如何基于LSM-tree架构实现一写多读

一 前言
PolarDB是阿里巴巴自研的新一代云原生关系型数据库,在存储计算分离架构下,利用了软硬件结合的优势,为用户提供具备极致弹性、海量存储、高性能、低成本的数据库服务。X-Engine是阿里巴巴自研的新一代存储引擎,作为AliSQL的核心引擎之一已广泛用于阿里巴巴集团核心业务,包括交易历史库,钉钉历史库,图片空间等。X-Engine基于LSM-tree架构,其核心特征是数据以追加写方式写入,高压缩低成本,适用于写多读少,有低成本诉求的业务场景。传统MySQL基于binlog复制的主备架构有它的局限性,包括存储空间有限,备份恢复慢,主备复制延迟等问题,为了解决用户对于云上RDS(X-Engine)大容量存储,以及弹性伸缩的诉求,PolarDB推出了历史库(基于X-Engine引擎的一写多读)产品,支持物理复制,提供一写多读的能力,目前已经在阿里云官网售卖。本文主要阐述如何基于LSM-tree结构的存储引擎实现数据库的一写多读能力。
二 LSM-tree数据库引擎
LSM-Tree全称是Log Structured Merge Tree,是一种分层,有序,面向磁盘设计的数据结构,其核心思想是利用磁盘批量的顺序写要比随机写性能高的特点,将所有更新操作都转化为追加写方式,提升写入吞吐。LSM-tree类的存储引擎最早源于Google三驾马车之一的BigTable的存储引擎以及它的开源实现LevelDB。LSM-tree存储引擎有几个特点,首先增量数据像日志一样,通过追加方式写入,顺序落盘;其次,数据按照key来进行有序组织,这样在内存和磁盘中会形成一颗颗小的“有序树”;最后,各个“有序树”可以进行归并,将内存中的增量数据迁移到磁盘上,磁盘上的多个“有序树”可以进行归并,优化树的形状,整个LSM-tree是一个有序的索引组织结构。
在云原生数据库时代,一写多读技术已被广泛应用于生产环境中,主要云产商都有其标杆产品,典型代表包括亚马逊的Aurora,阿里云的PolarDB以及微软云的Socrates。它的核心思想是计算存储分离,将有状态的数据和日志下推到分布式存储,计算节点无状态,多个计算节点共享一份数据,数据库可以低成本快速扩展读性能。Aurora是这个领域的开山鼻祖,实现了业内第一个一写多读的数据库,计算节点Scale up,存储节点Scale out,并将日志模块下推到存储层,计算节点之间,计算与存储节点之间传输redo日志,计算节点基于Quorum协议写多副本保证可靠性,存储层提供多版本页服务。PolarDB与Aurora类似,也采用了存储计算分离架构,与Aurora相比,PolarDB它自己的特色,存储基座是一个通用的分布式文件系统,大量采用OS-bypass和zero-copy技术,存储的多副本一致性由ParallelRaft协议保证。PolarDB计算节点与存储节点同时传输数据页和redo日志,计算节点与计算节点之间只传递位点信息。与Aurora的“日志即数据库”理念一样,Socrates的节点之间只传输redo日志,也实现了多版本页服务,它的特点是将数据库存储层的持久性与可用性分开,抽象出一套日志服务。整个数据库分为3层,一层计算服务,一层page server服务和一层日志服务,这样设计的好处是可以分层进行优化,提供更灵活和细粒度的控制。
虽然Aurora,PolarDB和Socrates在设计上各有特点,但它们都共同践行了存储计算分离思想,数据库层面提供一写多读的能力。深入到存储引擎这一层来说,这几个产品都是基于B+tree的存储引擎,如果基于LSM-tree存储引擎来做呢?LSM-tree有它自己的特点,追加顺序写,数据分层存储,磁盘上数据块只读更有利于压缩。X-Engine引擎云上产品RDS(X-Engine)已经充分发挥了LSM-tree高压缩低成本特点,同样的数据量,存储空间只占到RDS(InnoDB)的1/3甚至更少,RDS(X-Engine)传统的主备架构,依然面临着主备复制延迟大,备份恢复慢等问题。
基于LSM-tree引擎实现一写多读,不仅计算资源和存储资源解耦,多个节点共享一份数据还能进一步压缩存储成本。基于LSM-tree引擎实现一写多读面临着与B+tree引擎不一样的技术挑战,首先是存储引擎日志不一样,LSM-tree引擎是双日志流,需要解决双日志流的物理复制问题;其次是数据组织方式不一样,LSM-tree引擎采用分层存储,追加写入新数据,需要解决多个计算节点一致性物理快照以及Compation问题。最后,作为数据库引擎,还需要解决一写多读模式下DDL的物理复制问题。同时,为了产品化,充分发挥B+tree引擎和LSM-tree引擎的各自优势,还面临着新的挑战,即如何在一个数据库产品中同时实现两个存储引擎(InnoDB,X-Engine)的一写多读。
三 LSM-tree引擎一写多读的关键技术
1 PolarDB整体架构
PolarDB支持X-Engine引擎后,X-Engine引擎与InnoDB引擎仍然独立存在。两个引擎各自接收写入请求,数据和日志均存储在底层的分布式存储上,其中idb文件表示的是InnoDB的数据文件,sst文件表示的是X-Engine的数据文件。这里最主要的点在于InnoDB与XEngine共享一份redo日志,X-Engine写入时,将wal日志嵌入到InnoDB的redo中,Replica节点和Standby节点在解析redo日志后,分发给InnoDB引擎和XEngine引擎分别回放进行同步。

X-Engine引擎架构
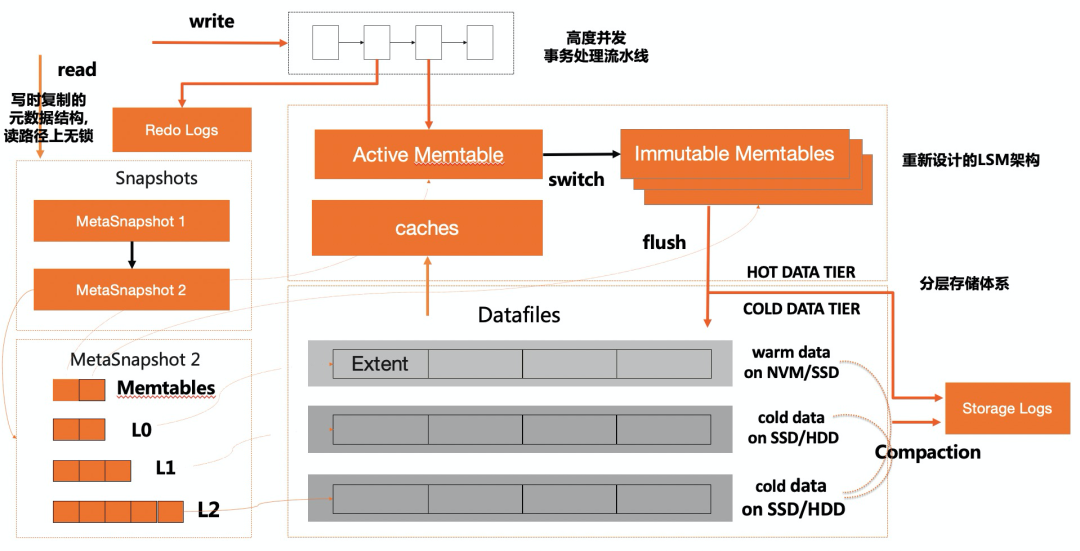
X-Engine引擎采用LSM-tree结构,数据以追加写的方式写入内存,并周期性物化到磁盘上,内存中数据以memtable形式存在,包括一个活跃的active memtable和多个静态的immutable。磁盘上数据分层存储,总共包括3层,L0,L1和L2,每一层数据按块有序组织。X-Engine最小空间分配单位是一个extent,默认是2M,每个extent包含若干个block,默认是16k。数据记录紧凑存储在block中,由于追加写特点,磁盘上的数据块都是只读的,因此X-Engine引擎可以默认对block进行压缩,另外block中的记录还会进行前缀编码,综合这些使得X-Engine的存储空间相对于InnoDB引擎只有1/3,部分场景(比如图片空间)甚至能压缩到1/7。有利就有弊,追加写带来了写入优势,对于历史版本数据需要通过Compaction任务来进行回收。有关X-Engine的核心技术可以参考发表在Sigmod19的论文,《X-Engine: An Optimized Storage Engine for Large-scale E-commerce Transaction Processing》
2 物理复制架构
物理复制的核心是通过引擎自身的日志来完成复制,避免写额外的日志带来的成本和性能损失。MySQL原生的复制架构是通过binlog日志进行复制,写事务需要同时写引擎日志和binlog日志,这带来的问题是一方面单个事务在关键写路径上需要写两份日志,写性能受制于二阶段提交和binlog的串行写入,另一方面binlog复制是逻辑复制,复制延迟问题也使得复制架构的高可用,以及只读库的读服务能力大打折扣,尤其是在做DDL操作时,这个延迟会进一步放大。
在InnoDB中有redo和undo两种日志,undo日志可以理解为一种特殊的“data”,所以实际上InnoDB的所有操作都能通过redo日志来保证持久性。因此,在进行复制时,只需要在主从节点复制redo日志即可。X-Engine引擎包含两种日志,一种是wal日志(WriteAheadLog),用于记录前台的事务的操作;另一种是Slog(StorageLog),用于记录LSM-tree形状变化的操作,主要指Compaction/Flush等。wal日志保证了前台事务的原子性和持久性,Slog则保证了X-Engine内部LSM-tree形状变化的原子性和持久性,这两个日志缺一不可,都需要复制同步。
共享存储下的物理复制
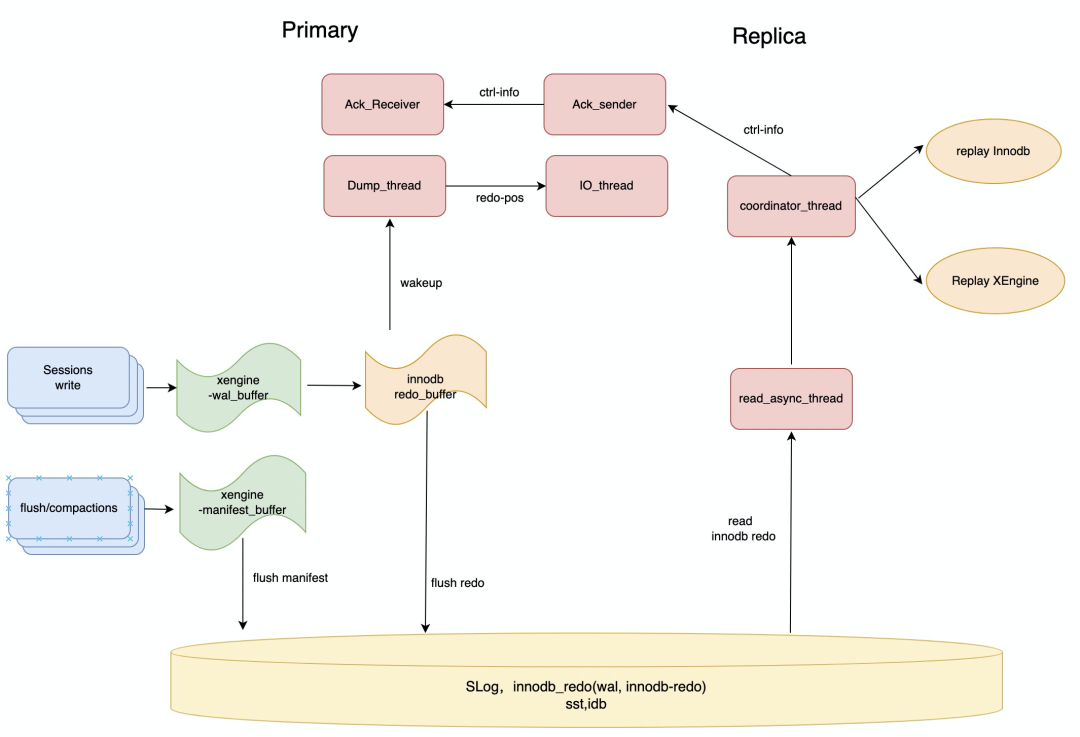
Primary-Replica物理复制架构
LSM-tree引擎一写多读的能力是对PolarDB进行功能增强,体现在架构层面就是充分利用已有的复制链路,包括Primary->Replica传递日志信息链路和Replica->Primary传递协同控制信息链路。InnoDB事务由若干个mtr(Mini-Transaction)组成,写入redo日志的最小单位是mtr。我们在Innodb的redo日志新增一种日志类型用于表示X-Engine日志,将X-Engine的事务内容作为一个mtr事务写入到redo日志中,这样Innodb的redo和X-Engine的wal日志能共享一条复制链路。由于Primary和Replica共享一份日志和数据,Dump_thread只需要传递位点信息,由Replica根据位点信息去读redo日志。Replica解析日志,根据日志类型来分发日志给不同的回放引擎,这种架构使得所有复制框架与之前的复制保持一致,只需要新增解析、分发X-Engine日志逻辑,新增X-Engine的回放引擎,充分与InnoDB引擎解耦。
由于LSM-tree追加写特点,内存memtable中数据会周期性的Flush到磁盘,为了保证Primary和Replica读到一致性物理视图,Primary和Replica需要同步SwitchMemtable,需要新增一条SwitchMemtable控制日志来协调。redo日志持久化后,Primary通过日志方式将位点信息主动推送给Replica,以便Replica及时回放最新的日志,减少同步延迟。对于Slog日志,既可以采用类似于redo的日志方式来主动“push”方式来同步位点,也可以采用Replica主动“pull”的方式来同步。SLog是后台日志,相对于前台事务回放实时性要求不高,不必要将redo位点和SLog位点都放在一条复制链路增加复杂性,所以采用了Replica的“pull”的方式来同步SLog。
灾备集群间的物理复制
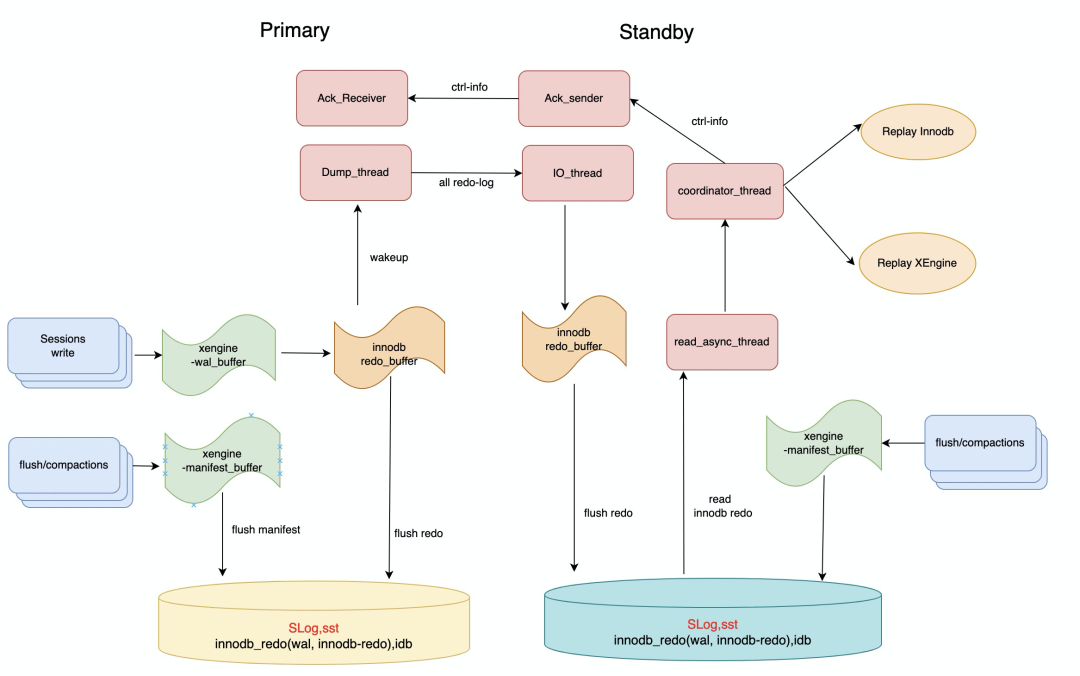
与共享集群复制不同,灾备集群有独立一份存储,Primary—>Standby需要传递完整的redo日志。Stanby与Replica区别在于日志来源不同,Replica从共享存储上获取日志,Standy从复制链路获取日志,其它解析和回放路径是一样的。是否将Slog日志作为redo日志一部分传递给Standby是一个问题,Slog日志由Flush/Compaction动作产生,记录的是LSM-tree形状的物理变化。如果也通过redo日志链路同步给Standby,会带来一些复杂性,一方面是X-Engine内部写日志的方式需要改动,需要新增新增文件操作相关的物理日志来确保主从物理结构一致,故障恢复的逻辑也需要适配;另一方面,Slog作为后台任务的操作日志,意味着复制链路上的所有角色都需要同构;如果放弃同构,那么Standy节点可能会触发Flush/Compaction任务写日志,这与物理复制中,只允许Primary写日志是相违背的。实际上,Slog同步写入到redo log中不是必须的,因为Slog是后台日志,这个动作不及时回放并不影响数据视图的正确性,因此,复制链路上只包含redo日志(X-Engine wal日志和InnoDB redo日志),Standby自己控制Flush/Compaction产生Slog日志,这样Standby也不必与Primary节点物理同构,整个架构与现有体系相匹配,同时也更加灵活。
3 并行物理复制加速
X-Engine的事务包括两个阶段,第一个阶段是读写阶段,这个阶段事务操作数据会缓存在事务上下文中,第二阶段是提交阶段,将操作数据写入到redo日志持久化,随后写到memtable中供读操作访问。对于Standby/Replica节点而言,回放过程与Primary节点类似,从redo中解析到事务日志,然后将事务回放到memtable中。事务之间不存在冲突,通过Sequence版本号来确定可见性。并行回放的粒度是事务,需要处理的一个关键问题就是可见性问题。事务串行回放时,Sequence版本号都是连续递增的,事务可见性不存在问题。在并行回放场景下,我们仍然需要保序,通过引入“滑动窗口”机制,只有连续一段没有空洞的Sequence才能推进全局的Sequence版本号,这个全局Sequence用于读操作获取快照。
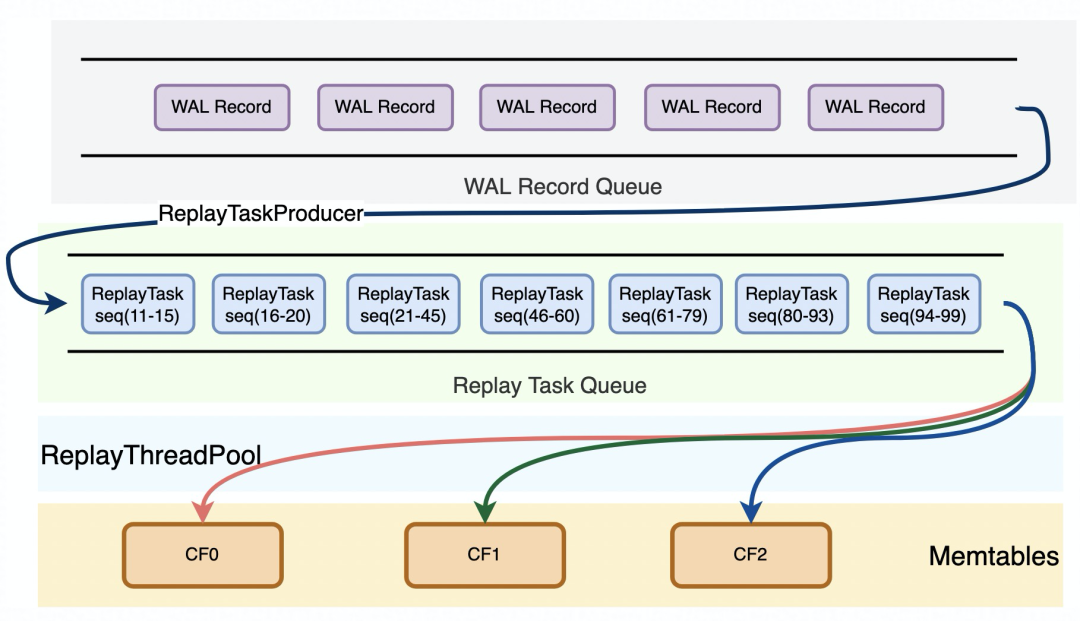
一写多读架构下,为了保证同一数据库实例的Primary、Replica、Standby三个角色的内存镜像完全一致,新增了一种SwitchMemtableLog,该Log Record在RW的switch_memtable过程中产生,因此RO、Standby不再主动触发switch_memtable操作,而是通过从RW上同步SwitchMemtableLog进行switch_memtable。SwitchMemtable操作是一个全局的屏障点,以防止当前可写memtable在插入过程中switch从而导致数据错乱。另外,对于2PC事务,并发控制也需要做适配。一个2PC事务除了数据本身的日志,还包括BeginPrepare、EndPrepare、Commit、Rollback四类日志,写入过程中保证BeginPrepare和EndPrepare写入到一个WriteBatch中并顺序落盘,因此可以保证同一个事务的Prepare日志都会被解析到一个ReplayTask中。在并行回放过程中,由于无法保证Commit或Rollback日志一定后于Prepare日志被回放,因此如果Commit、Rollback日志先于Prepare日志被回放,那么在全局的recovered_transaction_map中插入一个key对xid的空事务,对应的事务状态为Commit或Rollback;随后Prepare日志完成回放时,如果发现recovered_transaction_map中已经存在对应的事务,那么可以根据事务的状态来决定直接提交事务还是丢弃事务。
对于B+Tree的物理复制,LSM-tree的物理复制并不是真正的“物理”复制。因为B+Tree传递的redo的内容是数据页面的修改,而LSM-tree传递的redo内容是KeyValue值。这带来的结果是,B+tree物理复制可以基于数据页粒度做并发回放,而LSM-tree的物理复制是基于事务粒度的并发回放。B+tree并发回放有它自身的复杂性,比如需要解决系统页回放与普通数据页回放先后顺序问题,并且还需要解决同一个mtr中多个数据页并发回放可能导致的物理视图不一致问题。LSM-tree需要解决多个节点在同样位置SwitchMemtable,以及2PC事务回放等问题。
4 MVCC(多版本并发控制)
物理复制技术解决了数据同步的问题,为存储计算分离打下了基础。为了实现弹性,动态升降配,增删只读节点的能力,需要只读节点具备一致性读的能力,另外RW节点和RO节点共享一份数据,历史版本回收也是必需要考虑的问题。
一致性读
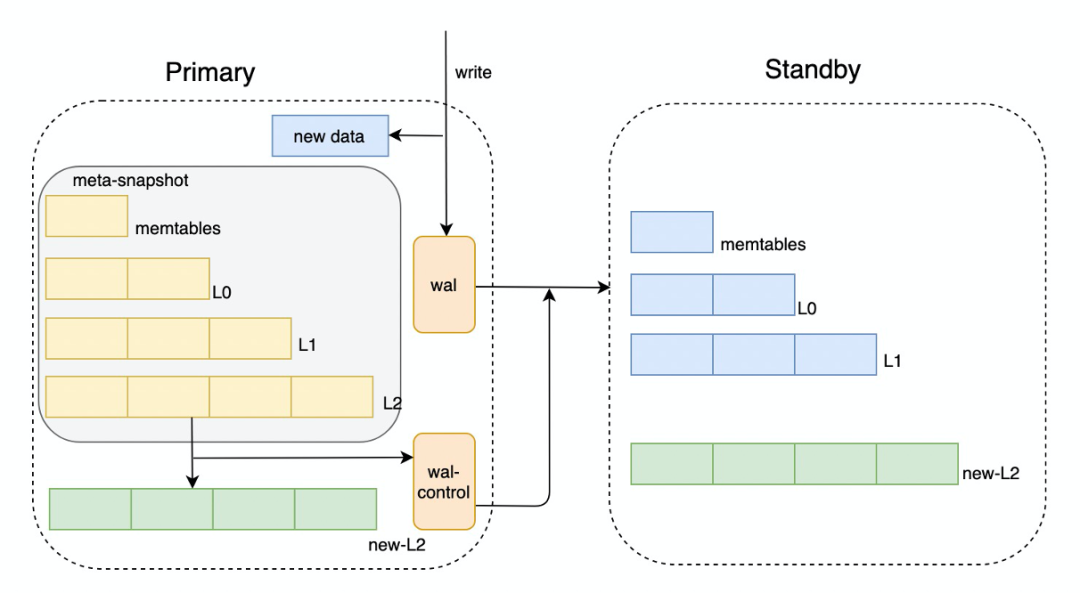
X-Engine提供快照读的能力,通过多版本机制来实现读写不互斥效果。从上述的X-Engine架构图可以看到,X-Engine的数据实际上包括了内存和磁盘两部分,不同于InnoDB引擎内存中page是磁盘上page的缓存,X-Engine中内存数据与磁盘数据完全异构,一份“快照”需要对应的是内存+磁盘数据。X-Engine采用追加写方式,新数据进来会产生新的memtable,后台任务做flush/compaction任务也会产生新的extent。那么如何获取一致性视图呢?X-Engine内部实际上是通过MetaSnapshot+Snapshot来管理,首先每个MetaSnapshot对应一组memtable和L0,L1, L2的extents,这样在物理上确定了数据范围,然后通过Snapshot来处理行级版本的可见性,这里的Snapshot实际上就是一个事务提交序列号Sequence。不同于InnoDB事务编号采用开始序,需要通过活跃事务视图来判断记录的可见性;X-Engine事务采用提交序,每条记录有一个唯一递增序列号Sequence,判断行级版本的可见性只需要比较Sequence即可。在一写多读的模式下,Replica节点与Primary节点共享一份磁盘数据,而磁盘数据是有内存中数据定期dump出来的,因此需要保证Primary和Replica节点有相同的切memtable位点,从而保证数据视图的一致性。
一写多读下的Compaction
在一写多读场景下,Replica可以通过类似于Primary的快照机制来实现快照读,需要处理的问题是历史版本回收问题。历史版本的回收,依赖于Compaction任务来完成,这里的回收包括两部分,一部分MetaSnapshot的回收,主要确认哪些memtable和extents可以被物理回收掉,另一部分是行级多版本回收,这里主要是确认哪些历史版本行可以被回收掉。对于MetaSnapshot的回收,Primary会收集所有Replica节点上的最小不再使用的MetaSnapshot版本号,X-Engine引擎的每个索引都是一个LSM-tree,因此汇报MetaSnaphot版本号是索引粒度的。Primary收集完MetaSnapshot版本号,计算最小可以回收的MetaSnapshot进行资源回收操作,回收操作以Slog日志的方式同步给Replica节点。Replica节点在回放日志进行资源回收时,需要将内存和磁盘资源分开,内存资源在各个节点是独立的,磁盘资源是共享的,因此Replica节点的内存资源可以独立释放,而磁盘资源则统一由Primary节点来释放。对于行级多版本的回收,同样需要由Primary节点收集所有Replica节点最小序列号Sequence,由Primary节点通过Compaction任务来消除。这块汇报链路复用PolarDB的ACK链路,只是新增了X-Engine的汇报信息。
5 DDL的物理复制如何实现
物理复制相对于逻辑复制一个关键优势在于DDL,对于DDL而言,逻辑复制可以简单理解为复制SQL语句,DDL在从库上会重新再执行一遍。逻辑复制对于比较重的DDL操作,比如Alter table影响非常大,一个Alter变更操作在主库执行需要半小时,那么复制到从库也需要再执行半小时,那么主从延迟最大可能就会是1个小时,这个延迟对只读库提供读服务产生严重影响。
Server层复制
DDL操作同时涉及到Server层和引擎层,包括字典,缓存以及数据。最基础的DDL操作,比如
Create/Drop操作,在一写多读架构下,要考虑数据与数据字典,数据与字典缓存一致性等问题。一写多读的基础是物理复制,物理复制日志只在引擎层流动,不涉及到Server层,因此需要新增日志来解决DDL操作导致的不一致问题。我们新增了meta信息变更的日志,并作为redo日志的一部分同步给从节点,这个meta信息变更日志主要包括两部分内容,一个是字典同步,主要是同步MDL锁,确保Primary/Replica节点字典一致;另一个是字典缓存同步,Replica上的内存是独立的,Server层缓存的字典信息也需要更新,因此要新增日志来处理,比如Drop Table/Drop db/Upate function/Upate precedure等操作。另外,还需要同步失效Replica的QueryCache,避免使用错误的查询缓存。
引擎层复制
X-Engine引擎与InnoDB引擎一样是索引组织表,在X-Engine内部,每个索引都是一个LSM-tree结构,内部称为Subtable,所有写入都是在Subtable中进行,Subtable的生命周期与DDL操作紧密相关。用户发起建表动作会产生Subtable,这个是物理LSM-tree结构的载体,然后才能有后续的DML操作;同样的,用户发起删表动作后,所有这个Subtable的DML操作都应该执行完毕。Create/Drop Table操作涉及到索引结构的产生和消亡,会同时产生redo控制日志和SLog日志,在回放时,需要解决redo控制日志和SLog日志回放的时序问题。这里我们将对应Subtable的redo日志的LSN位点持久化到SLog中,作为一个同步位点,Replica回放时,两个回放链路做协调即可,redo日志记录的是前台操作,Slog记录的是后台操作,因此两个链路做协同时,需要尽量避免redo复制链路等待Slog复制链路。比如,对于Create操作,回放Slog时,需要等待对应的redo日志的LSN位点回放完毕才推进;对于DROP操作,回放SLog也需要协同等待,避免回放前台事务找不到Subtable。
OnlineDDL复制技术
对于Alter Table操作,X-Engine实现了一套OnlineDDL机制,详细实现原理可以参考内核月报。在一写多读架构下,X-Engine引擎在处理这类Alter操作时采用了物理复制,实际上对于Replica而言,由于是同一份数据,并不需要重新生成物理extent,只需要同步元信息即可。对于Standby节点,需要通过物理extent复制来重新构建索引。DDL复制时,实际上包含了基线和增量部分。DDL复制充分利用了X-Engine的分层存储以及LSM-tree结构追加写特点,在获取快照后,利用快照直接构建L2作为基线数据,这部分数据以extent块复制形式,通过redo通道传递给Standby,而增量数据则与普通的DML事务一样,所以整个操作都是通过物理复制进行,大大提高了复制效率。这里需要限制的仅仅是在Alter操作过程中,禁止做到L2的compaction即可。整个OnlineDDL过程与InnoDB的OnlineDDL流程类似,也是包括3个阶段,prepare阶段,build阶段和commit阶段,其中prepare阶段需要获取快照,commit阶段元数据生效,需要通过MDL锁来确保字典一致。与基于B+tree的OnlineDDL复制相比,基线部分,B+tree索引复制的是物理页,而LSM-tree复制的是物理extent;增量部分B+tree索引是通过记增量日志,回放增量日志到数据页写redo日志进行同步,LSM-tree则是通过DML前台操作写redo的方式同步。
6 双引擎技术
Checkpoint位点推进
通过wal-in-redo技术,我们将X-Engine的wal日志嵌入到了InnoDB的redo中,首先要处理的一个问题就是redo日志的回收问题。日志回收首先涉及到一个位点问题,融合进redo日志后,X-Engine内部将RecoveryPoint定义为<lsn, Sequence>,lsn表示redo日志的位点,Sequence为对应的X-Engine的事务的版本号。Redo日志回收与Checkpoint(检查点)强相关,确保Checkpoint位点及时推进是需要考虑的问题,否则redo日志的堆积一方面影响磁盘空间,另一方面也影响恢复速度。这里有一个基本的原则是,Checkpoint=min(innodb-ckpt-lsn, xengine-ckpt-lsn),xengine-ckpt-lsn就是来源于X-Engine的RecoveryPoint,确保任何引擎有内存数据没有落盘时,对应的redo日志不能被清理。为了避免X-Engine的checkpoint推进影响整体位点推进,内部会确保xengine-ckpt-lsn与全局的redo-lsn保持一定的阀值,超过阀值则会强制将memtable落盘,推进检查点。
数据字典与DDL
X-Engine作为一个数据库引擎有自己独立的字典,InnoDB也有自己的字典,两份字典在一个系统里面肯定会存在问题。为了解决问题,这里有两种思路,一是X-Engine仍然保留自己的数据字典,在做DDL时,通过2PC事务来保证一致性,这带来的问题是需要有协调者。一般情况下,MySQL的协调者是binlog日志,在binlog关闭时是tclog日志。显然,从功能和性能角度,我们都不会强依赖binlog日志。我们采用了另外一种思路,X-Engine不再用自身引擎存储元数据,所有元数据均通过InnoDB引擎持久化,X-Engine元数据实际上是InnoDB字典的一份缓存,那么在做DDL变更时,元数据部分实际上只涉及InnoDB引擎,通过事务能保证DDL的原子性。
通过元数据归一化我们解决了元数据的原子性问题,但X-Engine数据和InnoDB元数据如何保证一致也是个问题。比如一个DDL操作,alter table xxx engine = xengine,这个DDL是将innodb表转为xengine表,由于表结构变更是Innodb字典修改,数据是在修改X-Engine,是一个跨引擎事务,跨引擎事务需要通过协调者保证一致性。为了避免引入binlog作为协调者依赖,tclog作为协调者没有经过大规模生产环境验证,我们选择了另外一种处理方式,具体来说,在涉及跨引擎事务时,优先提交X-Engine事务,然后再提交InnoDB事务。对于DDL来说,就是“先数据,后元数据”,元数据提交了,才真正表示这个DDL完成。如果中途失败,则结合“延迟删除”的机制,来保证垃圾数据能被最终清理掉,通过一个后台任务来周期性的对比X-Engine数据与InnoDB的字典,以InnoDB字典为准,结合X-Engine内存元信息,确认这部分数据是否有用。
CrashRecovery
X-Engine与InnoDB引擎一样是MySQL的一个插件,X-Enigne作为一个可选的插件,启动顺序在Innodb之后。每个引擎在恢复阶段都需要通过redo日志来将数据库恢复到宕机前状态。在双引擎形态下,所有redo都在InnoDB中,那意味着无论是InnoDB引擎还是X-Engine引擎在读取日志恢复时,都需要扫描整个redo日志,相当于整个恢复阶段扫描了两遍redo,这可能使得整个宕机恢复过程非常长,降低了系统的可用性。为了解决这个问题,我们将X-Engine的恢复阶段细分,并且调整引擎的启动顺序,在InnoDB启动前,先完成X-Engine的初始化以及Slog等恢复过程,处于恢复redo的状态。在InnoDB启动时,根据类型将日志分发X-Engine引擎,整个流程与正常同步redo日志的过程一致。当redo日志分发完毕,相当于InnoDB引擎和X-Engine引擎自身的宕机恢复过程已经完成,然后走正常XA-Recovery和Post-Recovery阶段即可,这个流程与之前保持一致。
HA
PolarDB支持双引擎后,整个升降级流程中都会嵌套有X-Engine引擎的逻辑,比如在Standby升级为RW前,需要确保X-Engine的回放流水线完成,并将未决的事务保存起来,以便后续通过XA_Recovery继续推进。RW降级为Standby的时候需要等待X-Engine写流水线回放,同时如果还残留有未决事务,需要在切换过程中将这部分未决事务遍历出来存入Recovered_transactions_集合供后续并发回放使用。
四 LSM-tree VS B+tree
上节我们详细描述了基于LSM-tree架构的存储引擎,实现一写多读所需要的关键技术,并结合PolarDB双引擎介绍了一些工程实现。现在我们跳出来看看基于B+tree和基于LSM-tree两种数据组织结构在实现技术上的对比。首先要回到一个基本点,B+tree是原地更新,而LSM-tree是追加写,这带来的区别就是B+tree的数据视图在内存和外存一个缓存映射关系,而LSM-tree是一个叠加的关系。因而需要面对的技术问题也不同,B+tree需要刷脏,需要有double-write(在PolarFS支持16k原子写后,消除了这个限制);LSM-tree需要Compaction来回收历史版本。在一写多读的模式下面临的问题也不一样,比如,B+tree引擎复制是单redo日志流,LSM-tree引擎是双日志流;B+tree在处理并行回放时,可以做到更细粒度的页级并发,但是需要处理SMO(SplitMergeOperation)问题,避免读节点读到“过去页”或是“未来页”。而LSM-tree是事务级别的并发,为了保证RW和RO节点“内存+磁盘”的一致性视图,需要RW和RO在相同的位点做Switch Memtable。下表以InnoDB引擎和X-Engine引擎为例,列出了一些关键的区别点。

五 LSM-tree引擎业内发展状况
目前业内LSM-tree类型引擎比较热的是Rocksdb,它的主要应用场景是作为一个KeyValue引擎使用。Facebook将Rocksdb引擎引入到了他们的MySQL8.0分支,类似于X-Engine之于AliSQL,主要服务于他们的用户数据库UDB业务,存储用户数据和消息数据,采用的仍然是基于binlog的主备复制结构,目前没有看到有做存储计算分离,以及一写多读的事情。另外,github上有一个rocksdb-cloud项目,将rocksdb作为底座,架在AWS等云服务上提供NoSQL接口服务,相当于做了存储计算分离,但并不支持物理复制和一写多读。在数据库领域,阿里巴巴的Oceanbase和谷歌的Spanner的底层存储引擎都是基于LSM-tree结构,这显示了LSM-tree作为数据库引擎的可行性,这两个数据库都是基于Share-Nothing的架构。基于Share-Storage的数据库,到目前为止还没有成熟的产品,PolarDB(X-Engine)是业内第一个基于LSM-tree结构的实现的一写多读方案,对于后来者有很好的借鉴意义,LSM-tree这种结构天然将内存和磁盘存储分离,我们充分利用了磁盘存储只读的特点,通过压缩将其成本优势发挥出来,结合一写多读的能力,将成本优势发挥到极致。
六 性能测试
基于X-Engine引擎实现一写多读能力后,我们采用基准测试工具sysbench对性能做了摸底,主要对比了RDS(X-Engine),PolarDB(X-Engine)以及PolarDB(InnoDB)的性能。
1 测试环境
测试的client和数据库server均从阿里云官网购买。client采用ecs,规格是ecs.c7.8xlarge(32core,64G),测试sysbench版本是sysbench-1.0.20,测试的数据库server包括RDS(X-Engine),PolarDB(X-Engine),PolarDB(InnoDB)均采用8core32G规格,配置文件采用线上默认的配置。测试场景覆盖了全内存态和IO-bound的几种典型的workload。测试表数目是250张表,全内存态单表行数为25000行,IO-bound的表行数为300万行。
2 测试结果
RDS VS PolarDB
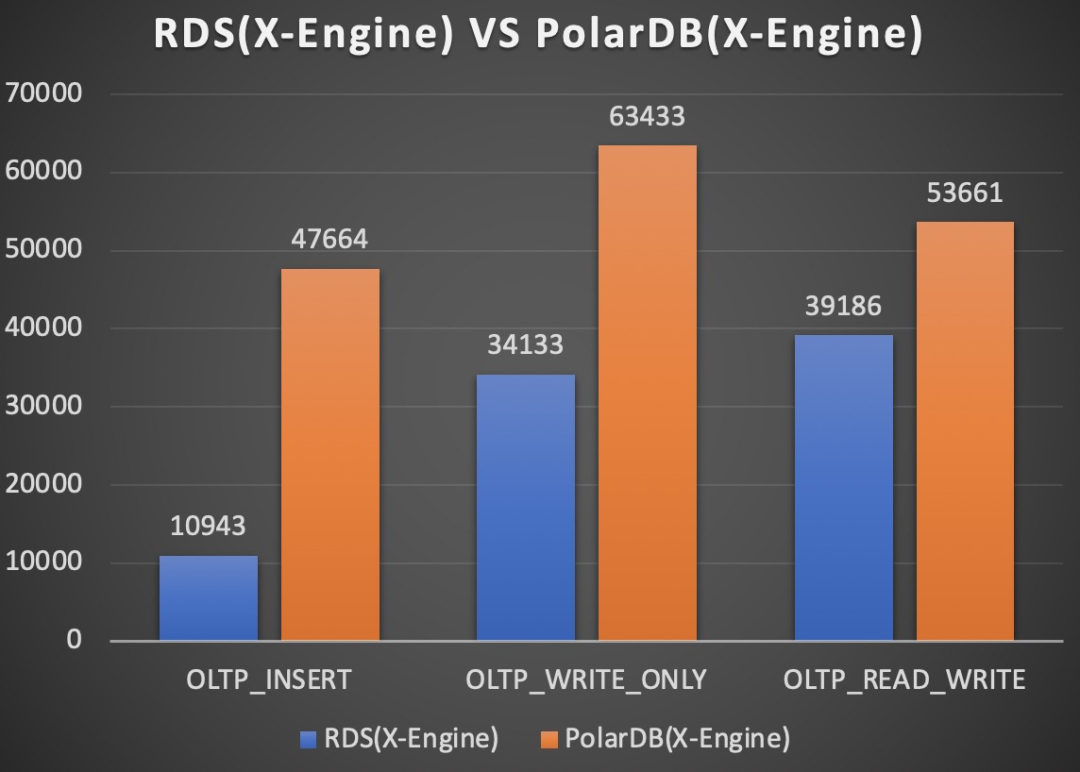
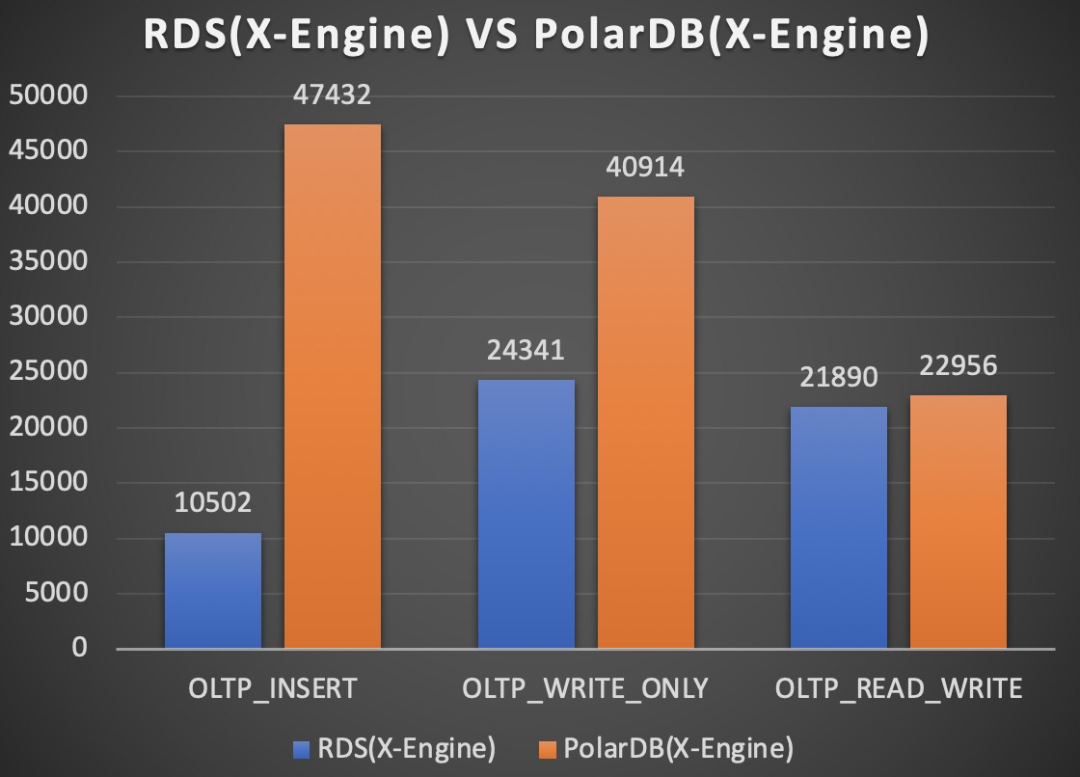
上面左图是小表全内存场景,右图是大表io-bound场景。PolarDB(X-Engine)相比RDS(X-Engine)主要是写入路径发生了变化,最核心的区别是RDS主备架构依赖binlog做复制,而PolarDB形态只需要redo日志即可。PolarDB形态的写相关workload的性能相比RDS形态,无论在全内存态,还是IO-bound场景,都有很大的性能提升。
B+tree VS LSM-tree
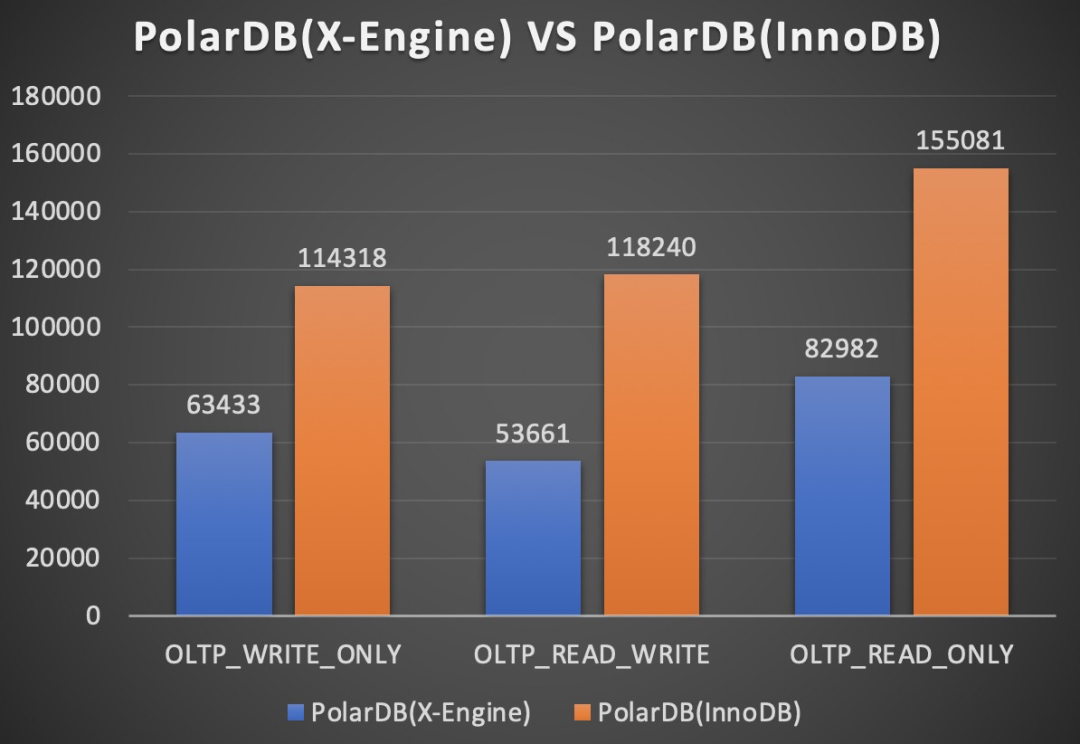
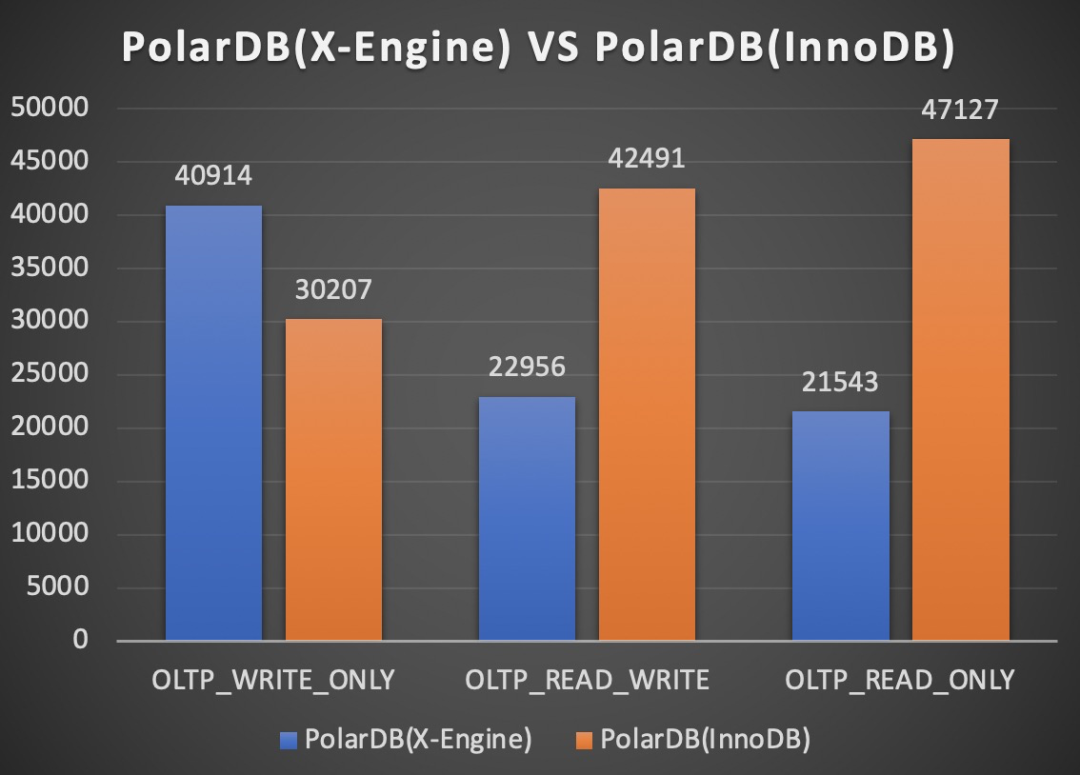
上图是小表全内存场景,下图是大表io-bound场景。PolarDB形态下,X-Engine引擎相对于InnoDB引擎还有差距,这个差距主要来源于range查询,另外更新场景导致的多版本,也会导致更新时需要做range查询,这些因素导致了读写相关的workload,InnoDB引擎比X-Engine表现更优秀。同时我们可以看到,在IO-bound场景,X-Engine引擎写入更有优势。
七 未来展望
PolarDB(X-Engine)解决方案很好解决了用户的归档存储问题,但目前来看还不够彻底。第一,技术上虽然PolarDB支持了双引擎,但我们还没有充分将两个引擎结合起来。一个可行的思路是在线归档一体化,用户的在线数据采用默认的引擎InnoDB,通过设定一定的规则,PolarDB内部自动将部分历史数据进行归档并转换为X-Engine引擎存储,整个过程对用户透明。第二,目前的存储都落在PolarDB的高性能存储PolarStore上,为了进一步降低成本,X-Engine引擎可以将部分冷数据存储在OSS上,这个对于分层存储是非常友好和自然的。实际上,基于LSM-tree的存储引擎有很强的可塑性,我们目前的工作只是充分发挥了存储优势,未来还可以对内存中数据结构进行进一步探索,比如做内存数据库等都是可以探索的方向。