案例:一次不寻常的慢查调优经历
问题描述和解决过程
最近有个非核心业务的CDB在巡检时总是能够发现慢查,其中出现最频繁的一条如下:
root@10.xx.xx.x 23:29: [xxl_job]> desc SELECT id FROM `xxl_job_log` WHERE !( (trigger_code in (0, 200) and handle_code = 0) OR (handle_code = 200) ) AND `alarm_status` = 0 ORDER BY id ASC LIMIT 1000;
+----+-------------+-------------+-------+------------------------------------------------------------+---------+---------+------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------------+-------+------------------------------------------------------------+---------+---------+------+---------+-------------+
| 1 | SIMPLE | xxl_job_log | index | I_handle_code,idx_xxl_job_log,idx_alarm_status_handle_code | PRIMARY | 8 | NULL | 4984979 | Using where |
+----+-------------+-------------+-------+------------------------------------------------------------+---------+---------+------+---------+-------------+
1 row in set (0.00 sec)老司机一看就能看出问题来,走了主键的全索引扫描,况且rows这么老大了,这代价可想而知。接下来我们来看一下表的索引部分
root@10.xx.xx.x 23:29: [xxl_job]> show create table xxl_job_log\\G
*************************** 1. row ***************************
Table: xxl_job_log
Create Table: CREATE TABLE `xxl_job_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
...
PRIMARY KEY (`id`),
KEY `I_trigger_time` (`trigger_time`),
KEY `I_handle_code` (`handle_code`),
KEY `idx_xxl_job_log` (`alarm_status`),
KEY `idx_alarm_status_handle_code` (`alarm_status`,`handle_code`,`trigger_code`),
KEY `idx_trigger_time` (`trigger_time`,`handle_code`,`trigger_code`),
KEY `index_0` (`job_id`,`trigger_time`)
) ENGINE=InnoDB AUTO_INCREMENT=63213303 DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)其实老司机一眼就能看出来,显然原表中有一个相对比较符合条件的索引idx_alarm_status_handle_code,可是为什么优化器没有选择呢?起初我以为是统计信息不够准确,所以我手动执行了重新收集统计信息,但是问题依旧,MySQL优化器并没有选择idx_alarm_status_handle_code
root@10.xx.xx.x 23:30: [xxl_job]> analyze table xxl_job_log;
+---------------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+---------------------+---------+----------+----------+
| xxl_job.xxl_job_log | analyze | status | OK |
+---------------------+---------+----------+----------+
1 row in set (0.07 sec)
root@10.xx.xx.x 23:31: [xxl_job]> desc SELECT id FROM `xxl_job_log` WHERE !( (trigger_code in (0, 200) and handle_code = 0) OR (handle_code = 200) ) AND `alarm_status` = 0 ORDER BY id ASC LIMIT 1000;
+----+-------------+-------------+-------+------------------------------------------------------------+---------+---------+------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------------+-------+------------------------------------------------------------+---------+---------+------+---------+-------------+
| 1 | SIMPLE | xxl_job_log | index | I_handle_code,idx_xxl_job_log,idx_alarm_status_handle_code | PRIMARY | 8 | NULL | 4228616 | Using where |
+----+-------------+-------------+-------+------------------------------------------------------------+---------+---------+------+---------+-------------+
1 row in set (27.18 sec)我们强制指定索引试一下,执行速度也是很快。
# 强制指定索引
root@10.xx.xx.x 23:30: [xxl_job]> desc SELECT id FROM `xxl_job_log` force index(idx_alarm_status_handle_code) WHERE !( (trigger_code in (0, 200) and handle_code = 0) OR (handle_code = 200) ) AND `alarm_status` = 0 ORDER BY id ASC LIMIT 1000;
+----+-------------+-------------+-------+------------------------------+------------------------------+---------+------+------+------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------------+-------+------------------------------+------------------------------+---------+------+------+------------------------------------------+
| 1 | SIMPLE | xxl_job_log | range | idx_alarm_status_handle_code | idx_alarm_status_handle_code | 5 | NULL | 1786 | Using where; Using index; Using filesort |
+----+-------------+-------------+-------+------------------------------+------------------------------+---------+------+------+------------------------------------------+
1 row in set (0.00 sec)
#实际执行
root@10.xx.xx.x 08:42: [xxl_job]> SELECT id FROM `xxl_job_log` force index(idx_alarm_status_handle_code) WHERE !( (trigger_code in (0, 200) and handle_code = 0) OR (handle_code = 200) ) AND `alarm_status` = 0 ORDER BY id ASC LIMIT 1000;
...
3 rows in set (0.01 sec)从这个强制指定索引的执行计划上来看,执行计划采用的是范围扫描的方式,处于对"范围"扫描的敏锐度,我大概知道问题出在哪里了,至于原因后面再说。
问题出在参数eq_range_index_dive_limit,关于这个参数,官方文档的解释如下:
The eq_range_index_dive_limit system variable enables you to configure the number of values at which the optimizer switches from one row estimation strategy to the other. To permit use of index dives for comparisons of up to N equality ranges, set eq_range_index_dive_limit to N + 1. To disable use of statistics and always use index dives regardless of N, set eq_range_index_dive_limit to 0.
Even under conditions when index dives would otherwise be used, they are skipped for queries that satisfy all these conditions:
- A single-index
FORCE INDEXindex hint is present. The idea is that if index use is forced, there is nothing to be gained from the additional overhead of performing dives into the index. - The index is nonunique and not a
FULLTEXTindex. - No subquery is present.
- No
DISTINCT,GROUP BY, orORDER BYclause is present.
Those dive-skipping conditions apply only for single-table queries. Index dives are not skipped for multiple-table queries (joins).
在使用范围扫描的时候,优化器在计算执行计划成本的时候会根据条件个数采用不同的方式以减小选择执行计划的开销,而eq_range_index_dive_limit就是莱控制这个条件个数的。当条件数N小于eq_range_index_dive_limit时,优化器认为此时条件个数尚可,可以采用成本较高但更为精确的index dive方式来计算执行成本;当N大于或等于eq_range_index_dive_limit时,优化器会认为此时使用index dive的方式计算成本带来的开销过大,此时MySQL优化器会根据index statistics直接估算成本。
大部分情况下,where条件中使用的索引列的选择性都还是不错的,使用index statistic直接估算返回行数并不会有太大偏差,并且能够避免index dive带来的开销,在IN条件较多的情况下,能快速找到正确的执行计划,提升系统性能。然而,不均匀分布的索引也不罕见,这种情况下,eq_range_index_dive_limit可能会显着影响查询执行计划。
root@10.xx.xx.x 23:32: [xxl_job]> show global variables like '%dive%';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| eq_range_index_dive_limit | 200 |
+---------------------------+-------+
1 row in set (0.00 sec)可以看到eq_range_index_dive_limit 原本配置的就是200,我们直接设置成1来关闭index dive。
root@10.xx.xx.x 23:32: [xxl_job]> set eq_range_index_dive_limit=1;
Query OK, 0 rows affected (0.00 sec)然后再来看执行计划
root@10.xx.xx.x 23:32: [xxl_job]> desc SELECT id FROM `xxl_job_log` WHERE !( (trigger_code in (0, 200) and handle_code = 0) OR (handle_code = 200) ) AND `alarm_status` = 0 ORDER BY id ASC LIMIT 1000;
+----+-------------+-------------+-------+------------------------------------------------------------+-----------------+---------+------+---------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------------+-------+------------------------------------------------------------+-----------------+---------+------+---------+------------------------------------+
| 1 | SIMPLE | xxl_job_log | range | I_handle_code,idx_xxl_job_log,idx_alarm_status_handle_code | idx_xxl_job_log | 1 | NULL | 1364433 | Using index condition; Using where |
+----+-------------+-------------+-------+------------------------------------------------------------+-----------------+---------+------+---------+------------------------------------+
1 row in set (0.00 sec)区别于执行的全索引扫描,这次优化器选择了索引idx_xxl_job_log,但是这索引似乎看起来并不是很理想,我们再次尝试下重新收集统计信息。
root@10.xx.xx.x 23:33: [xxl_job]> analyze table xxl_job_log;
+---------------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+---------------------+---------+----------+----------+
| xxl_job.xxl_job_log | analyze | status | OK |
+---------------------+---------+----------+----------+
1 row in set (0.06 sec)
root@10.xx.xx.x 23:33: [xxl_job]> desc SELECT id FROM `xxl_job_log` WHERE !( (trigger_code in (0, 200) and handle_code = 0) OR (handle_code = 200) ) AND `alarm_status` = 0 ORDER BY id ASC LIMIT 1000;
+----+-------------+-------------+-------+------------------------------------------------------------+-----------------+---------+------+---------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------------+-------+------------------------------------------------------------+-----------------+---------+------+---------+------------------------------------+
| 1 | SIMPLE | xxl_job_log | range | I_handle_code,idx_xxl_job_log,idx_alarm_status_handle_code | idx_xxl_job_log | 1 | NULL | 1430862 | Using index condition; Using where |
+----+-------------+-------------+-------+------------------------------------------------------------+-----------------+---------+------+---------+------------------------------------+
1 row in set (1.57 sec)再来回顾一下表结构,看到idx_xxl_job_log索引只包含alarm_status单列,属于冗余索引了,因此我们这里直接将idx_xxl_job_log索引删除(8.0版本可以设置为不可见)
root@10.xx.xx.x 23:29: [xxl_job]> show create table xxl_job_log\\G
*************************** 1. row ***************************
Table: xxl_job_log
Create Table: CREATE TABLE `xxl_job_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
...
PRIMARY KEY (`id`),
KEY `I_trigger_time` (`trigger_time`),
KEY `I_handle_code` (`handle_code`),
KEY `idx_xxl_job_log` (`alarm_status`),
KEY `idx_alarm_status_handle_code` (`alarm_status`,`handle_code`,`trigger_code`),
KEY `idx_trigger_time` (`trigger_time`,`handle_code`,`trigger_code`),
KEY `index_0` (`job_id`,`trigger_time`)
) ENGINE=InnoDB AUTO_INCREMENT=63213303 DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
root@10.xx.xx.x 23:34: [xxl_job]> alter table xxl_job_log drop index idx_xxl_job_log;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
root@10.xx.xx.x 23:34: [xxl_job]> desc SELECT id FROM `xxl_job_log` WHERE !( (trigger_code in (0, 200) and handle_code = 0) OR (handle_code = 200) ) AND `alarm_status` = 0 ORDER BY id ASC LIMIT 1000;
+----+-------------+-------------+-------+--------------------------------------------+------------------------------+---------+------+------+------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------------+-------+--------------------------------------------+------------------------------+---------+------+------+------------------------------------------+
| 1 | SIMPLE | xxl_job_log | range | I_handle_code,idx_alarm_status_handle_code | idx_alarm_status_handle_code | 5 | NULL | 1633 | Using where; Using index; Using filesort |
+----+-------------+-------------+-------+--------------------------------------------+------------------------------+---------+------+------+------------------------------------------+
1 row in set (0.00 sec)到这里执行计划终于是走对了,于是我们修改了全局eq_range_index_dive_limit为1来关闭index dive。调整后CDB表现如何
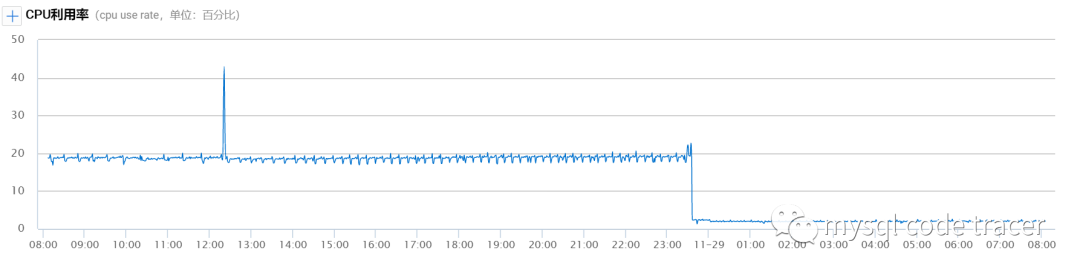
可以看到CPU使用率有一个明显的下降,总体来说效果还是不错的
再来说一下为什么之前在判断原因的时候我一下就想到了eq_range_index_dive_limit呢?因为在之前好几次问题诊断中,我都遇到过类似的情况,由于开启了index dive以后,导致了优化器并没有选择正确的索引或者说选择了正确的索引,但是走的扫描方式不正确,这种情况尤其在5.6版本和超大表中出现。其中有一次我做了trace,range扫描部分结果如下:
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "idx_c2c_um_coupon_activity_uid_dt",
"ranges": [
"57175354 <= uid <= 57175354"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 27034,
"cost": 32442,
"chosen": true
},
{
"index": "idx_uid_is_show_status",
"ranges": [
"57175354 <= uid <= 57175354 AND 1 <= is_show <= 1 AND 1 <= status <= 1 AND 1592893827 <= end_time"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 12,
"cost": 15.41,
"chosen": true
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
},
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "idx_uid_is_show_status",
"rows": 12,
"ranges": [
"57175354 <= uid <= 57175354 AND 1 <= is_show <= 1 AND 1 <= status <= 1 AND 1592893827 <= end_time"
]
},
"rows_for_plan": 12,
"cost_for_plan": 15.41,
"chosen": true
}
}很明显可以看到这里优化器在进行代价估算的时候使用了index_dives_for_eq_ranges,所以我就往这个方向研究了一下。
关于索引统计信息
统计信息分为持久化统计和动态统计,由参数innodb_stats_persistent控制
持久化统计
- 启用持久化统计信息,修改超过10%数据就要更新
- 动态自动统计,修改1/16数据就要更新
- innodb_stats_method控制统计信息针对索引中NULL值的算法当设置为nulls_equal所有的NULL值都视为一个value group;当设置为nulls_unequal每一个NULL值被视为一个value group;设置为nulls_ignore时,NULL值被忽略
- 执行show table status、show index,访问I_S.TABLES/STATISTICS视图时更新统计信息
动态统计
-
innodb_stats_persistent=0
-
统计信息不持久化,每次动态采集,存储在内存中,重启失效(需重新统计),不推荐
-
innodb_stats_transient_sample_pages
-
动态采集page,默认8个
-
每个表设定统计模式
-
CREATE/ALTER TABLE … STATS_PERSISTENT=1,STATS_AOTU_RECALC=1,STATS_SAMPLE_PAGES=200;
-
mysql -auto-rehash
总结
- 这是一个非典型案例,如果有经验的情况可能可以快速找到问题,由于我之前有过多次的经历所以处理起来比较快,大家以后碰到类似的情况可以往这个方面尝试寻找原因
- 碰到这种超大表,优化器又使用到范围扫描的情况下,不妨可以使用trace来进行诊断看看是不是由于index dive导致的,在我的印象中5.7几乎没有出现过
- 当怀疑统计信息不对的情况下,可以尝试重新收集统计信息,甚至可以加大sample_pages,例如可以收集20个page或者更多