Go 日志库 zerolog 大解剖
-
什么是 zerolog ?
-
使用 zerolog
-
安装
-
Contextual Logger
-
多级 Logger
-
注意事项
-
了解源码
-
看一下 Logger 结构体
-
debug 了解输出日志流程
-
从 zerolog 学习避免内存分配
-
学习日志级别
-
学习如何实现 Hook
-
学习如何得到调用者函数名
-
从日志采样中学习 atomic
-
Doc
-
比较
-
相似的库
-
参考资料
文章可能相对较长,请耐心看完。定有收获。
什么是 zerolog ?
zerolog 包提供了一个专门用于 JSON 输出的简单快速的 Logger。
zerolog 的 API 旨在为开发者提供出色的体验和令人惊叹的性能[1]。其独特的链式 API 允许通过避免内存分配和反射来写入 JSON ( 或 CBOR ) 日志。
uber 的 zap[2] 库开创了这种方法,zerolog 通过更简单的应用编程接口和更好的性能,将这一概念提升到了更高的层次。
使用 zerolog
安装
go get -u github.com/rs/zerolog/log
Contextual Logger
func TestContextualLogger(t *testing.T) {
log := zerolog.New(os.Stdout)
log.Info().Str("content", "Hello world").Int("count", 3).Msg("TestContextualLogger")
// 添加上下文 (文件名/行号/字符串)
log = log.With().Caller().Str("foo", "bar").Logger()
log.Info().Msg("Hello wrold")
}输出
// {"level":"info","content":"Hello world","count":3,"message":"TestContextualLogger"}
// {"level":"info","caller":"log_example_test.go:29","message":"Hello wrold"}与 zap 相同的是,都定义了强类型字段,你可以在这里[3]找到支持字段的完整列表。
与 zap 不同的是,zerolog 采用链式调用。
多级 Logger
zerolog 提供了从 Trace 到 Panic 七个级别
// 设置日志级别
zerolog.SetGlobalLevel(zerolog.WarnLevel)
log.Trace().Msg("Trace")
log.Debug().Msg("Debug")
log.Info().Msg("Info")
log.Warn().Msg("Warn")
log.Error().Msg("Error")
log.Log().Msg("没有级别")输出
{"level":"warn","message":"Warn"}
{"level":"error","message":"Error"}
{"message":"没有级别"}注意事项
1.zerolog 不会对重复的字段删除
logger := zerolog.New(os.Stderr).With().Timestamp().Logger()
logger.Info().
Timestamp().
Msg("dup")输出
{"level":"info","time":1494567715,"time":1494567715,"message":"dup"}
2.链式调用必须调用 Msg 或 Msgf,Send 才能输出日志,Send 相当于调用 Msg("")
3.一旦调用 Msg ,Event 将会被处理 ( 放回池中或丢掉 ),不允许二次调用。
了解源码
本次 zerolog 的源码分析基于 zerolog 1.22.0 版本,源码分析较长,希望大家耐心看完。希望大家能有所收获。
看一下 Logger 结构体
Logger 的参数 w 类型是 LevelWriter 接口,用于向目标输出事件。zerolog.New 函数用来创建 Logger,看下方源码。
// ============ log.go ===
type Logger struct {
w LevelWriter // 输出对象
level Level // 日志级别
sampler Sampler // 采样器
context []byte // 存储上下文
hooks []Hook
stack bool
}
func New(w io.Writer) Logger {
if w == nil {
// ioutil.Discard 所有成功执行的 Write 操作都不会产生任何实际的效果
w = ioutil.Discard
}
lw, ok := w.(LevelWriter)
// 传入的不是 LevelWriter 类型,封装成此类型
if !ok {
lw = levelWriterAdapter{w}
}
// 默认输出日志级别 TraceLevel
return Logger{w: lw, level: TraceLevel}
}debug 了解输出日志流程
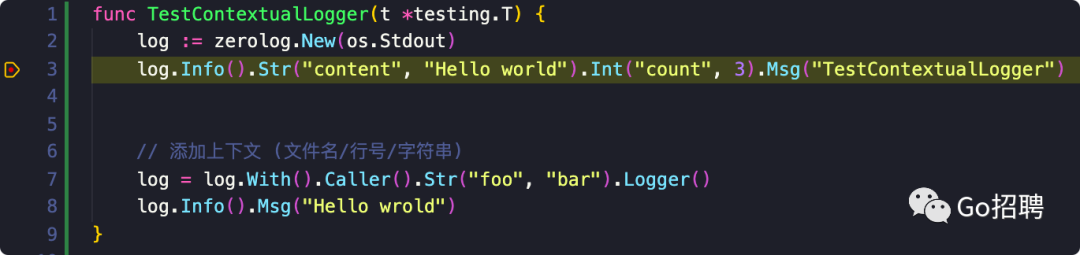
如上图所示,在第三行打上断点。
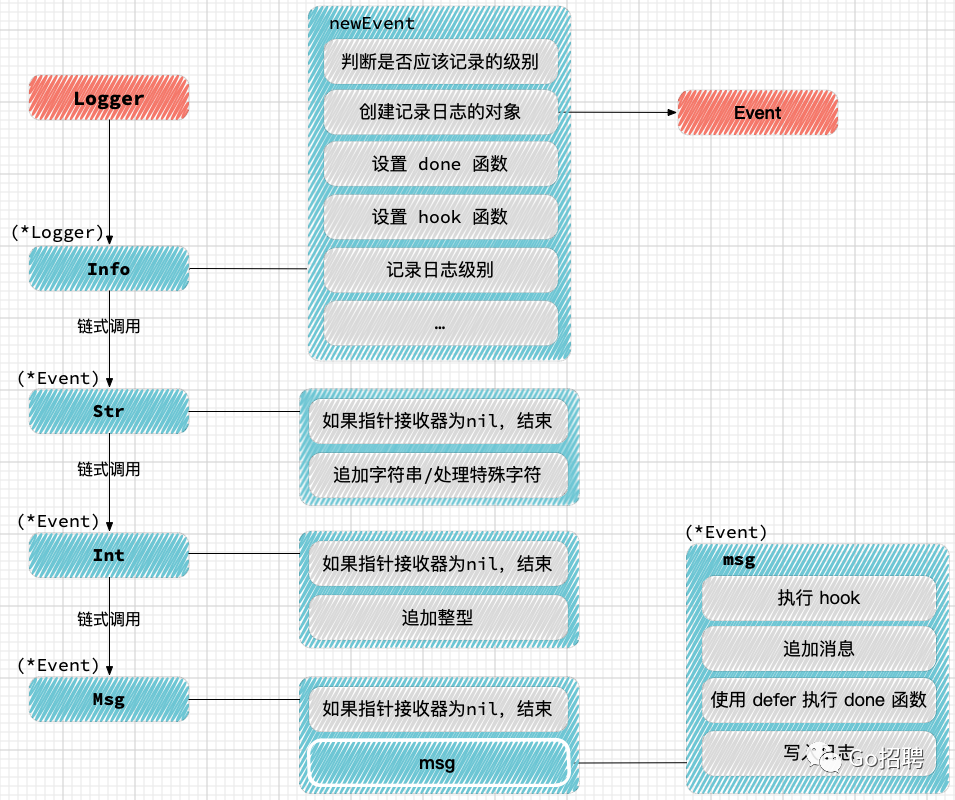
下图表示该行代码执行流程。
// ============ log.go ===
// Info 开始记录一条 info 级别的消息
// 你必须在返回的 *Event 上调用 Msg 才能发送事件
func (l *Logger) Info() *Event {
return l.newEvent(InfoLevel, nil)
}
func (l *Logger) newEvent(level Level, done func(string)) *Event {
// 判断是否应该记录的级别
enabled := l.should(level)
if !enabled {
return nil
}
// 创建记录日志的对象
e := newEvent(l.w, level)
// 设置 done 函数
e.done = done
// 设置 hook 函数
e.ch = l.hooks
// 记录日志级别
if level != NoLevel && LevelFieldName != "" {
e.Str(LevelFieldName, LevelFieldMarshalFunc(level))
}
// 记录上下文
if l.context != nil && len(l.context) > 1 {
e.buf = enc.AppendObjectData(e.buf, l.context)
}
// 堆栈跟踪
if l.stack {
e.Stack()
}
return e
}should 函数用于判断是否需要记录本次消息。
// ============ log.go ===
// should 如果应该被记录,则返回 true
func (l *Logger) should(lvl Level) bool {
if lvl < l.level || lvl < GlobalLevel() {
return false
}
// 采样后面讲
if l.sampler != nil && !samplingDisabled() {
return l.sampler.Sample(lvl)
}
return true
}newEvent 函数使用 sync.Pool 获取 Event 对象,并将 Event 参数初始化:日志级别level和写入对象LevelWriter。
// ============ event.go ===
// 表示一个日志事件
type Event struct {
buf []byte // 消息
w LevelWriter // 待写入的目标接口
level Level // 日志级别
done func(msg string) // msg 函数结束事件
stack bool // 错误堆栈跟踪
ch []Hook // hook 函数组
skipFrame int
}
func newEvent(w LevelWriter, level Level) *Event {
e := eventPool.Get().(*Event)
e.buf = e.buf[:0]
e.ch = nil
// 在开始添加左大括号 '{'
e.buf = enc.AppendBeginMarker(e.buf)
e.w = w
e.level = level
e.stack = false
e.skipFrame = 0
return e
}Str 函数是负责将键值对添加到 buf,字符串类型添加到 JSON 格式,涉及到特殊字符编码问题,如果是特殊字符,调用 appendStringComplex 函数解决。
// ============ event.go ===
func (e *Event) Str(key, val string) *Event {
if e == nil {
return e
}
e.buf = enc.AppendString(enc.AppendKey(e.buf, key), val)
return e
}
// ============ internal/json/base.go ===
type Encoder struct{}
// 添加一个新 key
func (e Encoder) AppendKey(dst []byte, key string) []byte {
// 非第一个参数,加个逗号
if dst[len(dst)-1] != '{' {
dst = append(dst, ',')
}
return append(e.AppendString(dst, key), ':')
}
// === internal/json/string.go ===
func (Encoder) AppendString(dst []byte, s string) []byte {
// 双引号起
dst = append(dst, '"')
// 遍历字符
for i := 0; i < len(s); i++ {
// 检查字符是否需要编码
if !noEscapeTable[s[i]] {
dst = appendStringComplex(dst, s, i)
return append(dst, '"')
}
}
// 不需要编码的字符串,添加到 dst
dst = append(dst, s...)
// 双引号收
return append(dst, '"')
}Int 函数将键值(int 类型)对添加到 buf,内部调用 strconv.AppendInt 函数实现。
// ============ event.go ===
func (e *Event) Int(key string, i int) *Event {
if e == nil {
return e
}
e.buf = enc.AppendInt(enc.AppendKey(e.buf, key), i)
return e
}
// === internal/json/types.go ===
func (Encoder) AppendInt(dst []byte, val int) []byte {
// 添加整数
return strconv.AppendInt(dst, int64(val), 10)
}Msg 函数
// === event.go ===
// Msg 是对 msg 的封装调用,当指针接收器为 nil 返回
func (e *Event) Msg(msg string) {
if e == nil {
return
}
e.msg(msg)
}
// msg
func (e *Event) msg(msg string) {
// 运行 hook
for _, hook := range e.ch {
hook.Run(e, e.level, msg)
}
// 记录消息
if msg != "" {
e.buf = enc.AppendString(enc.AppendKey(e.buf, MessageFieldName), msg)
}
// 判断不为 nil,则使用 defer 调用 done 函数
if e.done != nil {
defer e.done(msg)
}
// 写入日志
if err := e.write(); err != nil {
if ErrorHandler != nil {
ErrorHandler(err)
} else {
fmt.Fprintf(os.Stderr, "zerolog: could not write event: %v\n", err)
}
}
}
// 写入日志
func (e *Event) write() (err error) {
if e == nil {
return nil
}
if e.level != Disabled {
// 大括号收尾
e.buf = enc.AppendEndMarker(e.buf)
// 换行
e.buf = enc.AppendLineBreak(e.buf)
// 向目标写入日志
if e.w != nil {
// 这里传递的日志级别,函数内并没有使用
_, err = e.w.WriteLevel(e.level, e.buf)
}
}
// 将对象放回池中
putEvent(e)
return
}
// === writer.go ===
func (lw levelWriterAdapter) WriteLevel(l Level, p []byte) (n int, err error) {
return lw.Write(p)
}以上 debug 让我们对日志记录流程有了大概的认识,接下来扩充一下相关知识。
从 zerolog 学习避免内存分配
每一条日志都会产生一个 *Event对象 ,当多个 Goroutine 操作日志,导致创建的对象数目剧增,进而导致 GC 压力增大。形成 "并发大 - 占用内存大 - GC 缓慢 - 处理并发能力降低 - 并发更大" 这样的恶性循环。在这个时候,需要有一个对象池,程序不再自己单独创建对象,而是从对象池中获取。
使用 sync.Pool 可以将暂时不用的对象缓存起来,下次需要的时候从池中取,不用再次经过内存分配。
下面代码中 putEvent 函数,当对象中记录消息的 buf 不超过 64KB 时,放回池中。这里有个链接,通过这个 issue 23199[4]了解到使用动态增长的 buffer 会导致大量内存被固定,在活锁的情况下永远不会释放。
var eventPool = &sync.Pool{
New: func() interface{} {
return &Event{
buf: make([]byte, 0, 500),
}
},
}
func putEvent(e *Event) {
// 选择占用较小内存的 buf,将对象放回池中
// See https://golang.org/issue/23199
const maxSize = 1 << 16 // 64KiB
if cap(e.buf) > maxSize {
return
}
eventPool.Put(e)
}学习日志级别
下面代码中,包含了日志级别类型的定义,日志级别对应的字符串值,获取字符串值的方法以及解析字符串为日志级别类型的方法。
// ============= log.go ===
// 日志级别类型
type Level int8
// 定义所有日志级别
const (
DebugLevel Level = iota
InfoLevel
WarnLevel
ErrorLevel
FatalLevel
PanicLevel
NoLevel
Disabled
TraceLevel Level = -1
)
// 返回当前级别的 value
func (l Level) String() string {
switch l {
case TraceLevel:
return LevelTraceValue
case DebugLevel:
return LevelDebugValue
case InfoLevel:
return LevelInfoValue
case WarnLevel:
return LevelWarnValue
case ErrorLevel:
return LevelErrorValue
case FatalLevel:
return LevelFatalValue
case PanicLevel:
return LevelPanicValue
case Disabled:
return "disabled"
case NoLevel:
return ""
}
return ""
}
// ParseLevel 将级别字符串解析成 zerolog level value
// 当字符串不匹配任何已知级别,返回错误
func ParseLevel(levelStr string) (Level, error) {
switch levelStr {
case LevelFieldMarshalFunc(TraceLevel):
return TraceLevel, nil
case LevelFieldMarshalFunc(DebugLevel):
return DebugLevel, nil
case LevelFieldMarshalFunc(InfoLevel):
return InfoLevel, nil
case LevelFieldMarshalFunc(WarnLevel):
return WarnLevel, nil
case LevelFieldMarshalFunc(ErrorLevel):
return ErrorLevel, nil
case LevelFieldMarshalFunc(FatalLevel):
return FatalLevel, nil
case LevelFieldMarshalFunc(PanicLevel):
return PanicLevel, nil
case LevelFieldMarshalFunc(Disabled):
return Disabled, nil
case LevelFieldMarshalFunc(NoLevel):
return NoLevel, nil
}
return NoLevel, fmt.Errorf("Unknown Level String: '%s', defaulting to NoLevel", levelStr)
}
// ============= globals.go ===
var (
// ......
// 级别字段的 key 名称
LevelFieldName = "level"
// 各个级别的 value
LevelTraceValue = "trace"
LevelDebugValue = "debug"
LevelInfoValue = "info"
LevelWarnValue = "warn"
LevelErrorValue = "error"
LevelFatalValue = "fatal"
LevelPanicValue = "panic"
// 返回形参级别的 value
LevelFieldMarshalFunc = func(l Level) string {
return l.String()
}
// ......
)全局日志级别参数
这里使用 atomic 来保证原子操作,要么都执行,要么都不执行,外界不会看到只执行到一半的状态,原子操作由底层硬件支持,通常比锁更有效率。
atomic.StoreInt32 用于存储 int32 类型的值。
atomic.LoadInt32 用于读取 int32 类型的值。
在源码中,做级别判断时,多处调用 GlobalLevel 以保证并发安全。
// ============= globals.go ===
var (
gLevel = new(int32)
// ......
)
// SetGlobalLevel 设置全局日志级别
// 要全局禁用日志,入参为 Disabled
func SetGlobalLevel(l Level) {
atomic.StoreInt32(gLevel, int32(l))
}
// 返回当前全局日志级别
func GlobalLevel() Level {
return Level(atomic.LoadInt32(gLevel))
}
学习如何实现 Hook
首先定义 Hook 接口,内部有一个 Run 函数,入参包含 *Event,日志级别**level 和消息 ( **Msg** 函数的参数 )。
然后定义了 LevelHook 结构体,用于为每个级别设置 Hook 。
// ============= hook.go ===
// hook 接口
type Hook interface {
Run(e *Event, level Level, message string)
}
// HookFunc 函数适配器
type HookFunc func(e *Event, level Level, message string)
// Run 实现 Hook 接口.
func (h HookFunc) Run(e *Event, level Level, message string) {
h(e, level, message)
}
// 为每个级别应用不同的 hook
type LevelHook struct {
NoLevelHook, TraceHook, DebugHook, InfoHook, WarnHook, ErrorHook, FatalHook, PanicHook Hook
}
// Run 实现 Hook 接口
func (h LevelHook) Run(e *Event, level Level, message string) {
switch level {
case TraceLevel:
if h.TraceHook != nil {
h.TraceHook.Run(e, level, message)
}
case DebugLevel:
if h.DebugHook != nil {
h.DebugHook.Run(e, level, message)
}
case InfoLevel:
if h.InfoHook != nil {
h.InfoHook.Run(e, level, message)
}
case WarnLevel:
if h.WarnHook != nil {
h.WarnHook.Run(e, level, message)
}
case ErrorLevel:
if h.ErrorHook != nil {
h.ErrorHook.Run(e, level, message)
}
case FatalLevel:
if h.FatalHook != nil {
h.FatalHook.Run(e, level, message)
}
case PanicLevel:
if h.PanicHook != nil {
h.PanicHook.Run(e, level, message)
}
case NoLevel:
if h.NoLevelHook != nil {
h.NoLevelHook.Run(e, level, message)
}
}
}
// NewLevelHook 创建一个 LevelHook
func NewLevelHook() LevelHook {
return LevelHook{}
}在源码中是如何使用的?
定义 PrintMsgHook 结构体并实现 Hook 接口,作为参数传递给 log.Hook 函数,Logger 内部的 hooks 参数用来保存对象。
// 使用案例
type PrintMsgHook struct{}
// 实现 Hook 接口,用来向控制台输出 msg
func (p PrintMsgHook) Run(e *zerolog.Event, l zerolog.Level, msg string) {
fmt.Println(msg)
}
func TestContextualLogger(t *testing.T) {
log := zerolog.New(os.Stdout)
log = log.Hook(PrintMsgHook{})
log.Info().Msg("TestContextualLogger")
}添加 hook 源码如下
// ============ log.go ===
// Hook 返回一个带有 hook 的 Logger
func (l Logger) Hook(h Hook) Logger {
l.hooks = append(l.hooks, h)
return l
}输出日志必须调用 msg 函数,hook 将在此函数的开头执行。
// ============ event.go ===
// msg 函数用来运行 hook
func (e *Event) msg(msg string) {
for _, hook := range e.ch {
hook.Run(e, e.level, msg)
}
// .......
// 写入日志,此函数上面已经介绍过,此处省略
// .......
}学习如何得到调用者函数名
在看 zerolog 源码之前,需要知道一些关于 runtime.Caller 函数的前置知识,
- runtime.Caller 可以获取相关调用 goroutine 堆栈上的函数调用的文件和行号信息。
- 参数skip 是堆栈帧的数量,当 skip=0 时,输出当前函数信息; 当 skip=1 时,输出调用栈上一帧,即调用函数者的信息。
- 返回值为 程序计数器,文件位置,行号,是否能恢复信息
// ============ go@1.16.5 runtime/extern.go ===
func Caller(skip int) (pc uintptr, file string, line int, ok bool) {
rpc := make([]uintptr, 1)
n := callers(skip+1, rpc[:])
if n < 1 {
return
}
frame, _ := CallersFrames(rpc).Next()
return frame.PC, frame.File, frame.Line, frame.PC != 0
}再看 zerolog 源码,定义 callerHook 结构体并实现了 Hook 接口,实现函数中调用了参数 *Event 提供的 caller函数。
其中入参为预定义参数 CallerSkipFrameCount 和 contextCallerSkipFrameCount ,值都为 2。
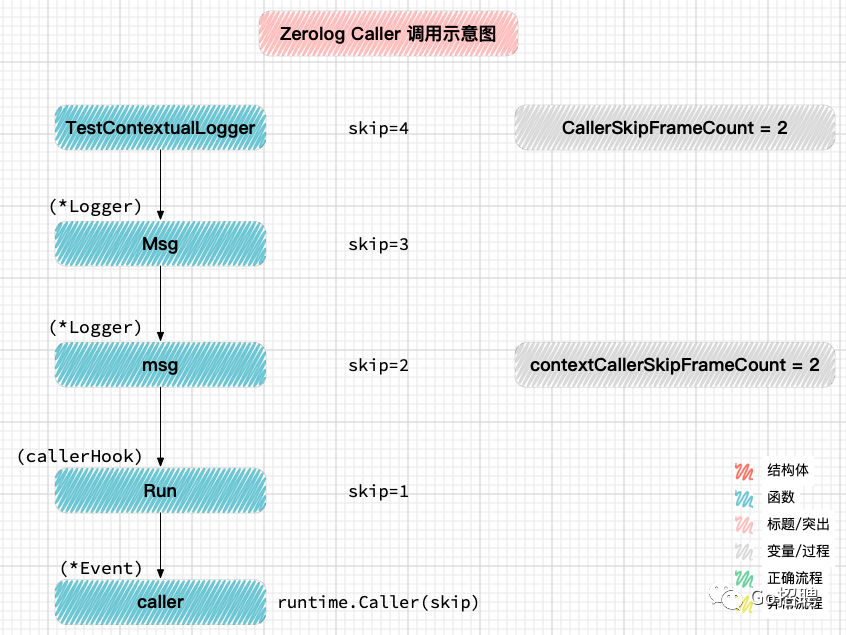
// ============ context.go ===
type callerHook struct {
callerSkipFrameCount int
}
func newCallerHook(skipFrameCount int) callerHook {
return callerHook{callerSkipFrameCount: skipFrameCount}
}
func (ch callerHook) Run(e *Event, level Level, msg string) {
switch ch.callerSkipFrameCount {
// useGlobalSkipFrameCount 是 int32 类型最小值
case useGlobalSkipFrameCount:
// CallerSkipFrameCount 预定义全局变量,值为 2
// contextCallerSkipFrameCount 预定义变量,值为 2
e.caller(CallerSkipFrameCount + contextCallerSkipFrameCount)
default:
e.caller(ch.callerSkipFrameCount + contextCallerSkipFrameCount)
}
}
// useGlobalSkipFrameCount 值:-2147483648
const useGlobalSkipFrameCount = math.MinInt32
// 创建默认 callerHook
var ch = newCallerHook(useGlobalSkipFrameCount)
// Caller 为 Logger 添加 hook ,该 hook 用于记录函数调用者的 file:line
func (c Context) Caller() Context {
c.l = c.l.Hook(ch)
return c
}// ============ event.go ===
func (e *Event) caller(skip int) *Event {
if e == nil {
return e
}
_, file, line, ok := runtime.Caller(skip + e.skipFrame)
if !ok {
return e
}
// CallerFieldName是默认的 key 名
// CallerMarshalFunc 函数用于拼接 file:line
e.buf = enc.AppendString(enc.AppendKey(e.buf, CallerFieldName), CallerMarshalFunc(file, line))
return e
}从日志采样中学习 atomic
这个使用案例中,TestSample 每秒允许 记录 5 条消息,超过则每 20 条仅记录一条
func TestSample(t *testing.T) {
sampled := log.Sample(&zerolog.BurstSampler{
Burst: 5,
Period: 1 * time.Second,
NextSampler: &zerolog.BasicSampler{N: 20},
})
for i := 0; i <= 50; i++ {
sampled.Info().Msgf("logged messages : %2d ", i)
}
}输出结果本来应该输出 50 条日志,使用了采样,在一秒内输出最大 5 条日志,当大于 5 条后,每 20 条日志输出一次。
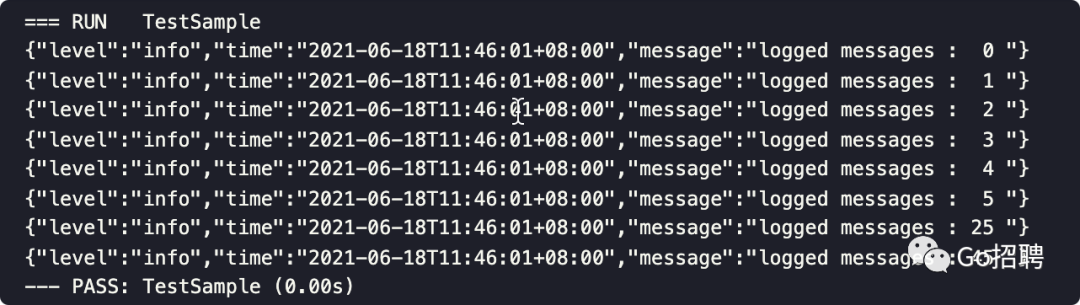
采样的流程示意图如下

下方是定义采样接口及实现函数的源码。
在 inc 函数中,使用 atomic 包将竞争的接收器对象的参数变成局部变量,是学习 atomic 很好的实例。函数说明都写在注释里。
// =========== sampler.go ===
// 采样器接口
type Sampler interface {
// 如果事件是样本的一部分返回 true
Sample(lvl Level) bool
}
// BasicSampler 基本采样器
// 每 N 个事件发送一次,不考虑日志级别
type BasicSampler struct {
N
counter uint32
}
// 实现采样器接口
func (s *BasicSampler) Sample(lvl Level) bool {
n := s.N
if n == 1 {
return true
}
c := atomic.AddUint32(&s.counter, 1)
return c%n == 1
}
type BurstSampler struct {
// 调用 NextSampler 之前每个时间段(Period)调用的最大事件数量
Burst uint32
// 如果为 0,则始终调用 NextSampler
Period time.Duration
// 采样器
NextSampler Sampler
// 用于计数在一定时间内(Period)的调用数量
counter uint32
// 时间段的结束时间(纳秒),即 当前时间+Period
resetAt int64
}
// 实现 Sampler 接口
func (s *BurstSampler) Sample(lvl Level) bool {
// 当设置了 Burst 和 Period,大于零时限制 一定时间内的最大事件数量
if s.Burst > 0 && s.Period > 0 {
if s.inc() <= s.Burst {
return true
}
}
// 没有采样器,结束
if s.NextSampler == nil {
return false
}
// 调用采样器
return s.NextSampler.Sample(lvl)
}
func (s *BurstSampler) inc() uint32 {
// 当前时间 (纳秒)
now := time.Now().UnixNano()
// 重置时间 (纳秒)
resetAt := atomic.LoadInt64(&s.resetAt)
var c uint32
// 当前时间 > 重置时间
if now > resetAt {
c = 1
// 重置 s.counter 为 1
atomic.StoreUint32(&s.counter, c)
// 计算下一次的重置时间
newResetAt := now + s.Period.Nanoseconds()
// 比较函数开头获取的重置时间与存储的时间是否相等
// 相等时,将下一次的重置时间存储到 s.resetAt,并返回 true
reset := atomic.CompareAndSwapInt64(&s.resetAt, resetAt, newResetAt)
if !reset {
// 在上面比较赋值那一步没有抢到的 goroutine 计数器+1
c = atomic.AddUint32(&s.counter, 1)
}
} else {
c = atomic.AddUint32(&s.counter, 1)
}
return c
}在代码中如何调用的呢?
Info 函数及其他级别函数都会调用 newEvent,在该函数的开头, should 函数用来判断是否需要记录的日志级别和采样。
// ============ log.go ===
// should 如果应该被记录,则返回 true
func (l *Logger) should(lvl Level) bool {
if lvl < l.level || lvl < GlobalLevel() {
return false
}
// 如果使用了采样,则调用采样函数,判断本次事件是否记录
if l.sampler != nil && !samplingDisabled() {
return l.sampler.Sample(lvl)
}
return true
}Doc
关于更多 zerolog 的使用可以参考 https://pkg.go.dev/github.com/rs/zerolog
比较
说明 : 以下资料来源于 zerolog 官方。从性能分析上 zerolog 比 zap 和其他 logger 库更胜一筹,关于 zerolog 和 zap 的使用,gopher 可根据实际业务场景具体考量。
记录 10 个 KV 字段的消息 :
| Library | Time | Bytes Allocated | Objects Allocated |
|---|---|---|---|
| zerolog | 767 ns/op | 552 B/op | 6 allocs/op |
| ⚡ zap | 848 ns/op | 704 B/op | 2 allocs/op |
| ⚡ zap (sugared) | 1363 ns/op | 1610 B/op | 20 allocs/op |
| go-kit | 3614 ns/op | 2895 B/op | 66 allocs/op |
| lion | 5392 ns/op | 5807 B/op | 63 allocs/op |
| logrus | 5661 ns/op | 6092 B/op | 78 allocs/op |
| apex/log | 15332 ns/op | 3832 B/op | 65 allocs/op |
| log15 | 20657 ns/op | 5632 B/op | 93 allocs/op |
使用一个已经有 10 个 KV 字段的 logger 记录一条消息 :
| Library | Time | Bytes Allocated | Objects Allocated |
|---|---|---|---|
| zerolog | 52 ns/op | 0 B/op | 0 allocs/op |
| ⚡ zap | 283 ns/op | 0 B/op | 0 allocs/op |
| ⚡ zap (sugared) | 337 ns/op | 80 B/op | 2 allocs/op |
| lion | 2702 ns/op | 4074 B/op | 38 allocs/op |
| go-kit | 3378 ns/op | 3046 B/op | 52 allocs/op |
| logrus | 4309 ns/op | 4564 B/op | 63 allocs/op |
| apex/log | 13456 ns/op | 2898 B/op | 51 allocs/op |
| log15 | 14179 ns/op | 2642 B/op | 44 allocs/op |
记录一个字符串,没有字段或 printf 风格的模板 :
| Library | Time | Bytes Allocated | Objects Allocated |
|---|---|---|---|
| zerolog | 50 ns/op | 0 B/op | 0 allocs/op |
| ⚡ zap | 236 ns/op | 0 B/op | 0 allocs/op |
| standard library | 453 ns/op | 80 B/op | 2 allocs/op |
| ⚡ zap (sugared) | 337 ns/op | 80 B/op | 2 allocs/op |
| go-kit | 508 ns/op | 656 B/op | 13 allocs/op |
| lion | 771 ns/op | 1224 B/op | 10 allocs/op |
| logrus | 1244 ns/op | 1505 B/op | 27 allocs/op |
| apex/log | 2751 ns/op | 584 B/op | 11 allocs/op |
| alog15 | 5181 ns/op | 5181 ns/op | 26 allocs/op |
相似的库
logrus[5] 功能强大
zap[6] 非常快速,结构化,分级
参考资料
[1] 性能: https://github.com/rs/zerolog#benchmarks
[2] zap: https://godoc.org/go.uber.org/zap
[3] 这里: https://pkg.go.dev/github.com/rs/zerolog#readme-standard-types
[4] issue 23199: https://golang.org/issue/23199
[5] logrus: https://github.com/sirupsen/logrus
[6] zap: https://github.com/uber-go/zap
[7] zerolog 官方文档: https://pkg.go.dev/github.com/rs/zerolog