面试官:熔断降级原理是什么?
概述
高可用三剑客 限流,熔断和削峰 , 今天是熔断降级专题,仅以两张图来初步形容一下 熔断 适用的场景:
- 雪崩

- 股灾
什么是熔断
来自 wiki 的 熔断机制 描述:
https://mp.weixin.qq.com/s/pqbmj8tchnXD0Zdric_ApQ转换成互联网语言可以这么理解:
- 当
异常幅度达到设定的阀值后触发的系统保护机制 - 保护机制会将某
部分能力关闭,以保证大部分能力的正常 - 这种机制是有损的,但是
利大于端
熔断机制的特点,在关闭一段时间后,会自动触发恢复检测,如果发现服务正常,则将服务逐渐开放。
1、雪崩效应
在分布式服务部署的架构下,整体链路可以参考为:
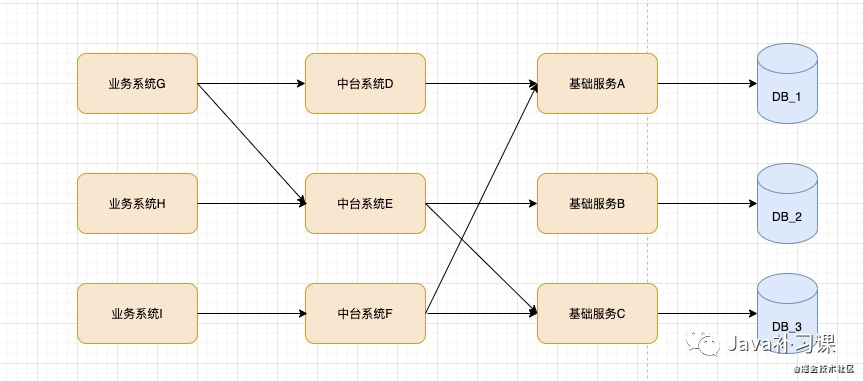
如果在大促期间, DB_2 由于 机器负载过高,sql执行缓慢,链接数打满 或网络抖动等情况,导致 DB_2 不可用,那么整体链路的影响就会变成:
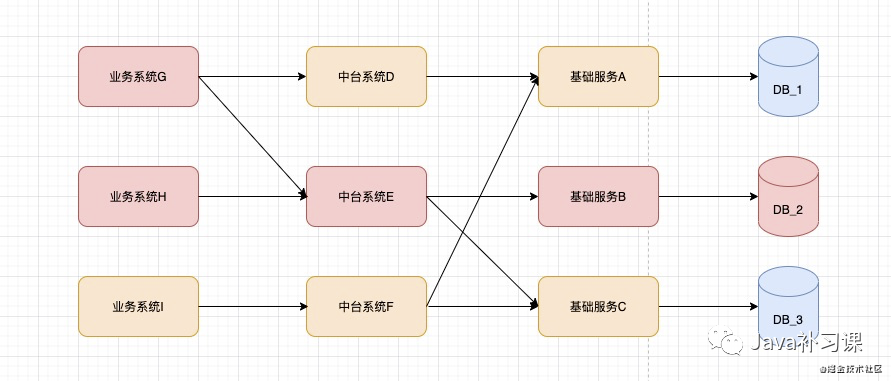
服务雪崩的每个阶段都可能由不同的原因造成, 比如造成 服务不可用 的原因有:
- 硬件故障
- 程序Bug
- 缓存击穿
- 用户大量请求
2、雪崩处理策略
- 流量控制:
限流和削峰都属于流量控制的一种策略 - 缓存优化:在上述案例中,
DB由于压力过大导致的雪崩,可以引入缓存,减轻DB压力 - 服务降级:通过异常
分支链路的快速失败,确保主链路正常提供服务 - 应用扩容:针对
机器压力过大,负载过高,可以通过机器扩容来解决,缓解流量压力
断路器模式
熔断器模式(Circuit Breaker Pattern),是一个现代软件开发的设计模式。用以侦测错误,并避免不断地触发相同的错误(如维护时服务不可用、暂时性的系统问题或是未知的系统错误)。
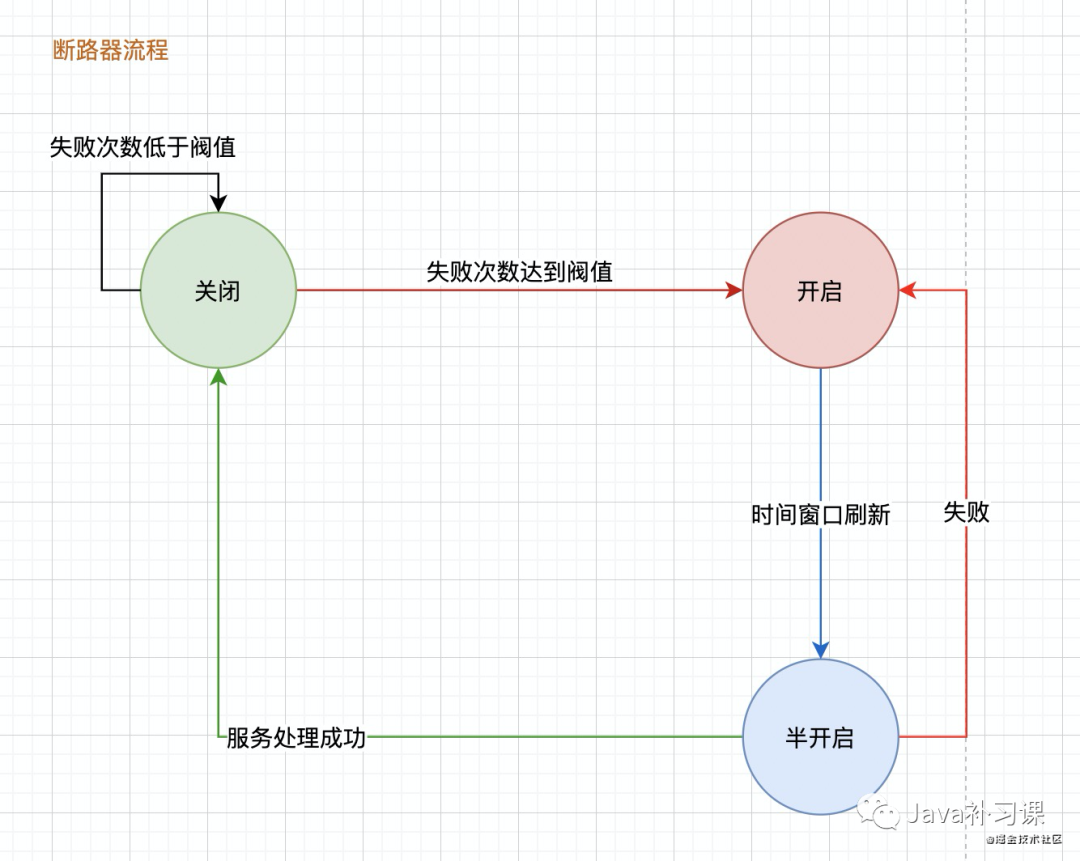
状态描述:
关闭:熔断器默认处于关闭状态,熔断器本身带有计数能力(如滑动窗口实现),当失败数量达到预设阀值后,触发状态变更,熔断器被打开开启:在一定时间内,所有请求都会被拒绝,或采用备用链路处理。半开启:在刷新时间窗口后,会进入半开启状态,熔断器尝试接受请求,如果这阶段出现请求失败,直接恢复到开启状态。
隔离策略
1、线程隔离
Hystrix 采用了 Bulkhead Partition舱壁隔离技术,来将外部依赖进行资源隔离,进而避免任何外部依赖的故障导致本服务崩溃。
舱壁隔离,是说将船体内部空间区隔划分成若干个隔舱,一旦某几个隔舱发生破损进水,水流不会在其间相互流动,如此一来船舶在受损时,依然能具有足够的浮力和稳定性,进而减低立即沉船的危险。

图片来源:《防雪崩利器:熔断器 Hystrix 的原理与使用》
Hystrix 在线程池隔离实现主要解决一下场景:
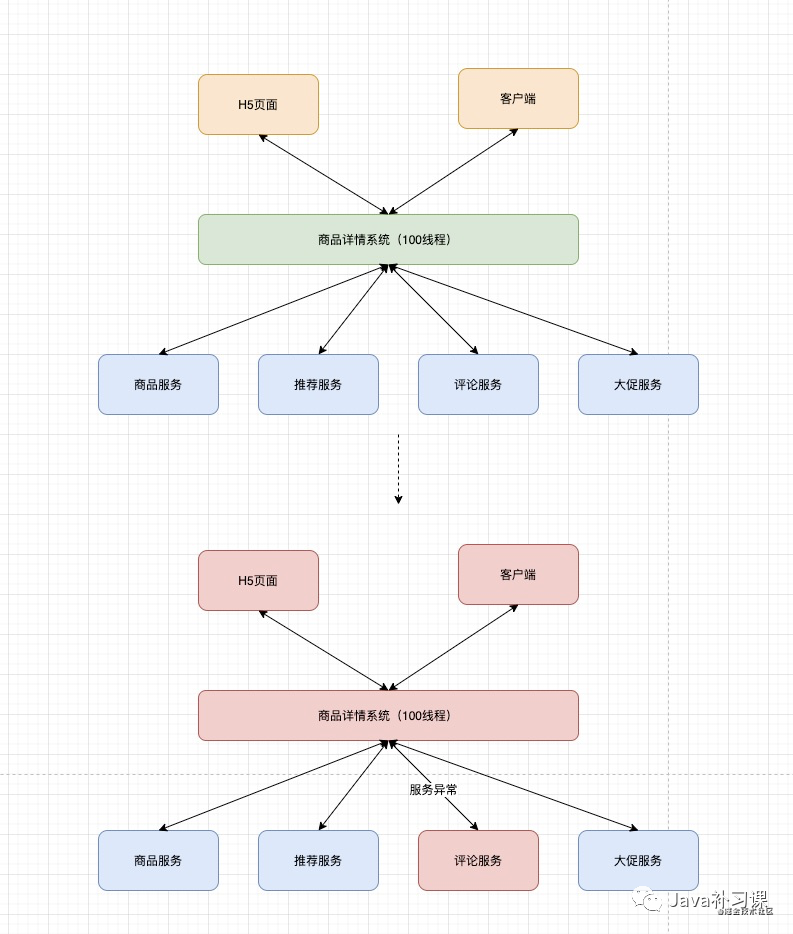
在商品详情系统中,如果没有对服务做降级措施,那么当评论服务出现异常时,整个商品详情系统都会受到影响,最终导致用户无法查看商品详情。
在这个例子中,商品详情服务,从请求入口分配线程处理,对每个服务使用同一个线程进行处理(同步),在评论服务出现异常时(响应缓慢,处理超时,服务异常等),导致整个线程阻塞,服务端响应超时,触发用户重试刷新请求,最终导致服务雪崩,系统崩溃。
Hystrix 线程池隔离方案;
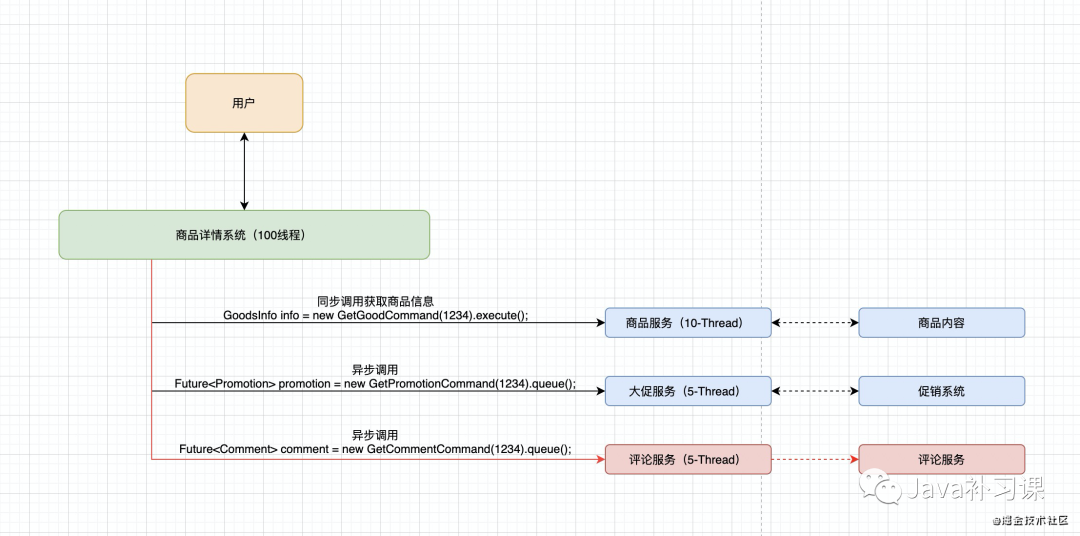
hystrix把每个依赖都进行隔离,对依赖的调用全部包装成HystrixCommand或者HystrixObservableCommand 在服务调用时,分配独立的线程池进行资源隔离调用,如下图中的评论服务出现不可用时,商品详情系统还是能够将商品信息,大促信息封装好返回给用户。评论服务的异常,并不会影响其他依赖的调用。
线程隔离特点
优点:
- 一个依赖可以给予一个线程池,这个依赖的异常不会影响其他的依赖。
- 使用线程可以完全隔离第三方代码,请求线程可以快速放回。
- 当一个失败的依赖再次变成可用时,线程池将清理,并立即恢复可用,而不是一个长时间的恢复。
- 可以完全模拟异步调用,方便异步编程。
- 使用线程池,可以有效的进行实时监控、统计和封装。
缺点:
- 使用线程池的缺点主要是增加了计算的开销。每一个依赖调用都会涉及到队列,调度,上下文切换,而这些操作都有可能在不同的线程中执行。
线程切换的性能损耗问题
Netflix在使用过程中详细评估了使用异步线程和同步线程带来的性能差异,结果表明在99%的情况下,异步线程带来的几毫秒延迟的完全可以接受的
2、信号量隔离
Hystrix 的信号量隔离限制对某个资源调用的异常比例。
Sentinel 在信号量隔离的限制上提供了更多的策略选择,基于慢调用比例、异常比例和异常数。
信号量隔离实现原理
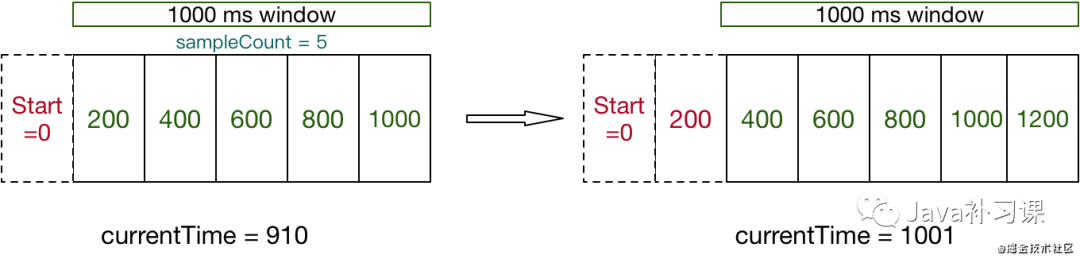
Sentinel 底层采用高性能的滑动窗口数据结构 LeapArray 来统计实时的秒级指标数据,在 信号量隔离的底层实现中, 通过根据不同的策略,如 异常数 策略,统计在 滑动窗口区间内, 异常请求量的比例,来决定对服务进行熔断降级处理。
滑动窗口示意图:
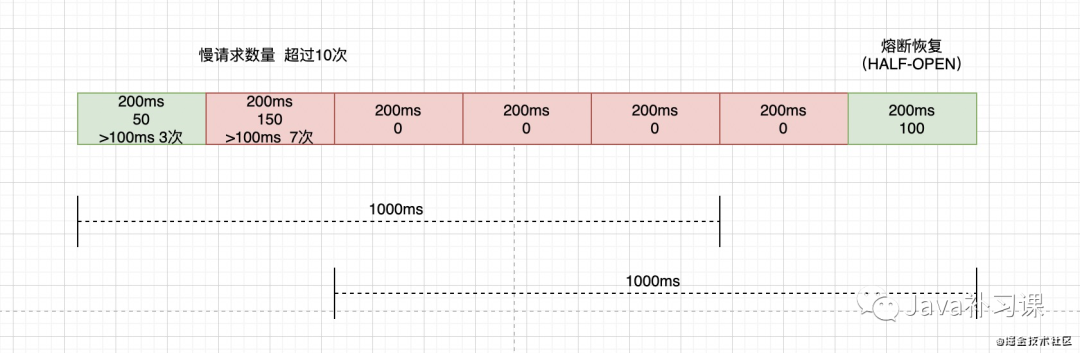
1、慢调用比例 (SLOW_REQUEST_RATIO) 设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当调用请求数量大于阀值,触发熔断。阀值设置,100ms响应,10个请求 如下图所示:
2、异常比例 (ERROR_RATIO
当单位统计时长内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。阀值设置 20% 如下图所示:
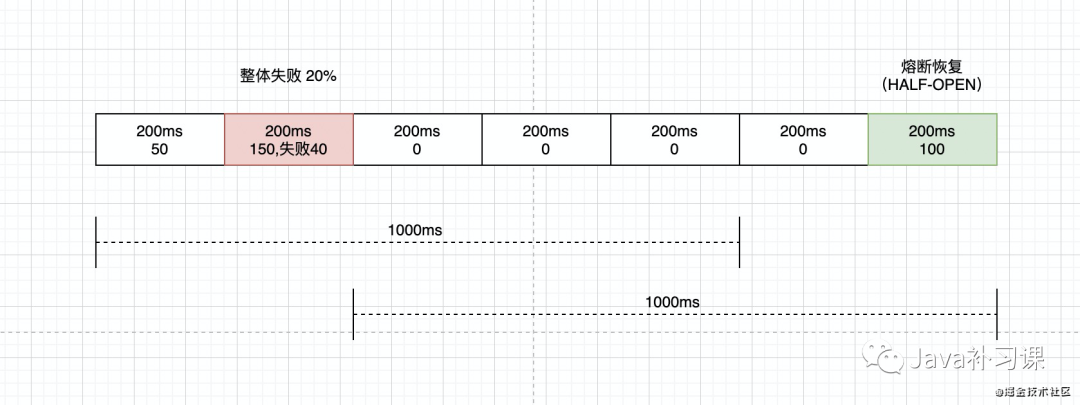
3、异常数 (ERROR_COUNT)
当单位统计时长内的异常数目超过阈值之后会自动进行熔断。阀值设置 5 如图所示:

熔断降级组件对比
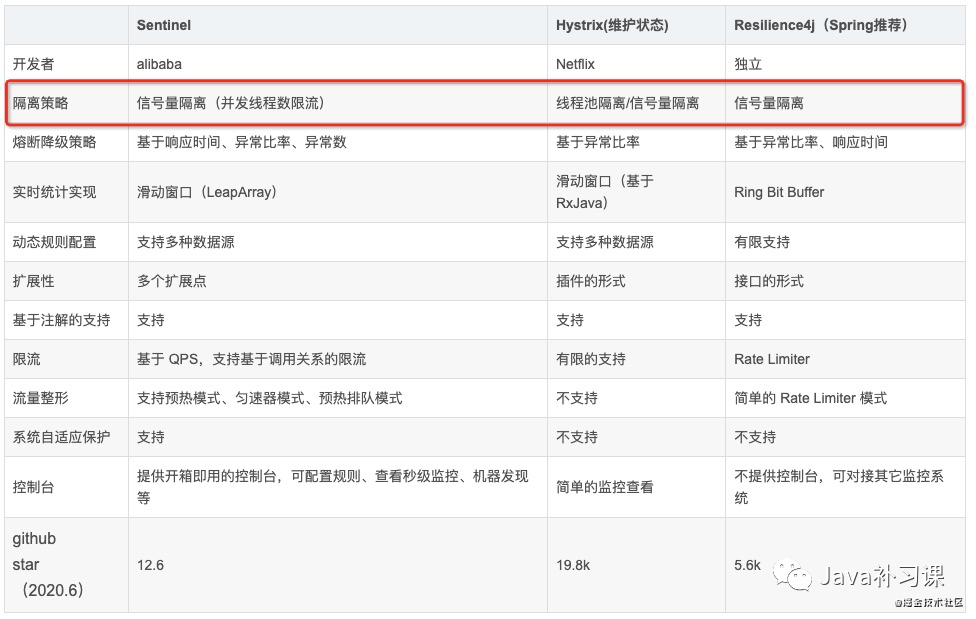
Sentinel
Sentinel是阿里中间件团队开源的,面向分布式服务架构的轻量级高可用流量控制组件,主要以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来帮助用户保护服务的稳定性。
Sentinel 的侧重点在于:
- 多样化的流量控制
- 熔断降级
- 系统负载保护
- 实时监控和控制台
Hystrix
Hystrix是Netflix开源的一款容错系统,能帮助使用者码出具备强大的容错能力和鲁棒性的程序。提供降级,熔断等功能。在2018年底,Hystrix在其Github主页宣布,不再开放新功能,推荐开发者使用其他仍然活跃的开源项目。
官方 wiki 描述:
Hystrix is designed to do the following:
Give protection from and control over latency and failure from dependencies accessed (typically over the network) via third-party client libraries.
Stop cascading failures in a complex distributed system.
Fail fast and rapidly recover.
Fallback and gracefully degrade when possible.
Enable near real-time monitoring, alerting, and operational control.- 对通过第三方客户端库访问的依赖项(通常是通过网络)的延迟和故障进行保护和控制。
- 在复杂的分布式系统中阻止级联故障。
- 快速失败,快速恢复。
- 回退,尽可能优雅地降级。
- 启用近实时监控、警报和操作控制。
resilience4j
resilience4j是一个轻量、易用、可组装的高可用框架,支持熔断、高频控制、隔离、限流、限时、重试等多种高可用机制。Netflix 官方在停止维护Hystrix 后,推荐使用 resilience4j 作为替代方案。
与Hystrix相比,它有以下一些主要的区别:
- Hystrix调用必须被封装到HystrixCommand里,而resilience4j以装饰器的方式提供对函数式接口、lambda表达式等的嵌套装饰,因此你可以用简洁的方式组合多种高可用机制
- Hystrix的频次统计采用滑动窗口的方式,而resilience4j采用环状缓冲区的方式
- 关于熔断器在半开状态时的状态转换,Hystrix仅使用一次执行判定是否进行状态转换,而resilience4j则采用可配置的执行次数与阈值,来决定是否进行状态转换,这种方式提高了熔断机制的稳定性
- 关于隔离机制,Hystrix提供基于线程池和信号量的隔离,而resilience4j只提供基于信号量的隔离
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,我后面会每周都更新几篇高质量的大厂面试和常用技术栈相关的文章。感谢大伙能看到这里,如果这个文章写得还不错, 求三连!!!创作不易,感谢各位的支持和认可,我们下篇文章见!