Feed流应用重构-架构篇
重构,于我而言,很大的快乐在于能够解决问题。
第一次重构是重构一个c#版本的彩票算奖系统。当时的算奖系统在开奖后,算奖经常超时,导致用户经常投诉。接到重构的任务,既兴奋又紧张,花了两天时间,除了吃饭睡觉,都在撸代码。重构效果也很明显,算奖耗时从原来的1个小时减少到10分钟。
去年,我以架构师的身份参与了家校朋友圈应用的重构。应用麻雀虽小,五脏俱全,和诸君分享架构设计的思路。
01 应用背景
1 . 应用介绍
移动互联网时代,Feed流产品是非常常见的,比如我们每天都会用到的朋友圈,微博,就是一种非常典型的Feed流产品。Feed(动态):Feed流中的每一条状态或者消息都是Feed,比如朋友圈中的一个状态就是一个Feed,微博中的一条微博就是一个Feed。Feed流:持续更新并呈现给用户内容的信息流。每个人的朋友圈,微博关注页等等都是一个Feed流。
家校朋友圈是校信app的一个子功能。学生和老师可以发送图片,视频,声音等动态信息,学生和老师可以查看班级下的动态聚合。

▍ 代码可维护性
服务端端代码已经有四年左右的历史,随着时间的推移,人员的变动,不断的修复Bug,不断的添加新功能,代码的可读性越来越差。而且很多维护的功能是在没有完全理解代码的情况下做修改的。新功能的维护越来越艰难,代码质量越来越腐化。
▍ 查询瓶颈服务端使用的mysql作为数据库。Feed表数据有两千万,Feed详情表七千万左右。服务端大量使用存储过程(200+)。动态查询基本都是多张千万级大表关联,查询耗时在5s左右。DBA同学反馈sql频繁超时。
2 . 重构过程
《重构:改善既有代码的设计》这本书重点强调: “不要为了重构而重构”。重构要考虑时间(2个月),人力成本(3人),需要解决核心问题。
1、功能模块化, 便于扩展和维护
2、灵活扩展Feed类型, 支撑新业务接入
3、优化动态聚合页响应速度
基于以上目标, 我和小伙伴按照如下的工作。
1)梳理朋友圈业务,按照清晰的原则,将单个家校服务端拆分出两个模块
- 1 space-app: 提供rest接口,供app调用
- 2 space-task: 推送消息, 任务处理
2)分库分表设计, 去存储过程, 数据库表设计
数据库Feed表已达到2000万, Feed详情表已达到7000万+。为了提升查询效率,肯定需要分库分表。但考虑到数据写入量每天才2万的量级,所以分表即可。
数据库里有200+的存储过程,为了提升数据库表设计效率,整理核心接口调用存储过程逻辑。在设计表的时候,需要考虑shardingKey冗余。按照这样的思路,梳理核心逻辑以及新表设计的时间也花了10个工作日。
产品大致有三种Feed查询场景
- 班级维度: 查询某班级下Feed动态列表
- 用户维度:查询某用户下Feed动态列表
- Feed维度: 查询feed下点赞列表
3)架构设计 在梳理业务,设计数据库表的过程中,并行完成各个基础组件的研发。
基础组件的封装包含以下几点:
- 分库分表组件,Id生成器,springboot starter
- rocketmq client封装
- 分布式缓存封装
03 分库分表
3.1 主键
分库分表的场景下我选择非常成熟的snowflake算法。
第一位不使用,默认都是0,41位时间戳精确到毫秒,可以容纳69年的时间,10位工作机器ID高5位是数据中心ID,低5位是节点ID,12位序列号每个节点每毫秒累加,累计可以达到2^12 4096个ID。

Long workerId = Math.abs(crc32(shardingKeyValue) % 1024)
//这里我们也可以认为是在1024个槽里的slot底层使用的是redis的自增incrby命令。
//转换成中间10位编码
Integer workerId = Math.abs(crc32(shardingKeyValue) % 1024);
String idGeneratorKey =
IdConstants.ID_REDIS_PFEFIX + currentTime;
Long counter = atomicCommand.incrByEx(
idGeneratorKey,
IdConstants.STEP_LENGTH,
IdConstants.SEQ_EXPIRE_TIME);
Long uniqueId = SnowFlakeIdGenerator.getUniqueId(
currentTime,
workerId.intValue(),
counter);为了避免频繁的调用redis命令,还加了一层薄薄的本地缓存。每次调用命令的时候,一次步长可以设置稍微长一点,保持在本地缓存里,每次生成唯一主键的时候,先从本地缓存里预取一次,若没有,然后再通过redis的命令获取。
3.2 策略
因为早些年阅读cobar源码的关系,所以采用了类似cobar的分库方式。
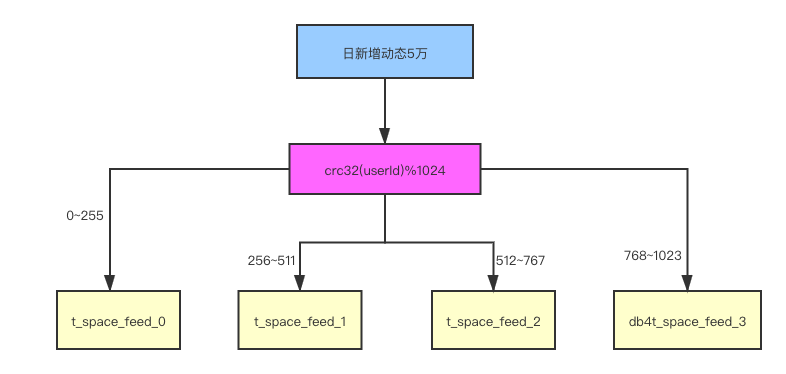
举例:用户编号23838,crc32(userId)%1024=562,562在区间[256,511]之间。所以该用户的Feed动态会存储在t_space_feed1表。
3.3 查询
带shardingkey的查询,比如就通过用户编号查询t_space_feed表,可以非常容易的定位表名。
假如不是shardingkey,比如通过Feed编号(主键)查询t_space_feed表,因为主键是通过snowflake算法生成的,我们可以通过Feed编号获取workerId(10位机器编号), 通过workerId也就确定数据位于哪张表了。
模糊查询场景很少。方案就是走ES查询,Feed数据落库之后,通过MQ消息形式,把数据同步ES,这种方式稍微有延迟的,但是这种可控范围的延迟是可以接受的。
3.4 工程
分库分表一般有三种模式:
- 代理模式,兼容mysql协议。如cobar,mycat,drds。
- 代理模式,自定义协议。如艺龙的DDA。
- 客户端模式,最有名的是shardingsphere的sharding-jdbc。
分库分表选型使用的是sharding-jdbc,最重要的原因是轻便简单,而且早期的代码曾经看过一两次,原理有基础的认识。
核心代码逻辑其实还是蛮清晰的。
ShardingRule shardingRule = new ShardingRule(
shardingRuleConfiguration,
customShardingConfig.getDatasourceNames());
DataSource dataSource = new ShardingDataSource(
dataSourceMap,
shardingRule,
properties);请注意: 对于整个应用来讲,client模式的最终结果是初始化了DataSource的接口。
- 需要定义初始化数据源信息 datasourceNames是数据源名列表, dataSourceMap是数据源名和数据源映射。
2 . 这里有一个概念逻辑表和物理表。
| 逻辑表 | 物理表 |
|---|---|
| t_space_feed (动态表) | t_space_feed_0~3 |
3 . 分库算法: DataSourceHashSlotAlgorithm:分库算法 TableHashSlotAlgorithm:分表算法 两个类的核心算法基本是一样的。
- 支持多分片键
- 支持主键查询
4 . 配置shardingRuleConfiguration。这里需要为每个逻辑表配置相关的分库分表测试。表规则配置类:TableRuleConfiguration。它有两个方法
- setDatabaseShardingStrategyConfig
- setTableShardingStrategyConfig
整体来看,shardingjdbc的api使用起来还是比较流畅的。符合工程师思考的逻辑。
04 Feed流
班级动态聚合页面,每一条Feed包含如下元素:
- 动态内容(文本,音频,视频)
- 前N个点赞用户
- 当前用户是否收藏,点赞数,收藏数
- 前N个评论
聚合首页需要显示15条首页动态列表,每条数据从数据数据库里读取,那接口性能肯定不会好。所以我们应该用缓存。那么这里就引申出一个问题,列表如何缓存?
4.1 列表缓存
列表如何缓存是我非常渴望和大家分享的技能点。这个知识点也是我 2012 年从开源中国上学到的,下面我以「查询博客列表」的场景为例。
我们先说第1种方案:对分页内容进行整体缓存。这种方案会 按照页码和每页大小组合成一个缓存key,缓存值就是博客信息列表。假如某一个博客内容发生修改, 我们要重新加载缓存,或者删除整页的缓存。
这种方案,缓存的颗粒度比较大,如果博客更新较为频繁,则缓存很容易失效。下面我介绍下第 2 种方案:仅对博客进行缓存。流程大致如下:
1)先从数据库查询当前页的博客id列表,sql类似:
select id from blogs limit 0,10
2)批量从缓存中获取博客id列表对应的缓存数据 ,并记录没有命中的博客id,若没有命中的id列表大于0,再次从数据库中查询一次,并放入缓存,sql类似:
select id from blogs where id in (noHitId1, noHitId2)
3)将没有缓存的博客对象存入缓存中
4)返回博客对象列表
理论上,要是缓存都预热的情况下,一次简单的数据库查询,一次缓存批量获取,即可返回所有的数据。另外,关于 缓 存批量获取,如何实现?
- 本地缓存:性能极高,for 循环即可
- memcached:使用 mget 命令
- Redis:若缓存对象结构简单,使用 mget 、hmget命令;若结构复杂,可以考虑使用 pipleline,lua脚本模式
第 1 种方案适用于数据极少发生变化的场景,比如排行榜,首页新闻资讯等。
第 2 种方案适用于大部分的分页场景,而且能和其他资源整合在一起。举例:在搜索系统里,我们可以通过筛选条件查询出博客 id 列表,然后通过如上的方式,快速获取博客列表。
4.2 聚合
Redis:若缓存对象结构简单,使用 mget 、hmget命令;若结构复杂,可以考虑使用 pipleline,lua脚本模式
这里我们使用的是pipeline模式。客户端采用了redisson。伪代码:
//添加like zset列表
ZsetAddCommand zsetAddCommand = new ZsetAddCommand(LIKE_CACHE_KEY + feedId, spaceFeedLike.getCreateTime().getTime(), userId);
pipelineCommandList.add(zsetAddCommand);
//设置feed 缓存的加载数量
HashMsetCommand hashMsetCommand = new HashMsetCommand(FeedCacheConstant.FEED_CACHE_KEY + feedId, map);
pipelineCommandList.add(hashMsetCommand);
//一次执行两个命令
List<?> result = platformBatchCommand.executePipelineCommands(pipelineCommandList);- 根据班级编号查询出聚合页面feedIdList;
- 根据列表缓存的策略分别加载 动态,点赞,收藏,评论数据,并组装起来。
| 模块 | redis存储格式 |
|---|---|
| 动态 | HASH 动态详情 |
| 点赞 | ZSET 存储userId ,前端显示用户头像,用户缓存使用string存储 |
| 收藏 | STRING 存储userId和FeedId的映射 |
| 评论 | ZSET 存储评论Id,评论详情存储在string存储 |
缓存全部命中的情况下,动态聚合页查询在5毫秒以内,全部走数据库的情况下50~80ms之间。
05 消息队列
我们参考阿里ons client 模仿他的设计模式,做了rocketmq的简单封装。
封装的目的在于方便工程师接入,减少工程师在各种配置上心智的消耗。
- 支持批量消费和单条消费;
- 支持顺序发送;
- 简单优化了rocketmq broker限流情况下,发送消息失败的场景。
写在最后
这篇文字主要和大家分享应用重构的架构设计。其实重构有很多细节需要处理。
- 数据迁移方案
- 团队协作,新人培养
- 应用平滑升级
每一个细节都需要花费很大的精力,才可能把系统重构好。