玩转 ByteBuffer
为什么要讲 Buffer
首先为什么一个小小的 Buffer 我们需要单独拎出来聊?或者说,Buffer 具体是在哪些地方被用到的呢?
例如,我们从磁盘上读取一个文件,并不是直接就从磁盘加载到内存中,而是首先会将磁盘中的数据复制到内核缓冲区中,然后再将数据从内核缓冲区复制到用户缓冲区内,在图里看起来就是这样:
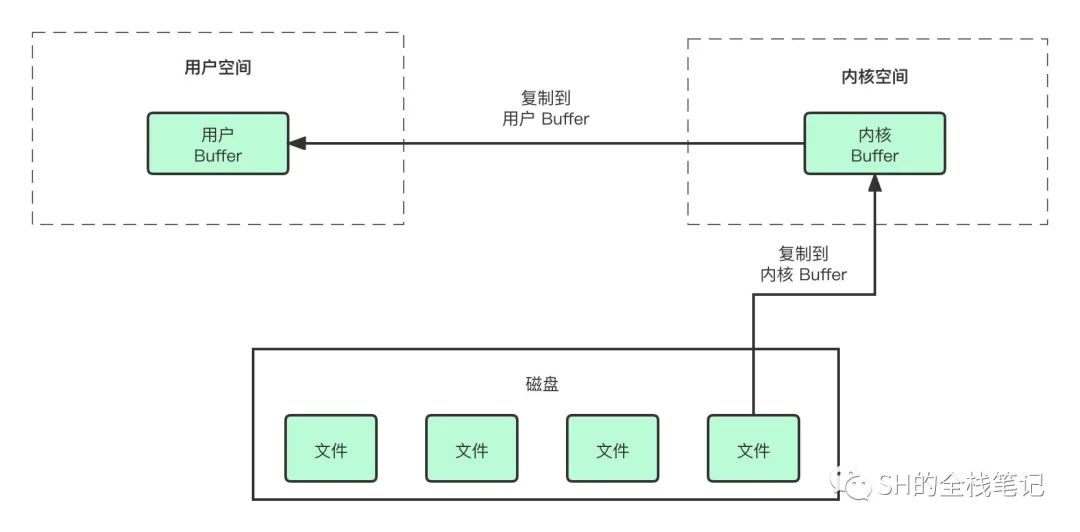
再比如,我们往磁盘上写文件,也不是直接将数据写到磁盘。而是将数据从用户缓冲区写到内核缓冲区,由操作系统择机将其刷入磁盘,图跟上面这个差不多,就不画了,自行理解。
再再比如,服务器接受客户端发过来的数据时,也不是直接到用户态的 Buffer 中。而是会先从网卡到内核态的 Buffer 中,再从内核态的 Buffer 中复制到用户态的 Buffer 中。
那为什么要这么麻烦呢?复制来复制去的,首先我们用排除法排除这样做是为了好玩。
Buffer 存在的目的是为了减少与设备(例如磁盘)的交互频率,在之前的博客中也提到过「磁盘的读写是很昂贵的操作」。那昂贵在哪里呢?简单来说,和设备的交互(例如和磁盘的IO)会设计到操作系统的中断。中断需要保存之前的进程运行的上下文,中断结束之后又需要恢复这个上下文,并且还涉及到内核态和用户态的切换,总体上是个耗时的操作。
看到这里,不熟悉操作系统的话可能会有点疑惑。例如:
- 啥是用户态
- 啥是内核态
大家可以去看看我之前写的文章 [《简单聊聊用户态和内核态的区别》]
Buffer 的使用
我们通过 Java 中 NIO 包中实现的 Buffer 来给大家讲解,Buffer 总共有 7 种实现,就包含了 Java 中实现的所有数据类型。
本篇文章中,我们使用的是 ByteBuffer,其常用的方法都有:
- put
- get
- flip
- rewind
- mark
- reset
- clear
接下来我们就通过实际的例子来了解这些方法。
put
put 就是往 ByteBuffer 里写入数据,其有有很多重载的实现:
public ByteBuffer put(ByteBuffer src) {...}
public ByteBuffer put(byte[] src, int offset, int length) {...}
public final ByteBuffer put(byte[] src) {...}我们可以直接传入 ByteBuffer 对象,也可以直接传入原生的 byte 数组,还可以指定写入的 offset 和长度等等。接下来看个具体的例子:
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'s','h'});
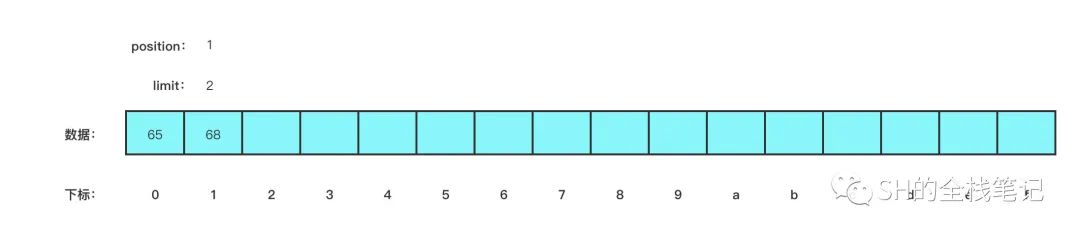
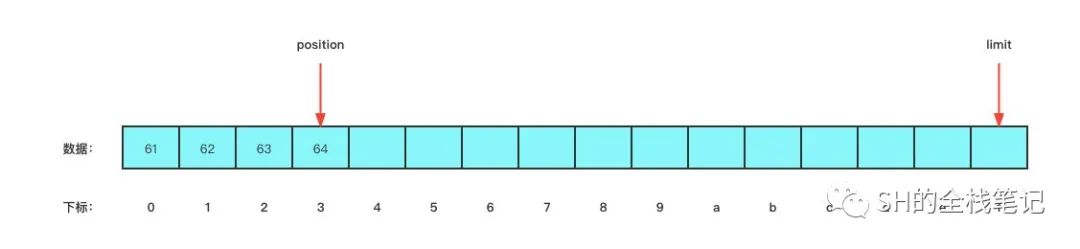
}为了能让大家更直观的看出 ByteBuffer 内部的情况,我将它整理成了图的形式。当上面的代码运行完之后 buffer 的内部长这样:

你尝试使用 System.out.println(buffer) 去打印变量 buffer 的时候,你会看到这样的结果:
java.nio.HeapByteBuffer[pos=2 lim=16 cap=16]
图里、控制台里都有 position 和 limit 变量,capacity 大家能理解,就是我们创建这个 ByteBuffer 的制定的大小 16。
而至于另外两个变量,相信大家从图中也可以看出来,position 变量指向的是下一次要写入的下标,上面的代码我们只写入了 2 个字节,所以 position 指向的是 2,而这个 limit 就比较有意思了,这个在后面的使用中结合例子一起讲。
get
get 是从 ByteBuffer 中获取数据。
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'s','h'});
System.out.println(buffer.get());
}如果你运行完上面的代码你会发现,打印出来的结果是 0 ,并不是我们期望的 s 的 ASCII 码 115。
首先告诉大家结论,这是符合预期的,这个时候就不应该能获取到值。我们来看看 get 的源码:
public byte get() { return hb[ix(nextGetIndex())]; }
protected int ix(int i) { return i + offset; }
final int nextGetIndex() {
int p = position;
if (p >= limit)
throw new BufferUnderflowException();
// 这里 position 会往后移动一位
position = p + 1;
return p;
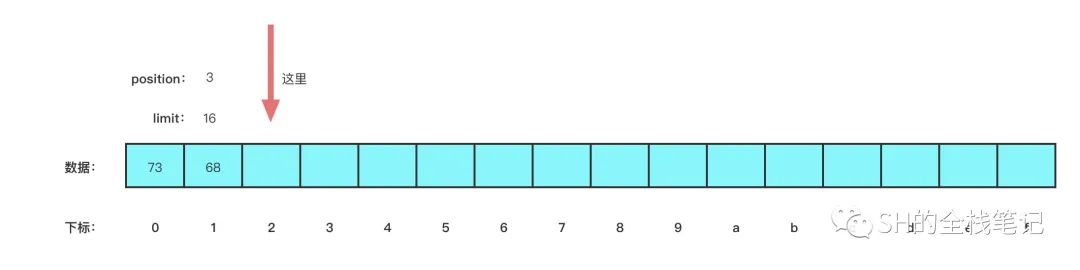
}当前 position 是 2,而 limit 是 16,所以最终 nextGetIndex 计算出来的值就是变量 p 的值 2 ,再过一次 ix ,那就是 2 + 0 = 2,这里的 offset 的值默认为 0 。
所以简单来说,最终会取到下标为 2 的数据,也就是下图这样。
get 方法虽然没有获取到任何数据,但是会使得 position 指针往后移动。换句话说,会占用一个位置。如果连续调用几次这种 get 之后,再调用 put 方法写入数据,就会造成有几个位置没有赋值。举个例子,假设我们运行以下代码:
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'s','h'});
buffer.get();
buffer.get();
buffer.get();
buffer.get();
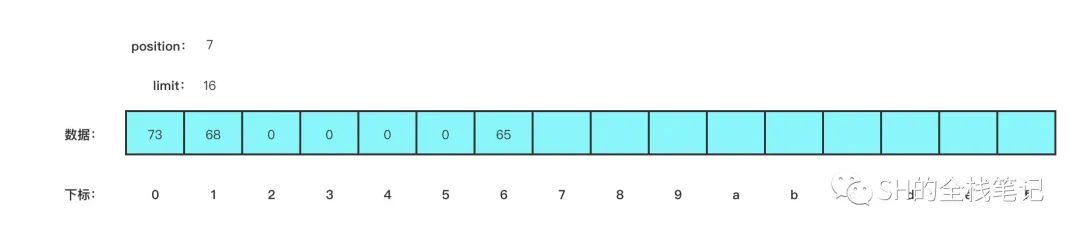
buffer.put(new byte[]{'e'});
}数据就会变成下图这样,position 会往后移动
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'s'});
System.out.println(buffer.get(0)); // 115
}传入我们想要获取的下标,就可以直接获取到,并且不会造成 position 的后移。
看到这那你更懵逼了,合着 get() 就没法用呗?还必须要给个 index。这就需要聊一下另一个方法 flip了。
flip
废话不多说,先看看例子:
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'s', 'h'}); // java.nio.HeapByteBuffer[pos=2 lim=16 cap=16]
buffer.flip();
System.out.println(buffer); // java.nio.HeapByteBuffer[pos=0 lim=2 cap=16]
}有意思的事情发生了,调用了 flip 之后,position 从 2 变成了 0,limit 从 16 变成了 2。
这个单词是「翻动」的意思,我个人的理解是像翻东西一样把之前存的东西全部翻一遍
你会发现,position 变成了 0,而 limit 变成 2,这个范围刚好是有值的区间。
接下来就更有意思了:
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'s', 'h'});
buffer.flip();
System.out.println((char)buffer.get()); // s
System.out.println((char)buffer.get()); // h
}调用了 flip 之后,之前没法用的 get() 居然能用了。结合 get 中给的源码不难分析出来,由于 position 变成了 0,最终计算出来的结果就是 0,同时使 position 向后移动一位。
终于到这了,你可以理解成 Buffer 有两种状态,分别是:
- 读模式
- 写模式
刚刚创建出来的 ByteBuffer 就处于一个写模式的状态,通过调用 flip 我们可以将 ByteBuffer 切换成读模式。但需要注意,这里讲的读、写模式只是一个逻辑上的概念。
举个例子,当调用 flip 切换到所谓的写模式之后,依然能够调用 put 方法向 ByteBuffer 中写入数据。
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'s', 'h'});
buffer.flip();
buffer.put(new byte[]{'e'});
}这里的 put 操作依然能成功,但你会发现最后写入的 e 覆盖了之前的数据,现在 ByteBuffer 的值变成了 eh 而不是 sh 了。
所以你现在应该能够明白,读模式、写模式更多的含义应该是:
- 方便你读的模式
- 方便你写的模式
顺带一提,调用 flip 进入写读模式之后,后续如果调用
get()导致position大于等于了limit的值,程序会抛出BufferUnderflowException异常。这点从之前get的源码也可以看出来。
rewind
rewind 你也可以理解成是运行在读模式下的命令,给大家看个例子:
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'s', 'h'});
buffer.flip();
System.out.println((char)buffer.get()); // s
System.out.println((char)buffer.get()); // h
// 从头开始读
buffer.rewind();
System.out.println((char)buffer.get()); // s
System.out.println((char)buffer.get()); // h
}所谓的从头开始读就是把 position 给归位到下标为 0 的位置,其源码也很简单:
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}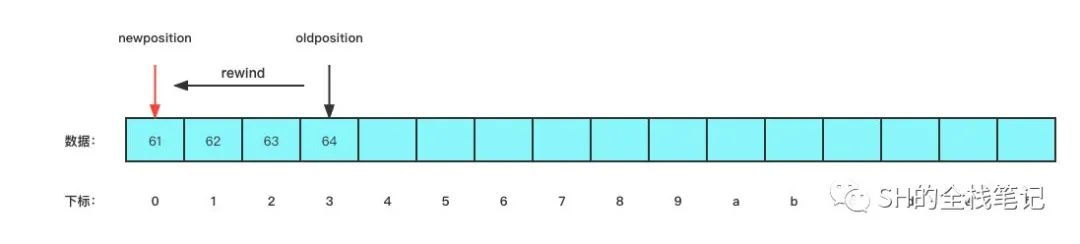
就是简单的把 position 赋值为 0,把 mark 赋值为 -1。那这个 mark 又是啥东西?这就是我们下一个要聊的方法。
mark & reset
mark 用于标记当前 postion 的位置,而 reset 之所以要放到一起讲是因为 reset 是 reset 到 mark 的位置,直接看例子:
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'a', 'b', 'c', 'd'});
// 切换到读模式
buffer.flip();
System.out.println((char) buffer.get()); // a
System.out.println((char) buffer.get()); // b
// 控记住当前的 position
buffer.mark();
System.out.println((char) buffer.get()); // c
System.out.println((char) buffer.get()); // d
// 将 position reset 到 mark 的位置
buffer.reset();
System.out.println((char) buffer.get()); // c
System.out.println((char) buffer.get()); // d
}可以看到的是 ,我们在 position 等于 2 的时候,调用了 mark 记住了 position 的位置。然后遍历完了所有的数据。然后调用 reset 使得 position 回到了 2 的位置,我们继续调用 get ,c d 就又可以被打印出来了。
clear
clear 表面意思看起来是将 buffer 清空的意思,但其实不是,看这个:
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'a', 'b', 'c', 'd'});
}put 完之后,buffer 的情况是这样的。

clear 之后,buffer 就会变成这样。
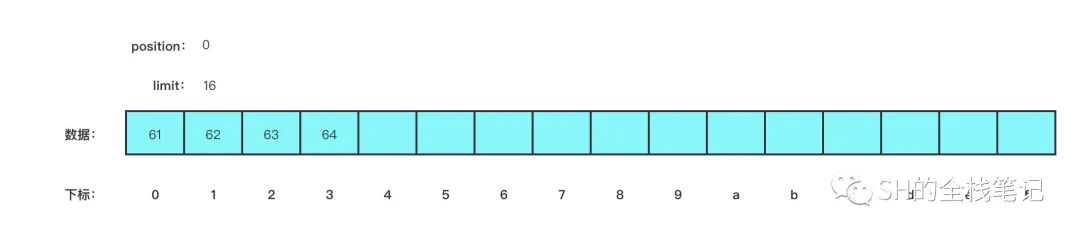
clear 之后只是切换到了写模式,因为这个时候往里面写数据,会覆盖之前写的数据,相当于起到了 clear 作用,再举个例子:
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'a', 'b', 'c', 'd'});
buffer.clear();
buffer.put(new byte[]{'s','h'});
}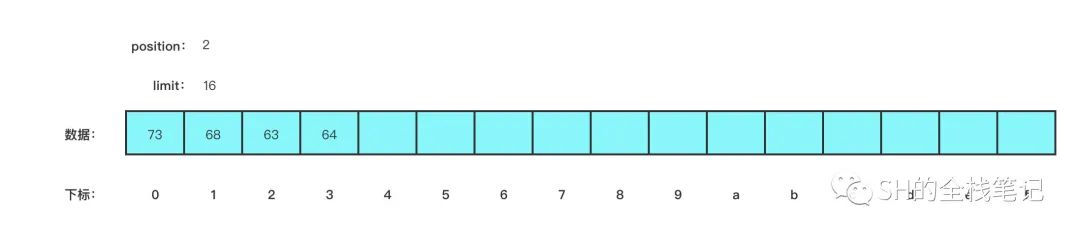
buffer 的数据变成了 shcd,后写入的数据将之前的数据给覆盖掉了。
除了 clear 可以切换到写模式之外,还有另一个方法可以切换,这就是本篇要讲的最后一个方法 compact。
compact
先一句话给出 compact 的作用:将还没有读完的数据挪到 Buffer 的首部,并切换到写模式,代码如下:
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put("abcd".getBytes(StandardCharsets.UTF_8));
// 切换到读模式
buffer.flip();
System.out.println((char) buffer.get()); // a
// 将没读过的数据, 移到 buffer 的首部
buffer.compact(); // 此时 buffer 的数据就会变成 bcdd
}当运行完 flip 之后,buffer 的状态应该没什么问题了:

而 compact 之后发生了什么呢?简单来说就两件事:
- 将
position移动至对应的位置 - 将没有读过的数据移动到
buffer的首部
这个对应是啥呢?先给大家举例子;例如没有读的数据是 bcd,那么 position 就为 3;如果没有读的数据为 cd,position 就为 2。所以你发现了,position 的值为没有读过的数据的长度。
从 buffer 内部实现机制来看,凡是在 position - limit 这个区间内的,都算没有读过的数据
所以,当运行完 compact 之后,buffer 长这样:
limit 为 16 是因为 compact 使 buffer 进入了所谓的写模式。
EOF
还有一些其他的方法就不在这里列举了,大家感兴趣可以自己去玩玩,都没什么理解上的难度了。之后可能会再专门写一写 Channel 和 Selector,毕竟 Java 的 nio 三剑客,感兴趣的可以关注一下。