Broker跨目录如丝顺滑迁移深入无码解析
如何跨目录迁移
为什么线上Kafka机器各个磁盘间的占用不均匀,经常出现“一边倒”的情形?这是因为Kafka只保证分区数量在各个磁盘上均匀分布,但它无法知晓每个分区实际占用空间,故很有可能出现某些分区消息数量巨大导致占用大量磁盘空间的情况。在1.1版本之前,用户对此毫无办法,因为1.1之前Kafka只支持分区数据在不同broker间的重分配,而无法做到在同一个broker下的不同磁盘间做重分配。1.1版本正式支持副本在不同路径间的迁移
怎么在一台Broker上用多个路径存放分区呢?
只需要在配置上接多个文件夹就行了
#### Log Basics ###
log.dirs=k0,k1注意同一个Broker上不同路径只会存放不同的分区,而不会将副本存放在同一个Broker; 不然那副本就没有意义了(容灾)
怎么针对跨路径迁移呢?
迁移的json文件有一个参数是log_dirs; 默认请求不传的话 它是"log_dirs": ["any"] (这个数组的数量要跟副本保持一致) 但是你想实现跨路径迁移,只需要在这里填入绝对路径就行了,例如下面
迁移的json文件示例
{
"version": 1,
"partitions": [
{
"topic": "topic1",
"partition": 0,
"replicas": [
0
],
"log_dirs": [
"/Users/xxxxx/work/IdeaPj/source/kafka/k0"
]
},
{
"topic": "topic2",
"partition": 0,
"replicas": [
0
],
"log_dirs": [
"/Users/xxxxx/work/IdeaPj/source/kafka/k1"
]
}
]
}
然后执行脚本
sh bin/kafka-reassign-partitions.sh --zookeeper xxxxx --reassignment-json-file config/reassignment-json-file.json --execute --bootstrap-serverxxxxx:9092 --replica-alter-log-dirs-throttle 10000
注意 --bootstrap-server 在跨路径迁移的情况下,必须传入此参数
如果需要限流的话 加上参数 --replica-alter-log-dirs-throttle ; 跟--throttle不一样的是 --replica-alter-log-dirs-throttle限制的是Broker内不同路径的迁移流量;

关于副本同步限流机制请看 [多图图解Kafka分区副本同步限流机制三部曲(原理篇 13张图让你百分百掌握副本同步限流机制 )]
源码解析
因为代码跟 分区副本重分配源码原理分析(附配套教学视频) 是一个模块,只是针对不同情况做了不同处理, 整个重分配的源码就不分析了, 只把 跨目录数据迁移 单独拿出来讲解。
首先理解一个知识点, 未来目录(-future) : 我们在做跨目录数据迁移的时候,实际上会先再目标目录中创建一个新的分区目录,他的格式为: topic-partition.uniqueId-future ; 等最终同步完成的时候才会把目录给重新命名,然后删除旧分区的目录。
有一点类似于删除topic的时候也是打上标记 -delete 。
Execute 执行迁移
ReassignPartitionsCommand#reassignPartitions
def reassignPartitions(throttle: Throttle = NoThrottle, timeoutMs: Long = 10000L): Boolean = {
// 发送AlterReplicaLogDirsRequest 的请求 允许Broker在正确的log dir 创建副本(如果那个路径的副本还没有被创建的话)
if (proposedReplicaAssignment.nonEmpty)
alterReplicaLogDirsIgnoreReplicaNotAvailable(proposedReplicaAssignment, adminClientOpt.get, timeoutMs)
// Send AlterReplicaLogDirsRequest again to make sure broker will start to move replica to the specified log directory.
// It may take some time for controller to create replica in the broker. Retry if the replica has not been created.
var remainingTimeMs = startTimeMs + timeoutMs - System.currentTimeMillis()
val replicasAssignedToFutureDir = mutable.Set.empty[TopicPartitionReplica]
while (remainingTimeMs > 0 && replicasAssignedToFutureDir.size < proposedReplicaAssignment.size) {
replicasAssignedToFutureDir ++= alterReplicaLogDirsIgnoreReplicaNotAvailable(
proposedReplicaAssignment.filter { case (replica, _) => !replicasAssignedToFutureDir.contains(replica) },
adminClientOpt.get, remainingTimeMs)
Thread.sleep(100)
remainingTimeMs = startTimeMs + timeoutMs - System.currentTimeMillis()
}
replicasAssignedToFutureDir.size == proposedReplicaAssignment.size
}- 发送 AlterReplicaLogDirsRequest 的请求 允许Broker在正确的log dir 创建副本(如果那个路径的副本还没有被创建的话)
解析replicaAssignment的Json文件,解析成
Map<Integer, Map<TopicPartition, String>> replicaAssignmentByBroker的格式,这个Key是 BrokerId, Value 对应的是需要变更的TopicPartition和目录路径logDir; 然后分别给这些对应的BrokerId 发起一个alterReplicaLogDirs请求。当然这个请求都是异步的, 这里返回了一个Futures对象;
当然接下来就是遍历 futures 执行 future.get() 来获取每个请求的返回结果。将所有处理成功的副本记录一下。
ALTER_REPLICA_LOG_DIRS
处理 修改副本日志目录的请求
KafkaApis.handleAlterReplicaLogDirsRequest
def alterReplicaLogDirs(partitionDirs: Map[TopicPartition, String]): Map[TopicPartition, Errors] = {
val alterReplicaDirsRequest = request.body[AlterReplicaLogDirsRequest]
val responseMap = {
if (authorize(request, ALTER, CLUSTER, CLUSTER_NAME))
// 处理逻辑, 如果发现当前Broker不存在对应的分区 则会什么也不做
replicaManager.alterReplicaLogDirs(alterReplicaDirsRequest.partitionDirs.asScala)
else
alterReplicaDirsRequest.partitionDirs.asScala.keys.map((_, Errors.CLUSTER_AUTHORIZATION_FAILED)).toMap
}
sendResponseMaybeThrottle(request, requestThrottleMs => new AlterReplicaLogDirsResponse(requestThrottleMs, responseMap.asJava))
- 如果请求过来的TopicPartition不存在当前Broker中(意思是不是本机进行的目录迁移),则忽略,直接返回,什么也不做。 (那么就是单独的走了 跨Broker之间的数据迁移了。)
- 入参的Topic 判断一下后面重命名之后的字符大小是否超过255,超过抛异常. 重命名的格式为 :
topic-partition.uniqueId-future; (是不是跟删除topic的时候很像。-delete),不要让topic名字太长了 - 判断一下传入的
logDir是不是绝对路径,不是的话抛出异常。并且该目标logDir必须是已经存在的并且在线的目录文件。 - 如果
destinationDir与现有目标日志目录不同,则停止当前副本移动 - 如果 当前操作的
topicPartition所在的父目录不是给定的未来迁移目录destinationDir&& 未来LogfutureLogs中不存在给定的destinationDir目录, 则将这个topicPartition和destinationDir缓存起来到MappreferredLogDirs中。听起来很拗口总结一下就是:如果这个destinationDir还没有被标记的话,则先缓存标记一下,当然如果你这个destinationDir跟你当前分区的路径是一致的话,就没有必要做迁移了,也就没有必要标记了 - 再检验一下分区副本的可用性,是否在线
- 创建新的Log文件目录和文件,但是这个时候的Log文件目录是
-future后缀的, 同时这个分区中的futureLog对象中也保存了这个Log。 - 暂停这个Log的清理删除工作(让
-future分区副本同步完了再清理也不迟) AbstractFetcherManager#addFetcherForPartitions添加一个Fetcher开始准备进行同步

AbstractFetcherManager#addFetcherForPartitions 添加Fetcher线程
添加一个Fetcher线程
/**
* 创建 ReplicaAlterLogDirsThread 线程Fetcher线程,然后将需要迁移的 partition 添加到这个Fetcher中
* 最后启动线程,开始进行同步
**/
def addFetcherForPartitions(partitionAndOffsets: Map[TopicPartition, InitialFetchState]): Unit = {
lock synchronized {
val partitionsPerFetcher = partitionAndOffsets.groupBy { case (topicPartition, brokerAndInitialFetchOffset) =>
BrokerAndFetcherId(brokerAndInitialFetchOffset.leader, getFetcherId(topicPartition))
}
// 添加并启动一个 Fetcher线程 ReplicaAlterLogDirsThread
def addAndStartFetcherThread(brokerAndFetcherId: BrokerAndFetcherId,
brokerIdAndFetcherId: BrokerIdAndFetcherId): T = {
val fetcherThread = createFetcherThread(brokerAndFetcherId.fetcherId, brokerAndFetcherId.broker)
fetcherThreadMap.put(brokerIdAndFetcherId, fetcherThread)
fetcherThread.start()
fetcherThread
}
for ((brokerAndFetcherId, initialFetchOffsets) <- partitionsPerFetcher) {
val brokerIdAndFetcherId = BrokerIdAndFetcherId(brokerAndFetcherId.broker.id, brokerAndFetcherId.fetcherId)
val fetcherThread = fetcherThreadMap.get(brokerIdAndFetcherId) match {
case Some(currentFetcherThread) if currentFetcherThread.sourceBroker == brokerAndFetcherId.broker =>
// reuse the fetcher thread 如果线程已经存在则直接重置线程
currentFetcherThread
case Some(f) =>
f.shutdown()
//添加并启动一个 Fetcher线程 ReplicaAlterLogDirsThread
addAndStartFetcherThread(brokerAndFetcherId, brokerIdAndFetcherId)
case None =>
//添加并启动一个 Fetcher线程 ReplicaAlterLogDirsThread
addAndStartFetcherThread(brokerAndFetcherId, brokerIdAndFetcherId)
}
val initialOffsetAndEpochs = initialFetchOffsets.map { case (tp, brokerAndInitOffset) =>
tp -> OffsetAndEpoch(brokerAndInitOffset.initOffset, brokerAndInitOffset.currentLeaderEpoch)
}
// ReplicaAlterLogDirsThread 启动之后 则将需要拉取的分区添加到线程中 (当然是被标记为-future 的)
addPartitionsToFetcherThread(fetcherThread, initialOffsetAndEpochs)
}
}
}
- 添加一个 Fetcher线程
ReplicaAlterLogDirsThread, 这个线程的创建有讲究
private[server] val fetcherThreadMap = new mutable.HashMap[BrokerIdAndFetcherId, T]
这个对象保存着 Fetcher的线程,key 是 BrokerIdAndFetcherId对象里面有BrokerId和 FetcherId 的属性.BrokerId是当前这台Broker的IDFetcherId 的值的计算方式如下。
// Visibility for testing
private[server] def getFetcherId(topicPartition: TopicPartition): Int = {
lock synchronized {
Utils.abs(31 * topicPartition.topic.hashCode() + topicPartition.partition) % numFetchersPerBroker
}
}当然线程不是随便创建的,Fetcher线程有最大值、最大值是numFetchersPerBroker :这个可以通过num.replica.alter.log.dirs.threads 进行配置。如果没有配置,则默认获取log.dirs 配置的目录数量来。
也就是说 如果你的log.dirs只有一个目录, 并且没有配置 num.replica.alter.log.dirs.threads 的话,那么这个ReplicaAlterLogDirsThread线程只会创建一个。
2. ReplicaAlterLogDirsThread 启动之后 则将需要拉取的分区添加到线程中 (当然是被标记为 -future 的分区)
3. 开启拉取数据 ( ReplicaAlterLogDirsThread 是继承抽象类AbstractFetcherManager的,启动线程拉取数据通用逻辑在父类)
构建Fetch请求 拉取数据
- 一次只移动一个分区以提高其追赶率,从而减少花费在 移动任何给定的副本。
- 副本按升序(按Topic字典顺序)准备好获取的分区。
- 如果某个分区的请求已经正在处理中,那么下次再次Fetch的时候还是会继续选择,直到它 变得不可用或被删除。
ReplicaAlterLogDirsThread#buildFetch
def buildFetch(partitionMap: Map[TopicPartition, PartitionFetchState]): ResultWithPartitions[Option[ReplicaFetch]] = {
// 如果发现限流了 则不发起请求了。这里的限流是指的 同一个Broker跨路径限流
if (quota.isQuotaExceeded) {
println(new SimpleDateFormat("yyyy-MM-dd-HH:mm:ss").format(new Date())+"AlterLogThread 限流了...")
ResultWithPartitions(None, Set.empty)
} else {
selectPartitionToFetch(partitionMap) match {
case Some((tp, fetchState)) =>
println(new SimpleDateFormat("yyyy-MM-dd-HH:mm:ss").format(new Date())+"AlterLogThread buildFetchForPartition...")
//开始给每个需要同步数据的分区 构建Fetch请求
buildFetchForPartition(tp, fetchState)
case None =>
ResultWithPartitions(None, Set.empty)
}
}
}- 先判断是否超过限流阈值,如果发现已经超过限流值了,则本次不构建请求,关于是否超过限流请看分区副本限流三部曲; 当然这里的限流值配置是
replica-alter-log-dirs-throttle - 获取一下 fetchOffset、logStartOffset 、fetchSize 等等数据构造 Fetch请求;其中
fetchSize可以通过配置replica.fetch.max.bytes进行配置,意思是一次Fetch请求最大获取的数据量。默认是1M - 如果没有构成Fetch请求(没有副本需要同步或者超过限流值),则等待1S钟。
- 遍历上面获取到的请求参数
fetchRequestOpt, 发起Fetch请求processFetchRequest,通过这里可以看到,我们是一个一个副本来进行处理的
发起Fetch请求 读取数据
可以看到 是向本地发起的请求,并没有通过网络请求获取数据
AbstractFetcherThread#processFetchRequest
private def processFetchRequest(sessionPartitions: util.Map[TopicPartition, FetchRequest.PartitionData],
fetchRequest: FetchRequest.Builder): Unit = {
// 其他省略.. 这里是通过 fetchRequest向 Leader发起请求获取数据的地方
responseData = fetchFromLeader(fetchRequest)
}
我们看着上面的fetchFromLeader好像以为这里我们就需要向分区Leader读取数据来着, 但是这个其实是一个抽象方法。ReplicaAlterLogDirsThread#fetchFromLeader 有对它具体的实现
def fetchFromLeader(fetchRequest: FetchRequest.Builder): Map[TopicPartition, FetchData] = {
// 其他忽略... 这里是从副本中读取数据
replicaMgr.fetchMessages(
0L, // timeout is 0 so that the callback will be executed immediately
Request.FutureLocalReplicaId,
request.minBytes,
request.maxBytes,
false,
request.fetchData.asScala.toSeq,
UnboundedQuota,
processResponseCallback,
request.isolationLevel,
None)
}这里就是直接去副本读取数据了。
我们也可以看看另一个实现类的实现方法ReplicaFetcherThread#fetchFromLeader
override protected def fetchFromLeader(fetchRequest: FetchRequest.Builder): Map[TopicPartition, FetchData] = {
try {
// 向LeaderEndPoint 发起了Fetch请求
val clientResponse = leaderEndpoint.sendRequest(fetchRequest)
val fetchResponse = clientResponse.responseBody.asInstanceOf[FetchResponse[Records]]
if (!fetchSessionHandler.handleResponse(fetchResponse)) {
Map.empty
} else {
fetchResponse.responseData.asScala
}
} catch {
case t: Throwable =>
fetchSessionHandler.handleError(t)
throw t
}
}
可以很明显的看到ReplicaFetcherThread是去Leader副本发起网络请求读取数据了。
关于限流
在读取数据的时候,会判断是否超过限流阈值, Leader 限流 Follower限流 分别是如何实现的呢?
Leader 层面的限流
Leader层面不需要限流,因为数据不是从Leader副本获取的,而是从同Broker源目录读取的本地磁盘数据到另一个目录中, 所以不需要进行Leader层面的限流。
ReplicaManager#readFromLocalLog 里面有一段代码
// 判断是否需要限流,超过限流的话,则不返回数据(当然这个时候数据其实已经读取到了)
val fetchDataInfo = if (shouldLeaderThrottle(quota, tp, replicaId)) {
// If the partition is being throttled, simply return an empty set.
FetchDataInfo(readInfo.fetchedData.fetchOffsetMetadata, MemoryRecords.EMPTY)
} else if (!hardMaxBytesLimit && readInfo.fetchedData.firstEntryIncomplete) {判断是否需要限流, 如果超出阈值的话就不返回数据了(当然这里已经读取了数据了), 具体限流相关请看 分区副本同步三部曲 。但是这一步骤在这里返回永远都是false ,具体原因看下面代码
// replicaId = Request.FutureLocalReplicaId = -3
def shouldLeaderThrottle(quota: ReplicaQuota, topicPartition: TopicPartition, replicaId: Int): Boolean = {
val isReplicaInSync = nonOfflinePartition(topicPartition).exists(_.inSyncReplicaIds.contains(replicaId))
!isReplicaInSync && quota.isThrottled(topicPartition) && quota.isQuotaExceeded
}
我们这里是跨目录数据迁移,replicaId = Request.FutureLocalReplicaId = -3 , quota的入参的类型是UnboundedQuota , 看名字就可以看出来,这个意思是无限量的限流,就是不限流,不管你配置什么,记录多少,就是不限流, 为什么?因为我们这里本来就是从当前的Broker的源目录同步数据到另一个目录,不走Leader同步,也就没有分区Leader限流相关的事情了。
Follower 层面的限流
记录限流数据
处理读取到的 数据
ReplicaAlterLogDirsThread#processPartitionData
// process fetched data
override def processPartitionData(topicPartition: TopicPartition,
fetchOffset: Long,
partitionData: PartitionData[Records]): Option[LogAppendInfo] = {
// 省略无关代码
....
// 计算数据的大小
val records = toMemoryRecords(partitionData.records)
// 把读取到的数据统计起来, 后面需要根据数据判断是否达到限流阈值了
quota.record(records.sizeInBytes)
}- 这里记录数据的时候, quota传入的类型是
ReplicationQuotaManager, 并且replicationType类型是AlterLogDirsReplication,那么数据就保存起来之后,后面就会判断是否超过限流值了。
限流时机
限流时机我们之前已经说到过了,就是在发起fetch的时候会判断
ReplicaAlterLogDirsThread#buildFetch
def buildFetch(partitionMap: Map[TopicPartition, PartitionFetchState]): ResultWithPartitions[Option[ReplicaFetch]] = {
// 在这里会直接判断是否需要限流
if (quota.isQuotaExceeded) {
ResultWithPartitions(None, Set.empty)
} else {
....
}
}
可以看到上面的quota.isQuotaExceeded是判断是否超过限流值,不跟 Leade和Follower一样还需要判断副本是否在ISR中,还有是否该分区是否在限流配置中,quota传入的类型是 ReplicationQuotaManager , 并且replicationType类型是AlterLogDirsReplication。对应ReplicaAlterLogDirs这种方式的限流,直接计算的是这一台Broker的所有跨副本数据同步的流量值。超过了阈值就会限速。
数据同步完成 ReplicaAlterLogDirsThread线程关闭
所有数据同步完成之后,现在自动关闭
LogDir目录选择策略?
跨目录的形式
在跨目录的情形下,
KafkaApis.handleAlterReplicaLogDirsRequest#maybeCreateFutureReplica会根据传入的logDir参数创建对应的分区目录文件, 创建的时候的文件目录是-future结尾的。
非跨目录的形式但是指定了LogDir
假如我们在做数据迁移的时候指定的LogDir;
例如:
{"version":1,"partitions":[{"topic":"Topic2","partition":1,"replicas":[0],"log_dirs":["/Users/shirenchuang/work/IdeaPj/didi_source/kafka/k1"]}]}
Topic2-1原本在Broker-1里面,执行上面的脚本将Topic2-1迁移到Broker-0里面的 "/Users/shirenchuang/work/IdeaPj/didi_source/kafka/k1" 目录中, 这个是属于非跨目录形式的迁移,但是指定了目录。
如果指定了目录,那么就一定会发起一个请求 AlterReplicaLogDirsRequest ;
在这个请求里面, 虽然在这种形式里面 他没有去创建对应的Log目录,但是它在这台Broker里面做了一个标记preferredLogDirs: 优先LogDir,这里面保存了我们刚刚传过来的目录。
然后等到 收到一个LeaderAndIsrRequest请求, 执行becomeLeaderOrFollower方法
ReplicaManager#makeFollowers... 最终到创建Log的方法
LogManager#getOrCreateLog
上面我们设置了 preferredLogDirs: 之后,这不是在创建Log的时候就用上了吗!
def getOrCreateLog(topicPartition: TopicPartition, config: LogConfig, isNew: Boolean = false, isFuture: Boolean = false): Log = {
logCreationOrDeletionLock synchronized {
getLog(topicPartition, isFuture).getOrElse {
// create the log if it has not already been created in another thread
if (!isNew && offlineLogDirs.nonEmpty)
throw new KafkaStorageException(s"Can not create log for $topicPartition because log directories ${offlineLogDirs.mkString(",")} are offline")
val logDirs: List[File] = {
// 看这里, 是不是我们刚刚设置过这个优先目录,这个时候就用上了
val preferredLogDir = preferredLogDirs.get(topicPartition)
if (preferredLogDir != null)
List(new File(preferredLogDir))
else
nextLogDirs()
}
..... 省略了部分 .....
val logDirName = {
if (isFuture)
Log.logFutureDirName(topicPartition)
else
Log.logDirName(topicPartition)
}
}
}非跨目录也没有指定LogDir
请看 Kafka多目录情况下如何选择目录进行存放数据呢?, 其实就是简单的按照 目录里面的分区数量进行排序然后创建, 尽量保证分区目录数量均衡。
源码总结
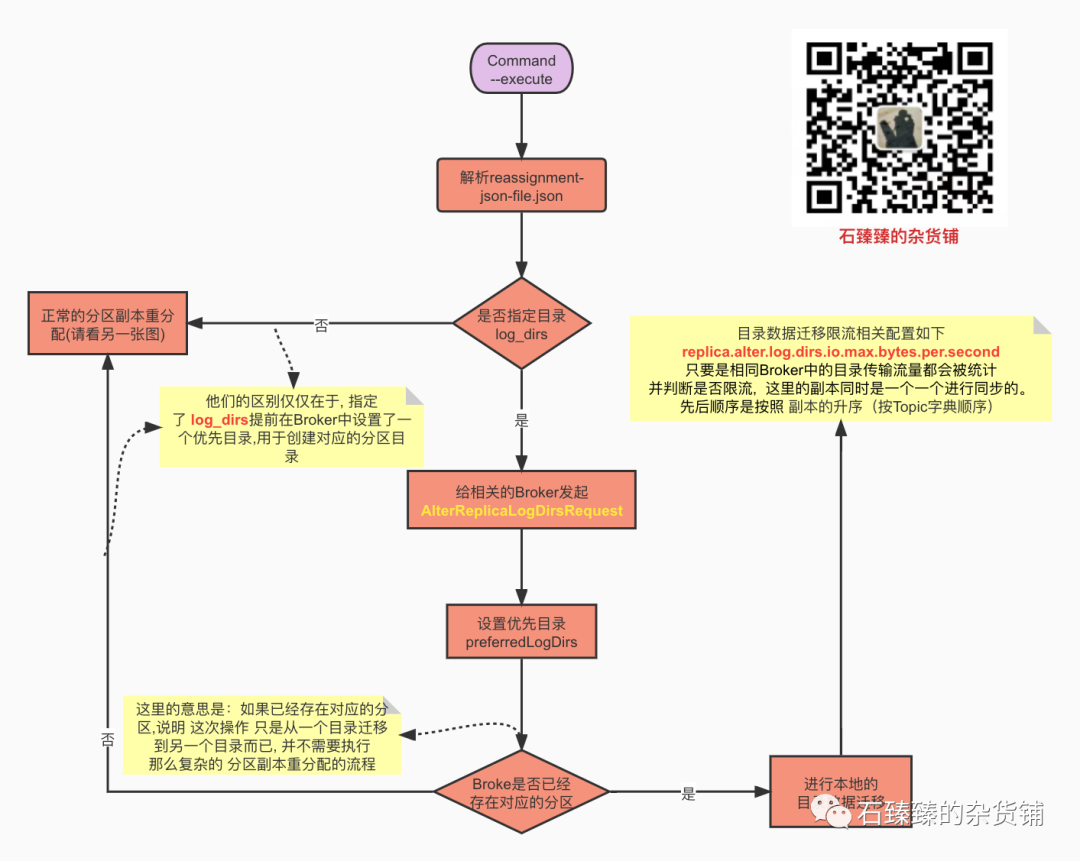
Q&A
1 . 如何在对应的目录中创建分区副本的?
指定了log_dirs 并且是目录迁移的情况, 那么在
AlterReplicaLogDirsRequest请求中就会创建, 其他情况是在LeaderAndIsrRequest中创建的。
2 . 创建的分区是在哪个目录中呢?
具体请看Kafka多目录情况下如何选择目录进行存放数据呢?, 具体是如果指定了dir,则创建的时候会使用指定的dir创建分区,否则的话,就会按照分区数量对各个目录排序,选择最少的那个创建。
3 . 跨目录迁移数据的时候,是从源目录读取分区副本的数据呢?还是从该分区的Leader中获取数据呢?
是从相同Broker中的源目录读取的数据,不是从Leader读取。
4 . 分区副本限流机制中, 在跨目录数据迁移的场景中, 会把这一部分的数据同步流量计算到 分区Leader限流的统计里面吗?
不会!因为在跨目录数据迁移的场景中, 在判断 是否需要进行Leader层面的限流时候
shouldLeaderThrottle,Quota限流传入的对象是UnboundedQuota意思是不进行限流。而且 跨目录迁移本来就不是去Leader副本读取数据来同步的,所以也不存在Leader层面的限流
5 . Follower 记录流量的地方在哪里?
ReplicaAlterLogDirsThread#processPartitionData