得物 iOS 工程演进之路
正文
大家好,我是来自得物 iOS 架构组的 Casa。今天想和大家分享一下得物这两年以来的 iOS 的工程演进,希望能给处在演进阶段的工程师带来一些新的启发。
工程演进规划
首先需要说明的是,我认为,有架构师的团队,和没有架构师的团队,工程演进方向是不一样的。
- 有架构师的团队:会对工程有规划,当遇到演进阶段的“分叉口”时,会有一个比较清晰的目标,决定接下来该往哪走。
- 没有架构师的团队:野蛮生长,业务需要什么添加什么。那么我首先来给大家分享一下,得物的工程规划一般是怎么做的?目前得物将工程演进分为了三个阶段:工程化、组件化以及容器化。
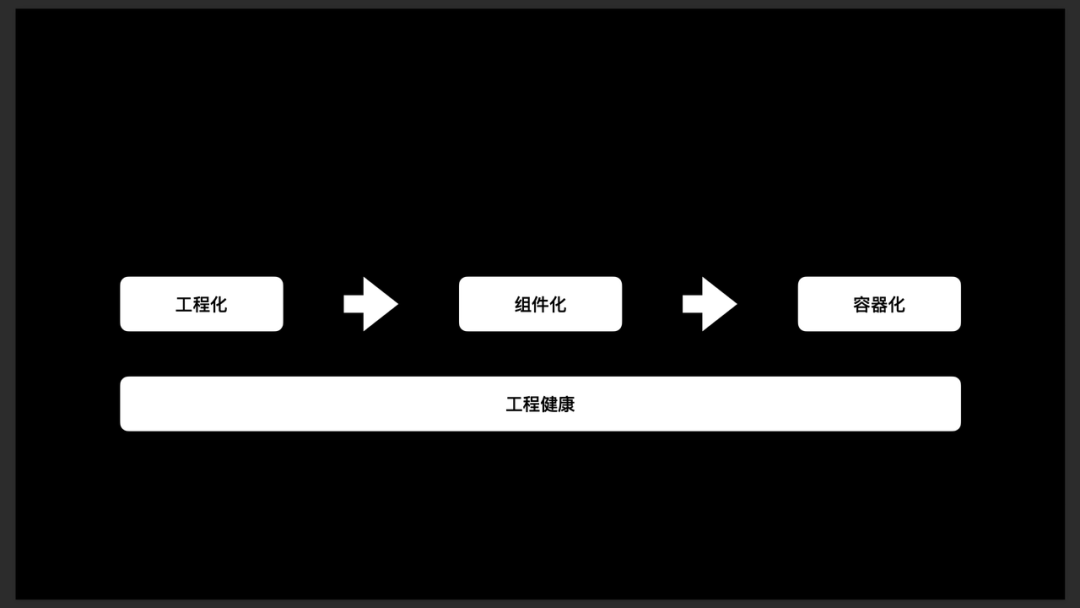
- 工程化:
- 定义:为项目搭建一系列的周边工具,打通 CI / CD 流程。
- 解决的问题:解决标准操作流程(SOP) 的问题。
2 . 组件化:
- 定义:将项目打碎并拆分成若干个组件组成的项目,以面向组件的方式进行开发。
- 解决的问题:解决工程业务复杂的问题。
3 . 容器化:
- 定义:利用拆分的组件,在快速满足业务需求的同时,尽量少地提升项目复杂度,同时以面向构件的方式进行开发。
- 解决的问题:解决组件复用性的问题。
- 需要注意的是,此处定义的“容器化”,是站在组件化的基础上实现的,与 Flutter、React Native、Weex、WebView 容器的概念有所区分。集成了上述容器技术的的应用,是具备容器能力的,但这并不代表工程是容器化的。
同时,工程健康是需要贯穿整个演进阶段的。接下来我会先来分享工程健康上,得物所做的优化,再来探讨项目工程化、组件化、容器化等演进阶段。
工程健康
工程健康主要包含:包体积治理、Crash 治理、启动流程治理等三项。对于部分资源充裕的项目,可能还会关注电量损耗、图片加载时长、API 请求时长等。
包体积大小治理
随着业务扩展,得物用了 2 - 3 个版本从 250M 上升到 350M,为了减少包大小,得物做了如下实践。

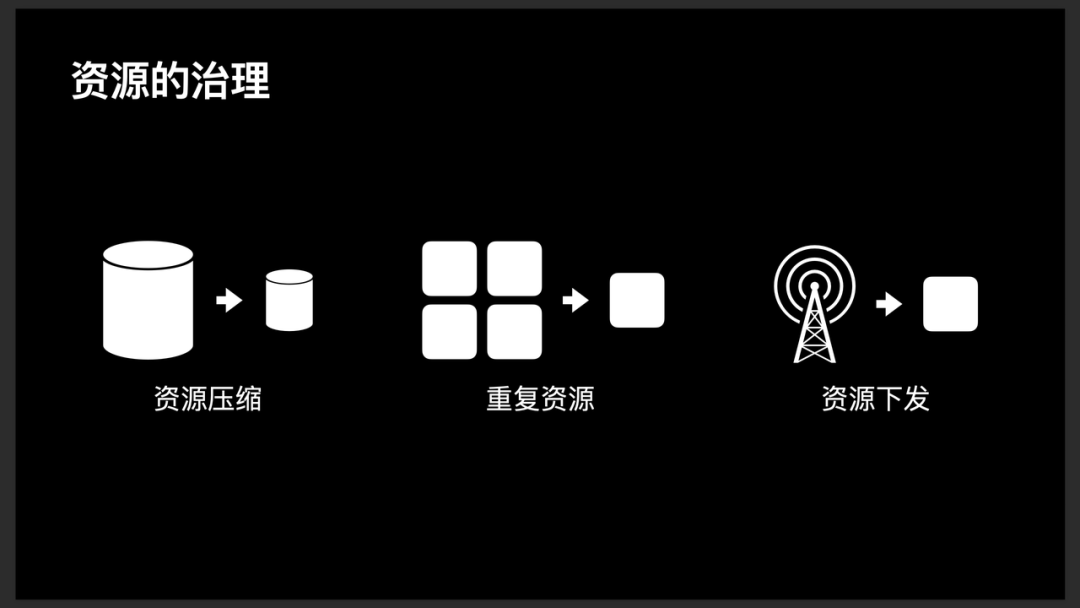
- 资源压缩:
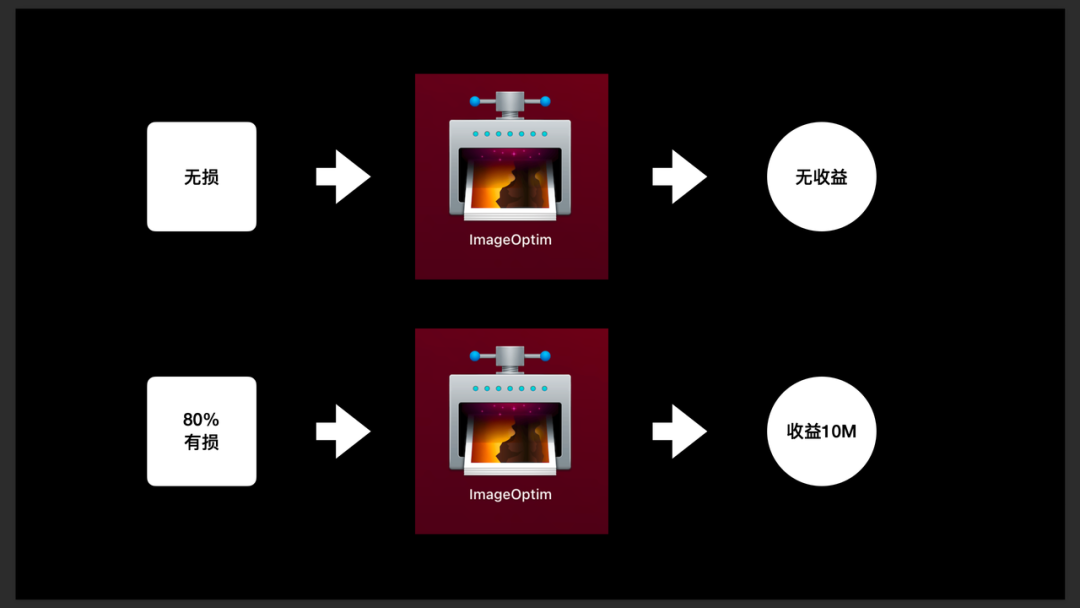
- 第一阶段:尝试使用 ImageOptim 进行无损压缩,但是发现毫无收益,原因是因为 Xcode 已经帮我们进行了无损压缩。
- 第二阶段:使用了 80% 的有损压缩,对于部分特殊图片,还可以选择更高的有损压缩。(此处得物工程获得了 10M+ 的收益)。

- 重复资源合并:由于组件化的存在,每个组件可能会存在自己使用到的图片,导致大量相似、甚至重复图片存在。这里得物分几个阶段进行了优化。
- 第一阶段:使用脚本扫描出重复资源,然后手工对资源进行合并。
- 第二阶段:实现了脚本合并。在编译结束时,针对资源计算 MD5,然后确认相同 MD5 资源的数量,若存在多个,则移除相同的冗余资源。同时为了让大家都使用相同的资源,我们对
imageNamed:等方法进行封装 / Hook,将传入的资源名字处理成 MD5,然后再进行资源的搜索。这样可以解决多组件使用相同资源的问题。 - 第三阶段:使用机器学习找出相同相似资源。除了 MD5 一样的资源,还有很多相似的资源是可以进行优化的。我们通过机器学习脚本找出所有的相似图片,对高相似度的资源进行脚本合并,相似度较低的交由业务线进行确认后再进行合并。
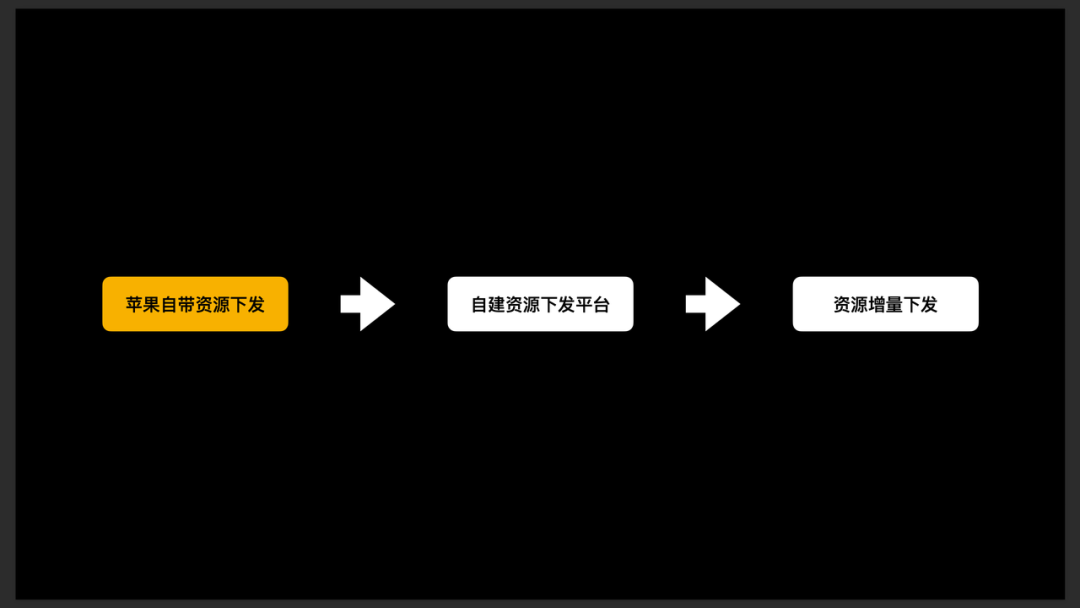
- 资源下发:
- 第一阶段:使用苹果 SKDownload 功能,但该功能更适合关卡类的游戏。对于得物的电商场景,由于没有关卡概念,也没有办法预测用户执行上下级页面的路径,所以这里只能将所有的下级资源全都下载,没有起到特别大效果 。
- 第二阶段:自建资源下发平台。每个版本对应一个资源包。eg:1.0.0 的版本,对应 1.0.0 的资源包;2.0.0 的版本,对应 2.0.0 的资源包。客户端通过“资源管理器”访问资源,如果资源没下载好,则访问 CDN 进行下载(非重要图片资源处理)。对于比较大的动画 / AR 资源,若未下载好,则使用图片资源进行业务逻辑的降级兜底。
- 第三阶段:资源增量下发,只下载新版本新增资源。(对于资源下发平台,得物此块获得了大概 3 - 4 倍的提升)
代码的治理可以分为以下几个方向:
- 三方库裁剪:
- 无用代码移除:
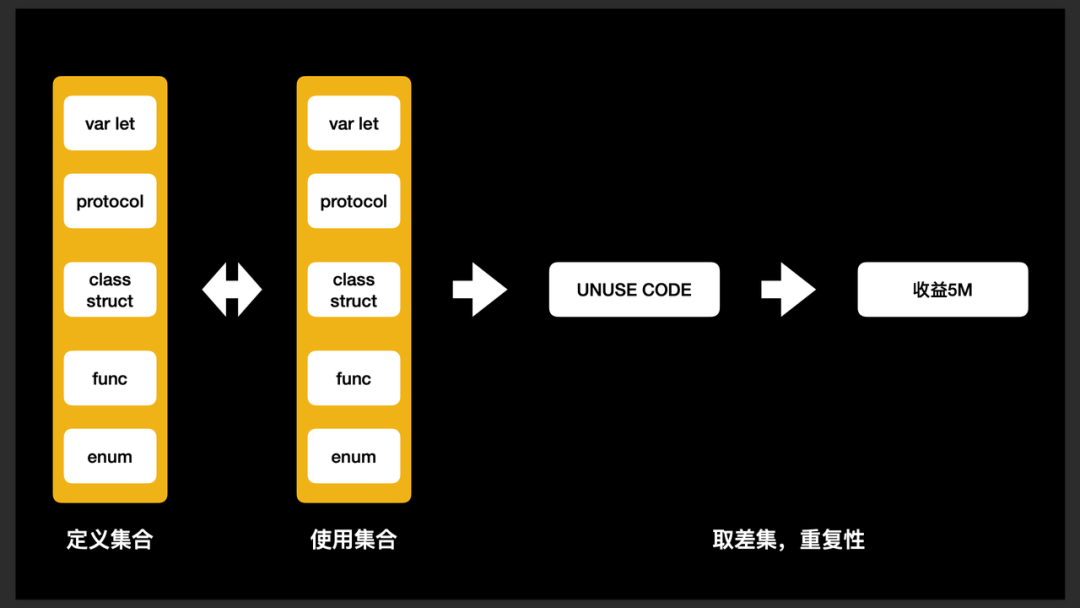
- 重复代码合并
找由于复制粘贴产生的重复代码,然后抽出中间组件,各组件对中间组件进行依赖实现。
经过上述资源层面及代码层面的优化,得物工程包体积从 350M 下降至 250M,包体积下降 28.5%。
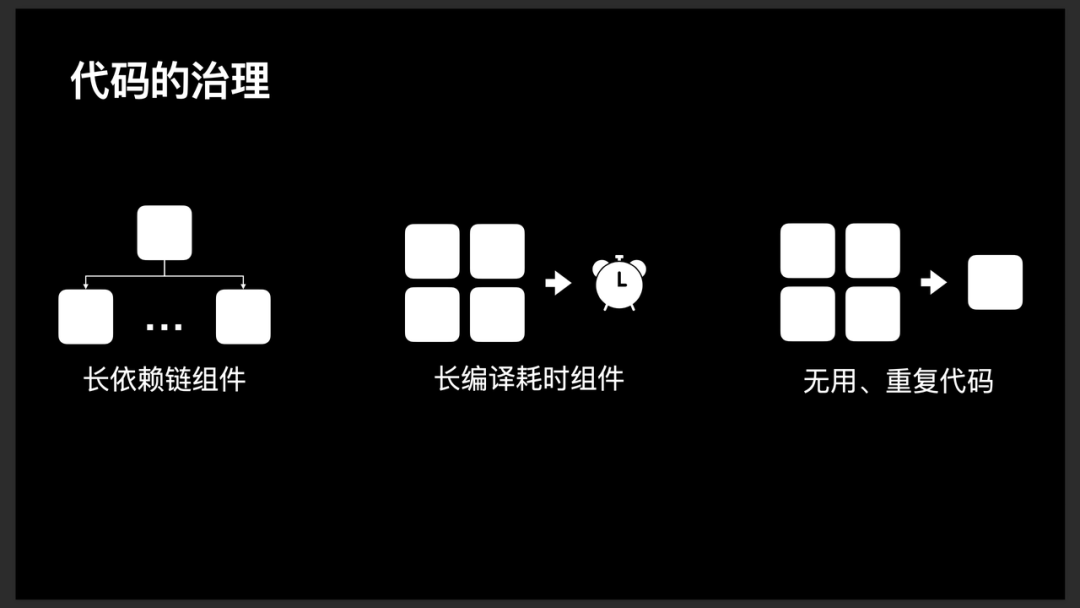
工程代码治理
-
长依赖链组件:部分项目中会存在组件依赖链过长的情况,如 A -> B -> C -> D(此处 "->" 代表依赖状态)。这样会导致使用 A 组件的时候,必须同时引入 B、C、D 组件。我们认为长依赖组件的出现是不合理的,是没有合理区分纵向依赖与横向依赖导致的。针对这部分内容的处理,需要调整依赖方式。
-
纵向依赖:直接依赖代码,通过 Pod Dependency 进行依赖。
-
横向依赖:通过组件调度的方式进行间接依赖,无需直接依赖代码。
-
长编译耗时组件:当新组件仅需使用大组件的小功能时,直接依赖了大组件,会导致新组件开发时,开发、编译成本变大。针对这部分内容,需要将大组件再次进行拆分成若干小组件进行处理。
-
无用、重复代码:此块内容已在包体积大小治理中阐明,不再赘述。
Crash 治理
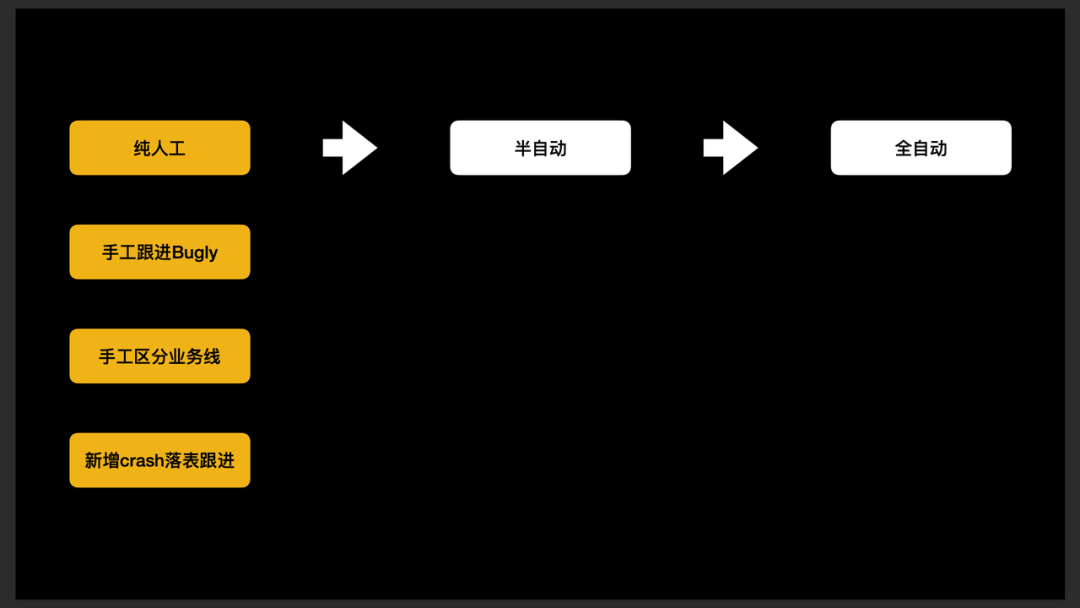
- 纯人工阶段:使用 Bugly Crash 管理系统,手工确认 Crash 后分给具体的业务线,同时人工跟进问题修复情况。
- 半自动化阶段:使用脚本爬 Bugly 信息(包括 Crash Stack 信息),然后自动识别业务线并自动落表。
- 全自动化阶段:由于 Bugly 是每小时统计一次 Crash 数据,所以有可能出现数据滞后的问题。为此我们重新搭建了 Crash 平台,去做自动化收集、解析、告警的事情,同时实现自动跟进修复情况。
启动流程治理
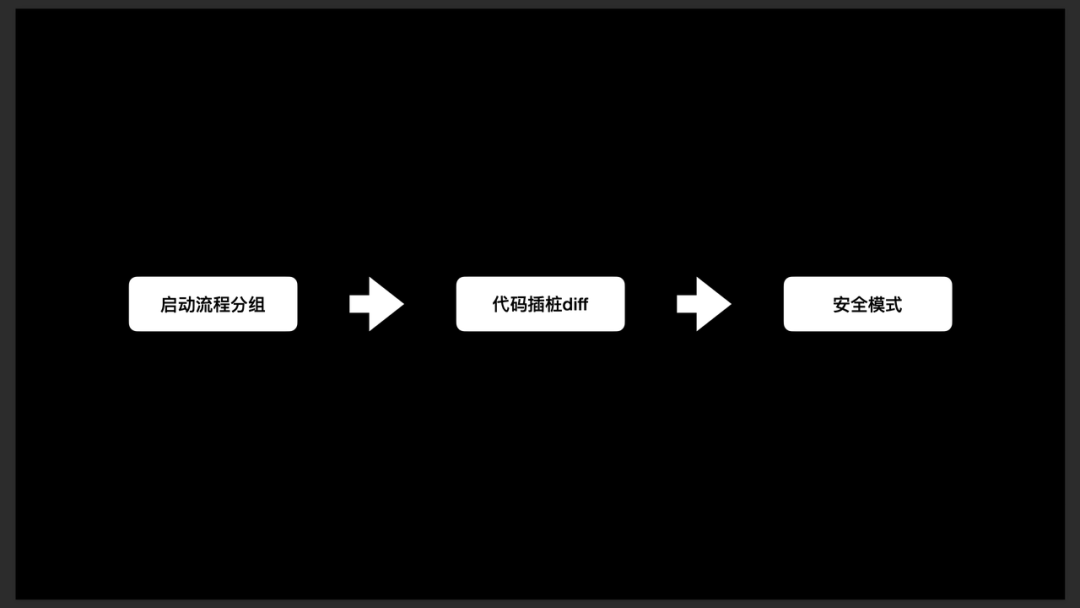
- 启动流程分组:将代码按业务线分块并标注,用以确定每条业务线所占的时长,随后可根据该指标治理部分业务线大幅增长的不合理情况。
- 代码插桩 diff:编译时,进行代码插桩。然后将新旧包代码插桩数据对比,当新增代码调用时,能够及时发现调用链的变化,用于确保调用链必要且合理。
- 安全模式:假设某个组件没有正常完成工作(如 DB 迁移、A / B Test 数据获取),可以进入安全模式,通过 Hook RunLoop 并尝试重启,以避免应用崩溃。
工程化
围绕组件化的基础设施
需要注意的是,工程化的基础设施,需要随着组件化、容器化阶段不停调整。并不是意味进入组件化后,工程化就不用继续,而是进入组件化后,工作重点主要放在组件化,但仍需投入精力调整优化相关的基础设施。
结合得物场景,主要围绕组件化实现了以下命令行工具,用以提供业务同学的开发效率:

- 组件创建脚本、组件工具:解决创建、管理组件的问题。
- 组件发版工具:解决组件发版的问题。
- 二进制调试工具:解决二进制组件调试问题。
- 组件上游依赖查询工具:解决组件依赖查询问题。
- 编译成功节点切换工具:解决“出包难”的问题。
- 裙带源码组件切换工具:解决 ARC 不对齐的问题。
后文会结合具体场景说明工具作用。
组件管理(包含组件创建、发版等组件工具)
区别于其他公司,得物没有使用在 Podfile 中定义版本号的方式。主要因为得物工程中组件较多(组件数量超 1430+),平均每隔 4.8 分钟发版一次(日均发版 100+)。如果使用 Podfile,会意味着每当组件发版,Podfile 都需要修改版本号,继而会产生大量的 Podfile 文件冲突。同时,得物也经常存在多组件联合发版的问题,这样依赖上游需要同时调整多个组件版本号,存在较大的沟通成本。
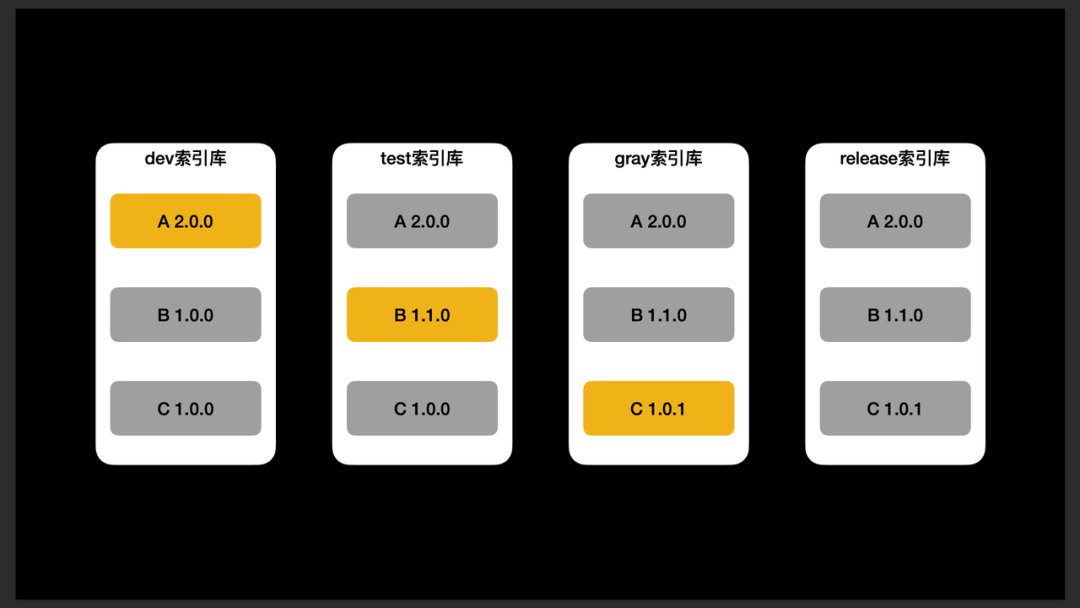
- 开发环境:使用 dev 索引库,规定组件发布新版本时,仅变更版本号的第一位,就像 A,从 1.0.0 变为 2.0.0。
- 沙盒环境:使用 test 索引库,规定组件发布新版本时,仅变更版本号的第二位,就像 B,从 1.0.0 变为 1.1.0。
- 灰度环境:使用 gray 索引库,规定组件发布新版本时,仅变更版本号的第三位,就像 C,从 1.0.0变为 1.0.1。
- 现网环境:使用 release 索引库,规定组件不能发布新版本。
不同环境使用不同的 Git 仓库,且 Podfile 中固定了每个组件当前环境的仓库地址(所以切换环境时,需要调整 Podfile 中的 Source,并处理不同环境 git upstream 的合并)。仓库环境的拆分,避免了新版本开发影响到已有版本逻辑。
二进制(包含二进制调试工具、组件上游依赖查询工具、裙带源码组件切换工具)
-
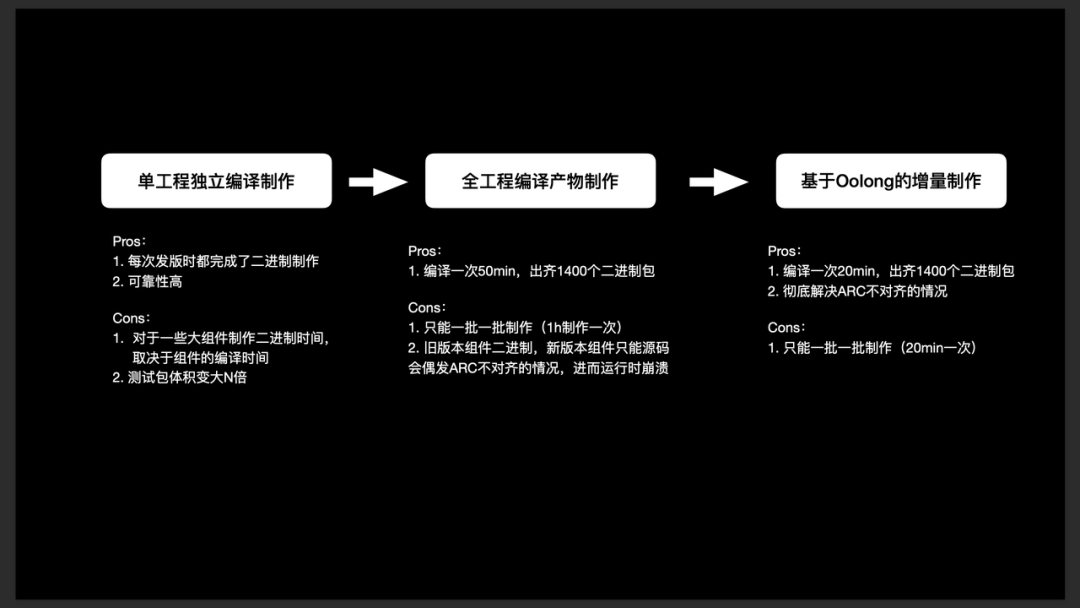
单工程独立编译制作:
-
优点:组件发版时完成二进制制作;可靠性高。
-
缺点:组件制作二进制时长取决于组件规模,大组件制作仍旧耗时;存在大量组件需要做二进制,单光算编译时长,需要 5 天制作;出现测试包体积变大。
-
全工程编译产物制作:利用编译缓存,从 Xcode 编译缓存 DerivedData 中取出组件。
-
优点:每 50min 完成 1400+ 二进制制作。
-
缺点:只能分批制作(1h / 次);存在 ARC 不对齐的情况。
-
ARC 不对齐:A 组件已经是二进制(在编译时加入 ARC),B 组件使用源码编译,此时再次编译(编译器会为 B 会添加 ARC,但不会对 A 组件进行处理,有可能导致 ARC 不对齐引发内存被提前释放,导致 EXC_BAD_ACCESS Crash)。为了解决该问题,在做二进制时,需要对新发版的组件做裙带组件源码切换:将其上游一级、下游一级的组件变成源码依赖而非二进制依赖。
-
基于 Oolong 的增量制作,Oolong 是得物开发的脚本(即上文中提到的裙带组件源码切换工具),能够将一个组件的上一级和下一级依赖的组件变为源码参与编译:
-
优点:彻底解决 ARC 不对齐;每 20 min 可以完成 1400+ 二进制制作。
-
缺点:只能分批制作(20 min / 次)。
最终,得物完成基于 Oolong 的增量制作。需要说明的是,得物不追求所有工程都是二进制,原因是开发工作一般以小时计,20min 的二进制编译时长已经能相对满足需求。
持续交付(包含编译成功节点切换工具)
得物工程较大,存在多人(100+)同时开发、多组件同时发布的情况。并且,为追求效率,我们没对组件进行编译验证,导致有时候,出一个“可用”的包比较困难。为了解决该问题,我们进行了如下方案。
-
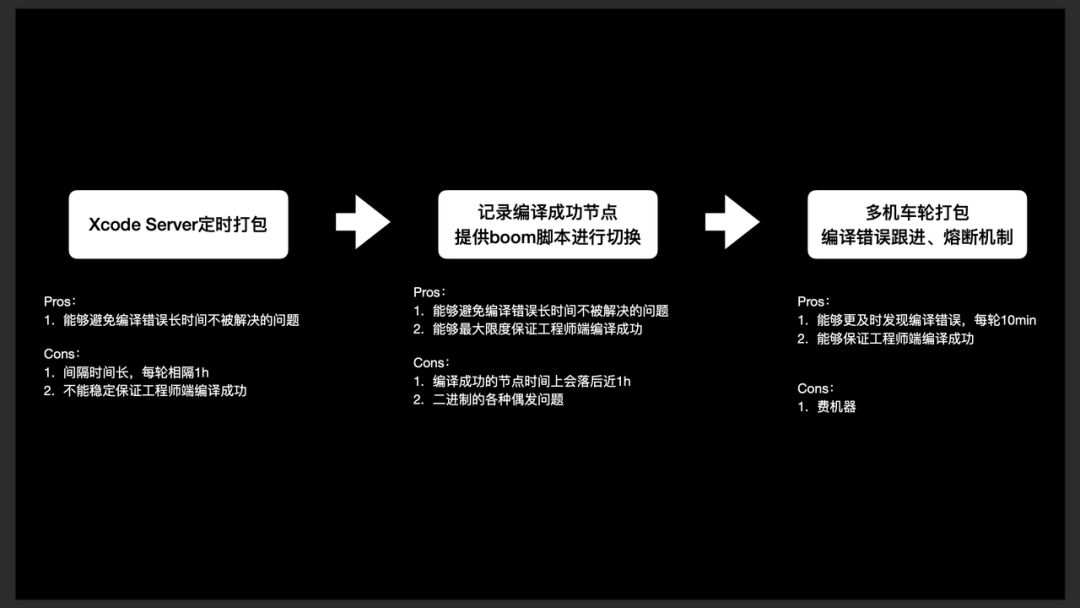
Xcode Server 定时打包:CI 机定时打包。
-
优点:能够避免编译错误长时间不被解决的问题。
-
缺点:不保证编译成功,且每轮编译时长较长,相隔 1h 才能获得编译结果;但 CI 机编译成功不代表开发端编译一定能成功,对新人不友善。
-
记录编译成功节点并提供脚本(“Boom”)用以切换:执行脚本后,将代码切换至当前分支最后一次编译成功节点。
-
优点:能够避免编译错误长时间不被解决的问题;能够最大限度保证开发端代码编译成功。
-
缺点:编译成功节点落后近 1h;由于开发的组件一定是源码,若使用二进制编译,会造成 ARC 不对齐引起的各种偶发问题。
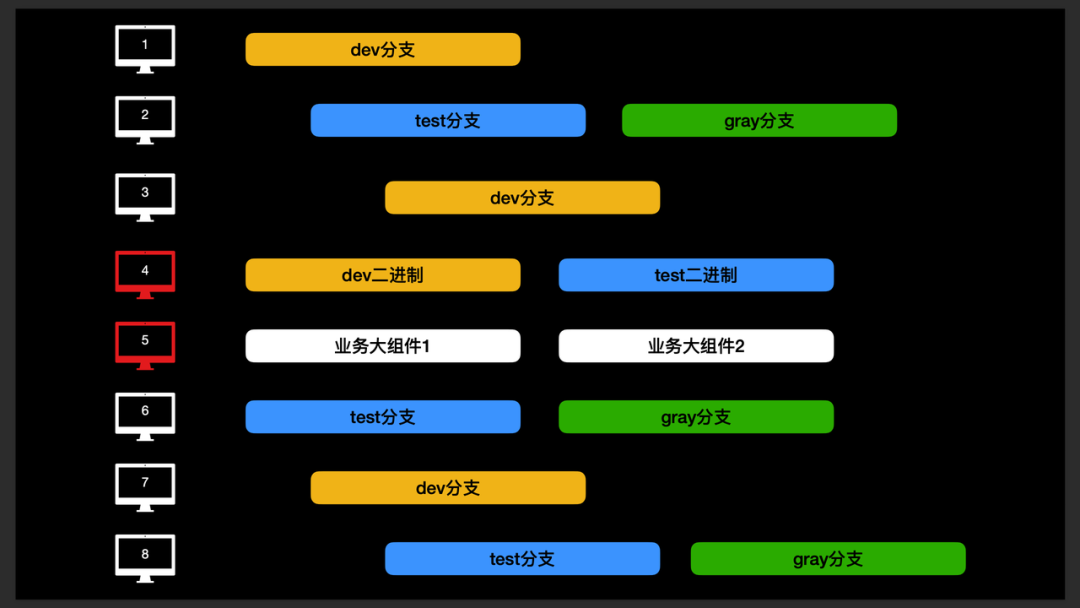
- 多机车轮打包:使用大量机器持续构建不同环境的包(如上图示)。
- 优点:能够及时发现编译错误,每轮 10 min;能够最大限度保证开发端代码编译成功。
- 缺点:需要较多机器资源。
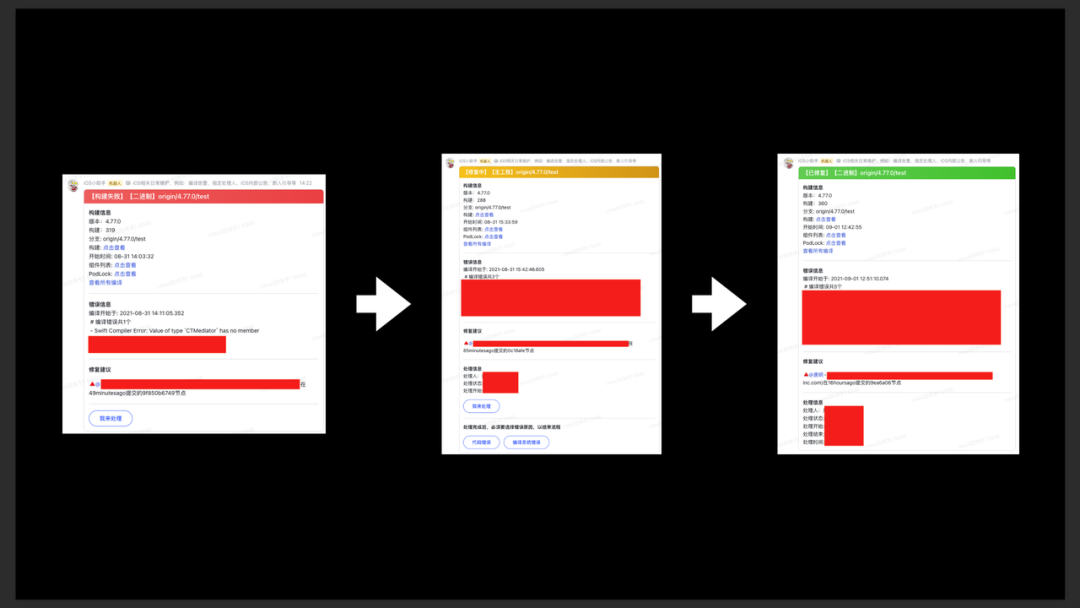
- 若出现构建失败,则自动提醒引发失败的工程师(一次构建可能包含多个不同的工程师,此时提醒该组工程师)进行处理。
- 若工程师开始排查,可点击“我来处理”,“飞书卡片”状态会发生变化,变为“修复中”状态。
- 若修复完成,会展示“飞书卡片”会展示“已修复”状态。
组件化
IPO 模型


**“IPO”模型是指:输入、处理、输出三者中,只要其中两者正确,剩余一者必定正确。**该模型的指导意义在于指导我们如何做组件化拆解和组件设计。
- 我们在做组件化拆解时,需要定义清楚这个组件的 Input。
- 我们在做组件化拆解时,需要确保组件的代码是正确的,也就是说 Process 是正确的。
- 在确定 Input 已经定义清楚,且 Process 是正确的情况下,我们可以不必关心 Output,因为根据 “IPO”模型,只要 Input 和 Process 是正确的,Output 就一定是正确的。
“IPO”模型指导了我们做组件拆分的重点:将 Input 定义清楚,且确保 Process 代码正确。
在 CTMediator 方案体系下,OC Category / Swift Extension 的目的就是要保证 Input 是定义清楚的;剩余只需保证组件能够正确执行,即 Process 是正确的。那么 Output 就一定正确。如此一来,一个组件就是完整正确的。一个工程中只要每个组件都是完整正确的,那么这个工程就是完整正确的。
为什么不使用基于注册的组件化方案
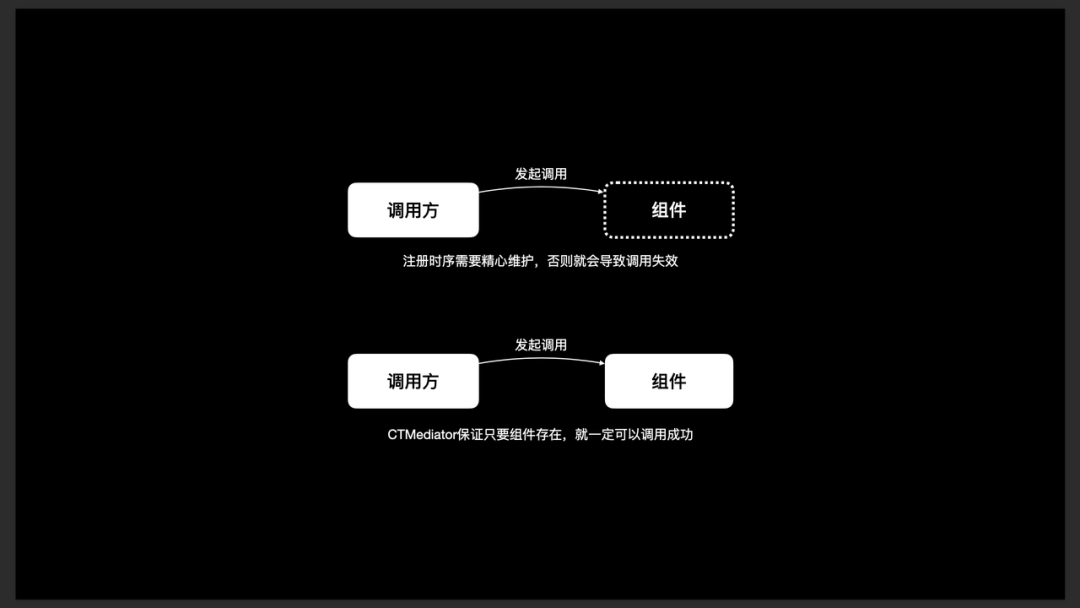
- 使用注册:又可分为 URL 注册 / Protocol 注册。
- 不使用注册:基于 Target-Action 及 Runtime:类 CTMediator 方案。
目前注册类方案存在管理注册时序、大量注册实例造成无用内存消耗、大量注册代码造成的时间损耗等问题,对于这些问题,我们可以使用各种“补丁逻辑”(例如直接将注册 URL 注入 mach_O 文件等)来解决。但若使用类 CTMediator 方案,则无需考虑类似问题,也就不需要去做“补丁逻辑”。
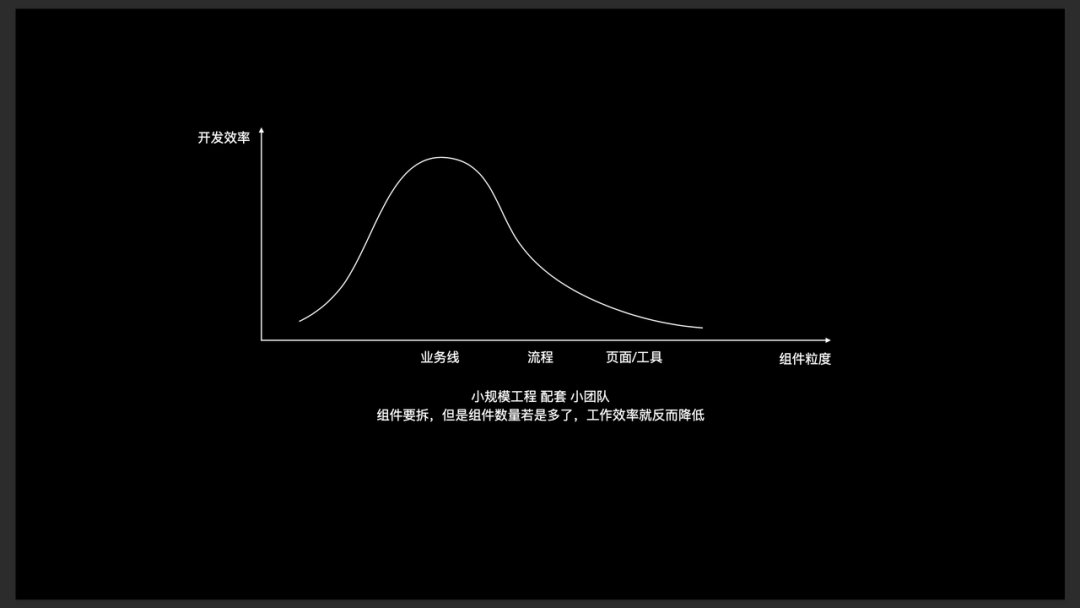
组件拆分粒度
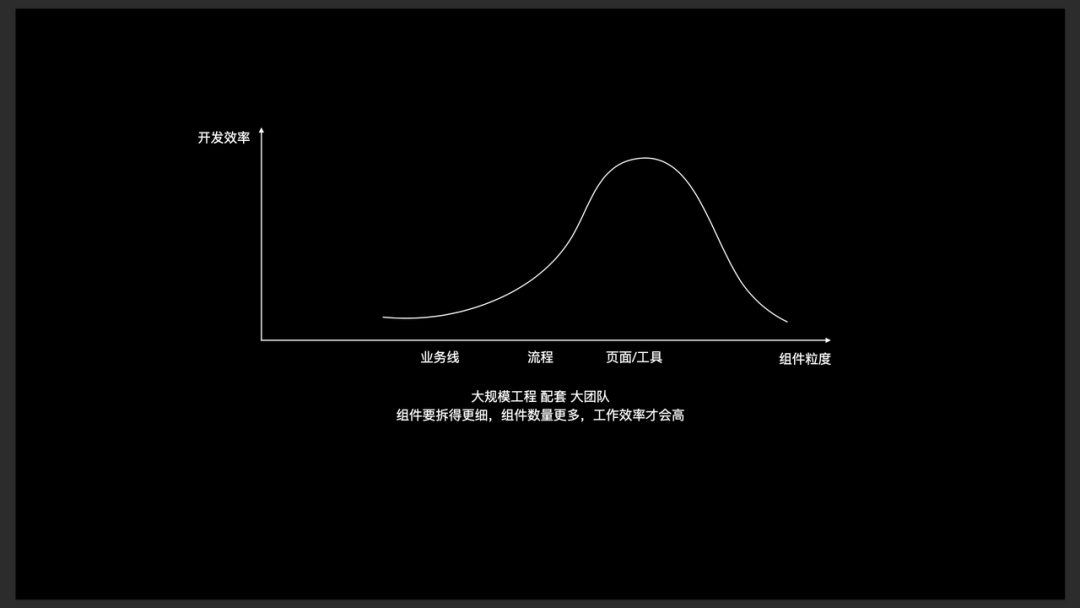
业界针对组件拆分粒度有不同的认知,因此也就会存在不同的讨论。这些讨论如果脱离了当前的业务阶和团队发展阶段,是没有意义的。在不同的阶段下,组件拆分粒度是不一样的。
小规模业务和团队
小规模业务和团队(5人以内):此时应以业务线为维度拆分组件,拆分出几个组件即可,大多数情况下是 3 - 5 个。如果此时不做组件化、或拆分过多组件,工作效率都会降低。
中等规模业务和团队
中等规模业务和团队一般在 10 - 20 人左右,此时应以流程为维度拆分组件,组件数量大约在十几个到数十个不等。如果还保留之前小规模阶段的粒度或者拆得太细,工作效率就都不太理想。
大规模业务和团队
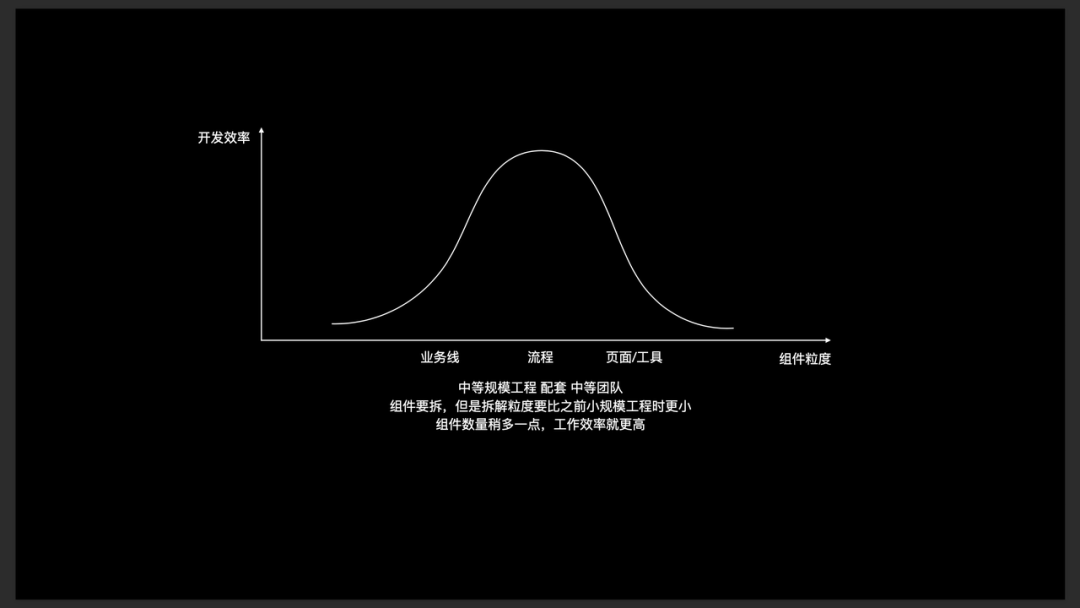
在大规模业务和团队下,工程师规模可能近百甚至几百,业务线越来越大。产品经理的数量也变得很多,需求越来越细。可能一个流程就是一个产品经理在提需求,一个业务线中有好几个产品经理去提需求是十分常见的情况。
那么,此时对应到我们的工程中,组件的拆解粒度也要更细,可能就要细到一个页面就是一个组件,一个工具就是一个组件。这样才能达到理想的工程效率。在这样的工程规模和组件粒度下,注册类的组件化方案可能就无法做到很好的支持。一方面注册会很消耗时间,另一方面,每拆一个组件就要对应要注册一个内容,提高了组件拆分的成本。
我们在进行架构设计的时候,要充分的考虑未来团队及工程的成长速度及成长规模,需要为工程设计一个合理的组件化方案。如果随着团队规模扩张,小问题再次变成大问题,没有真正的实现化整为零,则该组件化方案的价值就不大了。
- 由于产品需求很细,当我们做到组件的颗粒度也很细时,每次迭代需求中的修改范围就能够做到很小,修改范围小了,需要考虑的连带关系就少了,工作效率就能得到提高。
- 在这种规模的业务和团队情况下,我们会发现,整个工程的分层概念已经没有意义了。我们转而需要关注的是组件的依赖关系是否合理,需要做好纵向依赖和横向依赖的区分和管理;需要做到某一个条线或者某一个功能,都能够在自己的工程里进行独立编译、测试。
- 虽然分层概念在整个工程的范围中已经失去了意义,但分层概念其实已经下沉到了某个条线或者某个功能中。我们把某个条线或者某个功能理解为一个“组件群”,在这个组件群中,是可以落实分层的概念的。
好的架构没有 Common 没有 Core,也不应该有大组件的存在
为什么不允许存在公共模块
有 Common / Core 时,意味着有那么一部分代码,其职责是不明确的。不明确职责的代码会造成代码未来难以维护,因此不是一个好的架构。
另外每人对 Common / Core 的认知不同,很可能会使得 Common / Core 变成一个公共垃圾堆,出现 “既然放哪里都不合适,那我就放 Common / Core 吧” 的情况。该垃圾堆持续增长,成为一座垃圾山,导致 Common / Core 未来无法维护。
在得物中,规定每个组件实现了什么功能,就是什么组件,不存在 “有关部门” 这一说。
为什么不允许存在大组件
原因是大部分功能的开发,其实仅需要大组件的其中一个功能,但为了实现该功能,却需要引入一个大组件。这种情况不仅导致代码维护复杂,还会导致这个小组件编译时长不合理地增多。此时更合理的做法应该是将大组件打散成若干个小组件,其他组件需要啥,就只依赖它需要的那部分。我们认为一个大组件应该是由若干个小组件组成,而不是一个大组件由很多功能的代码拼成。
Argument List Too Long
Argument List Too Long 指的是 Xcode 代码编译基本完成后,在执行工程 Build Phases 中的 Run Script 时 / 编译时突然停止。


- 合并 Header Search Path、Library Search Path 到一个文件夹:建立专用文件目录,将相关数据迁移至该专用目录,然后在 Xcode 中设定该目录。
- 合并 ModuleMap 到一个文件:需要注意的是,Xcode 要求我们提供 ModuleMap 文件路径(而非文件夹路径),所以这里关键在于如何合并 ModuleMap 文件。由于 ModuleMap 编译时才产生,所以得物在编译 Pre Action 时,将其他 ModuleMap 内容合并至当前 DerivedData 路径下的 ModuleMap,同时设定 Xcode 读取的 ModuleMap 文件路径。
容器化
随着工程的成长和业务复杂度的提升,我们一路从工程化、组件化走来,最后走向容器化。在这个过程中,容器化在一定程度上引入了动态性,但动态性并不是工程的容器化阶段真正要解决的问题。
容器化真正解决的问题是改变工程的开发模式:容器化将工程师从业务、页面的开发,转而变成页面上某个小卡片小功能的开发,再由容器根据规则,将这些小卡片组装成为页面。
从组件化走向容器化是一个自然而然的过程,容器化并不是凭空出现的,容器化是基于上一个阶段组件化的组件积累,逐步整合出来的。在得物,容器化还是基于 CTMediator 实现的,这意味着很多我们在组件化阶段已积累的组件,是可以在容器化过程中直接使用的。
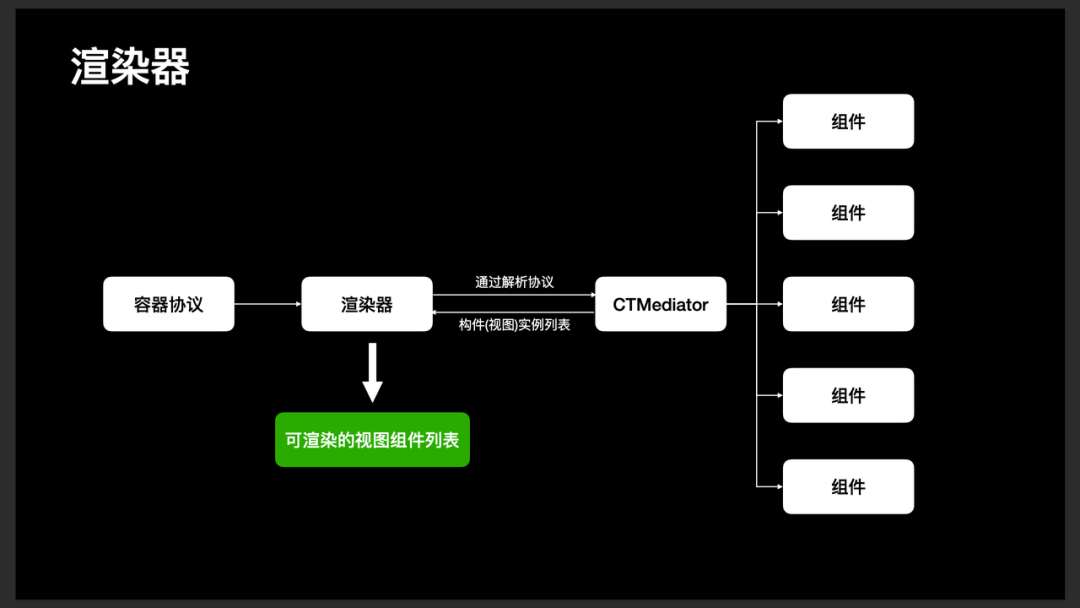
视图渲染
事件通信
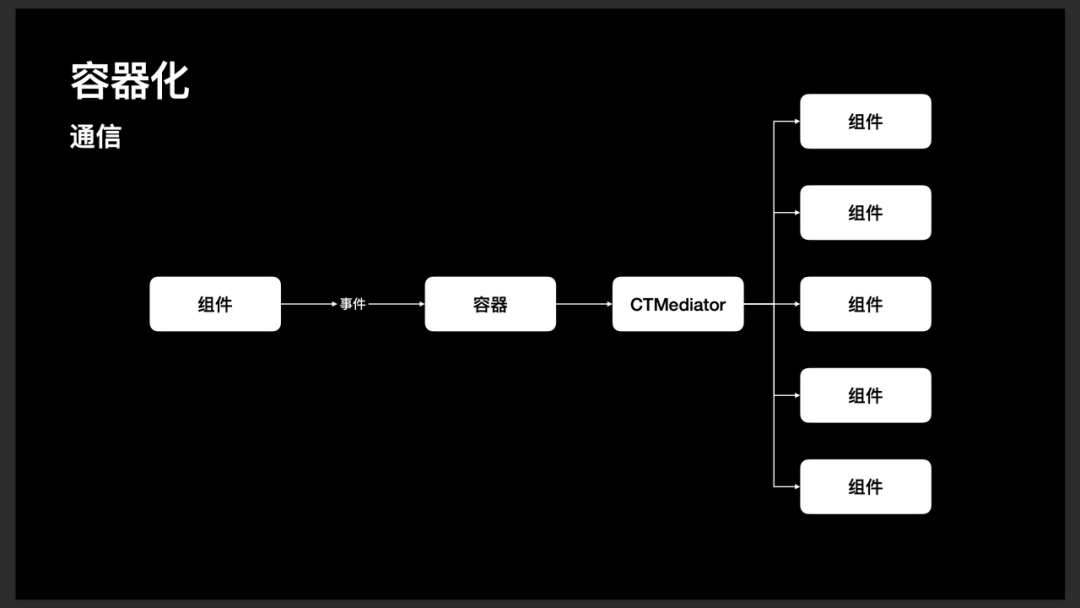
除此之外,我们认为以命令模式来描述一个事件更为合理。因为在该模式下,我们告诉了开发者实现事件所有的充要条件。由于命令模式与 CTMediator 的 Target-Action 设计是一样的体系,因此容器化使用 CTMediator 进行实现则显得十分自然。

此处再次重申,使用 WebView、Flutter、React、Weex 等容器技术搭建的工程,是具备了容器能力的工程。但在我个人看来,这并不意味着这个工程进入了容器化阶段。容器化阶段毕竟还是要从组件化逐步成长而来,利用组件化已有的体系和组件,针对已有的页面进行容器化的升级。
应用

总结
工程化、组件化一直是 iOS 业界日久不衰的话题之一。本次分享中,Casa 为我们分享了得物 App 如何在工程演进的过程中,逐渐落地工程化、组件化,并复盘了在落地过程中的遇到的困难以及后续的方案迭代。除此之外,Casa 还提出了更深层次的“容器化”思想,能够帮助我们在落地组件化之后,更好的面向构件开发。