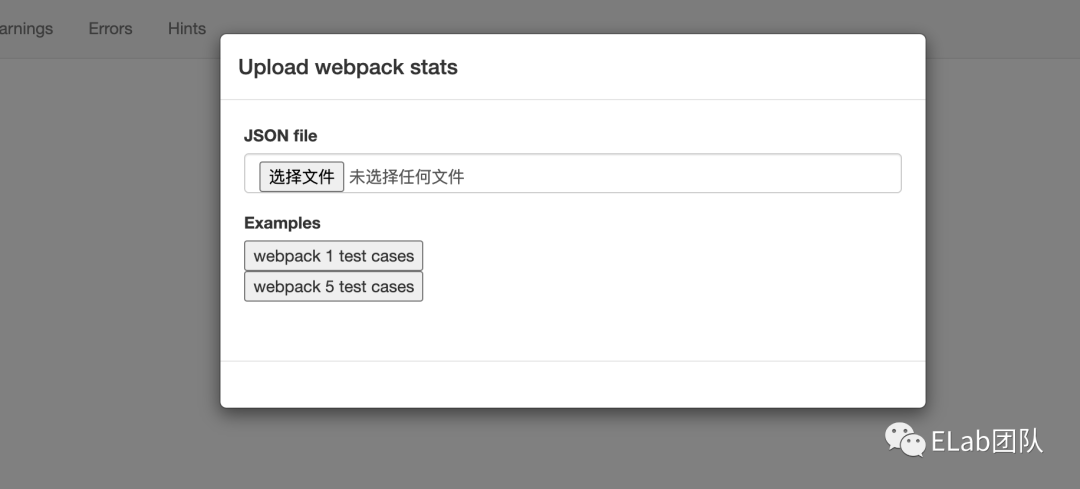
stats.json 文件发达到服务器,而是在浏览器本地解析,你不用担心自己的代码为此而泄露。选择文件后,你马上就能如下的效果图(可以先使用网页提供的Examples看一下效果):
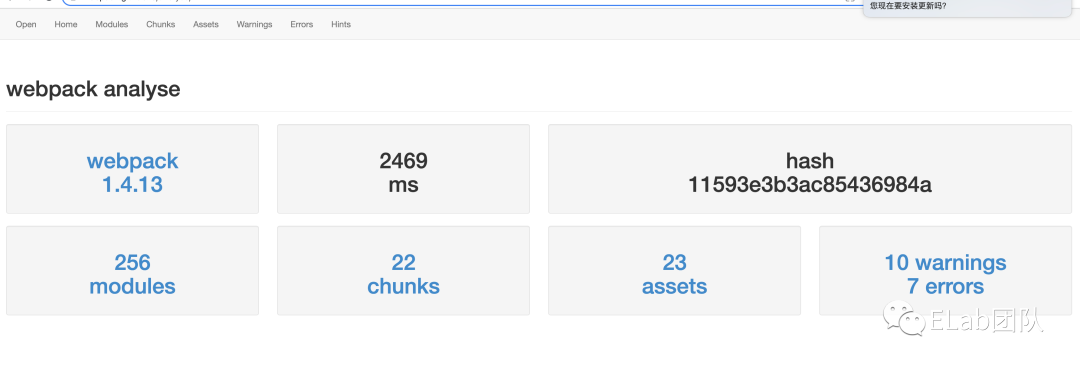
-
Modules:展示所有的模块,每个模块对应一个文件。并且还包含所有模块之间的依赖关系图、模块路径、模块ID、模块所属 Chunk、模块大小;
-
Chunks:展示所有的代码块,一个代码块中包含多个模块。并且还包含代码块的ID、名称、大小、每个代码块包含的模块数量,以及代码块之间的依赖关系图;
-
Assets:展示所有输出的文件资源,包括
.js、.css、图片等。并且还包括文件名称、大小、该文件来自哪个代码块; -
Warnings:展示构建过程中出现的所有警告信息;
-
Errors:展示构建过程中出现的所有错误信息;
-
Hints:展示处理每个模块的过程中的耗时。
我们的关注点主要是放在Module功能上,这里会显示出模块的依赖关系:
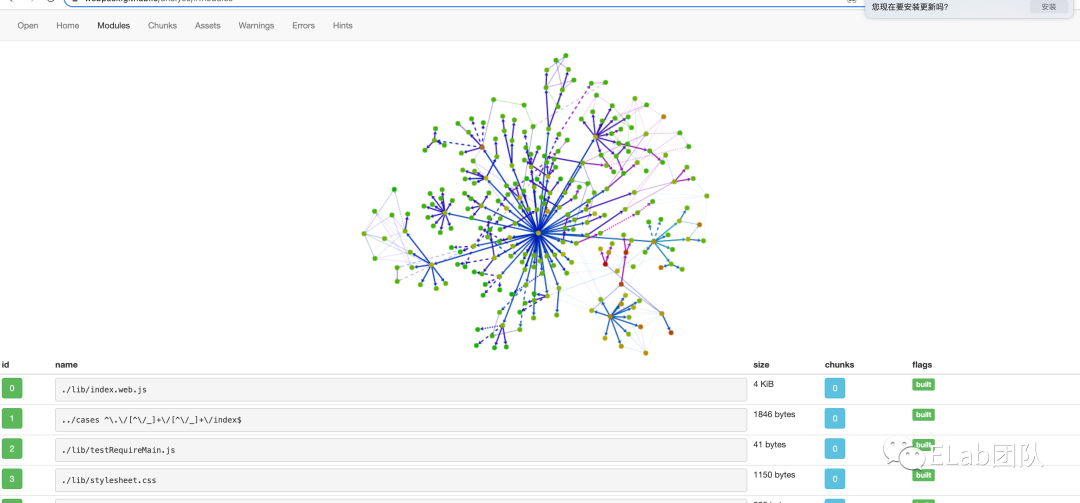
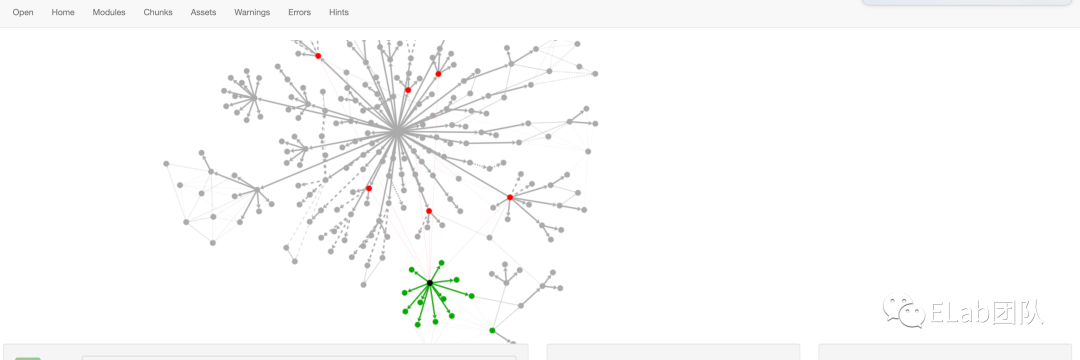
当然这样的依赖查询只能看到前后的module关系,当我们修改一个组件时,自然是希望拿到从该节点开始,一直向上检索,一直查询到最顶层组件,这样才是我们需要的,但是这样就需要我们手动处理。
手动解析,可以获取到组件的依赖链
我们已经知道上面生成的stats.json包含我们需要的依赖信息,那么当我们需要如果需要反推出我们的测试范围,那么我们接下来要做的就是根据这个文件的结构来提取其中的部分数据,构建出我们需要的数据结构。
重点关注的是module属性,以及module中每个对象的reasons属性:该属性包含该组件在哪里被依赖,那我们的大致想法就是构建一个树形结构,从目标module开始,作为根节点,遍历它的reasons属性,查找哪些组件依赖该组件,然后在module数组中找到该module,再遍历它的reasons属性,直到最后查找到顶层组件。这样一个树结构是自下而上生成的,不利于我们查找受影响的组件,所以我们需要遍历树结构,获取它的每一条路径,就能自上而下获取到所有的路径。
const fs = require('fs')
const loadsh=require('loadsh')
fs.readFile('../../nodeServerClient/stats.json', 'utf8' , (err, data) => {
if (err) {
console.error(err)
return
}
const fileObj=JSON.parse(data);//将读取到的文件内容,转换成JSON对象
const moduleArr=fileObj.modules;//获取模块数据的数组
const moduleObj={};
moduleArr.forEach(ele => { //将数组转换为对象的属性,key值为数组每一项的nameForCondition属性,方便之后查找到该module
moduleObj[ele.nameForCondition]=ele;
});
let filename='/Users/bytedance/workSpace/personDir/vscode_workspace/nodeServerClient/src/controller/ser.js'
const tree=[];
//从改变的模块向上检索出树形的结构图
function createTree(filename,tree){
//获取变更的module对象
/* const targetmodule=moduleObj[Object.keys(moduleObj).filter(ele=>{
return ele.includes(filename)||ele===filename;
})[0]]; */
const targetmodule=moduleObj[filename];
if(!targetmodule){
console.log(`未获取到:${filename}模块`);
return;
};
//查看当前的一级中是否已经添加了该module,因为一个module依赖另一个module时,会在该module的reasons中出现多次
let isHaveTarget=tree.filter(item=>{
return item.name===targetmodule.nameForCondition
});
if(isHaveTarget&&isHaveTarget.length>0){
return;
}
//将该模块放到该节点中
tree.push({
name:targetmodule.nameForCondition,
children:[]
});
if(targetmodule.reasons&&targetmodule.reasons.length>0){
for(let item of targetmodule.reasons){
//判断终止条件
if(item.type!=='entry' && item.resolvedModuleIdentifier!==tree[tree.length-1].name){
createTree(item.resolvedModuleIdentifier,tree[tree.length-1].children);
}
}
}else{
return;
}
}
//以修改的组件为根节点创建一个树形结构数据
createTree(filename,tree);
//获取哪些组件依赖了该组件
console.log('======',JSON.stringify(tree));
const pathArr=[];//存放所有路径的数组
//打印树结构的所有路径组成的数组
function getTreeAllPath(tree){
function getData(tree,path){
tree.forEach(ele => {
if(ele.children&&ele.children.length>0){
path.push(ele.name);
getData(ele.children,path);
path.pop();
}else{
path.push(ele.name);
pathArr.push(loadsh.cloneDeep(path));
path.pop();
}
});
}
getData(tree,[]);
}
getTreeAllPath(tree);
//数组的每一项也都是数组,颠倒数组的顺序
pathArr.forEach(item=>{
item.reverse();
})
console.log('++++++',JSON.stringify(pathArr));
})未来展望
上面所述的都是理论以及实现,未来的实践方向:1、进行yarn commit时,添加是否检索影响模块的功能,如果选择是,则需要根据提交文件,导出影响的相关业务功能,确定合理的测试范围。2、当在进行git MR时,依据合并的文件,导出影响的相关业务功能,进行最后一步的排查,是否有测试遗漏的场景。
参考资料
[1]loader-runner: https://link.segmentfault.com/?enc=vSHDoDE5PtM7BVecGUunzw==.wkkH43N8cYYT2zAlQiUEuY3khnCAbzvGwkKEVdMeNGsSAlOeKCGn0AEN0SSPF4li
[2]acorn: https://link.segmentfault.com/?enc=34W+CM3CjRJOYj7iDcn4XA==.U4A6T85QYId6tLeCAHGhl8oKu3oT2ZSKviItFDJjcqQdjEPhvbC74bdEI5ho4K6c
[3]chunk: https://www.webpackjs.com/glossary#c
[4]chunk objects: https://www.webpackjs.com/api/stats/#chunk-objects
[5]Webpack Analyse: http://webpack.github.io/analyse/