给小白演示 分库分表案例
大家好 ,受群里小伙伴之邀,搞一个分库分表案例,这样让很多没用过分库分表的心里也有个底,不然永远看到的都是网上的各种概念和解决方案性的文章。
说明:由于是给小白看的,所以大神勿喷,建议出门左转去学更牛逼的技术。
需求
由于用户表过于庞大,采取相关SQL优化,还是不能满足,所以现对其进行做分库分表。
数据库:my-sharding
数据库表:t_user
建表语句如下:
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`age` int NOT NULL,
`gender` int NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;关于数据库分库分表通常有两种方案:
- 垂直拆分
- 水平拆分
下面我们来演示水平拆分,大致思路:
通过t_user表的id进行hash,然后再和数据库个数进行取模,得出对应数据库。
通过hash值和每个数据库中表的个数进行取模,得出对应表名。
创建数据库和表
加入有2000万条数据,那么为了方便演示,我们就暂定分为五个库,每个数据库对应五个表。
理想状态:2000万/5/4,那么每个数据库分得400万,每个表分得80万。
总之,分库分表后,我们的每一张表的数据库和表都与之前的确实不是一个量级了。
五个数据库:

每个数据库有五张表:
建表语句如下:
DROP TABLE IF EXISTS `t_user_0`;
CREATE TABLE `t_user_0` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`age` int NOT NULL,
`gender` int NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `t_user_1`;
CREATE TABLE `t_user_1` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`age` int NOT NULL,
`gender` int NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `t_user_2`;
CREATE TABLE `t_user_2` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`age` int NOT NULL,
`gender` int NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `t_user_3`;
CREATE TABLE `t_user_3` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`age` int NOT NULL,
`gender` int NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `t_user_4`;
CREATE TABLE `t_user_4` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`age` int NOT NULL,
`gender` int NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;项目创建
使用技术栈:JDK8+MySQL+Spring Boot +Mybatis +Shardingsphere +Druid
maven 相关依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.17</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>配置文件相关配置如下:
server.port=9002
mybatis.mapper-locations=classpath:/mapper/*.xml
# mybatis.type-aliases-package=com.neutral.idmapping.dbshard.pojo
##### 连接池配置 #######
# 过滤器设置(第一个stat很重要,没有的话会监控不到SQL)
spring.datasource.druid.filters=stat,wall,log4j2
##### WebStatFilter配置 #######
#启用StatFilter
spring.datasource.druid.web-stat-filter.enabled=true
#添加过滤规则
spring.datasource.druid.web-stat-filter.url-pattern=/*
#排除一些不必要的url
spring.datasource.druid.web-stat-filter.exclusions=*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*
#开启session统计功能
spring.datasource.druid.web-stat-filter.session-stat-enable=true
#缺省sessionStatMaxCount是1000个
spring.datasource.druid.web-stat-filter.session-stat-max-count=1000
#spring.datasource.druid.web-stat-filter.principal-session-name=
#spring.datasource.druid.web-stat-filter.principal-cookie-name=
#spring.datasource.druid.web-stat-filter.profile-enable=
##### StatViewServlet配置 #######
#启用内置的监控页面
spring.datasource.druid.stat-view-servlet.enabled=true
#内置监控页面的地址
spring.datasource.druid.stat-view-servlet.url-pattern=/druid/*
#关闭 Reset All 功能
spring.datasource.druid.stat-view-servlet.reset-enable=false
#设置登录用户名
spring.datasource.druid.stat-view-servlet.login-username=admin
#设置登录密码
spring.datasource.druid.stat-view-servlet.login-password=admin
spring.shardingsphere.props.sql.show=false
#数据库名
spring.shardingsphere.datasource.names=dp0,dp1,dp2,dp3,dp4
#datasource
spring.shardingsphere.datasource.dp0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.dp0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.dp0.url=jdbc:mysql://localhost:3306/my-sharding_0?useUnicode=true&characterEncoding=utf-8&serverTimeZone=CTT&allowPublicKeyRetrieval=true&serverTimezone=UTC
spring.shardingsphere.datasource.dp0.username=root
spring.shardingsphere.datasource.dp0.password=123456
----------相同的代码部分这里就不贴了-------
# 对应 dp1、dp2、dp3、dp4 和上面dp0配置类似,不一样的就是数据库名字不一样
# 因为我使用的本地创建多个数据库演示的,这里就没有必要重复累赘了
#actual-data-nodes
#这里是配置所有的 库.表 的集合
#比如我这里配置的意思是 dp0.data_0 , dp0.data_1 ,dp0.data_2 , ...
#此缩写方式使用了shardingsphere 官方推荐的语法
#t_user 逻辑表名 在UserMapper.xml中使用
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=dp$->{0..4}.t_user_$->{0..4}
#table
#设置了以data中字段id作为分表的标准,这样到时候就会将id作为参数传入到下面配置的我们自定义的分表方法中做具体操
spring.shardingsphere.sharding.tables.t_user.table-strategy.standard.sharding-column=id
spring.shardingsphere.sharding.tables.t_user.table-strategy.standard.precise-algorithm-class-name=com.tian.shardingdemo.common.TableShardingAlgorithm
#database
#设置了以data中字段id作为分库的标准,这样到时候就会将id作为参数传入到下面配置的我们自定义的分库方法中做具体操作
spring.shardingsphere.sharding.tables.t_user.database-strategy.standard.sharding-column=id
spring.shardingsphere.sharding.tables.t_user.database-strategy.standard.precise-algorithm-class-name=com.tian.shardingdemo.common.DbShardingAlgorithm分库分表的两个分片类:
/**
* 分库
*/
public class DbShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
private Logger logger = LoggerFactory.getLogger(DbShardingAlgorithm.class);
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
String databaseName = availableTargetNames.stream().findFirst().get();
for (String dbName : availableTargetNames) {
//shardingValue.getValue()就是配置的传入的值
//我们这里选用的是传入sql中的id字段的值
String targetDbName= "dp" + genderToTableSuffix(shardingValue.getValue());
if (dbName.equals(targetDbName)) {
//匹配到对应的数据库,比如 dp0
//这个数据库名对应数据源处配置的dp0,dp1,...
logger.info("数据库名=" + dbName);
databaseName = dbName;
}
}
return databaseName;
}
private String genderToTableSuffix(Long value) {
//将id字段的值去hash值后去模运算得到分库的数字(就是一种算法而已)
int i = Hashing.murmur3_128(1823977).newHasher().putString(String.valueOf(value), Charsets.UTF_8).hash().asInt();
//hash与表个数进行取模
return String.valueOf(Math.abs(i) % 5);
}
}
/**
* 分表
*/
public class TableShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
private Logger logger = LoggerFactory.getLogger(TableShardingAlgorithm.class);
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
String table = availableTargetNames.stream().findFirst().get();
String targetName = "t_user_" + genderToTableSuffix(shardingValue.getValue());
for (String tableName : availableTargetNames) {
//检查计算出来的表名是否存在
if (tableName.equals(targetName)) {
logger.info("表名= " + tableName);
table = tableName;
}
}
return table;
}
private String genderToTableSuffix(Long value) {
//算出一个hash值 int类型
int i = Hashing.murmur3_128(8947189).newHasher().putString(String.valueOf(value), Charsets.UTF_8).hash().asInt();
//hash与表个数进行取模
return String.valueOf(Math.abs(i) % 5);
}
}下面是业务部分代码,先看UserMapper.xml内容:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.tian.shardingdemo.mapper.UserMapper">
<resultMap id="User" type="com.tian.shardingdemo.entity.User">
<id column="id" property="id"/>
<result column="user_name" property="userName"/>
</resultMap>
<insert id="insert">
INSERT INTO t_user (id, user_name,age,gender) VALUES ( #{id},#{userName},#{age},#{gender}
);
</insert>
<select id="selectUserById" resultMap="User">
select * from t_user
<where>
<if test="id != null">
id = #{id}
</if>
</where>
</select>
<update id="updateAuthorIfNecessary">
update t_user
<trim prefix="SET" suffixOverrides=",">
<if test="userName != null and userName != ''">
`user_name` = #{userName},
</if>
<if test="gender != null and gender != 0">
gender = #{gender},
</if>
<if test="age != null and age != 0">
age = #{age},
</if>
</trim>
where id=#{id}
</update>
</mapper>UserMapper接口:
import com.tian.shardingdemo.entity.User;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.springframework.stereotype.Repository;
@Mapper
@Repository
public interface UserMapper {
User selectUserById(@Param("id") Long id);
int updateAuthorIfNecessary(User user);
int insert(User user);
}为了更好地演示,我这里加入了controller层和service层,这也是大家平常开发套路。
service层代码如下:
public interface IUserService {
User selectUserById(Long id);
void add(Long id);
}
@Service
public class UserServiceImpl implements IUserService {
@Resource
private UserMapper userMapper;
@Override
public User selectUserById(Long id) {
return userMapper.selectUserById(id);
}
@Override
public void add(Long id) {
User user = new User();
user.setAge(22);
user.setGender(1);
user.setId(id);
user.setUserName("tian" + id);
userMapper.insert(user);
}
}controller层代码如下:
public interface IUserService {
User selectUserById(Long id);
void add(Long id);
}
@Service
public class UserServiceImpl implements IUserService {
@Resource
private UserMapper userMapper;
@Override
public User selectUserById(Long id) {
return userMapper.selectUserById(id);
}
@Override
public void add(Long id) {
User user = new User();
user.setAge(22);
user.setGender(1);
user.setId(id);
user.setUserName("tian" + id);
userMapper.insert(user);
}
}最后是项目的启动类:
@SpringBootApplication
@MapperScan({"com.tian.shardingdemo.mapper"})
public class ShardingDemoApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingDemoApplication.class, args);
}
}启动项目,启动成功:

下面我们来演示一下新增数据和查询。
添加数据到数据库中
先来添加数据到数据库中,这里使用的是IDEA中restful工具:

后台日志:

再查看数据库表中:
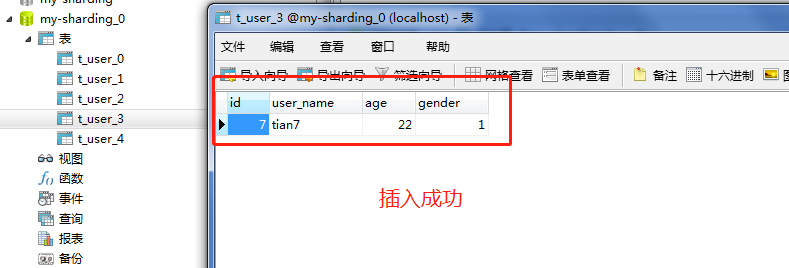
到此,我们的数据依旧落库,下面我们来演示一下数据查询。
数据查询
浏览器里输入:
http://localhost:9002/user/7
返回数据:
{"id":7,"userName":"tian7","age":22,"gender":1}
后台日志:

从日志和返回结果可以看出,已经为我们正确的选择到对应的数据库和表了,这样,一个分库分表的查询就成功了。
总结
本文没有太多的概念,直接使用案例演示。相关概念性的文章,还有分库分表解决方案的文章,网上一堆堆的,感兴趣可以自行查阅。
参考:http://01vh0.cn/mLQwN