为什么建议少用if语句!
相信大家或多或少的听说过,少用点if-else吧?但是为什么要少用呢,有人说他会影响程序运行效率,但是这并不是他最大的罪状...
if-else 的罪状
if-else 作为三种最基本的程序结构之一,是我们从最开始学习编程时就接触的基本语句。但是到后面的阶段就不断听人说少用if-else。
如果询问原因的话,你得到的结果大概率是if-else导致程序运行效率下降。这次来扯扯为什么我们说要少用if-else。
- 导致程序运行效率下降(大部分时候可以忽略)
- 破坏程序结构,导致代码难以维护(核心原因 ⭐)
if 语句与运行效率
说起if语句导致程序运行效率下降,就不得不提到CPU的流水线结构,效率降低主要是由于多级流水线结构造成的。
现代的大部分CPU在执行代码的时候并不是读取一条指令然后执行一条执行的,而是使用了一种叫做流水线技术的方式,同时去执行多个操作。
流水线的影响
比如三级流水线就是指,CPU在执行一条指令时,同时会读取后面的指令,并对进行译码。(读取、译码、执行)
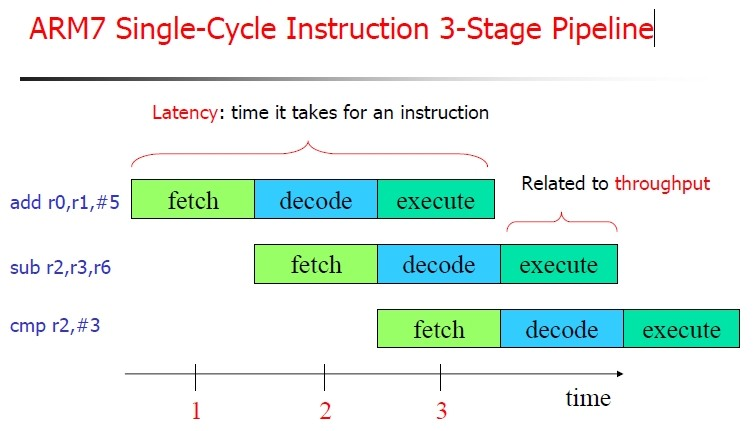
这样处理的优势很明显,使用流水线技术可以大大的提高执行效率。
但是它并不是所有时刻有效的,在程序中执行跳转代码时,CPU 会丢弃流水线现有的结果。 原因嘛,很简单!我都不执行后面的代码了,你提前读取有啥用~
所以在这个时候if语句相对于顺序执行的指令,会有几个时钟周期的差距。但这不是if语句所特有的,所有带跳转结构的语句都会这样(if、switch、for)。
分支预测的影响
多级流水线在遇到跳转时,会有几个时钟的周期的影响,但这并不是它被指控运行效率低的主要原因。 而是在因为它分支预测部分,它有可能有10-20个时钟周期的影响,在大量使用if的地方这种影响将被放大。
下面说说分支预测为什么会有这么大的影响。
在上面说到多级流水在遇到跳转指令时会清空当前流水线,CPU的设计者在设计引入了一种叫做分支预测的技术来进行处理这个问题。 分支预测简单说就是猜测后面的程序会执行那一段代码,并提前将它读取。

而大家所说的效率降低主要源于此。
if-else 对程序结构的影响
在大部分情况下,我们是不需要考虑if语句对代码执行效率的影响,我们甚至感觉不到它的存在。 因为大部分情况下,CPU的性能是足够的(性能优化时除外)。
但是if-else对程序结构的影响却是不容忽视的,因为我们可以直观的感受到它的存在,而且对开发和维护有极大的影响。
看下面一段代码:
if (condition1==true)
{f1();}
else if (condition2==true)
{f2();}
else if (condition3==true)
{f3();}这个代码非常简单:判断不同条件时执行不同的代码块。 这段代码写完测试时发现有点问题
- condition1和condition3同时满足时应该先执行f4
- condition3和condition4满足任意一个时执行f3 修改代码测试通过后,于是乎代码变成了下面的模样:
else if (condition1==true)
{
if (condition3==true)
{ f4(); }
f1();
}
else if (condition2==true)
{ f2(); }
else if (condition3==true || condition4==true)
{ f3(); }这只是我简单模拟的一段代码,对于稍微复杂的逻辑,if-else的数量远远大于上面的数量。
在这样的代码中,如果各种condition都是使用flag变量进行标记时,将会是一种巨大的灾难。
我之前碰到这样的代码时,心情只能用下图表示。
这个才是少用if-else真的原因!
如何消除if-else
既然上面说到了if-else有这么多的问题,那应该怎样减少使用它呢,
1. 巧妙使用算术表达式
比如下面的代码,在num不能被5整除时,num加一
else if (condition1==true)
{
if (condition3==true)
{ f4(); }
f1();
}
else if (condition2==true)
{ f2(); }
else if (condition3==true || condition4==true)
{ f3(); }可以替换成 num = num + !!(num%5);
这种一般是在对计算结果进行简单判断时可使用,它的优化点在于消除了分支结构,提高了执行效率。(虽然说很小)。
使用断言(assert)
在对函数参数进行合法性检查时常用,可以减少大量对参数进行时的if-else,适用场景也比较简单。
查找表(函数转移表)
查找表或者函数转移表,可以对程序的整体结构进行优化或者改进。 比如下面一个计算器的代码:
if(oper == ADD)
{ Result=add(op1,op2);}
else if(oper == SUB)
{ Result=add(op1,op2);}
if(oper == MUL)
{ Result=mul(op1,op2);}
else if(oper == DIV)
{ Result=div(op1,op2);}使用函数转移表可改进为
typedef int (*oper_t)(int, int);
oper_t oper_table[]={add, sub, mul, div};
...
result = oper_table[oper](op1,op2);查找表则相对更灵活,可以对不同类型的数据进行查找;
#define arrayof(x) (sizeof(x)/sizeof(x[0]))
typedef int (*oper_t)(int, int);
struct find_table_t {
char *oper_name;
oper_t oper_func;
}
find_table_t oper_table[]=
{{"add",add}, {"sub",sub}, {"mul",mul}, {"div",div}};
for(int i=0; i<arrayof(oper_table);i++)
{
if(strcmp(oper,oper[i].oper_name)==0)
{
result = oper[i].func(op1,op2);
return result;
}
}责任链(职责链)
责任链将一个复杂逻辑的流程进行分解,将每个判断条件的判断交给责任链节点进行处理,在处理完成后将结果传递给下一个节点。
在后面有专门一篇文章写责任链模式,在这就不展开了。
状态机
状态机也是消除if-else的一种方法,在状态机中对所有条件的判断变成的状态转移。
在后面也会有单独的文章讲解有限状态机的实现和应用。