CKV+异地容灾探索和实践
今天跟大家分享的题目为《CKV+异地容灾探索和实践》。CKV+是一个兼容redis协议的内存数据库,现在大部分用户对内存数据库的要求越来越高,对一致性、异地容灾等方面也提出更高的要求。下面从过往经验教训、可用性&一致性、CKV+架构演进、CKV+单活多可用区和CKV+多活架构探索等方面跟分享一些关于容灾的实践和思考。
01 过往的经验教训
2016年亚马逊的CTO发表了一篇文章,总结了过去十年亚马逊云服务的经验教训,其中第二点就讲到接受一切的故障,“故障总是意料之外,情理之中发生”。确实是这样子,在过去几年,CKV+也出现过包括主机故障、磁盘写满、流量突发、机房网络中断等方面引起的一些故障。在故障层面,涉及主机级、机架级,可用区级,以及机房级等都各种各样不同的故障。对于城市级的故障,印象比较深的是,在2015年,天津机房附近的天津滨海新区危险品仓库发生大爆炸,导致天津数据中心岌岌可及,大量业务需要做迁移。所以,故障总是不可预料的,但不管是天灾还是人祸,需要我们是要对不同的容灾级别做一些处理,这也是今天我们主要讨论的内容。
02 CKV+数据可用性&一致性的探索和思考
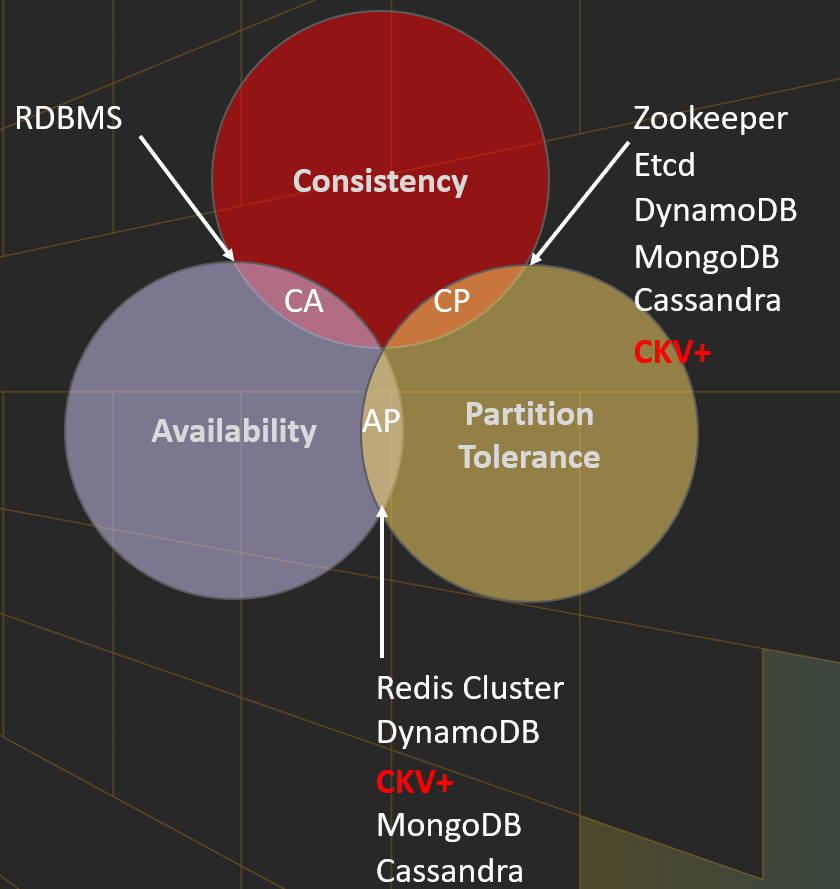
CKV+作为一个内容数据库,在容灾级别的探索上,数据可用性和一致性需要做怎么样的考虑或取舍,有几个点我们必须要先考虑的。第一,数据如何分布;第二,数据同步算法;第三,读写分离/异地多活等如何考虑?
大家都知道,CAP理论包含一致性、可用性和分区容忍性,这三点不能完全满足,只能同时满足其中两项。现有系统可能会区分为一个CA,或者AP,或者CP等。对于分布式系统来说,数据一定是分布式存储的,因此“分区容忍性”这一点是必须要满足。数据分布算法一般有hash算法,一致性hash,基于范围,以及hash+范围混合算法。hash和范围混合算法是将数据通过hash算法拆分为足够多的分片(编号0~n),每一个node负责一段连续的区间,是比较常用的分布算法,例如redis-cluster。ckv+也同样使用这种算法进行数据分布式分布。
在数据可用性和一致性上,CKV在默认的情况下,主要考虑性能,跟redis类似,使用类似的异步复制算法。在master故障的时候,slave可能无法保证数据跟master完全一致(可能丢失最近的一段日志),无法保证故障场景的强一致性,属于一个AP系统。但现在主流的NoSQL数据库,如dynamoDB,MongoDB,Cassandra等,支持可调一致性,既支持AP场景,也支持CP场景。因此,对于一些客户来说,也是希望CKV+也能够在高性能上做一些取舍,损失一定性能,支持强一致性能力。所以,我们在未来架构演进过程中,需要考虑如何实现多种一致性来满足不同用户的要求,同时也考虑不同的容灾级别。
03 CKV+架构演进
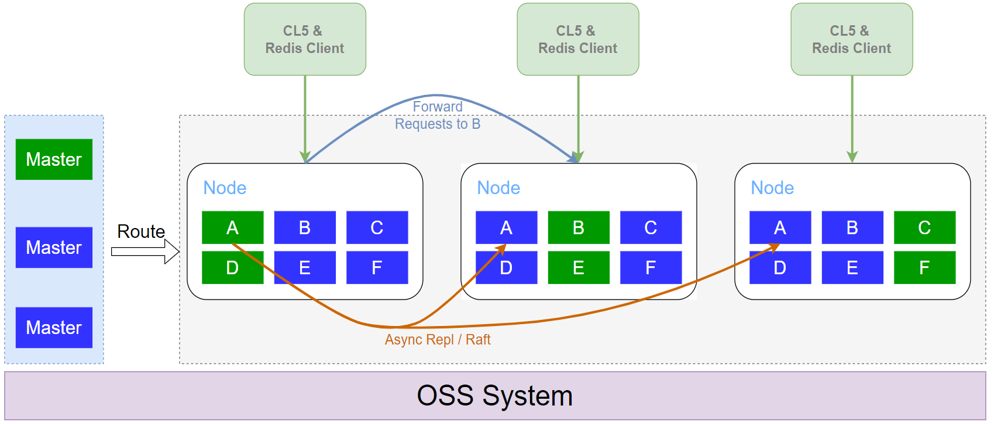
上图是CKV+架构,有以下特点:
- 接入层与存储层合并。跟一般的NoSQL不同的是,CKV+是没有接入层的,严格来说,应该是接入层和存储层合并了。一个Redis Client通过名字服务访问任意一个Node,如果数据分布在本节点,可以直接执行,减少一次接入层到存储层的转发,从而降低延时。如果数据分布到其他节点,这个Node会将请求forward到正确的Node中,充当接入层的角色。由于没有接入层,整体成本更低,延时也更低。
- 原生多租户。一个Node上,会管理多个用户实例的多个分片。在上图中可以看到,每个Node都负责部分实例的部分主分片(绿色),也负责部分备分片(蓝色)。由于不同用户实例的负载是不同的,主备分片的负载和压力也是不同的,目前的多租户设计可以充分的利用资源,提高资源的利用率。
- 基于seastar高性价无锁架构。CKV+基于seastar架构实现,每一个分片利用了其share-nothing的设计,会绑定到一个核上处理,这样就不用考虑单个分片的并发问题,无需引入锁。同时,利用seastar的bypass kernel能力,极大限度地避免了context switch, 用户态内核态切换,内存拷贝等浪费,从而提升整体性能。
- 多线程网络IO。虽然,单个分片绑定到单个核上,可以充分利用了单核能力,但对于QPS性能要求很高的情况下,网络IO会占用较多资源。CKV+是一个多线程结构,网络IO可以交给其他空闲核处理,从而提高单分片的吞吐能力。
- 在主备分片复制算法上,既支持了异步复制,也支持raft强一致算法。在默认情况下,ckv+会异步将主分片的增量日志通过异步方式同步到备分片中,实现主备分片的最终一致性,满足高吞吐低延时的访问要求。另外,ckv+内部也支持raft算法,确保备分片数据同步后再返回,保证数据主备分片一致性。
总体上,CKV+在架构设计上,是希望充分的压榨单机的性能,在追求极致性能的同时控制成本。
然而,基于CKV+原架构的特点,在容灾和性能平衡方面还有一些难点和问题。首先,数据和日志耦合性大。无论是异步还是raft复制,复制流程与当前的操作主流程耦合,尤其是raft实现,维护代价比较大。第二,repication占用资源较多。复制模块目前占用现有资源比例不低,特别时在写流量特别大的情况下,它占用的资源会比较多,在一定程度上影响了单核的性能。并且默认主分片的日志通过流的方式直接同步给备分片,但当备分片故障时或者网络短暂异常,日志是需要落盘的,这就会影响到主分片的性能,毛刺会更明显。第三,cache node无法处理大量日志。当前Cache Node一般使用内存容量较大的机型,对日志的落地存储空间和性能要求不高,是没有办法存大量的日志的。这就面临着备分片长时间断开后的断点续传,以及备份回档功能等较难落地,数据安全性上面同样面临挑战。所以,在用户对一致性强要求和容灾级别提出新的要求的情况下,我们提出了一个新的架构。
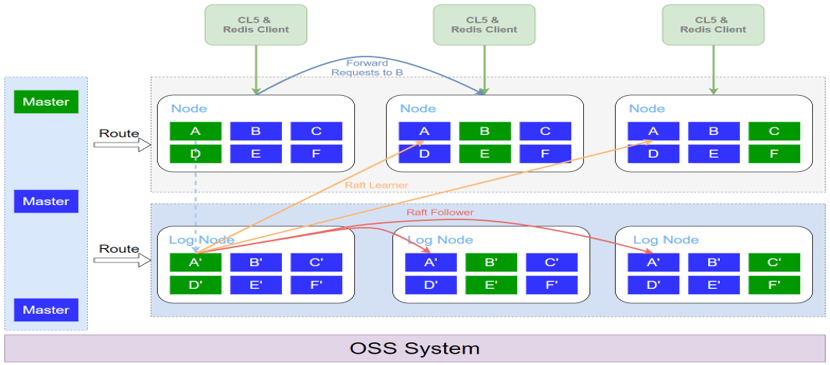
从以上图示看,对比于原架构,新架构有以下特点:
- 新增日志模块,实现数据和日志的解耦。将日志模块独立成一个服务,并且是基于raft的强一致日志存储。Node节点主要关心核心数据操作流程,增量日志只需通过RPC调用同步到日志服务即可,无需关心日志的持久化和同步问题,日志服务会自动解决这些问题。
- 故障处理更简单。每一个分片会组建一个raft group,Node的主分片无需处理replication,只需向对应的raft group提交增量日志即可,备分片会作为raft group的learner。当主分片发生故障,备分片只需保证将raft log执行完毕,就可以提升为master。当日志模块的master或着备分片发生故障,备分片基于raft算法能自动选主并且同步日志,解决故障或者网络瞬断等情况的复制异常问题。这样都可以简化整体故障处理流程,同时能保证数据不丢失。
- 成本控制更灵活。日志模块独立出来后,可以使用更灵活的机型,例如一些ssd类型的机型(内存较少,磁盘空间较大),成本更低。同时,日志模块能存储更多的日志,实现强一致性和持久化能力。并且数据模块和日志模块的副本数可以不一样,例如Node一主一备,日志模块一主两备,结合不同可用区/城市的部署关系,能够更灵活的控制整体成本。
- 其他高级特性更容易实现。得益于CKV+日志的解耦,理论上可以支持获取任意时刻的日志。例如PITR(Piont-in-Time Recovery),Change Data Capture等就比较容易实现了。同样的,异地多活也可以基于这个架构进行扩展,下面会详细描述。
04 CKV+单活多可用区异地容灾实践
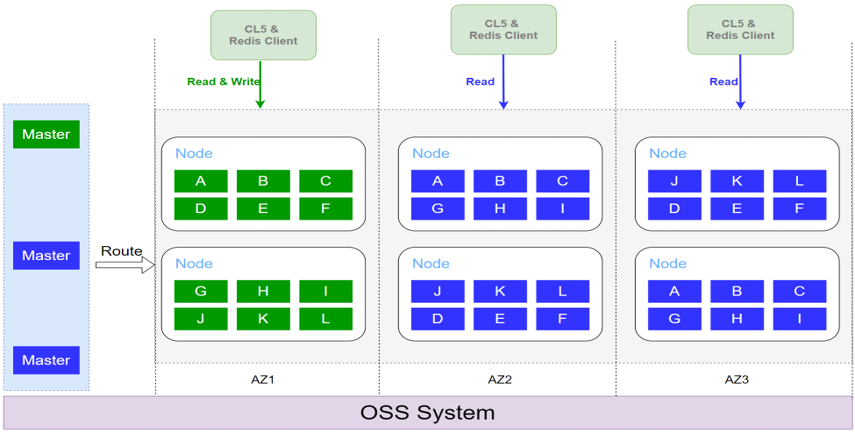
CKV+为了满足不同的容灾要求,已上线了单活多可用区特性,支持不同容灾级别:
- 单可用区:机架级容灾能力。
- 同地域多可用区:机架、可用区级容灾能力。
- 跨地域多可用区:跨城际容灾。
默认的情况下,CKV+的容灾级别是跨机架容灾,保证主备分片必须跨机架,避免一个机架掉电导致主备分片都不可用的问题。如果希望更高的容灾级别,可以选择同地域多可用区以及跨地域多可用区,当然这样可能导致的访问和主备延时会更大。在不同的级别上,容灾对于性能和成本其实是一个很微妙的关系。如果你需要更高的容灾级别,那么可能就需要牺牲一点性能和提高一点成本。
当然,CKV+在多可用区特性上,额外做了以下优化:
- 对于同一个CKV+实例,主分片部署在一个可用区。客户也会尽量将client部署在主可用区,从而获得同一个可用区的低延时访问。
- 备可读特性。其他可用区的备节点可以提供读能力,提高整体的读吞吐能力。
- client就近访问。不同可用区的client可以自动访问到就近的节点进行访问,对用户透明。
CKV+在故障的探测和切换上,目前的逻辑上副本所在节点连续两三个周期不可达(默认周期是2秒),就会进行一些判死,并经过第三方server二次确认仍然不可达就可进行切换,RTO目前是6~10s。不过,主备分片切换会导致可用区的变化,如原来分片1是a可用区的,切换后会变成b可用区,这个分片的访问延时很可能会变大。因此,CKV+在触发主备分片切换后,会尽快在原主可用区重建一个新副本,重建完后会自动执行分片的可用区调整,恢复主可用区的低延时访问。
05 CKV+多活架构异地容灾探索
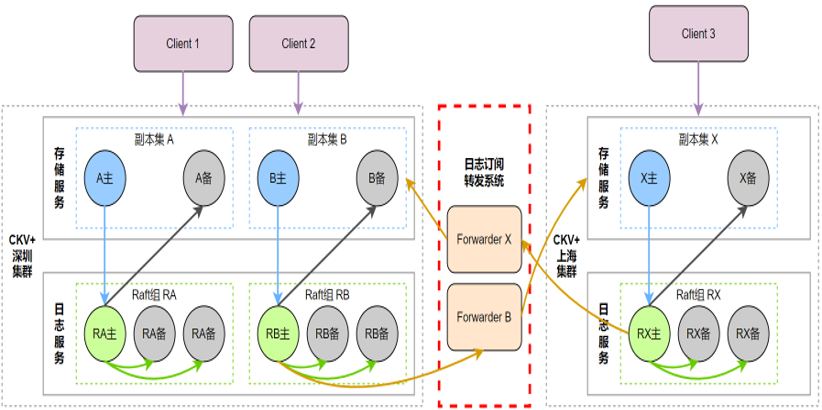
异地单活虽然提供了不同的容灾级别,甚至不同可用区提供了读能力,但只能在主可用区执行写操作。跨城延时一般在10~50ms级别,如果部署在上海的client希望对深圳集群执行写操作,网络延时将极大地影响性能。这个时候,应用希望总是以就近方式写入集群,多地的数据支持互相同步,并且解决一致性问题。这也是CKV+异地多活架构需要解决的问题。
CKV+多活架构存在着一些特点:首先,它是一个多城部署、就近读写访问,最终一致的形态。其次,将日志模块和存储服务分开,日志模块保障稳定可靠的日志服务。第三,新增日志订阅转发模块,并作为日志模块的raft learner(非DTS)节点,同时把增量日志同步到跨城集群中。第四,CKV+新架构衍生于存储和日志解耦的架构,对架构的入侵少。 基于CKV+的新架构,可解决以下场景的问题。第一,跨城容灾,每个城市都有一份完整的数据,即使发生城市级的灾难,数据和服务都能得到有效的保证。其次,边缘分布,就近提供最近端的服务,就近读写,性能会达到最高。另外,异地多活方案同样适用于未来跨云部署的方案。例如公有云A和公有云B都部署了各自的CKV+集群和Forwarder模块,Forwarder模块只需向另一个云端集群同步增量日志即可,解决跨云同步的问题,为实现多云数据访问创造可能。 CKV+新架构的优点和使用场景非常明显,但在实现过程中也存在着一些难点。主要包括:
- 环路复制检查。这里的重点需要保证保障复制不要形成环路,不要重复消费。
- 日志幂等处理,冲突解决。CKV+会对数据和日志进行深度定制,实现幂等的记录级日志,同时通过vector lock等机制来解决多地数据冲突的问题。
- 低延迟复制。目前所有节点的复制都是基于raft,raft算法可以基于pipeline和批量的方式来提升效率,降低延时。另外,日志订阅模块收到raft日志后,可以通过并行和批量执行等方式来增大整体吞吐,从而降低多地集群的同步延时。
- 故障处理。多活比较主流的做法是基于dts+mq机制来实现,这个做法其实是存在一些问题和挑战的,例如模块出现故障,需要选择从新的组里处理,在日志层面进行断点、续传等行为,这些都是非常麻烦的事情。但目前基于raft learner的方式,故障处理的难度将会大大降低。
- 扩缩容处理。数据分片扩容,就是将分片A的部分slot迁移到分片B。CKV+扩分片机制是snapshot加增量日志的模式,这样就有可能在不同的raft group中有两段相同的增量日志,需要一定的策略来处理这些相同的日志。
异地多活是CKV+ 2022年上线最重要的新特性之一,会基于数据和日志分离的架构继续演进,预计2022年5月能上线,敬请期待。