美团面试官:讲清楚MySQL结构体系,立马发offer
大家好, 今天给大家分享的是:MySQL的架构体系。
故事
继续和大家分享,我去上海美团面试遇到的技术问题,当时,回答的也是马马虎虎的,不能说不好,也不能说好,反正就是没有给面试官一种爽的感觉。
害,很多东西都是,平时感觉还行,一旦到了面试的时候啥都想不起来。
给大家推荐,我在美团面试遇到的技术问题,已经写了三篇:
[美团面试题:慢SQL有遇到过吗?是怎么解决的?]
[美团面试题:String s = new String("111")会创建几个对象?]
[美团面试题:为什么就能直接调用userMapper接口的方法?]
虽然,本人搞Java开发快五年了(2017年),用过Oracle数据库(银行里的系统),但大多数时候都是使用MySQL数据库,但是面对这个问题依然是一脸懵逼(硬着头皮也扯了一些),还以为面试官要问索引、慢查询、性能优化之类的(因为这些都是网上找点面试题背过了)。

今天我们就来聊聊MySQL的架构体系,尽管咱们是Java开发人员,但是在日常开发过程中也会经常和MySQL数据库打交道。如果公司有DBA能干点事还稍微好点,如果是没有DBA或者DBA没什么卵用的情况下,我们还是很有必要了解MySQL的整个体系的,况且在面试中遇到了也是一个加分项。

想要知道一条SQL是怎么查询的,只要对MySQL整个体系搞清楚了,才能说出个123。

所以于情于理,我们很有必要学习一下MySQL的架构体系的。
平时,我和小伙伴们聊天的时候,经常会把MySQL当做我们开发的一个软件系统,既然是软件系统,那么就有个架构图,以及架构是如何分层的,每一层的功能是什么。
MySQL是什么?
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle公司。MySQL是一种关联数据库管理系统,将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。MySQL是开源的,所以你不需要支付额外的费用。MySQL支持大型的数据库,可以处理拥有上千万条记录的大型数据库。MySQL使用标准的SQL数据语言形式。MySQL可以允许于多个系统上,并且支持多种语言,这些编程语言包括C、C++、Python、Java、Ped、PHP、Eifel、Ruby和TCL等。MySQL对PHP有很好的支持,PHP是目前最流行的Web开发语言。MySQL支持大型数据库,支持5000万条记录的数据仓库,32位系统表文件最大可支持4GB,64位系统支持最大的表文件为8TB。MySQL是可以定制的,采用了GPL协议,你可以修改源码来开发自己的MySQL系统。
请注意
MySQL拼写,另外,很多人可能有疑问,为什么MySQL的logo是一条海豚?
下面我们就来看看MySQL的整体架构图。
MySQL架构图
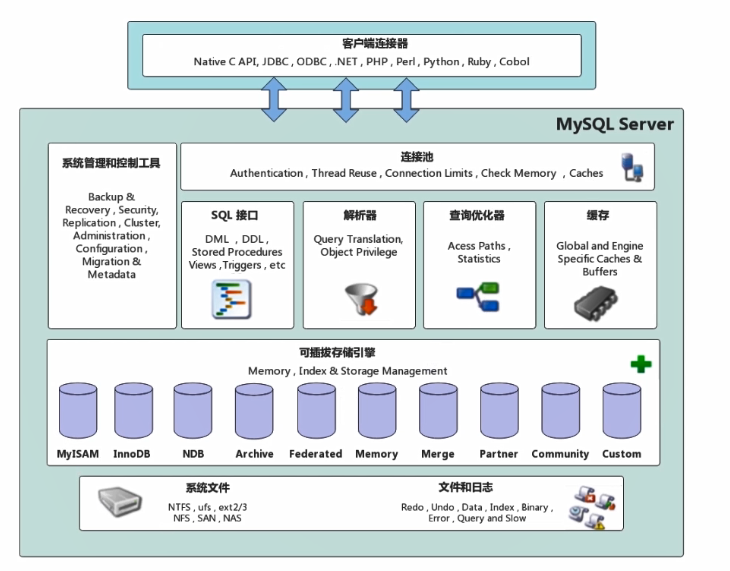
再来看看我们开发的系统架构图:
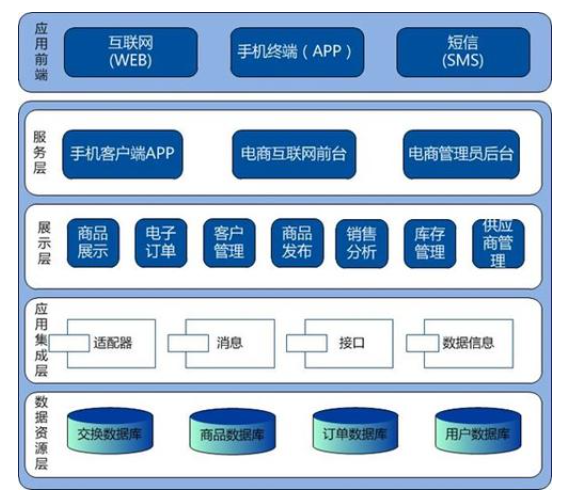
其实还是蛮相似的,都有分层的概念。既然我们开发的软件系统能进行分层,那么MySQL能分层吗?
答案是:能,下面我们就来聊聊MySQL的分层情况以及每一层的功能。
架构图分层
上面的架构图我们可以对其进行拆分,并做简要的说明。
连接层

与客户端打交道,上面已经写明了能支持的的语言。客户端的链接支持的协议很多,比如我们在 Java 开发中的 JDBC。
这一层是不是有点像我们项目中的网关层?如果对网关不熟悉,那我们可以理解我controller层。
服务层
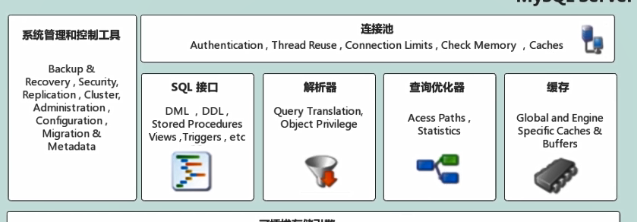
这一层,就相当于我们业务系统中的service层,大杂烩,相关业务的操作、代码优化、缓存等都在这里面。
连接池
主要是负责存储和管理客户端与数据库的链接,一个线程负责管理一个连接。自从引入了连接池以后,官方报道:当数据库的连接数达到128后,使用连接池与没有连接池的性能是提升了n倍(反正就是性能大大的提升了)。
连接建立完成后,就可以执行select语句了。执行逻辑就会先来到缓存模块。
缓存
MySQL拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果会以key-value对的形式存储在内存中。key是查询的语句,value是查询的结果。如果你的查询能够直接在这个缓存中找到key(命中),那么这个value就会被直接返回给客户端。
如果在缓存中未命中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。这里可以看到,如果查询命中缓存,MySQL不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
但是大多数情况下我会建议你不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。
查询缓存的失效非常频繁,只要有对一个表的某一条数据更新,这个表上所有的查询缓存都会被清空。
因此可能很费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。
比如:一个系统配置表,那这张表上的查询才适合使用查询缓存。
好在MySQL也提供了这种“按需使用”的方式。你可以将参数query_cache_type设置成DEMAND,这样对于默认的SQL语句都不使用查询缓存。
「注意」:MySQL 8.0版本直接将查询缓存的整块功能删掉了,标志着MySQL8.0开始彻底没有缓存这个功能了。
解析器
如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL需要知道你要做什么,因此需要对SQL语句做解析。
分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条SQL语句,MySQL需要识别出里面的字符串分别是什么,代表什么。
做完了词法分析以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个SQL语句是否满足MySQL语法。
如果我们在拼写SQL时候,少了或者写错了某个字母,,就会收到“You have an error in your SQL syntax”的错误提醒。
比如下面这个案例:
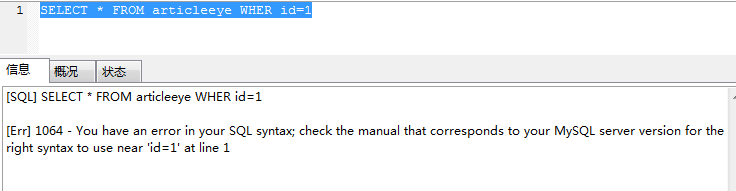
错误在于WHERE关键字中差了一个E。
同样,我们使用的SQL如果某个字段不存在。
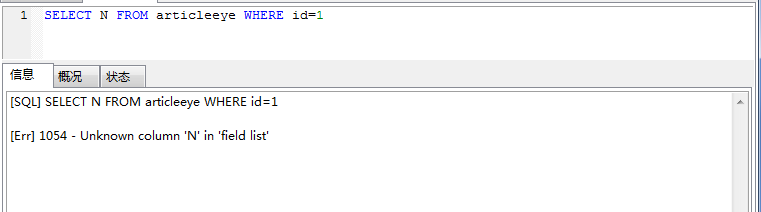
一般语法错误会提示第一个出现错误的位置,所以你要关注的是紧接“use near”的内容,仅供参考,有时候这个提示也不是非常靠谱。
经过分析器对SQL进行了分析,并且没有报错。那么此时就进入优化器中,对SQL进行优化。
优化器
优化器主要是在我们的数据库表中,如果存在多个多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序 。
比如说:
SELECT a.id, b.id FROM t_user a join t_user_detail b WHERE a.id=b.user_id and a.user_name='田维常' and b.id=10001
它会在条件查询上进行优化处理。
优化器处理完成过后,此时就已经确定了SQL的执行方案。然后继续进入执行器中。
执行器
首先,肯定是要判断权限,就是有没有权限执行这条SQL。工作中可能会对某些客户端进行权限控制。
比如说:生产环境中,对于大部分开发人员都只开查询权限,没有增删改权限(部分小公司除外)。
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
存储引擎层
这一层,我们可以理解为我们业务系统中的持久层。
存储引擎的概念是MySQL里面才有的,不是所有的关系型数据库都有存储引擎这个概念 。
数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以获得特定的功能。现在许多不同的数据库管理系统都支持多种不同的数据引擎。
因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(Table Type,即存储和操作此表的类型)。
- MySQL5.5版本(mysql 版本 < 5.5版本) 以前,默认使用的存储引擎是MyISAM 。
- MySQL5.5版本(mysql 版本 >= 5.5版本) 以后,默认使用的存储引擎是InnoDB 。
下面对部分相对使用多的引擎进行一个对比:
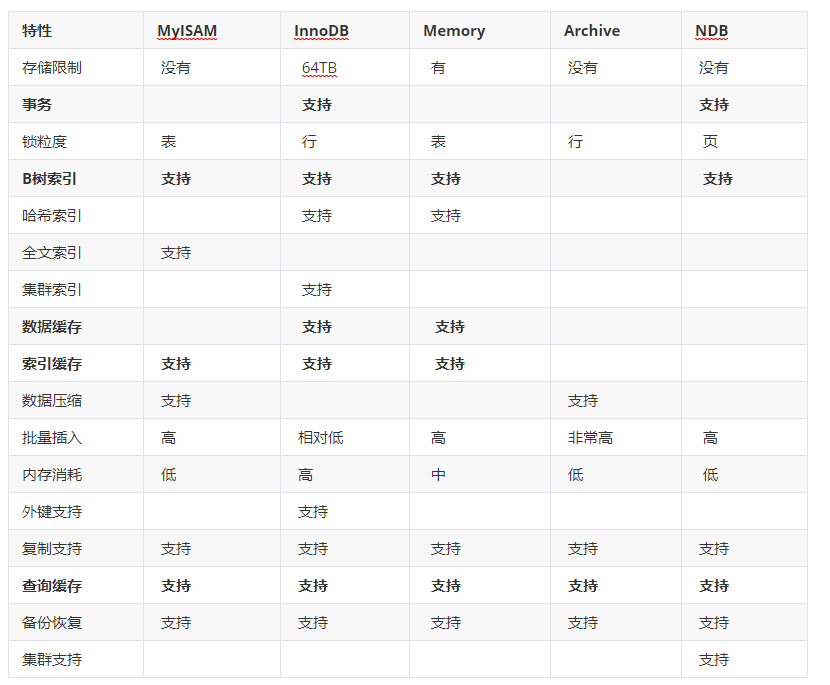
在实际项目中,大多数使用InnoDB,然后是MyISAM,至于其他存储引擎使用的非常至少。
我们可以使用命令来查看MySQL 已提供什么存储引擎 :
show engies;
也可以通过命令来查看 MySQL 当前默认的存储引擎 :
show variables like '%storage_engine%';
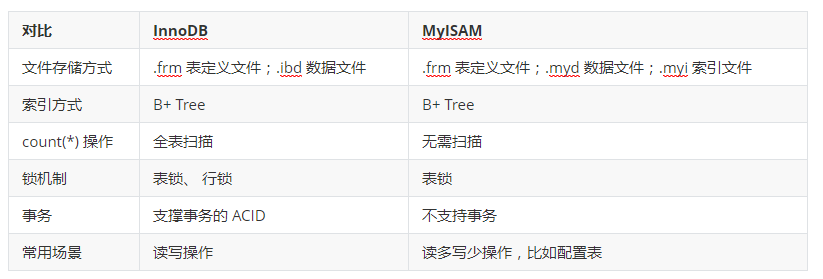
MyISAM与 InnoDB引擎的区别
MySQL5.5 版本之前默认的存储引擎就是 MyISAM 存储引擎,MySQL 中比较多的系统表使用 MyISAM 存储引擎,系统临时表也会用到 MyISAM 存储引擎,但是在 Mysql5.5 之后默认的存储引擎就是 InnoDB 存储引擎了。
如何在两种存储引擎中进行选择?
- 是否有事务操作?有,InnoDB。
- 是否存储并发修改?有,InnoDB。
- 是否追求快速查询,且数据修改较少?是,MyISAM。
- 是否使用全文索引?如果不引用第三方框架,可以选择MyISAM,但是可以选用第三方框架和InnDB效率会更高。
InnoDB 存储引擎主要有如下特点:
- 支持事务
- 支持 4 个级别的事务隔离
- 支持多版本读
- 支持行级锁
- 读写阻塞与事务隔离级别相关
- 支持缓存,既能缓存索引,也能缓存数据
- 整个表和主键以 Cluster 方式存储,组成一颗平衡树
当然也不是说 InnoDB 一定就是好的,在实际开发中,还是要根据具体的场景来选择到底是使用 InnoDB 还是 MyISAM 。
MyIASM(该引擎在 5.5 前的 MySQL 数据库中为默认存储引擎)特点:
- MyISAM 没有提供对数据库事务的支持
- 不支持行级锁和外键
- 由于 2,导致当执行 INSERT 插入或 UPDATE 更新语句时,即执行写操作需要锁定整个表,所以会导致效率降低
- MyISAM 保存了表的行数,当执行
SELECT COUNT(*) FROM TABLE时,可以直接读取相关值,不用全表扫描,速度快。
两者区别:
- MyISAM 是非事务安全的,而 InnoDB 是事务安全的
- MyISAM 锁的粒度是表级的,而 InnoDB 支持行级锁
- MyISAM 支持全文类型索引,而 InnoDB 在 MySQL5.6 之前不支持全文索引,从 MySQL5.6 之后开始支持 FULLTEXT 索引了。
使用场景比较:
- 如果要执行大量 select 操作,应该选择 MyISAM
- 如果要执行大量 insert 和 update 操作,应该选择 InnoDB
- 大尺寸的数据集趋向于选择 InnoDB 引擎,因为它支持事务处理和故障恢复。数据库的大小决定了故障恢复的时间长短,InnoDB 可以利用事务日志进行数据恢复,这会比较快。主键查询在 InnoDB 引擎下也会相当快,不过需要注意的是如果主键太长也会导致性能问题。
相对来说,InnoDB 在互联网公司使用更多一些。
系统文件存储层

这一层,我们同样的可以理解为我们业务系统中的数据库。
系统文件存储层主要是负责将数据库的数据和日志存储在系统的文件中,同时完成与存储引擎的之间的打交道,是文件的物理存储层。
比如:数据文件、日志文件、pid文件、配置文件等。
数据文件
「db.opt文件」:记录这个数据库的默认使用的字符集和校验规则。
「frm文件」:存储于边相关的元数据信息,包含表结构的定义信息等,每一张表都会有一个frm文件与之对应。
「MYD文件」:MyISAM存储引擎专用的文件,存储MyISAM表的数据信息,每一张MyISAM表都有有一个.MYD文件。
「MYI文件」:也是MyISAM存储引擎专用的文件,存放MyISAM表的索引相关信息,每一张MyISAM表都有对应的.MYI文件。
「ibd文件和ibdata文件」:存放InnoDB的数据文件(包括索引)。InnoDB存储引擎有两种表空间方式:独立表空间和共享表空间。
- 独享表空间使用ibd文件来存放数据,并且每一张InnoDB表存在与之对应的.ibd文件。
- 共享表空间使用ibdata文件,所有表共同使用一个或者多个.ibdata文件。
「ibdata1文件」:系统表空间数据文件,存储表元数据、Undo日志等。
「ib_logfile0、ib_logfile0文件」:Redo log日志文件。
日志文件
错误日志:默认是开启状态,可以通过命令查看:
show variables like '%log_error%';
二进制日志binary log:记录了对MySQL数据库执行的更改操作,并且记录了语句的发生时间、执行耗时;但是不记录查询select、show等不修改数据的SQL。主要用于数据库恢复和数据库主从复制。也是大家常说的binlog日志。
show variables like '%log_log%';//查看是否开启binlog日志记录。
show variables like '%binllog%';//查看参数
show binary logs;//查看日志文件慢查询日志:记录查询数据库超时的所有SQL,默认是10秒。
show variables like '%slow_query%';//查看是否开启慢查询日志记录。
show variables '%long_query_time%';//查看时长通用查询日志:记录一般查询语句;
show variables like '%general%';
配置文件
用于存放MySQL所有的配置信息的文件,比如:my.cnf、my.ini等。
「pid文件」
pid文件是mysqld应用程序在Linux或者Unix操作系统下的一个进程文件,和许多其他Linux或者Unix服务端程序一样,该文件放着自己的进程id。
「socket文件」
socket文件也是Linux和Unix操作系统下才有的,用户在Linux和Unix操作系统下客户端连接可以不通过TCP/IP网络而直接使用Unix socket来连接MySQL数据库。
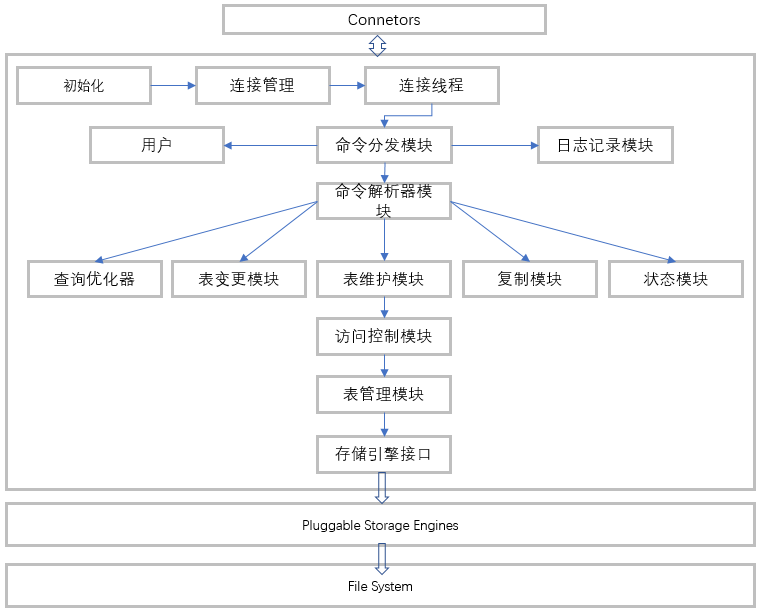
SQL查询流程图
总结
MySQL整个系统我们可以看成是我们日常开发的软件系统,也有接入层,专门对接外面客户端的,和我们系统的网关就很像,缓存也就类似我们业务代码中使用的缓存,解析器可以理解为业务系统中参数解析以及参数校验,优化层可以当做我们开发代码优化的手段,然后存储引擎就相当于我们的持久层,文件系统相当于整个业务系统中的数据库。
可能比喻不是非常的恰当,但是希望大家能领略轻重的含义,目的只有一个,那就是让大家能轻松掌握MySQL的整体情况。
不要天天羡慕什么大牛,什么大神,他们也是一步一步走来的。自信点,只要你一点一点搞,踏踏实实的干,你也会成为大神的。