哪个程序经得起这样的优化?
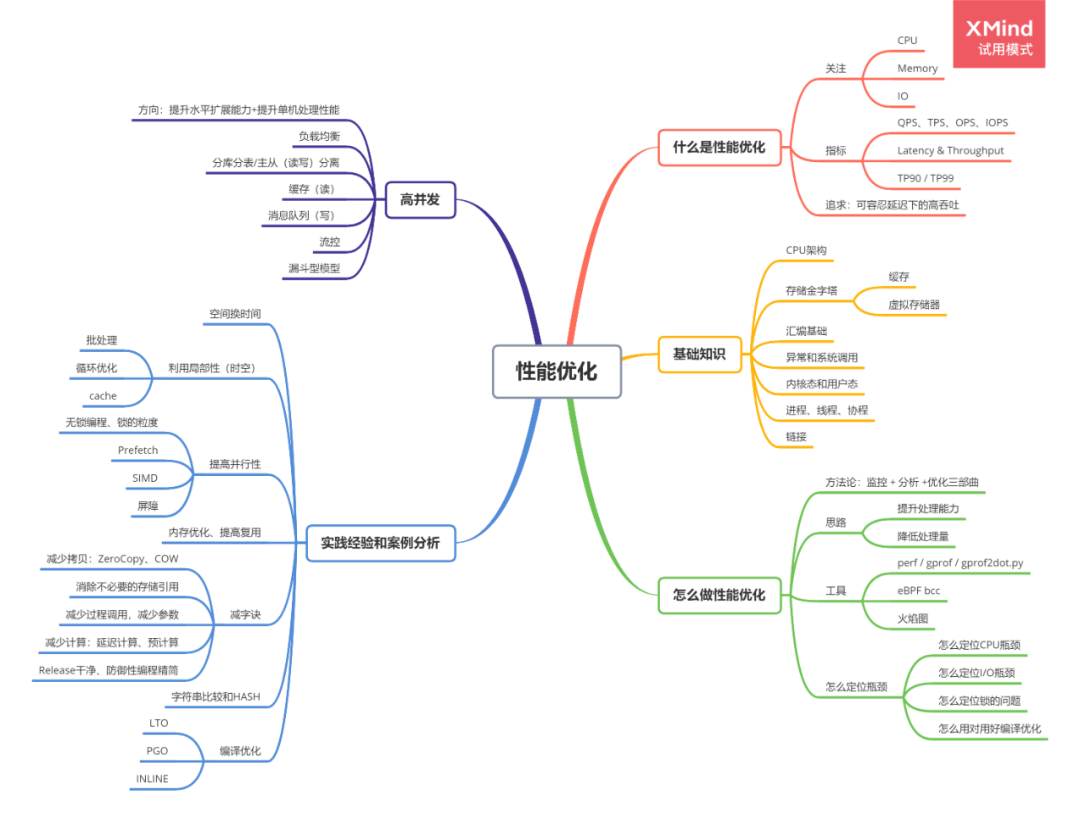
# 一、思维导图
# 二、什么是性能优化? 性能优化指在不影响系统运行正确性的前提下,使之运行得更快,完成特定功能所需的时间更短,或拥有更强大的服务能力。
## 关注
不同程序有不同的性能关注点,比如科学计算关注运算速度,比如游戏引擎注重渲染效率,而服务程序追求吞吐能力。
服务器一般都是可水平扩展的分布式系统,系统处理能力取决于单机负载能力和水平扩展能力,所以,提升单机性能和提升水平扩展能力是两个主要方向,理论上系统水平方向可以无限扩展,但水平扩展后往往面临通信成本飙高(甚至瓶颈),单机处理能力下降的问题。
## 指标
衡量单机性能有很多指标,比如:QPS(Query Per Second)、TPS、OPS、IOPS、最大连接数、并发数等评估吞吐的指标。
CPU为了提高吞吐,会把指令执行分为多个阶段,会搞指令Pipeline,同样,软件系统为了提升处理能力,往往会引入批处理(攒包)等,但跟CPU流水线会引起Latency增加一样,伴随着系统负载增加也会导致延迟(Latency)增加,可见,系统吞吐和延迟是两个冲突的目标。
显然,过高的延迟是不能接受的,所以,服务器性能优化的目标往往变成:追求可容忍延迟(Latency)下的最大吞吐(Throughput)。
延迟(也叫响应时间:RT)不是固定的,通常在一个范围内波动,我们可以用平均时延去评估系统性能,但有时候,平均时延是不够的,这很容易理解,比如80%的请求都在10毫秒以内得到响应,但20%的请求时延超过2秒,而这20%的高延迟可能会引发投诉,同样不可接受。
一个改进措施是使用TP90、TP99之类的指标,它不是取平均,而是需确保排序后90%、99%请求满足时延的要求。
通常,执行效率(CPU)是我们的重点关注,但有时候,我们也需要关注内存占用、网络带宽、磁盘IO等,影响性能的因素很多,它是一个复杂的问题。
# 三、基础知识
能编写运行正确的程序不一定能做性能优化,性能优化有更高的要求,这样讲并不是想要吓阻想做性能优化的工程师,而是实事求是讲,性能优化既需要扎实的系统知识,又需要丰富的实践经验,只有这样,你才能具备case by case分析问题解决问题的能力。
所以,相比直接给出结论,我更愿意多花些篇幅讲一些基础知识,我坚持认为底层基础是理解并掌握性能优化技能的前提,值得花费一些时间掌握这些根技术。
## CPU架构
你需要了解CPU架构,理解运算单元、记忆单元、控制单元是如何既各司其职又相互配合完成工作的。
你需要了解CPU如何读取数据,CPU如何执行任务。
你需要了解数据总线,地址总线和控制总线的区别和作用。
你需要了解指令周期:取指、译指、执行、写回。
你需要了解CPU Pipeline,超标量流水线,乱序执行。
你需要了解多CPU、多核心、逻辑核、超线程、多线程、协程这些概念。
## 存储金字塔
CPU的速度和访存速度相差200倍,高速缓存跨越这个鸿沟的桥梁,你需要理解存储金字塔,而这个层次结构思维基于着一个称为局部性原理(principle of locality),它对软硬件系统的设计和性能有着极大的影响。
局部性又分为空间局部性和时间局部性。
### 缓存
现代计算机系统一般有L1-L2-L3三级缓存。
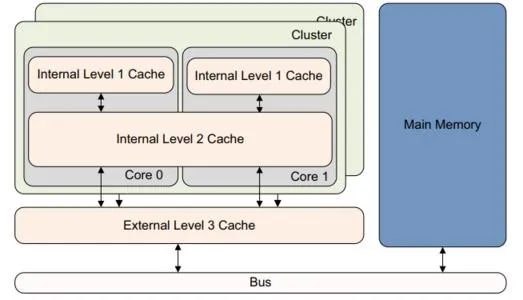
每个CPU核心有独立的L1、L2高速缓存,所以L1和L2是on-chip缓存;L3是多个CPU核心共享的,它是off-chip缓存。
L1缓存又分为i-cache(指令缓存)和d-cache(数据缓存),L1缓存通常只有32K/64KB,速度高达4 cycles。
L2缓存能到256KB,速度在8 cycles左右。
L3则高达30MB,速度32 cycles左右。
而内存高达数G,访存时延则在200 cycles左右。
所以CPU->寄存器->L1->L2->L3->内存->磁盘构成存储层级结构,越靠近CPU,存储容量越小、速度越快、单位成本越高,越远离CPU,存储容量越大、速度越慢、单位成本越低。
### 虚拟存储器(VM)
进程和虚拟地址空间是操作系统的2个核心抽象。
系统中的所有进程共享CPU和主存资源,虚拟存储是对主存的抽象,它为每个进程提供一个大的、一致的、私有的地址空间,我们gdb调试的时候,打印出来的变量地址是虚拟地址。
操作系统+CPU硬件(MMU)紧密合作完成虚拟地址到物理地址的翻译(映射),这个过程总是沉默的自动的进行,不需要应用程序员的任何干预。
每个进程有一个单独的页表(Page Table),页表是一个页表条目(PTE)的数组,该表的内容由操作系统管理,虚拟地址空间中的每个页(4M或者8M)通过查找页表找到物理地址,页表往往是层级式的,多级页表减少了页表的存储需求,命失(Page Fault)将导致页面调度(Swapping或者Paging),这个惩罚很重,所以,我们要改善程序的行为,让它有更好的局部性,如果一段时间内访存的地址过于发散,将导致颠簸(Thrashing),从而严重影响程序性能。
为了加速地址翻译,MMU中增加了一个关于PTE的小的缓存,叫翻译后备缓冲器(TLB),地址翻译单元做地址翻译的时候,会先查询TLB,只有TLB命失才会查询高速缓存(L1-2-3)。
## 汇编基础
了解汇编,了解几种寻址模式,了解数据操作、分支、传送、控制跳转指令。
理解C语言的if else、while/do while/for、switch case、函数调用是怎么翻译成汇编代码。
理解ebp+esp寄存器在函数调用过程中是如何构建和撤销栈帧的。
理解函数参数和返回值是怎么传递的。
## 异常和系统调用
异常会导致控制流突变,异常控制流发生在计算机系统的各个层次,异常可以分为四类:
中断(interrupt):中断是异步发生的,来自处理器外部IO设备信号,中断处理程序分上下部。
陷阱(trap):陷阱是有意的异常,是执行一条指令的结果,系统调用是通过陷阱实现的,陷阱在用户程序和内核之间提供一个像过程调用一样的接口“系统调用”。
故障(fault):故障由错误情况引起,它有可能被故障处理程序修复,故障发生,处理器将控制转移到故障处理程序,缺页(Page Fault)是经典的故障实例
终止(abort):终止是不可恢复的致命错误导致的结果,通常是硬件错误,会终止程序的执行。
## 内核态和用户态
你需要了解操作系统的一些概念,比如内核态和用户态,应用程序在用户态运行我们编写的逻辑,一旦调用系统调用,便会通过一个特定的中断陷入内核态,通过系统调用号标识功能,不同于普通函数调用,陷入内核态和从内核态返回需要做上下文切换,需要做环境变量的保存和恢复工作,它会带来额外的消耗,我们编写的程序应避免频繁做context swap,提升用户态的CPU占比是性能优化的一个目标。
## 进程、线程、协程
在linux内核中,进程和线程是同样的系统调用(clone),进程跟线程的区别:线程是共享存储空间的,每个执行流有一个执行控制结构体,这里面会有一个指针,指向地址空间结构,一个进程内的多个线程,通过指向同一地址结构实现共享同一虚拟地址空间。
通过fork创建子进程的时候,不会马上copy数据,而是推迟到子进程对地址空间进行改写,这样做是合理的,此即为COW(Copy On Write),在应用程序开发中,也有大量的类似借鉴。
协程是用户态的多执行流,C语言提供makecontext/getcontext/swapcontext系列接口,很多协程库也是基于这些接口实现的,微信的libco通过hook慢速系统调用(比如write,read)做到静默替换,非常巧妙。
## 链接
C/C++源代码经编译链接后产生可执行程序,其中数据和代码分段存储,我们写的函数将进入text节,全局数据将进入数据段,未初始化的全局变量进入bss,堆和栈向着相反的方向生长,局部变量在栈里,参数和返回值也会通过栈传递。
想要程序运行的更快,最好把相互调用,关系紧密的函数放到代码段相近的地方,这样能提高icache命中性。减少代码量、减少函数调用、减少函数指针同样能提高i-cache命中性。
内联既避免了栈帧建立撤销的开销,又避免了控制跳转对i-cache的冲刷,所以有利于性能。同样,关键路径的性能敏感函数也应该避免递归函数。
减少函数调用(就地展开)跟封装是相违背的,有时候,为了性能,我们不得不破坏封装和损伤可读性的代码,这是一个权衡利弊的问题。
## 常识和数据
CPU拷贝数据一般一秒钟能做到几百兆,当然每次拷贝的数据长度不同,吞吐不同。
一次函数执行如果耗费超过1000 cycles就比较大了(刨除调用子函数的开销)。
pthread_mutex_t首次加解锁大概耗时4000-5000 cycles左右,之后,每次加解锁大概120 cycles,O2优化的时候100 cycles,spinlock耗时略少。
lock内存总线+xchg需要50 cycles,一次内存屏障要50 cycles。
有一些无锁的技术,比如linux kernel里的kfifo,主要使用了整型回绕+内存屏障。
# 四、怎么做性能优化(TODO)
两个⽅向:提⾼运⾏速度 + 减少计算量。
性能优化监控先⾏,要基于数据⽽⾮基于猜测,要搭建能尽量模拟真实运⾏状态的压⼒测试环境,在此基于上获取的profiling数据才是有⽤的。
方法论:监控 -> 分析 -> 优化 三部曲
# 五、几个具体问题(TODO)
1. 如何定位CPU瓶颈?
2. 如何定位IO瓶颈?
3. 如何定位⽹络瓶颈?
4.如何定位锁的问题?
5. 如何提⾼并发能⼒?
大家都知道锁会引入额外开销,但锁的开销到底有多大,估计很多人没有实测过,我可以给一个数据,一般单次加解锁100 cycles,spinlock或者cas更快一点。
使用锁的时候,要注意锁的粒度,但锁的粒度也不是越小越好,太大会增加撞锁的概率,太小会导致代码更难写。
多线程场景下,如果cpu利用率上不去,而系统吞吐也上不去,那就有可能是锁导致的性能下降,这个时候,可以观察程序的sys cpu和usr cpu,这个时候通过perf如果发现lock的开销大,那就没错了。